
Explainable Stacked Ensemble Deep Learning (SEDL) Framework to Determine Cause of Death from Verbal Autopsies

 , and
, and 
Abstract
:1. Introduction
2. Deep Learning in VA
2.1. Ensemble DL
2.2. Explainable AI
3. Materials and Methods
3.1. Study Design
3.2. Study Population
3.3. Data Source and Description
3.4. Preprocessing
3.5. Word Embedding and Representation
3.6. Text Classification with Deep Learning Architectures
3.6.1. Long-Term Short Memory
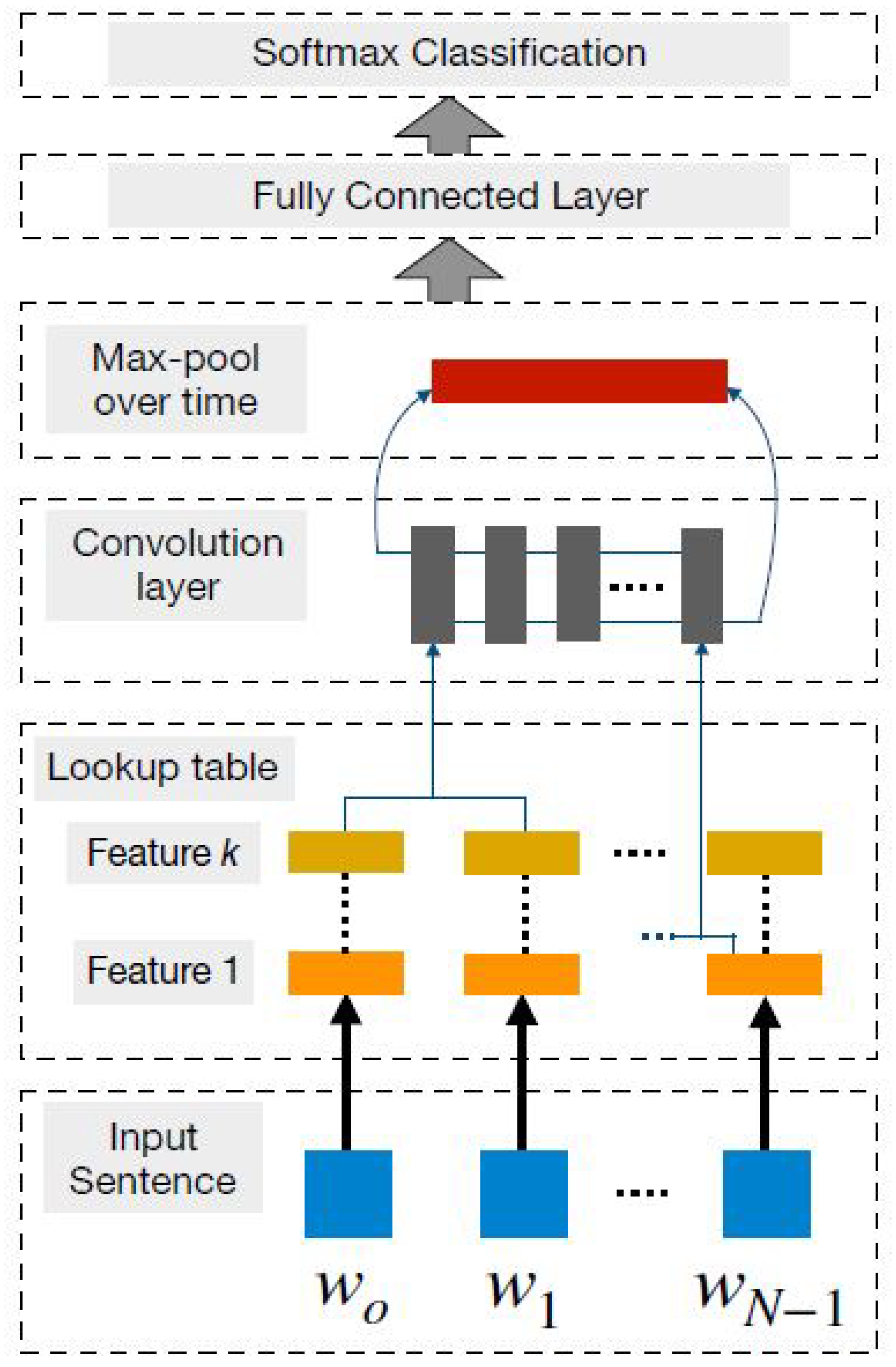
3.6.2. Convolutional Neural Network
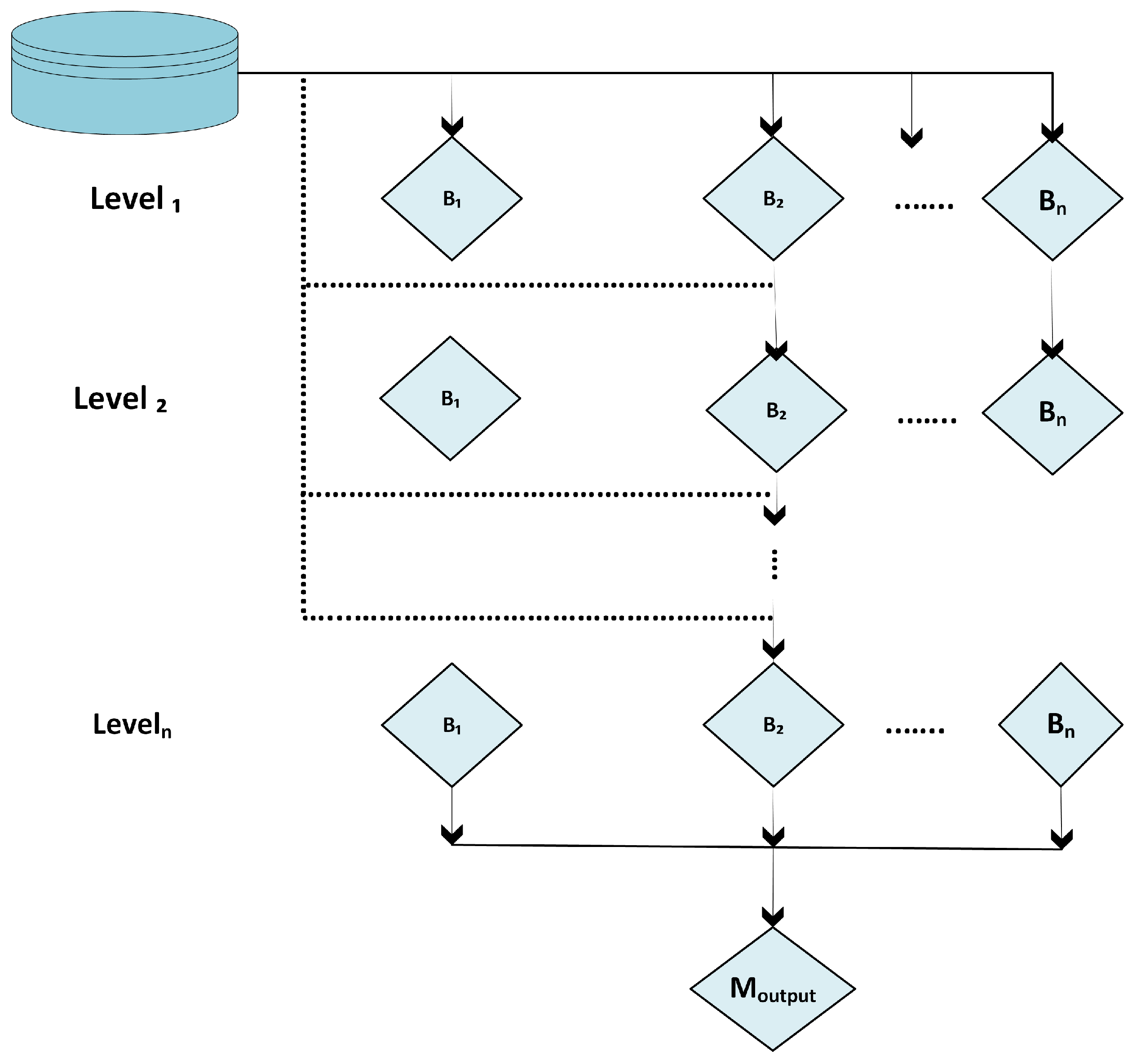
3.7. Stacked Ensemble DL Models
3.8. Explainable AI Using LIME
4. Experiments
Deep Learning Models
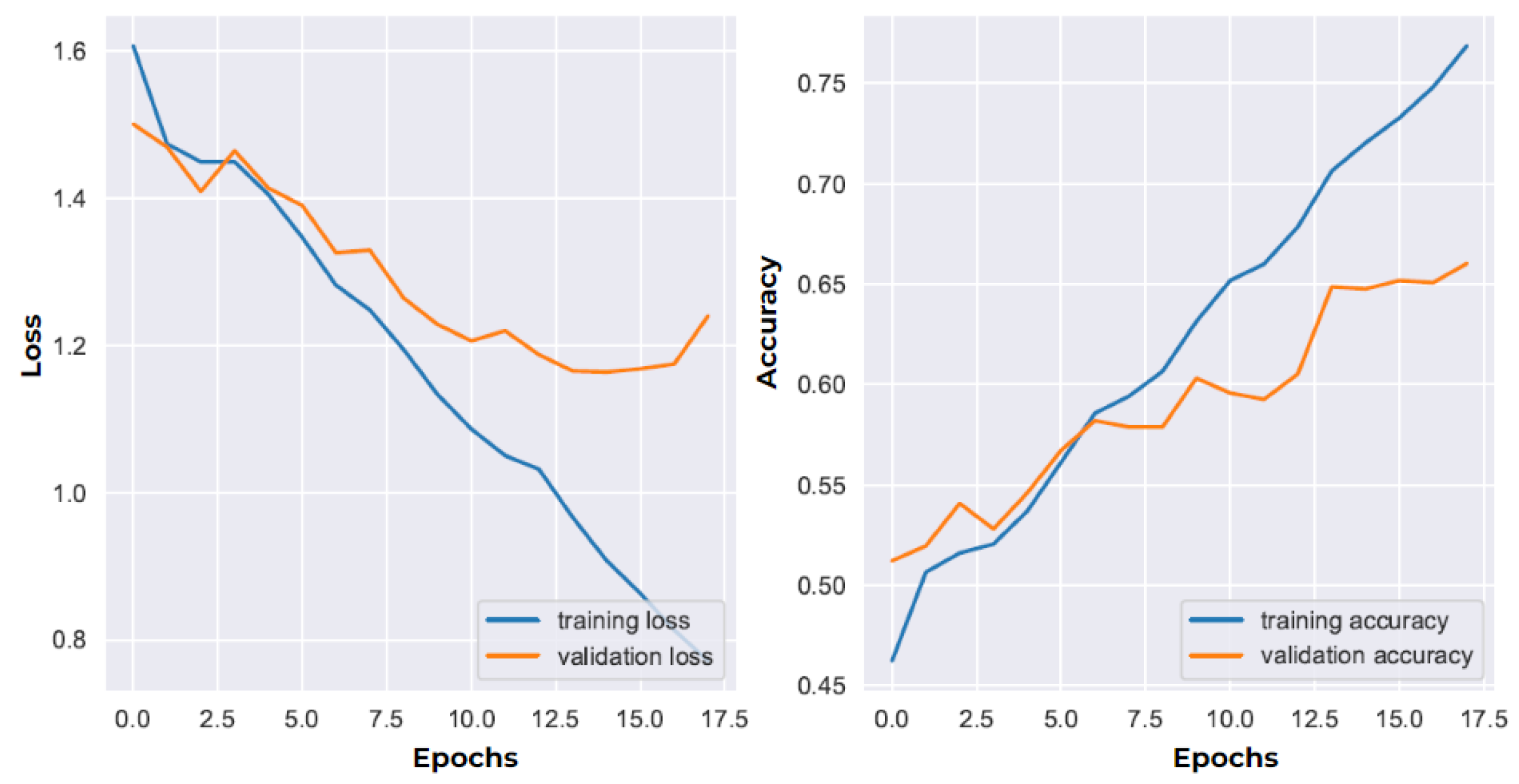
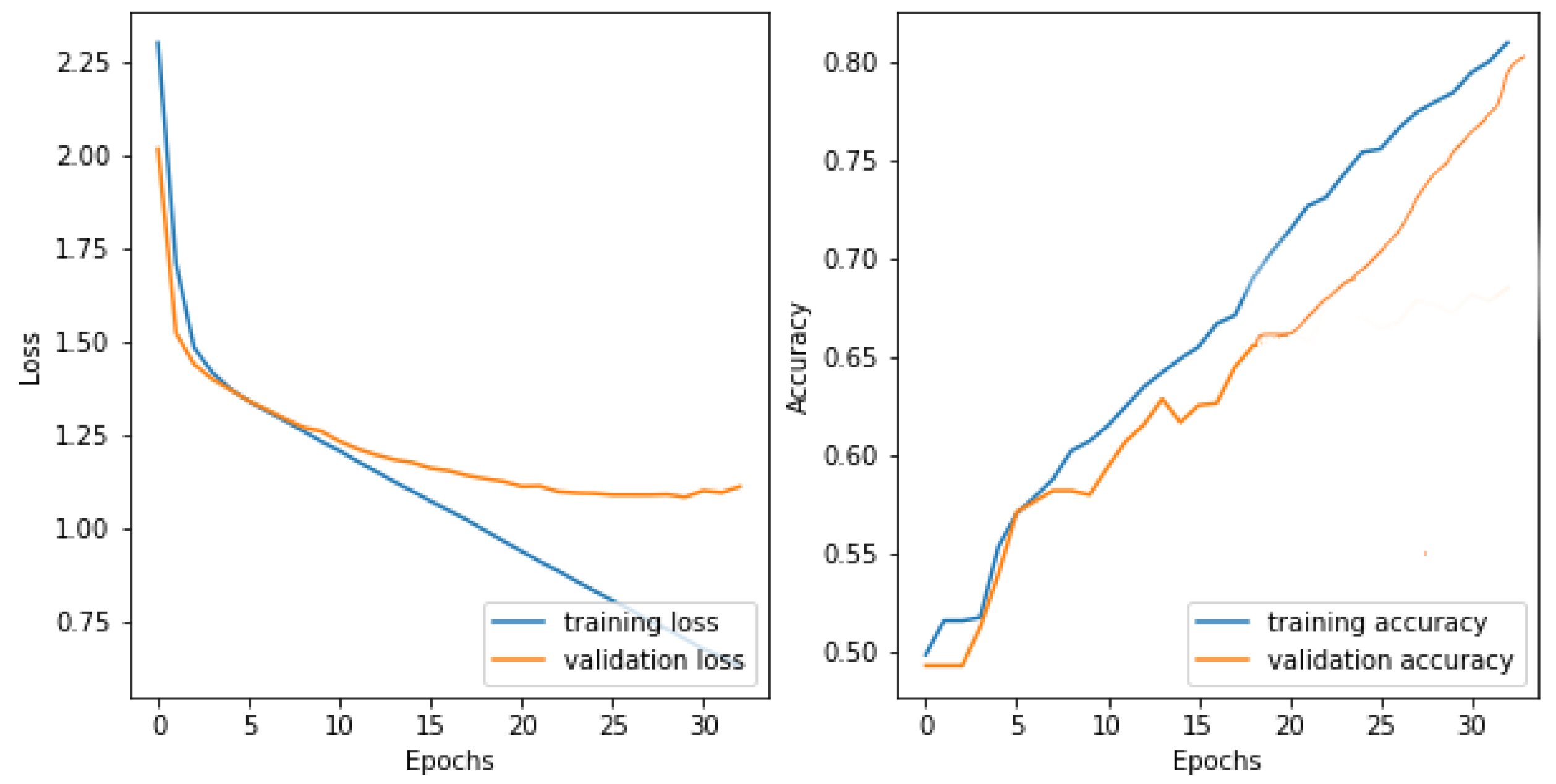
5. DL Model Evaluation
6. Results
6.1. Model Performance
6.2. Model Explainability
- Bad.
- Poor.
- Fair.
- Good.
- Excellent.
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| CCVA | Computer-Coded Verbal Autopsy |
| CoD | Cause of Death |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| XAI | Explainable Artificial Intelligence |
| LIME | Local Interpretable Model-agnostic Explanations |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| PCVA | Physician-Coded Verbal Autopsy |
| RNN | Recurrent Neural Network |
| SEDL | Stacked Ensemble Deep Learning |
| VA | Verbal Autopsy |
References
- Nichols, E.K.; Byass, P.; Chandramohan, D.; Clark, S.J.; Flaxman, A.D.; Jakob, R.; Leitao, J.; Maire, N.; Rao, C.; Riley, I.; et al. The WHO 2016 verbal autopsy instrument: An international standard suitable for automated analysis by InterVA, InSilicoVA, and Tariff 2.0. PLoS Med. 2018, 15, e1002486. [Google Scholar] [CrossRef]
- Thomas, L.M.; D’Ambruoso, L.; Balabanova, D. Verbal autopsy in health policy and systems: A literature review. BMJ Glob. Health 2018, 3, e000639. [Google Scholar] [CrossRef]
- Jeblee, S.; Gomes, M.; Jha, P.; Rudzicz, F.; Hirst, G. Automatically determining cause of death from verbal autopsy narratives. BMC Med. Inform. Decis. Mak. 2019, 19, 127. [Google Scholar] [CrossRef]
- Soleman, N.; Chandramohan, D.; Shibuya, K. Verbal autopsy: Current practices and challenges. Bull. World Health Organ. 2006, 84, 239–245. [Google Scholar] [CrossRef] [PubMed]
- Bailo, P.; Gibelli, F.; Ricci, G.; Sirignano, A. Verbal autopsy as a tool for defining causes of death in specific healthcare contexts: Study of applicability through a traditional literature review. Int. J. Environ. Res. Public Health 2022, 19, 11749. [Google Scholar] [CrossRef] [PubMed]
- Clark, S.J. A Guide to Comparing the Performance of VA Algorithms. arXiv 2018, arXiv:1802.07807. [Google Scholar]
- Desai, N.; Aleksandrowicz, L.; Miasnikof, P.; Lu, Y.; Leitao, J.; Byass, P.; Tollman, S.; Mee, P.; Alam, D.; Rathi, S.K.; et al. Performance of four computer-coded verbal autopsy methods for cause of death assignment compared with physician coding on 24,000 deaths in low-and middle-income countries. BMC Med. 2014, 12, 20. [Google Scholar] [CrossRef]
- James, S.L.; Flaxman, A.D.; Murray, C.J. Performance of the Tariff Method: Validation of a simple additive algorithm for analysis of verbal autopsies. Popul. Health Metrics 2011, 9, 31. [Google Scholar] [CrossRef]
- Byass, P.; Herbst, K.; Fottrell, E.; Ali, M.M.; Odhiambo, F.; Amek, N.; Hamel, M.J.; Laserson, K.F.; Kahn, K.; Kabudula, C.; et al. Comparing verbal autopsy cause of death findings as determined by physician coding and probabilistic modelling: A public health analysis of 54 000 deaths in Africa and Asia. J. Glob. Health 2015, 5. [Google Scholar]
- McCormick, T.H.; Li, Z.R.; Calvert, C.; Crampin, A.C.; Kahn, K.; Clark, S.J. Probabilistic cause-of-death assignment using verbal autopsies. J. Am. Stat. Assoc. 2016, 111, 1036–1049. [Google Scholar] [CrossRef]
- Miasnikof, P.; Giannakeas, V.; Gomes, M.; Aleksandrowicz, L.; Shestopaloff, A.Y.; Alam, D.; Tollman, S.; Samarikhalaj, A.; Jha, P. Naive Bayes classifiers for verbal autopsies: Comparison to physician-based classification for 21,000 child and adult deaths. BMC Med. 2015, 13, 286. [Google Scholar] [CrossRef] [PubMed]
- Boulle, A.; Chandramohan, D.; Weller, P. A case study of using artificial neural networks for classifying cause of death from verbal autopsy. Int. J. Epidemiol. 2001, 30, 515–520. [Google Scholar] [CrossRef] [PubMed]
- Flaxman, A.D.; Vahdatpour, A.; Green, S.; James, S.L.; Murray, C.J. Random forests for verbal autopsy analysis: Multisite validation study using clinical diagnostic gold standards. Popul. Health Metrics 2011, 9, 29. [Google Scholar] [CrossRef]
- Quigley, M.A.; Chandramohan, D.; Setel, P.; Binka, F.; Rodrigues, L.C. Validity of data-derived algorithms for ascertaining causes of adult death in two African sites using verbal autopsy. Trop. Med. Int. Health 2000, 5, 33–39. [Google Scholar] [CrossRef] [PubMed]
- Mwanyangala, M.A.; Urassa, H.M.; Rutashobya, J.C.; Mahutanga, C.C.; Lutambi, A.M.; Maliti, D.V.; Masanja, H.M.; Abdulla, S.K.; Lema, R.N. Verbal autopsy completion rate and factors associated with undetermined cause of death in a rural resource-poor setting of Tanzania. Popul. Health Metrics 2011, 9, 41. [Google Scholar] [CrossRef] [PubMed]
- Koopman, B.; Karimi, S.; Nguyen, A.; McGuire, R.; Muscatello, D.; Kemp, M.; Truran, D.; Zhang, M.; Thackway, S. Automatic classification of diseases from free-text death certificates for real-time surveillance. BMC Med Informatics Decis. Mak. 2015, 15, 53. [Google Scholar] [CrossRef]
- Koopman, B.; Zuccon, G.; Nguyen, A.; Bergheim, A.; Grayson, N. Extracting cancer mortality statistics from death certificates: A hybrid machine learning and rule-based approach for common and rare cancers. Artif. Intell. Med. 2018, 89, 1–9. [Google Scholar] [CrossRef]
- Mujtaba, G.; Shuib, L.; Raj, R.G.; Rajandram, R.; Shaikh, K.; Al-Garadi, M.A. Automatic ICD-10 multi-class classification of cause of death from plaintext autopsy reports through expert-driven feature selection. PLoS ONE 2017, 12, e0170242. [Google Scholar] [CrossRef]
- Mujtaba, G.; Shuib, L.; Raj, R.G.; Rajandram, R.; Shaikh, K.; Al-Garadi, M.A. Classification of forensic autopsy reports through conceptual graph-based document representation model. J. Biomed. Inform. 2018, 82, 88–105. [Google Scholar] [CrossRef]
- Mujtaba, G.; Shuib, L.; Raj, R.G.; Rajandram, R.; Shaikh, K. Prediction of cause of death from forensic autopsy reports using text classification techniques: A comparative study. J. Forensic Leg. Med. 2018, 57, 41–50. [Google Scholar] [CrossRef]
- Mapundu, M.T.; Kabudula, C.W.; Musenge, E.; Olago, V.; Celik, T. Performance evaluation of machine learning and Computer Coded Verbal Autopsy (CCVA) algorithms for cause of death determination: A comparative analysis of data from rural South Africa. Front. Public Health 2022, 10, 990838. [Google Scholar] [CrossRef]
- Miotto, R.; Wang, F.; Wang, S.; Jiang, X.; Dudley, J.T. Deep learning for healthcare: Review, opportunities and challenges. Briefings Bioinform. 2017, 19, 1236–1246. [Google Scholar] [CrossRef] [PubMed]
- Prakash, J.A.; Ravi, V.; Sowmya, V.; Soman, K. Stacked ensemble learning based on deep convolutional neural networks for pediatric pneumonia diagnosis using chest X-ray images. Neural Comput. Appl. 2022, 35, 8259–8279. [Google Scholar] [CrossRef]
- Ravì, D.; Wong, C.; Deligianni, F.; Berthelot, M.; Andreu-Perez, J.; Lo, B.; Yang, G.Z. Deep learning for health informatics. IEEE J. Biomed. Health Inform. 2016, 21, 4–21. [Google Scholar] [CrossRef] [PubMed]
- Kwak, G.H.J.; Hui, P. Deephealth: Deep learning for health informatics. ACM Trans. Comput. Healthc. 2019. [Google Scholar]
- Srivastava, S.; Soman, S.; Rai, A.; Srivastava, P.K. Deep learning for health informatics: Recent trends and future directions. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; pp. 1665–1670. [Google Scholar]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Zhang, T.; Oles, F.J. Text categorization based on regularized linear classification methods. Inf. Retr. 2001, 4, 5–31. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. arXiv 2015, arXiv:1509.01626. [Google Scholar]
- Kowsari, K.; Brown, D.E.; Heidarysafa, M.; Meimandi, K.J.; Gerber, M.S.; Barnes, L.E. Hdltex: Hierarchical deep learning for text classification. In Proceedings of the 2017 16th IEEE international conference on machine learning and applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 364–371. [Google Scholar]
- Mujtaba, G.; Shuib, L.; Idris, N.; Hoo, W.L.; Raj, R.G.; Khowaja, K.; Shaikh, K.; Nweke, H.F. Clinical text classification research trends: Systematic literature review and open issues. Expert Syst. Appl. 2019, 116, 494–520. [Google Scholar] [CrossRef]
- Johnson, R.; Zhang, T. Effective use of word order for text categorization with convolutional neural networks. arXiv 2014, arXiv:1412.1058. [Google Scholar]
- Irsoy, O.; Cardie, C. Opinion mining with deep recurrent neural networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 720–728. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Document modeling with gated recurrent neural network for sentiment classification. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1422–1432. [Google Scholar]
- Liu, F.; Zheng, J.; Zheng, L.; Chen, C. Combining attention-based bidirectional gated recurrent neural network and two-dimensional convolutional neural network for document-level sentiment classification. Neurocomputing 2020, 371, 39–50. [Google Scholar] [CrossRef]
- Ghosh, M.; Sanyal, G. Document modeling with hierarchical deep learning approach for sentiment classification. In Proceedings of the 2nd International Conference on Digital Signal Processing, Tokyo, Japan, 25–27 February 2018; pp. 181–185. [Google Scholar]
- Xu, J.; Chen, D.; Qiu, X.; Huang, X. Cached long short-term memory neural networks for document-level sentiment classification. arXiv 2016, arXiv:1610.04989. [Google Scholar]
- Jelodar, H.; Wang, Y.; Orji, R.; Huang, S. Deep sentiment classification and topic discovery on novel coronavirus or covid-19 online discussions: Nlp using lstm recurrent neural network approach. IEEE J. Biomed. Health Inform. 2020, 24, 2733–2742. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Jeblee, S.; Gomes, M.; Hirst, G. Multi-task learning for interpretable cause of death classification using key phrase prediction. In Proceedings of the BioNLP 2018 Workshop, Melbourne, Australia, 19 July 2018; pp. 12–17. [Google Scholar]
- Yan, Z.; Jeblee, S.; Hirst, G. Can Character Embeddings Improve Cause-of-Death Classification for Verbal Autopsy Narratives? In Proceedings of the 18th BioNLP Workshop and Shared Task, Florence, Italy, 1 August 2019; pp. 234–239. [Google Scholar]
- Blanco, A.; Perez, A.; Casillas, A.; Cobos, D. Extracting Cause of Death from Verbal Autopsy with Deep Learning interpretable methods. IEEE J. Biomed. Health Inform. 2020, 25, 1315–1325. [Google Scholar] [CrossRef]
- Kivrak, M.; Guldogan, E.; Colak, C. Prediction of death status on the course of treatment in SARS-COV-2 patients with deep learning and machine learning methods. Comput. Methods Programs Biomed. 2021, 201, 105951. [Google Scholar] [CrossRef]
- Heidarysafa, M.; Kowsari, K.; Barnes, L.; Brown, D. Analysis of Railway Accidents’ Narratives Using Deep Learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1446–1453. [Google Scholar]
- El Asnaoui, K. Design ensemble deep learning model for pneumonia disease classification. Int. J. Multimed. Inf. Retr. 2021, 10, 55–68. [Google Scholar] [CrossRef]
- Tang, S.; Wang, C.; Nie, J.; Kumar, N.; Zhang, Y.; Xiong, Z.; Barnawi, A. EDL-COVID: Ensemble deep learning for COVID-19 case detection from chest X-ray images. IEEE Trans. Ind. Inform. 2021, 17, 6539–6549. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Hu, M.; Malik, A.; Tanveer, M.; Suganthan, P. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Baccouche, A.; Garcia-Zapirain, B.; Castillo Olea, C.; Elmaghraby, A. Ensemble deep learning models for heart disease classification: A case study from Mexico. Information 2020, 11, 207. [Google Scholar] [CrossRef]
- Loh, H.W.; Ooi, C.P.; Seoni, S.; Barua, P.D.; Molinari, F.; Acharya, U.R. Application of explainable artificial intelligence for healthcare: A systematic review of the last decade (2011–2022). Comput. Methods Programs Biomed. 2022, 226, 107161. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Weng, Y.; Lund, J. Applications of explainable artificial intelligence in diagnosis and surgery. Diagnostics 2022, 12, 237. [Google Scholar] [CrossRef] [PubMed]
- Javed, A.R.; Khan, H.U.; Alomari, M.K.B.; Sarwar, M.U.; Asim, M.; Almadhor, A.S.; Khan, M.Z. Toward explainable AI-empowered cognitive health assessment. Front. Public Health 2023, 11, 1024195. [Google Scholar] [CrossRef]
- Knapič, S.; Malhi, A.; Saluja, R.; Främling, K. Explainable artificial intelligence for human decision support system in the medical domain. Mach. Learn. Knowl. Extr. 2021, 3, 740–770. [Google Scholar] [CrossRef]
- Kabudula, C.W.; Tollman, S.; Mee, P.; Ngobeni, S.; Silaule, B.; Gómez-Olivé, F.X.; Collinson, M.; Kahn, K.; Byass, P. Two decades of mortality change in rural northeast South Africa. Glob. Health Action 2014, 7, 25596. [Google Scholar] [CrossRef] [PubMed]
- Danso, S.; Atwell, E.; Johnson, O. A comparative study of machine learning methods for verbal autopsy text classification. arXiv 2014, arXiv:1402.4380. [Google Scholar]
- King, G.; Lu, Y. Verbal autopsy methods with multiple causes of death. Stat. Sci. 2008, 23, 78–91. [Google Scholar] [CrossRef]
- Shah, C. A Hands-On Introduction to Data Science; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Naili, M.; Chaibi, A.H.; Ghezala, H.H.B. Comparative study of word embedding methods in topic segmentation. Procedia Comput. Sci. 2017, 112, 340–349. [Google Scholar] [CrossRef]
- Alami, N.; Meknassi, M.; En-nahnahi, N. Enhancing unsupervised neural networks based text summarization with word embedding and ensemble learning. Expert Syst. Appl. 2019, 123, 195–211. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. arXiv 2017, arXiv:1708.02709. [Google Scholar]
- Zaki, M.J.; Meir, W., Jr. Data Mining and Machine Learning: Fundamental Concepts and Algorithms; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Leskovec, J.; Rajaraman, A.; Ullman, J.D. Mining of Massive Data Sets; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Kirillov, A.; Schlesinger, D.; Forkel, W.; Zelenin, A.; Zheng, S.; Torr, P.; Rother, C. Efficient likelihood learning of a generic CNN-CRF model for semantic segmentation. arXiv 2015, arXiv:1511.05067. [Google Scholar]
- Malinowski, M.; Rohrbach, M.; Fritz, M. Ask your neurons: A neural-based approach to answering questions about images. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1–9. [Google Scholar]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Watt, J.; Borhani, R.; Katsaggelos, A. Machine Learning Refined: Foundations, Algorithms, and Applications; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Anzanello, M.J.; Fogliatto, F.S. Learning curve models and applications: Literature review and research directions. Int. J. Ind. Ergon. 2011, 41, 573–583. [Google Scholar] [CrossRef]
- Hoiem, D.; Gupta, T.; Li, Z.; Shlapentokh-Rothman, M.M. Learning Curves for Analysis of Deep Networks. arXiv 2020, arXiv:2010.11029. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disease Category | Class Label | Number of Samples |
|---|---|---|
| HIV/TB | 0 | 3388 |
| Other Infectious | 1 | 964 |
| Metabolic | 2 | 242 |
| Cardiovascular | 3 | 140 |
| Indeterminate | 4 | 1468 |
| Maternal and Neonatal | 5 | 121 |
| Abdominal | 6 | 117 |
| Neoplasms | 7 | 93 |
| Neurological | 9 | 57 |
| Respiratory | 10 | 46 |
| Other NCD | 11 | 21 |
| Model | Training Accuracy (%) | Validation Accuracy (%) | Test Accuracy (%) | Test Loss (%) |
|---|---|---|---|---|
| LSTM | 76.11 | 67.05 | 67 | 11.95 |
| CNN | 76.35 | 66.16 | 66.2 | 12.64 |
| SEDL | 82.1 | 82 | 82 | 1.15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mapundu, M.T.; Kabudula, C.W.; Musenge, E.; Olago, V.; Celik, T. Explainable Stacked Ensemble Deep Learning (SEDL) Framework to Determine Cause of Death from Verbal Autopsies. Mach. Learn. Knowl. Extr. 2023, 5, 1570-1588. https://doi.org/10.3390/make5040079
Mapundu MT, Kabudula CW, Musenge E, Olago V, Celik T. Explainable Stacked Ensemble Deep Learning (SEDL) Framework to Determine Cause of Death from Verbal Autopsies. Machine Learning and Knowledge Extraction. 2023; 5(4):1570-1588. https://doi.org/10.3390/make5040079
Chicago/Turabian StyleMapundu, Michael T., Chodziwadziwa W. Kabudula, Eustasius Musenge, Victor Olago, and Turgay Celik. 2023. "Explainable Stacked Ensemble Deep Learning (SEDL) Framework to Determine Cause of Death from Verbal Autopsies" Machine Learning and Knowledge Extraction 5, no. 4: 1570-1588. https://doi.org/10.3390/make5040079
APA StyleMapundu, M. T., Kabudula, C. W., Musenge, E., Olago, V., & Celik, T. (2023). Explainable Stacked Ensemble Deep Learning (SEDL) Framework to Determine Cause of Death from Verbal Autopsies. Machine Learning and Knowledge Extraction, 5(4), 1570-1588. https://doi.org/10.3390/make5040079