
Detecting Adversarial Examples Using Surrogate Models


Abstract
:1. Introduction
- Creation of three novel detection strategies exploiting the differences in predictions of original and surrogate models;
- Using ensembles of surrogate models for increased robustness;
- A large-scale evaluation against seven strong white-box attacks on multiple well-known CNN architectures, including an adaptive attacker setting.
2. Related Work
- Availability: misclassifications that compromise normal system operation;
- Integrity: misclassifications that do not compromise normal system operation;
- Confidentiality/privacy: revelation of confidential information on the learned model, its users, or its training data.
2.1. Adversarial Example Generation
2.2. Defences against Adversarial Examples
3. Threat Model
3.1. Attacker’s Goal
- Security violation: We classify the violation along the integrity, availability, and confidentiality (CIA) triangle. The attacker we consider aims to cause either an integrity violation, i.e., to evade detection without compromising normal system operation, or an availability violation, i.e., to compromise the normal system functionalities available to legitimate users. Confidentiality of the model or data is not our concern.
- Attack specificity: We consider both targeted and untargeted attacks. Targeted attacks aim to cause the model to misclassify a specific set of samples (to target a given system user or protected service), while with untargeted attacks, the attacker aims to cause misclassification of any sample (to target any system user or protected service, e.g., with universal adversarial examples).
- Error specificity: We consider the attacker aiming to misclassify a sample misclassified to a specific class or generically as any of the classes different from the true class.
3.2. Attacker’s Knowledge
- White-box setting: the attacker is assumed to know everything about the targeted system.
- Gray-box setting: the attacker is assumed to know something about the targeted system.
- Black-box setting: the attacker is assumed to know nothing about the targeted system.
3.3. Attacker’s Capability
3.4. Adaptive Attacker
4. Surrogates for Detecting Adversarial Examples
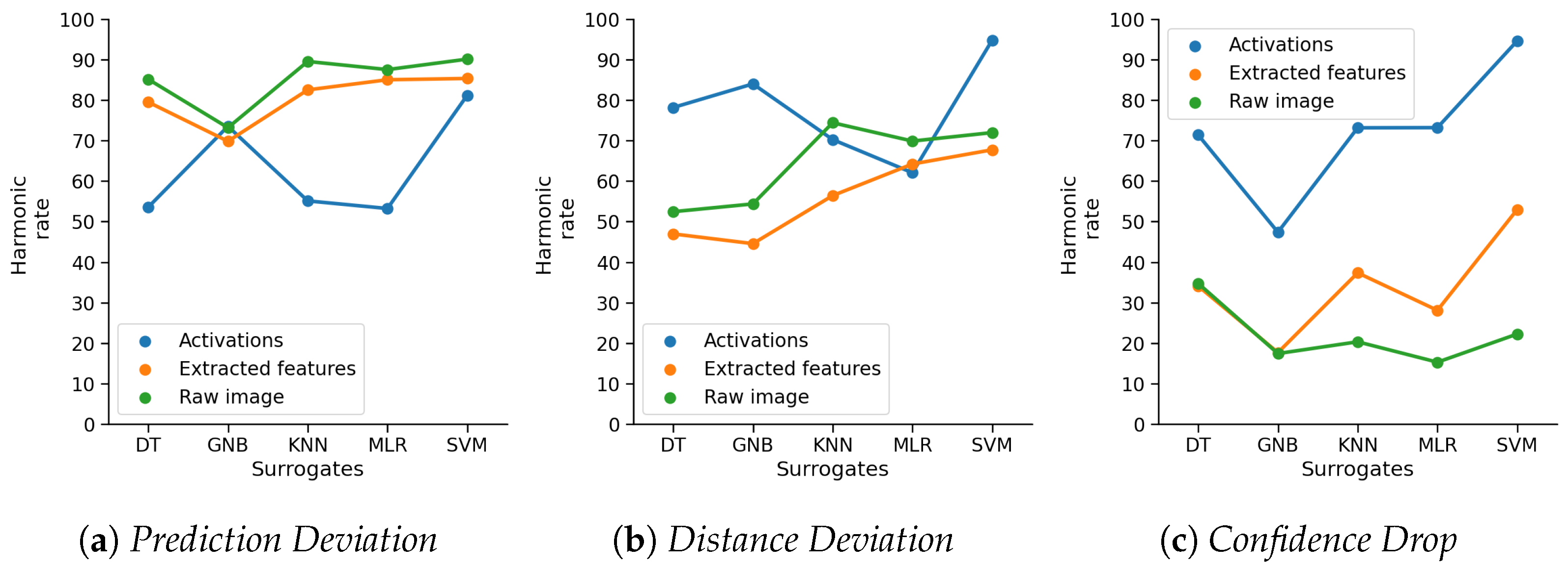
4.1. Prediction Deviation
4.2. Distance Deviation
4.3. Confidence Drop
5. Evaluation Methodology
5.1. Datasets
5.2. Attacks
5.3. Evaluation Metrics
6. Evaluation
6.1. Evaluation Configuration
6.2. Results of the Basic Defence
6.2.1. MNIST
6.2.2. Fashion MNIST
6.2.3. CIFAR-10
6.3. Changing the Tuning Set
6.4. Adaptive Attacker
7. Discussion and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
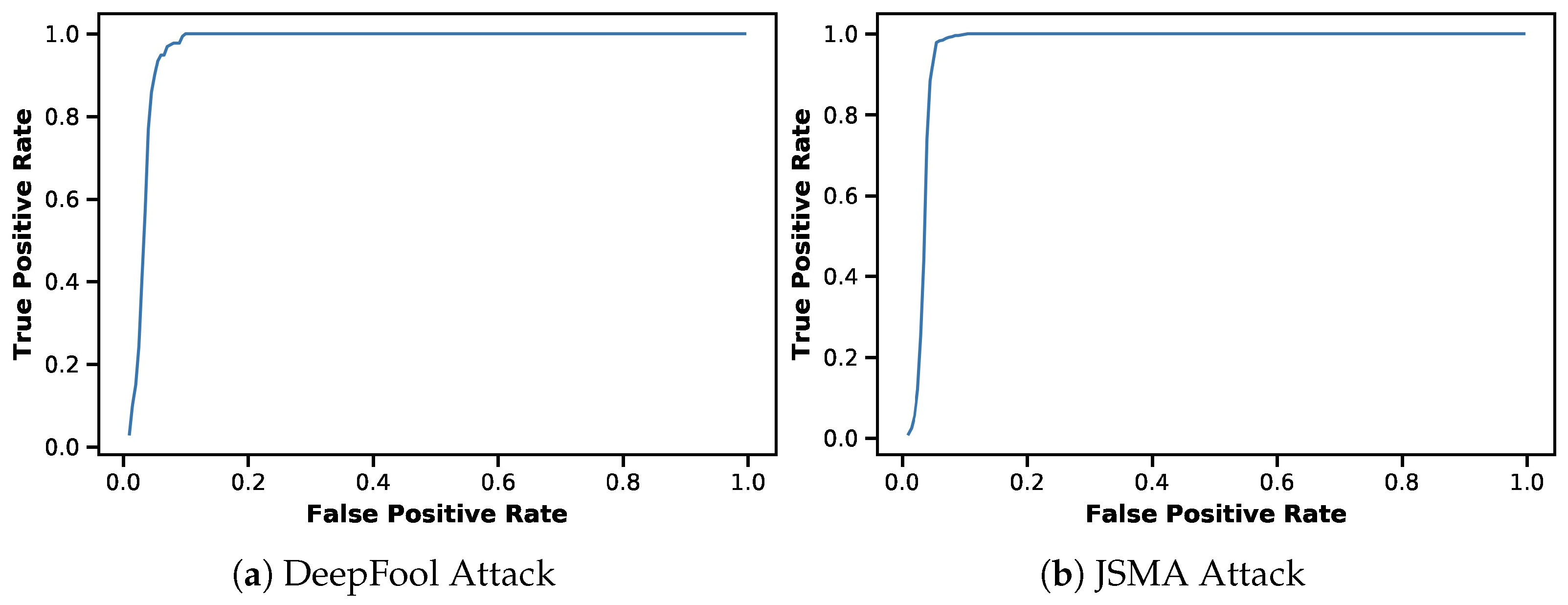
Appendix A. ROC Curves for Detector

Appendix B. Class Vector for Surrogate ML Models
Appendix C. Accuracy of the Surrogates

Appendix D. Detailed Results and Generation Properties for the Adversarial Example Attacks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack | SimpleNet | DualPath_28_10 | ||||
|---|---|---|---|---|---|---|
| Success Rate | Time | Success Rate | Time | |||
| CW | 100.00 | 0.12 | 9 h 1 m 46 s 745 ms | 99.80 | 0.11 | 21 h 40 m 33 s 646 ms |
| DeepFool | 75.05 | 0.34 | 4 m 2 s 624 ms | 88.11 | 0.32 | 20 m 2 s 628 ms |
| JSMA | 100.00 | 0.42 | 8 m 4 s 367 ms | 98.78 | 0.35 | 13 m 59 s 470 ms |
| FGM-0.1 | 8.85 | 0.24 | 667 ms | 38.41 | 0.24 | 2 s 858 ms |
| FGM-0.2 | 40.44 | 0.49 | 660 ms | 85.67 | 0.49 | 2 s 857 ms |
| FGM-0.3 | 65.09 | 0.72 | 656 ms | 92.78 | 0.72 | 2 s 884 ms |
| BIM-0.1 | 86.12 | 0.22 | 34 s 14 ms | 90.35 | 0.24 | 2 m 34 s 926 ms |
| BIM-0.2 | 100.00 | 0.32 | 33 s 732 ms | 100.00 | 0.44 | 2 m 34 s 934 ms |
| BIM-0.3 | 100.00 | 0.38 | 33 s 702 ms | 100.00 | 0.62 | 2 m 35 s 209 ms |
| PGD-0.1 | 86.12 | 0.22 | 14 m 13 s 133 ms | 91.57 | 0.24 | 1 h 40 m 3 s 368 ms |
| PGD-0.2 | 100.00 | 0.34 | 14 m 12 s 238 ms | 100.00 | 0.46 | 1 h 40 m 14 s 924 ms |
| PGD-0.3 | 100.00 | 0.45 | 14 m 11 s 475 ms | 100.00 | 0.69 | 1 h 40 m 44 s 688 ms |
| UnivJSMA | 44.27 | 0.63 | 20 m 54 s 170 ms | 17.58 | 0.63 | 1 h 2 m 9 s 791 ms |
| UnivDeepFool | 15.59 | 0.42 | 9 m 41 s 462 ms | 52.54 | 0.37 | 1 h 13 m 12 s 857 ms |
| UnivFGM-eps0.1 | 28.67 | 0.45 | 28 s 714 ms | 86.18 | 0.46 | 2 s 567 ms |
| UnivFGM-eps0.2 | 26.06 | 0.48 | 25 s 451 ms | 68.50 | 0.48 | 12 s 537 ms |
| UnivFGM-eps0.3 | 31.59 | 0.50 | 25 s 343 ms | 71.65 | 0.50 | 3 s 109 ms |
| UnivBIM-eps0.1 | 12.07 | 0.32 | 8 m 45 s 813 ms | 82.42 | 0.42 | 28 s 11 ms |
| UnivBIM-eps0.2 | 21.13 | 0.34 | 6 m 37 s 298 ms | 79.17 | 0.47 | 27 s 211 ms |
| UnivBIM-eps0.3 | 14.49 | 0.34 | 6 m 36 s 942 ms | 71.34 | 0.49 | 21 s 988 ms |
| UnivPGD-eps0.1 | 23.04 | 0.36 | 2 h 37 m 29 s 769 ms | 77.54 | 0.44 | 8 m 3 s 688 ms |
| UnivPGD-eps0.2 | 28.87 | 0.37 | 2 h 5 m 27 s 528 ms | 74.29 | 0.48 | 14 m 47 s 863 ms |
| UnivPGD-eps0.3 | 13.68 | 0.44 | 2 h 2 m 1 s 564 ms | 77.54 | 0.50 | 8 m 5 s 145 ms |
| Attack | SimpleNet | DualPath_28_10 | ||||
|---|---|---|---|---|---|---|
| Success Rate | Time | Success Rate | Time | |||
| CW | 100.00 | 0.03 | 5 h 29 m 38 s 800 ms | 99.79 | 0.01 | 40 h 45 m 51 s 955 ms |
| DeepFool | 69.01 | 0.06 | 3 m 49 s 894 ms | 59.19 | 0.03 | 19 m 53 s 693 ms |
| JSMA | 71.78 | 0.12 | 1 m 33 s 760 ms | 100.00 | 0.10 | 9 m 29 s 483 ms |
| FGM-0.1 | 73.06 | 0.22 | 629 ms | 88.58 | 0.22 | 2 s 943 ms |
| FGM-0.2 | 90.84 | 0.42 | 627 ms | 90.03 | 0.42 | 2 s 833 ms |
| FGM-0.3 | 93.29 | 0.62 | 627 ms | 91.07 | 0.62 | 2 s 847 ms |
| BIM-0.1 | 100.00 | 0.17 | 32 s 29 ms | 100.00 | 0.17 | 2 m 33 s 979 ms |
| BIM-0.2 | 100.00 | 0.27 | 31 s 937 ms | 100.00 | 0.28 | 2 m 34 s 432 ms |
| BIM-0.3 | 100.00 | 0.32 | 31 s 912 ms | 100.00 | 0.35 | 2 m 34 s 452 ms |
| PGD-0.1 | 100.00 | 0.18 | 12 m 39 s 933 ms | 100.00 | 0.17 | 1 h 47 m 5 s 865 ms |
| PGD-0.2 | 100.00 | 0.31 | 12 m 40 s 462 ms | 100.00 | 0.30 | 1 h 46 m 57 s 358 ms |
| PGD-0.3 | 100.00 | 0.42 | 12 m 38 s 518 ms | 100.00 | 0.41 | 1 h 47 m 6 s 843 ms |
| UnivJSMA | 27.90 | 0.51 | 26 m 27 s 324 ms | 32.09 | 0.51 | 44 m 21 s 34 ms |
| UnivDeepFool | 25.13 | 0.19 | 10 m 2 s 932 ms | 56.28 | 0.11 | 1 h 4 m 25 s 954 ms |
| UnivFGM-eps0.1 | 49.73 | 0.34 | 18 s 255 ms | 84.74 | 0.34 | 8 s 965 ms |
| UnivFGM-eps0.2 | 41.11 | 0.37 | 17 s 633 ms | 82.24 | 0.38 | 8 s 799 ms |
| UnivFGM-eps0.3 | 57.72 | 0.37 | 18 s 262 ms | 81.83 | 0.40 | 9 s 342 ms |
| UnivBIM-eps0.1 | 81.15 | 0.32 | 1 m 28 s 174 ms | 86.71 | 0.29 | 18 s 55 ms |
| UnivBIM-eps0.2 | 81.58 | 0.33 | 2 m 48 s 347 ms | 82.35 | 0.30 | 19 s 865 ms |
| UnivBIM-eps0.3 | 71.03 | 0.34 | 39 s 529 ms | 87.12 | 0.31 | 18 s 172 ms |
| UnivPGD-eps0.1 | 79.98 | 0.30 | 1 h 12 m 20 s 30 ms | 85.36 | 0.29 | 16 m 28 s 73 ms |
| UnivPGD-eps0.2 | 84.98 | 0.29 | 1 h 20 m 53 s 146 ms | 83.70 | 0.32 | 5 m 46 s 353 ms |
| UnivPGD-eps0.3 | 82.75 | 0.33 | 1 h 26 m 10 s 425 ms | 83.49 | 0.37 | 5 m 30 s 18 ms |
| Attack | DenseNet | ||
|---|---|---|---|
| Success Rate | Time | ||
| CW | 100.00 | 0.00 | 8 h 38 m 31 s 252 ms |
| DeepFool | 52.55 | 0.00 | 18 m 49 s 226 ms |
| JSMA | 100.00 | 0.03 | 5 m 47 s 191 ms |
| FGM-0.1 | 87.13 | 0.20 | 2 s 920 ms |
| FGM-0.2 | 88.40 | 0.38 | 2 s 928 ms |
| FGM-0.3 | 89.79 | 0.56 | 2 s 960 ms |
| BIM-0.1 | 100.00 | 0.12 | 2 m 33 s 926 ms |
| BIM-0.2 | 100.00 | 0.16 | 2 m 33 s 356 ms |
| BIM-0.3 | 100.00 | 0.17 | 2 m 34 s 687 ms |
| PGD-0.1 | 100.00 | 0.13 | 51 m 9 s 740 ms |
| PGD-0.2 | 100.00 | 0.23 | 51 m 22 s 294 ms |
| PGD-0.3 | 100.00 | 0.32 | 51 m 17 s 39 ms |
| UnivJSMA | 11.70 | 0.34 | 24 m 6 s 587 ms |
| UnivDeepFool | 65.43 | 0.04 | 26 m 59 s 453 ms |
| UnivFGM-eps0.1 | 86.49 | 0.26 | 3 s 443 ms |
| UnivFGM-eps0.2 | 87.02 | 0.32 | 3 s 439 ms |
| UnivFGM-eps0.3 | 87.45 | 0.34 | 3 s 466 ms |
| UnivBIM-eps0.1 | 88.62 | 0.21 | 14 s 281 ms |
| UnivBIM-eps0.2 | 89.47 | 0.20 | 14 s 140 ms |
| UnivBIM-eps0.3 | 90.32 | 0.22 | 12 s 307 ms |
| UnivPGD-eps0.1 | 89.04 | 0.21 | 10 m 38 s 399 ms |
| UnivPGD-eps0.2 | 90.64 | 0.27 | 2 m 18 s 398 ms |
| UnivPGD-eps0.3 | 90.64 | 0.29 | 2 m 18 s 380 ms |
References
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust Physical-World Attacks on Deep Learning Visual Classification. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yuan, X.; He, P.; Zhu, Q.; Li, X. Adversarial examples: Attacks and defenses for deep learning. IEEE Trans. Neural Netw. Learn. Syst. (TNNLS) 2019, 30, 2805–2824. [Google Scholar] [CrossRef] [PubMed]
- Molnar, C. Interpretable Machine Learning; Lulu. com. 2019. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 16 October 2023).
- Fawzi, A.; Moosavi-Dezfooli, S.M.; Frossard, P. Robustness of classifiers: From adversarial to random noise. In Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2016; Volume 29. [Google Scholar]
- Deniz, O.; Vallez, N.; Bueno, G. Adversarial Examples are a Manifestation of the Fitting-Generalization Trade-off. In Proceedings of the Advances in Computational Intelligence, Cham, Portsmouth, UK, 4–6 September 2019; Volume 11506, pp. 569–580. [Google Scholar] [CrossRef]
- Biggio, B.; Roli, F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership Inference Attacks Against Machine Learning Models. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar] [CrossRef]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model Inversion Attacks That Exploit Confidence Information and Basic Countermeasures. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, New York, NY, USA, 12–16 October 2015; CCS; pp. 1322–1333. [Google Scholar] [CrossRef]
- Lederer, I.; Mayer, R.; Rauber, A. Identifying Appropriate Intellectual Property Protection Mechanisms for Machine Learning Models: A Systematisation of Watermarking, Fingerprinting, Model Access, and Attacks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Oliynyk, D.; Mayer, R.; Rauber, A. I Know What You Trained Last Summer: A Survey on Stealing Machine Learning Models and Defences. Acm Comput. Surv. 2023, 55, 1–41. [Google Scholar] [CrossRef]
- Gu, T.; Liu, K.; Dolan-Gavitt, B.; Garg, S. BadNets: Evaluating Backdooring Attacks on Deep Neural Networks. IEEE Access 2019, 7, 47230–47244. [Google Scholar] [CrossRef]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Proceedings of the International Conference on Learning Representations (ICLR), Workshop Track Proceedings, Toulon, France, 24–26 April 2017. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 3 April–3 May 2018. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrücken, Germany, 21–24 March 2016. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the IEEE Symposium on Security and Privacy (S&P), San Jose, CA, USA, 22–24 May 2017. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Miller, D.J.; Xiang, Z.; Kesidis, G. Adversarial Learning Targeting Deep Neural Network Classification: A Comprehensive Review of Defenses Against Attacks. Proc. IEEE 2020, 108, 402–433. [Google Scholar] [CrossRef]
- Xu, W.; Evans, D.; Qi, Y. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. In Proceedings of the Network and Distributed Systems Security Symposium (NDSS), San Diego, CA, USA, 18–21 February 2018. [Google Scholar] [CrossRef]
- Aldahdooh, A.; Hamidouche, W.; Fezza, S.A.; Déforges, O. Adversarial example detection for DNN models: A review and experimental comparison. Artif. Intell. Rev. 2022, 55, 4403–4462. [Google Scholar] [CrossRef]
- Meng, D.; Chen, H. Magnet: A two-pronged defense against adversarial examples. In Proceedings of the ACM Conference on Computer and Communications Security (CCS), Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar] [CrossRef]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. PixelDefend: Leveraging Generative Models to Understand and Defend against Adversarial Examples. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Salimans, T.; Karpathy, A.; Chen, X.; Kingma, D.P. PixelCNN++: A PixelCNN Implementation with Discretized Logistic Mixture Likelihood and Other Modifications. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Speakman, S.; Sridharan, S.; Remy, S.; Weldemariam, K.; McFowland, E. Subset Scanning Over Neural Network Activations. arXiv 2018, arXiv:1810.08676. [Google Scholar]
- Sperl, P.; Kao, C.Y.; Chen, P.; Lei, X.; Böttinger, K. DLA: Dense-Layer-Analysis for Adversarial Example Detection. In Proceedings of the IEEE European Symposium on Security and Privacy (EuroS&P), Genoa, Italy, 7–11 September 2020. [Google Scholar] [CrossRef]
- Lu, J.; Issaranon, T.; Forsyth, D. SafetyNet: Detecting and Rejecting Adversarial Examples Robustly. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Metzen, J.H.; Genewein, T.; Fischer, V.; Bischoff, B. On Detecting Adversarial Perturbations. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Li, X.; Li, F. Adversarial examples detection in deep networks with convolutional filter statistics. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Carrara, F.; Falchi, F.; Caldelli, R.; Amato, G.; Fumarola, R.; Becarelli, R. Detecting adversarial example attacks to deep neural networks. In Proceedings of the International Workshop on Content-Based Multimedia Indexing, Florence, Italy, 19–21 June 2017. [Google Scholar] [CrossRef]
- Dong, Y.; Su, H.; Zhu, J.; Bao, F. Towards interpretable deep neural networks by leveraging adversarial examples. arXiv 2017, arXiv:1708.05493. [Google Scholar]
- Jankovic, A.; Mayer, R. An Empirical Evaluation of Adversarial Examples Defences, Combinations and Robustness Scores. In Proceedings of the 2022 ACM on International Workshop on Security and Privacy Analytics, Baltimore MD, USA, 24–27 April 2022; IWSPA; pp. 86–92. [Google Scholar] [CrossRef]
- Pang, T.; Xu, K.; Du, C.; Chen, N.; Zhu, J. Improving Adversarial Robustness via Promoting Ensemble Diversity. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 4970–4979. [Google Scholar]
- Sen, S.; Ravindran, B.; Raghunathan, A. EMPIR: Ensembles of Mixed Precision Deep Networks for Increased Robustness Against Adversarial Attacks. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Verma, G.; Swami, A. Error Correcting Output Codes Improve Probability Estimation and Adversarial Robustness of Deep Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Shamir, A.; Melamed, O.; BenShmuel, O. The Dimpled Manifold Model of Adversarial Examples in Machine Learning. arXiv 2022, arXiv:2106.10151. [Google Scholar]
- Carlini, N.; Athalye, A.; Papernot, N.; Brendel, W.; Rauber, J.; Tsipras, D.; Goodfellow, I.; Madry, A.; Kurakin, A. On Evaluating Adversarial Robustness. arXiv 2019, arXiv:1902.06705. [Google Scholar]
- Cohen, G.; Afshar, S.; Tapson, J.; van Schaik, A. EMNIST: An extension of MNIST to handwritten letters. arXiv 2017, arXiv:1702.05373v2. [Google Scholar]
- Coates, A.; Ng, A.; Lee, H. An Analysis of Single-Layer Networks in Unsupervised Feature Learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 11–13 April 2011; Volume 15. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diegeo, CA, USA, 20–26 June 2005. [Google Scholar] [CrossRef]
- He, W.; Wei, J.; Chen, X.; Carlini, N.; Song, D. Adversarial Example Defenses: Ensembles of Weak Defenses Are Not Strong. In Proceedings of the USENIX Conference on Offensive Technologies, Berkeley, CA, USA, 27 June 2017. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C. MNIST Handwritten Digit Database. ATT Labs [Online]. 2010. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 20 October 2023).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images. Technical Report, University of Toronto. 2009. Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 16 October 2023).
- HasanPour, S.H.; Rouhani, M.; Fayyaz, M.; Sabokrou, M. Lets keep it simple, Using simple architectures to outperform deeper and more complex architectures. arXiv 2016, arXiv:1608.06037. [Google Scholar]
- Chen, Y.; Li, J.; Xiao, H.; Jin, X.; Yan, S.; Feng, J. Dual path networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. In Proceedings of the Proceedings of the British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Foret, P.; Kleiner, A.; Mobahi, H.; Neyshabur, B. Sharpness-Aware Minimization for Efficiently Improving Generalization. arXiv 2020, arXiv:2010.01412. [Google Scholar]
- Nicolae, M.I.; Sinn, M.; Tran, M.N.; Buesser, B.; Rawat, A.; Wistuba, M.; Zantedeschi, V.; Baracaldo, N.; Chen, B.; Ludwig, H.; et al. Adversarial Robustness Toolbox v1.2.0. arXiv 2018, arXiv:1807.01069. [Google Scholar]
- Ding, G.W.; Wang, L.; Jin, X. AdverTorch v0.1: An Adversarial Robustness Toolbox based on PyTorch. arXiv 2019, arXiv:1902.07623. [Google Scholar]
- Tramer, F.; Carlini, N.; Brendel, W.; Madry, A. On Adaptive Attacks to Adversarial Example Defenses. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Virtual, 6–12 December 2020; Volume 33. [Google Scholar]
- Tramér, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing Machine Learning Models via Prediction APIs. In Proceedings of the 25th USENIX Security Symposium (USENIX Security 16), Austin, TX, USA, 10–12 August 2016; pp. 601–618. [Google Scholar]
- Mosli, R.; Wright, M.; Yuan, B.; Pan, Y. They Might NOT Be Giants Crafting Black-Box Adversarial Examples Using Particle Swarm Optimization. In Proceedings of the European Symposium on Research in Computer Security (ESORICS), Guildford, UK, 14–18 September 2020. [Google Scholar] [CrossRef]
- Athalye, A.; Carlini, N.; Wagner, D.A. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Miller, D.J.; Wang, Y.; Kesidis, G. When Not to Classify: Anomaly Detection of Attacks (ADA) on DNN Classifiers at Test Time. arXiv 2018, arXiv:1712.06646. [Google Scholar] [CrossRef] [PubMed]
- Wu, T.F.; Lin, C.J.; Weng, R.C. Probability Estimates for Multi-Class Classification by Pairwise Coupling. J. Mach. Learn. Res. (JMLR) 2004, 5, 975–1005. [Google Scholar]







| Attacker’s Capability | Attacker’s Goal | ||
|---|---|---|---|
| Integrity | Availability | Confidentiality | |
| Test data | Evasion (e.g., adversarial examples) | - | Model stealing, model inversion, membership inference, … |
| Train data | Poisoning for subsequent intrusions (e.g., backdoors) | Poisoning to maximise error | - |
| Attack | FGM-x | BIM-x | PGD-x | JSMA | DeepFool | CW | Universal Attack |
|---|---|---|---|---|---|---|---|
| Parameters | , | , | , |
| Attack | Pred Dev | Dist Dev | Conf Drop | Joint PD and CD | Feat Sqz | Mag Net | Pixel Defend | Subset Scan |
|---|---|---|---|---|---|---|---|---|
| FP rate | 2.45 | 4.75 | 4.89 | 5.76 | 3.02 | 5.32 | 5.04 | 4.60 |
| CW | 92.91 | 85.82 | 100.00 | 94.07 | 99.86 | 100.00 | 100.00 | 100.00 |
| DeepFool | 93.63 | 89.94 | 97.33 | 95.07 | 99.59 | 100.00 | 100.00 | 100.00 |
| JSMA | 95.83 | 93.24 | 100.00 | 96.40 | 99.86 | 100.00 | 88.63 | 72.95 |
| FGSM-0.1 | 72.41 | 77.59 | 81.03 | 81.03 | 94.83 | 100.00 | 100.00 | 100.00 |
| FGSM-0.2 | 88.39 | 90.26 | 99.25 | 92.13 | 99.63 | 100.00 | 100.00 | 100.00 |
| FGSM-0.3 | 93.84 | 92.92 | 99.77 | 95.43 | 100.00 | 100.00 | 100.00 | 100.00 |
| BIM-0.1 | 88.01 | 96.96 | 50.34 | 90.20 | 98.48 | 100.00 | 100.00 | 100.00 |
| BIM-0.2 | 86.76 | 96.12 | 73.38 | 89.50 | 84.32 | 100.00 | 100.00 | 100.00 |
| BIM-0.3 | 83.45 | 94.82 | 91.80 | 86.33 | 73.67 | 100.00 | 100.00 | 100.00 |
| PGD-0.1 | 89.47 | 96.60 | 54.62 | 91.73 | 98.87 | 100.00 | 100.00 | 100.00 |
| PGD-0.2 | 89.21 | 96.83 | 72.37 | 91.22 | 95.25 | 100.00 | 100.00 | 100.00 |
| PGD-0.3 | 89.78 | 96.55 | 88.20 | 91.22 | 98.27 | 100.00 | 100.00 | 100.00 |
| UnivJSMA | 97.64 | 94.61 | 100.00 | 97.98 | 99.66 | 100.00 | 100.00 | 100.00 |
| UnivDeepFool | 96.97 | 95.96 | 100.00 | 96.97 | 100.00 | 100.00 | 100.00 | 100.00 |
| UnivFGSM-0.1 | 97.51 | 97.01 | 100.00 | 98.01 | 100.00 | 100.00 | 100.00 | 100.00 |
| UnivFGSM-0.2 | 97.09 | 94.19 | 99.42 | 98.26 | 100.00 | 100.00 | 100.00 | 100.00 |
| UnivFGSM-0.3 | 98.28 | 95.40 | 100.00 | 98.85 | 100.00 | 100.00 | 100.00 | 100.00 |
| UnivBIM-0.1 | 96.83 | 94.44 | 91.27 | 97.62 | 95.24 | 100.00 | 100.00 | 100.00 |
| UnivBIM-0.2 | 95.80 | 93.28 | 45.38 | 96.64 | 98.32 | 100.00 | 100.00 | 100.00 |
| UnivBIM-0.3 | 98.15 | 96.30 | 97.22 | 98.15 | 99.07 | 100.00 | 100.00 | 100.00 |
| UnivPGD-0.1 | 90.96 | 96.99 | 100.00 | 92.17 | 100.00 | 100.00 | 100.00 | 100.00 |
| UnivPGD-0.2 | 96.41 | 95.81 | 52.69 | 98.20 | 99.40 | 100.00 | 100.00 | 100.00 |
| UnivPGD-0.3 | 97.74 | 95.49 | 99.25 | 97.74 | 100.00 | 100.00 | 100.00 | 100.00 |
| SAE rate | 91.35 | 91.99 | 89.12 | 93.21 | 97.09 | 100.00 | 98.38 | 96.14 |
| FAE rate | 6.69 | 42.74 | 85.64 | 11.05 | 94.76 | 99.50 | 100.00 | 100.00 |
| Harm. rate | 95.56 | 94.22 | 93.18 | 93.92 | 97.01 | 96.25 | 95.99 | 95.62 |
| F1 rate | 94.35 | 93.59 | 92.02 | 93.72 | 97.04 | 97.27 | 96.64 | 95.76 |
| Attack | Pred Dev | Dist Dev | Conf Drop | Feat Sqz | Mag Net | Pixel Defend | Subset Scan |
|---|---|---|---|---|---|---|---|
| FP rate | 3.34 | 5.38 | 4.22 | 5.52 | 5.09 | 3.49 | 5.09 |
| CW | 97.80 | 100.00 | 100.00 | 99.85 | 99.71 | 98.98 | 100.00 |
| DeepFool | 98.31 | 95.08 | 95.76 | 98.14 | 99.66 | 99.83 | 100.00 |
| JSMA | 99.85 | 100.00 | 100.00 | 99.27 | 100.00 | 49.49 | 23.49 |
| FGSM | 97.84 | 100.00 | 100.00 | 98.87 | 100.00 | 100.00 | 100.00 |
| BIM-0.1 | 97.90 | 99.84 | 100.00 | 99.84 | 100.00 | 100.00 | 100.00 |
| BIM-0.2 | 97.82 | 100.00 | 100.00 | 99.56 | 99.42 | 100.00 | 100.00 |
| BIM-0.3 | 96.66 | 100.00 | 100.00 | 97.97 | 70.64 | 100.00 | 100.00 |
| PGD-0.1 | 98.25 | 99.84 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| PGD-0.2 | 98.55 | 100.00 | 100.00 | 99.56 | 99.56 | 100.00 | 100.00 |
| PGD-0.3 | 98.26 | 100.00 | 100.00 | 99.42 | 75.44 | 100.00 | 100.00 |
| Universal | 99.66 | 100.00 | 100.00 | 99.94 | 99.94 | 11.44 | 100.00 |
| SAE rate | 98.47 | 99.28 | 99.39 | 99.27 | 97.12 | 79.96 | 89.07 |
| FAE rate | 1.94 | 99.99 | 100.00 | 78.17 | 93.44 | 86.18 | 100.00 |
| Harm. rate | 97.21 | 96.01 | 96.87 | 95.90 | 95.58 | 90.73 | 93.04 |
| F1 rate | 97.56 | 96.89 | 97.55 | 96.82 | 96.00 | 87.46 | 91.90 |
| Attack | Pred Dev | Dist Dev | Conf Drop | Joint PD and CD | Feat Sqz | Mag Net | Pixel Defend | Subset Scan |
|---|---|---|---|---|---|---|---|---|
| FP rate | 6.53 | 5.64 | 5.49 | 6.38 | 4.45 | 7.27 | 5.93 | 4.90 |
| CW | 90.06 | 96.88 | 94.66 | 99.55 | 42.88 | 90.65 | 11.13 | 80.86 |
| DeepFool | 91.02 | 89.77 | 92.07 | 93.11 | 23.80 | 87.68 | 20.46 | 84.76 |
| JSMA | 99.11 | 98.66 | 97.77 | 98.07 | 70.92 | 83.83 | 26.26 | 13.65 |
| FGM-0.1 | 89.77 | 100.00 | 100.00 | 100.00 | 65.51 | 88.12 | 100.00 | 100.00 |
| FGM-0.2 | 86.50 | 100.00 | 100.00 | 100.00 | 73.17 | 88.29 | 100.00 | 100.00 |
| FGM-0.3 | 75.49 | 100.00 | 100.00 | 100.00 | 77.27 | 81.01 | 100.00 | 100.00 |
| BIM-0.1 | 86.80 | 100.00 | 100.00 | 100.00 | 83.83 | 99.70 | 100.00 | 85.31 |
| BIM-0.2 | 81.90 | 100.00 | 100.00 | 100.00 | 95.85 | 98.96 | 100.00 | 94.81 |
| BIM-0.3 | 74.78 | 100.00 | 100.00 | 100.00 | 97.92 | 98.22 | 100.00 | 97.33 |
| PGD-0.1 | 90.65 | 100.00 | 100.00 | 100.00 | 64.84 | 100.00 | 100.00 | 86.35 |
| PGD-0.2 | 89.91 | 100.00 | 100.00 | 100.00 | 74.33 | 100.00 | 100.00 | 99.55 |
| PGD-0.3 | 85.01 | 100.00 | 100.00 | 100.00 | 80.86 | 100.00 | 100.00 | 100.00 |
| UnivJSMA | 38.28 | 100.00 | 100.00 | 100.00 | 17.70 | 77.03 | 49.76 | 15.31 |
| Universal etc. | 93.79 | 99.78 | 99.87 | 99.81 | 65.79 | 96.55 | 99.97 | 99.42 |
| SAE rate | 88.93 | 97.87 | 97.77 | 98.65 | 62.41 | 91.67 | 64.75 | 79.83 |
| FAE rate | 6.23 | 98.51 | 97.70 | 99.07 | 50.57 | 82.14 | 71.86 | 91.47 |
| Harm. rate | 92.03 | 95.42 | 95.49 | 95.11 | 82.13 | 92.40 | 82.56 | 89.82 |
| F1 rate | 91.15 | 96.09 | 96.11 | 96.07 | 75.50 | 92.20 | 76.70 | 86.80 |
| Attack | Pred Dev | Dist Dev | Conf Drop | Joint PD and CD | Feat Sqz | Mag Net | Pixel Defend | Subset Scan |
|---|---|---|---|---|---|---|---|---|
| FP rate | 4.10 | 5.93 | 7.29 | 4.71 | 3.04 | 7.29 | 5.47 | 4.86 |
| CW | 83.59 | 68.54 | 53.50 | 84.65 | 96.05 | 82.37 | 6.69 | 5.02 |
| DeepFool | 83.04 | 68.42 | 57.31 | 83.33 | 93.86 | 79.82 | 6.43 | 6.43 |
| JSMA | 91.34 | 82.83 | 69.91 | 90.12 | 74.77 | 86.63 | 5.47 | 8.36 |
| FGM-0.1 | 81.55 | 99.82 | 100.00 | 100.00 | 3.16 | 35.33 | 82.78 | 100.00 |
| FGM-0.2 | 67.13 | 100.00 | 100.00 | 100.00 | 0.17 | 41.18 | 99.31 | 100.00 |
| FGM-0.3 | 81.62 | 100.00 | 100.00 | 100.00 | 0.00 | 53.79 | 100.00 | 100.00 |
| BIM-0.1 | 85.26 | 100.00 | 100.00 | 100.00 | 0.00 | 99.39 | 15.96 | 100.00 |
| BIM-0.2 | 85.26 | 100.00 | 100.00 | 100.00 | 0.00 | 99.54 | 41.79 | 100.00 |
| BIM-0.3 | 85.26 | 100.00 | 100.00 | 100.00 | 0.00 | 99.85 | 47.57 | 100.00 |
| PGD-0.1 | 56.23 | 100.00 | 100.00 | 100.00 | 0.00 | 99.85 | 13.98 | 99.70 |
| PGD-0.2 | 19.91 | 100.00 | 100.00 | 100.00 | 0.00 | 100.00 | 97.26 | 100.00 |
| PGD-0.3 | 22.64 | 100.00 | 100.00 | 100.00 | 0.00 | 100.00 | 99.85 | 100.00 |
| UnivJSMA | 57.32 | 57.32 | 52.44 | 47.56 | 54.88 | 65.85 | 0.00 | 17.07 |
| Universal etc. | 77.53 | 99.63 | 99.84 | 99.42 | 3.58 | 63.53 | 72.90 | 99.84 |
| SAE rate | 75.52 | 87.93 | 82.32 | 98.26 | 39.15 | 79.36 | 40.62 | 58.86 |
| FAE rate | 60.94 | 87.22 | 82.68 | 83.86 | 33.40 | 55.17 | 55.32 | 65.98 |
| Harm. rate | 88.54 | 92.09 | 89.24 | 94.65 | 66.67 | 88.15 | 67.12 | 79.97 |
| F1 rate | 84.49 | 90.90 | 87.20 | 94.26 | 55.78 | 85.52 | 56.83 | 72.73 |
| Only CNN | PredDev | DistDev | ConfDrop | |
|---|---|---|---|---|
| L2 distance | 4.75 | 5.61 | 5.29 | 5.56 |
| Queries | 50.81 | 424.75 | 1180.96 | 10,000.08 |
| Iterations | 4.98 | 34.49 | 92.10 | 761.47 |
| Detection rate (%) | — | 74.26 | 16.83 | 89.11 |
| Only CNN | PredDev | DistDev | ConfDrop | |
|---|---|---|---|---|
| L2 distance | 1.41 | 1.49 | 1.45 | 1.53 |
| Queries | 173.70 | 2568.34 | 438.84 | 2156.13 |
| Iterations | 14.89 | 197.86 | 36.35 | 169.27 |
| Detection rate (%) | — | 69.30 | 51.48 | 72.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feldsar, B.; Mayer, R.; Rauber, A. Detecting Adversarial Examples Using Surrogate Models. Mach. Learn. Knowl. Extr. 2023, 5, 1796-1825. https://doi.org/10.3390/make5040087
Feldsar B, Mayer R, Rauber A. Detecting Adversarial Examples Using Surrogate Models. Machine Learning and Knowledge Extraction. 2023; 5(4):1796-1825. https://doi.org/10.3390/make5040087
Chicago/Turabian StyleFeldsar, Borna, Rudolf Mayer, and Andreas Rauber. 2023. "Detecting Adversarial Examples Using Surrogate Models" Machine Learning and Knowledge Extraction 5, no. 4: 1796-1825. https://doi.org/10.3390/make5040087
APA StyleFeldsar, B., Mayer, R., & Rauber, A. (2023). Detecting Adversarial Examples Using Surrogate Models. Machine Learning and Knowledge Extraction, 5(4), 1796-1825. https://doi.org/10.3390/make5040087