

Painting the Black Box White: Experimental Findings from Applying XAI to an ECG Reading Setting

 ,
,  , , and
, , and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
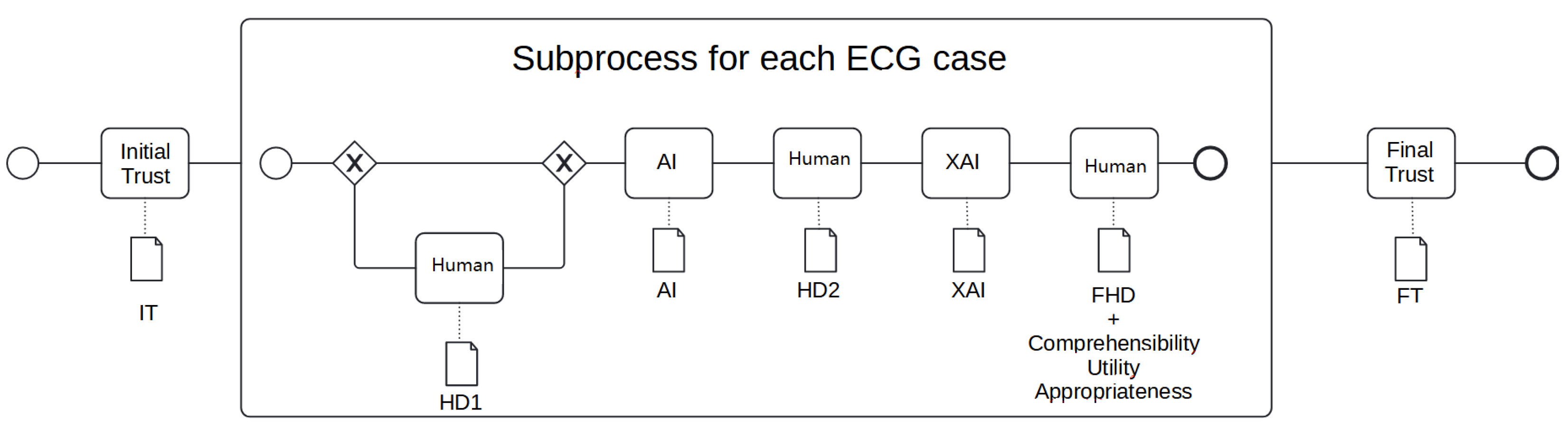
2. Methods
- (RQ1):
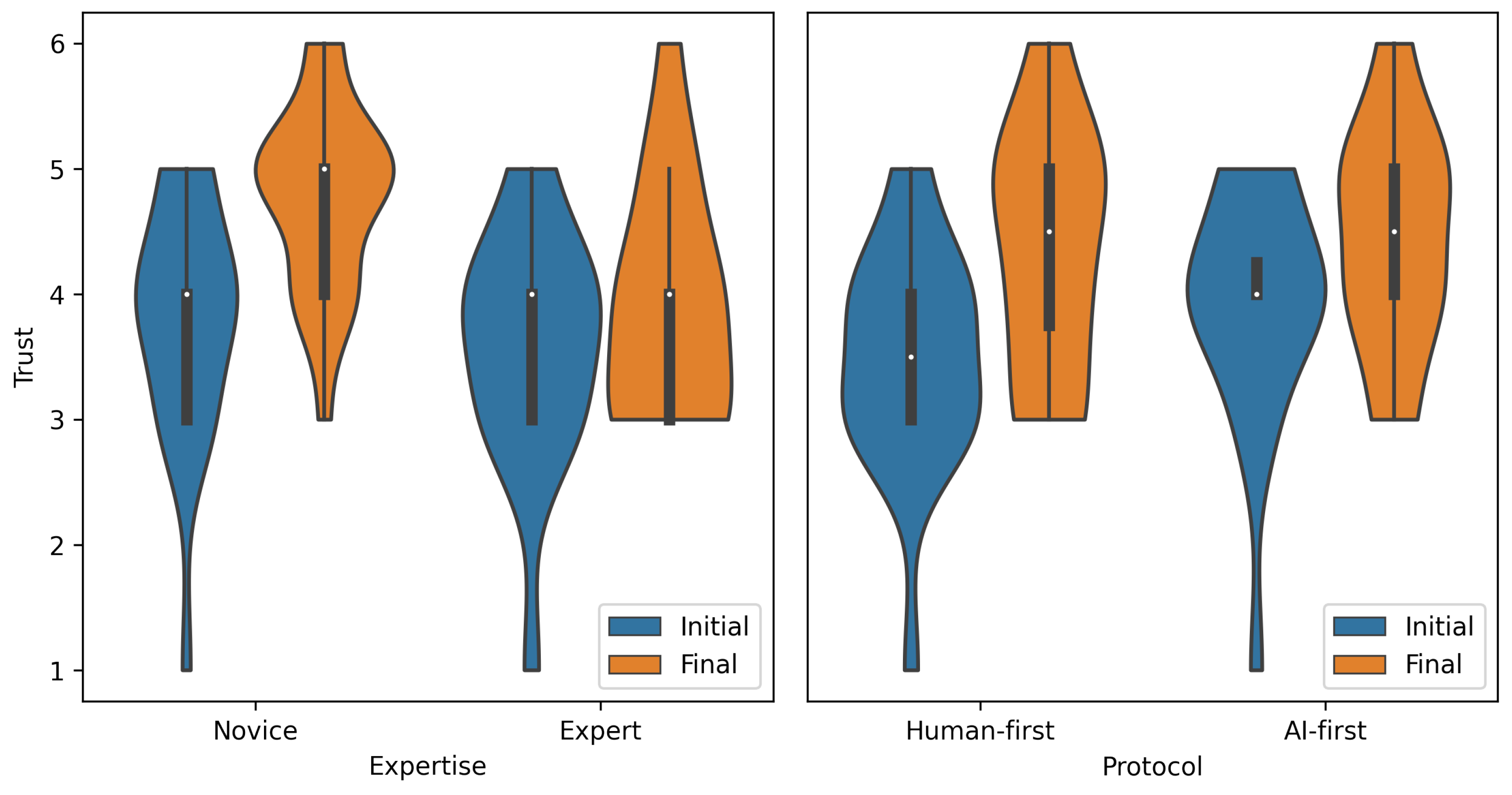
- Does the readers’ expertise have any effect in terms of either basal trust, difference in trust by the readers, or final trust (RQ1a)? Does the interaction protocol (human-first vs. AI-first) have any effect on differences in trust by the readers, or final trust (RQ1b)?
- (RQ2):
- Is there any difference or correlation between the three investigated psychometric dimensions (i.e., comprehensibility, appropriateness, utility)? A positive answer to this latter question would justify the use of a latent quality construct (defined as the average of the psychometric dimensions) to simplify the treatment of other research questions.
- (RQ3):
- Does the readers’ expertise, diagnostic ability (i.e., accuracy), and the adopted interaction protocol have any effect in terms of differences in perceived explanations’ quality? Similarly, does the perceived quality of explanations correlate with the basal or final trust? Regarding diagnostic ability, we stratified readers based on whether their baseline accuracy (cf. HD1, see Figure 2) was either higher or lower than the median.
- (RQ14):
- Is there any correlation between the explanations’ perceived quality and the readers’ susceptibility to technology dominance [39,40]? Although technological dominance is a multifactorial concept, for our practical aims, we express it in terms of the rate of decision change due to exposition to the output of an AI system. Moreover, we distinguished between positive dominance, when changes occur from initial wrong decisions (e.g., diagnoses) to eventually correct ones and negative dominance, for the dual case, when the AI support misleads decision makers.
- (RQ5):
- Finally, does the correctness of the explanation (and of the associated classification) make any difference in terms of either perceived explanations’ quality or influence (i.e., dominance)?
3. Results and Discussion
3.1. RQ1—Effect of Expertise and Interaction Protocol on Trust
3.2. RQ2—Correlation between the Psychometric Dimensions
3.3. RQ3—Perceived Explanations’ Quality with Respect to Expertise, Accuracy, Interaction Protocol, and Possible Correlation with Basal or Final Trust
3.4. RQ4—Correlation between Perceived Quality of Explanation and Technology Dominance
3.5. RQ5—Relationship between the Correctness of Explanations and Dominance
3.6. Limitations and Further Research
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADM | Automated Decision Making |
| BPMN | Business Process Model and Notation (i.e., the OMG standard on process modelling) |
| AI | Artificial Intelligence |
| ECG | ElectroCardioGram |
| EU | European Union |
| FHD | Final Human Decision |
| GDPR | General Data Protection Regulation (cf. EU 2016/679) |
| HD | Human Decision |
| ML | Machine Learning |
| RBC | Rank Biserial Correlation |
| QT | QT interval, i.e., the time from the start of the Q wave to the end of the T wave in an ECG |
| RQ | Research Question |
| TTD | Theory of Technological Dominance |
| XAI | eXplainable AI |
References
- Calegari, R.; Ciatto, G.; Omicini, A. On the integration of symbolic and sub-symbolic techniques for XAI: A survey. Intell. Artif. 2020, 14, 7–32. [Google Scholar] [CrossRef]
- Springer, A.; Hollis, V.; Whittaker, S. Dice in the black box: User experiences with an inscrutable algorithm. In Proceedings of the 2017 AAAI Spring Symposium Series, Stanford, CA, USA, 27–29 March 2017. [Google Scholar]
- Cinà, G.; Röber, T.; Goedhart, R.; Birbil, I. Why we do need Explainable AI for Healthcare. arXiv 2022, arXiv:2206.15363. [Google Scholar]
- Gerlings, J.; Shollo, A.; Constantiou, I. Reviewing the need for explainable artificial intelligence (xAI). arXiv 2020, arXiv:2012.01007. [Google Scholar]
- Goebel, R.; Chander, A.; Holzinger, K.; Lecue, F.; Akata, Z.; Stumpf, S.; Kieseberg, P.; Holzinger, A. Explainable AI: The new 42? In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Hamburg, Germany, 27 August 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 295–303. [Google Scholar]
- De Bruijn, H.; Warnier, M.; Janssen, M. The perils and pitfalls of explainable AI: Strategies for explaining algorithmic decision-making. Gov. Inf. Q. 2022, 39, 101666. [Google Scholar] [CrossRef]
- Janssen, M.; Hartog, M.; Matheus, R.; Yi Ding, A.; Kuk, G. Will algorithms blind people? The effect of explainable AI and decision-makers’ experience on AI-supported decision-making in government. Soc. Sci. Comput. Rev. 2022, 40, 478–493. [Google Scholar] [CrossRef]
- Lipton, Z.C. The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Schemmer, M.; Kühl, N.; Benz, C.; Satzger, G. On the Influence of Explainable AI on Automation Bias. arXiv 2022, arXiv:2204.08859. [Google Scholar]
- Poursabzi-Sangdeh, F.; Goldstein, D.G.; Hofman, J.M.; Wortman Vaughan, J.W.; Wallach, H. Manipulating and measuring model interpretability. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–52. [Google Scholar]
- Zhang, Y.; Liao, Q.V.; Bellamy, R.K. Effect of confidence and explanation on accuracy and trust calibration in AI-assisted decision making. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 295–305. [Google Scholar]
- Bansal, G.; Wu, T.; Zhou, J.; Fok, R.; Nushi, B.; Kamar, E.; Ribeiro, M.T.; Weld, D. Does the whole exceed its parts? The effect of ai explanations on complementary team performance. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–16. [Google Scholar]
- Buçinca, Z.; Malaya, M.B.; Gajos, K.Z. To trust or to think: Cognitive forcing functions can reduce overreliance on AI in AI-assisted decision-making. Proc. ACM Hum.-Comput. Interact. 2021, 5, 1–21. [Google Scholar] [CrossRef]
- Suresh, H.; Lao, N.; Liccardi, I. Misplaced trust: Measuring the interference of machine learning in human decision-making. In Proceedings of the 12th ACM Conference on Web Science, Southampton, UK, 6–10 July 2020; pp. 315–324. [Google Scholar]
- Eiband, M.; Buschek, D.; Kremer, A.; Hussmann, H. The impact of placebic explanations on trust in intelligent systems. In Proceedings of the Extended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–6. [Google Scholar]
- Ghassemi, M.; Oakden-Rayner, L.; Beam, A.L. The false hope of current approaches to explainable artificial intelligence in health care. Lancet Digit. Health 2021, 3, e745–e750. [Google Scholar] [CrossRef]
- Finzel, B.; Saranti, A.; Angerschmid, A.; Tafler, D.; Pfeifer, B.; Holzinger, A. Generating Explanations for Conceptual Validation of Graph Neural Networks: An Investigation of Symbolic Predicates Learned on Relevance-Ranked Sub-Graphs. KI-Künstl. Intell. 2022, 36, 271–285. [Google Scholar] [CrossRef]
- Cabitza, F.; Campagner, A.; Malgieri, G.; Natali, C.; Schneeberger, D.; Stoeger, K.; Holzinger, A. Quod erat demonstrandum?-Towards a typology of the concept of explanation for the design of explainable AI. Expert Syst. Appl. 2022, 213, 118888. [Google Scholar] [CrossRef]
- Green, B.; Chen, Y. Disparate interactions: An algorithm-in-the-loop analysis of fairness in risk assessments. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 90–99. [Google Scholar]
- Shin, D. The effects of explainability and causability on perception, trust, and acceptance: Implications for explainable AI. Int. J. Hum.-Comput. Stud. 2021, 146, 102551. [Google Scholar] [CrossRef]
- Holzinger, A.; Langs, G.; Denk, H.; Zatloukal, K.; Müller, H. Causability and explainability of artificial intelligence in medicine. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1312. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Langer, E.J.; Blank, A.; Chanowitz, B. The mindlessness of ostensibly thoughtful action: The role of “placebic” information in interpersonal interaction. J. Personal. Soc. Psychol. 1978, 36, 635. [Google Scholar] [CrossRef]
- Cabitza, F.; Campagner, A.; Simone, C. The need to move away from agential-AI: Empirical investigations, useful concepts and open issues. Int. J. Hum.-Comput. Stud. 2021, 155, 102696. [Google Scholar] [CrossRef]
- Cabitza, F.; Campagner, A.; Famiglini, L.; Gallazzi, E.; La Maida, G.A. Color Shadows (Part I): Exploratory Usability Evaluation of Activation Maps in Radiological Machine Learning. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Vienna, Austria, 23–26 August 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 31–50. [Google Scholar]
- Parimbelli, E.; Peek, N.; Holzinger, A.; Guidotti, R.; Mittelstadt, B.; Dagliati, A.; Nicora, G. Explainability, Causability, Causality, Reliability: The many facets of “good” explanations in XAI for health. In Proceedings of the Challenges of Trustable AI and Added-Value on Health, Nice, France, 27–30 May 2022; EFMI: Nice, France, 2022. [Google Scholar]
- Ebrahimi, Z.; Loni, M.; Daneshtalab, M.; Gharehbaghi, A. A review on deep learning methods for ECG arrhythmia classification. Expert Syst. Appl. X 2020, 7, 100033. [Google Scholar] [CrossRef]
- Huang, J.S.; Chen, B.Q.; Zeng, N.Y.; Cao, X.C.; Li, Y. Accurate classification of ECG arrhythmia using MOWPT enhanced fast compression deep learning networks. J. Ambient. Intell. Humaniz. Comput. 2020, 1–18. [Google Scholar] [CrossRef]
- Chen, C.Y.; Lin, Y.T.; Lee, S.J.; Tsai, W.C.; Huang, T.C.; Liu, Y.H.; Cheng, M.C.; Dai, C.Y. Automated ECG classification based on 1D deep learning network. Methods 2022, 202, 127–135. [Google Scholar] [CrossRef] [PubMed]
- Bond, R.; Finlay, D.; Al-Zaiti, S.S.; Macfarlane, P. Machine learning with electrocardiograms: A call for guidelines and best practices for ‘stress testing’ algorithms. J. Electrocardiol. 2021, 69, 1–6. [Google Scholar] [CrossRef]
- Rojat, T.; Puget, R.; Filliat, D.; Del Ser, J.; Gelin, R.; Díaz-Rodríguez, N. Explainable Artificial Intelligence (XAI) on TimeSeries Data: A Survey. arXiv 2021, arXiv:2104.00950. [Google Scholar]
- Raza, A.; Tran, K.P.; Koehl, L.; Li, S. Designing ECG monitoring healthcare system with federated transfer learning and explainable AI. Knowl.-Based Syst. 2022, 236, 107763. [Google Scholar] [CrossRef]
- Panigutti, C.; Perotti, A.; Pedreschi, D. Doctor XAI: An ontology-based approach to black-box sequential data classification explanations. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency (FAT* ’20), Barcelona, Spain, 27–30 January 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 629–639. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Nair, B.; Vavilala, M.S.; Horibe, M.; Eisses, M.J.; Adams, T.; Liston, D.E.; Low, D.K.W.; Newman, S.F.; Kim, J.; et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2018, 2, 749–760. [Google Scholar] [CrossRef]
- Neves, I.; Folgado, D.; Santos, S.; Barandas, M.; Campagner, A.; Ronzio, L.; Cabitza, F.; Gamboa, H. Interpretable heartbeat classification using local model-agnostic explanations on ECGs. Comput. Biol. Med. 2021, 133, 104393. [Google Scholar] [CrossRef] [PubMed]
- Dahlbäck, N.; Jönsson, A.; Ahrenberg, L. Wizard of oz studies—Why and how. In Proceedings of the 1993 International Workshop on Intelligent User Interfaces, Orlando, FL, USA, 4–7 January 1993; pp. 4–7. [Google Scholar]
- Ronzio, L.; Campagner, A.; Cabitza, F.; Gensini, G.F. Unity Is Intelligence: A Collective Intelligence Experiment on ECG Reading to Improve Diagnostic Performance in Cardiology. J. Intell. 2021, 9, 17. [Google Scholar] [CrossRef]
- Nourani, M.; King, J.; Ragan, E. The role of domain expertise in user trust and the impact of first impressions with intelligent systems. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, Hilversum, The Netherlands, 25–29 October 2020; Volume 8, pp. 112–121. [Google Scholar]
- Kim, A.; Yang, M.; Zhang, J. When Algorithms Err: Differential Impact of Early vs. Late Errors on Users’ Reliance on Algorithms. ACM Trans. Comput.-Hum. Interact. 2020. [Google Scholar] [CrossRef]
- Arnold, V.; Sutton, S.G. The theory of technology dominance: Understanding the impact of intelligent decision aids on decision maker’s judgments. Adv. Account. Behav. Res. 1998, 1, 175–194. [Google Scholar]
- Sutton, S.G.; Arnold, V.; Holt, M. An Extension of the Theory of Technology Dominance: Understanding the Underlying Nature, Causes and Effects. Causes Eff. 2022. Available online: https://www.nhh.no/globalassets/centres/digaudit/activities/sutton-arnold-and-holt-2022-april-an-extension-of-the-theory-of-technology-dominance.pdf (accessed on 30 April 2022). [CrossRef]
- Glick, A.; Clayton, M.; Angelov, N.; Chang, J. Impact of explainable artificial intelligence assistance on clinical decision-making of novice dental clinicians. JAMIA Open 2022, 5, ooac031. [Google Scholar] [CrossRef] [PubMed]
- Paleja, R.; Ghuy, M.; Ranawaka Arachchige, N.; Jensen, R.; Gombolay, M. The Utility of Explainable AI in Ad Hoc Human-Machine Teaming. Adv. Neural Inf. Process. Syst. 2021, 34, 610–623. [Google Scholar]
- Noga, T.; Arnold, V. Do tax decision support systems affect the accuracy of tax compliance decisions? Int. J. Account. Inf. Syst. 2002, 3, 125–144. [Google Scholar] [CrossRef]
- Arnold, V.; Collier, P.A.; Leech, S.A.; Sutton, S.G. Impact of intelligent decision aids on expert and novice decision-makers’ judgments. Account. Financ. 2004, 44, 1–26. [Google Scholar] [CrossRef]
- Jensen, M.L.; Lowry, P.B.; Burgoon, J.K.; Nunamaker, J.F. Technology dominance in complex decision making: The case of aided credibility assessment. J. Manag. Inf. Syst. 2010, 27, 175–202. [Google Scholar] [CrossRef]
- Cabitza, F. Biases affecting human decision making in AI-supported second opinion settings. In Proceedings of the International Conference on Modeling Decisions for Artificial Intelligence, Milan, Italy, 4–6 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 283–294. [Google Scholar]
- Cabitza, F.; Campagner, A.; Ronzio, L.; Cameli, M.; Mandoli, G.E.; Pastore, M.C.; Sconfienza, L.; Folgado, D.; Barandas, M.; Gamboa, H. Rams, Hounds and White Boxes: Investigating Human-AI Collaboration Protocols in Medical Diagnosis. Artif. Intell. Med. 2022. submitted. [Google Scholar] [CrossRef]
- Bansal, G.; Nushi, B.; Kamar, E.; Horvitz, E.; Weld, D.S. Is the most accurate ai the best teammate? optimizing ai for teamwork. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 11405–11414. [Google Scholar]
- Nunnally, J.; Bernstein, I. Psychometric Theory, 3rd ed.; McGraw-Hil: New York, NY, USA, 1994. [Google Scholar]
- Cho, E.; Kim, S. Cronbach’s coefficient alpha: Well known but poorly understood. Organ. Res. Methods 2015, 18, 207–230. [Google Scholar] [CrossRef]
- Gaube, S.; Suresh, H.; Raue, M.; Merritt, A.; Berkowitz, S.J.; Lermer, E.; Coughlin, J.F.; Guttag, J.V.; Colak, E.; Ghassemi, M. Do as AI say: Susceptibility in deployment of clinical decision-aids. NPJ Digit. Med. 2021, 4, 31. [Google Scholar] [CrossRef] [PubMed]
- Brill, T.M.; Munoz, L.; Miller, R.J. Siri, Alexa, and other digital assistants: A study of customer satisfaction with artificial intelligence applications. J. Mark. Manag. 2019, 35, 1401–1436. [Google Scholar] [CrossRef]
- Yang, J.; Hurmelinna-Laukkanen, P. Benefiting from innovation–Playing the appropriability cards. In Innovation; Routledge: Abingdon, UK, 2022; pp. 310–331. [Google Scholar]
- Jacobs, M.; Pradier, M.F.; McCoy, T.H.; Perlis, R.H.; Doshi-Velez, F.; Gajos, K.Z. How machine-learning recommendations influence clinician treatment selections: The example of antidepressant selection. Transl. Psychiatry 2021, 11, 108. [Google Scholar] [CrossRef]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Vilone, G.; Longo, L. Notions of explainability and evaluation approaches for explainable artificial intelligence. Inf. Fusion 2021, 76, 89–106. [Google Scholar] [CrossRef]
- Reason, J. Human error: Models and management. BMJ 2000, 320, 768–770. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Parimbelli, E.; Buonocore, T.M.; Nicora, G.; Michalowski, W.; Wilk, S.; Bellazzi, R. Why did AI get this one wrong?—Tree-based explanations of machine learning model predictions. Artif. Intell. Med. 2023, 135, 102471. [Google Scholar] [CrossRef] [PubMed]
- Amann, J.; Vetter, D.; Blomberg, S.N.; Christensen, H.C.; Coffee, M.; Gerke, S.; Gilbert, T.K.; Hagendorff, T.; Holm, S.; Livne, M.; et al. To explain or not to explain?—Artificial intelligence explainability in clinical decision support systems. PLoS Digit. Health 2022, 1, e0000016. [Google Scholar] [CrossRef]
- Shortliffe, E.H.; Davis, R.; Axline, S.G.; Buchanan, B.G.; Green, C.C.; Cohen, S.N. Computer-based consultations in clinical therapeutics: Explanation and rule acquisition capabilities of the MYCIN system. Comput. Biomed. Res. Int. J. 1975, 8, 303–320. [Google Scholar] [CrossRef]
- Bos, J.M.; Attia, Z.I.; Albert, D.E.; Noseworthy, P.A.; Friedman, P.A.; Ackerman, M.J. Use of artificial intelligence and deep neural networks in evaluation of patients with electrocardiographically concealed long QT syndrome from the surface 12-lead electrocardiogram. JAMA Cardiol. 2021, 6, 532–538. [Google Scholar] [CrossRef] [PubMed]
- Klein, G.; Hoffman, R.; Mueller, S. Naturalistic Psychological Model of Explanatory Reasoning: How people explain things to others and to themselves. In Proceedings of the International Conference on Naturalistic Decision Making, San Francisco, CA, USA, 17–21 June 2019. [Google Scholar]
- Gunning, D.; Aha, D. DARPA’s explainable artificial intelligence (XAI) program. AI Mag. 2019, 40, 44–58. [Google Scholar]
- Green, B.; Chen, Y. The principles and limits of algorithm-in-the-loop decision making. Proc. Acm Hum.-Comput. Interact. 2019, 3, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Vaccaro, M.; Waldo, J. The Effects of Mixing Machine Learning and Human Judgment: Collaboration between humans and machines does not necessarily lead to better outcomes. Queue 2019, 17, 19–40. [Google Scholar] [CrossRef]
- Mueller, S.T.; Veinott, E.S.; Hoffman, R.R.; Klein, G.; Alam, L.; Mamun, T.; Clancey, W.J. Principles of explanation in human-AI systems. arXiv 2021, arXiv:2102.04972. [Google Scholar]
- Shneiderman, B. Human-centered artificial intelligence: Reliable, safe & trustworthy. Int. J. Hum.–Comput. Interact. 2020, 36, 495–504. [Google Scholar]
- Dignum, V. Relational Artificial Intelligence. arXiv 2022, arXiv:2202.07446. [Google Scholar]
- Reverberi, C.; Rigon, T.; Solari, A.; Hassan, C.; Cherubini, P.; Cherubini, A. Experimental evidence of effective human–AI collaboration in medical decision-making. Sci. Rep. 2022, 12, 14952. [Google Scholar] [CrossRef] [PubMed]
- Holzinger, A.T.; Muller, H. Toward Human–AI Interfaces to Support Explainability and Causability in Medical AI. Computer 2021, 54, 78–86. [Google Scholar] [CrossRef]
- Dellermann, D.; Calma, A.; Lipusch, N.; Weber, T.; Weigel, S.; Ebel, P. The future of human-ai collaboration: A taxonomy of design knowledge for hybrid intelligence systems. In Proceedings of the Hawaii International Conference on System Sciences (HICSS), Maui, HI, USA, 8–11 January 2019. [Google Scholar]
- Andrews, R.W.; Lilly, J.M.; Srivastava, D.; Feigh, K.M. The role of shared mental models in human-AI teams: A theoretical review. Theor. Issues Ergon. Sci. 2022, 2, 1–47. [Google Scholar] [CrossRef]
- Neerincx, M.A.; Waa, J.v.d.; Kaptein, F.; Diggelen, J.v. Using perceptual and cognitive explanations for enhanced human-agent team performance. In Proceedings of the International Conference on Engineering Psychology and Cognitive Ergonomics, Las Vegas, NV, USA, 15 July 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 204–214. [Google Scholar]
- Cooke, N.J.; Lawless, W.F. Effective Human–Artificial Intelligence Teaming. In Systems Engineering and Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2021; pp. 61–75. [Google Scholar]
- Liu, B. In AI we trust? Effects of agency locus and transparency on uncertainty reduction in human–AI interaction. J. Comput.-Mediat. Commun. 2021, 26, 384–402. [Google Scholar] [CrossRef]
- Wang, D.; Churchill, E.; Maes, P.; Fan, X.; Shneiderman, B.; Shi, Y.; Wang, Q. From human-human collaboration to Human-AI collaboration: Designing AI systems that can work together with people. In Proceedings of the Extended Abstracts of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–6. [Google Scholar]
- Klein, G. A naturalistic decision making perspective on studying intuitive decision making. J. Appl. Res. Mem. Cogn. 2015, 4, 164–168. [Google Scholar] [CrossRef] [Green Version]
- Asan, O.; Choudhury, A. Research trends in artificial intelligence applications in human factors health care: Mapping review. JMIR Hum. Factors 2021, 8, e28236. [Google Scholar] [CrossRef] [PubMed]
- Parasuraman, R.; Sheridan, T.B.; Wickens, C.D. A model for types and levels of human interaction with automation. IEEE Trans. Syst. Man Cybern.-Part A Syst. Humans 2000, 30, 286–297. [Google Scholar] [CrossRef] [Green Version]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cabitza, F.; Campagner, A.; Natali, C.; Parimbelli, E.; Ronzio, L.; Cameli, M. Painting the Black Box White: Experimental Findings from Applying XAI to an ECG Reading Setting. Mach. Learn. Knowl. Extr. 2023, 5, 269-286. https://doi.org/10.3390/make5010017
Cabitza F, Campagner A, Natali C, Parimbelli E, Ronzio L, Cameli M. Painting the Black Box White: Experimental Findings from Applying XAI to an ECG Reading Setting. Machine Learning and Knowledge Extraction. 2023; 5(1):269-286. https://doi.org/10.3390/make5010017
Chicago/Turabian StyleCabitza, Federico, Andrea Campagner, Chiara Natali, Enea Parimbelli, Luca Ronzio, and Matteo Cameli. 2023. "Painting the Black Box White: Experimental Findings from Applying XAI to an ECG Reading Setting" Machine Learning and Knowledge Extraction 5, no. 1: 269-286. https://doi.org/10.3390/make5010017
APA StyleCabitza, F., Campagner, A., Natali, C., Parimbelli, E., Ronzio, L., & Cameli, M. (2023). Painting the Black Box White: Experimental Findings from Applying XAI to an ECG Reading Setting. Machine Learning and Knowledge Extraction, 5(1), 269-286. https://doi.org/10.3390/make5010017