
GAN-Based Tabular Data Generator for Constructing Synopsis in Approximate Query Processing: Challenges and Solutions


Abstract
:1. Introduction
2. Background
2.1. Data Synopsis in Databases
2.2. Approximate Query Processing (AQP)
2.3. Synopsis Construction
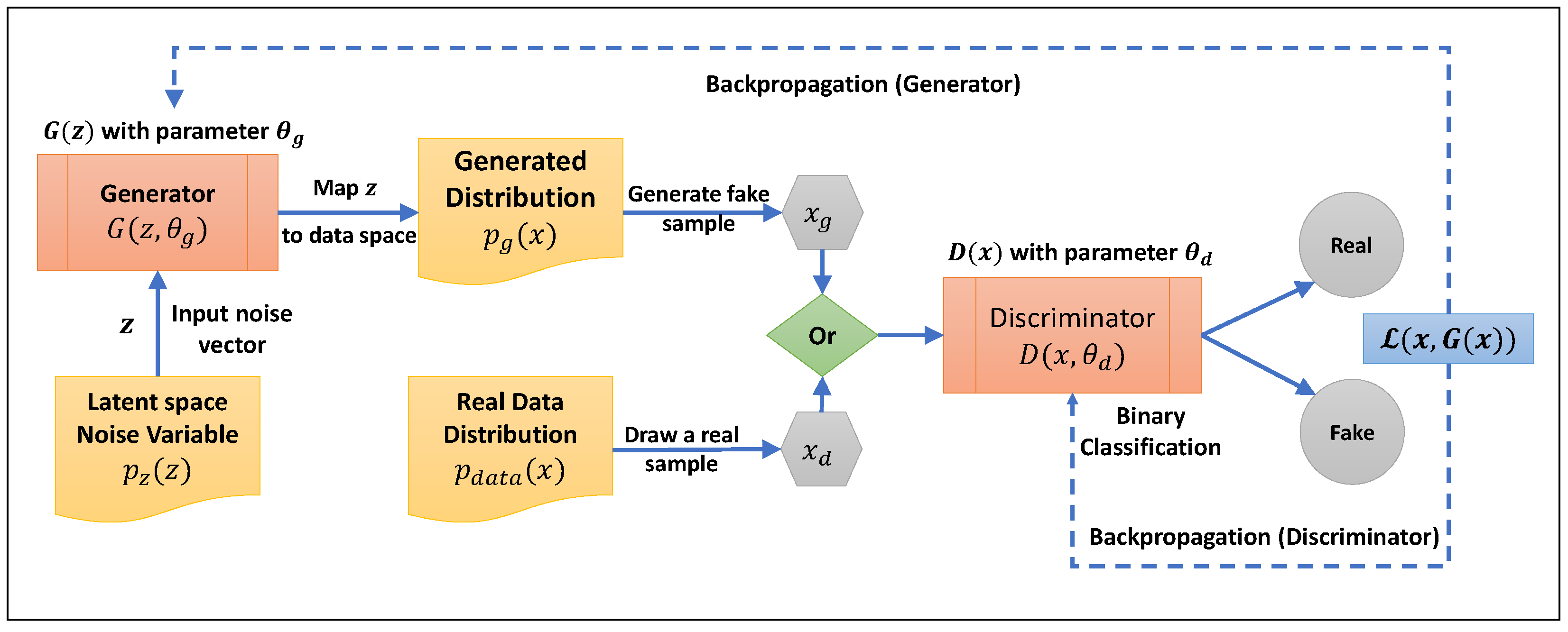
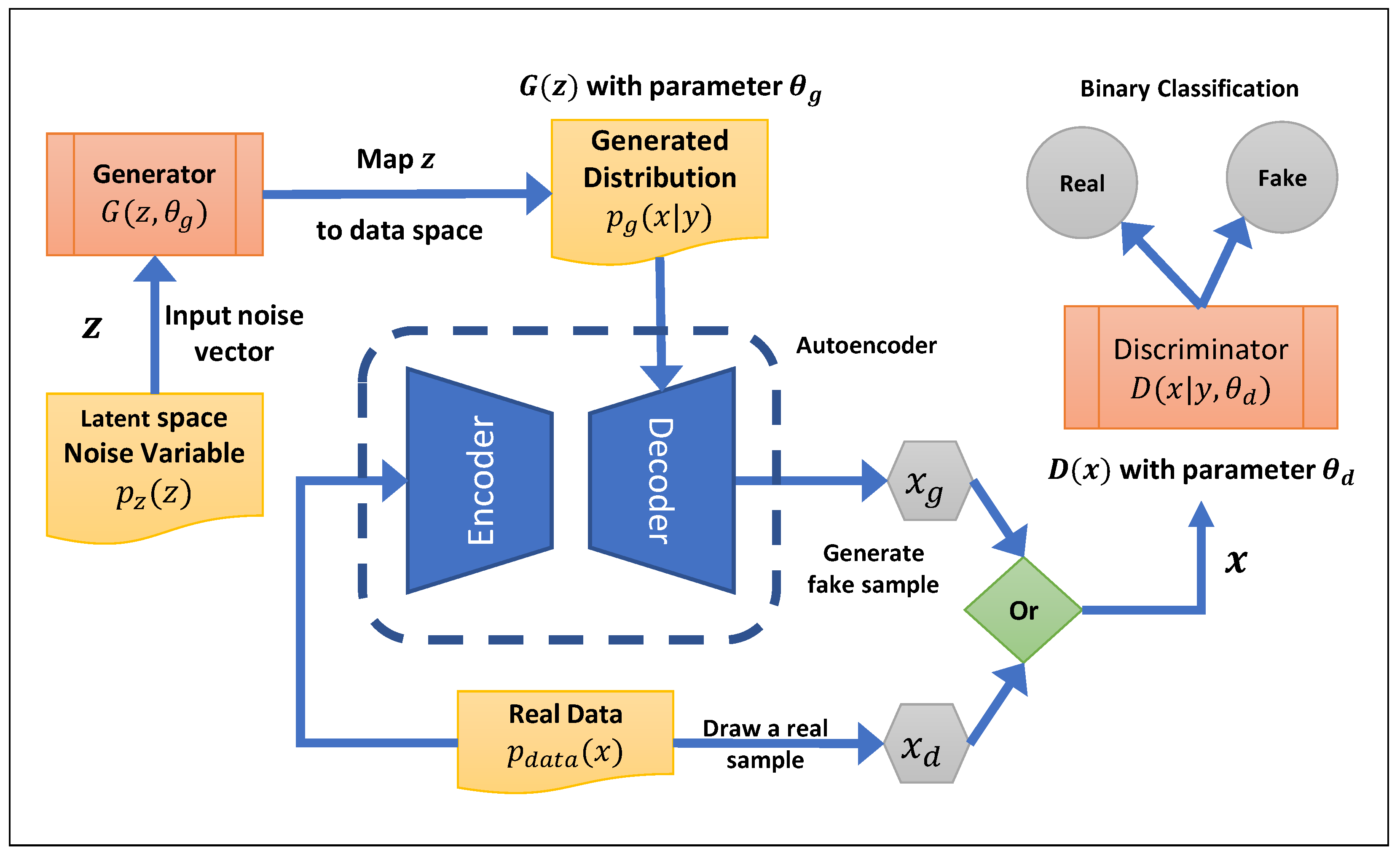
2.4. GAN-Based Tabular Generator
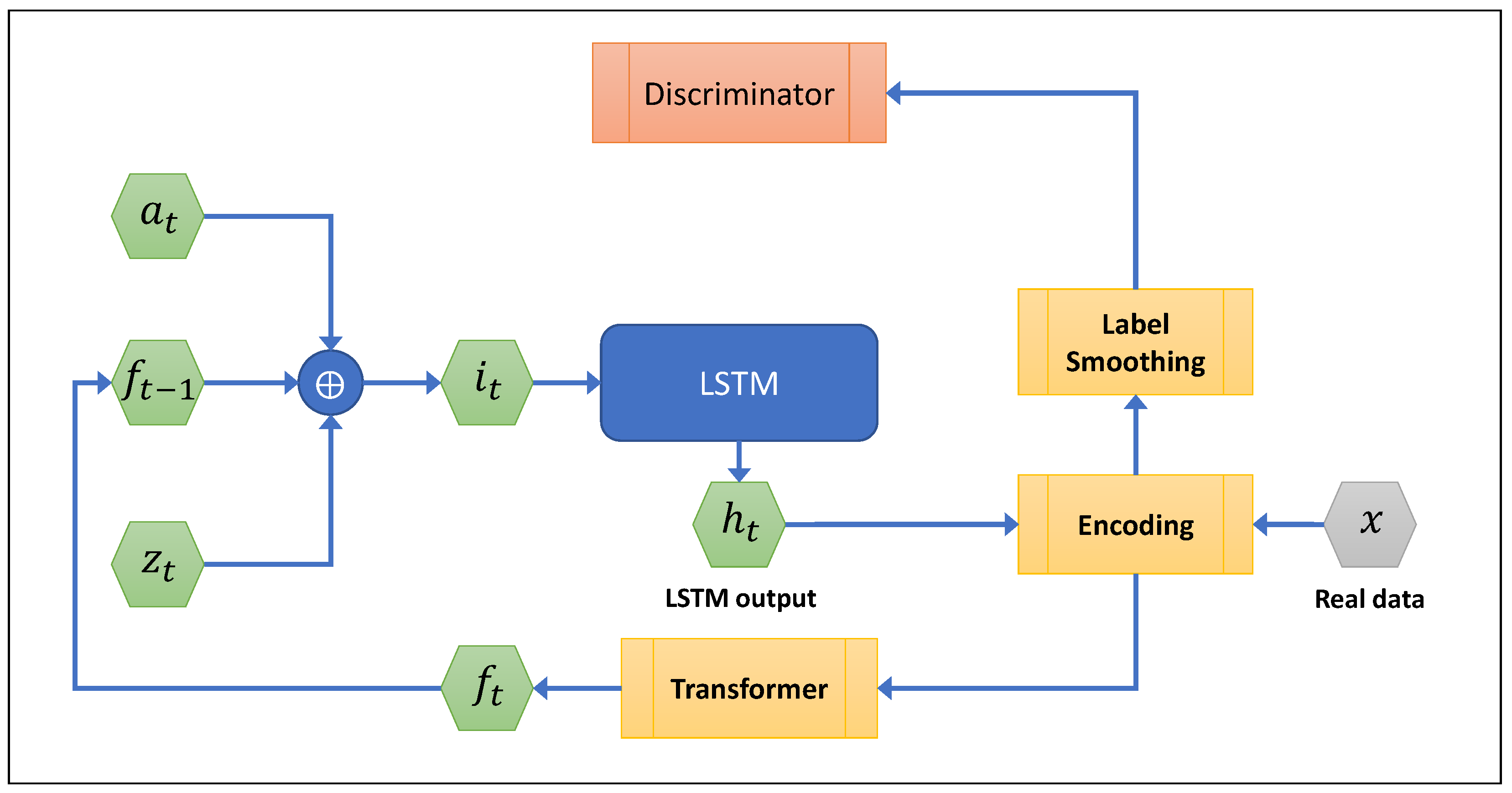
2.5. Tabular GAN Evolution
3. Synopsis Construction Challenges
3.1. Data Type
3.2. Bounded Continuous Columns
3.3. Non-Gaussian Distribution
3.4. Imbalanced Categorical Columns
3.5. Semantic Relationships and Constraints
4. GAN-Based Synopsis Construction Solutions
4.1. Data Transformation
4.2. Distribution Matching
4.3. Conditional and Informed Generator
4.4. Comparative Analysis of GAN-Based Methods
5. Synopsis Evaluation and Error Estimation
- Query Type: In terms of aggregation functions and conditions, what types of queries are covered by the methods?
- Time Complexity: How long does it take to produce the synopses and return an approximate result?
- Space Complexity: What is the required storage space for data synopses?
- Accuracy: Does the approximate answer meet the error confidence interval?
5.1. Data Coverage
5.2. Data Constraint
5.3. Data Similarity
5.4. Data Relationship
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sagiroglu, S.; Sinanc, D. Big data: A review. In Proceedings of the 2013 International Conference on Collaboration Technologies and Systems (CTS), San Diego, CA, USA, 20–24 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 42–47. [Google Scholar]
- Li, K.; Li, G. Approximate query processing: What is new and where to go? Data Sci. Eng. 2018, 3, 379–397. [Google Scholar] [CrossRef]
- Muniswamaiah, M.; Agerwala, T.; Tappert, C.C. Approximate Query Processing for Big Data in Heterogeneous Databases. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5765–5767. [Google Scholar]
- Hellerstein, J.M.; Haas, P.J.; Wang, H.J. Online aggregation. In Proceedings of the ACM SIGMOD, Tucson, AZ, USA, 11–15 May 1997; Volume 26, pp. 171–182. [Google Scholar]
- Chaudhuri, S.; Ding, B.; Kandula, S. Approximate query processing: No silver bullet. In Proceedings of the SIGMOD/PODS 17: ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 511–519. [Google Scholar]
- Ma, Q.; Triantafillou, P. Dbest: Revisiting approximate query processing engines with machine learning models. In Proceedings of the SIGMOD 19: 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 1553–1570. [Google Scholar]
- Zhang, M.; Wang, H. LAQP: Learning-based approximate query processing. Inf. Sci. 2021, 546, 1113–1134. [Google Scholar] [CrossRef]
- Savva, F.; Anagnostopoulos, C.; Triantafillou, P. Ml-aqp: Query-driven approximate query processing based on machine learning. arXiv 2020, arXiv:2003.06613. [Google Scholar]
- Ruthotto, L.; Haber, E. An introduction to deep generative modeling. GAMM-Mitteilungen 2021, 44, e202100008. [Google Scholar] [CrossRef]
- Thirumuruganathan, S.; Hasan, S.; Koudas, N.; Das, G. Approximate query processing for data exploration using deep generative models. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1309–1320. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I. Nips 2016 tutorial: Generative adversarial networks. arXiv 2016, arXiv:1701.00160. [Google Scholar]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A review on generative adversarial networks: Algorithms, theory, and applications. IEEE Trans. Knowl. Data Eng. 2021, 35, 3313–3332. [Google Scholar] [CrossRef]
- Markl, V. Query Processing (in Relational Databases). In Encyclopedia of Database Systems; Springer: Boston, MA, USA, 2009; pp. 2288–2293. [Google Scholar] [CrossRef]
- Spiegel, J.; Polyzotis, N. Graph-based synopses for relational selectivity estimation. In Proceedings of the 2006 ACM SIGMOD International Conference on Management of Data, Chicago, IL, USA, 27–29 June 2006; pp. 205–216. [Google Scholar]
- Liu, Q. Approximate Query Processing; Springer: Boston, MA, USA, 2009. [Google Scholar]
- Spiegel, J.; Polyzotis, N. TuG synopses for approximate query answering. ACM Trans. Database Syst. (TODS) 2009, 34, 1–56. [Google Scholar] [CrossRef]
- Mozafari, B.; Niu, N. A Handbook for Building an Approximate Query Engine. IEEE Data Eng. Bull. 2015, 38, 3–29. [Google Scholar]
- Aggarwal, C.C.; Yu, P.S. A survey of synopsis construction in data streams. In Data Streams; Springer: Boston, MA, USA, 2007; pp. 169–207. [Google Scholar]
- Tan, J.; Zhang, D.; Zhang, H.; Zhang, Z. One-pass streaming algorithm for DR-submodular maximization with a knapsack constraint over the integer lattice. Comput. Electr. Eng. 2022, 99, 107766. [Google Scholar] [CrossRef]
- Zhang, Q. Data Sampling. In Encyclopedia of Database Systems; Springer: Boston, MA, USA, 2009; pp. 630–634. [Google Scholar] [CrossRef]
- Piatetsky-Shapiro, G.; Connell, C. Accurate estimation of the number of tuples satisfying a condition. ACM Sigmod Rec. 1984, 14, 256–276. [Google Scholar] [CrossRef]
- Russell, S.; Yoon, V. Applications of wavelet data reduction in a recommender system. Expert Syst. Appl. 2008, 34, 2316–2325. [Google Scholar] [CrossRef]
- Yang, T.; Liu, L.; Yan, Y.; Shahzad, M.; Shen, Y.; Li, X.; Cui, B.; Xie, G. Sf-sketch: A fast, accurate, and memory efficient data structure to store frequencies of data items. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 103–106. [Google Scholar]
- Halevy, A.Y. Answering queries using views: A survey. VLDB J. 2001, 10, 270–294. [Google Scholar] [CrossRef]
- Wang, Z.; She, Q.; Ward, T.E. Generative adversarial networks in computer vision: A survey and taxonomy. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Choi, E.; Biswal, S.; Malin, B.; Duke, J.; Stewart, W.F.; Sun, J. Generating multi-label discrete patient records using generative adversarial networks. In Proceedings of the 2nd Machine Learning for Healthcare Conference, Boston, MA, USA, 18–19 August 2017; pp. 286–305. [Google Scholar]
- Mottini, A.; Lheritier, A.; Acuna-Agost, R. Airline passenger name record generation using generative adversarial networks. arXiv 2018, arXiv:1807.06657. [Google Scholar]
- Bellemare, M.G.; Danihelka, I.; Dabney, W.; Mohamed, S.; Lakshminarayanan, B.; Hoyer, S.; Munos, R. The cramer distance as a solution to biased wasserstein gradients. arXiv 2017, arXiv:1705.10743. [Google Scholar]
- Park, N.; Mohammadi, M.; Gorde, K.; Jajodia, S.; Park, H.; Kim, Y. Data synthesis based on generative adversarial networks. arXiv 2018, arXiv:1806.03384. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Xu, L.; Veeramachaneni, K. Synthesizing tabular data using generative adversarial networks. arXiv 2018, arXiv:1811.11264. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley Series in Telecommunications and Signal Processing, Wiley-Interscience; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling tabular data using Conditional GAN. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Zhao, Z.; Kunar, A.; Birke, R.; Chen, L.Y. CTAB-GAN: Effective table data synthesizing. In Proceedings of the Asian Conference on Machine Learning, Virtual, 17–19 November 2021; pp. 97–112. [Google Scholar]
- Lederrey, G.; Hillel, T.; Bierlaire, M. DATGAN: Integrating expert knowledge into deep learning for synthetic tabular data. arXiv 2022, arXiv:2203.03489. [Google Scholar]
- Khurana, U.; Galhotra, S. Semantic Annotation for Tabular Data. arXiv 2020, arXiv:2012.08594. [Google Scholar]
- Deecke, L.; Murray, I.; Bilen, H. Mode normalization. In Proceedings of the Seventh International Conference on Learning Representations, ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein GANs. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier GANs. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Saxena, D.; Cao, J. Generative adversarial networks (GANs) challenges, solutions, and future directions. ACM Comput. Surv. (CSUR) 2021, 54, 1–42. [Google Scholar] [CrossRef]
- Kodali, N.; Abernethy, J.; Hays, J.; Kira, Z. On convergence and stability of gans. arXiv 2017, arXiv:1705.07215. [Google Scholar]
- Fonseca, J.; Bacao, F. Tabular and latent space synthetic data generation: A literature review. J. Big Data 2023, 10, 115. [Google Scholar] [CrossRef]
- Pathare, A.; Mangrulkar, R.; Suvarna, K.; Parekh, A.; Thakur, G.; Gawade, A. Comparison of tabular synthetic data generation techniques using propensity and cluster log metric. Int. J. Inf. Manag. Data Insights 2023, 3, 100177. [Google Scholar] [CrossRef]
- Dell’Aquila, C.; Di Tria, F.; Lefons, E.; Tangorra, F. Accuracy estimation in approximate query processing. In Proceedings of the 14th WSEAS International Conference on Computers: Part of the 14th WSEAS CSCC Multiconference, Corfu Island, Greece, 23–25 July 2010; Volume 2, pp. 452–458. [Google Scholar]
- Gretton, A.; Borgwardt, K.; Rasch, M.; Schölkopf, B.; Smola, A. A kernel method for the two-sample-problem. In Proceedings of the Advances in Neural Information Processing Systems 19 (NIPS 2006), Vancouver, BC, Canada, 4–7 December 2006. [Google Scholar]
- Theis, L.; Oord, A.v.d.; Bethge, M. A note on the evaluation of generative models. In Proceedings of the International Conference on Learning Representations (ICLR 2016), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- DataCebo, Inc. Synthetic Data Metrics, v0.7.0; DataCebo, Inc.: Weston, MA, USA, 2022. [Google Scholar]
- Becker, B.; Kohavi, R. Adult. In UCI Machine Learning Repository; 1996. [Google Scholar] [CrossRef]
- Kamthe, S.; Assefa, S.; Deisenroth, M. Copula flows for synthetic data generation. arXiv 2021, arXiv:2101.00598. [Google Scholar]
- Biskup, J. A formal approach to null values in database relations. In Advances in Data Base Theory; Springer: Boston, MA, USA, 1981; pp. 299–341. [Google Scholar]
- Date, C.J. Database Design and Relational Theory: Normal Forms and All That Jazz; Apress: New York, NY, USA, 2019. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variant | Capability | Generator | Discriminator | Extra Loss Functions | Additional Networks |
|---|---|---|---|---|---|
| medGAN | Generate high-dimensional discrete columns. | FNN * | FCN * | MSE | Autoencoder |
| Avoid mode collapse. | Cross-entropy | ||||
| PNR-GAN | Generate discrete columns. | Cross-Layer FCN | Cross-Layer FCN | Cramer loss | |
| Handle null values. | |||||
| table-GAN | Increase semantic integrity. | CNN * | CNN | Information loss | Classifier (MLP *) |
| Classification loss | |||||
| TGAN | Learn multimodal distributions. | LSTM * | FCN | Cross-entropy | |
| Generate mixed-type variables. | |||||
| CTGAN | Learn non-Gaussian and multimodal distributions. | FCN | FCN | Wasserstein loss with gradient penalty | |
| Address imbalanced discrete column issue. | |||||
| CTAB-GAN | Generate discrete and mixed-type columns. | CNN | CNN | Cross-entropy | Classifier (MLP) |
| Address imbalanced discrete column issue. | Information loss | ||||
| Learn long-tail distributions. | Classification loss | ||||
| DATGAN | Increase semantic integrity. | LSTM | FCN | Wasserstein loss with gradient penalty | DAG |
| Increase representation of imbalanced class. |
| Data Type | Possible Role in Queries | ||
|---|---|---|---|
| Numerical | Continuous | Numeric intervals of real numbers without a finite set of values | aggregation, condition |
| Discrete | Finite, countable set of integer numbers | aggregation, condition, groupby | |
| Mixed | Numeric, but considered as categorical based on the different range | aggregation, condition, groupby | |
| Categorical | Binary | One-hot encoded | condition, groupby |
| Textual | One-hot encoding needed | condition, groupby | |
| Numeric | Treats textual and numbers as meaningless. | condition, groupby | |
| Ordinal | Numeric | Numeric categories with a clear ordering (like 1–5 rating) | aggregation, condition, groupby |
| Aspect | GAN-Based Methods | Traditional Methods |
|---|---|---|
| Data Complexity | Excels at high-dimensional, complex data. | Suited for simpler, lower-dimensional data. |
| Realism | Generates highly realistic and detailed data. | Less capable of producing realistic data. |
| Computational Load | Higher, but necessary for complex model training. | Lower, but may compromise data complexity. |
| Ease of Use | Complex, but offers superior results for skilled users. | Simpler, but limited in advanced capabilities. |
| Versatility | Highly versatile for various domains and data types. | Limited versatility and application scope. |
| Control Over Data | Advanced techniques allow increased control. | More direct control, but at the expense of data quality. |
| Adaptability | Adapts well to new and evolving data patterns. | Less adaptive to changing data environments. |
| Innovation Potential | Continually evolving with cutting-edge research. | Lacks the rapid innovation seen in GAN-based methods. |
| Data Augmentation | Superior at generating novel data variations. | Basic augmentation capabilities. |
| Privacy Preservation | Can be tailored for privacy-preserving data generation. | Often lacks sophisticated privacy-preserving mechanisms. |
| Column | Metric | Copula | CTGAN | VAE | Copula-GAN |
|---|---|---|---|---|---|
| age | KS Statistic | 0.97 | 0.89 | 0.90 | 0.94 |
| workclass | TVD Statistic | 0.98 | 0.79 | 0.89 | 0.94 |
| fnlwgt | KS Statistic | 0.93 | 0.97 | 0.55 | 0.90 |
| education | TVD Statistic | 0.97 | 0.88 | 0.92 | 0.91 |
| education-num | KS Statistic | 0.85 | 0.93 | 0.96 | 0.94 |
| marital-status | TVD Statistic | 0.97 | 0.93 | 0.94 | 0.95 |
| occupation | TVD Statistic | 0.96 | 0.81 | 0.91 | 0.88 |
| relationship | TVD Statistic | 0.98 | 0.88 | 0.91 | 0.88 |
| race | TVD Statistic | 0.98 | 0.96 | 0.96 | 0.96 |
| sex | TVD Statistic | 0.99 | 0.92 | 0.98 | 0.93 |
| capital-gain | KS Statistic | 0.09 | 0.44 | 0.59 | 0.94 |
| capital-loss | KS Statistic | 0.53 | 0.97 | 0.99 | 0.96 |
| hours-per-week | KS Statistic | 0.78 | 0.93 | 0.96 | 0.93 |
| native-country | TVD Statistic | 0.97 | 0.90 | 0.93 | 0.87 |
| income | TVD Statistic | 0.99 | 0.98 | 0.97 | 0.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fallahian, M.; Dorodchi, M.; Kreth, K. GAN-Based Tabular Data Generator for Constructing Synopsis in Approximate Query Processing: Challenges and Solutions. Mach. Learn. Knowl. Extr. 2024, 6, 171-198. https://doi.org/10.3390/make6010010
Fallahian M, Dorodchi M, Kreth K. GAN-Based Tabular Data Generator for Constructing Synopsis in Approximate Query Processing: Challenges and Solutions. Machine Learning and Knowledge Extraction. 2024; 6(1):171-198. https://doi.org/10.3390/make6010010
Chicago/Turabian StyleFallahian, Mohammadali, Mohsen Dorodchi, and Kyle Kreth. 2024. "GAN-Based Tabular Data Generator for Constructing Synopsis in Approximate Query Processing: Challenges and Solutions" Machine Learning and Knowledge Extraction 6, no. 1: 171-198. https://doi.org/10.3390/make6010010
APA StyleFallahian, M., Dorodchi, M., & Kreth, K. (2024). GAN-Based Tabular Data Generator for Constructing Synopsis in Approximate Query Processing: Challenges and Solutions. Machine Learning and Knowledge Extraction, 6(1), 171-198. https://doi.org/10.3390/make6010010