
Alternative Formulations of Decision Rule Learning from Neural Networks †


Abstract
:1. Introduction
- We propose a new formulation of a trainable OR neuron based on continuously trainable weights without the need to binarize the weights, in the same way that the AND neuron is formulated. Moreover, our new formulation of the OR neuron is generalized in the same way as our AND neuron formulation in that inputs can now be negated by means of negative weights. This creates more flexibility in the training process.
- We further added a new trainable “NAND neuron” (Not AND), which is also based on the same model of trainable continuous weights.
- From De Morgan’s law, we know that an AND-OR logic network is logically equivalent to a NAND-NAND logic network. Therefore, given our formulation of a trainable NAND neuron, we propose a new neural net architecture called NN-Net (short for NAND-NAND Net) for decision rule learning as an alternative to DR-Net. We also modified the formulation of DR-Net with our new formulations of the AND and OR neurons.
- Further, given our new formulations of Boolean logic operators as trainable neurons with continuous weights, existing sparsity-promoting neural net training techniques like reweighted regularization can be directly applied to derive simpler decision rule sets, in addition to a stochastic regularization approach that was previously used in [11].
- In addition, we added many new experiments in our experimental evaluation section. In particular, we evaluated our new formulations of DR-Net and NN-Net, together with two sparsity-promoting regularization approaches. We also added new experiments to analyze the training process and show the effects of the proposed sparsity-promoting mechanisms, including the analysis of training convergence and the effects of using different combinations of regularization coefficients, which affect the model complexities.
2. Background
2.1. Binarization of Tabular Data
2.2. The Decision Rule Learning Problem
3. Boolean Logic Operators as Trainable Neurons
3.1. AND Neuron
3.2. OR Neuron
3.3. NAND Neuron
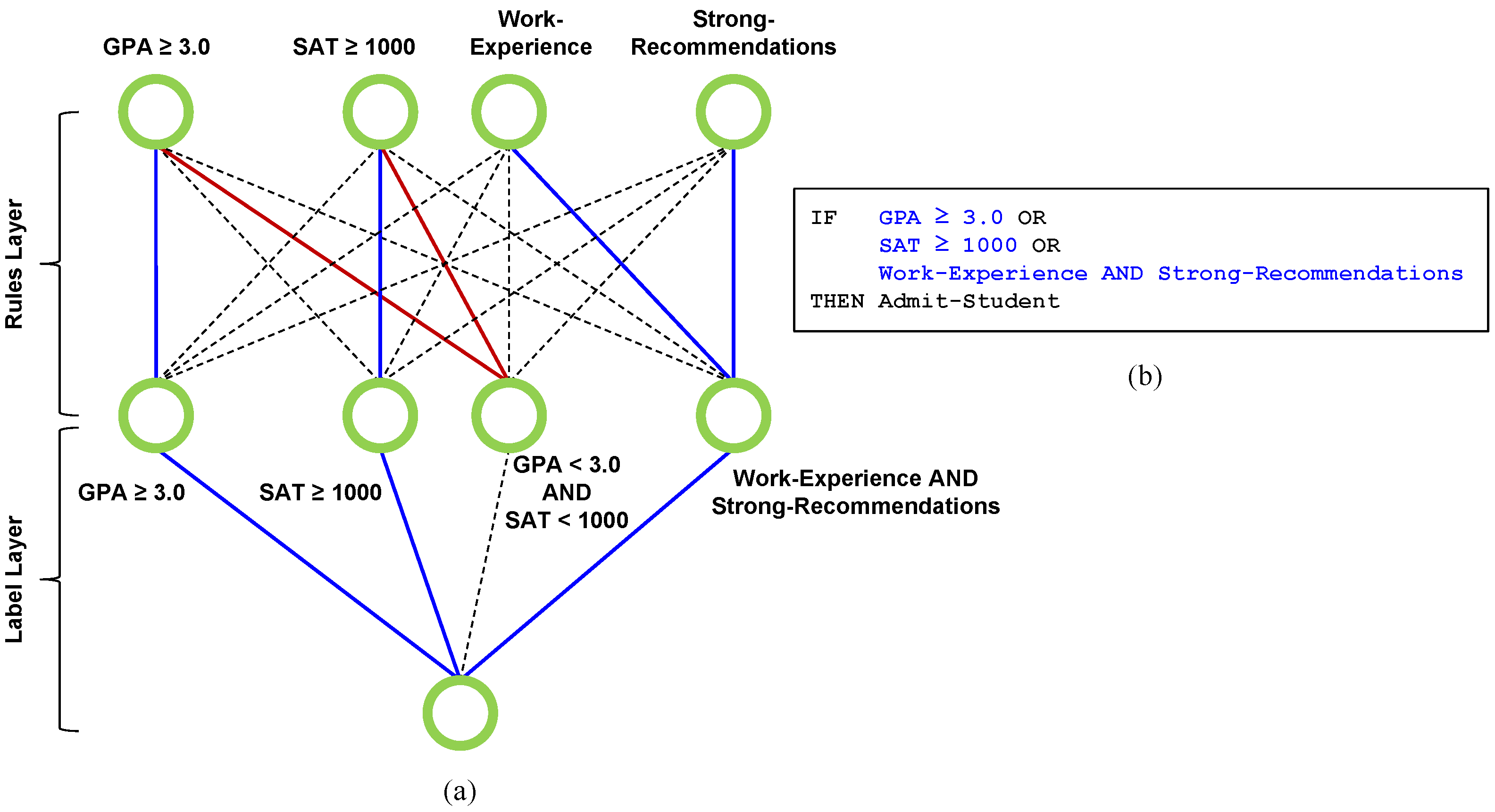
4. Design Rule Learning as a Trainable Neural Network
4.1. Decision Rules Network
4.2. NAND-NAND Network
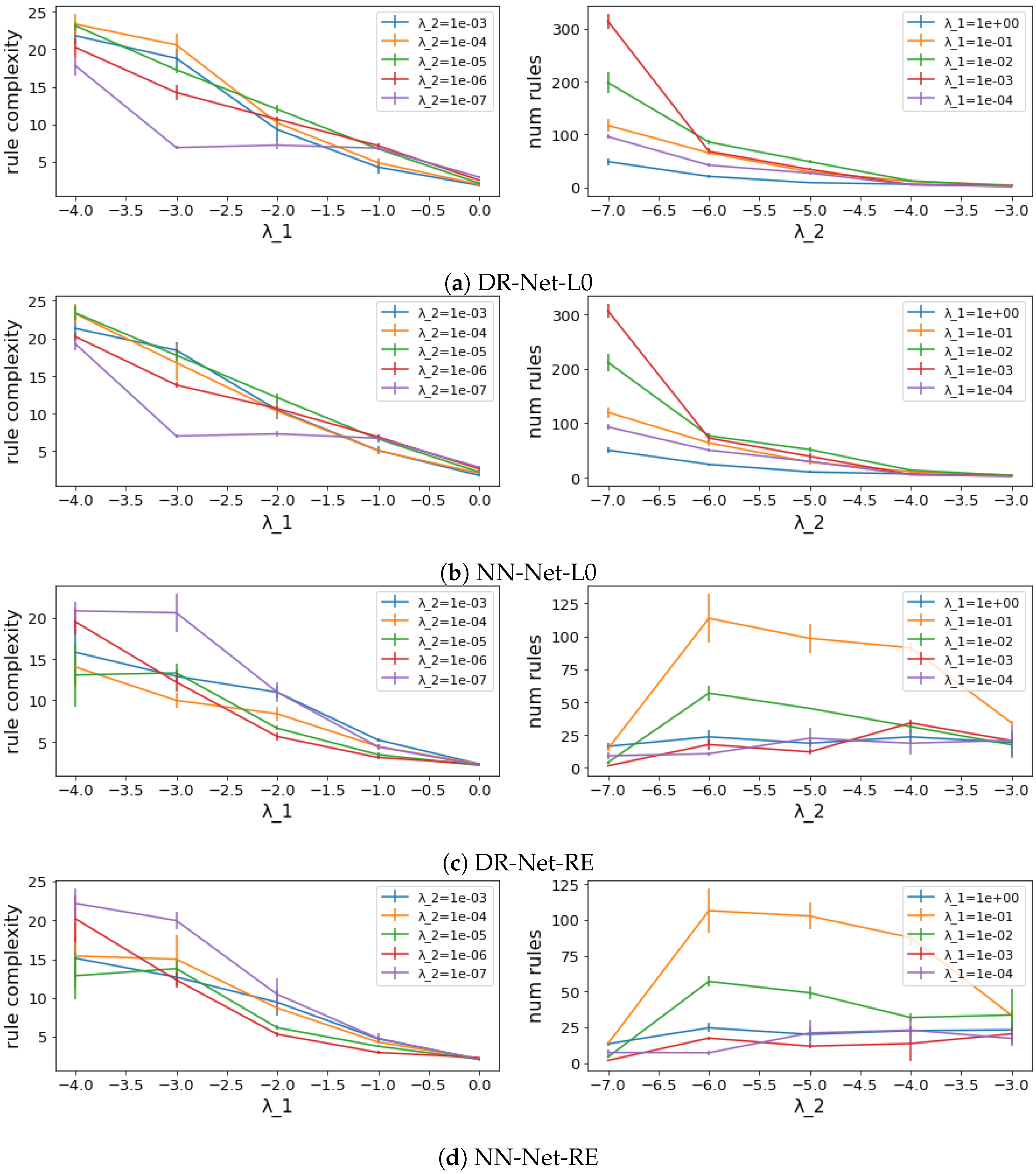
5. Simplifying Rules through Sparsity
5.1. Sparsification with Regularization
5.2. Sparsification with Reweighted Regularization
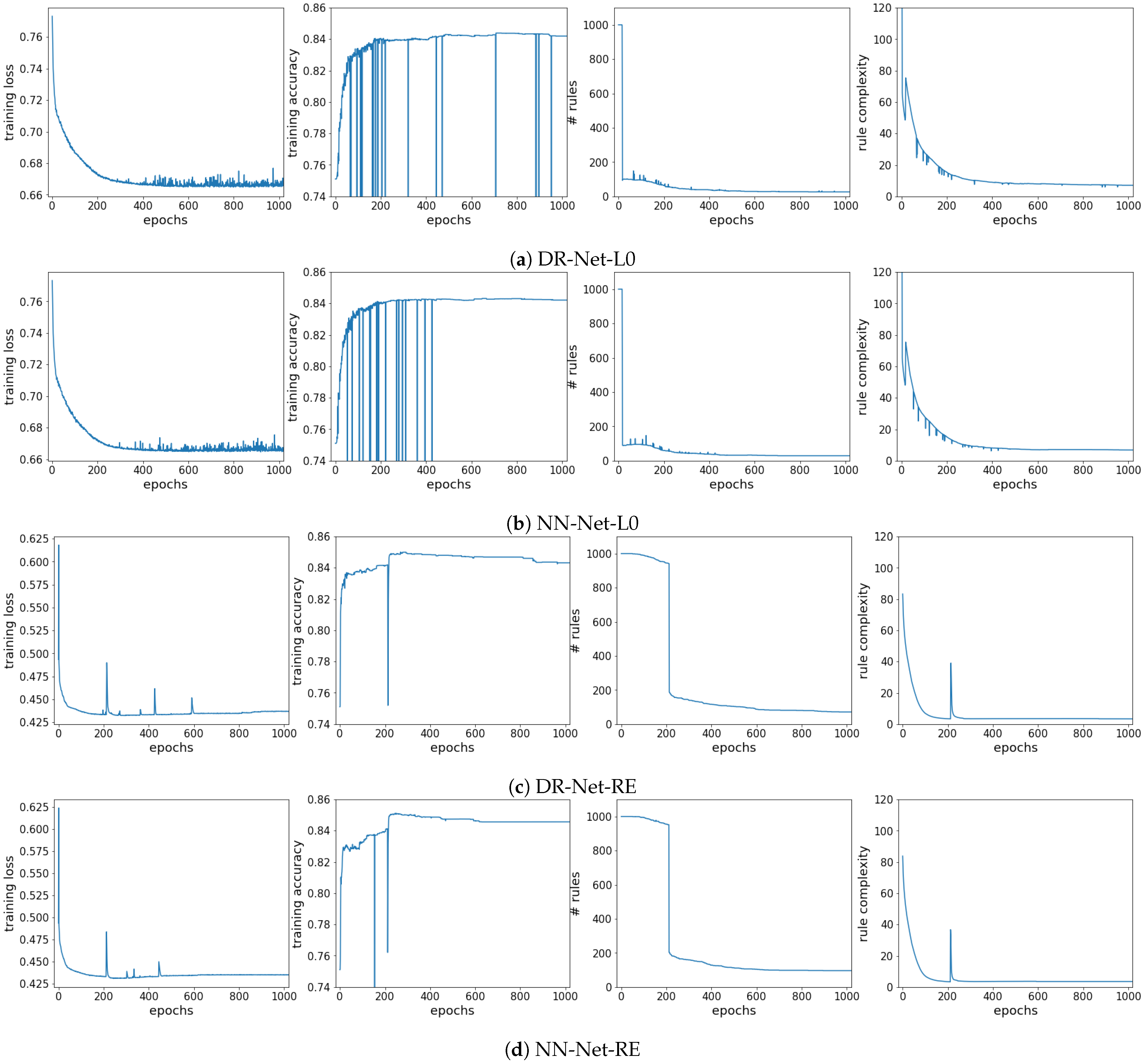
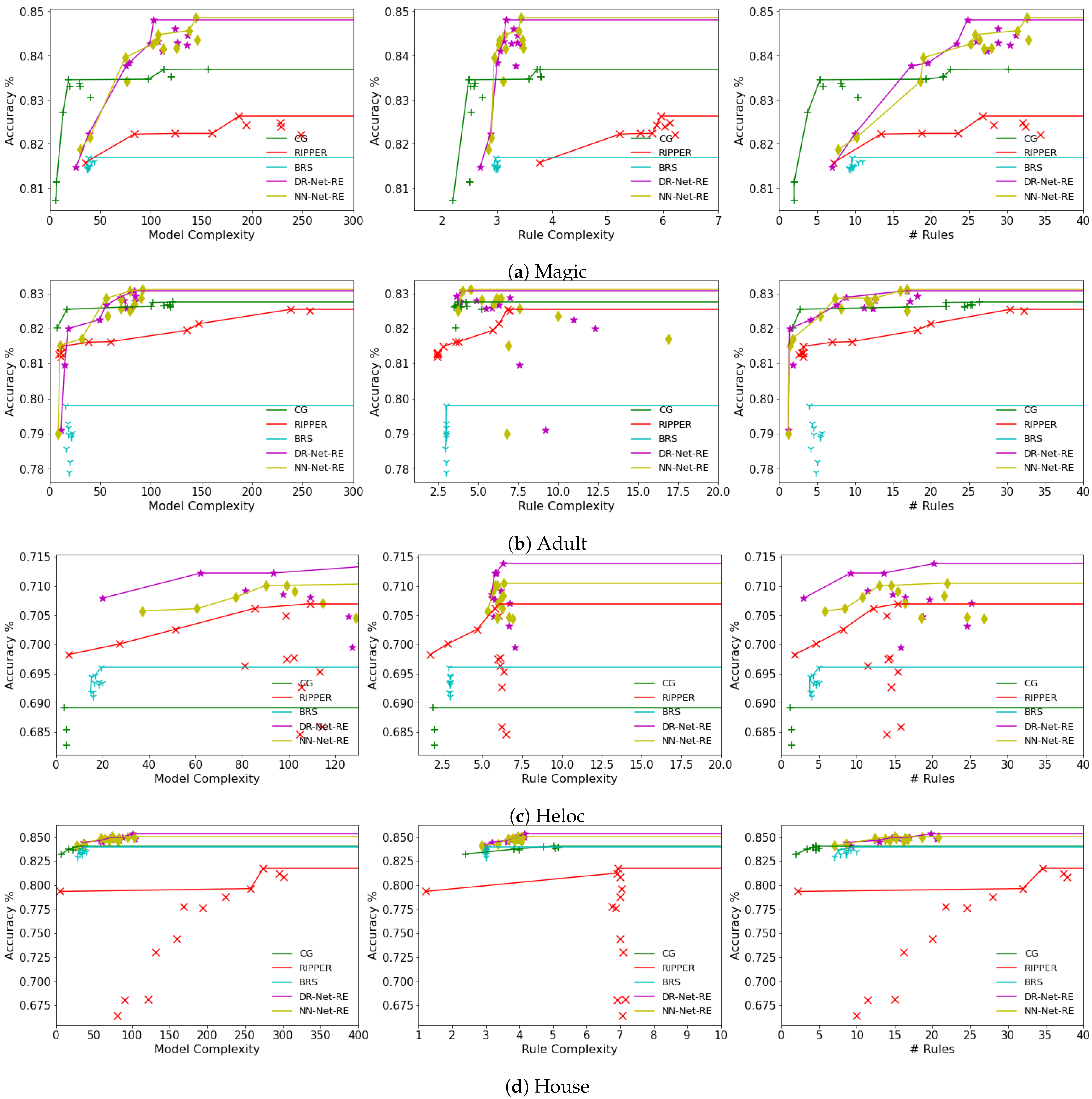
6. Experimental Evaluation
6.1. Training Analysis
6.2. Classification Performance and Interpretability
7. Related Work
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Rudin, C. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Cohen, W.W. Fast Effective Rule Induction. In Proceedings of the Twelfth International Conference on Machine Learning, Tahoe City, CA, USA, 9–12 July 1995; Morgan Kaufmann: Burlington, MA, USA, 1995; pp. 115–123. [Google Scholar]
- Su, G.; Wei, D.; Varshney, K.R.; Malioutov, D.M. Interpretable Two-level Boolean Rule Learning for Classification. arXiv 2015, arXiv:1511.07361. [Google Scholar]
- Lakkaraju, H.; Bach, S.H.; Leskovec, J. Interpretable Decision Sets: A Joint Framework for Description and Prediction. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’16), New York, NY, USA, 13–17 August 2016; pp. 1675–1684. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Rudin, C.; Doshi-Velez, F.; Liu, Y.; Klampfl, E.; MacNeille, P. A Bayesian Framework for Learning Rule Sets for Interpretable Classification. J. Mach. Learn. Res. 2017, 18, 1–37. [Google Scholar]
- Dash, S.; Günlük, O.; Wei, D. Boolean Decision Rules via Column Generation. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS’18), Red Hook, NY, USA, 13–18 December 2018; pp. 4660–4670. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Arık, S.O.; Pfister, T. Tabnet: Attentive interpretable tabular learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Katzir, L.; Elidan, G.; El-Yaniv, R. Net-DNF: Effective Deep Modeling of Tabular Data. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Qiao, L.; Wang, W.; Lin, B. Learning Accurate and Interpretable Decision Rule Sets from Neural Networks. In Proceedings of the AAAI, Virtually, 2–9 February 2021. [Google Scholar]
- Bengio, Y.; Léonard, N.; Courville, A. Estimating or Propagating Gradients through Stochastic Neurons for Conditional Computation. arXiv 2013, arXiv:1308.3432. [Google Scholar]
- Candès, E.; Wakin, M.; Boyd, S.P. Enhancing Sparsity by Reweighted L1 Minimization. J. Fourier Anal. Appl. 2007, 14, 877–905. [Google Scholar] [CrossRef]
- Louizos, C.; Welling, M.; Kingma, D.P. Learning Sparse Neural Networks through L0 Regularization. arXiv 2017, arXiv:1712.01312. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both Weights and Connections for Efficient Neural Network. arXiv 2015, arXiv:1506.02626. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 25 June 2023).
- Dash, S.; Malioutov, D.M.; Varshney, K.R. Screening for learning classification rules via Boolean compressed sensing. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3360–3364. [Google Scholar]
- Chen, C.; Lin, K.; Rudin, C.; Shaposhnik, Y.; Wang, S.; Wang, T. An Interpretable Model with Globally Consistent Explanations for Credit Risk. arXiv 2018, arXiv:1811.12615. [Google Scholar]
- Vanschoren, J.; van Rijn, J.N.; Bischl, B.; Torgo, L. OpenML: Networked Science in Machine Learning. SIGKDD Explor. 2013, 15, 49–60. [Google Scholar] [CrossRef] [Green Version]
- Arya, V.; Bellamy, R.K.E.; Chen, P.Y.; Dhurandhar, A.; Hind, M.; Hoffman, S.C.; Houde, S.; Liao, Q.V.; Luss, R.; Mojsilović, A.; et al. One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques. arXiv 2019, arXiv:1909.03012. [Google Scholar]
- Breiman, L.; Friedman, J.; Stone, C.; Olshen, R. Classification and Regression Trees; The Wadsworth and Brooks-Cole Statistics-Probability Series; Taylor & Francis: Abingdon, UK, 1984. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Clark, P.; Niblett, T. The CN2 Induction Algorithm. Mach. Learn. 1989, 3, 261–283. [Google Scholar] [CrossRef]
- Liu, B.; Hsu, W.; Ma, Y. Integrating Classification and Association Rule Mining. In Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining (KDD’98), New York, NY, USA, 27–31 August 1998; pp. 80–86. [Google Scholar]
- Crama, Y.; Hammer, P.L.; Ibaraki, T. Cause-Effect Relationships and Partially Defined Boolean Functions. Ann. Oper. Res. 1988, 16, 299–325. [Google Scholar] [CrossRef] [Green Version]
- Boros, E.; Hammer, P.L.; Ibaraki, T.; Kogan, A.; Mayoraz, E.; Muchnik, I. An implementation of logical analysis of data. IEEE Trans. Knowl. Data Eng. 2000, 12, 292–306. [Google Scholar] [CrossRef] [Green Version]
- Qiao, L.; Wang, W.; Dasgupta, S.; Lin, B. Rethinking Logic Minimization for Tabular Machine Learning. IEEE Trans. Artif. Intell. 2022, 1–12. [Google Scholar] [CrossRef]
- Rivest, R.L. Learning Decision Lists. Mach. Learn. 1987, 2, 229–246. [Google Scholar] [CrossRef] [Green Version]
- Bertsimas, D.; Chang, A.; Rudin, C. ORC: Ordered Rules for Classification a Discrete Optimization Approach to Associative Classification; Massachusetts Institute of Technology, Operations Research Center: Cambridge, MA, USA, 2012. [Google Scholar]
- Letham, B.; Rudin, C.; McCormick, T.H.; Madigan, D. Interpretable classifiers using rules and Bayesian analysis: Building a better stroke prediction model. arXiv 2015, arXiv:1511.01644. [Google Scholar] [CrossRef]
- Rokach, L.; Maimon, O. Top–Down Induction of Decision Trees Classifiers—A survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2005, 35, 476–487. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Qiao, L.; Lin, B. Disjunctive Threshold Networks for Tabular Data Classification. IEEE Open J. Comput. Soc. 2023, 4, 185–194. [Google Scholar] [CrossRef]
- Wang, W.; Qiao, L.; Lin, B. Tabular machine learning using conjunctive threshold neural networks. Mach. Learn. Appl. 2022, 10, 100429. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Magic | Adult | Heloc | House |
|---|---|---|---|---|
| Interpretable | ||||
| NN-Net-RE | 84.14 | 82.59 | 70.76 | 84.89 |
| (0.69) | (0.23) | (0.66) | (0.46) | |
| NN-Net-L0 | 84.45 | 83.13 | 70.71 | 86.17 |
| (0.51) | (0.59) | (0.67) | (0.50) | |
| DR-Net-RE | 84.63 | 82.50 | 71.05 | 84.84 |
| (0.53) | (0.68) | (0.57) | (0.66) | |
| DR-Net-L0 | 84.10 | 83.09 | 70.07 | 85.90 |
| (0.82) | (0.51) | (0.89) | (0.50) | |
| DR-Net | 84.42 | 82.97 | 69.71 | 85.71 |
| (0.53) | (0.51) | (1.05) | (0.40) | |
| CG | 83.68 | 82.67 | 68.65 | 83.90 |
| (0.87) | (0.48) | (3.48) | (0.18) | |
| BRS | 81.44 | 79.35 | 69.42 | 83.04 |
| (0.61) | (1.78) | (3.72) | (0.11) | |
| RIPPER | 82.22 | 81.67 | 69.67 | 82.47 |
| (0.51) | (1.05) | (2.09) | (1.84) | |
| CART | 80.56 | 78.87 | 60.61 | 82.37 |
| (0.86) | (0.12) | (2.83) | (0.29) | |
| Uninterpretable | ||||
| RF | 86.47 | 82.64 | 70.30 | 88.70 |
| (0.54) | (0.49) | (3.70) | (0.28) | |
| DNN | 87.07 | 84.33 | 70.64 | 88.84 |
| (0.71) | (0.42) | (3.37) | (0.26) | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, L.; Wang, W.; Lin, B. Alternative Formulations of Decision Rule Learning from Neural Networks. Mach. Learn. Knowl. Extr. 2023, 5, 937-956. https://doi.org/10.3390/make5030049
Qiao L, Wang W, Lin B. Alternative Formulations of Decision Rule Learning from Neural Networks. Machine Learning and Knowledge Extraction. 2023; 5(3):937-956. https://doi.org/10.3390/make5030049
Chicago/Turabian StyleQiao, Litao, Weijia Wang, and Bill Lin. 2023. "Alternative Formulations of Decision Rule Learning from Neural Networks" Machine Learning and Knowledge Extraction 5, no. 3: 937-956. https://doi.org/10.3390/make5030049
APA StyleQiao, L., Wang, W., & Lin, B. (2023). Alternative Formulations of Decision Rule Learning from Neural Networks. Machine Learning and Knowledge Extraction, 5(3), 937-956. https://doi.org/10.3390/make5030049