
Hierarchical Reinforcement Learning: A Survey and Open Research Challenges


Abstract
:1. Introduction
2. Background
2.1. Markov Decision Processes
- defines the set of possible states the agent can be in, also called the state-space,
- contains the set of actions the agent can execute, also called the action-space,
- is the transition function. This function determines what the outcome-state of an action in a state will be. This function is also often called the environment-model.
- is the reward-function, an agent can receive reward when visiting certain states.
Semi-Markov Decision Processes
2.2. Reinforcement Learning
2.2.1. Value-Based Methods
2.2.2. Policy Gradient Methods
2.3. Deep Reinforcement Learning
3. Hierarchical Reinforcement Learning
3.1. Mechanisms
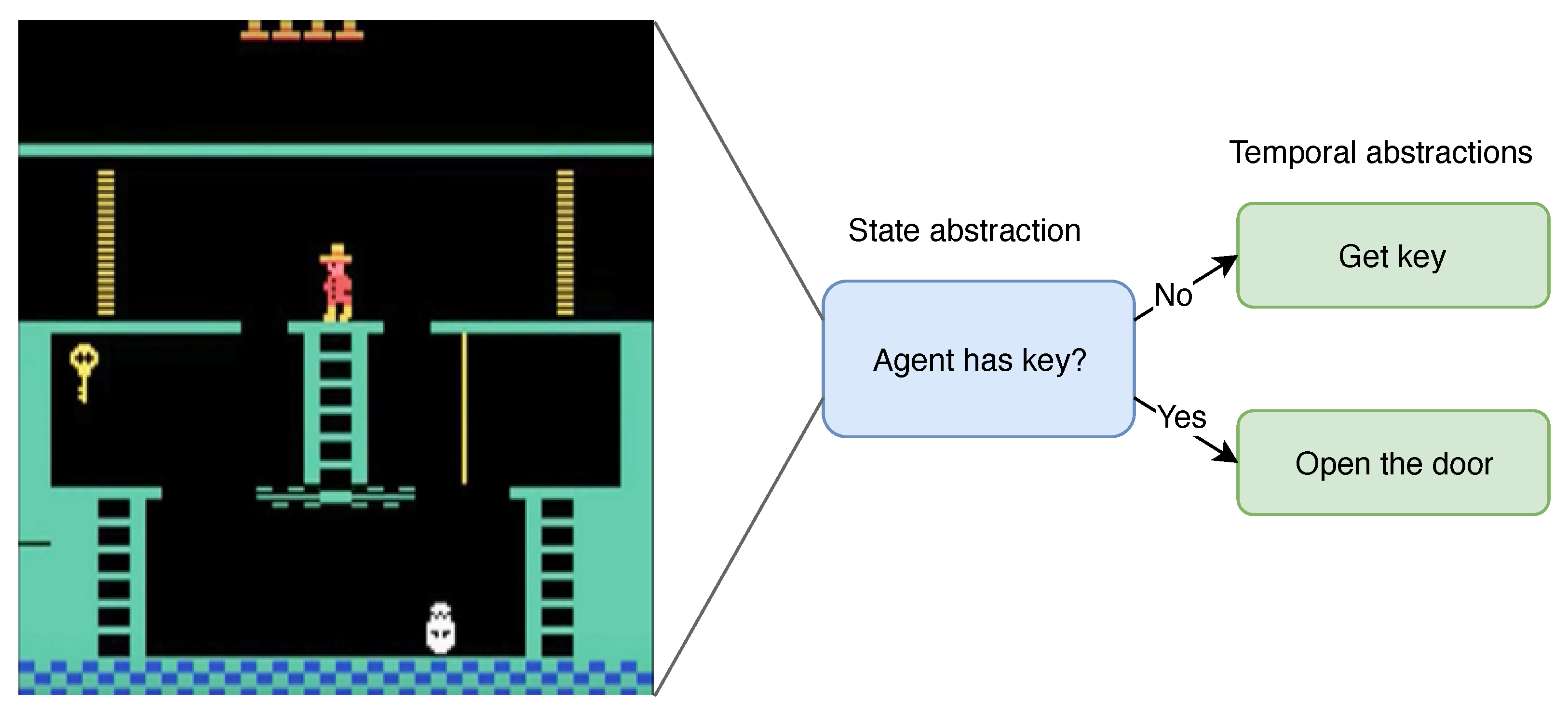
3.1.1. Temporal Abstractions
3.1.2. State Abstractions
3.2. HRL Advantages
3.2.1. Credit Assignment
3.2.2. Exploration
3.2.3. Continual Learning
3.3. HRL Challenges
3.3.1. Automatic Discovery of Abstractions
3.3.2. Development of Abstractions
3.3.3. Decomposing Example Trajectories
3.3.4. Composition
- Bottom-up training: the sub-behaviors are discovered and developed first. Once they have been sufficiently developed, they are frozen, and a composition-policy is learned by sampling different sub-behaviors. This is the most straightforward way, as the higher level does not need to take into account that the outcome of the selected temporal extended actions might have changed. Sub-behaviors learned using a bottom-up approach, can often also be transferred to solve similar problems. However, in the first phase, time might be spent learning sub-behaviors which the higher-level actually does not need.
- Top-down training: the higher-level first selects a subgoal it deems interesting in order to reach the overall goal. Once selected, the lower-level is trained to reach the proposed subgoal. This approach is often more efficient, compared to training bottom-up in solving a single control problem. However, it needs to take non-stationary sub-behaviors into account. It is also often not straight-forward to transfer sub-behaviors to different problems.
4. Problem-Specific Models
4.1. Feudal
4.2. Hierarchies of Abstract Machines
4.3. MAXQ
- Max-nodes define different sub-behaviors in the decomposition, and are context-independent
- Q-nodes are used to represent the different actions that are available for each sub-behavior, and are specific to the task at hand.
5. Options
5.1. Framework
- is the initiation set, containing all states in which the option can be initiated.
- is the intra-option policy, determining the action-selection of the option based on the current state (and optionally the set of states, since the option was invoked).
- makes up the termination condition, which determines when the option will halt its execution.
5.1.1. Initiation Set
5.1.2. Termination Condition
5.1.3. Intra-Option Policy
5.1.4. Policy-over-Options
- Hierarchical-optimal: a policy that achieves the maximum highest cumulative reward on the entire task.
- Recursive-optimal [172]: the different sub-behaviors of the agent are optimal individually.
5.2. Option Subgoal Discovery
5.2.1. Landmark States
5.2.2. Reinforcement Learning Signal
5.2.3. Bottleneck States
5.2.4. Access States
5.2.5. Graph Partitioning
5.2.6. State Clustering
5.2.7. Skill Chaining
5.3. Motion Templates
5.4. Macro-Actions
5.5. Using Options in High-Dimensional State-Spaces
5.6. Option Discovery as Optimization Problem
5.7. Options as a Tool for Meta-Learning
6. Goal-Conditional
6.1. General Value Functions
6.2. Information Hiding
6.3. Unsupervised Learning in HRL
6.4. End-to-End Algorithms
7. Benchmarks
7.1. Low-Dimensional State-Space Environments
7.2. High-Dimensional State-Space Environments
7.2.1. Discrete Action Spaces
7.2.2. Continuous Control
8. Comparative Analysis
8.1. Frameworks Summary
8.2. Algorithms
- Training method: how is the algorithm trained? Can it be trained end-to-end, or is a staged pre-training phase required?
- Required priors: how much additional domain knowledge is required, external to the gathered experience in the environment?
- Interpretable elements: what parts of the resulting policies can be interpreted by humans?
- Transferrable policy: are the abstractions proposed by the algorithm transferable to other problems, or are they task-specific?
- Improvement: what is the main improvement of the algorithm over the previous state of the art?
8.2.1. Training Method
8.2.2. Required Priors
8.2.3. Interpretable Elements
8.2.4. Transferrable Policy
9. Open Research Challenges
9.1. Top-Down Hierarchical Learning
9.2. Subgoal Representation
9.3. Lifelong Learning
9.4. HRL for Exploration
9.5. Increasing Depth
9.6. Interpretable RL
9.7. Benchmark
9.8. Alternative Frameworks
10. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An introduction to deep reinforcement learning. Found. Trends® Mach. Learn. 2018, 11, 219–354. [Google Scholar] [CrossRef] [Green Version]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef] [Green Version]
- Li, Y. Deep Reinforcement Learning: An Overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Justesen, N.; Bontrager, P.; Togelius, J.; Risi, S. Deep learning for video game playing. IEEE Trans. Games 2019, 12, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Luketina, J.; Nardelli, N.; Farquhar, G.; Foerster, J.; Andreas, J.; Grefenstette, E.; Whiteson, S.; Rocktäschel, T. A Survey of Reinforcement Learning Informed by Natural Language. arXiv 2019, arXiv:1906.03926. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Hessel, M.; Modayil, J.; Van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Badia, A.P.; Piot, B.; Kapturowski, S.; Sprechmann, P.; Vitvitskyi, A.; Guo, D.; Blundell, C. Agent57: Outperforming the Atari Human Benchmark. arXiv 2020, arXiv:2003.13350. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- OpenAI. Dota 2 with Large Scale Deep Reinforcement Learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- OpenAI. OpenAI Five. 2018. Available online: https://blog.openai.com/openai-five/ (accessed on 9 December 2021).
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster Level in StarCraft II Using Multi-Agent Reinforcement Learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]
- Jaderberg, M.; Czarnecki, W.M.; Dunning, I.; Marris, L.; Lever, G.; Castañeda, A.G.; Beattie, C.; Rabinowitz, N.C.; Morcos, A.S.; Ruderman, A.; et al. Human-level performance in 3D multiplayer games with population-based reinforcement learning. Science 2019, 364, 859–865. [Google Scholar] [CrossRef] [Green Version]
- OpenAI. Learning Dexterous In-Hand Manipulation. arXiv 2019, arXiv:1808.00177. [Google Scholar]
- Mahmood, A.R.; Korenkevych, D.; Vasan, G.; Ma, W.; Bergstra, J. Benchmarking Reinforcement Learning Algorithms on Real-World Robots. In Proceedings of the Conference on Robot Learning, CoRL18, Zürich, Switzerland, 29–31 October 2018. [Google Scholar]
- Kalashnikov, D.; Irpan, A.; Pastor, P.; Ibarz, J.; Herzog, A.; Jang, E.; Quillen, D.; Holly, E.; Kalakrishnan, M.; Vanhoucke, V.; et al. QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation. arXiv 2018, arXiv:1806.10293. [Google Scholar]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-End Training of Deep Visuomotor Policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Quillen, D. Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection. Int. J. Robot. Res. 2016, 37, 421–436. [Google Scholar] [CrossRef]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef] [Green Version]
- Cuayáhuitl, H.; Renals, S.; Lemon, O.; Shimodaira, H. Evaluation of a hierarchical reinforcement learning spoken dialogue system. Comput. Speech Lang. 2010, 24, 395–429. [Google Scholar] [CrossRef] [Green Version]
- Mandel, T.; Liu, Y.E.; Levine, S.; Brunskill, E.; Popovic, Z. Offline Policy Evaluation Across Representations with Applications to Educational Games. In Proceedings of the 2014 International Conference on Autonomous Agents and Multi-Agent Systems, Paris, France, 5–9 May 2014. [Google Scholar]
- Pan, X.; You, Y.; Wang, Z.; Lu, C. Virtual to real reinforcement learning for autonomous driving. arXiv 2017, arXiv:1704.03952. [Google Scholar]
- Ng, A.Y.; Kim, H.J.; Jordan, M.I.; Sastry, S. Autonomous Helicopter Flight via Reinforcement Learning. Advances in Neural Information Processing Systems 16 (NIPS 2003). Available online: https://proceedings.neurips.cc/paper/2003/hash/b427426b8acd2c2e53827970f2c2f526-Abstract.html (accessed on 9 December 2021).
- François-Lavet, V.; Taralla, D.; Ernst, D.; Fonteneau, R. Deep reinforcement learning solutions for energy microgrids management. In Proceedings of the European Workshop on Reinforcement Learning (EWRL 2016), Barcelona, Spain, 3–4 December 2016. [Google Scholar]
- Lin, K.; Zhao, R.; Xu, Z.; Zhou, J. Efficient large-scale fleet management via multi-agent deep reinforcement learning. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1774–1783. [Google Scholar]
- Mirhoseini, A.; Goldie, A.; Pham, H.; Steiner, B.; Le, Q.V.; Dean, J. A Hierarchical Model for Device Placement. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Mao, H.; Alizadeh, M.; Menache, I.; Kandula, S. Resource management with deep reinforcement learning. In Proceedings of the 15th ACM Workshop on Hot Topics in Networks, Atlanta, GA, USA, 9–10 November 2016; pp. 50–56. [Google Scholar]
- Zhang, J.; Hao, B.; Chen, B.; Li, C.; Chen, H.; Sun, J. Hierarchical reinforcement learning for course recommendation in MOOCs. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 435–442. [Google Scholar]
- Zhu, H.; Yu, J.; Gupta, A.; Shah, D.; Hartikainen, K.; Singh, A.; Kumar, V.; Levine, S. The Ingredients of Real World Robotic Reinforcement Learning. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Lee, S.Y.; Choi, S.; Chung, S.Y. Sample-Efficient Deep Reinforcement Learning via Episodic Backward Update. Advances in Neural Information Processing Systems 32 (NeurIPS 2019). Available online: https://proceedings.neurips.cc/paper/2019/hash/e6d8545daa42d5ced125a4bf747b3688-Abstract.html (accessed on 9 December 2021).
- Yu, Y. Towards Sample Efficient Reinforcement Learning. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Wang, Z.; Bapst, V.; Heess, N.; Mnih, V.; Munos, R.; Kavukcuoglu, K.; de Freitas, N. Sample Efficient Actor-Critic with Experience Replay. In Proceedings of the ICLR17, Toulon, France, 24–26 April 2017. [Google Scholar]
- Strehl, A.L.; Li, L.; Wiewiora, E.; Langford, J.; Littman, M.L. PAC Model-Free Reinforcement Learning. In Proceedings of the 23rd International Conference on Machine Learning—ICML’06, Pittsburgh, PA, USA, 7–10 June 2006; ACM Press: New York, NY, USA, 2006. [Google Scholar] [CrossRef]
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete problems in AI safety. arXiv 2016, arXiv:1606.06565. [Google Scholar]
- García, J.; Fernández, F. A Comprehensive Survey on Safe Reinforcement Learning. J. Mach. Learn. Res. 2015, 16, 1437–1480. [Google Scholar]
- Wang, H.; Zariphopoulou, T.; Zhou, X.Y. Reinforcement Learning in Continuous Time and Space: A Stochastic Control Approach. J. Mach. Learn. Res. 2020, 21, 1–34. [Google Scholar]
- Ramstedt, S.; Pal, C. Real-time reinforcement learning. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 3073–3082. [Google Scholar]
- Doya, K. Reinforcement learning in continuous time and space. Neural Comput. 2000, 12, 219–245. [Google Scholar] [CrossRef]
- Georgievski, I.; Aiello, M. HTN planning: Overview, comparison, and beyond. Artif. Intell. 2015, 222, 124–156. [Google Scholar] [CrossRef]
- Dean, T.; Lin, S.H. Decomposition techniques for planning in stochastic domains. In Proceedings of the Intemational Joint Conference on Artijicial Intelligence, Montreal, QC, Canada, 20–25 August 1995. [Google Scholar]
- Sacerdoti, E.D. Planning in a Hierarchy of Abstraction Spaces. Artif. Intell. 1973, 5, 115–135. [Google Scholar] [CrossRef]
- Lake, B.M.; Ullman, T.D.; Tenenbaum, J.B.; Gershman, S.J. Building machines that learn and think like people. Behav. Brain Sci. 2017, 40, e253. [Google Scholar] [CrossRef] [Green Version]
- Ng, A.Y.; Harada, D.; Russell, S.J. Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping. In Proceedings of the International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999. [Google Scholar]
- Schmidhuber, J. Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990–2010). IEEE Trans. Auton. Ment. Dev. 2010, 2, 230–247. [Google Scholar] [CrossRef]
- Burda, Y.; Edwards, H.; Storkey, A.; Klimov, O. Exploration by Random Network Distillation. arXiv 2018, arXiv:1810.12894. [Google Scholar]
- Burda, Y.; Edwards, H.; Pathak, D.; Storkey, A.; Darrell, T.; Efros, A.A. Large-Scale Study of Curiosity-Driven Learning. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Pathak, D.; Agrawal, P.; Efros, A.A.; Darrell, T. Curiosity-Driven Exploration by Self-Supervised Prediction. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Bellemare, M.G.; Srinivasan, S.; Ostrovski, G.; Schaul, T.; Saxton, D.; Munos, R. Unifying Count-Based Exploration and Intrinsic Motivation. arXiv 2016, arXiv:1606.01868. [Google Scholar]
- Nachum, O.; Tang, H.; Lu, X.; Gu, S.; Lee, H.; Levine, S. Why Does Hierarchy (Sometimes) Work So Well in Reinforcement Learning? arXiv 2019, arXiv:1909.10618. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Gu, S.; Lillicrap, T.; Ghahramani, Z.; Turner, R.E.; Levine, S. Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Taylor, M.E.; Stone, P. An Introduction to Intertask Transfer for Reinforcement Learning. AI Mag. 2011, 32, 15. [Google Scholar] [CrossRef] [Green Version]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How Transferable Are Features in Deep Neural Networks? In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Bengio, Y. Deep learning of representations for unsupervised and transfer learning. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Bellevue, DC, USA, 2 July 2012; pp. 17–36. [Google Scholar]
- Hausman, K.; Springenberg, J.T.; Wang, Z.; Heess, N.; Riedmiller, M. Learning an Embedding Space for Transferable Robot Skills. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Tessler, C.; Givony, S.; Zahavy, T.; Mankowitz, D.J.; Mannor, S. A Deep Hierarchical Approach to Lifelong Learning in Minecraft. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Silver, D.L.; Yang, Q.; Li, L. Lifelong Machine Learning Systems: Beyond Learning Algorithms. In Proceedings of the AAAI Spring Symposium: Lifelong Machine Learning, Stanford, CA, USA, 25–27 March 2013. [Google Scholar]
- Mott, A.; Zoran, D.; Chrzanowski, M.; Wierstra, D.; Rezende, D.J. Towards Interpretable Reinforcement Learning Using Attention Augmented Agents. arXiv 2019, arXiv:1906.02500. [Google Scholar]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.A.; Kagal, L. Explaining Explanations: An Overview of Interpretability of Machine Learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–4 October 2018; pp. 80–89. [Google Scholar]
- Garnelo, M.; Arulkumaran, K.; Shanahan, M. Towards Deep Symbolic Reinforcement Learning. arXiv 2016, arXiv:1609.05518. [Google Scholar]
- Barto, A.G.; Mahadevan, S. Recent advances in hierarchical reinforcement learning. Discret. Event Dyn. Syst. 2003, 13, 41–77. [Google Scholar] [CrossRef]
- Puterman, M. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons, Inc.: New York, NY, USA, 1994. [Google Scholar]
- Bradtke, S.J.; Duff, M.O. Reinforcement learning methods for continuous-time Markov decision problems. In Proceedings of the 7th International Conference on Neural Information Processing Systems, Denver, CO, USA, 1 January 1994. [Google Scholar]
- Mahadevan, S.; Das, T.K.; Gosavi, A. Self-Improving Factory Simulation using Continuous-time Average-Reward Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Nashville, TN, USA, 8–12 July 1997. [Google Scholar]
- Parr, R.E.; Russell, S. Hierarchical Control and Learning for Markov Decision Processes; University of California: Berkeley, CA, USA, 1998. [Google Scholar]
- Bellman, R. On the theory of dynamic programming. Proc. Natl. Acad. Sci. USA 1952, 38, 716. [Google Scholar] [CrossRef] [Green Version]
- Plappert, M.; Houthooft, R.; Dhariwal, P.; Sidor, S.; Chen, R.Y.; Chen, X.; Asfour, T.; Abbeel, P.; Andrychowicz, M. Parameter Space Noise for Exploration. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Fortunato, M.; Azar, M.G.; Piot, B.; Menick, J.; Osband, I.; Graves, A.; Mnih, V.; Munos, R.; Hassabis, D.; Pietquin, O.; et al. Noisy Networks for Exploration. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Houthooft, R.; Chen, X.; Chen, X.; Duan, Y.; Schulman, J.; Turck, F.D.; Abbeel, P. VIME: Variational Information Maximizing Exploration. arXiv 2016, arXiv:1605.09674. [Google Scholar]
- Dabney, W.; Ostrovski, G.; Silver, D.; Munos, R. Implicit Quantile Networks for Distributional Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Bellemare, M.G.; Dabney, W.; Munos, R. A Distributional Perspective on Reinforcement Learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70. [Google Scholar]
- Harutyunyan, A.; Dabney, W.; Mesnard, T.; Heess, N.; Azar, M.G.; Piot, B.; van Hasselt, H.; Singh, S.; Wayne, G.; Precup, D.; et al. Hindsight Credit Assignment. arXiv 2019, arXiv:1912.02503. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; University of Cambridge, Department of Engineering: Cambridge, UK, 1994. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27–30 December 2000. [Google Scholar]
- Konda, V.R.; Tsitsiklis, J.N. Actor-critic algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27–30 December 2000. [Google Scholar]
- Diuk, C.; Cohen, A.; Littman, M.L. An object-oriented representation for efficient reinforcement learning. In Proceedings of the International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; ACM: New York, NY, USA, 2008; pp. 240–247. [Google Scholar]
- Damien, E.; Pierre, G.; Louis, W. Tree-Based Batch Mode Reinforcement Learning. J. Mach. Learn. Res. 2005, 6, 503–556. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–8 December 2012. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3128–3137. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual Question Answering. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2425–2433. [Google Scholar] [CrossRef] [Green Version]
- Donahue, J.; Simonyan, K. Large Scale Adversarial Representation Learning. arXiv 2019, arXiv:1907.02544. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2016, arXiv:1511.06434. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A Neural Algorithm of Artistic Style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 14–17 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised Pre-training for Speech Recognition. arXiv 2019, arXiv:1904.05862. [Google Scholar]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-End Attention-Based Large Vocabulary Speech Recognition. arXiv 2016, arXiv:1508.04395. [Google Scholar]
- Sainath, T.N.; Mohamed, A.r.; Kingsbury, B.; Ramabhadran, B. Deep Convolutional Neural Networks for LVCSR. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, p. 16. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. 2019. Available online: https://www.persagen.com/files/misc/radford2019language.pdf (accessed on 9 December 2021).
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Litjens, G.J.S.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Kingma, D.P.; Welling, M. An Introduction to Variational Autoencoders. Found. Trends Mach. Learn. 2019, 12, 307–392. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; Technical Report; California Univ San Diego La Jolla Inst for Cognitive Science: San Diego, CA, USA, 1985. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Edinburgh, Scotland, 30 July–5 August 2005; Volume 2, pp. 729–734. [Google Scholar]
- Van Hasselt, H.; Doron, Y.; Strub, F.; Hessel, M.; Sonnerat, N.; Modayil, J. Deep Reinforcement Learning and the Deadly Triad. arXiv 2018, arXiv:1812.02648. [Google Scholar]
- Fu, J.; Kumar, A.; Soh, M.; Levine, S. Diagnosing Bottlenecks in Deep Q-learning Algorithms. In Proceedings of the 36rd International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Bellemare, M.G.; Naddaf, Y.; Veness, J.; Bowling, M. The arcade learning environment: An evaluation platform for general agents. J. Artif. Intell. Res. 2013, 47, 253–279. [Google Scholar] [CrossRef]
- Tsitsiklis, J.N.; Van Roy, B. Analysis of temporal-diffference learning with function approximation. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 1–6 December 1997. [Google Scholar]
- Zhang, S.; Sutton, R.S. A Deeper Look at Experience Replay. arXiv 2017, arXiv:1712.01275. [Google Scholar]
- Lin, L.J. Self-improving reactive agents based on reinforcement learning, planning and teaching. Mach. Learn. 1992, 8, 293–321. [Google Scholar] [CrossRef]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized Experience Replay. arXiv 2016, arXiv:1511.05952. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; van Hasselt, H.; Lanctot, M.; de Freitas, N. Dueling Network Architectures for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Sutton, R.S. Learning to predict by the methods of temporal differences. Mach. Learn. 1988, 3, 9–44. [Google Scholar] [CrossRef]
- Dabney, W.; Rowland, M.; Bellemare, M.; Munos, R. Distributional Reinforcement Learning with Quantile Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Schulman, J.; Levine, S.; Moritz, P.; Jordan, M.I.; Abbeel, P. Trust Region Policy Optimization. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Barreto, A.; Borsa, D.; Hou, S.; Comanici, G.; Aygün, E.; Hamel, P.; Toyama, D.; Hunt, J.; Mourad, S.; Silver, D.; et al. The Option Keyboard: Combining Skills in Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Li, L.; Walsh, T.J.; Littman, M.L. Towards a Unified Theory of State Abstraction for MDPs. In Proceedings of the Ninth International Symposium on Artificial Intelligence and Mathematics, Fort Lauderdale, FL, USA, 4–6 January 2006. [Google Scholar]
- Konidaris, G.; Barto, A.G. Efficient Skill Learning using Abstraction Selection. In Proceedings of the International Joint Conferences on Artificial Intelligence, Pasadena, CA, USA, 11–17 July 2009. [Google Scholar]
- Larsen, K.G.; Skou, A. Bisimulation through probabilistic testing. Inf. Comput. 1991, 94, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Ferns, N.; Panangaden, P.; Precup, D. Metrics for Finite Markov Decision Processes. In Proceedings of the Twentieth Conference on Uncertainty in Artificial Intelligence, Banff, AB, Canada, 9–11 July 2004. [Google Scholar]
- Castro, P.S.; Precup, D. Using bisimulation for policy transfer in MDPs. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Castro, P.S.; Precup, D. Automatic Construction of Temporally Extended Actions for MDPs Using Bisimulation Metrics. In Recent Advances in Reinforcement Learning; Series Title: Lecture Notes in Computer Science; Hutchison, D., Kanade, T., Kittler, J., Kleinberg, J.M., Mattern, F., Mitchell, J.C., Naor, M., Nierstrasz, O., Pandu Rangan, C., Steffen, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7188, pp. 140–152. [Google Scholar] [CrossRef]
- Anders, J.; Andrew, G.B. Automated State Abstraction for Options using the U-Tree Algorithm. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27–30 November 2000. [Google Scholar]
- Sutton, R.S.; Precup, D.; Singh, S. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artif. Intell. 1999, 112, 181–211. [Google Scholar] [CrossRef] [Green Version]
- McGovern, A.; Sutton, R.S.; Fagg, A.H. Roles of macro-actions in accelerating reinforcement learning. In Proceedings of the Grace Hopper Celebration of Women in Computing, San Jose, CA, USA, 19–21 September 1997. [Google Scholar]
- Jong, N.K.; Hester, T.; Stone, P. The utility of temporal abstraction in reinforcement learning. In Proceedings of the International Conference on Autonomous Agents and Multiagent Systems, Estoril, Portugal, 12–16 May 2008. [Google Scholar]
- Bacon, P.L.; Harb, J.; Precup, D. The option-critic architecture. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Heess, N.; Wayne, G.; Tassa, Y.; Lillicrap, T.; Riedmiller, M.; Silver, D. Learning and transfer of modulated locomotor controllers. arXiv 2016, arXiv:1610.05182. [Google Scholar]
- Schaul, T.; Horgan, D.; Gregor, K.; Silver, D. Universal value function approximators. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Johnson, M.; Hofmann, K.; Hutton, T.; Bignell, D. The Malmo Platform for Artificial Intelligence Experimentation. In Proceedings of the International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009. [Google Scholar]
- Singh, S.P. Transfer of learning by composing solutions of elemental sequential tasks. Machine Learning 1992, 8, 323–339. [Google Scholar] [CrossRef] [Green Version]
- Mahadevan, S.; Connell, J. Automatic programming of behavior-based robots using reinforcement learning. Artif. Intell. 1992, 55, 311–365. [Google Scholar] [CrossRef]
- Maes, P.; Brooks, R.A. Learning to Coordinate Behaviors. In Proceedings of the National Conference on Artificial Intelligence, Boston, MA, USA, 29 July–3 August 1990. [Google Scholar]
- Eysenbach, B.; Gupta, A.; Ibarz, J.; Levine, S. Diversity Is All You Need: Learning Skills without a Reward Function. arXiv 2019, arXiv:1802.06070. [Google Scholar]
- Nachum, O.; Gu, S.S.; Lee, H.; Levine, S. Data-efficient hierarchical reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Vezhnevets, A.S.; Osindero, S.; Schaul, T.; Heess, N.; Jaderberg, M.; Silver, D.; Kavukcuoglu, K. Feudal networks for hierarchical reinforcement learning. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Jinnai, Y.; Abel, D.; Hershkowitz, D.E.; Littman, M.L.; Konidaris, G. Finding Options That Minimize Planning Time. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Abel, D.; Umbanhowar, N.; Khetarpal, K.; Arumugam, D.; Precup, D.; Littman, M.L. Value Preserving State-Action Abstractions. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, Palermo, Italy, 26–28 August 2020. [Google Scholar]
- Machado, M.C.; Bellemare, M.G.; Bowling, M.H. A Laplacian Framework for Option Discovery in Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- McGovern, A.; Barto, A.G. Automatic discovery of subgoals in reinforcement learning using diverse density. In Proceedings of the International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001. [Google Scholar]
- Haarnoja, T.; Hartikainen, K.; Abbeel, P.; Levine, S. Latent Space Policies for Hierarchical Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Kulkarni, T.D.; Narasimhan, K.; Saeedi, A.; Tenenbaum, J.B. Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Peng, X.B.; Abbeel, P.; Levine, S.; van de Panne, M. DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills. ACM Trans. Graph. 2018, 37. [Google Scholar] [CrossRef] [Green Version]
- Ross, S.; Gordon, G.J.; Bagnell, J.A. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- Argall, B.D.; Chernova, S.; Veloso, M.; Browning, B. A Survey of Robot Learning from Demonstration. Robot. Auton. Syst. 2009, 57. [Google Scholar] [CrossRef]
- Bain, M.; Sommut, C. A framework for behavioural cloning. Mach. Intell. 1999, 15, 103. [Google Scholar]
- Le, H.M.; Jiang, N.; Agarwal, A.; Dudík, M.; Yue, Y.; Daumé, H. Hierarchical Imitation and Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Fox, R.; Krishnan, S.; Stoica, I.; Goldberg, K. Multi-level discovery of deep options. arXiv 2017, arXiv:1703.08294. [Google Scholar]
- Krishnan, S.; Fox, R.; Stoica, I.; Goldberg, K.Y. DDCO: Discovery of Deep Continuous Options for Robot Learning from Demonstrations. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017. [Google Scholar]
- Ho, J.; Ermon, S. Generative Adversarial Imitation Learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Ng, A.Y.; Russell, S.J. Algorithms for Inverse Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000. [Google Scholar]
- Pan, X.; Ohn-Bar, E.; Rhinehart, N.; Xu, Y.; Shen, Y.; Kitani, K.M. Human-Interactive Subgoal Supervision for Efficient Inverse Reinforcement Learning. arXiv 2018, arXiv:1806.08479. [Google Scholar]
- Krishnan, S.; Garg, A.; Liaw, R.; Miller, L.; Pokorny, F.T.; Goldberg, K. Hirl: Hierarchical inverse reinforcement learning for long-horizon tasks with delayed rewards. arXiv 2016, arXiv:1604.06508. [Google Scholar]
- Dayan, P.; Hinton, G.E. Feudal reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 30 November–3 December 1992. [Google Scholar]
- Kumar, A.; Swersky, K.; Hinton, G. Feudal Learning for Large Discrete Action Spaces with Recursive Substructure. In Proceedings of the NIPS Workshop Hierarchical Reinforcement Learning, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Parr, R.; Russell, S.J. Reinforcement learning with hierarchies of machines. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 1–6 December 1997. [Google Scholar]
- Ghavamzadeh, M.; Mahadevan, S. Continuous-time hierarchical reinforcement learning. In Proceedings of the International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001. [Google Scholar]
- Dietterich, T.G. Hierarchical reinforcement learning with the MAXQ value function decomposition. J. Artif. Intell. Res. 2000, 13, 227–303. [Google Scholar] [CrossRef] [Green Version]
- Hengst, B. Discovering Hierarchy in Reinforcement Learning with HEXQ. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 8–12 July 2002. [Google Scholar]
- Jonsson, A.; Barto, A.G. Causal Graph Based Decomposition of Factored MDPs. J. Mach. Learn. Res. 2006, 7. [Google Scholar]
- Mehta, N.; Ray, S.; Tadepalli, P.; Dietterich, T.G. Automatic discovery and transfer of MAXQ hierarchies. In Proceedings of the International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008. [Google Scholar]
- Mann, T.A.; Mannor, S. Scaling Up Approximate Value Iteration with Options: Better Policies with Fewer Iterations. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Silver, D.; Ciosek, K. Compositional Planning Using Optimal Option Models. In Proceedings of the International Conference on Machine Learning, Edinburgh, Scotland, 26 June–1 July 2012. [Google Scholar]
- Precup, D.; Sutton, R.S. Multi-time Models for Temporally Abstract Planning. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 1–6 December 1997. [Google Scholar]
- Brunskill, E.; Li, L. Pac-inspired option discovery in lifelong reinforcement learning. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Guo, Z.; Thomas, P.S.; Brunskill, E. Using options and covariance testing for long horizon off-policy policy evaluation. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Konidaris, G.; Barto, A.G. Skill Discovery in Continuous Reinforcement Learning Domains using Skill Chaining. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–9 December 2009. [Google Scholar]
- Neumann, G.; Maass, W.; Peters, J. Learning complex motions by sequencing simpler motion templates. In Proceedings of the International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009. [Google Scholar]
- Şimşek, Ö.; Barto, A.G. Using relative novelty to identify useful temporal abstractions in reinforcement learning. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 5–8 July 2004; ACM: New York, NY, USA, 2004. [Google Scholar]
- Comanici, G.; Precup, D. Optimal Policy Switching Algorithms for Reinforcement Learning. In Proceedings of the 9th International Conference on Autonomous Agents and Multiagent Systems, Toronto, ON, Canada, 10–14 May 2010; p. 7. [Google Scholar] [CrossRef]
- Sutton, R.S.; Precup, D.; Singh, S.P. Intra-Option Learning about Temporally Abstract Actions. In Proceedings of the International Conference on Machine Learning, Madison, WI, USA, 24–27 July 1998. [Google Scholar]
- Mankowitz, D.J.; Mann, T.A.; Mannor, S. Time regularized interrupting options. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Harb, J.; Bacon, P.L.; Klissarov, M.; Precup, D. When waiting is not an option: Learning options with a deliberation cost. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Kaelbling, L.P. Hierarchical Learning in Stochastic Domains: Preliminary Results. In Proceedings of the International Conference on Machine Learning, Amherst, MA, USA, 27–29 July 1993. [Google Scholar]
- Digney, B.L. Learning hierarchical control structures for multiple tasks and changing environments. In Proceedings of the Fifth International Conference on Simulation of Adaptive Behavior on from Animals to Animats, Zurich, Switzerland, 17–21 August 1998. [Google Scholar]
- Stolle, M.; Precup, D. Learning options in reinforcement learning. In Proceedings of the International Symposium on Abstraction, Reformulation, and Approximation, Kananaskis, AB, Canada, 2–4 August 2002. [Google Scholar]
- Dietterich, T.G.; Lathrop, R.H.; Lozano-Pérez, T. Solving the multiple instance problem with axis-parallel rectangles. Artif. Intell. 1997, 89, 31–71. [Google Scholar] [CrossRef] [Green Version]
- Maron, O.; Lozano-Pérez, T. A framework for multiple-instance learning. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 1–6 December 1997. [Google Scholar]
- Kulkarni, T.D.; Saeedi, A.; Gautam, S.; Gershman, S.J. Deep successor reinforcement learning. arXiv 2016, arXiv:1606.02396. [Google Scholar]
- Dayan, P. Improving Generalization for Temporal Difference Learning: The Successor Representation. Neural Comput. 1993, 5, 613–624. [Google Scholar] [CrossRef] [Green Version]
- Goel, S.; Huber, M. Subgoal Discovery for Hierarchical Reinforcement Learning Using Learned Policies. In Proceedings of the FLAIRS Conference, St. Augustine, FL, USA, 11–15 May 2003. [Google Scholar]
- Menache, I.; Mannor, S.; Shimkin, N. Q-Cut—Dynamic Discovery of Sub-goals in Reinforcement Learning. In Proceedings of the European Conference on Machine Learning, Helsinki, Finland, 19–23 August 2002. [Google Scholar]
- Waissi, G.R. Network Flows: Theory, Algorithms, and Applications; Prentice-Hall: Englewood Cliffs, NJ, USA, 1994. [Google Scholar]
- Şimşek, Ö.; Wolfe, A.P.; Barto, A.G. Identifying useful subgoals in reinforcement learning by local graph partitioning. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; ACM: New York, NY, USA, 2005. [Google Scholar]
- Mahadevan, S. Proto-value functions: Developmental reinforcement learning. In Proceedings of the International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; ACM: New York, NY, USA, 2005. [Google Scholar]
- Machado, M.C.; Rosenbaum, C.; Guo, X.; Liu, M.; Tesauro, G.; Campbell, M. Eigenoption Discovery through the Deep Successor Representation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Lakshminarayanan, A.S.; Krishnamurthy, R.; Kumar, P.; Ravindran, B. Option discovery in hierarchical reinforcement learning using spatio-temporal clustering. arXiv 2016, arXiv:1605.05359. [Google Scholar]
- Da Silva, B.C.; Konidaris, G.; Barto, A.G. Learning Parameterized Skills. In Proceedings of the International Conference on Machine Learning, Edinburgh, Scotland, 26 June–1 July 2012. [Google Scholar]
- Vezhnevets, A.; Mnih, V.; Agapiou, J.; Osindero, S.; Graves, A.; Vinyals, O.; Kavukcuoglu, K. Strategic Attentive Writer for Learning Macro-Actions. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Gregor, K.; Danihelka, I.; Graves, A.; Rezende, D.J.; Wierstra, D. DRAW: A Recurrent Neural Network For Image Generation. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Sharma, S.; Lakshminarayanan, A.S.; Ravindran, B. Learning to Repeat: Fine Grained Action Repetition for Deep Reinforcement Learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Rusu, A.A.; Colmenarejo, S.G.; Gulcehre, C.; Desjardins, G.; Kirkpatrick, J.; Pascanu, R.; Mnih, V.; Kavukcuoglu, K.; Hadsell, R. Policy distillation. arXiv 2015, arXiv:1511.06295. [Google Scholar]
- Daniel, C.; Neumann, G.; Peters, J. Hierarchical relative entropy policy search. In Proceedings of the Artificial Intelligence and Statistics, La Palma, Canary Islands, 21–23 April 2012; pp. 273–281. [Google Scholar]
- Peters, J.; Mülling, K.; Altun, Y. Relative Entropy Policy Search. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Daniel, C.; Van Hoof, H.; Peters, J.; Neumann, G. Probabilistic inference for determining options in reinforcement learning. Mach. Learn. 2016, 104, 337–357. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.S. Temporal Credit Assignment in Reinforcement Learning. Ph.D. Thesis, University of Massachusetts Amherst, Amherst, MA, USA, 1984. [Google Scholar]
- Baird, L.C. Advantage Updating, Wright Lab. Technical Report WL-TR-93-1l46. 1993. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.49.4950&rep=rep1&type=pdf (accessed on 9 December 2021).
- Klissarov, M.; Bacon, P.L.; Harb, J.; Precup, D. Learnings Options End-to-End for Continuous Action Tasks. In Proceedings of the Hierarchical Reinforcement Learning Workshop, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Harutyunyan, A.; Dabney, W.; Borsa, D.; Heess, N.; Munos, R.; Precup, D. The Termination Critic. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Naha, Japan, 16–18 April 2019; pp. 2231–2240. [Google Scholar]
- Wang, J.X.; Kurth-Nelson, Z.; Tirumala, D.; Soyer, H.; Leibo, J.Z.; Munos, R.; Blundell, C.; Kumaran, D.; Botvinick, M. Learning to Reinforcement Learn. arXiv 2017, arXiv:1611.05763. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Duan, Y.; Schulman, J.; Chen, X.; Bartlett, P.L.; Sutskever, I.; Abbeel, P. RL$$: Fast Reinforcement Learning via Slow Reinforcement Learning. arXiv 2016, arXiv:1611.02779. [Google Scholar]
- Frans, K.; Ho, J.; Chen, X.; Abbeel, P.; Schulman, J. Meta Learning Shared Hierarchies. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Li, A.C.; Florensa, C.; Clavera, I.; Abbeel, P. Sub-Policy Adaptation for Hierarchical Reinforcement Learning. arXiv 2020, arXiv:1906.05862. [Google Scholar]
- Sohn, S.; Woo, H.; Choi, J.; Lee, H. Meta Reinforcement Learning with Autonomous Inference of Subtask Dependencies. arXiv 2020, arXiv:2001.00248. [Google Scholar]
- Sutton, R.S.; Modayil, J.; Delp, M.; Degris, T.; Pilarski, P.M.; White, A.; Precup, D. Horde: A scalable real-time architecture for learning knowledge from unsupervised sensorimotor interaction. In Proceedings of the International Conference on Autonomous Agents and Multiagent Systems, Taipei, Taiwan, 2–6 May 2011. [Google Scholar]
- Bengio, E.; Thomas, V.; Pineau, J.; Precup, D.; Bengio, Y. Independently Controllable Features. arXiv 2017, arXiv:1703.07718. [Google Scholar]
- Hinton, G.E. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Levy, A.; Platt, R.; Saenko, K. Hierarchical Reinforcement Learning with Hindsight. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Van Seijen, H.; Fatemi, M.; Romoff, J.; Laroche, R.; Barnes, T.; Tsang, J. Hybrid reward architecture for reinforcement learning. arXiv 2017, arXiv:1706.04208. [Google Scholar]
- Jaderberg, M.; Mnih, V.; Czarnecki, W.M.; Schaul, T.; Leibo, J.Z.; Silver, D.; Kavukcuoglu, K. Reinforcement learning with unsupervised auxiliary tasks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.P.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Riedmiller, M.A.; Hafner, R.; Lampe, T.; Neunert, M.; Degrave, J.; de Wiele, T.V.; Mnih, V.; Heess, N.; Springenberg, J.T. Learning by Playing—Solving Sparse Reward Tasks from Scratch. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; Dey, A.K. Maximum Entropy Inverse Reinforcement Learning. In Proceedings of the AAAI, Chicago, IL, USA, 13–17 July 2008. [Google Scholar]
- Todorov, E. Linearly-solvable Markov decision problems. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–5 December 2006. [Google Scholar]
- Haarnoja, T.; Tang, H.; Abbeel, P.; Levine, S. Reinforcement Learning with Deep Energy-Based Policies. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Nachum, O.; Gu, S.; Lee, H.; Levine, S. Near-Optimal Representation Learning for Hierarchical Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Sukhbaatar, S.; Denton, E.; Szlam, A.; Fergus, R. Learning Goal Embeddings via Self-Play for Hierarchical Reinforcement Learning. arXiv 2018, arXiv:1811.09083. [Google Scholar]
- Florensa, C.; Duan, Y.; Abbeel, P. Stochastic neural networks for hierarchical reinforcement learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Tang, Y.; Salakhutdinov, R.R. Learning Stochastic Feedforward Neural Networks. Advances in Neural Information Processing Systems 26. Available online: https://proceedings.neurips.cc/paper/2013/hash/d81f9c1be2e08964bf9f24b15f0e4900-Abstract.html (accessed on 9 December 2021).
- Radford, N. Learning Stochastic Feedforward Networks; Department of Computer Science University of Toronto: Toronto, ON, Canada, 1990; Volume 4. [Google Scholar]
- Gregor, K.; Rezende, D.J.; Wierstra, D. Variational Intrinsic Control. arXiv 2016, arXiv:1611.07507. [Google Scholar]
- Salge, C.; Glackin, C.; Polani, D. Empowerment—An introduction. In Guided Self-Organization: Inception; Springer: Berlin/Heidelberg, Germany, 2014; pp. 67–114. [Google Scholar]
- Achiam, J.; Edwards, H.; Amodei, D.; Abbeel, P. Variational option discovery algorithms. arXiv 2018, arXiv:1807.10299. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Dibya, G.; Abhishek, G.; Sergey, L. Learning Actionable Representations with Goal-Conditioned Policies. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Menashe, J.; Stone, P. Escape Room: A Configurable Testbed for Hierarchical Reinforcement Learning. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, Montreal, QC, Canada, 13–17 May 2019; pp. 2123–2125. [Google Scholar]
- Barto, A.G.; Sutton, R.S.; Anderson, C.W. Neuronlike adaptive elements that can solve difficult learning control problems. IEEE Trans. Syst. Man, Cybern. 1983, 5, 834–846. [Google Scholar] [CrossRef]
- Cobbe, K.; Klimov, O.; Hesse, C.; Kim, T.; Schulman, J. Quantifying Generalization in Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Kempka, M.; Wydmuch, M.; Runc, G.; Toczek, J.; Jaśkowski, W. Vizdoom: A doom-based ai research platform for visual reinforcement learning. In Proceedings of the 2016 IEEE Conference on Computational Intelligence and Games (CIG); IEEE: Piscataway, NJ, USA, 2016; pp. 1–8. [Google Scholar]
- Beattie, C.; Leibo, J.Z.; Teplyashin, D.; Ward, T.; Wainwright, M.; Küttler, H.; Lefrancq, A.; Green, S.; Valdés, V.; Sadik, A.; et al. Deepmind lab. arXiv 2016, arXiv:1612.03801. [Google Scholar]
- Vinyals, O.; Ewalds, T.; Bartunov, S.; Georgiev, P.; Vezhnevets, A.S.; Yeo, M.; Makhzani, A.; Küttler, H.; Agapiou, J.; Schrittwieser, J.; et al. Starcraft ii: A new challenge for reinforcement learning. arXiv 2017, arXiv:1708.04782. [Google Scholar]
- Santiago, O.; Gabriel, S.; Alberto, U.; Florian, R.; David, C.; Mike, P. A survey of real-time strategy game AI research and competition in StarCraft. IEEE Trans. Comput. Intell. AI Games 2013, 5. [Google Scholar]
- Todorov, E.; Erez, T.; Tassa, Y. MuJoCo: A physics engine for model-based control. In Proceedings of the International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012. [Google Scholar]
- Tassa, Y.; Doron, Y.; Muldal, A.; Erez, T.; Li, Y.; de Las Casas, D.; Budden, D.; Abdolmaleki, A.; Merel, J.; Lefrancq, A.; et al. DeepMind Control Suite. arXiv 2018, arXiv:1801.00690. [Google Scholar]
- Coumans, E.; Bai, Y. PyBullet, a Python Module for Physics Simulation for Games, Robotics and Machine Learning. 2016. Available online: http://pybullet.org (accessed on 9 December 2021).
- Duan, Y.; Chen, X.; Houthooft, R.; Schulman, J.; Abbeel, P. Benchmarking deep reinforcement learning for continuous control. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Engstrom, L.; Ilyas, A.; Santurkar, S.; Tsipras, D.; Janoos, F.; Rudolph, L.; Madry, A. Implementation Matters in Deep RL: A Case Study on PPO and TRPO. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep Reinforcement Learning That Matters. arXiv 2017, arXiv:1709.06560. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.C.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Savinov, N.; Raichuk, A.; Vincent, D.; Marinier, R.; Pollefeys, M.; Lillicrap, T.; Gelly, S. Episodic Curiosity through Reachability. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Jinnai, Y.; Park, J.W.; Machado, M.C.; Konidaris, G. Exploration in Reinforcement Learning with Deep Covering Options. In Proceedings of the International Conference on Learning Representations, ICLR2020, Addis Ababa, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Greydanus, S.; Koul, A.; Dodge, J.; Fern, A. Visualizing and Understanding Atari Agents. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Atrey, A.; Clary, K.; Jensen, D. Exploratory Not Explanatory: Counterfactual Analysis of Saliency Maps for Deep Reinforcement Learning. In Proceedings of the ICLR2020, Addis Ababa, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Rupprecht, C.; Ibrahim, C.; Pal, C.J. Finding and Visualizing Weaknesses of Deep Reinforcement Learning Agents. In Proceedings of the ICLR20, Addis Ababa, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Shu, T.; Xiong, C.; Socher, R. Hierarchical and Interpretable Skill Acquisition in Multi-Task Reinforcement Learning. In Proceedings of the International Conference on Learning Representations 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Osband, I.; Doron, Y.; Hessel, M.; Aslanides, J.; Sezener, E.; Saraiva, A.; McKinney, K.; Lattimore, T.; Szepezvari, C.; Singh, S.; et al. Behaviour Suite for Reinforcement Learning. arXiv 2019, arXiv:1908.03568. [Google Scholar]
- Dhariwal, P.; Hesse, C.; Klimov, O.; Nichol, A.; Plappert, M.; Radford, A.; Schulman, J.; Sidor, S.; Wu, Y.; Zhokhov, P. OpenAI Baselines. 2017. Available online: https://github.com/openai/baselines (accessed on 9 December 2021).
- Jiang, Y.; Gu, S.; Murphy, K.; Finn, C. Language as an Abstraction for Hierarchical Deep Reinforcement Learning. In Proceedings of the NeurIPS19, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Shang, W.; Trott, A.; Zheng, S.; Xiong, C.; Socher, R. Learning World Graphs to Accelerate Hierarchical Reinforcement Learning. arXiv 2019, arXiv:1907.00664. [Google Scholar]
- Zambaldi, V.; Raposo, D.; Santoro, A.; Bapst, V.; Li, Y.; Babuschkin, I.; Tuyls, K.; Reichert, D.; Lillicrap, T.; Lockhart, E.; et al. Deep Reinforcement Learning with Relational Inductive Biases. In Proceedings of the ICLR19, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Santoro, A.; Raposo, D.; Barrett, D.G.; Malinowski, M.; Pascanu, R.; Battaglia, P.; Lillicrap, T. A Simple Neural Network Module for Relational Reasoning. In Proceedings of the NIPS17, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problem-Specific Models | Options | Goal-Conditional | |
|---|---|---|---|
| Sub-behaviors | Problem-specific sub-behaviors that work together in order to solve a very specific task. | A more generic system of modules that work together to tackle a limited set of similar sub problems. | A generic system that is capable of expressing a wide range of sub-behaviors. |
| Capabilities | Intuitive way of modeling hierarchies of sub-behaviors. | - Generic framework capable of modeling sub-behaviors. - Transfers well in similar environments. - Various learning algorithms available. | - Generalization of sub-behaviors. - Capable of supporting a large amount of sub-behaviors. - Various learning algorithms available. |
| Challenges | - Not generally applicable. - Requires a lot of expert knowledge. - Lack of learning algorithms. | - Learning is often sample inefficient. - Difficult to share knowledge between options. - Limited scalable: only a few options at the same time are feasible. | - Efficient representation of subgoals. - How to efficiently sample goal-vectors during training, in order to maximize generalization over sub-behaviors. - Often suffers from instability. - Scaling to more than two levels remains difficult. |
| Required priors | Almost entirely hand-crafted. | Some expert knowledge required in the form of termination conditions, and intrinsic reward signals. | None, however intrinsic reward has been demonstrated to speed up training [155]. |
| Interpretability | High | High, however often due to introduced priors | Low, often uses latent-spaces. |
| Algorithm | Training Method | Required Priors | Interpretable Elements | Transferrable Policy | Improvement |
|---|---|---|---|---|---|
| Feudal-Q | End-to-end | State-space division | None | No, problem-specific solution | More comprehensive exploration than flat Q-learning |
| HAM-Q | End-to-end | HAM | Trained HAMs | HAM language can be used to transfer knowledge | Significant improvement over flat Q-learning |
| MAXQ-Q | End-to-end | MAXQ decomposition | MAXQ decomposition | MAX-nodes | Faster training, compared to flat Q-learning |
| HEXQ | Staged | None | MAXQ decomposition | MAX-nodes | Automatic discovery of MAXQ decompositions |
| VISA | End-to-end | DBN model | MAXQ decomposition | MAX-nodes | More complex decomposition than HEXQ |
| HI-MAT | End-to-end | a successful trajectory | MAXQ decomposition | MAX-nodes | More compact hierarchies than VISA |
| Algorithm | Training Method | Required Priors | Interpretable Elements | Transferrable Policy | Improvement |
|---|---|---|---|---|---|
| Diverse density | Staged | Number of options, successful trajectories | Subgoal states | Same environment | Automatic subgoal detection learns faster compared to using only primitive actions |
| h-DQN | Staged | Subgoals as pixel masks | Subgoals | Same environment | First HRL approach to hard-exploration in high-dimensional state-spaces |
| HiREPs | End-to-end | Number of options | None | No, problem-specific solutions | Improved performance over non-hierarchical REPS algorithm |
| STRAW | End-to-end | None | Macro-actions | No, problem-specific solutions | Improved performance in some Atari games |
| H-DRLN | Staged | Task curriculum | None | Same environment, similar tasks | Demonstrates building blocks for lifelong learning framework |
| Eigen-Options | Staged | Number of options | Subgoals | Same environment | Discovered options allow better exploration then bottleneck-based options |
| MLSH | Staged | Number of options | None | Transfer possible to tasks different from previously seen tasks | Faster training performance when applied on new tasks |
| DDO | Staged | Demonstrations | None | Solutions are task specific | Faster training in Atari RAM environments. |
| Option-Critic | End-to-end | Number of options | Termination probabilities | Same environment | First end-to-end algorithm |
| Algorithm | Training Method | Required Priors | Interpretable Elements | Transferrable Policy | Improvement |
|---|---|---|---|---|---|
| VIC | Staged | None | None | Same environment | Demonstrated capabilities of unsupervised learning in HRL |
| SNN | Staged | Proxy reward | Sub-behaviors | Same environment | Increased expressiveness and multimodality of sub-behaviors |
| FuN | End-to-end | None | None | Task-specific solutions | Significant improvement over Option-Critic |
| DIAYN | Staged | None | None | Same environment | Discovers more diverse sub-behavior than VIC |
| SAC-LSP | Staged and End-to-end | None, however reward shaping is supported | None | Same environment | Outperforms previously proposed non-hierarchical algorithms |
| HIRO | End-to-End | None | None | Same environment | Outperforms FuN, especially in sample efficiency |
| VALOR | Staged | None | None, sub-behaviors are encoded by a latent vector | Similar environments | Qualitatively better sub-behaviors than DIAYN and VIC |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hutsebaut-Buysse, M.; Mets, K.; Latré, S. Hierarchical Reinforcement Learning: A Survey and Open Research Challenges. Mach. Learn. Knowl. Extr. 2022, 4, 172-221. https://doi.org/10.3390/make4010009
Hutsebaut-Buysse M, Mets K, Latré S. Hierarchical Reinforcement Learning: A Survey and Open Research Challenges. Machine Learning and Knowledge Extraction. 2022; 4(1):172-221. https://doi.org/10.3390/make4010009
Chicago/Turabian StyleHutsebaut-Buysse, Matthias, Kevin Mets, and Steven Latré. 2022. "Hierarchical Reinforcement Learning: A Survey and Open Research Challenges" Machine Learning and Knowledge Extraction 4, no. 1: 172-221. https://doi.org/10.3390/make4010009
APA StyleHutsebaut-Buysse, M., Mets, K., & Latré, S. (2022). Hierarchical Reinforcement Learning: A Survey and Open Research Challenges. Machine Learning and Knowledge Extraction, 4(1), 172-221. https://doi.org/10.3390/make4010009