1. Introduction
Machine Learning (ML) has continuously attracted the interest of the research community motivated by the promising results obtained in many decision-critical domains. Along with the interest arises some concerns related to the trustworthiness and robustness of the models [
1]. The notion of uncertainty is of major importance in ML, and a trustworthy representation of uncertainty should be considered as a key feature of any ML method [
2,
3]. In application domains such as medicine, information about the reliability of the automated decisions is crucial to improve the system’s safety [
4,
5]. Uncertainty also plays a role in AI at the methodological level, such as in active learning [
6,
7] and self-training [
8,
9].
Uncertainty is ubiquitous and happens in every single event we encounter in the real-world arising from different sources in various forms. According to the origin of uncertainty, a distinction between aleatoric uncertainty and epistemic uncertainty is commonly used. Aleatoric uncertainty refers to the inherent randomness in nature, and epistemic uncertainty refers to uncertainty caused by lack of knowledge of the physical world (knowledge uncertainty), as well as the ability to measure and model the physical world (model uncertainty) [
10]. In ML, these two sources of uncertainty are usually not distinguished. However, some studies have been proposed showing the usefulness of quantifying and distinguishing the sources of uncertainties in different applications, such as self-driving cars [
11], where the authors emphasize “the importance of epistemic uncertainty or ‘uncertainty on uncertainty’ in these AI-assisted systems”, referring to the first accident of a self-driving car that led to the death of the driver, or in medicine, where the authors focused their evaluation on medical data of chest pain patients and their diagnoses [
12].
Until recently, almost all evaluations of ML-based recognition algorithms have taken the form of “close set” recognition, where it is assumed that the train and test data distributions are the same and that all testing classes are known at training time [
13]. However, a more realistic scenario for deployed classifiers is to assume that the world is an open set of objects, that our knowledge is always incomplete and, thus, the unknown classes should be submitted to an algorithm during testing [
14]. For instance, the diagnosis and treatment of infectious diseases relies on the accurate detection of bacterial infections. However, deploying a ML method to perform bacterial identification is challenging, as real data are highly likely to contain unseen classes not seen in training data [
15]. Similarly, verification problems for security-oriented face matching or unplanned scenarios for self-driving cars lead to what is called “open set” recognition, in comparison to systems that use “close set” recognition.
Based on the basic recognition categories of classes asserted by Scheirer et al. [
16], there are three categories of classes:
known classes: classes with distinctly labeled positive training samples (also serving as negative samples for other known classes);
known unknown classes: classes labeled negative samples, not necessary grouped into meaningful categories;
unknown unknown classes: classes unseen in training.
Traditional supervised classification methods consider only known classes. Some improved the implementation by starting to include known unknown results in models with an explicit “other class” or a detector trained with unclassified negatives. Open Set Recognition (OSR) algorithms, where new classes unseen in training appear in testing, considers the unknown unknown classes category. In this scenario, the classifier needs not only to accurately classify known classes but also effectively reject unknown classes. Although the classification with a reject option is more than 60 years old [
17], the focus on rejection has been the ambiguity between classes (aleatoric uncertainty), not for addressing unknown inputs (epistemic uncertainty). Based on Chow’s theory, the inputs are rejected if the posterior probability is not sufficiently high based on a predefined threshold that optimizes the ambiguous regions between classes. Epistemic uncertainty is high near the decision boundary, and most classifiers increase confidence with the distance from the decision boundary. Thus, an unknown far from the boundary is not only incorrectly labeled but will be incorrectly classified with very high confidence [
14]. Although classification with rejection is related to OSR, it still works under the close set assumption where a classifier rejects to classify a sample due to its low confidence on an overlapping region between classes, which leads to high aleatoric uncertainty. For OSR problems, One-Class Classification (OCC) is commonly used since it tries to focus on the known class and ignore everything else. A popular approach for OSR scenario using OCC is to adapt the familiar Support Vector Machine (SVM) methodology using a one-vs-one or one-vs-all scenario. OSR problems are usually focused on novel, anomaly or outlier detection, so that they are only interested in the epistemic uncertainty due to the lack of knowledge. Although the OSR method indirectly deals with epistemic uncertainty, a proper uncertainty quantification is rarely done.
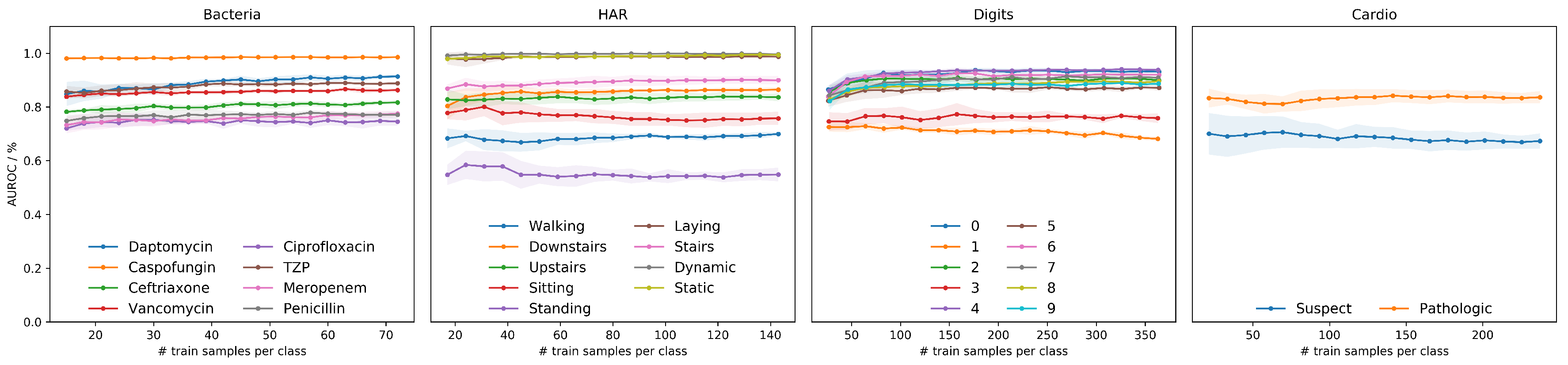
In this work, we focus on uncertainty quantification of individual predictions, where an input can be rejected for both aleatoric and epistemic uncertainty. Due to the difficulty of dealing with unknown samples, we propose a new method for knowledge uncertainty quantification and combined it with measures of entropy using ensemble techniques. The experimental results are validated on four datasets with different data modalities:
a human activity dataset using inertial data from smartphones where uncertainty estimation plays an important role in the recognition of abnormal human activities. Indoor location solutions can also benefit from a proper uncertainty estimation where high confident activity classifications should increase positioning accuracy;
a handwritten digits dataset using images where uncertainty estimation might be used for unrecognized handwritten digits;
a bacterial dataset using Raman spectra for the identification of bacteria pathogens where novel pathogens often appear and its identification is critical;
a cardiotocograms dataset using fetal heart rate and uterine contraction where rarely seen conditions of patient data can be accessed through uncertainty estimation.
Overall, the contributions of this work can be summarized as follows:
a new uncertainty measure for quantifying knowledge uncertainty and rejecting unknown inputs;
a combination strategy to incorporate different uncertainty measures, evaluating the increase of classification accuracy versus rejection rate by uncertainty measures;
an experimental evaluation of in- and out-distribution inputs over four different datasets and eight state-of-the-art methods.
2. Uncertainty in Supervised Learning
The awareness of uncertainty is of major importance in ML and constitutes a key element of ML methodology. Traditionally, uncertainty in ML is modeled using probability theory, which has always been perceived as the reference tool for uncertainty handling [
2]. Uncertainty arises from different sources in various forms and is commonly classified into aleatoric uncertainty or epistemic uncertainty. Aleatoric uncertainty is related to data and increases with the increase of noise in the observations, which can cause class overlap. On the other hand, epistemic uncertainty is related to the model and the knowledge that is given to it. This uncertainty increases with test samples in out-of-distribution (OOD) regions, and it captures the lack of knowledge of the model’s parameters. Epistemic uncertainty can be reduced with the collection of more samples. However, aleatoric uncertainty is irreducible [
18]. Although traditional probabilistic predictors may be a viable approach for representing uncertainty, there is no explicit distinction between different types of uncertainty in ML.
2.1. Uncertainty on Standard Probability Estimation
In the standard probabilistic modeling and Bayesian inference, the representation of uncertainty about a prediction is given by the probability of the predicted class. Considering a distribution
over input features
x and labels
, where
consists of a finite set of
K class labels, the predictive uncertainty of a classification model
trained on a finite dataset
, with
N samples, is an uncertainty measure that combines aleatoric and epistemic uncertainty. The probability of the predicted class, or maximum probability, is a measure of confidence in the prediction that can be obtained by
Another measure of uncertainty is the (Shannon) entropy of the predictive posterior distribution, which behaves similarly to maximum probability, but represents the uncertainty encapsulated in the entire distribution:
Both maximum probability and entropy of the predictive posterior distribution can be seen as measures of the total uncertainty in predictions [
19]. These measures of uncertainty for probability distributions primarily capture the shape of the distribution and, hence, are mostly concerned with the aleatoric part of the overall uncertainty. In this paradigm, the classification with a rejection option introduced by Chow [
17] suggests that objects are rejected for which the maximum posterior probability is below a threshold. If the classifier is not sufficiently accurate for the task at hand, then one can take the approach not to classify all examples, but only those whose posterior probability is sufficiently high. Chow’s theory is suitable when a sufficiently large training sample is available for all classes and when the training sample is not contaminated by outliers [
20]. Fumera et al. [
21] show that Chow’s rule does not perform well if a significant error in probability estimation is present. In that case, a different rejection threshold per class has to be used. In classifiers with a rejection option, the key parameters are the thresholds that define the reject area, which may be hard to define and may vary significantly in value, especially when classes have a large spread. Additionally, Bayesian inference is more akin to aleatoric uncertainty, and it has been argued that probability distributions are less suitable for representing ignorance in the sense of lack of knowledge [
2,
22].
2.2. Knowledge Uncertainty
Knowledge uncertainty is often associated with novelty, anomaly or outlier detection where the testing samples come from a different population than the training set. Approaches based on generative models typically use densities,
, to decide whether to reject a test input that is located in a region without training inputs. These low-density regions, where no training inputs have been encountered so far, represent a high knowledge uncertainty. Traditional methods, such as Kernel Density Estimation (KDE), can be used to estimate
, and often threshold-based methods are applied on top of the density where a classifier can refuse to predict a test input in that region [
23]. Related to this topic is the closed-world assumption, which is often violated in experimental evaluations of ML algorithms. Almost all supervised classification methods assume that all train and test data distributions are the same and that all classes in the test set are present in the training set. However, this is unrealistic for many real-world applications where new unseen classes in training appear in testing. This problem has been studied under different names with varying levels of difficulty, including the previously mentioned classification with rejection option, OOD detection and OSR [
24]. In the classification with a rejection option, the test distribution has usually the same classes as the training distribution, and the classifier rejects inputs it cannot confidently classify. OOD detection is the ability of a classifier to reject a novel input rather than assigning it an incorrect label. In this setting, OOD inputs are usually considered as outliers that come from entirely different datasets. This topic is particularly important in deep neural networks and has been recognized by several studies showing that deep neural networks usually predict OOD inputs with high confidence [
25,
26]. The OSR approach is similar to OOD detection and can be viewed as tackling both the classification and novelty detection problem at the same time. Contrary to the OOD detection, the novel classes that are not observed during training are often made up of the remaining classes in the same dataset. This task is probably the hardest one because the statistics of a class are often very similar to the statistics of other classes in the dataset [
24]. In each case, the goal is to correctly classify inputs that belong to the same distribution as the training set and to reject inputs that are outside this distribution.
A number of approaches have been proposed in the literature to handle unknown classes in the testing phase [
27,
28]. A popular and promising approach for open-set scenarios is the OCC since it focuses on the known class and ignores any additional class. OCC problems consist of defining the limits of all, or most, of the training data, by having a single target class. All the samples outside those limits will be considered outliers [
29]. SVM models are commonly used in OCC problems by fitting a hyperplane that separates normal data points from outliers in a high-dimensional space [
30]. Typically, SVM model separates the training set containing only samples from the known classes by the widest interval possible. Training samples on the OOD region are penalized, and the prediction is made by assigning the samples to the known or unknown region. Binary classification with the one-vs-all approach can also be applied to the open-set recognition [
31]. In this scenario, the most confident binary classifier which classifies as in-distribution is chosen to predict the final class of the multiclass classifier. When there is no in-distribution classification from the binary classifiers, the test sample is classified as unknown. Different adaptions of OCC and variations of the SVM have been applied for OSR aiming at minimizing the risk of the unknown classification [
13,
16,
32]. However, a drawback of these methods is the need for re-training the models from scratch, at a relatively high computational cost, when new classes are discovered and become available. Therefore, they are not well-suited for incremental updates or scalability required for open-world recognition [
33]. Distance-based approaches are more suitable to open-world scenarios, since the addition of new classes to existing classes can be made at near-zero cost [
34]. Distance-based classifiers with a rejection option are easily applied to OSR because the classifiers can create a bounded known space in the feature space, rejecting test inputs that are far away from training data. For instance, the Nearest Class Mean (NCM) classifier is a distance-based classifier that represents classes by their mean feature vector of its elements [
34]. The problem for most of the methods dealing with rejection by thresholding the similarity score is the difficulty to determine such a threshold that defines whether a test input is an outlier or not. In this context, Júnior et al. [
35] extended the traditional close-set Nearest Neighbor classifier applying a threshold on the ratio of similarity scores of the two most similar classes and called it Open Set Nearest Neighbors (OSNN).
2.3. Combined Approaches for Uncertainty Quantification
The previously mentioned studies do not explicitly quantify uncertainty nor distinguish the different sources of uncertainty. However, we argue that probabilistic methods are more concerned with handling aleatoric uncertainty to reject low-confident inputs, and OSR algorithms are mainly focused on effectively rejecting unknown inputs, which intrinsically have a high epistemic uncertainty due to the lack of knowledge.
However, in a real-world applications, and advocating a trustworthy representation of uncertainty in ML, both sources are important, and a proper distinction between them is desirable, all the more in safety-critical applications of ML. Motivated by such scenarios, several works have been developed for uncertainty quantification showing the usefulness of distinguishing both types of uncertainty in the context of Artificial Intelligence (AI) safety [
11,
12]. Some initial proposals for dealing with OSR and properly quantify uncertainty can already be found in the literature, mostly in the area of deep neural networks [
19,
36].
An approach for the quantification of aleatoric, epistemic, and total uncertainty (given by the sum of the previous two uncertainties) separately is to approximate these measures by means of ensemble techniques [
19,
37], presenting the posterior distribution
by a finite ensemble of
M hypotheses,
, that map instances
x to probability distributions on outcomes. This approach was developed in the context of neural networks for regression [
38], but the idea is more general and can also be applied to other settings, such as in the work of Shaker et al. [
37] where the measures of entropy were applied using the Random Forest (RF) classifier. Using an ensemble approach,
, a measure of total uncertainty can be approximate by the entropy of predictive posterior given by
An ensemble estimate of aleatoric uncertainty considers the average entropy of each model in an ensemble. The idea is that by fixing a hypotheses
h, the epistemic uncertainty is essentially removed. However, since
h is not precisely known, the aleatoric uncertainty is measured in terms of the expectation of entropy with regard to the posterior probability:
Epistemic uncertainty is measured in terms of mutual information between hypotheses and outcomes, which is a measure of the spread of an ensemble. Epistemic uncertainty can be expressed as the difference of the total uncertainty, captured by the entropy of expected distribution, and the expected data uncertainty, captured by expected entropy of each member of the ensemble [
19].
Epistemic uncertainty is high if the distribution varies a lot for different hypotheses h with high probability but leading to quite different predictions.
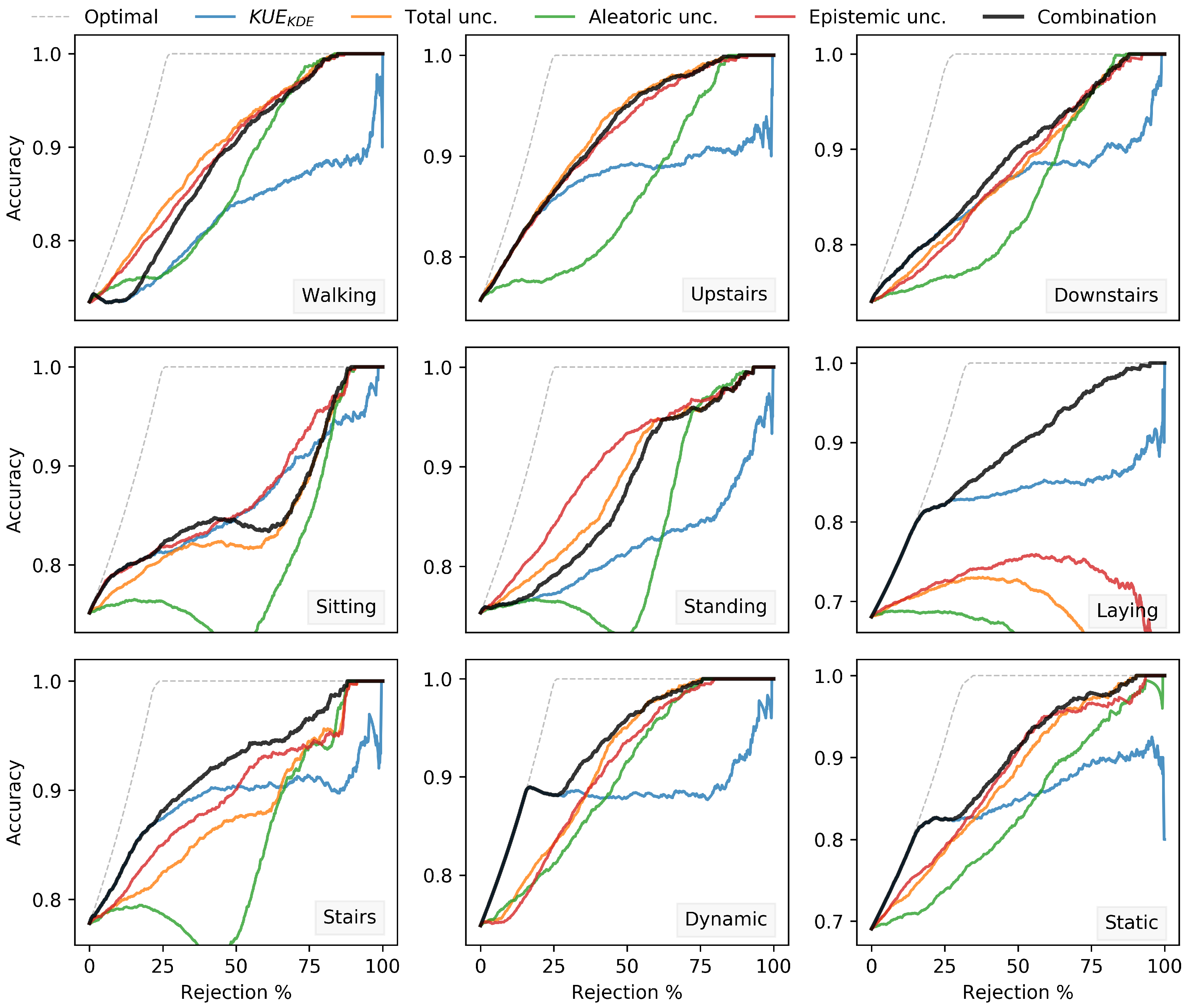
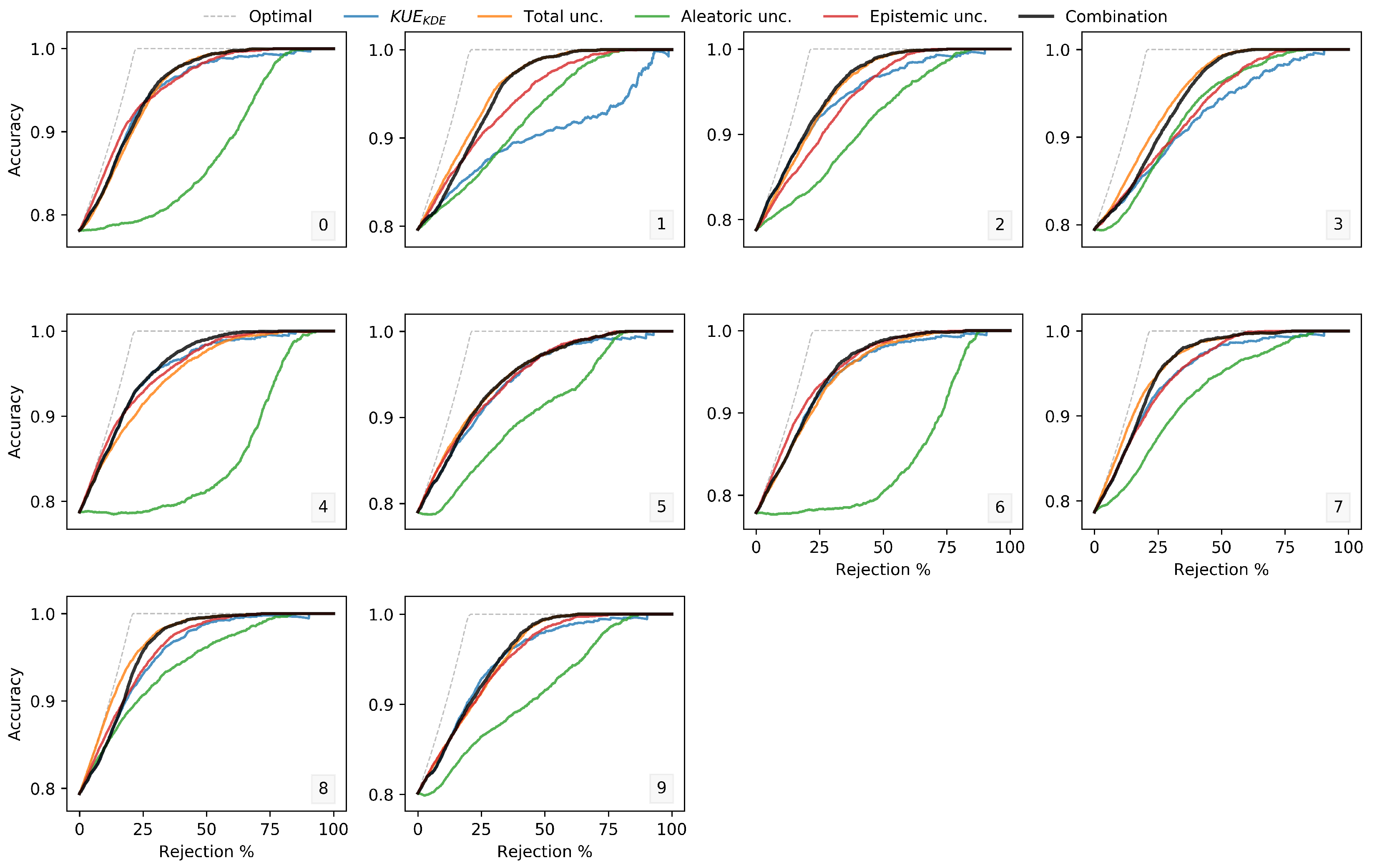
Finally, besides the uncertainty quantification into aleatoric, epistemic and total uncertainty, there are also open questions regarding the empirical evaluation of different methods, since data usually do not contain information about ground truth uncertainty. Commonly the evaluation is done indirectly through the increase of successful predictions, such as the Accuracy-Rejection (AR) curve which depicts the accuracy of a predictor as a function of the percentage of rejections [
2].
3. Proposed Method
In this paper, we are interested in predictive uncertainty, where the uncertainty related to the prediction
over input features
x is quantified in terms of aleatoric and epistemic (and total) uncertainty. Due to the complexity of novelty, anomaly or outlier detection, a specific uncertainty measure to deal with knowledge uncertainty is also proposed, summarizing the relationship of novelty detection and multiclass recognition as a combination of OSR problems. We formulate the problem as traditional OSR where a model is trained only over in-distribution data, denoted by a distribution
, and tested on a mixture distribution with in- and out-distribution inputs, drawn from
and
where the latter represents the out-distribution data. Given a finite training set
drawn from
where
is the
i-th training input and
is the finite set of class labels, a classifier is trained to correctly identify the class label from
and to reject unknown classes not seen in training from
by an uncertainty threshold. In
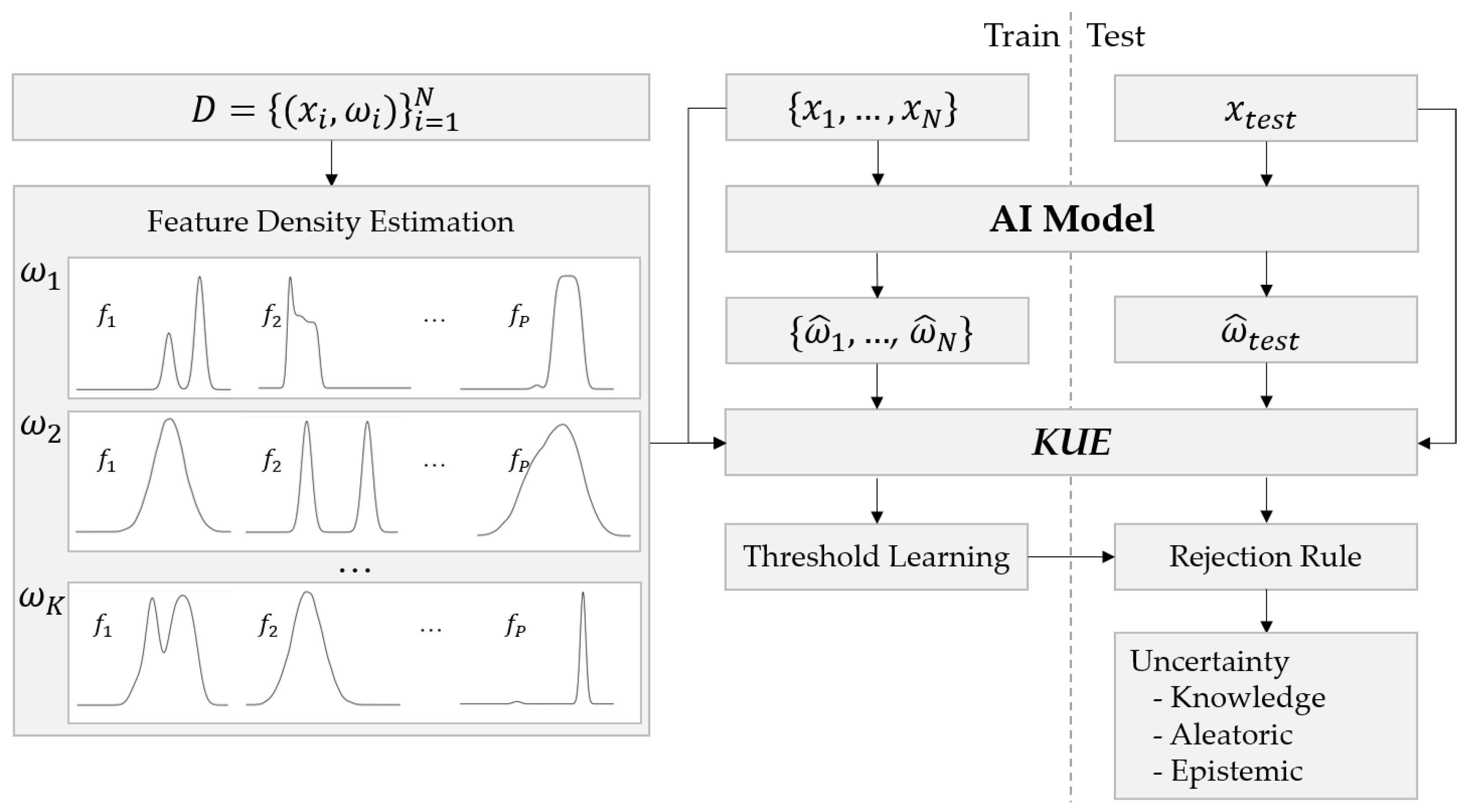
Figure 1, the main steps of the proposed approach are summarized. Besides the traditional classification processes, our method learns the feature density estimation from the training data to feed the Knowledge Uncertainty Estimation measure used for rejecting test inputs with an uncertainty value higher than the learned threshold during training. Finally, each prediction is also quantified using entropy measures in terms of total uncertainty or aleatoric and epistemic uncertainty if ensemble techniques are used.
Uncertainty is modeled through a combination of a normalized density estimation over input feature space for each known class. Assuming an input
represented by
P-dimensional feature vectors, where
is the feature vector in a bounded area of the feature space, an independent density estimation of the
P features conditional by the class label is estimated and normalized by its maximum density, in order to set all values in the interval
. Thus, each feature density is transformed on an uncertainty distance,
, assuming values in
, where 1 represents the maximum density seen in training, and near-zero values represent low-density regions where no training inputs were observed during training. The combination between each feature distance is computed by the product rule over whole features. Thus, given a test input
from class
the uncertainty is measured using the proposed Knowledge Uncertainty Estimation method,
, calculated by
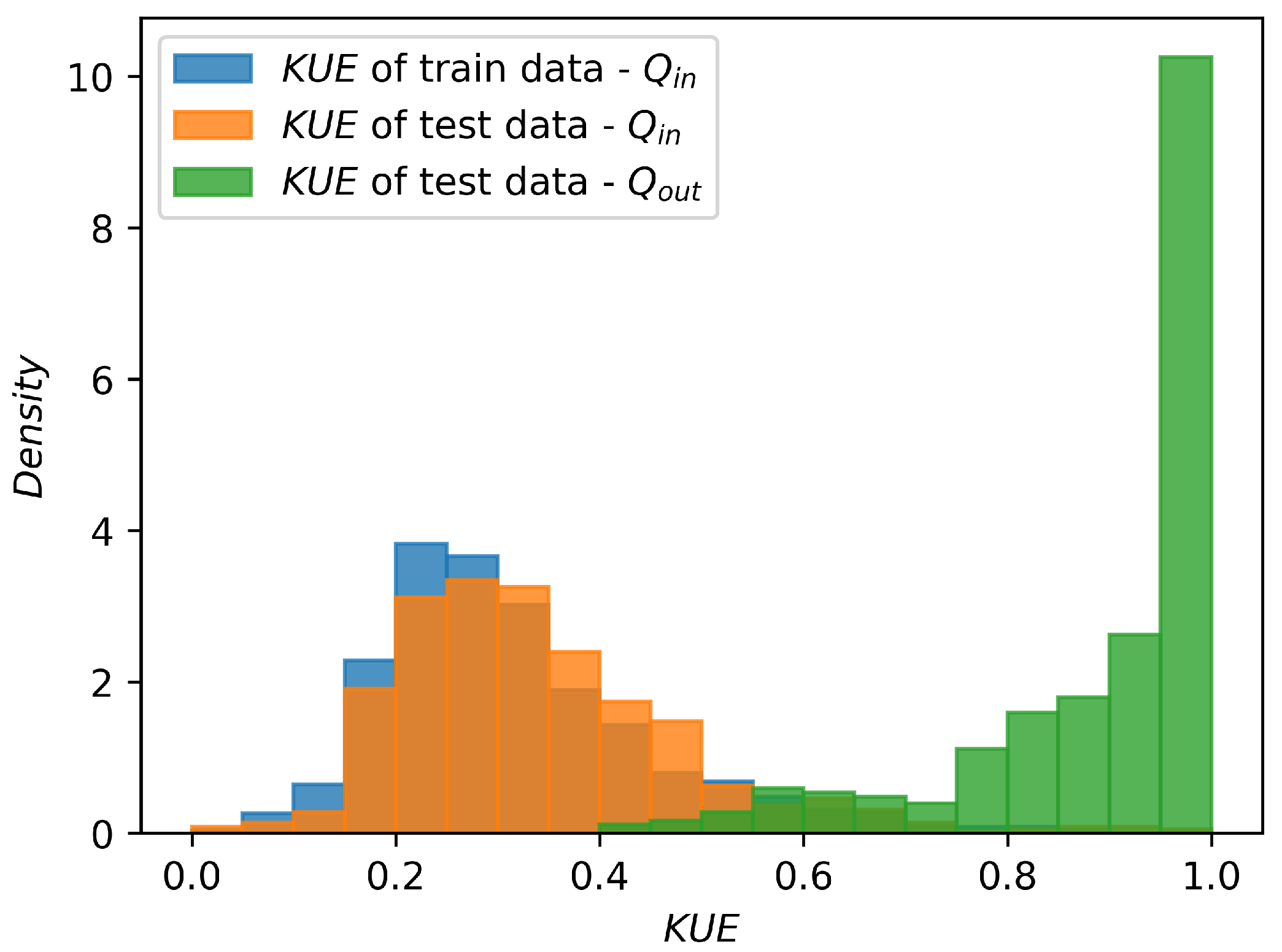
An example of the proposed uncertainty measure distribution over a Bacteria dataset (we will present and discuss this dataset in
Section 4.1) with a 30-dimensional feature vector, 28 known classes and 2 unknown classes is shown in
Figure 2.
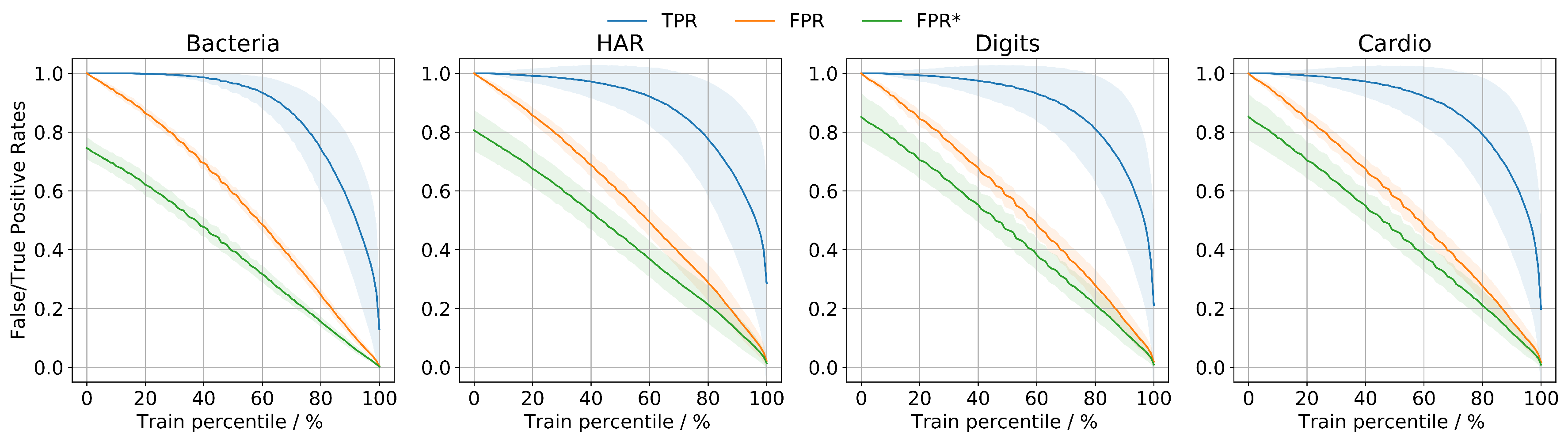
A common approach to define a threshold for OOD or even to tune a model’s hyperparameters is to use a certain amount of OOD as validation data. However, this approach is unrealistic due to the proper definition of OOD inputs that come from an unknown distribution, leading to compromised performance in real-world applications, as Shafei et al. [
39] showed in their recent study. Therefore, we argue that a more realistic approach is to learn a threshold only from in-distribution data. Due to the differences between data from different datasets, learning a global threshold for all datasets is not a reliable approach. Therefore, our hypothesis is that if we learn the training uncertainty distribution for each class within a dataset, there is a specific threshold for each distribution that will bound our uncertainty space, so input samples that fall outside the upper bound threshold are rejected. The upper bound threshold is defined based on a predefined percentile from the training uncertainty distribution. The percentile choice is defined according to different applications scenarios, whether the end-user is willing reject more or less in-distribution samples. As train and test in-distribution data come from the same distribution it is expected that the percentage of reject samples from test data will represent approximately 10% if the chosen percentile is set to 90%. From this 10% we can also argue that a certain percentage can represent classification errors or, if rejected samples were correctly classified, the classification was done under limited evidence so that a high uncertainty is associated with that decision. Thus, the rejection rule for input sample
for in- and out-distribution is given by
in Equation (
7), where
represents the uncertainty value for the
r-th percentile of the train uncertainty data distribution associated with class
. The output values
and 1 mean that the input sample
is rejected or accepted, respectively:
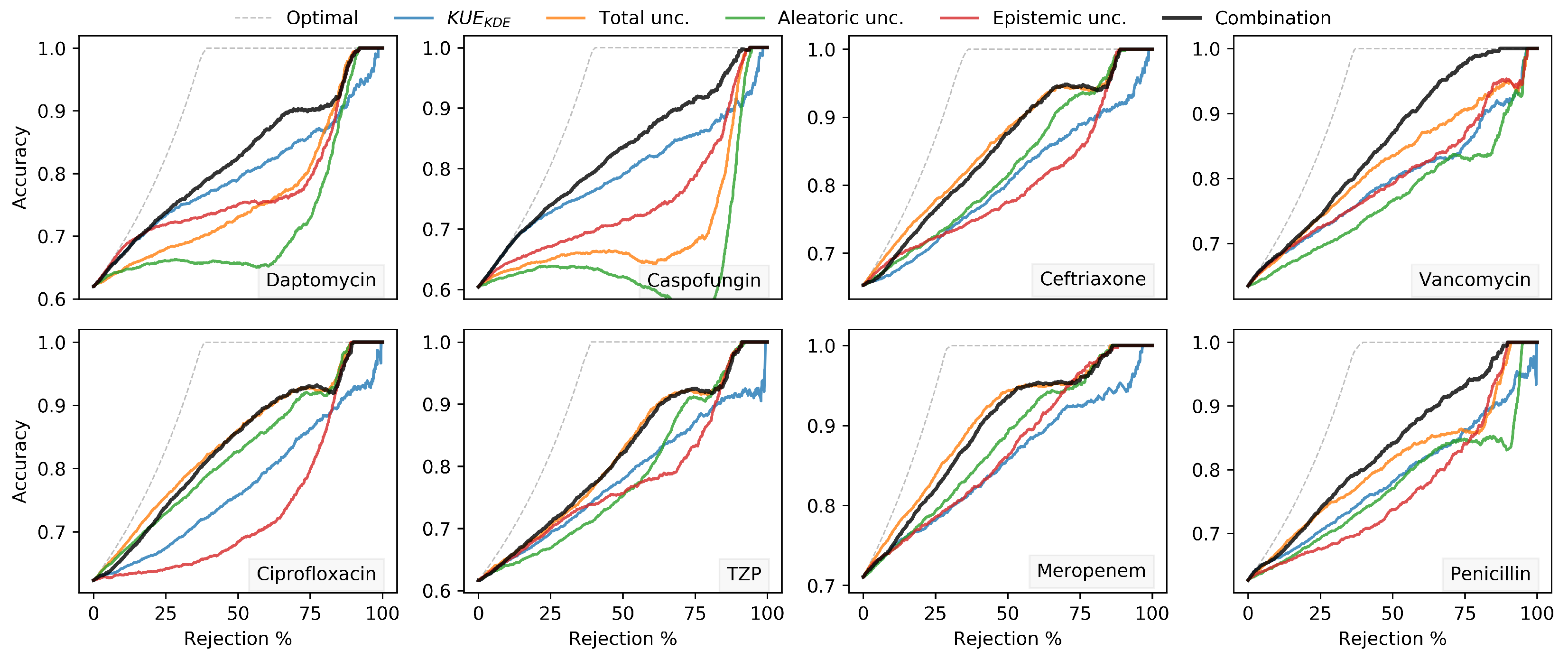
Since the proposed measure only deals with knowledge uncertainty, besides the in- and out-distribution detection we also combined our proposed approach with the uncertainty measures presented in Equations (
3)–(
5) to quantify total, aleatoric and epistemic uncertainty, respectively.
5. Discussion and Conclusions
The importance of uncertainty quantification in ML has recently gained attention in the research community. However, its proper estimation is still an open research area. In a standard Bayesian setting, uncertainty is reflected by the predicted posterior probability, which is more akin to the aleatoric part of the overall uncertainty. On the other hand, epistemic uncertainty is commonly associated with OOD detection problems, despite its quantification not being explicitly performed. Although OSR settings are a more realistic scenario for the deployment of ML models, they are mainly focused on effectively rejecting unknown inputs.
With this in mind, we proposed a new method for knowledge uncertainty estimation, KUE, and combined it with the classical information-theoretical measures of entropy proposed in the context of neural networks for distinguishing aleatoric, epistemic and total uncertainty by means of ensemble techniques.
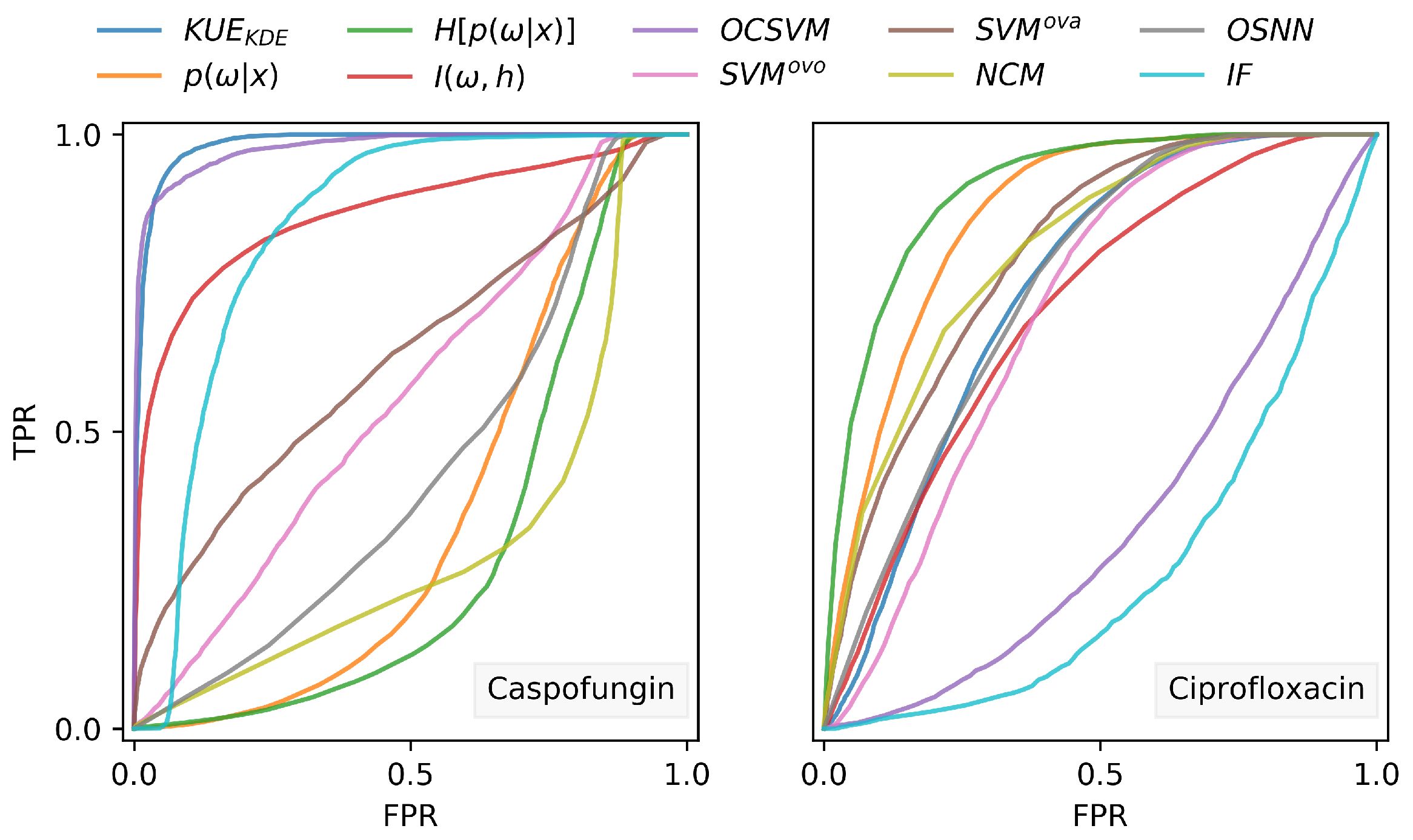
Our proposed KUE method is based on a feature level density estimation of in-distribution train data, and it does not rely on out-distribution inputs for hyperparameters tuning nor for threshold selection. Since different classifiers have different accuracies for the classification of the very same data, we proposed a method that, although dependent on the classification accuracy, can be easily applied to any feature level model without changing the underlying classification methodology. As the nature of the data is often difficult to determine, we proposed a KDE method for feature density estimation. However, due to the computational cost of KDE with the increase of training size, we also compared the proposed method using a Gaussian distribution. For the four different datasets used for evaluation, Gaussian estimation showed similar results with KDE, which can significantly reduce the computational cost on large datasets. Nevertheless, if possible, the train data distribution can be calculated to choose the best kernel to be applied. Regarding the AUROC, our method KUE showed competitive performance results comparable to state-of-the-art methods. Furthermore, we also defined a threshold for OOD input rejection that is chosen based on the percentage of in-distribution test samples that we are willing to reject. We showed its dependency on FPR and also demonstrated that misclassified inputs tend to have high uncertainty values. Although the proposed threshold selection strategy effectively controlled the FPR, the TPR had a high variability between different datasets, and it was not possible to estimate its behavior for unknown inputs. For future research, this limitation should be addressed by combining KUE with different methods adopting a hybrid generative discriminative model perspective.
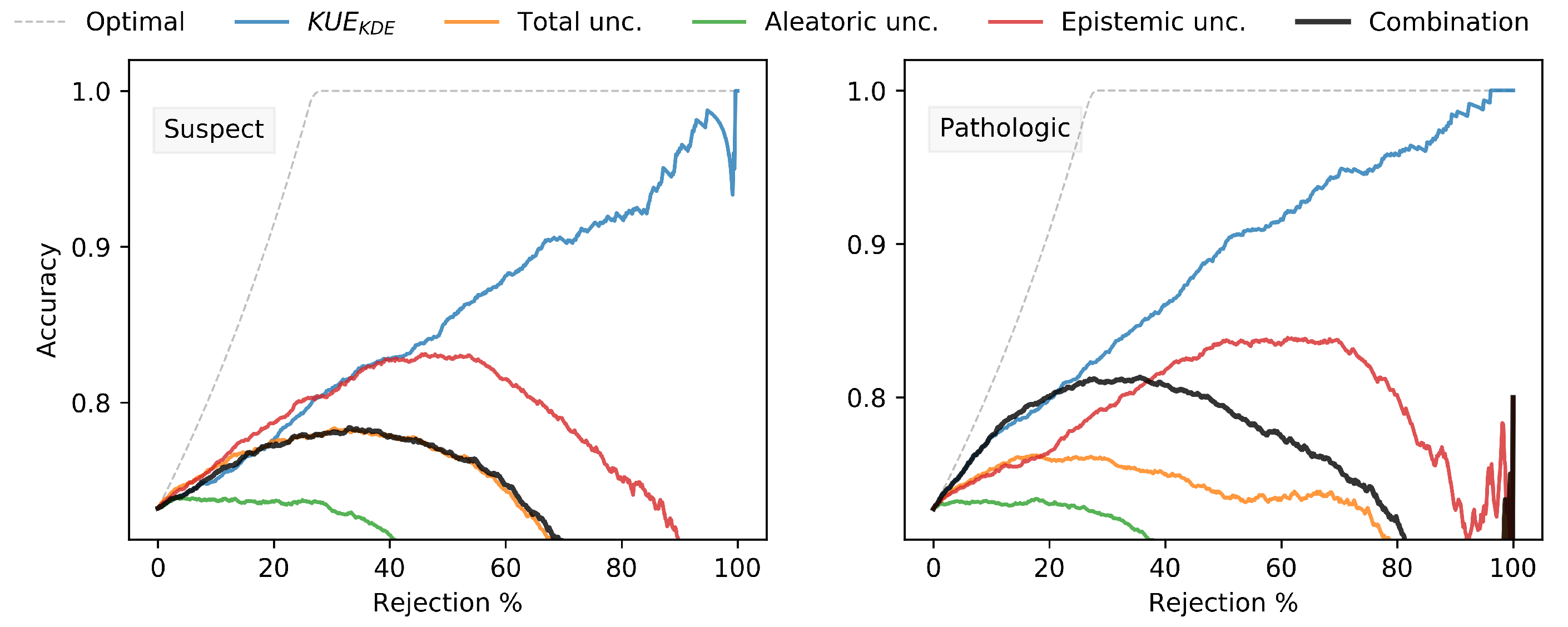
The aleatoric, epistemic and total uncertainty produced by measures of entropy showed a monotone dependency between reject rate and classification accuracy, which confirmed that these measures of uncertainty are a reliable indicator of the uncertainty involved in a classification decision. Moreover, the proposed uncertainty measures combination between our proposed KUE method and total uncertainty outperformed the individual entropy measures of uncertainty for the classification with a rejection option.
Future research includes the study of different combination strategies of uncertainty measures for classification with a rejection option. Leveraging the uncertainty for the interpretability of the rejected inputs is another interesting research direction. In addition, expanding the testing scenarios with more datasets should provide more indications about the robustness of the measures used. If more specialized OOD detection methods are able to properly quantify their own uncertainty, different combinations between existing methods and other sources of uncertainty should also be explored.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








