3.1. Bias in the German Credit Risk Dataset
The German Credit Risk data set (
https://archive.ics.uci.edu/dataset/144/statlog+german+credit+data, accessed on 17 July 2023) suffers from a gender bias, as shown in
Figure 2. In the context of fairness, bias systematically favors a privileged group while penalizing an unprivileged group [
18]. Privileged and unprivileged groups are determined by the distribution of a
favorable label [
18] regarding a
protected attribute [
46,
47]. Discrimination occurs when an unprivileged group is systematically disadvantaged because of a protected characteristic. Notice that discrimination can occur directly or indirectly.
Direct discrimination is based on a protected attribute, while
indirect discrimination is caused by apparently neutral features that are highly correlated with the protected attribute [
37]. To quantify bias, we split the data into four groups [
10]:
- DP
Deprived (unprivileged) group with Positive (favorable) label
- DN
Deprived (unprivileged) group with Negative (unfavorable) label
- FP
Favored (privileged) group with Positive (favorable) label
- FN
Favored (privileged) group with Negative (unfavorable) label
Consider
Figure 2 that displays the distribution of the favorable label
good credit risk conditioned on the protected attribute
gender: This reveals a gender bias, as the favored group
male receives the positive label more likely than the deprived group
female.
By now, we have presented bias mostly narratively, raising the question: How can it be quantified? Metrics measuring bias are called bias-detection metrics. Most bias-detection metrics measure conditional classification model performance differences. For instance, a fair classifier requires that the recall of the model— in our case, the correctly detected good credit risks— is stable with respect to gender as a protected attribute.
Definition 1 (Protected Attribute). Let S be the protected attribute and let and mark the privileged and unprivileged groups, respectively.
Definition 2 (Favorable Label). Let be a prediction, where denotes the favorable label and the unfavorable outcome label, respectively.
In the following, we present five bias-detection metrics: Statistical Parity [
48], Equalized Odds [
23], Equalized Opportunity [
23], False Positive Error Rate Balance [
49], and Predictive Parity [
49]. According to the definition of Statistical Parity (SP) [
48], a classifier is fair if the probability of receiving the unfavorable label is distributed equally across privileged and unprivileged groups, i.e.,
where
P is the probability of the predictive outcome
conditioned on the protected attribute
S. When we now condition the probability of receiving the unfavorable label, i.e.,
, on the privileged and unprivileged groups
and
, we obtain
and
, respectively. From the definition in Equation (
1) directly follows the assumption that Statistical Parity exists if the conditional difference of receiving the unfavorable label is zero between the privileged and unprivileged groups. The differential form of (
1) is given in Equation (
2), which states that a fair classifier should yield a Statistical Parity estimate
, i.e.,
The main difference between Statistical Parity compared to the remaining bias-detection metrics is that it does not require access to the ground truth, as it solely relies on the prediction conditioned on a known protected attribute. In contrast, Equalized Odds (EqOdds) [
23] includes the ground truth label
y in the condition of each side:
Equation (
4) formulates EqOdds as an average of two differences. Each part of the sum is a performance difference between the privileged and the unprivileged group. The conditional probability is now replaced by performance metrics of a binary classification. Equalized Odds likewise considers the false positive (
) and the true positive rate (
):
In fact, the idea of (
3) forms the basis of Equal Opportunity (EqOpp) [
23], False Positive Error Rate Balance (FPERB) [
49], and Predictive Parity (PP) [
49], where EqOpp uses the
in (
5) and FPERB the
in (
6). Predictive Parity is slightly different as it exploits the false discovery rate (
) in (
7), calculated by
.
Our explanatory and interactive
FairCaipi cycle will present the bias-detection metrics, as defined above, to the user. Its purpose is to notify and educate users about the impact of their changes have on the fairness of the classifier. Furthermore, Statistical Parity (
2) will play an important role in the benchmark test in the simulation study as Reweighing is optimized for Statistical Parity.
3.2. Explanatory Interactive Machine Learning
The state-of-the-art XIML algorithm
Caipi [
14] involves users by iteratively including prediction and explanation corrections.
Caipi has three prediction outcome states:
Right for the
Right
Reasons (
RRR),
Right for the
Wrong
Reasons (
RWR), or
Wrong for the
Wrong
Reasons (
W). The two erroneous cases require human intervention. Although users correct the label in the
W case, they give feedback for wrong explanations in the
RWR case, where so-called counterexamples are generated. Counterexamples are additional novel instances, containing solely the decisive features. They are supposed to shape the model’s mechanism into a presumably correct direction from a user’s perspective. Practically, using suitable data augmentation procedures, a single explanation correction yields multiple different counterexamples. For the remainder of this work, let us assume that a procedure
Gen generates counterexamples using a user-induced explanation correction.
Definition 3 (Counterexample Generation). Consider the prediction and suppose that, according to a user, the vector is decisive for , in the sense that the attribution effect of each non-zero feature in exceeds a threshold value, where vector is derived from x such that the set of non-zero components of is a subset of the set of non-zero components in x. Let us assume a procedure Gen that takes x, , , c as inputs and returns counterexample feature and target data sets and . For , we repeat for c times. And for , x is repeated c times. Whenever is not set in , is disturbed, e.g., by randomization.
We use
SHapley Additive exPlanations (SHAP) [
50] to obtain local explanations of a classification model, whereas traditional
Caipi uses LIME. SHAP tends to be a fruitful option at this point, as LIME’s performance is sensitive to segmentation algorithms [
51]. SHAP, in contrast, performs reliably on tabular data [
50]. The SHAP explanation model approximates a model
f for a specific input
x by an explanation
g that uses a simplified input
that maps to the original input
x via a mapping
. It ensures that
whenever
and where
and
M is the number of simplified input features. The SHAP method relies on Shapley values, which measure the importance of a feature
for a prediction by calculating the impact of knowledge about this feature for the prediction. The contribution of a feature value
to a prediction outcome is known as the SHAP value
, such that the sum of all feature attributions approximates the output
of the original model.
The SHAP method is built upon three desirable properties:
local accuracy,
missingness, and
consistency [
50]. SHAP’s simplified representation of a classification model
including a simplified feature space representation
, i.e.,
directly satisfies the
local accuracy property, whenever
holds [
50]. SHAP approximates a model
f for an input
x in the sense that attributions are
added such that the explanation model
for simplified input
should at least match the output of the original model
: In the vanilla case, attributions
are added linearly, where each
represents the importance of a feature (or a combination of a feature subset) with size
M. The baseline attribution
is calculated by
.
Apart from local accuracy, SHAP satisfies the missingness and consistency properties [
50].
Missingness states that zero (in this case missing) feature values have an attribution value of zero. However,
consistency guarantees that a stronger feature importance for
f is also represented by the attribution value
. Ensuring all three properties, SHAP attributions are given as:
where
represents all
vectors where the non-zero entries are a subset of the non-zero entries in
,
is the number of non-zero entries in
,
and
denotes setting
. The right-hand side of Equation (
9) reflects the original idea behind Shapley values, as it is the difference for
between including versus excluding the
i-th feature of
. Equation (
9) is the single possible solution that follows from the properties: local accuracy, missingness, and consistency [
50]. Young (1985) [
52] originally proves that Shapley values are the only possible representations that satisfy local accuracy and missingness. Young (1985) [
52] utilizes an additional axiom, which Lundberg and Lee (2017) prove to be non-essential. According to Lundberg and Lee (2017), the missingness property is non-essential for Shapley values themselves. However, it is essential for additive feature attribution methods such as SHAP.
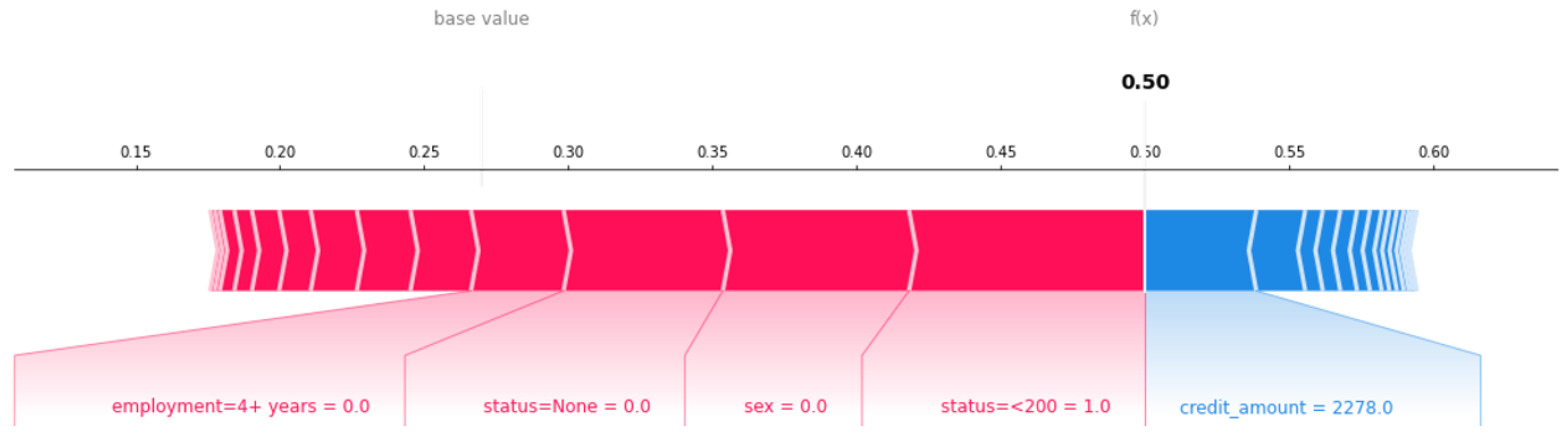
Consider
Figure 3 as an exemplary SHAP explanation for an arbitrary instance and a classification model with a prediction score of
, where values lower than
indicate a good credit risk and values higher or equal to
, a bad credit risk. SHAP’s base value lies approximately at
. From this point, some attributes have a positive impact, i.e., a positive attribution value—they drag the decision toward bad credit risk. Here, having a bank account’s
that is not None (it exists), but the average incoming monthly payment within the last year is smaller than 200 German Mark, being female (
) and not been employed for over 4 years (
) are the major reasons for bad credit risk. On the contrary, the investigated instance requested a
of 2278 German Mark, which is the only feature that receives a negative attribution value and thus contributes to a good credit risk.
CAIPI has a local explanation procedure that takes a feature instance and a classification model as input and reveals the decisive features to the user. Mathematically, our procedure Exp is built upon SHAP.
Definition 4 (Local Explanation).
Let ϕ be attribution values assigned to x, highlighting the importance of each feature in x for (9). Furthermore, let α be an importance threshold. Let denote the set of features such that holds. We assume an explanation procedure Exp that takes x, f, and α as input and returns e. CAIPI [
14] leverages user feedback regarding the model’s prediction and explanation depending on the prediction outcome state. In each iteration, it selects the most informative instance from an unlabeled dataset—that is, the instance with prediction score closets to the decision boundary (in our case
) regarding the classifier trained on a smaller pool of labeled data. We argue that this instance is
most informative, as we associate predictions close to the decision boundary with high uncertainty. Knowledge about its label maximizes the information gain for the classifier in the next iteration. The procedure
MII retrieves the index of the most informative instance. At this point, we assume access to both the prediction scores and the decision boundary.
Definition 5 (Most Informative Instance). Let the procedure MII take a set of predictions and a decision boundary β as input. It returns the index m of the most informative instance, i.e., the prediction with the score closest to β.
CAIPI requires human feedback at two points: to evaluate the correctness of the prediction and the explanation. In the second case, by correcting the local explanation, users can induce a desirable decision mechanism. We denote the interaction points by the procedure
Interact and summarize
Caipi in Algorithm 1. In each iteration,
Caipi trains a model on the labeled data (line 2) and draws predictions on the unlabeled feature instances (line 3) to obtain the most informative instance (line 4). The user examines the prediction and provides the correct label if the prediction is incorrect (line 7). Otherwise, if the prediction is correct,
Caipi presents the corresponding local explanation, which can be corrected by the user if necessary (line 9). If the explanation is correct, the instance is added to the labeled dataset (line 12), otherwise, counterexamples are generated (line 14). The current most informative instance is removed from the set of unlabeled data to prepare the next iteration (line 15). In contrast to the original
Caipi algorithm [
14], we formalize each component explicitly. We will utilize our explicit formalization to adapt
Caipi to fair ML in the next section.
| Algorithm 1 Caipi [] [14] |
![Make 05 00076 i001]() |
3.3. Fair Explanatory and Interactive Machine Learning
FairCaipi adapts the original
Caipi framework with a fairness objective in two ways: (i) it evaluates the local explanation to detect biased decision-making, and (ii) it thus accounts for protected attributes during the counterexample generation. Regarding adaptation (i), we recapture the groups DP, DN, FP, and FN from
Section 3.1, where D indicates the deprived and F the favored group, each with either the desirable positive or undesirable negative outcome, P or N, respectively. We argue that the over-proportional presence of DN and FP manifests a bias, as the first assigns the undesirable outcome to the deprived and the second the desirable outcome to the favored group. Consequently, we define an explanation—a decision-making mechanism—as unfair if the fact of belonging to the deprived group is a reason for receiving the undesirable label. Conversely, belonging to the favored group is a reason to receive the desirable label. Regarding adaptation (ii), our goal is to remove protected attributes from the decision-making mechanism. This is achieved if the protected attributes are randomized, and all remaining features are held constant during counterexample generation. Randomization, in our case, means that if the fact of being male is a reason for a good credit risk, our counterexample is the identical instance, but the gender is female. Let us formalize the notion of
biased decision making:
Definition 6 (Biased Decision Making).
Consider features from explanation e, written , for a model’s outcome , and a protected attribute S with deprived group and favored group s. We define the decision-making
mechanism of f to be biased
if it holds that FairCaipi’s bias-mitigation strategy takes place in the counterexample generation procedure
GEN’ (Algorithm 2), where we identify the parameterization of the protected attribute that would reproduce a bias regarding the prediction (line 2). For example, if the prediction would be a bad credit risk, then the bias-reproducing parameterization of the protected attribute gender would be female. Next, we build a set of all possible values of the protected attribute without the bias-reproducing value (line 3). To generate a counterexample instance, we repeat each feature but randomly replace the protected attribute (line 5), and add the input label (line 6). The resulting counterexample dataset contains all initial correlations except for the correlation between the protected attribute and the target.
| Algorithm 2 GEN’ [] (Counterexample Generation) |
![Make 05 00076 i002]() |
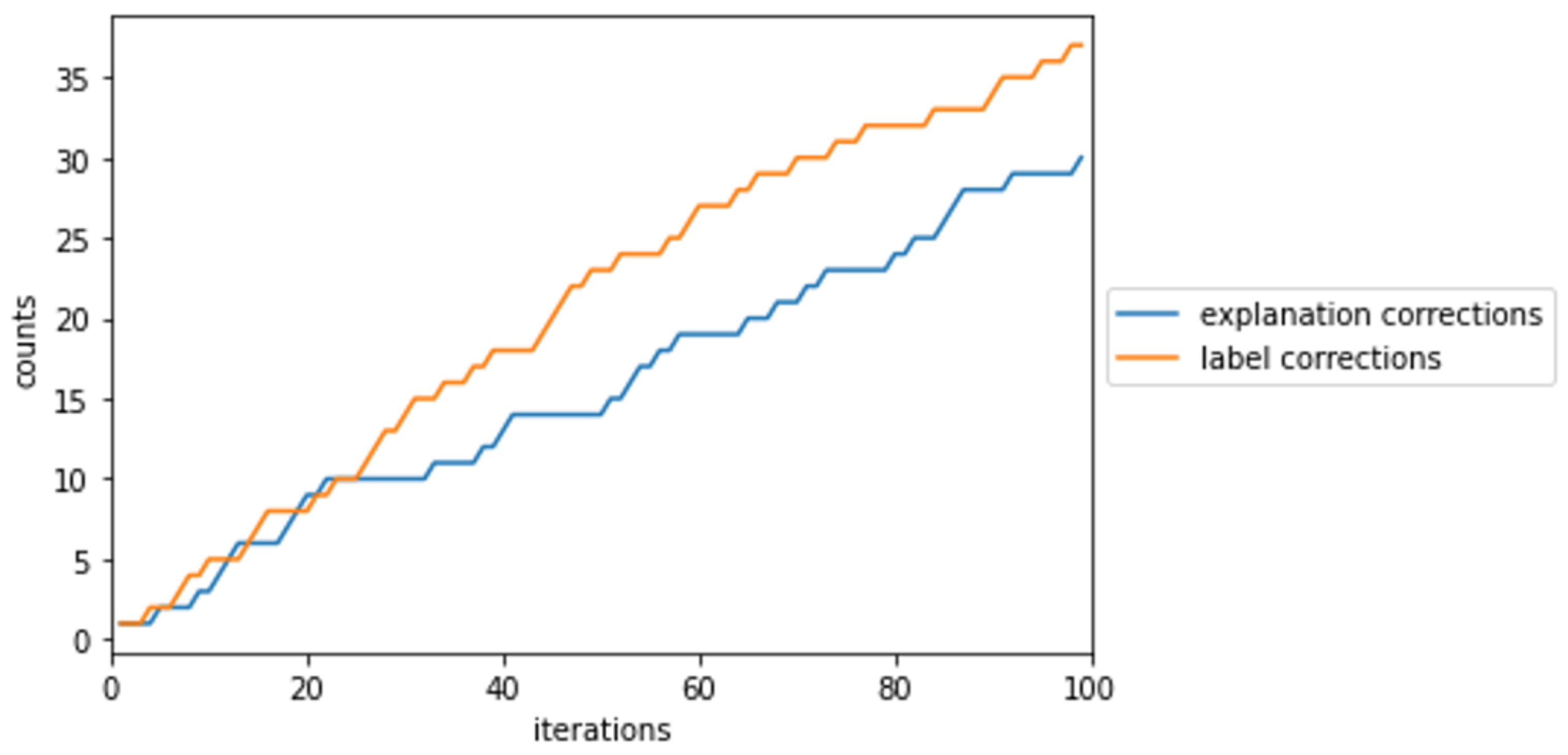
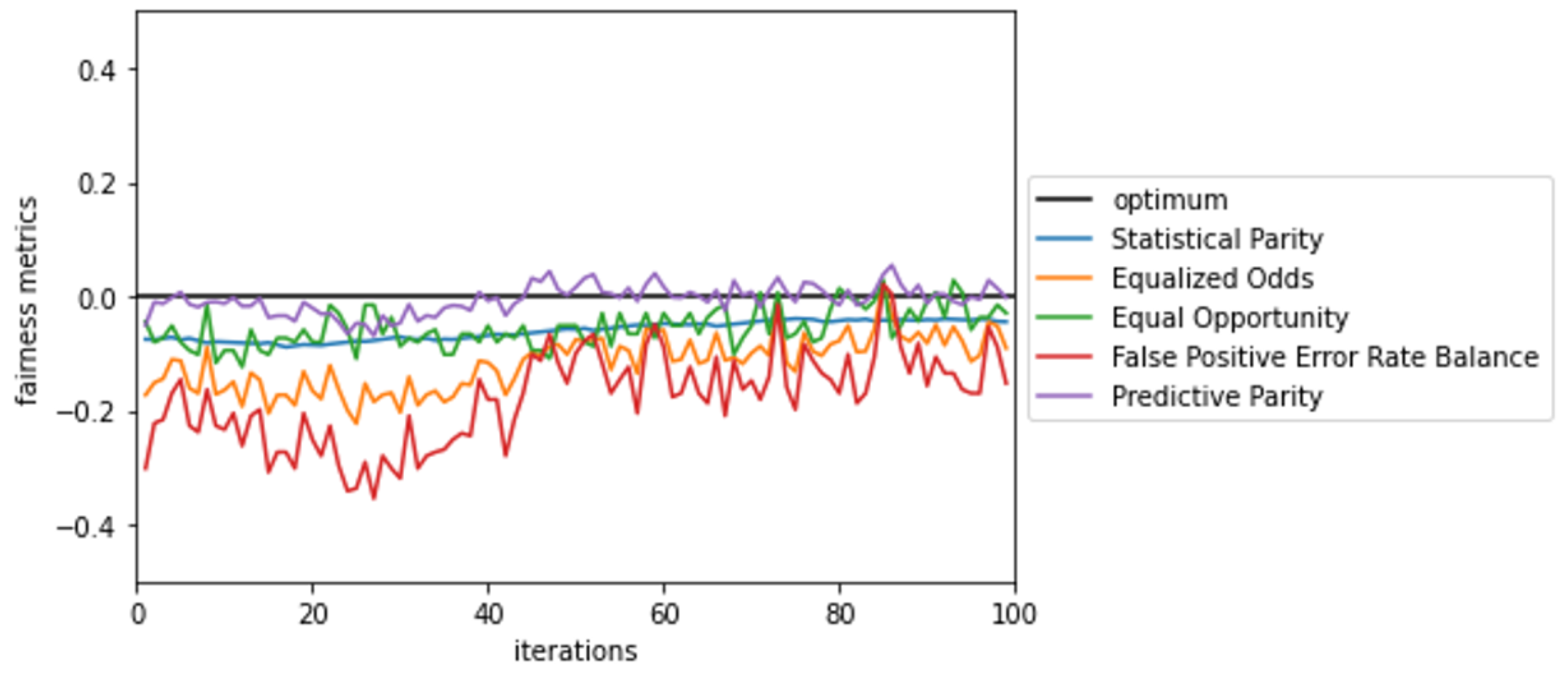
In contrast to original Caipi, FairCaipi (Algorithm 3) takes the protected attribute as an input. The users still provide feedback on the model’s explanation. However, their task is no longer to induce correct mechanisms but to mitigate bias. Thus, according to Definition 6, the interaction in line 10 returns if the explanation is biased and otherwise, where an identified bias yields bias mitigating counterexamples (line 14).
FairCaipi is capable of (i) detecting and (ii) reducing machine bias and (iii) uncovering human bias. Note, however, that technically, so far
FairCaipi does not require human feedback as long as we have access to all elements of Algorithm 3, which often is a realistic assumption when experiments are only pseudo-unlabeled. Although this qualifies
FairCaipi to meet the first two capabilities, the latter is still not met. Practically, we explicitly want to include a human user in the optimization cycle. The user can override
FairCaipi’s biased decision (Definition 6). This might be due to good human intentions—passive bias, when the users fail to correct a biased mechanism—or active bias, when users intentionally miss corrections or correct the mechanism such that the bias-detection metrics suffer. We enrich
FairCaipi to present bias detection metrics (
Section 3.1) to the user at the beginning and the end of each iteration, i.e., before and after refitting the model (line 2). Furthermore, we include an interaction step where the user has the opportunity to provide feedback, and
FairCaipi notifies the user in the case conducted or missed corrections negatively affect the bias-detection metrics. Placing
FairCaipi in the priory-described design (
Figure 4) has an essential benefit: It educates users, as it relates human feedback directly to bias-detection metrics.
| Algorithm 3 FairCaipi [] |
![Make 05 00076 i003]() |
Our approach aims at improving the model quality while minimizing the number of queries, interactions, and overall cost. According to [
14], active learning benefits from a significantly improved sample complexity compared to passive learning due to the specific selection of instances for labeling. Regarding its computational complexity, our approach is influenced by its model-agnostic nature, inheriting the complexities associated with fitting a model and making predictions for specific instances based on the underlying machine-learning algorithm. The core components of our approach, including
FairCaipi and its associated computations, such as computing fairness metrics and SHAP values, maintain reasonable complexity: Notably, SHAP computation being part of the
Exp procedure, although generally intractable, can be efficiently approximated in polynomial time [
50,
53]. Procedures
MIIand
GEN’ for counterexample generation, as well as used set operations are at most of polynomial complexity. Hence, we argue that
FairCaipi is a computationally viable XIML approach.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










