1. Introduction
Explaining the predictions of sophisticated machine-learning algorithms is an important issue for the foundations of AI. Recent efforts [
1,
2,
3,
4,
5] have proposed various methods for providing explanations. Among these, model-based, logical approaches completely characterise one aspect of the decision offer complete and valid explanations. “Model-free” or model-agnostic, heuristic approaches like those in [
1,
2,
6] cannot.
Model-based logical methods are thus
a priori desirable, but they have an epistemological problem: they may be too complex for humans to understand or even to write down in human-readable form. Interpretability requires
epistemically accessible explanations, explanations humans can grasp
and compute. Yet what is a sufficiently complete and
adequate epistemically accessible explanation, a
good explanation still needs analysis [
7].
We address this open question and characterize sufficiently good, or fair and adequate, explanations in terms of counterfactuals—explanations, that is that are framed in terms of what would have happened had certain conditions (that do not obtain) been the case. Counterfactual explanations, as we argue below, are a good place to start for finding accessible explanations, because they are typically more compact than other forms of explanation. While there have been many other counterfactual approaches, our approach is novel in that it provides an explicit, logical model for counterfactual explanations and links this model to techniques used to find counterfactual counterparts and explanations in ML systems like heat or saliency maps [
8] or adversarial examples [
3,
9].
Another novel element of our approach is that for us a fair and adequate explanation must take into account the cognitive constraints and fairness requirements of an explainee
[
10,
11,
12].
asks for an explanation for why
when she wasn’t expecting
. Her not expecting
follows from beliefs that must now be revised—how to specify this revision is the conundrum of
. An adequate explanation is a pragmatic act that should solve the conundrum that gave rise to the request for explanation; solving the conundrum makes the explanation useful to
[
13]. In addition, an adequate explanation must lay bare biases that might be unfair or injurious to
(the fairness constraint).
More precisely, we frame the pragmatic component of explanations in terms of what we call the
conundrum and
fairness requirements of the
explainee, the person who requested the explanation or for whom the explanation is intended). It is this conundrum that makes the explainee request an explanation. This pragmatic act is naturally modelled in a game theoretic setting in which the explainer must understand explainee E’s conundrum and respond so as to resolve it. A cooperative explainer will provide an explanation in terms of the type he assigns to E, as the type will encode the relevant portions of E’s cognitive state. On the other hand the explainee will need to interpret the putative explanation in light of her model of the explainer’s view of his type. Thus, both explainer and explainee have strategies that exploit information about the other—naturally suggesting a game theoretic framework for analysis. Our theory thus analyzes the important pragmatic component of explanations and addresses a so far unsolved challenge for explanations noted by [
14], according to which good, counterfactual explanations should take into account the explainee’s preferences and beliefs.
In an initial description of our view of fair and adequate explanations [
15], we exploited both a logical theory of counterfactuals [
16] and mathematical approaches for adversarial perturbation techniques [
5,
8,
9,
14,
17,
18,
19,
20,
21] to prove a novel and precise correspondence between logical and mathematical formulations for counterfactuals. We then formalized conundra to provide a novel pragmatic notion of fair and adequate explanations, and we developed Explanation games for proving computational complexity results for finding fair and adequate explanations in non cooperative settings.
In this paper, we review some of the results of [
15] in the first four sections.
Section 2 provides a background to our view of explanations;
Section 3 analyzes counterfactual explanations in more detail;
Section 4 analyzes the pragmatic component of counterfactual explanations; and
Section 5 analyzes the computational complexity of fair and adequate explanations. But in this paper, we have extended
Section 3 to analyze the partiality of counterfactual explanations and how many other approaches that use counterfactual techniques often provide invalid explanations and hide possibly injurious biases. We have extended
Section 5 to show how to use Explanation games to investigate properties of counterfactual models.
In addition, this paper has two sections with completely new work. In
Section 6, we set out certain desiderata for counterfactual models that are more sophisticated than those in [
15]. In
Section 7, we propose two models of counterfactuals that are much more sophisticated than the ones contemplated in our earlier work—counterfactual models based on causal structural causal models or graphs, and counterfactual models based on transport theories. These models present much more sophisticated views of counterfactual counterparts. We extend our link between between logical and statistics based counterfactual methods to these sophisticated models. This leads us to change the underlying logical framework of counterfactuals by introducing probabilities explicitly into counterfactual semantics. We show that transport based approaches are especially interesting because they allow us to address in principle important challenges for applying counterfactual models to ML cited by [
14]: first, transport methods allow us to construct counterfactual predictions based on partial data (when data about some features are missing). Second in some cases. they yield a set of counterfactuals that are equivalent to those provided by a causal theory. This means that we can have causally based counterfactuals in the absence of a fully specified causal structural model. A third advantage and potentially revolutionary advantage is that transport models form the basis of ML systems in which we can eliminate adversarial examples where the change in prediction of the system is not intelligible to examples in which the change in prediction is clearly intelligible and a classic case of a counterfactual counterpart [
22].
As the reader will see, this is a theoretical paper. While we believe that experiments using various systems on different data sets can yield insights, we also think there is an important place for papers like this one that carve out a theoretical space. Our paper sets out a formal and explicit analysis of counterfactual explainability. We show how counterfactual models can address problems for ML systems at a theoretical level, and we address worst cases computational costs for fair and adequate explanations in some counterfactual models. In light of these developments, we think that the counterfactual approach has very rich empirical applications, some of which are explored in [
22]; but adding a discussion of these applications would go far beyond this paper’s intended scope.
2. Background on Explanations
Following [
10,
11], we take explanations to be answers to
why questions. Consider the case where a bank, perhaps using a machine learning program, judges
’s application for a bank loan and
is turned down.
is in a position to ask a
why question like,
- (1)
why was I turned down for a loan?
When her beliefs would not have predicted this. Her beliefs might not have been sufficient to infer that she wouldn’t get a loan; or her beliefs might have been mistaken—they might have led her to conclude that she would get the loan. In any case, must now revise her beliefs to accord with reality. Counterfactual explanations, explanations expressed with counterfactual statements, help do this by offering an incomplete list of relevant factors that together with unstated properties of entail the explanandum—the thing needs explained, in this case her not getting the loan. For instance, the bank might return the following answer to (1):
- (2)
Your income is €50 K per year.
- (3)
If your income had been €100 K per year, you would have gotten the loan.
The counterfactual statement (3) states what, given all of
’s other qualities, would have been sufficient to get the loan. But since her income is in fact not €100 K per year, the semantics of counterfactuals entails that
does not get the loan. (3) also proposes to
how to revise her beliefs to make them accord with reality, in that it suggests that she mistakenly thought that her actual salary was sufficient for getting the loan and that the correct salary level is €100 K per year. Ref. [
23] provides a superficially similar picture to the pragmatic one we present, but their aim, to provide a semantics for argumentation frameworks, is quite different from ours. For us the pragmatic aspect of explanations is better explained via a game theoretic framework, as we shall see in
Section 5.
Counterfactual explanations, we have seen, are partial, because they do not explicitly specify logically sufficient conditions for the prediction. They are also local, because their reliance on properties of a particular sample makes them valid typically only for that sample. Had we considered a different individual, say , the bank’s explanation for their treatment of might have differed. might have had different, relevant properties from ; for instance, might be just starting out on a promising career with a salary of €50 K per year, while is a retiree with a fixed income.
The partiality and locality of counterfactuals make them simpler and more epistemically accessible than other forms of model-based logical explanations. Logical methods often return rather long explanations even for relatively simple classifiers with large number of features that makes the explanations hard for humans to understand [
24]. Nevertheless, the logical theory of counterfactuals enables us to move from a counterfactual to a complete and logically valid explanation. So in principle counterfactual explanations can provide both rigour and epistemic accessibility. But not just any partiality will do, since partiality makes possible explanations that are misleading, that hide injurious or unfair biases.
To show how the partiality of counterfactual explanations can hide unfair biases, consider the following scenario. The counterfactual in (2) might be true but it also might be misleading, hiding an unfair bias. (1) and (2) can be true while another, more morally repugnant explanation that hinges on ’s being female is also true. Had been male, she would have gotten the loan with her actual salary of €50 K per year. A fair and adequate explanation should expose such biases.
We now move to a more abstract setting. Let be a machine learning algorithm, with an n-dimensional feature space encoding data and Y the prediction space. Concretely, we assume that is some sort of classifier. When , an explainee may want an explanation, an answer to the question, “why ?” We will say that an explanation is an event by an explainer, the provider of the explanation, directed towards the explainee (the person requesting the explanation or to whom the explanation is directed) with a conundrum. An explanation will consist of of an explanandum, the event or prediction to be explained, an explanans, the information that is linked in some way to the explanandum so as to resolve the explainee’s conundrum. When the explanation is about a particular individual, we call that individual the focal point of the explanation.
Explanations have thus several parameters. The first is the scope of the explanation. For a global explanation of , the explainee wants to know the behavior of over the total space . But such an explanation may be practically uncomputable; and for many purposes, we might only want to know how behaves on a selection of data points of interest or focal points, like ’s bank profile in our example. Explanations that are restricted to focal points are local explanations.
Explanations of program behavior also differ as to the nature of the
explanans. In this paper, we will be concerned with
external explanations that involve an explanatory link between an
explanans consisting of features of the input or feature space
X, and the output in
Y without considering any internal states of the learning mechanism [
25]. These are attractive epistemically, because unpacking the algorithms’ internal states and assigning them a meaning can be a very complicated affair. Most explanations of complex ML systems like those that appeal to heat maps for instance are also external explanations. Most ML systems
in effect are too complex or opaque for its behaviour to be analyzed statically.
Explanations are not only characterized by what sort of
explanans they appeal to, a set of features in our case; they must also make explicit å
how the explanans is derived. To derive the
explanans, we might have to appeal to the internal states of the learning mechanism. Explanations that use heat maps and gradient descent [
8,
26,
27] do this as well as logic based explanations. These are all
model = based types of explanation. On the other hand, explanations based on approximations of the behavior of the learning mechanisms like [
1,
2] do not use any internal states of the learning mechanism to find an explanans. The latter are known as
model free explanations.
A third pertinent aspect of explanations concerns the link between
explanans and the
explanandum. Refs. [
4,
28,
29] postulate a deductive or logical consequence link between
explanans and
explanandum. Ref. [
4] represent
as a set of logic formulas
. By assuming features with finitely many values, an
instance is then a set of literals that in which values are assigned to every feature in the feature space; if the features are binary, we can just have literals
ℓ that such that
ℓ represent the presence of a feature and
the absence of that feature. An
abductive explanation of why
is a subset minimal set of literals
such that
. Abductive explanations exploit universal generalizations and a deductive consequence relation. They explain why
any instance that has
is such that
and hence are known as
global explanations [
30]. On the other hand, model-free explanations typically don’t provide any explicit analysis of the relation between
explanans and
explanandum.
Counterfactuals offer a natural way to provide epistemically accessible, partial explanations of properties of individuals or focal points. The counterfactual in (3) gives a sufficient reason for
’s getting the loan,
all other factors of her situation being equal or being as equal as possible (
ceteris paribus) given the assumption of a different salary for
. Such explanations are often called
local explanations [
30,
31], as they depend on the nature of the focal point. Deductive explanations, on the other hand, are invariant with respect to the choice of focal point.
Counterfactual explanations are also partial [
3], because the truth of the antecedent of a counterfactual is not by itself logically sufficient to yield the truth of the formula in the consequent. Model based counterfactual explanations instead derive logically sound predictions via points that verify the antecedent of the counterfactual and are minimally changed from the focal point. Because counterfactual explanations exploit
ceteris paribus conditions, factors that deductive explanations must mention can remain implicit in a counterfactual explanation. Thus, counterfactual explanations are typically more compact and thus in principle easier to understand (see [
29] for some experimental evidence of this). Counterfactuals are also intuitive vehicles for explanations as they also encode an analysis of causation [
32].
Counterfactual Explanations for Learning Algorithms
A counterfactual language
is a propositional language to which a two place modal operator
is added. Its canonical semantics, as outlined in [
16], for exploits a possible worlds model for propositional logic,
, where:
W is a non-empty set (of worlds), ≤ is a ternary similarity relation (
), and
assigns to elements in
P, the set of proposition letters or atomic formulas of the logic, a function from worlds to truth values or set of possible worlds. Then, where ⊧ represents truth in such a model, we define truth recursively as usual for formulas of ordinary propositional logic and for counterfactuals
, we have:
Definition 1. just in case: .
What motivates this semantics with a similarity relation? We can find both epistemic and metaphysical motivations. Epistemically, finding a closest or most similar world in which the antecedent
of the counterfactual
is true to evaluate its consequent
follows a principle of belief revision [
33], according to which it is rational to make minimal revisions to one’s epistemic state upon acquiring new conflicting information. A metaphysical motivation comes from the link Lewis saw between counterfactuals and causation;
implies that if
hadn’t been the case,
wouldn’t have been the case, capturing much of the semantics of the statement
caused . The truth of such intuitive causal statements, however, relies on the presence of a host of secondary or enabling conditions. Intuitively the statement that if I had dropped this glass on the floor, it would have broken is true; but in order for the consequent to hold after dropping the glass, there are many elements that have to be the same in that counterfactual situation as in the actual world—the floor needs to be hard, there needs to be a gravitational field around the strength of the Earth’s that accelerates the glass towards the floor, and many other conditions. In other words, in order for such ordinary statements to be true, the situation in which one evaluates the consequent of a counterfactual has to resemble very closely the actual world.
Though intuitive, as this logical definition of counterfactuals stands, it is not immediately obvious how to apply it to explanations of learning algorithm behavior. We need to adapt it to a more analytical setting. We will do so by interpreting the similarity relation appealed to in the semantics of counterfactuals as a distance function or norm as in [
34] over the feature space
, an n-dimensional space, used to describe data points. To fill out our semantics for counterfactuals in this application, we identify instances in
as the relevant “worlds” for the semantics of the counterfactuals.
We will fix a quantifier free counterfactual language with a finite set of variables for each dimension i of . To each and for each element in we will assign a value; in effect our elements in function like assignments. Our language will also contain a set of constants that designate values P that elements can take in . We add to this a set of formulas that describe the predictions in Y of . Atomic formulae are of the form and and the language is closed under Boolean operations and the counterfactual operator .
Notice that our learning function is itself not expressed in the language. Rather, it informs the counterfactual model as we see from the following definition. In addition our elements.
Definition 2. A counterfactual model for with is a structure with D a non empty set containing , W a set of worlds , a norm on and , and .
We can now give the generic semantics for .
Definition 3. Let be a counterfactual model for with .
iff
iff
the usual clauses for and of
just in case: if
Each instance in
has a finite theory that is a conjunction of atomic formulae of
the form
where
is a variable for dimension
i and
is its value. We now need to specify a norm for
. A very simple norm assumes that each dimension of
is orthogonal and has a Boolean set of values; in this case,
has a natural
norm or Manhattan or edit distance [
35]. While this assumption commits us to the fact that the dimensions of
capture
all the causally relevant factors and that they are all independent—both of which are false for typical instances of learning algorithms, it is simple and makes our problem concrete. We will indicate below when our results depend on this simplifying assumption. Otherwise, we will only assume a finite set of finitely valued features through
Section 5. In
Section 6 and
Section 7, we will complicate our language.
A logic of counterfactuals can now exploit the link between logic formulas, features of points in
, and a learning algorithm
described in [
4,
36,
37]. Suppose a focal point
is such that
. A counterfactual
that is true at the point
, where
is a prediction incompatible with
, has an antecedent that is a conjunction of atomic formulae that defines a sufficient and minimal shift in the features of
to get the prediction
. Each counterfactual that explains the behavior of
around a focal point
thus defines a minimal transformation of the features of
to change the prediction. This transformation can either be set valued or individual valued. Here we will consider them to be functions on
for simplicity. We now define the transformations on
that counterfactuals induce.
Definition 4. Let be a set of variables designating values of dimensions I. A fixed transformation is a function such that for , if , then and differ only on values assigned to . We write to mean that and agree on the values assigned to . Given , and and where is a natural norm on , we shall be interested in the following types of transformations.
- (i)
is appropriate if where η and π are two incompatible predictions in Y.
- (ii)
is minimally appropriate if it is appropriate and in addition, such that and , .
- (iii)
is sufficiently appropriate if it is appropriate and in addition, for any , is not appropriate.
- (iv)
is sufficiently minimally appropriate if it is both sufficiently and minimally appropriate.
Note that when X is a space of Boolean features, then conditions (ii) and (iv) of Definition 4 trivially hold. Given a focal point in , minimally appropriate transformations represent the minimal changes necessary to the features of to bring about a change in the value predicted by .
Let and consider now a counterfactual language . Given a counterfactual model for with norm on , we say that is definable just in case for any worlds there is a formula of , which we call a separating formula, such that for all , and .
Proposition 1. Let and let be a counterfactual model for with an definable norm. Suppose also that . Then:
, where and ϕ is a separating formula that assigns values to variables for iff there is a minimally appropriate transformation such that , and .
Proposition 1 follows easily from Definitions 1, 2 and 4.
Proposition 1 is general and can apply to many different norms and languages. We will sometimes be concerned here with a special and simple case:
Corollary 1. Let be a propositional counterfactual language with a set P of propositional letters, where P is the set of Boolean valued features of , and let be a counterfactual model for with an norm. Then: , where and ψ is a conjunction of literals in P iff there is a minimally appropriate transformation over the dimensions I fixed by ψ such that , and .
We can generate minimally appropriate transformations via efficient (poly-time) techniques like optimal transport or diffeomorphic deformations [
5,
17,
18,
19,
20,
21] or techniques for computing adversarial perturbations [
9]. In effect all of these diverse methods yield counterfactuals or sets of counterfactuals given Proposition 1. A typical definition of an adversarial perturbation of an instance
x, given a classifier, is that it is a smallest change to
x such that the classification changes. Essentially, this is a counterfactual by a different name. Finding a closest possible world to
x such that the classification changes is, under the right choice of distance function, the same as finding the smallest change to
x to get the classifier to make a different prediction. Such minimal perturbations may not reflect the ground truth, the causal facts that our machine learning algorithm is supposed to capture with its predictions, as noted by [
38]. We deal with this in
Section 3.
Proposition 1 has two advantages. First it offers, as we shall see later, a way to define various counterfactual models defined with increasingly sophisticated transformations. Second, it marries efficient techniques to generate counterfactual explanations with the logical semantics of counterfactuals that provides logically valid (LV) explanations from counterfactual explanations, unlike heuristic, model-free methods [
2,
39]. Thus, counterfactual explanations build a bridge between logical rigor and computational feasibility.
Proposition 2. A counterfactual explanation given by a minimally appropriate in , with an definable norm and with finitely many values for each yields a minimal, LV explanation in at worst a linear number of calls to an NP oracle.
Proof sketch. Recall that each “world” or point of evaluation is encoded as a conjunction of literals
for some values
(the variables
representing features or dimensions of
). Together with the logical representation
of
, this suffices to reconstruct the atomic diagram of
[
40]. Further, given Corollary 1 and Definition 2, each minimally appropriate
defines a set of literals
describing
such that
. Refs. [
4,
29] provide an algorithm for finding a subset minimal set of literals
with
in a linear number relative to
of calls to an NP oracle [
41]. □
3. From Partial to More Complete Explanations
We have observed that counterfactual explanations are intuitively simpler than deductive ones, as they typically offer only a partial explanation. In fact there are three sorts of partiality in a counterfactual explanation. First, a counterfactual explanation is deductively incomplete; it doesn’t specify the ceteris paribus conditions and so doesn’t specify what is necessary for a proof of the prediction for a particular focal point. Second, counterfactual explanations are also partial in the sense that they don’t specify all the sufficient conditions that lead to ; they are hence globally incomplete. Finally, counterfactuals are partial in a third sense; they are also locally incomplete. To explain this sense, we need the notion of overdetermination.
Definition 5. A prediction by is overdetermined
for a focal point if the set of minimally sufficiently appropriate transformations of contains at least two elements. Locally incomplete explanations via counterfactuals can occur whenever ’s counterfactual decisions are over-determined for a given focal point. Many real world applications like our bank loan example will have this feature.
These different forms of partiality affect many heuristic forms of explanation and can lead to bad explanations or interpretations of ML systems. Refs. [
24,
42] show that heuristic counterfactual models like those proposed by [
1,
2,
6] often give unsound explanations for a classifier’s predictions. Moreover, heuristic approaches to explanation like Lime, Anchor and Shap provide explanations unmoored from their underpinnings in counterfactual semantics. Thus, the explanations they provide are naturally understood as simple premises of a deductive explanation The problem is, for such approaches we can find two focal points
and
such that the approaches return the same explanans
for the predictions
and
but
and
are incompatible. And this is unsound: in a sound explanation
cannot serve as an
explanans in a deductive explanation to both
and
.
Given our framework, it is not hard to see why these heuristic frameworks do this; they are in fact offering counterfactual explanations but without taking into account or making explicit the fact that counterfactual explanations assume that certain ceteris paribus conditions are assumed to hold. These ceteris paribus conditions make counterfactual explanations deductively incomplete, and so when using explanations to verify or to interpret a ML algorithm’s behavior, we have to take this partiality into account. Worse, these systems are sometimes interpreted as providing globally valid explanations, which ignores the second kind of incompleteness of counterfactual explanations. In the current framework on the other hand, Proposition 2 shows exactly how to get a deductively valid, global explanation from a counterfactual one, something which heuristic approaches to counterfactual explanations are not able to do.
Finally, locally incomplete explanations can, given a particular ML model , hide implicitly defined properties that show to be unacceptably biased in some way and so pose a problem for fair and adequate explanations. Local incompleteness allows for several explanatory counterfactuals with very different explanans to be simultaneously true. This means that even with an explanation, may act in ways unknown to the agent or the public that is biased or unfair. Worse, the constructor or owner of will be able to conceal this fact if the decision for is overdetermined, by offering counterfactual explanations using maps that don’t mention the biased feature.
Definition 6. A prejudicial factor P is a map, and exhibits a biased dependency
on prejudicial factor P just in case for some , , and for some incompatible predictions η and π, Dimensions of the feature space that are atomic formulas in can provide examples of a prejudicial factor P. But prejudical factors P may be also implicitly definable in a counterfactual model . Assume that is a map from real individuals x to their representation as data points . Recall that each point is uniquely identified by a formula for some values . Then:
Definition 7. Some exogenous property P is implicitly definable just in case for all x such that , iff for some boolean combination of atomic formulas, χ, .
All in all, our analysis shows why forms of counterfactual explanations that do not take into account the logical underpinnings of a counterfactual framework will give flawed results.
We’ve just described some pitfalls of locally incomplete counterfactual explanations. Thanks to Proposition 1, however, our logic based and statistical counterfactual framework shows how to move from a partial picture of the behavior of to a more complete one using counterfactuals. Again this is a feature that heuristic approaches but also deductive logical approaches do not have. Imagine that at a focal point , and we want to know why not .
Definition 8. In a counterfactual model with a set of Boolean valued features P, the collection of counterfactuals with ϕ a Boolean combination of values for atoms in true at gives the complete explanation for why π would have occurred at .
Appropriate transformations on in a counterfactual model to produce associated with counterfactuals via Proposition 1 can capture and permit us to plot the local complete explanation of around a focal point with regard to prediction .
Definition 9. is a minimal appropriate transformation for some
Proposition 3. In a counterfactual model ,
We now fix a counterfactual model to simplify notation.
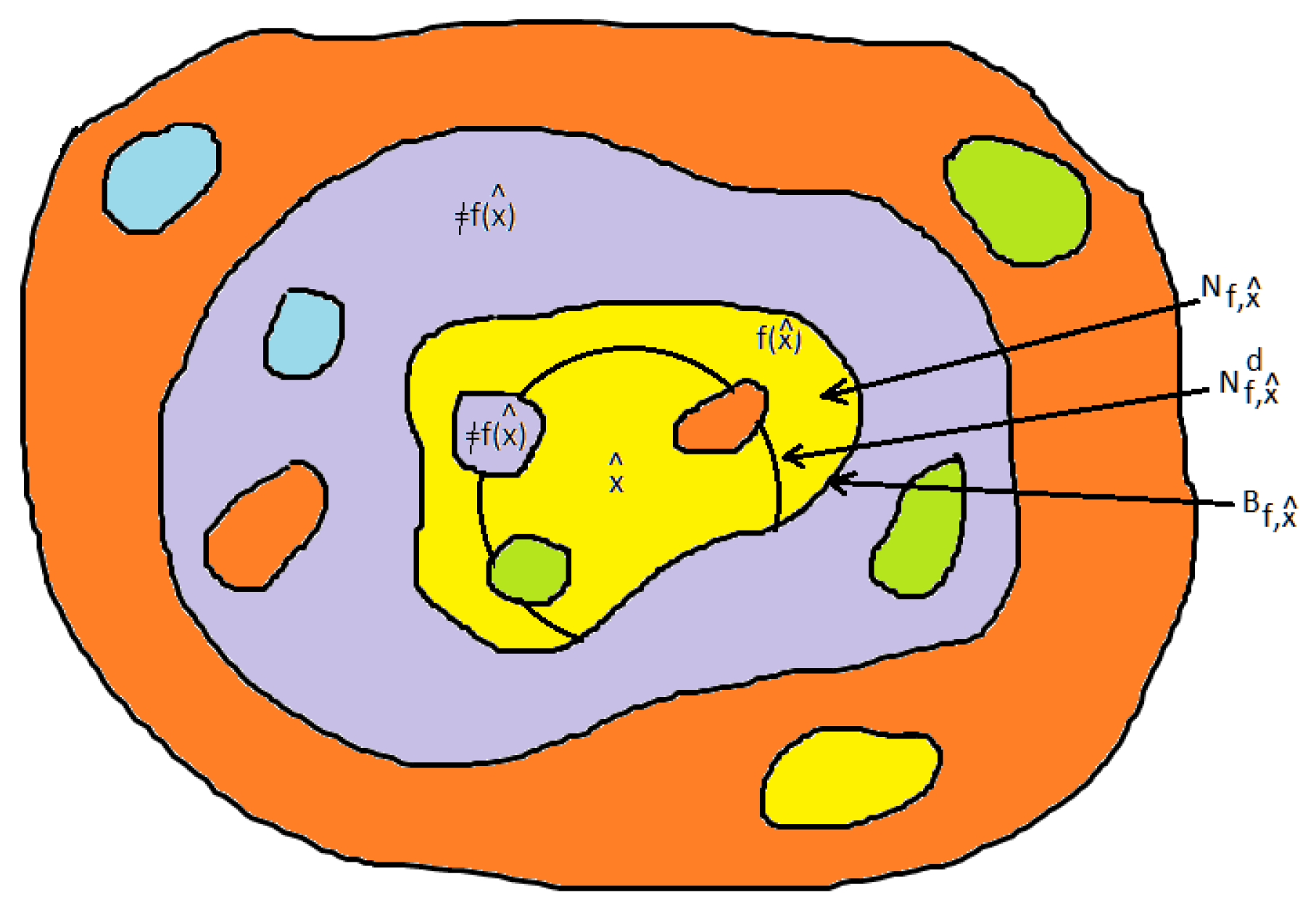
We are interested in the neighborhood or “similarity” space around with boundary and the targeted outcome space verifying the consequent of counterfactuals in .
Definition 10. - 1.
is the subspace of such that (i) and (ii) includes in its interior all those points z for which and (iii) the boundary of is given by .
- 2.
is a subspace of with boundary , where , where
- 3.
The set
can have a complex or “gappy” structure in virtue of the presence of
ceteris paribus assumptions. Because strengthening of the antecedent fails in semantics for counterfactuals, the counterfactuals in (4) relevant to our example of
Section 2 are all satisfiable at a world without forcing the antecedents of (4)b or (4)c to be inconsistent:
- (4)
- a.
If I were making €100 K euro, I would have gotten the loan.
- b.
If I were making €100 K or more but were convicted of a serious financial fraud, I would not get the loan.
- c.
If I were making €100 K or more and were convicted of a serious financial fraud but then the conviction was overturned and I was awarded a medal, I would get the loan.
The closest worlds in which I make €100 K do not include a world
w in which I make €100 K but am also convicted of fraud. Counterfactuals share this property with other conditionals that have been studied in nonmonotonic reasoning [
43,
44]. However, if the actual world turns out to be like
w, then by weak centering (4)a turns out to be false, because the
ceteris paribus assumption in (4)a is that the actual world is one in which I’m not convicted of fraud.
Figure 1 provides a visual rendering of
(in purple) and related concepts.
Given we can count how many times the value of the consequent changes of flips as we move from one antecedent to a logically more specific one; e.g., does the prediction flip from A to or from to ? For generality, we will also include in the number of flips, the flips that happen when we change the Boolean value of a feature—going from A to for example. We will call the number of flips the flip degree of , as well as of .
There is an important connection between the flip degree of and the geometry of . In a counterfactual model, the move from one antecedent of a counterfactual a to logically more specific antecedent of , with will, given certain assumptions about the underlying norm yield , with y being a closest to point verifying and z a closest point verifying . In fact we generalize this property of norms.
Definition 11. A norm in a counterfactual model respects the logical specificity of the model iff for any such that and for counterfactual antecedents describing features of such that such that and , there are collinear such that for each i, is a closest point to z such that and .
Remark 1. An L1 norm for a counterfactual model is a logical specificity respecting norm.
In addition, a flip (move from a point verifying to a point verifying corresponds to a move from a transformation to a transformation with . Thus, flips determine a partial ordering under ⊆ over the shifted dimensions i: thus , if . We are interested in the behavior of with respect to the partial ordering on .
Definition 12. is nearly constant around , if for every sufficiently minimally appropriate for all , .
A nearly constant changes values only once for each combination of features/dimensions moving out from a focal point . So at some distance d, nearly constant becomes constant . For a nearly constant around , , has flip degree 1. A complete local explanation for ’s prediction of within d, , is a global explanation ’s behavior with respect to .
We can generalize this notion to define an n-shifting . If flips values n times moving out from , has flip degree n.
Remark 2. If , has flip degree 1, then a counterfactual explanation of ’s behavior with respect to π is also a formally valid, abductive explanation.
Corollary 2. Let be any ML algorithm that is nearly constant around and with an associated for which there is a polynomial procedure for finding a suitable minimal . Then we can find an abductive explanation for ’s behavior at in polynomial time.
Proposition 4. Suppose A counterfactual model has a logical specificity respecting norm, then: , has a flip degree iff forms a convex subspace of .
Proof sketch. Assume has flip degree . Then will contain counterfactuals with antecedents , , such that but, say, and counterfactually support but not . As the underlying norm respects ⊧, there are collinear points x, y, and z, where x is a closest point to where is true, y is a closest world, and z is a closest world such that . But , while and , which makes non convex. Conversely, suppose is non convex. Using the construction of counterfactuals from the boundary of will yield a set with flip degree 3 or higher. □
The flip degree of
gives a measure of the degree of non-convexity of
, and a measure of the complexity of an explanation of
’s behavior. A low flip degree for
with minimal overdeterminations provides a more general and comprehensive explanation. With Proposition 4, a low flip degree converts a local complete explanation into a global explanation, which is
a priori preferable. It is also arguably closer to our prior beliefs about basic causal processes. The size of
gives us a measure to evaluate
itself; a large
doesn’t approximate very well a good scientific theory or the causal structures postulated by science. Such a
lacks generality; it has neither captured the sufficient nor the necessary conditions for its predictions in a clear way. This could be due to a bad choice of features determining
’s input
[
20]; too low level or unintuitive features could lead to lack of generality with high flip degrees and numerous overdeterminations. Thus, we can use
to evaluate
and its input representation
.
Can we exploit flip degrees to have bounds on the confidence of our explanations? Yes, perhaps we can. Let us suppose that exogenously given to us is a probability distribution over the features of samples in . We could calculate this distribution relative to itself. Let us suppose we have calculated joint probability distributions for all of the antecedents of conditionals in , where is the antecedent for the counterfactual that gives flip number i.
Proposition 5. Suppose that the flip degree of but that , for . Then that furnishes a formally valid, abductive explanation.
The flip degree of
and the topology of
can also tell us about the relation between counterfactual explanations based on some element in
X and ground truth instances provided during training. Our learning algorithm
is trying to approximate or learn some phenomenon, which we can represent as a function
; the observed pairs
are ground truth points for
. Ideally,
should fit and converge to
f—i.e., with the number of data points
N is trained on
; in the limit explanations of the behavior of
will explain
f, the phenomenon we want to understand. Given that we generate counterfactual situations using techniques used to find adversarial examples, however, counterfactual explanations may also be based on adversarial examples that have little to no intuitive connection with the ground truth instances
was trained on. While these can serve to explain the behavior of
and as such can be valuable, they typically aren’t good explanations of the phenomenon
f that
is trying to model. Ref. [
38] seek to isolate good explanations of
f from the behavior of
and propose a criterion of topological connectedness for good counterfactual explanations. This idea readily be implemented as a constraint on
: roughly,
as an approximation of
f will yield good counterfactual explanations relative to a focal point
only if for any point
y outside of
, there is a region
C where
returns the same value and a path of points
between
y and a ground truth data point
p such that
. (We note that our discussion and constraint make clear the distinction between
f and
which is implicit in [
13,
38]).
4. Pragmatic Constraints on Explanations
While we have clarified the partiality of counterfactual explanations, AI applications can encode data via hundreds even thousands of features. Even for our simple running example of a bank loan program, the number of parameters might provide a substantial set of counterfactuals in the complete local explanation given by . This complete local explanation might very well involve too many counterfactuals for humans to grasp. We still to understand what counterfactual explanations are pragmatically relevant in a given case.
Pragmatic relevance relies on two observations. First, once we move out a certain distance from the focal point, then the counterfactual shifts intuitively cease to be about the focal point; they cease to be counterparts of
and become a different case. Exactly what that distance is, however, will depend on a variety of factors about the explainee
and what the explainer believes about
. Second, appropriate explanations must respond to the particular
conundrum or cognitive problem that led
to ask for the explanation [
10,
11,
12]. On our view, the explainee
requires an explanation when her beliefs do not lead her to expect the observed prediction
. When
’s beliefs suffice to predict
, she has
a priori an answer to the question
Why did ? In our bank example from
Section 2, had
’s beliefs been such that she did not expect a loan from the bank, she wouldn’t have needed to ask,
why did the bank not give me a loan? Of course,
might want to know whether her beliefs matched the bank’s reasons for denying her a loan, but that’s a different question—and in particular it’s not a
why question).
The conundrum comes from a mismatch between ’s understanding of what was supposed to model (our function f) and ’s actual predictions. So , in requesting an explanation of ’s behavior, might also want an explanation of f itself (see the previous section for a discussion). Either is mistaken about the nature of , or her grasp of is incomplete ( could also be mistaken about or have an incomplete grasp of f; she might also be mistaken about how differs from f. But we will not pursue this here). More often than not, will have certain preconceptions about , and then many if not most of the counterfactuals in may be irrelevant to . A relevant or fair and adequate explanation for should provide a set of appropriate with showing which of ’s assumptions were faulty or incomplete, thus solving her conundrum.
Suppose that the explainee requests an explanation why , and that is decomposed into .
- CI
Suppose ’s conundrum based on incompleteness; i.e., the conundrum arises from the fact that for only pays attention to the values of dimensions in the sense that for her , for any values . Then there is a such that and while
- CM
Suppose ’s conundrum is based on a mistake. Then there is a such that such that . I.e., must resolve ’s conundrum by providing the values for the dimensions of on which is mistaken.
A fair and adequate explanation must not only contain counterfactuals that resolve the explainee’s conundrum. It must make clear the biases of the system which may account for 0’s incomplete understanding of ; it must lay bare any prejudicial factors P that affect the explainee and thus in effect all overdetermining factors as in Definition 5. An explainee might reasonably want to know whether such biases resulted in a prediction concerning her. E.g., the explanation in (3) might satisfy CM or CI, but still be misleading. Thus:
- CB
∀ prejudicial factors P, there is a such that and . In our bank loan example, if the bank is constrained to provide an explanation obeying CB, then it must provide an explanation according to which being white and having ’s salary would have sufficed to get the loan.
Definition 13. A set of counterfactuals provides a fair and adequate explanation of for at just in case they together satisfy CM, CI and CB within a certain distance d of .
The counterfactuals in jointly provide a fair and adequate explanation of for , though individually they may not satisfy all of the constraints. We investigate how hard it is to find an adequate local explanation in the next section.
5. The Algorithmic Complexity of Finding Fair and Adequate Explanations
In this section, we examine the computational complexity of finding a fair and adequate explanation. To find an appropriate explanation, we imagine a game played, say, between the bank and the would-be loan taker
in our example from
Section 2, in which
can ask questions of the bank (or owner/developer of the algorithm) about the algorithm’s decisions. We propose to use a two player game, an
explanation game to get appropriate explanations for the explainee.
The pragmatic nature of explanations already motivates the use of a game theoretic framework. We have argued fair and adequate explanations must obey pragmatic constraints; and in order to satisfy these in a cooperative game the explainer must understand explainee
’s conundrum and respond so as to resolve it. Providing an explanation is a pragmatic act that takes into account an explainee’s cognitive state and the conundrum it engenders for the particular fact that needs explaining. A cooperative explainer will provide an explanation in terms of the type he assigns to
, as the type will encode the relevant portions of
’s cognitive state. On the other hand the explainee will need to interpret the putative explanation in light of her model of the explainer’s view of his type. Thus, both explainer and explainee naturally have strategies that exploit information about the other. Signaling games [
45] are a well-understood and natural formal framework in which to explore the interactions between explainer and explainee; the game theoretic machinery we develop below can be easily adapted into a signaling game between explainer and explainee where explanations succeed when their strategies coordinate on the same outcome.
Rather than develop signaling games however for coordinating on successful explanations, we look at non-cooperative scenarios where the explainer may attempt to hide a good explanation. For instance, the bank in our running example might have encoded directly or indirectly biases into its loan program that are prejudicial to , and it might not want to expose these biases. The games below provide a formal account of the difficulty our explainee has in finding a winning strategy in such a setting.
To define an explanation game, we first fix a set of two players .
The moves or actions for explainee are: playing an ACCEPT move—in which accepts a proposed if it partially solves her conundrum; playing an N-REQUEST move—i.e., requesting a where j differs from all i such that has been proposed by in prior play; playing a P-REQUEST move—i.e., for some particular i, requesting . may also play a CHALLENGE move, in which claims that a set of features of the focal point that entails in the counterfactual model associated with . We distinguish three types of ME explanation games for based on the types of moves she is allowed: the Forcing ME explanation games, in which may play ACCEPT, N-REQUEST, P-REQUEST; the more restrictive Restriction ME explanation games, in which may only play ACCEPT, N-REQUEST; and finally Challenge ME explanation games in which CHALLENGE moves are allowed.
Adversary ’s moves consists of the following: producing and computing in response to N-REQUEST or P-REQUEST by ; if is a forcing game, must play at move m in , if has played P-REQUEST at . In reacting to a N-REQUEST, player may offer any new ; if he is noncooperative, he will offer a new that is not relevant to ’s conundrum, unless he has no other choice. On the other hand, must react to a CHALLENGE move by by playing a that either completes or corrects the Challenge assumption. A CHALLENGE demands a cooperative response; and since it can involve any implicitly definable prejudicial factor as in Definition 5, it can also establish CB, as well as remedy CI or CM.
5.1. Generic Explanation Games
We now specify a win-lose, generic explanation game.
Definition 14. An Explanation game , , concerning a polynomially computable function , where is a space of boolean valued features for the data and Y a set of predictions, is a tuple where:
- i.
resolves ’s conundrum and obeys CB.
- ii.
is the starting position, d is the antecedently fixed distance parameter.
- iii.
, but not has access to the behavior of and a fortiori .
- iv.
opens with a REQUEST or CHALLENGE move
- v.
responds to ’s requests by playing some .
- vi.
may either play ACCEPT, in which case the game ends or again play a REQUEST or CHALLENGE move.
- vii.
is the set of plays ρ that contain the sufficient to resolve (resolve ’s conundra)
The game terminates when (a) has resolved or gives up.
always has a winning strategy in an explanation game. The real question is how quickly can compute her winning condition. An answer depends on what moves we allow for in the Explanation game; we can restrict to playing a Restriction explanation game, a Forcing game or a Forcing game with CHALLENGE moves.
Proposition 6. Suppose is a forcing explanation game. Then the computation of ’s winning strategy in is Polynomial Local Search complete (PLS) [46,47]. On the other hand if is only a Restriction game, then the worst case complexity for finding her strategy is exponential. Proof sketch. Finding
is a search problem using
.
is finite with, say,
m elements. These elements need not be unique; they just need jointly to solve the conundrum. This search problem is PLS just in case every solution element is polynomially bounded in the size of the input instance,
is poly-time, the cost of the solution is poly-time and it is possible to find the neighbors of any solution in poly-time. Let
be the input instance. By assumption,
is polynomial; and given the bound
d, the solutions
y for
and
are polynomially bounded in the size of the description of
. Now, finding a point
that solves at least part of
’s conundrum, as well as finding neighbors of
y is poly-time, since
can use P-REQUEST moves to direct the search. To determine the cost
c of finding
for
in poly-time: we set for
the
jth element of
computed as
; if
,
. Finding
thus involves determining
m local minima and is PLS. In addition, determining
encodes the PLS complete problem FLIP [
46]: the solutions
y in
have the same edit distance as the solutions in FLIP,
encodes a starting position, and our cost function can be recoded over the values of the Boolean features defining
y to encode the cost function of FLIP and the function that compares solutions in FLIP is also needed and constructible in
. So finding
is PLS complete in
as it encodes FLIP.
The fact that forcing explanation games are PLS complete makes getting an appropriate explanation computationally difficult. Worse, if is a Restriction Explanation game, then can force to enumerate all possible within radius d of to find . □
Proposition 7. Suppose is a Challenge explanation game. Then has a winning strategy in that is linear time computable, provided ’s values are already known.
Proof sketch. must respond to ’s CHALLENGE moves by correcting or completing ’s proposed list of features. can determine in a number of moves that is linear in the size of . □
A Challenge explanation game mimics a coordination game where has perfect information about , because it forces cooperativity and coordination on the part of . Suppose in our bank example claims that her salary should be sufficient for a loan. In response to the challenge, the bank could claim the salary is not sufficient; but that’s not true—the salary is sufficient provided other conditions hold. That is, ’s conundrum is an instance of CI. Because of the constraint on CHALLENGE answers by the opponent, the bank must complete the missing element: if you were white with a salary of €50 K, … Proposition 7 shows that when investigating an in a challenge game, exploiting a conundrum is a highly efficient strategy. Of course we’re here not counting the fact that computing takes polynomial time since we have assumed that computing is poly time.
The flip degree of and the number of overdetermining factors (Definition 5) typically affect the size of and thus the complexity of the conundrum and search for fair and adequate explanations and their logical valid associates. More particularly, when and the cost of the prediction is as in the proof of Proposition 6, ’s conundrum and the explanations resolving it may require n local minima. When the flip degree of is m, may need to compute m local minima.
To develop practical algorithms for fair and adequate explanations for AI systems, we need to isolate
’s conundrum. This will enable us to exploit the efficiencies of Challenge explanation games. Extending the framework to discover
’s conundrum behind her request for an explanation is something we plan to do using epistemic games from [
48] with more developed linguistic moves. In a more restricted setting where Challenge games are not available, our game framework shows that clever search algorithms and heuristics for PLS problems will be essential to providing users with relevant, and provably fair and adequate counterfactual explanations. This is something current techniques like enumeration or finding closest counterparts, which may not be relevant [
4,
29,
37]—do not do.
5.2. Exploring Counterfactual Models with Explanation Games
Explanation games can be used also to discover facts about
and about the explanatory generalizability of an explanation for a prediction of
at a particular focal point. For instance, a Forcing game can be used to establish a degree of robustness of
around a focal point, in the sense that we can compute a radius
d and a ball
around
such that
. In such a case we can say that
has a local Lipschitz robustness of degree 0 in a ball of radius
d around
, since for any points
in
. By calculating
d, we can establish the robustness also of our counterfactual explanation at
in the sense of [
49]. The techniques used Proposition 6 can also be used to establish the extent of
. In addition, techniques to generate adversarial examples can help us determine perhaps more efficiently the radius of
.
Another use for the sort of games we have introduced in this section is to find confounders. Consider our loan example in which is robust with respect to changes on a particular variable for race ( if is a disfavored minority and is 1 otherwise); that is, where and differ only on values for dimension i. But in fact varies on variables for diet ( if diet is that of a disfavored minority) and home address ( if home address is in an affluent neighborhood, 0 otherwise). It turns out that there is a very strong correlation between and ; an overwhelming number of disfavored minority class members represented in are such that their theories entail . While the bank might claim that its algorithm is racially insensitive by cherry-picking certain cases—namely those individuals y for which their theories are such that and , in either a Challenge or forcing Explanation game will be able to establish an implicit and unfair bias in by continuing to ask for predictions on individuals for whom . This is even possible if race is not explicitly represented as a dimension in , as long as it is implicitly definable in the model. Note that this procedure to find confounders is also useful for showing whether is biased for or against a particular group.
To formalize this search for confounders, we tweak the notion of an explanation game to define an explanation investigation game. We do not need to rely on Boolean features for the data; they can even be continuously valued.
Definition 15. An explanation investigation game , , concerning a polynomially computable function , is a tuple where:
- i.
Suppose for some values , implicitly defines in a subset P of individuals where .
- ii.
has access to the implicit definition of ϕ in
- iii.
, but not has access to the behavior of .
- iv.
wins if she discovers a pair in (i); i.e., a play iff it ends with an for some such that where and .
- v.
opens with a REQUEST move concerning some
- vi.
responds to ’s requests by playing some that applies to .
Remark 3. Let be a forcing explanation investigation game where for and . Then has a winning strategy in in polynomial time.
We can strengthen Remark 3 by considering a stronger winning condition: suppose
P is finite and
is to find a sufficiently large sample of
pairs. In this case, if the assumptions of Remark 3 are met,
also has a winning strategy in
with
calls to
. If
is large or if
is not sufficiently representative, then this strategy may not be feasible to establish the presence of confounders or their absence. We need more information from the counterfactual model to do this. In
Section 7, we will see an example of a counterfactual model that can help us.
More generally, a forcing explanation investigation game can detect dependencies between features that may have gone unnoticed by the designers of . Just as we can find implicit equivalences between Boolean combinations of feature value assignments and other properties, so too will an explanation investigation game be able to detect equivalences between two Boolean combinations of feature value assignments, incompatibilities or independence. We can establish these relations either relative to some finite set or globally relative to all points in by moving from the counterfactual model to the proof theory that encodes and the input data.
6. Generalizing towards More Sophisticated Counterfactual Models
While much of our exploration has been general, some results, in particular those of the previous section, have relied on a particularly simple notion of norm or distance to define counterfactual counterparts. In the remainder of the paper, we want to look at other ways of defining more sophisticated counterfactual models. We look at three different ways to generalize the simple models above: generalizing from very simple norms, adding indeterminism, adding randomness, and providing counterfactual correlates that take account of dependencies and distributions. We then look at two types of counterfactual models, one based on causal graphs and another based on transport theories. We argue that transport based counterfactual models should provide very relevant explanations of an algorithm’s behavior.
6.1. Moving from an L1 Norm to More Sophisticated Ways of Determining Counterfactual Correlates
Specifying a norm for our space of data
is crucial for building a counterfactual model and specifying counterfactual correlates. But when we have specified a norm, it has been a very simple one that assumes that each dimension of
is orthogonal and has a Boolean set of values; in this case,
has a natural
norm or Manhattan or edit distance [
35]. But for this choice of norm to make sense we must assume that the dimensions of
are all independent, and this assumption is not only manifestly false for typical instances of learning algorithms but also gives very unintuitive results in concrete cases [
50].
For example, consider a set of data with dimensions for sex, weight and height; and now consider the counterfactual assumption Nicholas is a woman. Assume that Nicholas is slightly over average in weight and about average in height for men. But now consider his counterfactual counterfactual female counterpart with the same weight and height as the actual Nicholas. This counterpart would be an outlier in the distribution of females over those dimensions, thus making the following counterfactual true. ex. If Nicholas were a woman, she would be unusually heavy and unusually tall.
Intuitions differ here, but most people find such counterfactuals rather odd, if not false. Much more acceptable would be a counterfactual where we explicitly restrict the counterfactual counterpart to have exactly all of Nicholas’s current properties. ex. If Nicholas were a woman and she had the same height and weight as Nicholas actually does, she would be unusually heavy and unusually tall.
If one shares these intuitions, then it appears that we need to reframe a counterfactual model in terms of a more sophisticated notion of counterfactual correlate. What we want is a notion of counterfactual correlate where the dependencies between features are taken into account.
6.2. Adding Indeterminism
Given Proposition 1, we can rewrite a counterfactual model in terms of a set of minimal appropriate transformations and exploit this in the semantics of counterfactuals:
Definition 16. Counterfactual semantics with transformations:
be a counterfactual model with transformations that extends a standard counterfactual model for with with a set of minimal adequate transformations for each set of variables .
Let ψ define a set of values for variables . Then just in case: The transformations now define the relevant counterfactual counterparts directly for the semantics. Note that each standard counterfactual model obviously extends to a counterfactual model with transformations in view of Proposition 1.
Another restriction in the work in the previous sections is that our transformations so far have been single valued functions. That is, if any element in xX has a counterfactual element, it is unique. This forces our models to verify conditional excluded middle, which could be unintuitive.
Definition 17. Conditional Excluded Middle:
Consider, for example, the intervention on my salary where I make €100 K per year instead of €60 K. Such an intervention does not determine all of my properties. In a counterfactual situation where I make €100 K instead of €60 K, I might still have the same bicycle that I go to work on. Or I might not. There doesn’t seem to be a set answer to the question,
- (5)
Were Nicholas to make €100 K per year, would he still use the same bicycle he does now to go to work?
But with conditional excluded middle, a counterfactual model must support one of
- (6)
- (a.)
Were Nicholas to make €100 K per year, he would use the same bicycle he does now to go to work.
- (b.)
Were Nicholas to make €100 K per year, he not would use the same bicycle he does now to go to work.
A counterfactual asks us to entertain a situtation different from the current one. In semantic terms, the antecedent of a counterfactual introduces an “intervention” into the actual circumstance of evaluation that shifts us away from that circumstance to a different one in which the antecedent is true, thereby defining a counterfactual correlate. Our argument of the previous paragraph indicates that such an intervention does not determine every property of the correlate.
We can remedy this defect of our semantics by lifting our transformations to set valued functions. i.e.,
Definition 18. Let . A set valued fixed transformation is a function , where is the powerset operation, such that for and , if , then x and y differ in the dimensions i. Given , and and where is a natural norm on ,
- (i)
is appropriate if with and π incompatible predictions in Y.
- (ii)
is minimally appropriate if it is appropriate and,
and , .
With set valued transformations, we can build counterfactual models as before. The difference now is that conditional excluded middle is no longer valid.
Definition 19. Let ψ define a set of values for a set of variables and let be a counterfactual model with a set D of minimal appropriate set valued transformations . just in case: 6.3. Introducing Randomness and Probabilities
Using set valued transformations has introduced indeterminism into our counterfactual models. With indeterminism, not every intervention described by the antecedent of a counterfactual yields a unique outcome. In fact, this sort of indeterminism is a feature of Lewisian counterfactuals [
16], where counterfactual correlates may or may not have certain properties. Once such indeterminism is introduced, however, it is also natural to take the counterfactual correlates as more or less likely to have those properties. That is, it is natural to add to our indeterministic picture a notion of probability, a probability distribution over the properties that counterfactual correlates may exhibit.
Consider again the intervention on my salary where I make €100 K instead of €60 K euros. Such an intervention we’ve argued does not determine all of my properties. In a counterfactual situation where I make €100 K instead of €60 K, I might still have the same bicycle that I go to work on. Or I might not. That is, the counterfactuals in (6) repeated below are plausibly both false.
- (7)
- a.
Were Nicholas to make €100 K euros per year, he would use the same bicycle he does now to go to work.
- b.
Were Nicholas to make €100 K euros per year, he not would use the same bicycle he does now to go to work.
On the other hand, a probabilistic statement like
- (8)
Were Nicholas to make €100 K euros per year, there is a 70% chance that he would use the same bicycle he does now to go to work.
is plausible. We find this addition to the semantics of counterfactuals very appealing. Adding probabilities to the logic of counterfactuals, however, takes us far beyond the framework of Lewis’s semantics for counterfactuals. Ref. [
51] argues that a logical semantics for languages with probabilities comes in two types, because probabilities can be used to represent two different kinds of information as [
51,
52,
53] have argued. One sort of information has to do with degrees of belief; that is, to what degree, for instance, does Nicholas believe that he will use his bicycle to go to work? We can represent following [
53] this degree of belief as a probability measure of sets of possible worlds; on a very basic level, my degree of belief is a function of the size of the set of worlds in which I take my bicycle to work among all my doxastic counterparts (worlds compatible with my beliefs).
The other sort of information has to do with probabilistic quantifiers like 90% of the schools as in
- (9)
90% of the schools are closed due to Covid.
This is a statement about the actual world according to [
52]. It doesn’t have to do with anyone’s degree of belief. It requires a probabilistic quantifier to be properly expressed. Refs. [
51,
54] provide complexity results for a first order logic of probability with both sorts of probability measures. In general such logics are not even axiomatizable when the consequence relation we have mind takes into account something like a domain characterized by the theory of real closed fields. In finite domains of fixed size, such logics remain axiomatizable and decidable, as one would expect, and in the case of propositional logics with probability measures, we also have axiomatizability and decidability. Ref. [
51] argues that these two notions of probability should be kept distinct; degrees of belief go with probability measures over worlds or points of evaluation, while statistical information about our world has to do with a distribution over events or individuals in the actual world. But does this ring true for our set up? Our “worlds”
w are not doxastic or epistemic alternatives in the standard sense. They function like assignments and they are characterized as types in the logical sense. Hence intuitively they represent types of individuals; e.g., the instance
w characterize individuals that are characterized by the feature value pairs in the conjunction
. If we assume that
is finite, it is hence natural to assign to each one of these “individuals” in
a probability and a discrete probability measure over all of
. In the case when
has the cardinality of the reals, we will define probabilities around neighborhoods of
. We shall assume
henceforth.
Departing from the semantics of [
51,
52], we will remain with a quantifier free language. How do we use probability statements? It seems that they are operators similar to modal operators. Consider the following:
- (10)
- a.
Necessarily
- b.
Possibly
- c.
Probably
Where could be a formula describing a particular data point or any set of data points. For instance the set of females in could be represented just by the formula where g is the dimension of gender. That is the set of females in the model are just those instances that satisfy . Each such set should receive a probability measure.
This observation tells us in effect how to render a counterfactual logic distribution aware. Given a counterfactual language , we add sentential operators for . are formulas where is an formula. Call this language We may also want to talk about the probability of a randomly chosen ’s being a woman? One option is to introduce quantifiers like Bacchus that range over elements of . But this makes our language more complex by introducing variables for our points of evaluation into our language. Alternatively, we can evaluate formulas over subsets of not just elements, For instance, consider the formula . We can evaluate over sets of assignments S to get the probability that a random x from S is a woman given that x is in S. When , we just have the probability of some x’s being a woman in the model.
To this end, we modify our notion of a counterfactual model. To a counterfactual model we add
a countably additive measure P over the modal free definable subsets D of , with , . P is then a probability measure. Recall that in our framework each element in is defined by a conjunction of literals of . Thus, every element has a probability.
iff
We remark that all
definable sets are measurable sets. Relative to our background probability measure
P, we define for formulas
of
the conditional distribution for worlds and finite sets
For a probabilistic counterfactual language ,we add to the clauses below. Note that we both supply a truth value and a probability to the consequents of counterfactuals. We note that the counterfactual here has a “dynamic” flavor in that the consequent is evaluated relative to worlds that are modified from the input set via an update mechanism given by the antecedent of the counterfactual. This will be particularly pertinent for evaluating the probabilities of consequents of counterfactuals.
Definition 20. Let be a counterfactual model with transformations and let , and let Let be free formulas and ψ define a set of values for a set of variables
- 1.
iff
- 2.
iff
- 3.
- 4.
iff
- 5.
just in case: - 6.
just in case: - 7.
just in case: - 8.
just in case:
We have defined both truth at an evaluation point in and sets of evaluation points and probabilities at both single points and sets of evaluation points. For computing probabilities of simple sentences, we have simply exploited our assumption of a discrete measure over a finite set of possibilities in . For counterfactuals, we have in addition exploited the internally dynamic aspect of these operators by looking at measures on sets that have been shifted away from the original point of evaluation by the counterfactual operation.
What about computing probabilities for consequents of counterfactuals—formulas of the form ? To evaluate the truth of such a formula at w, we first exploit clause 6, and so we have . By clause 4, this holds iff , which is equivalent to .


{kind=link}
{kind=link}

