

A Survey on GAN Techniques for Data Augmentation to Address the Imbalanced Data Issues in Credit Card Fraud Detection

Abstract
:1. Introduction
- Comparison of GAN variants for data augmentation in credit card fraud detection domain;
- Detailed discussion of the most recent and relevant GAN variants for fraud detection;
- The most common evaluation metrics are discussed and elucidated;
- This report reviews the recent advancements in using GANs in data augmentation;
- We also provide an analysis and comparison in terms of strengths and limitations across the GAN variants discussed in this paper.
Organization of this Survey
- Section 2 provides the background of the imbalanced class challenge, the definition and structure of GAN, and the importance of data augmentation using GANs;
- Section 3 briefly describes different GAN approaches used in the credit card fraud domain to handle imbalanced class challenges. In addition, this section also presents the tabular evaluation of several GAN methodologies based on precision, recall and F1-score;
- Section 4 concludes this research survey and provides future research recommendations.
2. Background
2.1. Class Imbalance Challenge
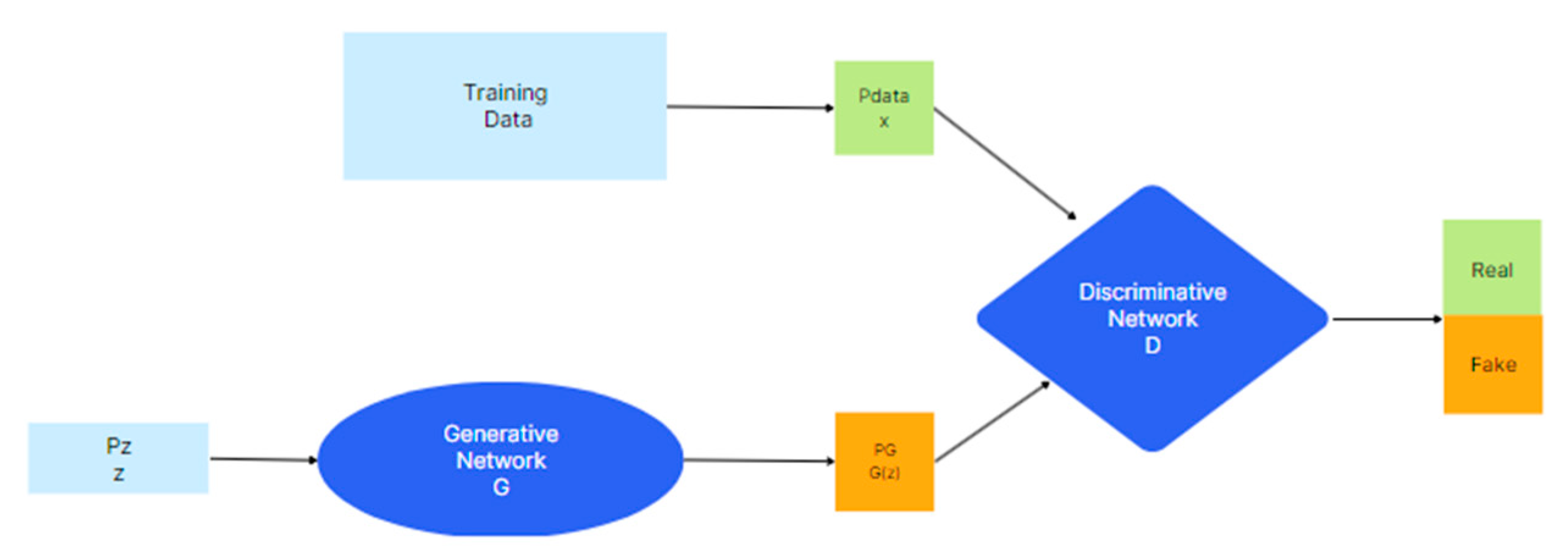
2.2. Generative Adversarial Networks (GANs)
2.2.1. Definition and Structure
2.2.2. The Discriminator
2.2.3. The Generator
2.2.4. Loss Functions
2.3. GANs in Credit Card Fraud Detection Domain
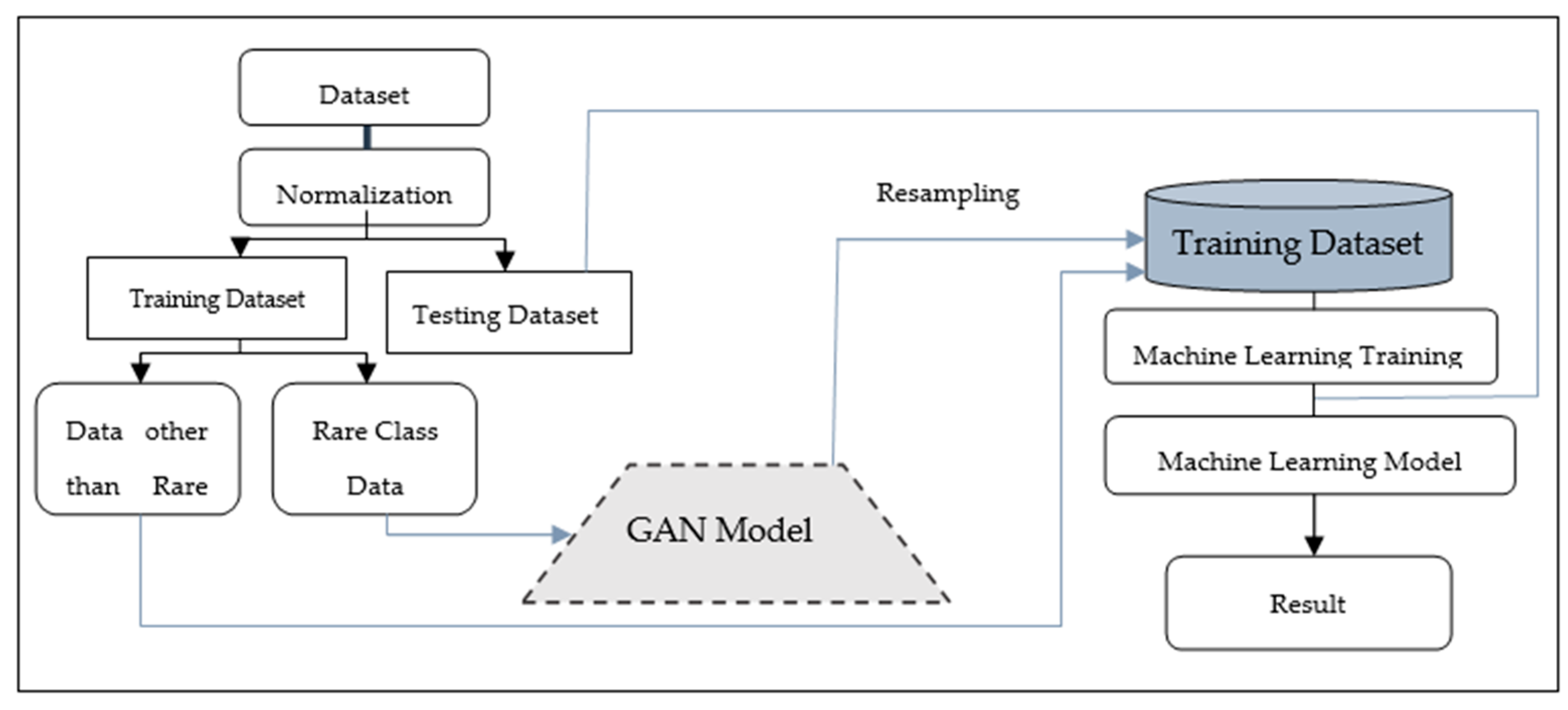
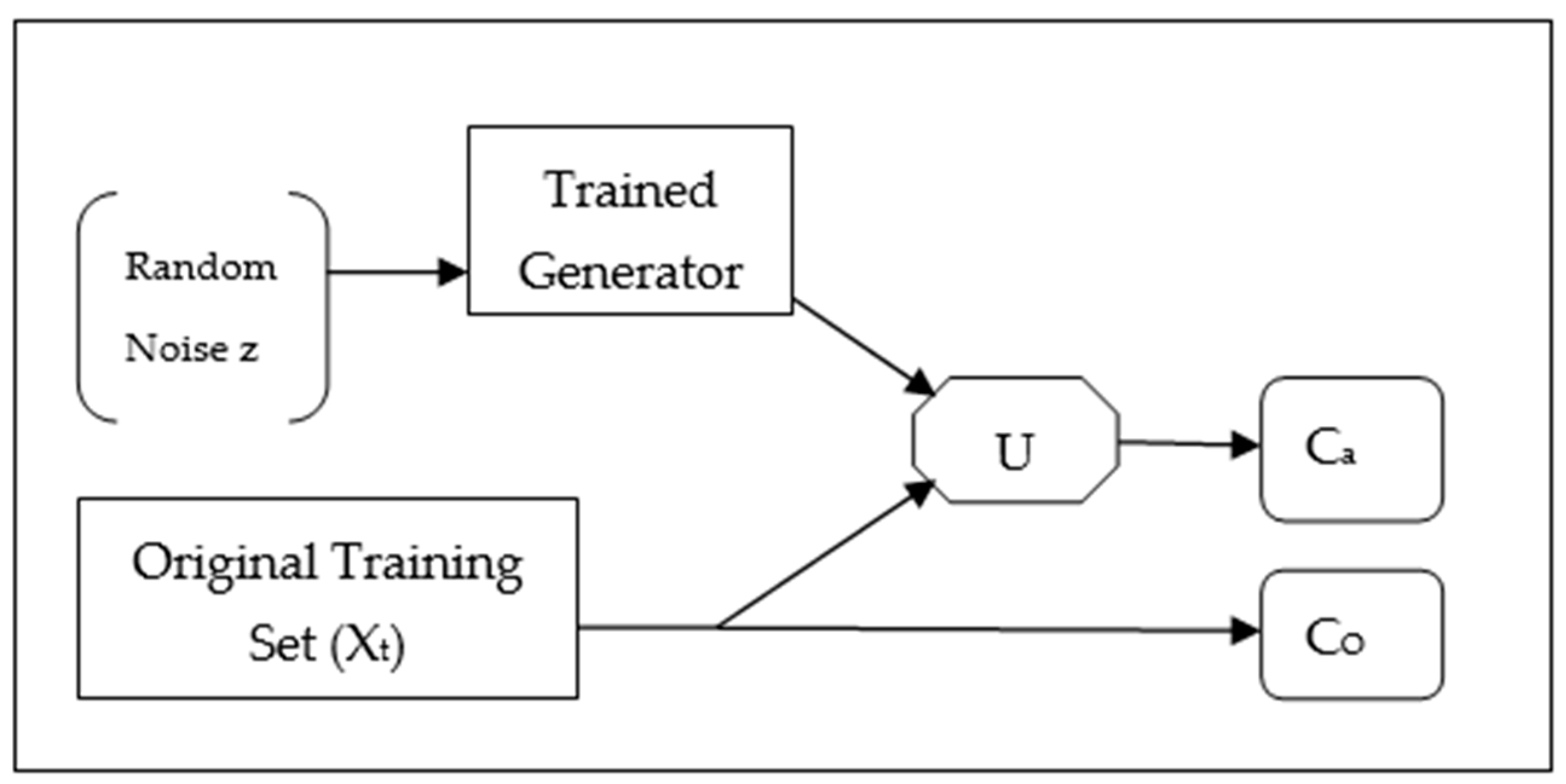
2.4. Data Augmentation using GANs
2.4.1. Limited Training Data
2.4.2. Lack of Relevant Data
2.4.3. Model Overfitting
2.4.4. Imbalanced Data
2.5. Challenges and Limitations of GAN Based Data Augmentation
2.6. Recent Advancements to Deal with the Challenges and Limitations
3. Literature on Architecture-Variant GANs
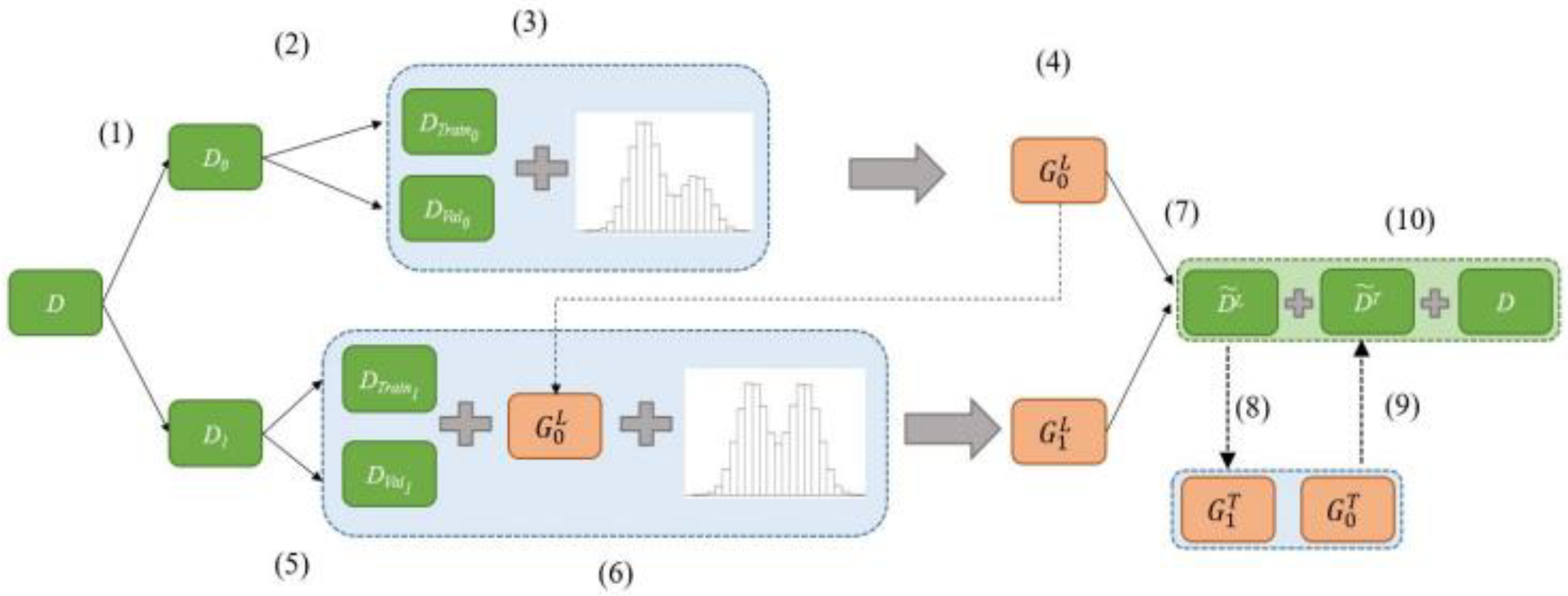
3.1. Duo-GAN Approach
3.1.1. Process
- This approach employs two GANs instead of one to create synthetic data.
- This approach enables each Generator to learn the class-conditional distributions and the correlation of each class so as to learn the distribution and relationship of the actual data.
3.1.2. Strengths
- This novel framework can generate artificial data for highly imbalanced datasets.
- It can generate artificial data without overfitting the real data.
- It outperforms classifiers trained on data generated by one-GAN models.
3.1.3. Limitations
- This framework does not incorporate the computational resources and time required to train the models.
- The divergence metric encounters some problems when dealing with the continuous characteristics.
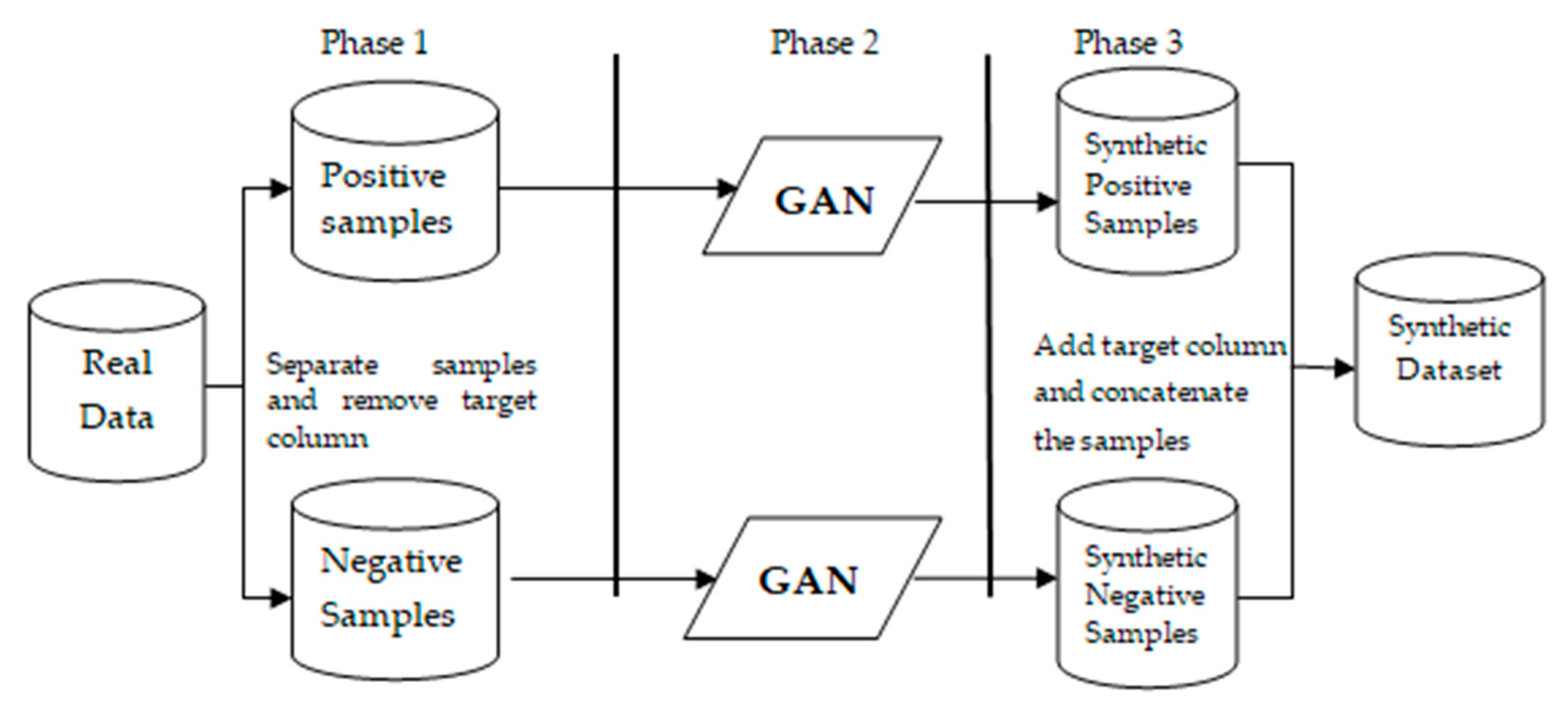
3.2. Majority-Minority GAN Transfer
3.2.1. Process
- This process investigates the use of synthetic data from not only the minority class, but also the majority class. By doing so, the Generator captures more information about p data.
- The model retrains the fraud case model directly on actual transaction data.
3.2.2. Strengths
- This framework used to generate synthetic samples can generate data streams with one or multiple minority classes.
- It trains the Generator first so as to model conditional distribution.
3.2.3. Limitations
- This GAN variant performed well compared to other GAN generators, but struggled in modeling log-transformed variables on some occasions, mainly where univariant histograms are incredibly skewed.
- This technique lacks feature transfer to control distributional differences.
- Further investigations are needed as this framework is in the initial phase.
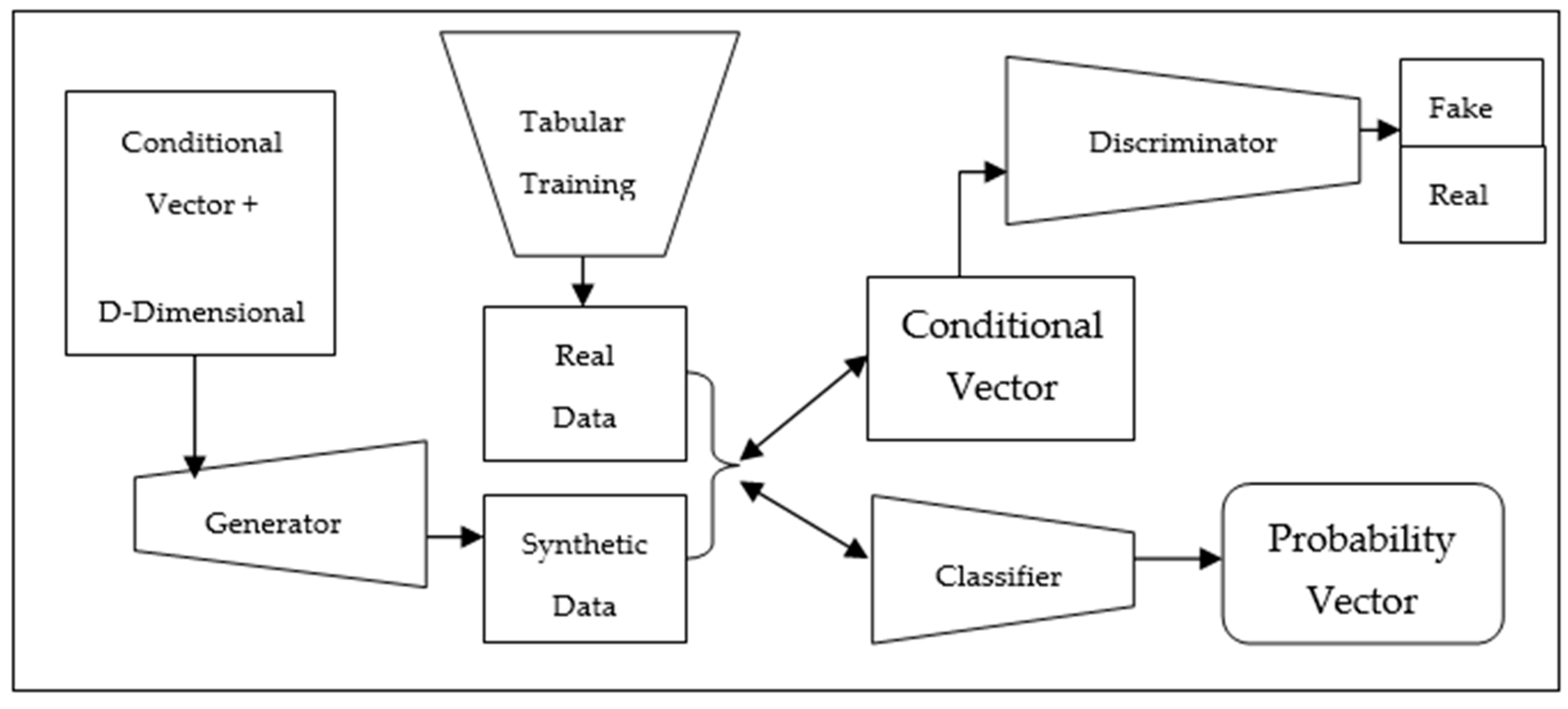
3.3. The Conditional Table GAN (CTAB-GAN)
3.3.1. Process
- Encodes mixed data.
- Efficient modeling of long-tailed continuous variables.
- Deals with highly skewed distributions for continuous variables.
3.3.2. Strengths
- Outperforms other state-of-the-art generative algorithms.
- Provides better distance-based privacy guarantees than Table GAN.
- Preserves data privacy.
3.3.3. Limitations
- CTAB GAN functions well with complex datasets, but cannot converge to a better optimum for small and straightforward datasets.
- There is still room to enhance the performance of CTAB GAN. For example, it generates more zero values than in the original distribution, as it amplifies the dominance of zero values in mixed data-type variables.
3.4. Synthetic Data Generation GAN (SDG-GAN)
3.4.1. Process
- The “G” and “D” in SDG-GAN are feed-forward networks with an MLP architecture.
- Feature matching loss was adopted in this technique instead of the regular loss.
- The “G” attempts to learn the actual distribution of the data.
- This technique is based on conditional GAN.
3.4.2. Strengths
- This technique can be used in multiple fields.
- The feature matching technique was used in this novel GAN. This technique changes the cost function for the “G” to lessen the statistical disparity between real and artificial data traits.
3.4.3. Limitations
- This proposed GAN outperformed the other four techniques in three out of four observed imbalanced datasets. This indicates that there is room to enhance the ability of SDG-GAN.
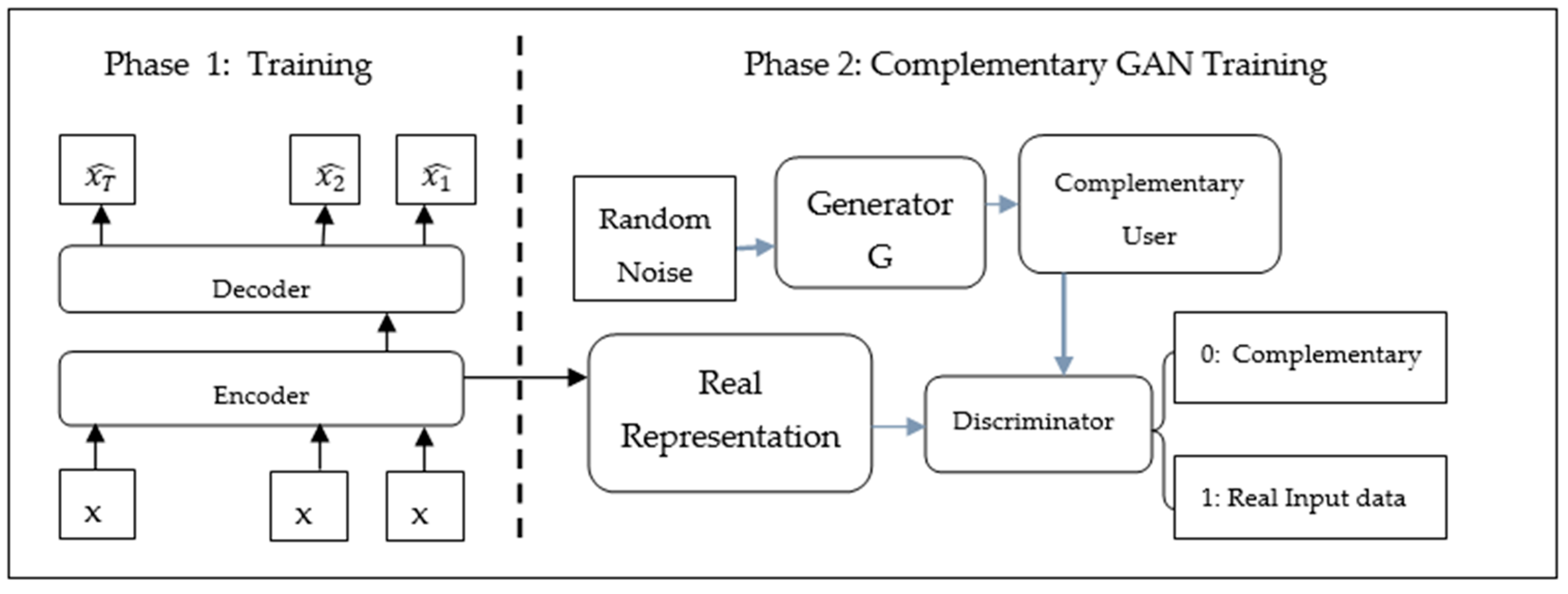
3.5. One-Class Adversarial Nets for Fraud Detection (OCAN)
3.5.1. Process
- In the first training phase, the LSTM autoencoder is adopted to learn representations of legitimate users from the sequences of their activities.
- The encoder figures unseen representations of the inputs, and the decoder calculates the reconstructed inputs.
- In the second phase, containing training, a complementary GAN comprises a Discriminator that distinguishes the legitimate and fraudulent users.
3.5.2. Strengths
- OCAN outperforms other one-class classification GAN models.
- Details about fraudulent users are not required in this technique. Thus, this framework is more adaptive to fraudulent user identification tasks.
- Unlike single-class classification GAN models, OCAN generates complimentary samples of fraudulent users.
- It can capture the sequential details of the user’s actions.
3.5.3. Limitations
- OCAN can detect fraudulent activities; however, more evaluation is needed to evaluate the accuracy of this model.
- The stability of OCAN is lower than the normal threshold.
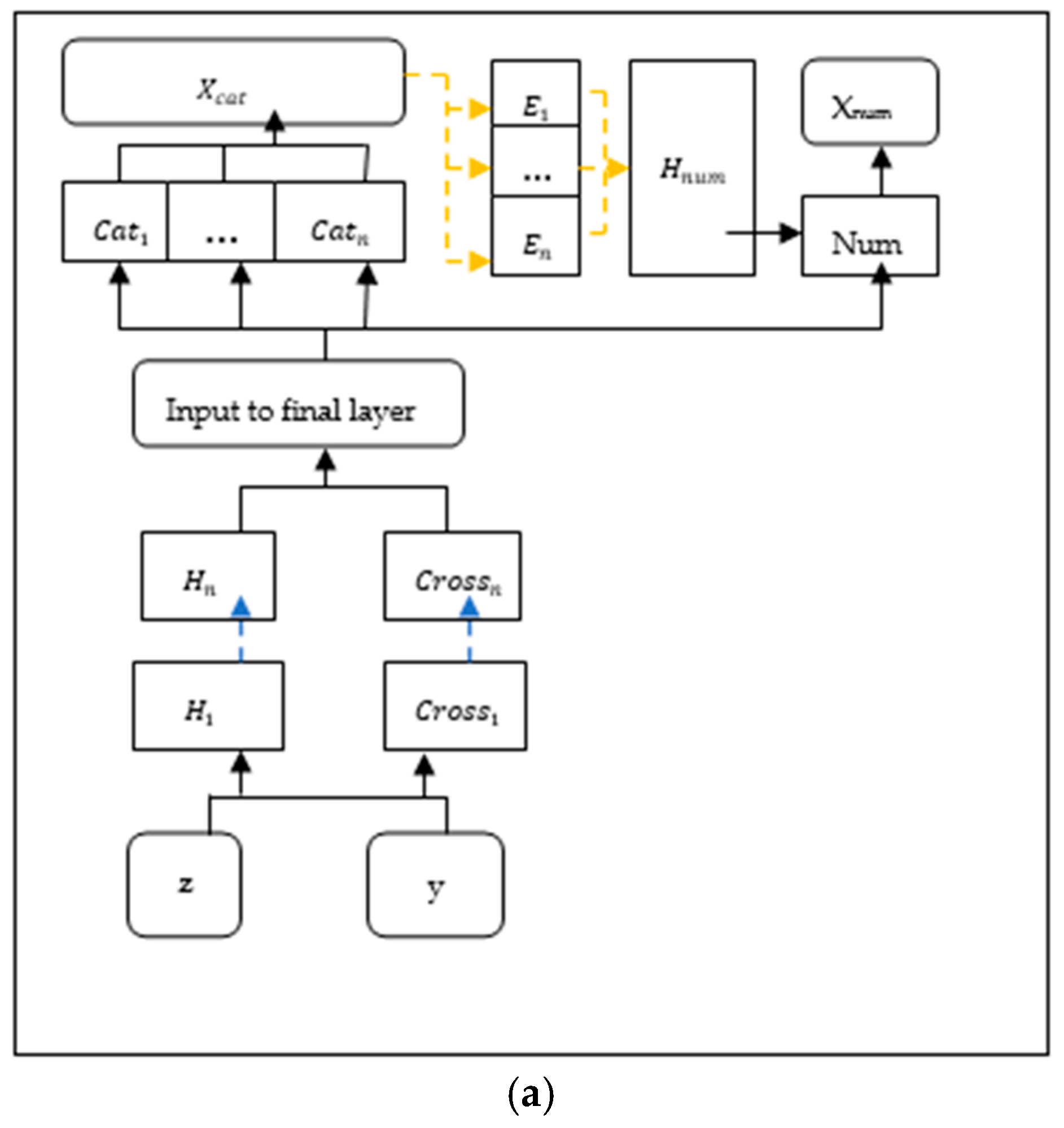
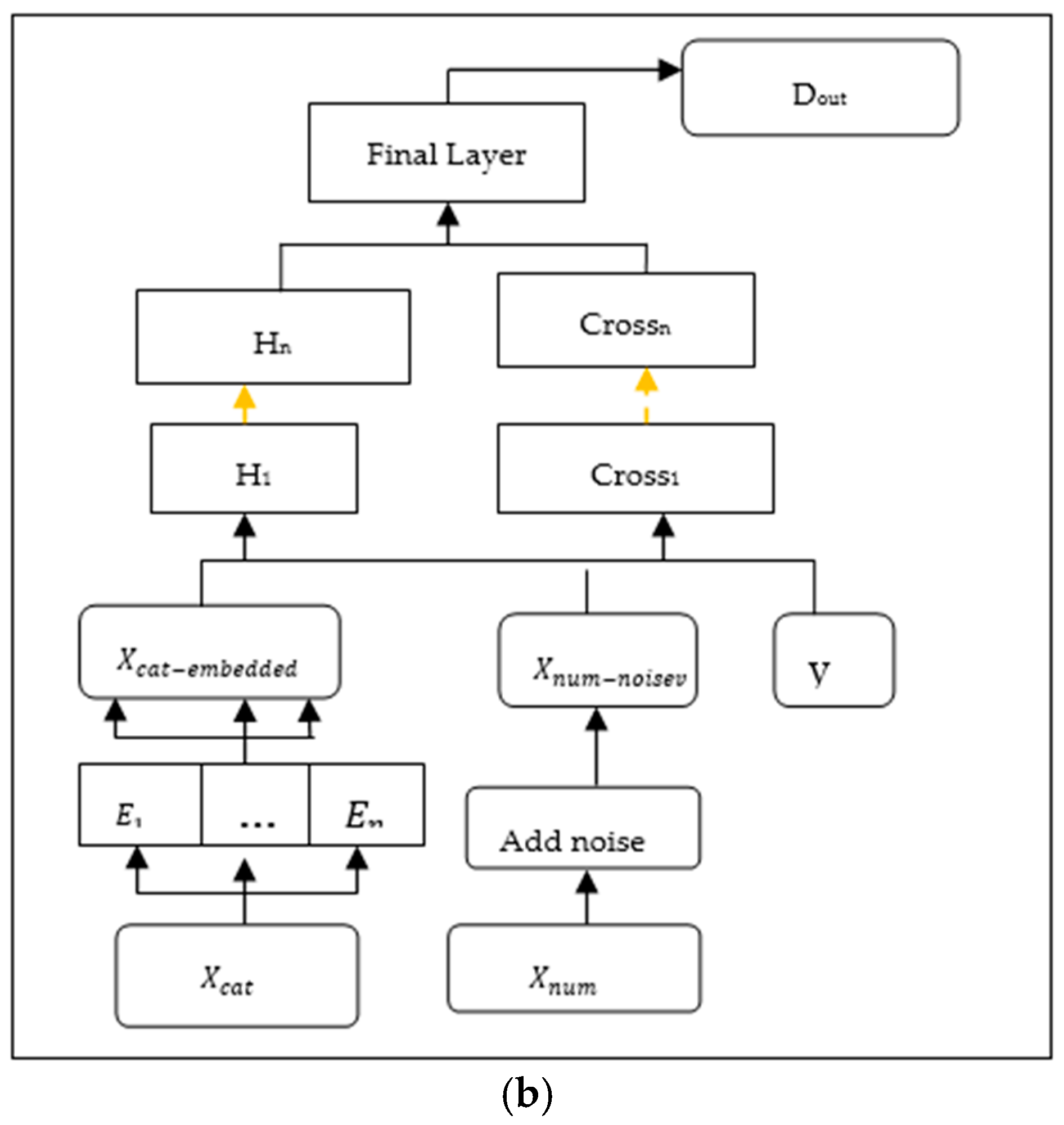
3.6. Conditional Wasserstein GAN (cWGAN)-Based Oversampling Method
3.6.1. Process
- This method has several elements not present in conventional methods, such as the AC loss, the W-GAN GP, etc.
- The authors employed the cGAN framework to estimate the distribution to sample the minority class.
3.6.2. Strengths
- This method efficiently models tabular datasets with categorical and numerical variables.
- This novel method pays extraordinary attention to the downstream classification task via an auxiliary classifier loss.
- This method also works well for nonlinear datasets.
3.6.3. Limitations
- Yet to test on heavily unbalanced datasets.
- Model enhancement is imperative to identifying better default hyper-parameter settings.
- Improvement is needed in fine-tuning this model.
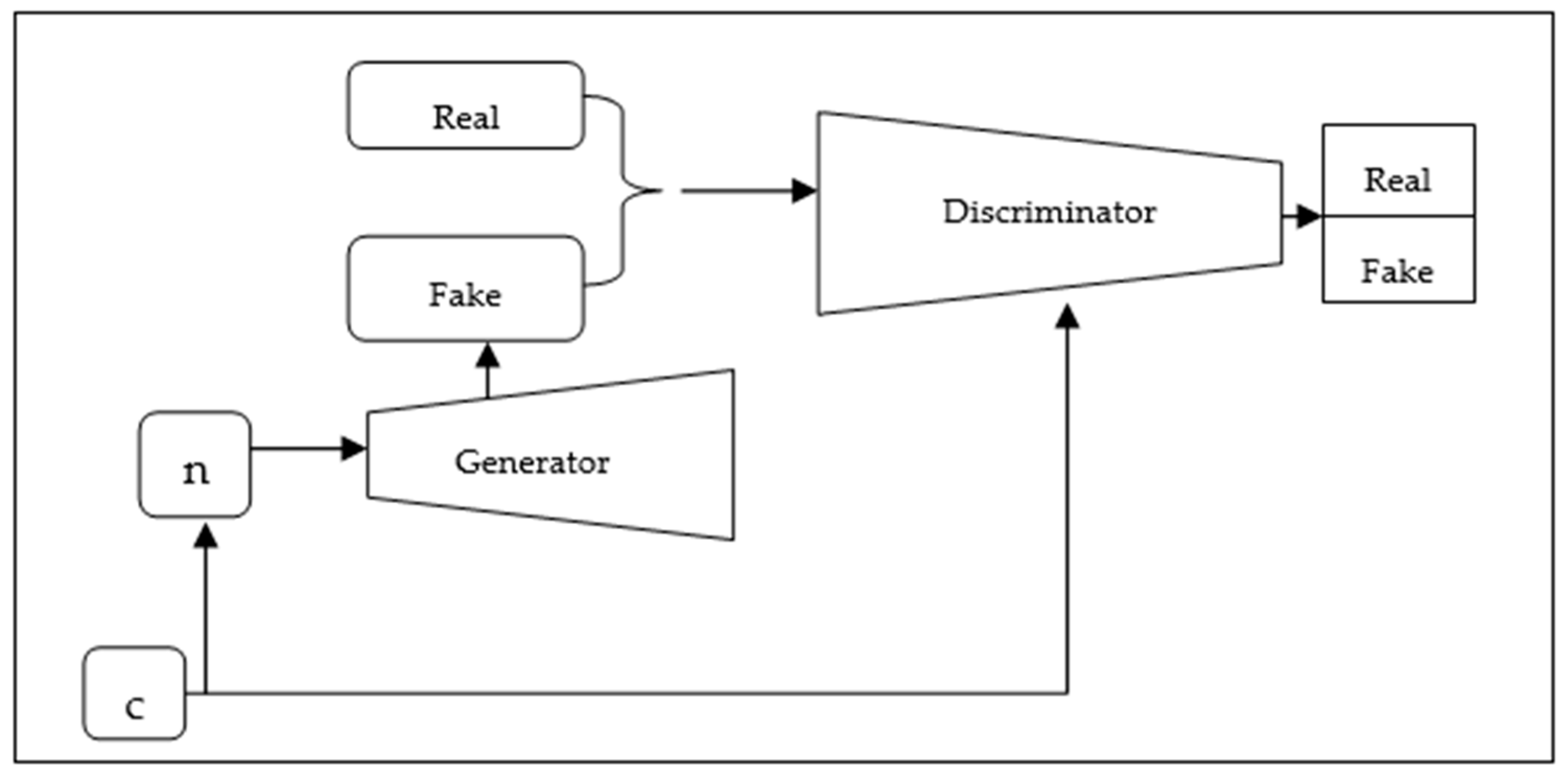
3.7. ScoreGAN
3.7.1. Process
- The Discriminator D differentiates between human fraud reviews from fraud bot reviews, and calculates the probability of a score based on fraud reviews and corresponding scores.
- After that, the Discriminator can differentiate genuine reviews from fraud reviews.
- On the other hand, the Generator takes the score and random noise, generating fake bot reviews.
3.7.2. Strengths
- This framework can convert the discrete form into a continuous one. This research work used the Tripadvisor and Yelp datasets, which are more reliable than datasets labeled by humans.
- This proposed method outperforms other systems when applied to the used dataset, according to the metrics.
3.7.3. Limitations
- The Discriminator can only estimate the reward for generating complete sentences, not partial ones.
3.8. Conditional Generative Adversarial Network (CGAN)
3.9. GAN-RF
3.10. Tuned-GAN
4. Tabular Comparison of Different GAN Variants
Detailed Discussion on the Above-Reviewed GAN Variants
5. Conclusions and Future Recommendations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Adewumi, A.O.; Akinyelu, A.A. A survey of machine-learning and nature-inspired based credit card fraud detection tech-niques. Int. J. Syst. Assur. Eng. Manag. 2017, 8, 937–953. [Google Scholar] [CrossRef]
- Bahnsen, A.C.; Aouada, D.; Stojanovic, A.; Ottersten, B. Feature engineering strategies for credit card fraud detection. Expert Syst. Appl. 2016, 51, 134–142. [Google Scholar] [CrossRef]
- Srivastava, A.; Kundu, A.; Sural, S.; Majumdar, A. Credit card fraud detection using hidden Markov model. IEEE Trans. Dependable Secur. Comput. 2008, 5, 37–48. [Google Scholar] [CrossRef]
- Tan, G.W.H.; Ooi, K.B.; Chong, S.C.; Hew, T.S. NFC mobile credit card: The next frontier of mobile payment? Telemat. Inform. 2014, 31, 292–307. [Google Scholar] [CrossRef]
- Fiore, U.; De Santis, A.; Perla, F.; Zanetti, P.; Palmieri, F. Using generative adversarial networks for improving classification effectiveness in credit card fraud detection. Inf. Sci. 2019, 479, 448–455. [Google Scholar] [CrossRef]
- Zhang, F.; Liu, G.; Li, Z.; Yan, C.; Jiang, C. GMM-based Undersampling and Its Application for Credit Card Fraud Detection. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Guo, X.; Yin, Y.; Dong, C.; Yang, G.; Zhou, G. On the class imbalance problem. In Proceedings of the Fourth International Conference on Natural Computation, Jinan, China, 18–20 October 2008; Volume 4, pp. 192–201. [Google Scholar]
- Malave, N.; Nimkar, A.V. A survey on effects of class imbalance in data pre-processing stage of classification problem. Int. J. Comput. Syst. Eng. 2020, 6, 63–75. [Google Scholar] [CrossRef]
- Moreno-Barea, F.J.; Jerez, J.M.; Franco, L. Improving classification accuracy using data augmentation on small data sets. Expert Syst. Appl. 2020, 161, 113696. [Google Scholar] [CrossRef]
- Al Olaimat, M.; Lee, D.; Kim, Y.; Kim, J.; Kim, J. A learning-based data augmentation for network anomaly detection. In Proceedings of the 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 3–6 August 2020; pp. 1–10. [Google Scholar]
- Tamtama, A.S.; Arifudin, R. Increasing Accuracy of The Random Forest Algorithm Using PCA and Resampling Techniques with Data Augmentation for Fraud Detection of Credit Card Transaction. J. Adv. Inf. Syst. Technol. 2022, 4, 60–76. [Google Scholar]
- Langevin, A.; Cody, T.; Adams, S.; Beling, P. Synthetic data augmentation of imbalanced datasets with generative adversarial networks under varying distributional assumptions: A case study in credit card fraud detection. J. Oper. Res. Soc. 2021, 1–28. [Google Scholar] [CrossRef]
- Wang, C.; Deng, C.; Wang, S. Imbalance-XGBoost: Leveraging weighted and focal losses for binary label-imbalanced classi-fication with XGBoost. Pattern Recognit. Lett. 2020, 136, 190–197. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef] [Green Version]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S.S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. (CSUR) 2018, 51, 92. [Google Scholar] [CrossRef]
- Bauder RA, Khoshgoftaar TM, Hasanin, T. An empirical study on class rarity in big data. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 785–790. [CrossRef]
- Kotsiantis, S.B.; Kanellopoulos, D.; Pintelas, P.E. Data preprocessing for supervised leaning. Int. J. Comput. Sci. 2006, 1, 111–117. [Google Scholar]
- Yang, W.; Zhang, Y.; Ye, K.; Li, L.; Xu, C.-Z. FFD: A Federated Learning Based Method for Credit Card Fraud Detection. In Proceedings of the Big Data–BigData 2019: 8th International Congress, Held as Part of the Services Conference Federation, SCF, San Diego, CA, USA, 25–30 June 2019; pp. 18–32. [Google Scholar] [CrossRef]
- Tanaka, F.H.K.D.S.; Aranha, C. Data augmentation using GANs. arXiv 2019, arXiv:1904.09135v1. [Google Scholar]
- Cordón, I.; García, S.; Fernández, A.; Herrera, F. Imbalance: Oversampling algorithms for imbalanced classification in R. Knowledge-Based Syst. 2018, 161, 329–341. [Google Scholar] [CrossRef]
- Benchaji, I.; Douzi, S.; El Ouahidi, B. Using genetic algorithm to improve classification of imbalanced datasets for credit card fraud detection. In Smart Data and Computational Intelligence: Proceedings of the International Conference on Advanced Information Technology, Services and Systems (AIT2S-18), 17–18 October 2018; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; Volume 3, pp. 220–229. [Google Scholar]
- Cai, Z.; Wang, X.; Zhou, M.; Xu, J.; Jing, L. Supervised class distribution learning for GANs-based im-balanced classification. In Proceedings of the IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 41–50. [Google Scholar]
- Sayed, G.I.; Soliman, M.M.; Hassanien, A.E. A novel melanoma prediction model for imbalanced data using opti-mized SqueezeNet by bald eagle search optimization. Comput. Biol. Med. 2021, 136, 104712. [Google Scholar] [CrossRef]
- Kuppa, A.; Aouad, L.; Le-Khac, N.A. Towards improving privacy of synthetic datasets. In Privacy Technologies and Policy, Proceedings of the 9th Annual Privacy Forum, APF, Oslo, Norway, 17–18 June 2021; Springer International Publishing: Cham, Switzerland; pp. 106–119.
- Sakharova, I. Payment card fraud: Challenges and solutions. In Proceedings of the 2012 IEEE International Conference on Intelligence and Security Informatics, Washington, USA, 11–14 June 2012; pp. 227–234. [Google Scholar]
- Triastcyn, A.; Faltings, B. Generating artificial data for private deep learning. arXiv 2018, arXiv:1803.03148. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets (Advances in Neural Information Processing Systems); Red Hook: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Chen, J.; Shen, Y.; Ali, R. Credit card fraud detection using sparse autoencoder and generative adver-sarial network. In Proceedings of the IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 1–3 November 2018; pp. 1054–1059. [Google Scholar]
- Wei, W.; Li, J.; Cao, L.; Ou, Y.; Chen, J. Effective detection of sophisticated online banking fraud on extremely im-balanced data. World Wide Web 2013, 16, 449–475. [Google Scholar] [CrossRef]
- Kajal, D.; Kaur, K. Credit card fraud detection using imbalance resampling method with feature selection. Int. J. 2021, 10, 2061–2071. [Google Scholar]
- Makki, S.; Assaghir, Z.; Taher, Y.; Haque, R.; Hacid, M.-S.; Zeineddine, H. An Experimental Study With Imbalanced Classification Approaches for Credit Card Fraud Detection. IEEE 2019, 7, 93010–93022. [Google Scholar] [CrossRef]
- Dal Pozzolo, A.; Caelen, O.; Le Borgne, Y.-A.; Waterschoot, S.; Bontempi, G. Learned lessons in credit card fraud detection from a practitioner perspective. Expert Syst. Appl. 2014, 41, 4915–4928. [Google Scholar] [CrossRef]
- Thennakoon, A.; Bhagyani, C.; Premadasa, S.; Mihiranga, S.; Kuruwitaarachchi, N. Real-time credit card fraud detection using machine learning. In Proceedings of the 9th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Uttar Pradesh, India, 10–11 January 2019; pp. 488–493. [Google Scholar]
- Chaudhary, K.; Yadav, J.; Mallick, B. A review of fraud detection techniques: Credit card. Int. J. Comput. Appl. 2012, 45, 39–44. [Google Scholar]
- Dong, Q.; Gong, S.; Zhu, X. Imbalanced Deep Learning by Minority Class Incremental Rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1367–1381. [Google Scholar] [CrossRef] [Green Version]
- Assefa, S.A.; Dervovic, D.; Mahfouz, M.; Tillman, R.E.; Reddy, P.; Veloso, M. Generating synthetic data in finance: Opportunities, challenges and pitfalls. In Proceedings of the First ACM International Conference on AI in Finance, New York, NY, USA, 15–16 October 2020; pp. 1–8. [Google Scholar]
- Wang, S.; Yao, X. Multiclass Imbalance Problems: Analysis and Potential Solutions. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 2012, 42, 1119–1130. [Google Scholar] [CrossRef] [PubMed]
- Herland, M.; Khoshgoftaar, T.M.; Bauder, R.A. Big Data fraud detection using multiple medicare data sources. J. Big Data 2018, 5, 29. [Google Scholar] [CrossRef]
- Lee, J.; Park, K. GAN-based imbalanced data intrusion detection system. Pers. Ubiquitous Comput. 2021, 25, 121–128. [Google Scholar] [CrossRef]
- Seiffert, C.; Khoshgoftaar, T.M.; Van Hulse, J.; Napolitano, A. Mining data with rare events: A case study. In Proceedings of the 19th IEEE International Conference on Tools with Artificial Intelligence (ICTAI), Patras, Greece, 29–31 October 2007; Volume 2, pp. 132–139. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Pan, Z.; Yu, W.; Yi, X.; Khan, A.; Yuan, F.; Zheng, Y. Recent Progress on Generative Adversarial Networks (GANs): A Survey. IEEE Access 2019, 7, 36322–36333. [Google Scholar] [CrossRef]
- Antipov, G.; Baccouche, M.; Dugelay, J.L. Face aging with conditional generative adversarial networks. In Proceedings of the 2017 IEEE international conference on image processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2089–2093. [Google Scholar]
- Dziugaite, G.K.; Roy, D.M.; Ghahramani, Z. Training generative neural networks via maximum mean dis-crepancy optimization. In Proceedings of the Thirty-First Conference on Uncertainty in Artificial Intelligence, Amsterdam, The Netherlands, 12–16 July 2015; pp. 258–267. [Google Scholar]
- Lassner, C.; Pons-Moll, G.; Gehler, P.V. A generative model of people in clothing. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 853–862. [Google Scholar]
- Hwang, J.; Kim, K. An Efficient Domain-Adaptation Method using GAN for Fraud Detection. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 94–103. [Google Scholar] [CrossRef]
- Cai, Z.; Xiong, Z.; Xu, H.; Wang, P.; Li, W.; Pan, Y. Generative adversarial networks: A survey toward private and secure applications. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A survey on deep semi-supervised learning. IEEE Trans. Knowl. Data Eng. 2022, 1, 1–20. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, W.; Yang, Y.; Han, Z.; Xu, D.; Su, C. CNN-and GAN-based classification of malicious code families: A code visualization approach. Int. J. Intell. Syst. 2022, 37, 12472–12489. [Google Scholar] [CrossRef]
- Jiang, J.; Liu, F.; Liu, Y.; Tang, Q.; Wang, B.; Zhong, G.; Wang, W. A dynamic ensemble algorithm for anomaly detection in IoT imbalanced data streams. Comput. Commun. 2022, 194, 250–257. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, W.; Wang, W.; Jin, Z.; Zhao, C.; Cai, Z.; Chen, H. Cbgru: A detection method of smart contract vulnerability based on a hybrid model. Sensors 2022, 22, 3577. [Google Scholar] [CrossRef] [PubMed]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Park, S.-W.; Ko, J.-S.; Huh, J.-H.; Kim, J.-C. Review on Generative Adversarial Networks: Focusing on Computer Vision and Its Applications. Electronics 2021, 10, 1216. [Google Scholar] [CrossRef]
- Cauli, N.; Recupero, D.R. Survey on Videos Data Augmentation for Deep Learning Models. Futur. Internet 2022, 14, 93. [Google Scholar] [CrossRef]
- Ali-Gombe, A.; Elyan, E.; Savoye, Y.; Jayne, C. Few-shot classifier GAN. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Burks, R.; Islam, K.A.; Lu, Y.; Li, J. Data Augmentation with Generative Models for Improved Malware Detection: A Comparative Study. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019; pp. 0660–0665. [Google Scholar] [CrossRef]
- Jain, S.; Seth, G.; Paruthi, A.; Soni, U.; Kumar, G. Synthetic data augmentation for surface defect detection and classi-fication using deep learning. J. Intell. Manuf. 2022, 33, 1007–1020. [Google Scholar] [CrossRef]
- Torkzadehmahani, R.; Kairouz, P.; Paten, B. Dp-cgan: Differentially private synthetic data and label generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 1–7. [Google Scholar]
- Alqahtani, H.; Kavakli-Thorne, M.; Kumar, G. Applications of Generative Adversarial Networks (GANs): An Updated Review. Arch. Comput. Methods Eng. 2021, 28, 525–552. [Google Scholar] [CrossRef]
- Kim, J.; Jeong, K.; Choi, H.; Seo, K. GAN-based anomaly detection in imbalance problems. In Proceedings of the Computer Vision–ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; pp. 128–145. [Google Scholar] [CrossRef]
- Saqlain, A.S.; Fang, F.; Ahmad, T.; Wang, L.; Abidin, Z.-U. Evolution and effectiveness of loss functions in generative adversarial networks. China Commun. 2021, 18, 45–76. [Google Scholar] [CrossRef]
- Ba, H. Improving Detection of Credit Card Fraudulent Transactions using Generative Adversarial Networks. arXiv 2019, arXiv:1907.03355. [Google Scholar]
- Sethia, A.; Patel, R.; Raut, P. Data augmentation using generative models for credit card fraud detection. In Proceedings of the 4th International Conference on Computing Communication and Automation (ICCCA), Greater Noida, India, 14–15 December 2018; pp. 1–6. [Google Scholar]
- Liu, H.; Lang, B. Machine Learning and Deep Learning Methods for Intrusion Detection Systems: A Survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef] [Green Version]
- Charitou, C.; Dragicevic, S.; Garcez, A.D.A. Synthetic Data Generation for Fraud Detection using GANs. arXiv 2021, arXiv:2109.12546. [Google Scholar]
- Ngwenduna, K.S.; Mbuvha, R. Alleviating class imbalance in actuarial applications using generative adversarial net-works. Risks 2021, 9, 49. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Eom, S.; Huh, J.-H. The Opening Capability for Security against Privacy Infringements in the Smart Grid Environment. Mathematics 2018, 6, 202. [Google Scholar] [CrossRef] [Green Version]
- Eom, S.; Huh, J.-H. Group signature with restrictive linkability: Minimizing privacy exposure in ubiquitous environment. J. Ambient. Intell. Humaniz. Comput. 2018, 1, 1–11. [Google Scholar] [CrossRef]
- Chen, J.; Tam, D.; Raffel, C.; Bansal, M.; Yang, D. An empirical survey of data augmentation for limited data learning in NLP. arXiv 2021, arXiv:2106.07499. [Google Scholar]
- Laddha, S.; Kumar, V. DGCNN: Deep convolutional generative adversarial network based convolutional neural net-work for diagnosis of COVID-19. Multimed. Tools Appl. 2022, 81, 31201–31218. [Google Scholar] [CrossRef] [PubMed]
- Talavera, E.; Iglesias, G.; González-Prieto, Á.; Mozo, A.; Gómez-Canaval, S. Data Augmentation techniques in time series domain: A survey and taxonomy. arXiv 2022, arXiv:2206.13508. [Google Scholar]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the International Interdisciplinary PhD Workshop (IIPhDW), Swinoujscie, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar] [CrossRef]
- Antoniou, A.; Storkey, A.; Edwards, H. Data augmentation generative adversarial networks. arXiv 2017, arXiv:1711.04340. [Google Scholar]
- Saxena, D.; Cao, J. Generative adversarial networks (GANs) challenges, solutions, and future directions. ACM Com-Puting Surv. (CSUR) 2021, 54, 1–42. [Google Scholar]
- Chen, H. Challenges and Corresponding Solutions of Generative Adversarial Networks (GANs): A Survey Study. J. Physics: Conf. Ser. 2021, 1827, 012066. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, B.; Lv, Y.; Shi, T.; Chang, F. Data Augment in Imbalanced Learning Based on Generative Adversarial Networks. In Neural Information Processing, Proceedings of the 26th International Conference, ICONIP 2019, Sydney, NSW, Australia, 12–15 December 2019; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; Part IV 26; pp. 21–30. [Google Scholar] [CrossRef]
- Xia, X.; Pan, X.; Li, N.; He, X.; Ma, L.; Zhang, X.; Ding, N. GAN-based anomaly detection: A review. Neurocomputing 2022, 493, 497–535. [Google Scholar] [CrossRef]
- Niu, X.; Wang, L.; Yang, X. A comparison study of credit card fraud detection: Supervised versus unsuper-vised. arXiv 2019, arXiv:1904.10604. [Google Scholar]
- Mullick, S.S.; Datta, S.; Das, S. Generative adversarial minority oversampling. In Proceedings of the IEEE/CVF Interntional Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1695–1704. [Google Scholar]
- Kodali, N.; Abernethy, J.; Hays, J.; Kira, Z. On Convergence and Stability of GANs. arXiv 2017, arXiv:1705.07215. [Google Scholar]
- Kossaifi, J.; Tran, L.; Panagakis, Y.; Pantic, M. Gagan: Geometry-aware generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 878–887. [Google Scholar]
- Mangalam, K.; Garg, R. Overcoming mode collapse with adaptive multi adversarial training. arXiv 2021, arXiv:2112.14406. [Google Scholar]
- Wang, Z.; She, Q.; Ward, T.E. Generative adversarial networks in computer vision: A survey and taxonomy. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2017; pp. 214–223. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Ferreira, F.; Lourenço, N.; Cabral, B.; Fernandes, J.P. When Two are Better Than One: Synthesizing Heavily Un-balanced Data. IEEE Access 2021, 9, 150459–150469. [Google Scholar] [CrossRef]
- Zhao, Z.; Kunar, A.; Birke, R.; Chen, L.Y. Ctab-gan: Effective table data synthesizing. In Proceedings of the Asian Conference on Machine Learning, Online, 17–19 November 2021; pp. 97–112. Available online: https://proceedings.mlr.press/v157/zhao21a (accessed on 13 February 2023).
- Engelmann, J.; Lessmann, S. Conditional Wasserstein GAN-based oversampling of tabular data for imbalanced learning. Expert Syst. Appl. 2021, 174, 114582. [Google Scholar] [CrossRef]
- Choi, E.; Biswal, S.; Malin, B.; Duke, J.; Stewart, W.F.; Sun, J. Generating multi-label discrete patient records using generative adversarial networks. In Proceedings of the Machine learning for Healthcare Conference, Boston, MA, USA, 18–19 August 2017; pp. 286–305. [Google Scholar]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling tabular data using conditional gan. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Park, N.; Mohammadi, M.; Gorde, K.; Jajodia, S.; Park, H.; Kim, Y. Data synthesis based on generative adversarial networks. arXiv 2018, arXiv:1806.03384. [Google Scholar] [CrossRef] [Green Version]
- Zheng, P.; Yuan, S.; Wu, X.; Li, J.; Lu, A. One-class adversarial nets for fraud detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HA, USA, 29–31 January 2019; Volume 33, pp. 1286–1293. [Google Scholar]
- Shehnepoor, S.; Togneri, R.; Liu, W.; Bennamoun, M. ScoreGAN: A Fraud Review Detector Based on Regulated GAN With Data Augmentation. IEEE Trans. Inf. Forensics Secur. 2021, 17, 280–291. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Lei, K.; Xie, Y.; Zhong, S.; Dai, J.; Yang, M.; Shen, Y. Generative adversarial fusion network for class imbalance credit scoring. Neural Comput. Appl. 2020, 32, 8451–8462. [Google Scholar] [CrossRef]
- Vijayaraghavan, S.; Guan, T. GAN based Data Augmentation to Resolve Class Imbalance. arXiv 2022, arXiv:2206.05840. [Google Scholar]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications. IEEE Trans. Knowl. Data Eng. 2021, 35, 3313–3332. [Google Scholar] [CrossRef]
- Pandey, A.; Bhatt, D.; Bhowmik, T. Limitations and Applicability of GANs in Banking Domain. In Proceedings of the Workshop on Applied Deep Generative Networks co-located with 24th European Conference on Artificial Intelligence (ECAI 2020), Santiago de Compostela, Spain, 29 August 2020. [Google Scholar]
- Ramponi, G.; Protopapas, P.; Brambilla, M.; Janssen, R. T-cgan: Conditional generative adversarial network for data augmentation in noisy time series with irregular sampling. arXiv 2018, arXiv:1811.08295. [Google Scholar]
- Vega-Márquez, B.; Rubio-Escudero, C.; Riquelme, J.C.; Nepomuceno-Chamorro, I. Creation of synthetic data with conditional generative adversarial networks. In Proceedings of the 14th International Conference on Soft Computing Models in Industrial and Environmental Applications (SOCO 2019), Seville, Spain, 13–15 May 2019; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 231–240. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy | Precision | Recall | F-Measure |
|---|---|---|---|---|
| Duo-GAN | — | — | — | — |
| C-GAN | 0.826 | — | — | 0.509 |
| CT-GAN | 21.51% | — | — | CTGAN = 0.274 |
| SDG GAN | — | 0.9863 | 0.8090 | 0.8889 |
| OCAN | 0.826 | — | — | 0.509 |
| cWGAN | — | — | — | — |
| ScoreGAN | — | — | — | — |
| GAN-RF | 99.83 | GAN-RF = 99.88 | GAN-RF = 99.9 | GAN-RF = 99.90 |
| Tuned GAN | 0.99963 | GAN = 0.93204 | — | GAN = 0.82051 |
| Majority–minority GAN | — | — | — | Bank B = 0.552 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Strelcenia, E.; Prakoonwit, S. A Survey on GAN Techniques for Data Augmentation to Address the Imbalanced Data Issues in Credit Card Fraud Detection. Mach. Learn. Knowl. Extr. 2023, 5, 304-329. https://doi.org/10.3390/make5010019
Strelcenia E, Prakoonwit S. A Survey on GAN Techniques for Data Augmentation to Address the Imbalanced Data Issues in Credit Card Fraud Detection. Machine Learning and Knowledge Extraction. 2023; 5(1):304-329. https://doi.org/10.3390/make5010019
Chicago/Turabian StyleStrelcenia, Emilija, and Simant Prakoonwit. 2023. "A Survey on GAN Techniques for Data Augmentation to Address the Imbalanced Data Issues in Credit Card Fraud Detection" Machine Learning and Knowledge Extraction 5, no. 1: 304-329. https://doi.org/10.3390/make5010019
APA StyleStrelcenia, E., & Prakoonwit, S. (2023). A Survey on GAN Techniques for Data Augmentation to Address the Imbalanced Data Issues in Credit Card Fraud Detection. Machine Learning and Knowledge Extraction, 5(1), 304-329. https://doi.org/10.3390/make5010019