
Review of Automatic Microexpression Recognition in the Past Decade



Abstract
:1. Introduction
2. Features Used in Microexpression Recognition
2.1. 3D Histograms of Oriented Gradients (3DHOG)
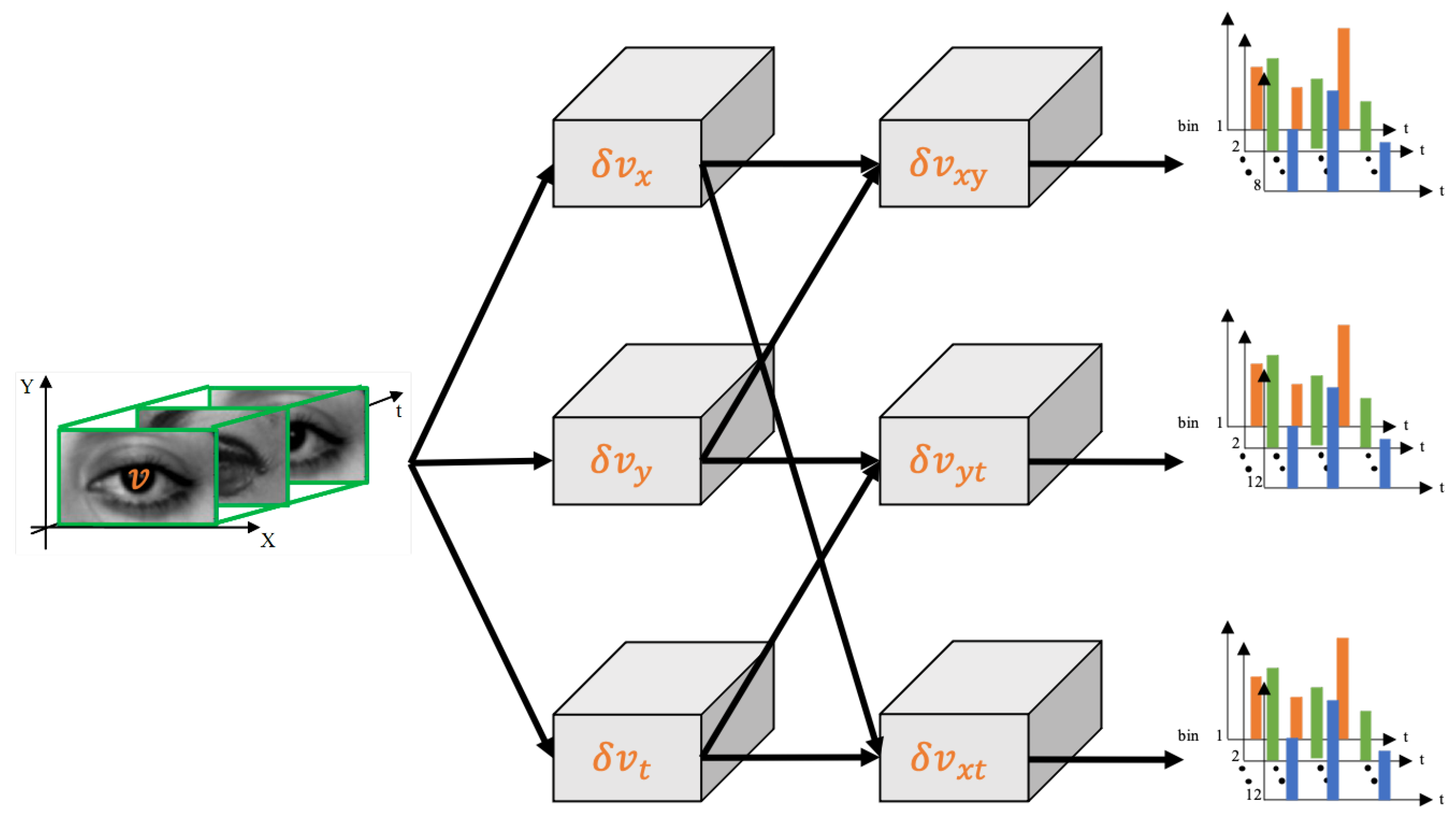
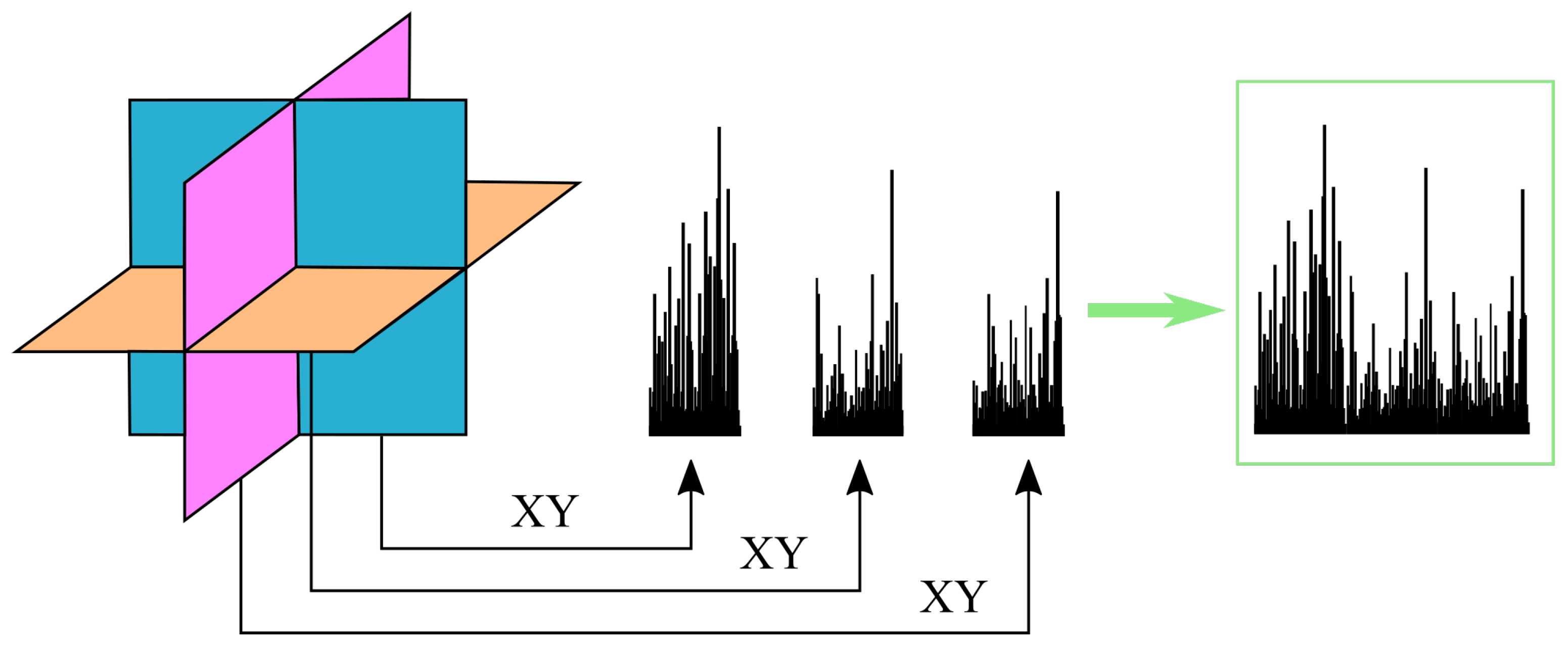
2.2. Local Binary Pattern-Three Orthogonal Planes (LBP-TOP)
2.3. Histogram of Oriented Optical Flow (HOOF)
2.4. Deep Learning
2.5. Closing Remarks
3. Microexpression Databases
3.1. Open-Source Spontaneous Microexpression Databases
3.1.1. CASME
3.1.2. SMIC
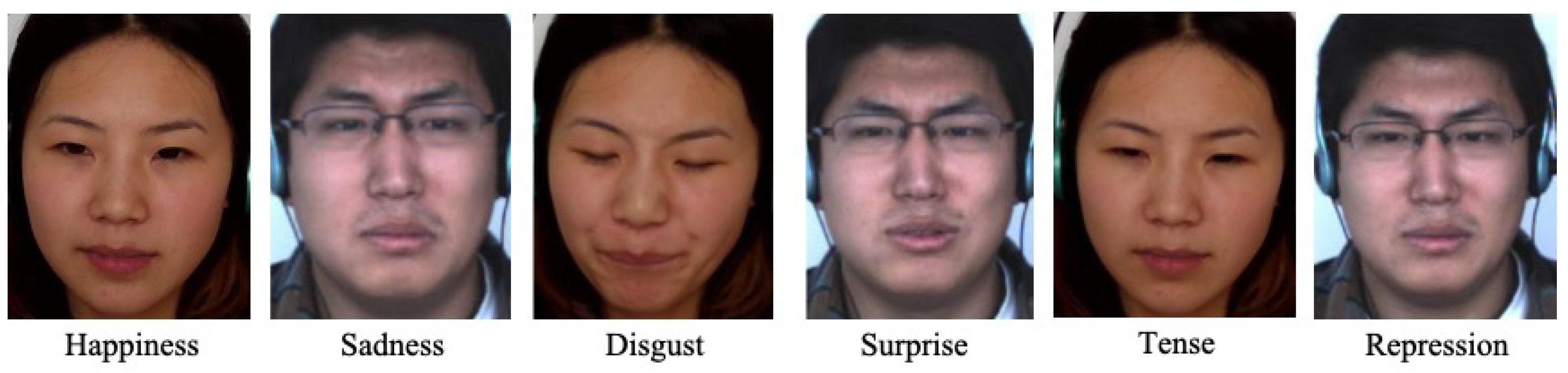
3.1.3. CASME II
3.1.4. SAMM
3.1.5. CAS(ME)
3.2. Data Collection and Methods for Systematic Microexpression Evocation
3.2.1. CAS Data Acquisition Protocol
3.2.2. SMIC Data Acquisition Protocol
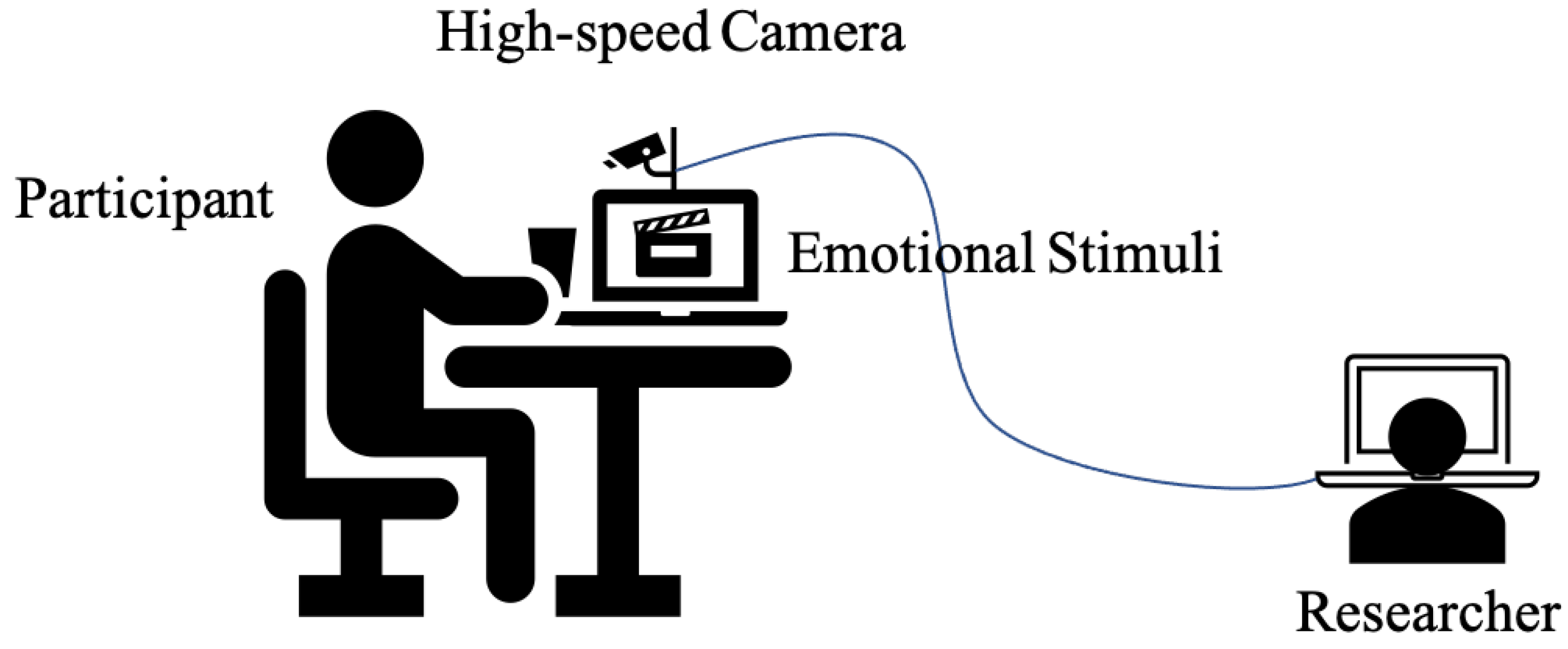
3.2.3. SAMM Data Acquisition Protocol
3.3. Publicly Available Current Micro-Expression Data Sets—A Recap
4. Outstanding Challenges and Future Work
4.1. Action Unit Detection
4.2. Data and Its Limitations
4.3. Real-Time Microexpression Recognition
4.4. Standardization of Performance Metrics
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MER | Microexpression Recognition |
| MEGC | Microexpression Grand Challenge |
| HOG | Histograms of Oriented Gradients |
| LBP-TOP | Local Binary Pattern-Three Orthogonal Planes |
| HOOF | Histograms of Oriented Optical Flow |
| FACS | Facial Action Coding System |
| LBP-SIP | Local Binary Pattern with Six Intersection Points |
| CBP | Centralized Binary Pattern |
| SMIC | Spontaneous Microexpression Corpus |
| CASME | Chinese Academy of Sciences Micro-Expressions |
| CASME II | Chinese Academy of Sciences Micro-Expression II |
| SAMM | Spontaneous Actions and Micromovements |
| CAS(ME) | Chinese Academy of Sciences Spontaneous Macro-Expressions and Micro-Expressions |
| LOSO | Leave One Subject Out |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Feature | Method | Database | Best Result |
|---|---|---|---|---|
| 2011 Pfister et al. [18] | Hand-crafted | LBP-TOP | Earlier version of SMIC | Acc: 71.4% |
| 2013 Li et al. [41] | Hand-crafted | LBP-TOP | SMIC | Acc: 52.11% (VIS) |
| 2014 Guo et al. [45] | Hand-crafted | LBP-TOP | SMIC | Acc: 65.83% |
| 2014 Wang et al. [26] | Hand-crafted | TICS | CASME | Acc: 61.85% |
| CASME II | Acc: 58.53% | |||
| 2014 Wang et al. [46] | Hand-crafted | DTSA | CASME | Acc: 46.90% |
| 2014 Yan et al. [42] | Hand-crafted | LBP-TOP | CASME II | Acc: 63.41% |
| 2015 Huang et al. [47] | Hand-crafted | STLBP-IP | SMIC | Acc: 57.93% |
| CASME II | Acc: 59.51% | |||
| 2015 Huang et al. [35] | Hand-crafted | STCLQP | SMIC | Acc: 64.02% |
| CASME | Acc: 57.31% | |||
| CASME II | Acc: 58.39% | |||
| 2015 Le et al. [48] | Hand-crafted | DMDSP+LBP-TOP | CASME II | F1-score: 0.52 |
| 2015 Le et al. [49] | Hand-crafted | LBP-TOP+STM | SMIC | Acc: 44.34% |
| CASME II | Acc: 43.78% | |||
| 2015 Liong et al. [50] | Hand-crafted | OSW-LBP-TOP | SMIC | Acc: 57.54% |
| CASME II | Acc: 66.40% | |||
| 2015 Lu et al. [51] | Hand-crafted | DTCM | SMIC | Acc: 82.86% |
| CASME | Acc: 64.95% | |||
| CASME II | Acc: 64.19% | |||
| 2015 Wang et al. [27] | Hand-crafted | TICS, CIELuv and CIELab | CASME | Acc: 61.86% |
| CASME II | Acc: 62.30% | |||
| 2015 Wang et al. [52] | Hand-crafted | LBP-SIP and LBP-MOP | CASME | Acc: 66.8% |
| 2016 Ben et al. [53] | Hand-crafted | MMPTR | CASME | Acc: 80.2% |
| 2016 Chen et al. [54] | Hand-crafted | 3DHOG | CASME II | Acc: 86.67% |
| 2016 Kim et al. [33] | Deep Learning | CNN+LSTM | CASME II | Acc: 60.98% |
| 2016 Liong et al. [55] | Hand-crafted | Optical Strain | SMIC | Acc: 52.44% |
| CASME II | Acc: 63.41% | |||
| 2016 Liu et al. [29] | Hand-crafted | MDMO | SMIC | Acc: 80% |
| CASME | Acc: 68.86% | |||
| CASME II | Acc: 67.37% | |||
| 2016 Oh et al. [56] | Hand-crafted | I2D | SMIC | F1-score: 0.44 |
| CASME II | F1-score: 0.41 | |||
| 2016 Talukder et al. [57] | Hand-crafted | LBP-TOP | SMIC | Acc: 62% (NIR) |
| 2016 Wang et al. [21] | Hand-crafted | STCCA | CASME | Acc: 41.20% |
| CASME II | Acc: 38.39% | |||
| 2016 Zheng et al. [58] | Hand-crafted | LBP-TOP, HOOF | CASME | Acc: 69.04% |
| CASME II | Acc: 63.25% | |||
| 2017 Happy and Routray [59] | Hand-crafted | FHOFO | SMIC | F1-score: 0.5243 |
| CASME | F1-score: 0.5489 | |||
| CASME II | F1-score: 0.5248 | |||
| 2017 Liong et al. [60] | Hand-crafted | Bi-WOOF | SMIC | Acc: 53.52% (VIS) |
| CASME II | F1-score: 0.59 | |||
| 2017 Peng et al. [34] | Deep Learning | DTSCNN | CASMEI/II | Acc: 66.67% |
| 2017 Wang et al. [61] | Hand-crafted | LBP-TOP | CASME II | Acc: 75.30% |
| 2017 Zhang et al. [62] | Hand-crafted | LBP-TOP | CASME II | Acc: 62.50% |
| 2017 Zong et al. [63] | Hand-crafted | LBP-TOP, TSRG | CASME II and SMIC | UAR: 0.6015 |
| 2018 Ben et al. [64] | Hand-crafted | HWP-TOP | CASME II | Acc: 86.8% |
| 2018 Hu et al. [65] | Hand-crafted | LGBP-TOP and CNN | SMIC | Acc: 65.1% |
| CASME II | Acc: 66.2% | |||
| 2018 Khor et al. [36] | Deep Learning | ELRCN | CASME II | F1-score: 0.5 |
| SAMM | F1-score: 0.409 | |||
| 2018 Li et al. [66] | Hand-crafted | HIGO | SMIC | Acc: 68.29 (HS) |
| CASME II | Acc: 67.21 | |||
| 2018 Liong et al. [67] | Hand-crafted | Bi-WOOF | SMIC | F1-score: 0.62 (HS) |
| CASME II | F1-score: 0.61 | |||
| 2018 Su et al. [68] | Hand-crafted | DS-OMMA | CASME II | F1-score: 0.7236 |
| CAS(ME) | F1-score: 0.7367 | |||
| 2018 Zhu et al. [69] | Hand-crafted | LBP-TOP and OF | CASME II | Acc: 53.3% |
| 2018 Zong et al. [70] | Hand-crafted | STLBP-IP | CASME II | Acc: 63.97% |
| 2019 Gan et al. [71] | Deep Learning | OFF-ApexNet | SMIC | Acc: 67.6% |
| CASME II | Acc: 88.28% | |||
| SAMM | Acc: 69.18% | |||
| 2019 Huang et al. [72] | Hand-crafted | DiSTLBP-RIP | SMIC | Acc: 63.41% |
| CASME | Acc: 64.33% | |||
| CASME II | Acc: 64.78% | |||
| 2019 Li et al. [73] | Deep Learning | 3D-FCNN | SMIC | Acc: 55.49% |
| CASME | Acc: 54.44% | |||
| CASME II | Acc: 59.11% | |||
| 2019 Liong et al. [74] | Deep Learning | STSTNet | SMIC, CASME II and SAMM | UF1: 0.7353 and UAR: 0.7605 |
| 2019 Liu et al. [75] | Deep Learning | EMR | SMIC, CASME II and SAMM | UF1: 0.7885 and UAR: 0.7824 |
| 2019 Peng et al. [76] | Hand-crafted | HIGO-TOP, ME-Booster | SMIC | Acc: 68.90% (HS) |
| CASME II | Acc: 70.85% | |||
| 2019 Peng et al. [77] | Deep Learning | Apex-Time Network | SMIC | UF1: 0.497 and UAR: 0.489 |
| CASME II | UF1: 0.523 and UAR: 0.501 | |||
| SAMM | UF1: 0.429 and UAR: 0.427 | |||
| 2019 Van Quang et al. [78] | Deep Learning | CapsuleNet | SMIC, CASME II and SAMM | UF1: 0.6520 and UAR: 0.6506 |
| 2019 Xia et al. [79] | Deep Learning | MER-RCNN | SMIC | Acc: 57.1% |
| CASME | Acc: 63.2% | |||
| CASME II | Acc: 65.8% | |||
| 2019 Zhao and Xu [80] | Hand-crafted | NMPs | SMIC | Acc: 69.37% |
| CASME II | Acc: 72.08% | |||
| 2019 Zhou et al. [81] | Deep Learning | Dual-Inception | SMIC, CASME II and SAMM | UF1: 0.7322 and UAR: 0.7278 |
| 2020 Wang et al. [82] | Deep Learning | ResNet, Micro-Attention | SMIC | Acc:49.4% |
| CASME II | Acc:65.9% | |||
| SAMM | Acc: 48.5% | |||
| 2020 Xie et al. [83] | Deep Learning | AU-GACN | CASME II | Acc:49.2% |
| SAMM | Acc: 48.9% |
References
- Ekman, P.; Oster, H. Facial Expressions of Emotion. Annu. Rev. Psychol. 1979, 30, 527–554. [Google Scholar] [CrossRef]
- Dimberg, U.; Thunberg, M.; Elmehed, K. Unconscious facial reactions to emotional facial expressions. Psychol. Sci. 2000, 11, 86–89. [Google Scholar] [CrossRef] [PubMed]
- Haggard, E.A.; Isaacs, K.S. Micromomentary facial expressions as indicators of ego mechanisms in psychotherapy. In Methods of Research in Psychotherapy; Springer: Berlin/Heidelberg, Germany, 1966. [Google Scholar]
- Ekman, P.; Friesen, W.V. Nonverbal Leakage and Clues to Deception. Psychiatry 1969, 32, 88–106. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P. Lie Catching and Microexpressions. In The Philosophy of Deception; Oxford University Press: New York, USA, 2011. [Google Scholar]
- Morris, M.W.; Keltner, D. How emotions work: The social functions of emotional expression in negotiations. Res. Organ. Behav. 2000, 22, 1–50. [Google Scholar] [CrossRef]
- Whitehill, J.; Serpell, Z.; Lin, Y.C.; Foster, A.; Movellan, J.R. The faces of engagement: Automatic recognition of student engagement from facial expressions. IEEE Trans. Affect. Comput. 2014, 5, 86–98. [Google Scholar] [CrossRef]
- Oh, Y.H.; See, J.; Le Ngo, A.C.; Phan, R.C.W.; Baskaran, V.M. A survey of automatic facial micro-expression analysis: Databases, methods, and challenges. Front. Psychol. 2018, 9, 1128. [Google Scholar] [CrossRef] [Green Version]
- Goh, K.M.; Ng, C.H.; Lim, L.L.; Sheikh, U.U. Micro-expression recognition: An updated review of current trends, challenges and solutions. Vis. Comput. 2020, 36, 445–468. [Google Scholar] [CrossRef]
- Rani, M.; Rathee, N. Microexpression Analysis: A Review. In Proceedings of the 3rd International Conference on Computing Informatics and Networks: ICCIN 2020, Delhi, India, 29–30 July 2020; Springer Nature: Berlin/Heidelberg, Germany, 2021; p. 125. [Google Scholar]
- Pan, H.; Xie, L.; Wang, Z.; Liu, B.; Yang, M.; Tao, J. Review of micro-expression spotting and recognition in video sequences. Virtual Real. Intell. Hardw. 2021, 3, 1–17. [Google Scholar] [CrossRef]
- Polikovsky, S.; Kameda, Y.; Ohta, Y. Facial Micro-Expressions Recognition Using High Speed Camera and 3D-Gradient Descriptor; IET Seminar Digest; IET: London, UK, 2009. [Google Scholar]
- Ekman, P.; Friesen, W.V. Facial Action Coding System: A Technique for the Measurement of Facial Movement; Consulting Psychologists Press: Palo Alto, CA, USA, 1971. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Fan, J.; Arandjelović, O. Employing domain specific discriminative information to address inherent limitations of the LBP descriptor in face recognition. In Proceedings of the International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Karsten, J.; Arandjelović, O. Automatic vertebrae localization from CT scans using volumetric descriptors. In Proceedings of the International Conference of the IEEE Engineering in Medicine and Biology Society, Jeju, Korea, 11–15 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 576–579. [Google Scholar]
- Zhao, G.; Pietikäinen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef] [Green Version]
- Pfister, T.; Li, X.; Zhao, G.; Pietikäinen, M. Recognising spontaneous facial micro-expressions. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Cootes, T.F.; Taylor, C.J.; Cooper, D.H.; Graham, J. Active shape models-their training and application. Comput. Vis. Image Underst. 1995, 61, 38–59. [Google Scholar] [CrossRef] [Green Version]
- Goshtasby, A. Image registration by local approximation methods. Image Vis. Comput. 1988, 6, 255–261. [Google Scholar] [CrossRef]
- Wang, S.J.; Yan, W.J.; Sun, T.; Zhao, G.; Fu, X. Sparse tensor canonical correlation analysis for micro-expression recognition. Neurocomputing 2016, 214, 218–232. [Google Scholar] [CrossRef]
- Wang, Y.; See, J.; Raphael, R.; Oh, Y.H. LBP with six intersection points: Reducing redundant information in LBP-TOP for micro-expression recognition. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015. [Google Scholar]
- Fu, X.; Wei, W. Centralized binary patterns embedded with image euclidean distance for facial expression recognition. In Proceedings of the 4th International Conference on Natural Computation, ICNC 2008, Jinan, China, 18–20 October 2008. [Google Scholar]
- Guo, Y.; Xue, C.; Wang, Y.; Yu, M. Micro-expression recognition based on CBP-TOP feature with ELM. Optik 2015, 126, 4446–4451. [Google Scholar] [CrossRef]
- Arandjelović, O. Colour invariants under a non-linear photometric camera model and their application to face recognition from video. Pattern Recognit. 2012, 45, 2499–2509. [Google Scholar] [CrossRef]
- Wang, S.J.; Yan, W.J.; Li, X.; Zhao, G.; Fu, X. Micro-expression recognition using dynamic textures on tensor independent color space. In Proceedings of the International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014. [Google Scholar]
- Wang, S.J.; Yan, W.J.; Li, X.; Zhao, G.; Zhou, C.G.; Fu, X.; Yang, M.; Tao, J. Micro-Expression Recognition Using Color Spaces. IEEE Trans. Image Process. 2015, 24, 6034–6047. [Google Scholar] [CrossRef]
- Zhang, L.; Arandjelović, O.; Dewar, S.; Astell, A.; Doherty, G.; Ellis, M. Quantification of advanced dementia patients’ engagement in therapeutic sessions: An automatic video based approach using computer vision and machine learning. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 5785–5788. [Google Scholar]
- Liu, Y.J.; Zhang, J.K.; Yan, W.J.; Wang, S.J.; Zhao, G.; Fu, X. A Main Directional Mean Optical Flow Feature for Spontaneous Micro-Expression Recognition. IEEE Trans. Affect. Comput. 2016, 7, 299–310. [Google Scholar] [CrossRef]
- Asthana, A.; Zafeiriou, S.; Cheng, S.; Pantic, M. Robust discriminative response map fitting with constrained local models. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Chaudhry, R.; Ravichandran, A.; Hager, G.; Vidal, R. Histograms of oriented optical flow and Binet-Cauchy kernels on nonlinear dynamical systems for the recognition of human actions. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2009, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Xu, F.; Zhang, J.; Wang, J.Z. Microexpression Identification and Categorization Using a Facial Dynamics Map. IEEE Trans. Affect. Comput. 2017, 8, 254–267. [Google Scholar] [CrossRef]
- Kim, D.H.; Baddar, W.J.; Ro, Y.M. Micro-expression recognition with expression-state constrained spatio-temporal feature representations. In Proceedings of the MM 2016—Proceedings of the 2016 ACM Multimedia Conference, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Peng, M.; Wang, C.; Chen, T.; Liu, G.; Fu, X. Dual temporal scale convolutional neural network for micro-expression recognition. Front. Psychol. 2017, 8, 1745. [Google Scholar] [CrossRef]
- Huang, X.; Zhao, G.; Hong, X.; Zheng, W.; Pietikäinen, M. Spontaneous facial micro-expression analysis using Spatiotemporal Completed Local Quantized Patterns. Neurocomputing 2015, 175, 564–578. [Google Scholar] [CrossRef]
- Khor, H.Q.; See, J.; Phan, R.C.W.; Lin, W. Enriched long-term recurrent convolutional network for facial micro-expression recognition. In Proceedings of the 13th IEEE International Conference on Automatic Face and Gesture Recognition, FG 2018, Xi’an, China, 15–19 May 2018. [Google Scholar]
- Donahue, J.; Hendricks, L.A.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Darrell, T.; Saenko, K. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Shreve, M.; Godavarthy, S.; Goldgof, D.; Sarkar, S. Macro- and micro-expression spotting in long videos using spatio-temporal strain. In Proceedings of the 2011 IEEE International Conference on Automatic Face and Gesture Recognition and Workshops, FG 2011, Santa Barbara, CA, USA, 21–25 March 2011. [Google Scholar]
- Warren, G.; Schertler, E.; Bull, P. Detecting deception from emotional and unemotional cues. J. Nonverbal Behav. 2009, 33, 59–69. [Google Scholar] [CrossRef]
- Yan, W.J.; Wu, Q.; Liu, Y.J.; Wang, S.J.; Fu, X. CASME database: A dataset of spontaneous micro-expressions collected from neutralized faces. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, FG 2013, Shanghai, China, 22–26 April 2013. [Google Scholar]
- Li, X.; Pfister, T.; Huang, X.; Zhao, G.; Pietikainen, M. A Spontaneous Micro-expression Database: Inducement, collection and baseline. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, FG 2013, Shanghai, China, 22–26 April 2013. [Google Scholar]
- Yan, W.J.; Li, X.; Wang, S.J.; Zhao, G.; Liu, Y.J.; Chen, Y.H.; Fu, X. CASME II: An improved spontaneous micro-expression database and the baseline evaluation. PLoS ONE 2014, 9, e86041. [Google Scholar] [CrossRef]
- Davison, A.K.; Lansley, C.; Costen, N.; Tan, K.; Yap, M.H. SAMM: A Spontaneous Micro-Facial Movement Dataset. IEEE Trans. Affect. Comput. 2018, 9, 116–129. [Google Scholar] [CrossRef] [Green Version]
- Qu, F.; Wang, S.J.; Yan, W.J.; Li, H.; Wu, S.; Fu, X. CAS(ME)2: A Database for Spontaneous Macro-Expression and Micro-Expression Spotting and Recognition. IEEE Trans. Affect. Comput. 2018, 9, 424–436. [Google Scholar] [CrossRef]
- Guo, Y.; Tian, Y.; Gao, X.; Zhang, X. Micro-expression recognition based on local binary patterns from three orthogonal planes and nearest neighbor method. In Proceedings of the International Joint Conference on Neural Networks, Beijing, China, 6–11 July 2014. [Google Scholar]
- Wang, S.J.; Chen, H.L.; Yan, W.J.; Chen, Y.H.; Fu, X. Face recognition and micro-expression recognition based on discriminant tensor subspace analysis plus extreme learning machine. Neural Process. Lett. 2014, 39, 25–43. [Google Scholar] [CrossRef]
- Huang, X.; Wang, S.J.; Zhao, G.; Piteikainen, M. Facial Micro-Expression Recognition Using Spatiotemporal Local Binary Pattern with Integral Projection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Le Ngo, A.C.; Liong, S.T.; See, J.; Phan, R.C.W. Are subtle expressions too sparse to recognize? In Proceedings of the International Conference on Digital Signal Processing, DSP, Singapore, 21–24 July 2015. [Google Scholar]
- Le Ngo, A.C.; Phan, R.C.W.; See, J. Spontaneous subtle expression recognition: Imbalanced databases and solutions. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015. [Google Scholar]
- Liong, S.T.; See, J.; Phan, R.C.; Le Ngo, A.C.; Oh, Y.H.; Wong, K.S. Subtle expression recognition using optical strain weighted features. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015. [Google Scholar]
- Lu, Z.; Luo, Z.; Zheng, H.; Chen, J.; Li, W. A Delaunay-based temporal coding model for micro-expression recognition. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015. [Google Scholar]
- Wang, Y.; See, J.; Phan, R.C.; Oh, Y.H. Efficient spatio-temporal local binary patterns for spontaneous facial micro-expression recognition. PLoS ONE 2015, 10, e0124674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ben, X.; Zhang, P.; Yan, R.; Yang, M.; Ge, G. Gait recognition and micro-expression recognition based on maximum margin projection with tensor representation. Neural Comput. Appl. 2016, 27, 2629–2646. [Google Scholar] [CrossRef]
- Chen, M.; Ma, H.T.; Li, J.; Wang, H. Emotion recognition using fixed length micro-expressions sequence and weighting method. In Proceedings of the 2016 IEEE International Conference on Real-Time Computing and Robotics, RCAR 2016, Angkor Wat, Cambodia, 6–10 June 2016. [Google Scholar]
- Liong, S.T.; See, J.; Phan, R.C.; Oh, Y.H.; Cat Le Ngo, A.; Wong, K.S.; Tan, S.W. Spontaneous subtle expression detection and recognition based on facial strain. Signal Process. Image Commun. 2016, 47, 170–182. [Google Scholar] [CrossRef] [Green Version]
- Oh, Y.H.; Le Ngo, A.C.; Phari, R.C.; See, J.; Ling, H.C. Intrinsic two-dimensional local structures for micro-expression recognition. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Shanghai, China, 20–25 March 2016. [Google Scholar]
- Talukder, B.M.; Chowdhury, B.; Howlader, T.; Rahman, S.M. Intelligent recognition of spontaneous expression using motion magnification of spatio-temporal data. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2016. [Google Scholar]
- Zheng, H.; Geng, X.; Yang, Z. A relaxed K-SVD algorithm for spontaneous micro-expression recognition. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2016. [Google Scholar]
- Happy, S.L.; Routray, A. Fuzzy Histogram of Optical Flow Orientations for Micro-expression Recognition. IEEE Trans. Affect. Comput. 2017, 10, 394–406. [Google Scholar] [CrossRef]
- Liong, S.T.; See, J.; Wong, K.; Phan, R.C.W. Automatic micro-expression recognition from long video using a single spotted apex. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2017. [Google Scholar]
- Wang, Y.; See, J.; Oh, Y.H.; Phan, R.C.; Rahulamathavan, Y.; Ling, H.C.; Tan, S.W.; Li, X. Effective recognition of facial micro-expressions with video motion magnification. Multimed. Tools Appl. 2017, 76, 21665–21690. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Feng, B.; Chen, Z.; Huang, X. Micro-expression recognition by aggregating local spatio-temporal patterns. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2017. [Google Scholar]
- Zong, Y.; Huang, X.; Zheng, W.; Cui, Z.; Zhao, G. Learning a target sample re-generator for cross-database micro-expression recognition. In Proceedings of the MM 2017—Proceedings of the 2017 ACM Multimedia Conference, Mountain View, CA, USA, 23–27 October 2017. [Google Scholar]
- Ben, X.; Jia, X.; Yan, R.; Zhang, X.; Meng, W. Learning effective binary descriptors for micro-expression recognition transferred by macro-information. Pattern Recognit. Lett. 2018, 107, 50–58. [Google Scholar] [CrossRef]
- Hu, C.; Jiang, D.; Zou, H.; Zuo, X.; Shu, Y. Multi-task Micro-expression Recognition Combining Deep and Handcrafted Features. In Proceedings of the International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 946–951. [Google Scholar]
- Li, X.; Hong, X.; Moilanen, A.; Huang, X.; Pfister, T.; Zhao, G.; Pietikainen, M. Towards reading hidden emotions: A comparative study of spontaneous micro-expression spotting and recognition methods. IEEE Trans. Affect. Comput. 2018, 9, 563–577. [Google Scholar] [CrossRef] [Green Version]
- Liong, S.T.; See, J.; Wong, K.S.; Phan, R.C. Less is more: Micro-expression recognition from video using apex frame. Signal Process. Image Commun. 2018, 62, 82–92. [Google Scholar] [CrossRef] [Green Version]
- Su, W.; Wang, Y.; Su, F.; Zhao, Z. Micro-expression recognition based on the spatio-temporal feature. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo Workshops, ICMEW 2018, San Diego, CA, USA, 23–27 July 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018. [Google Scholar]
- Zhu, X.; Ben, X.; Liu, S.; Yan, R.; Meng, W. Coupled source domain targetized with updating tag vectors for micro-expression recognition. Multimed. Tools Appl. 2018, 77, 3105–3124. [Google Scholar] [CrossRef]
- Zong, Y.; Huang, X.; Zheng, W.; Cui, Z.; Zhao, G. Learning from hierarchical spatiotemporal descriptors for micro-expression recognition. IEEE Trans. Multimed. 2018, 20, 3160–3172. [Google Scholar] [CrossRef] [Green Version]
- Gan, Y.S.; Liong, S.T.; Yau, W.C.; Huang, Y.C.; Tan, L.K. OFF-ApexNet on micro-expression recognition system. Signal Process. Image Commun. 2019, 74, 129–139. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Wang, S.J.; Liu, X.; Zhao, G.; Feng, X.; Pietikainen, M. Discriminative Spatiotemporal Local Binary Pattern with Revisited Integral Projection for Spontaneous Facial Micro-Expression Recognition. IEEE Trans. Affect. Comput. 2019, 10, 32–47. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Wang, Y.; See, J.; Liu, W. Micro-expression recognition based on 3D flow convolutional neural network. Pattern Anal. Appl. 2019, 22, 1331–1339. [Google Scholar] [CrossRef]
- Liong, S.T.; Gan, Y.S.; See, J.; Khor, H.Q.; Huang, Y.C. Shallow triple stream three-dimensional CNN (STSTNet) for micro-expression recognition. In Proceedings of the 14th IEEE International Conference on Automatic Face and Gesture Recognition, FG 2019, Lille, France, 14–18 May 2019. [Google Scholar]
- Liu, Y.; Du, H.; Zheng, L.; Gedeon, T. A neural micro-expression recognizer. In Proceedings of the 14th IEEE International Conference on Automatic Face and Gesture Recognition, FG 2019, Lille, France, 14–18 May 2019. [Google Scholar]
- Peng, W.; Hong, X.; Xu, Y.; Zhao, G. A boost in revealing subtle facial expressions: A consolidated Eulerian framework. In Proceedings of the 14th IEEE International Conference on Automatic Face and Gesture Recognition, FG 2019, Lille, France, 14–18 May 2019. [Google Scholar]
- Peng, M.; Shi, Y.; Wang, C.; Zhou, X.; Bi, T.; Chen, T. A novel apex-time network for cross-dataset micro-expression recognition. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), Cambridge, UK, 3–6 September 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Van Quang, N.; Chun, J.; Tokuyama, T. CapsuleNet for micro-expression recognition. In Proceedings of the 14th IEEE International Conference on Automatic Face and Gesture Recognition, FG 2019, Lille, France, 14–18 May 2019. [Google Scholar]
- Xia, Z.; Feng, X.; Hong, X.; Zhao, G. Spontaneous facial micro-expression recognition via deep convolutional network. In Proceedings of the 2018 8th International Conference on Image Processing Theory, Tools and Applications, IPTA 2018, Xi’an, China, 7–10 November 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019. [Google Scholar]
- Zhao, Y.; Xu, J. An improved micro-expression recognition method based on necessary morphological patches. Symmetry 2019, 11, 497. [Google Scholar] [CrossRef] [Green Version]
- Zhou, L.; Mao, Q.; Xue, L. Dual-inception network for cross-database micro-expression recognition. In Proceedings of the 14th IEEE International Conference on Automatic Face and Gesture Recognition, FG 2019, Lille, France, 14–18 May 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019. [Google Scholar]
- Wang, C.; Peng, M.; Bi, T.; Chen, T. Micro-attention for micro-expression recognition. Neurocomputing 2020, 410, 354–362. [Google Scholar] [CrossRef]
- Xie, H.X.; Lo, L.; Shuai, H.H.; Cheng, W.H. AU-assisted Graph Attention Convolutional Network for Micro-Expression Recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]













| Database | CASME [40] | SMIC [41] | CASME II [42] | SAMM [43] | CAS(ME)2 [44] | ||
|---|---|---|---|---|---|---|---|
| HS | VIS | NIR | |||||
| Microexpressions | 195 | 164 | 71 | 71 | 247 | 159 | 57 |
| Participants | 35 | 20 | 10 | 10 | 35 | 32 | 22 |
| FPS | 60 | 100 | 25 | 25 | 200 | 200 | 30 |
| Ethnicities | 1 | 3 | 1 | 13 | 1 | ||
| Average Age | 22.03 | N/A | 22.03 | 33.24 | 22.59 | ||
| Resolution | 640 × 480 1280 × 720 | 640 × 480 | 640 × 480 | 2040 × 1088 | 640 × 480 | ||
| Facial Resolution | 150 × 190 | 190 × 230 | 280 × 340 | 400 × 400 | N/A | ||
| Emotion Classes | 8 Happiness Sadness Disgust Surprise Contempt Fear Repression Tense | 3 PositiveNegativeSurprise | 5 Happiness Disgust Surprise Repression Others | 7 Contempt Disgust Fear Anger Sadness Happiness Surprise | 4 Positive Negative Surprise Others | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Arandjelović, O. Review of Automatic Microexpression Recognition in the Past Decade. Mach. Learn. Knowl. Extr. 2021, 3, 414-434. https://doi.org/10.3390/make3020021
Zhang L, Arandjelović O. Review of Automatic Microexpression Recognition in the Past Decade. Machine Learning and Knowledge Extraction. 2021; 3(2):414-434. https://doi.org/10.3390/make3020021
Chicago/Turabian StyleZhang, Liangfei, and Ognjen Arandjelović. 2021. "Review of Automatic Microexpression Recognition in the Past Decade" Machine Learning and Knowledge Extraction 3, no. 2: 414-434. https://doi.org/10.3390/make3020021
APA StyleZhang, L., & Arandjelović, O. (2021). Review of Automatic Microexpression Recognition in the Past Decade. Machine Learning and Knowledge Extraction, 3(2), 414-434. https://doi.org/10.3390/make3020021