
Machine Learning Based Restaurant Sales Forecasting




Abstract
:
1. Introduction
2. Literature Review
3. Materials and Methods
3.1. Data Acquisition
3.2. Additional Stationary Datasets
3.3. Feature Definitions
3.4. Considered Models
3.5. Metrics
3.6. Baselines
3.7. Feature Selection
3.8. Model Train/Test Set
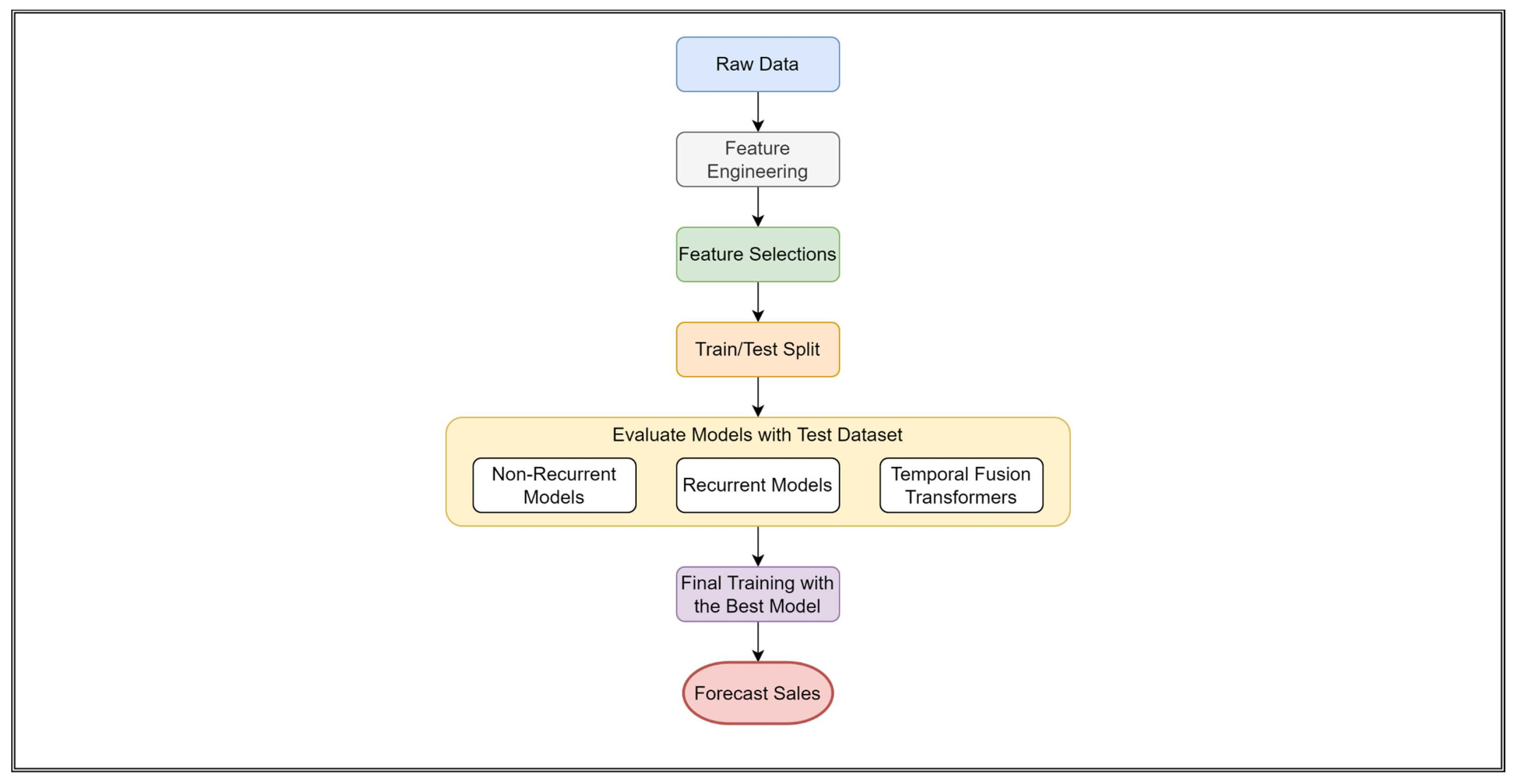
3.9. Complete Model Learning Methodology
4. Results
4.1. Baseline Results
4.2. Feature Test Results
4.3. One-Day Forecasting Results
4.4. One-Week Forecasting Results
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Green, Y.N.J. An Exploratory Investigation of the Sales Forecasting Process in the Casual Themeand Family Dining Segments of Commercial Restaurant Corporations; Virginia Polytechnic Institute and State University: Blacksburg, VA, USA, 2001. [Google Scholar]
- Cranage, D.A.; Andrew, W.P. A comparison of time series and econometric models for forecasting restaurant sales. Int. J. Hosp. Manag. 1992, 11, 129–142. [Google Scholar] [CrossRef]
- Lasek, A.; Cercone, N.; Saunders, J. Restaurant Sales and Customer Demand Forecasting: Literature Survey and Categorization of Methods, in Smart City 360°; Springer International Publishing: Cham, Switzerland, 2016; pp. 479–491. [Google Scholar]
- Green, Y.N.J.; Weaver, P.A. Approaches, techniques, and information technology systems in the restaurants and foodservice industry: A qualitative study in sales forecasting. Int. J. Hosp. Tour. Adm. 2008, 9, 164–191. [Google Scholar] [CrossRef]
- Lim, B.; Arik, S.O.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting. arXiv 2019, arXiv:1912.09363. [Google Scholar] [CrossRef]
- Borovykh, A.; Bohte, S.; Oosterlee, C.W. Conditional Time Series Forecasting with Convolutional Neural Networks. arXiv 2018, arXiv:1703.04691. [Google Scholar]
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. 2021, 379, 20200209. [Google Scholar] [CrossRef]
- Bandara, K.; Shi, P.; Bergmeir, C.; Hewamalage, H.; Tran, Q.; Seaman, B. Sales Demand Forecast in E-commerce Using a Long Short-Term Memory Neural Network Methodology. In International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 462–474. [Google Scholar]
- Helmini, S.; Jihan, N.; Jayasinghe, M.; Perera, S. Sales forecasting using multivariate long short term memorynetwork models. PeerJ PrePrints 2019, 7, e27712v1. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, 3. [Google Scholar] [CrossRef] [Green Version]
- Stergiou, K.; Karakasidis, T.E. Application of deep learning and chaos theory for load forecastingin Greece. Neural Comput. Appl. 2021, 33, 16713–16731. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Physia D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef] [Green Version]
- Graves, A. Generating Sequences with Recurrent Neural Networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Holmberg, M.; Halldén, P. Machine Learning for Restauraunt Sales Forecast; Department of Information Technology, UPPSALA University: Uppsala, Sweden, 2018; p. 80. [Google Scholar]
- Tanizaki, T.; Hoshino, T.; Shimmura, T.; Takenaka, T. Demand forecasting in restaurants usingmachine learning and statistical analysis. Procedia CIRP 2019, 79, 679–683. [Google Scholar] [CrossRef]
- Rao, G.S.; Shastry, K.A.; Sathyashree, S.R.; Sahu, S. Machine Learning based Restaurant Revenue Prediction. Lect. Notes Data Eng. Commun. Technol. 2021, 53, 363–371. [Google Scholar]
- Sakib, S.N. Restaurant Sales Prediction Using Machine Learning. 2021. Available online: https://engrxiv.org/preprint/view/2073 (accessed on 10 January 2022).
- Liu, X.; Ichise, R. Food Sales Prediction with Meteorological Data-A Case Study of a Japanese Chain Supermarket. Data Min. Big Data 2017, 10387, 93–104. [Google Scholar]
- Schmidt, A. Machine Learning based Restaurant Sales Forecasting. In Computer Science; University of New Orleans: New Orleans, LA, USA, 2021. [Google Scholar]
- Bianchi, F.M.; Livi, L.; Mikalsen, K.O.; Kampffmeyer, M.; Jenssen, R. Learning representations of multivariate time series with missing data. Pattern Recognit. 2019, 96, 106973. [Google Scholar] [CrossRef]
- Allison, P.D. Missing Data; Sage Publications: Newcastle upon Tyne, UK, 2001. [Google Scholar]
- Wu, Z.; Huang, N.E.; Long, S.R.; Peng, C.-K. On the trend, detrending, and variability of nonlinearand nonstationary time series. Proc. Natl. Acad. Sci. USA 2007, 104, 14889–14894. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2018. [Google Scholar]
- Marquardt, D.W.; Snee, R.D. Ridge regression in practice. Am. Stat. 1975, 29, 3–20. [Google Scholar]
- Brown, P.J.; Zidek, J.V. Adaptive Multivariant Ridge Regression. Ann. Stat. 1980, 8, 64–74. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Bottou, L. Large-Scale Machine Learning with Stochastic Gradient Descent. In COMPSTAT’2010; Physica-Verlag HD: Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Biased Estimation for Nonorthogonal Problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. 2010, 33, 1. [Google Scholar] [CrossRef] [Green Version]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- MacKay, D.J. Bayesian Interpolation. Neural Comput. 1991, 4, 415–447. [Google Scholar] [CrossRef]
- Raftery, A.E.; Madigan, D.; Hoeting, J.A. Bayesian Model Averaging for Linear Regressions Models. J. Am. Stat. Assoc. 1997, 92, 179–191. [Google Scholar] [CrossRef]
- Hofmann, M. Support vector machines-kernels and the kernel trick. In Notes; University of Bamberg: Bamberg, Germany, 2006; Volume 26, pp. 1–16. [Google Scholar]
- Welling, M. Kernel ridge Regression. In Max Welling’s Class Lecture Notes in Machine Learning; University of Toronto: Toronto, Canada, 2013. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Loh, W.-Y. Classification and Regression Trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: San Francisco, CA, USA, 2016. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Schölkopf, B.S.; Smola, A.J.; Williamson, R.C.; Bartlett, P.L. New Support Vector Algorithms. Neural Comput. 2000, 12, 1207–1245. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Ho, C.-H.; Lin, C.-J. Large-scale Linear Support Vector Regression. J. Mach. Learn. Res. 2012, 13, 3323–3348. [Google Scholar]
- Cover, T.; Hart, P. Nearest Neighbor Pattern Classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Goldberger, J.; Roweis, S.; Hinton, G.; Salakhutdinov, R. Neighbourhood Components Analysis. Adv. Neural Inf. Process. Syst. 2004, 17, 513–520. [Google Scholar]
- Hu, L.-Y.; Huang, M.-W.; Ke, S.-W.; Tsai, C.-F. The distance function effect on k-nearest neighbor classification for medical datasets. SpringerPlus 2016, 5, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rasmussen, C.E. Gaussian Processes for Machine Learning; Summer school on machine learning; Springer: Heidelberg/Berlin, Germany, 2003. [Google Scholar]
- Duvenaud, D. Automatic Model Construction with Gaussian Processes; University of Cambridge: Cambridge, UK, 2014. [Google Scholar]
- Breiman, L. Stacked Regressions. Mach. Learn. 1996, 24, 49–64. [Google Scholar] [CrossRef] [Green Version]
- Iqbal, S.; Hoque, M.T. PBRpredict-Suite: A Suite of Models to Predict Peptide Recognition Domain Residues from Protein Sequence. Bioinformatics 2018, 34, 3289–3299. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gattani, S.; Mishra, A.; Hoque, M.T. StackCBPred: A Stacking based Prediction of Protein-Carbohydrate Binding Sites from Sequence. Carbohydr. Res. 2019, 486, 107857. [Google Scholar] [CrossRef] [PubMed]
- Mishra, A.; Pokhrel, P.; Hoque, T. StackDPPred: A Stacking based Prediction of DNA-binding Protein from Sequence. Bioinformatics 2019, 35, 433–441. [Google Scholar] [CrossRef] [PubMed]
- Wolpert, D.H. Stacked Generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive Logistic Regression: A Statistical View of Boosting. Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient BoostingDecision Tree. Adv. Neural Inf. Processing Syst. 2017, 30, 3146–3154. [Google Scholar]
- Anderson, J.A. An Introduction to Neural Networks; MIT Press: Cambridge, MA, USA, 1993. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Hecht-Nielsen, R. Theory of the Backpropagation Neural Network in Neural Networks for Perception; Academic Press: Cambridge, MA, USA, 1992; pp. 65–93. [Google Scholar]
- Medsker, L.; Jain, L.C. Recurrent Neural Networks: Design and Applications; CRC Press LLC: Boca Raton, FL, USA, 1999. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 26 May 2013; pp. 1310–1318. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–DecoderApproaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation ofGated Recurrent Neural Networkson Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Borchani, H.; Varando, G.; Bielza, C.; Larranaga, P. A survey on multi-output regression. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2015, 5, 216–233. [Google Scholar] [CrossRef] [Green Version]
- Cerqueira, V.; Torgo, L.; Mozetič, I. Evaluating time series forecasting models: An empirical study on performance estimation methods. Mach. Learn. 2020, 109, 1997–2028. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoderfor Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Description |
|---|---|
| Year | The year ranging from 2016–2019. |
| Day | The day of the month. |
| Month | Each month of the year. One-hot encoding applied. |
| Weekday | Each day of a seven-day week. One-hot encoding applied. |
| Holiday | 29 different holidays included. Full list can be seen in Supplementary Materials Table S1. One-hot encoding applied. |
| Carnival Season | Mardi Gras holiday season. Lasts from January 6th to Mardi Gras Day. |
| Lent Fasting | Starts Ash Wednesday and end 40 days later. Fasting stops on Sundays and St. Patrick’s Day. |
| Ramadan | One month of fasting. Variable start dates. |
| Christmas Season | 1 December to 25 December. |
| Previous 14 Days of Sales | Each sales or differenced value from the previous 14 days are included as individual features. 14 is chosen as the lookback time, but any multiple of seven would be appropriate. |
| Weekday Average | The weekday average is found as where t is the current time-period and n is the number of preceding weeks. D refers to the set of individual weekdays (ex. All Mondays or all Tuesdays). |
| Daily Average | The day average is found as where t is the current time-period and n is the total number of preceding days. |
| Daily Maximum | |
| Daily Minimum | |
| Predicted Weekday Busyness | where the weekday influences the predicted busyness. |
| Predicted Daily Busyness | where the total average influences the predicted busyness. |
| Daily Differenced Average | See Daily Average, but the daily differenced sales are used. Not included when predicting actual sales. |
| Weekly Differenced Average | See Weekday Average, but the daily differenced sales are used. Not included when predicting actual sales. |
| Minimum Daily Difference | See Daily Minimum, but the daily differenced sales are used. Not included when predicting actual sales. |
| Minimum Daily Difference | See Daily Maximum, but the daily differenced sales are used. Not included when predicting actual sales. |
| Model | Family | Resources |
|---|---|---|
| Linear Regression | Linear Models | [24,25,26] |
| SGD Regression | Linear Models | [27] |
| Ridge Regression | Linear Models | [24,25,28,29] |
| Lasso Regression | Linear Models | [26,29] |
| Elastic-Net Regression | Linear Models | [29,30] |
| Bayesian Ridge Regression | Linear Models | [28,31,32] |
| Kernel Ridge Regression | Linear Models | [33,34] |
| Decision Tree Regression | Decision Tree Models | [35,36,37] |
| Support Vector Regression | Support Vector Models | [33,38,39,40] |
| Nu Support Vector Regression | Support Vector Models | [39,40] |
| Linear SVR | Support Vector Models | [41] |
| K-Neighbors Regression | Clustering Models | [42,43,44] |
| Gaussian Process Regression | Gaussian Models | [45,46] |
| Stacking Regression | Ensemble Models | [47,48,49,50,51] |
| Supplementary Materials Table S2 | ||
| Voting Regression | Ensemble Models | [47,52] |
| Supplementary Materials Table S3 | ||
| Extra Trees Regression | Decision Tree/Ensemble Models | [53] |
| XGB Regression | Decision Tree/Ensemble Models | [37,53] |
| LGBM Regression | Decision Tree/Ensemble Models | [37,54] |
| Multi-Layer Perceptron | Neural Networks | [6,54,55,56,57] |
| Recurrent Neural Network | Recurrent Neural Networks | [6,13,58,59] |
| Supplementary Materials Figure S1 | ||
| Long-Short Term Memory | Recurrent Neural Networks | [9,12,13,58,60] |
| Supplementary Materials Figure S2 | ||
| Gated Recurrent Unit | Recurrent Neural Networks | [12,61,62] |
| Supplementary Materials Figures S3 and S4 | ||
| Temporal Fusion Transformer | Recurrent Neural Networks | [5,7,12] |
| Supplementary Materials Figure S5 and Table S4 | ||
| Multioutput Regression | Wrapper Model | [5,63] |
| Model | Type | MAE | sMAPE | gMAE | Dataset |
|---|---|---|---|---|---|
| Stacking | NR | 220 | 0.195 | 142 | Actual |
| TFT Less Features | R | 220 | 0.196 | 133 | Actual |
| Bayesian Ridge | NR | 221 | 0.195 | 144 | Actual |
| Linear | NR | 221 | 0.195 | 144 | Actual |
| Ridge | NR | 221 | 0.195 | 144 | Actual |
| SGD | NR | 221 | 0.195 | 144 | Actual |
| LSTM | R | 222 | 0.196 | 131 | Actual |
| Lasso | NR | 226 | 0.201 | 147 | Actual |
| GRU | R | 227 | 0.2 | 144 | Actual |
| Extra Trees | NR | 231 | 0.204 | 128 | Actual |
| Use-Last-Week-Enhanced | NR | 239 | 0.215 | 150 | Actual |
| TFT All Features | R | 244 | 0.215 | 159 | Actual |
| Kernel Ridge | NR | 214 | 0.196 | 126 | Daily |
| Ridge | NR | 216 | 0.195 | 144 | Daily |
| Bayesian Ridge | NR | 217 | 0.196 | 146 | Daily |
| Linear | NR | 219 | 0.198 | 137 | Daily |
| Lasso | NR | 223 | 0.201 | 141 | Daily |
| Stacking | NR | 223 | 0.2 | 148 | Daily |
| XGB | NR | 241 | 0.214 | 152 | Daily |
| Voting | NR | 238 | 0.213 | 144 | Weekly |
| Stacking | NR | 242 | 0.215 | 139 | Weekly |
| Bayesian Ridge | NR | 245 | 0.218 | 142 | Weekly |
| Kernel Ridge | NR | 245 | 0.219 | 144 | Weekly |
| Linear Regression | NR | 245 | 0.217 | 140 | Weekly |
| Lasso | NR | 246 | 0.218 | 141 | Weekly |
| Model | Type | MAE | sMAPE | gMAE | Dataset | Weekday | Mean | Std Dev |
|---|---|---|---|---|---|---|---|---|
| TFT Less Features | R | 215 | 0.202 | 123 | Actual | Friday | 222 | 3.363 |
| GRU | R | 218 | 0.195 | 116 | Actual | Sunday | 233 | 13.477 |
| LSTM | R | 222 | 0.197 | 134 | Actual | Thursday | 228 | 5.339 |
| Use-Last-Week-Enhanced | NR | 230 | 0.203 | 139 | Actual | Tuesday | 232 | 2.437 |
| GRU+ | R | 233 | 0.204 | 136 | Actual | Wednesday | 246 | 14.612 |
| ExtraTrees | NR | 235 | 0.206 | 145 | Actual | Wednesday | 240 | 4.085 |
| Stacking | NR | 237 | 0.208 | 146 | Actual | Tuesday | 243 | 4.634 |
| Voting | NR | 237 | 0.209 | 140 | Actual | Friday | 246 | 8.256 |
| Kernel Ridge | NR | 239 | 0.213 | 143 | Actual | Wednesday | 244 | 4.229 |
| SGD | NR | 240 | 0.214 | 140 | Actual | Tuesday | 249 | 7.712 |
| Bayesian Ridge | NR | 242 | 0.216 | 145 | Actual | Wednesday | 248 | 3.408 |
| Lasso | NR | 243 | 0.218 | 147 | Actual | Thursday | 248 | 2.979 |
| Transformer | R | 267 | 0.239 | 153 | Actual | Wednesday | 268 | 1.131 |
| Lasso | NR | 280 | 1.016 | 162 | Daily | Sunday | 287 | 6.53 |
| Lasso | NR | 253 | 1.284 | 137 | Weekly | Sunday | 256 | 3.156 |
| Ridge | NR | 256 | 1.274 | 144 | Weekly | Sunday | 261 | 3.403 |
| Kernel Ridge | NR | 257 | 1.274 | 146 | Weekly | Sunday | 262 | 3.436 |
| Elastic | NR | 257 | 1.327 | 153 | Weekly | Sunday | 259 | 1.495 |
| SGD | NR | 257 | 1.28 | 148 | Weekly | Monday | 261 | 2.978 |
| LinSVR | NR | 258 | 1.405 | 149 | Weekly | Sunday | 260 | 1.939 |
| Bayesian Ridge | NR | 259 | 1.304 | 151 | Weekly | Sunday | 260 | 1.21 |
| Stacking | NR | 260 | 1.281 | 151 | Weekly | Monday | 264 | 2.694 |
| Transformer | R | 263 | 1.371 | 147 | Weekly | Tuesday | 278 | 9.849 |
| RNN | R | 273 | 1.722 | 162 | Weekly | Sunday | 278 | 2.95 |
| GRU | R | 273 | 1.674 | 154 | Weekly | Sunday | 279 | 4.318 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schmidt, A.; Kabir, M.W.U.; Hoque, M.T. Machine Learning Based Restaurant Sales Forecasting. Mach. Learn. Knowl. Extr. 2022, 4, 105-130. https://doi.org/10.3390/make4010006
Schmidt A, Kabir MWU, Hoque MT. Machine Learning Based Restaurant Sales Forecasting. Machine Learning and Knowledge Extraction. 2022; 4(1):105-130. https://doi.org/10.3390/make4010006
Chicago/Turabian StyleSchmidt, Austin, Md Wasi Ul Kabir, and Md Tamjidul Hoque. 2022. "Machine Learning Based Restaurant Sales Forecasting" Machine Learning and Knowledge Extraction 4, no. 1: 105-130. https://doi.org/10.3390/make4010006
APA StyleSchmidt, A., Kabir, M. W. U., & Hoque, M. T. (2022). Machine Learning Based Restaurant Sales Forecasting. Machine Learning and Knowledge Extraction, 4(1), 105-130. https://doi.org/10.3390/make4010006