




Distributed Learning in the IoT–Edge–Cloud Continuum


Abstract
:1. Introduction
Related Works
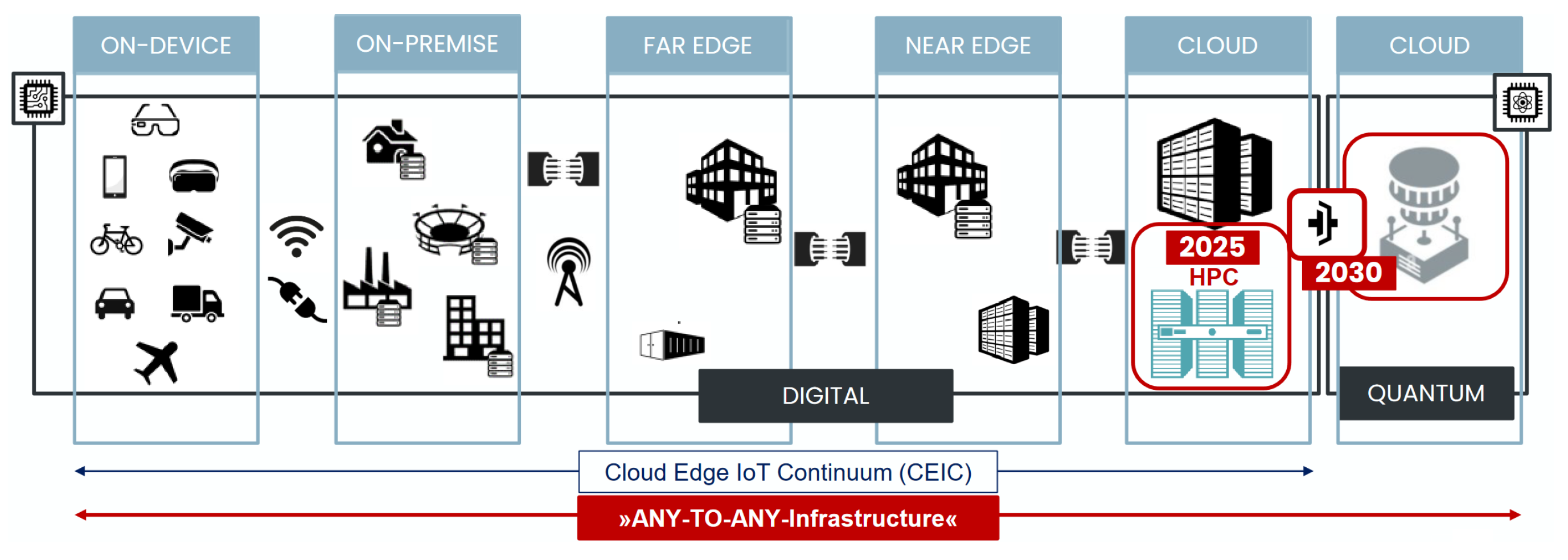
2. IoT–Edge–Cloud Continuum
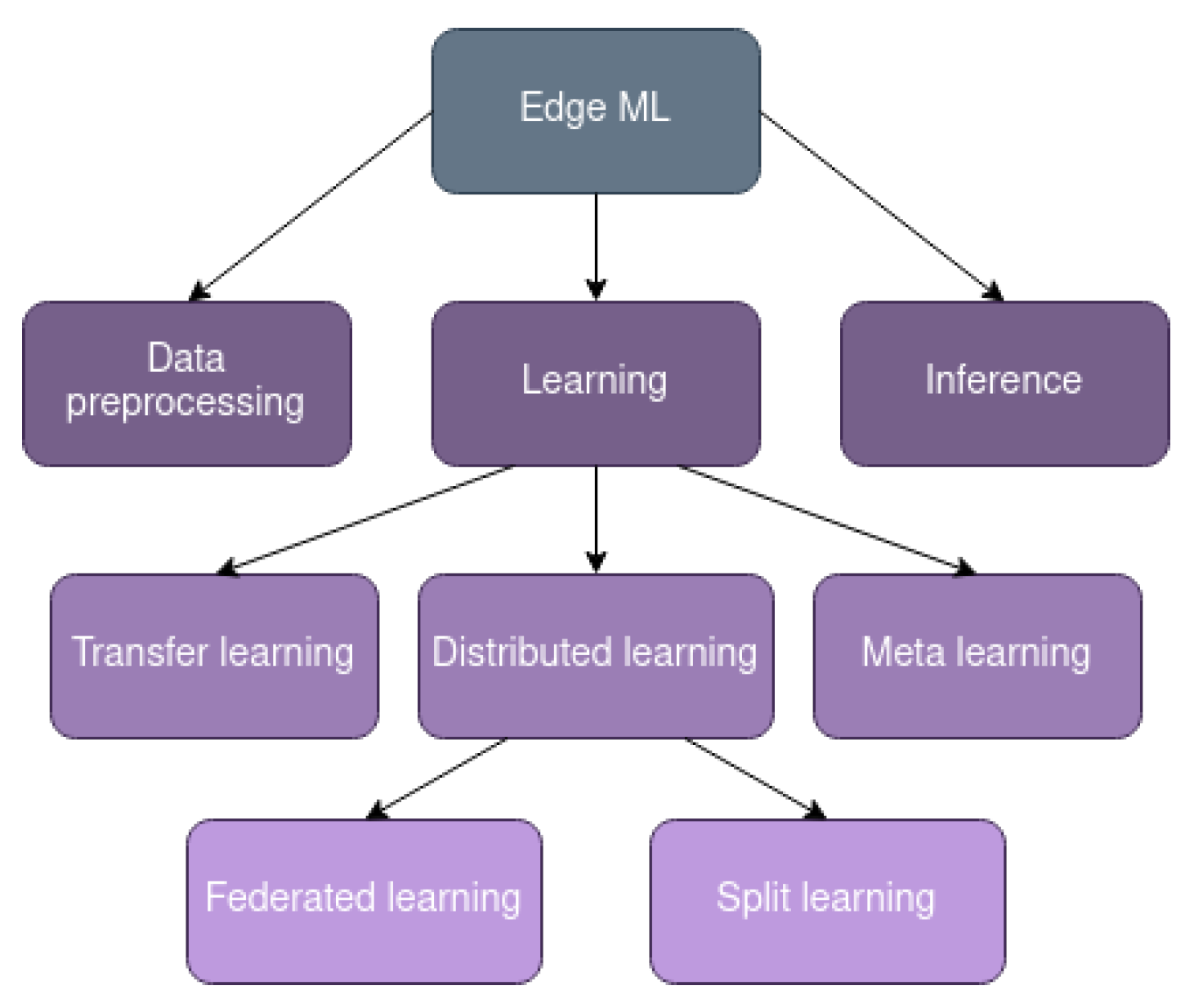
3. Distributed Learning
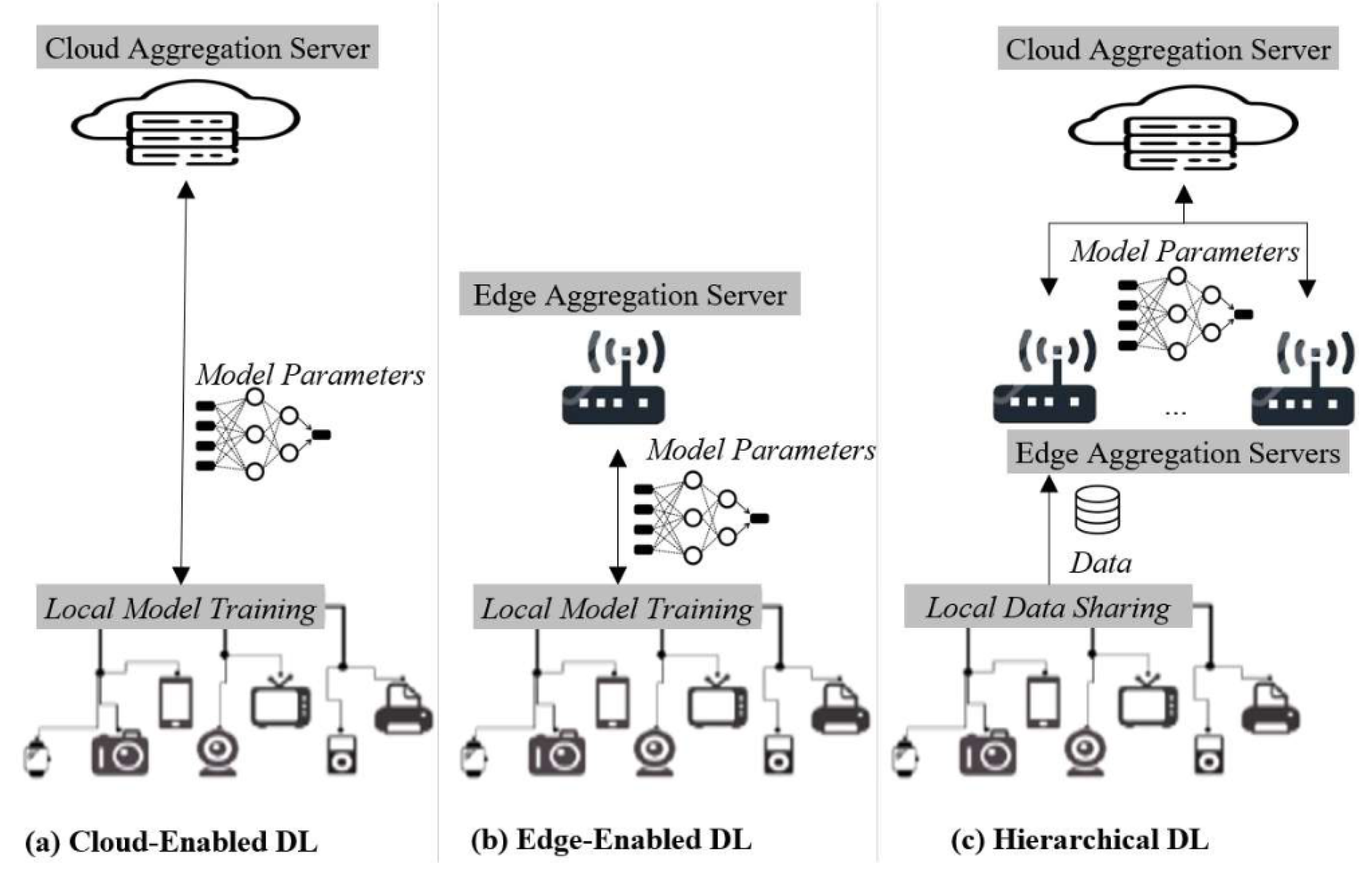
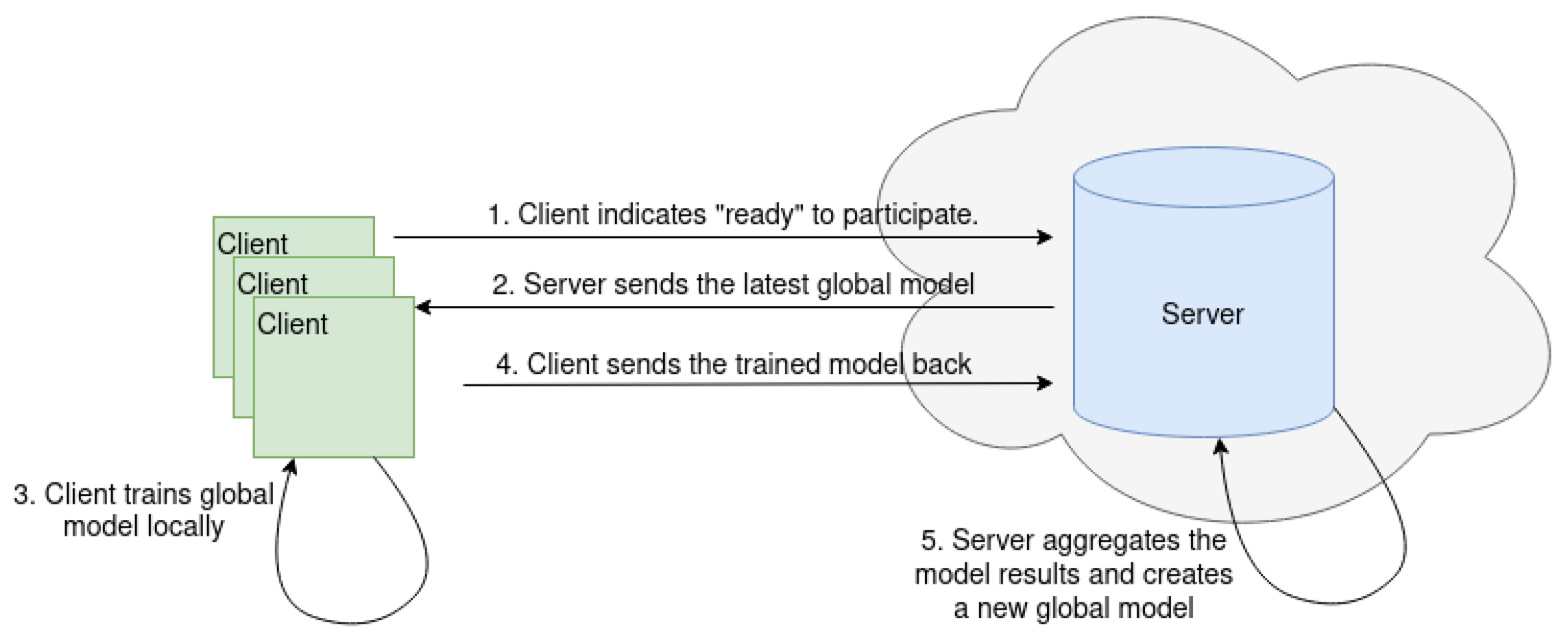
3.1. Federated Learning
- FedAvg—The default aggregating method that takes the average of received model results [23];
- FedProx—Improves the FedAvg method by adding regularization to optimize the aggregation results by limiting the differences between the local and global models. This method decreases the influence of result heterogeneity. Tian Li et al. [24] proposed this method and compared its effectiveness to FedAvg. The results showed that, in cases where there are no stragglers, both methods have essentially the same performance. However, by increasing the straggler count, the FedProx method beat FedAvg by a large margin. This was achieved by introducing a proximal term that defines the proximity of the local model in relation to the global model—this controls how far the local model can train away from the global model; thus, limiting the overfitting to the local model features. This results in the local model being closer to the global model. This problem may be the result of the local models having different local data features, dimensions, and other characteristics that make the model train further from other local models, including the global model. The FedProx method gets the best results because it uses the results from stragglers later on in the training process, and even uses their unfinished training results, while FedAvg just ignores them [24];
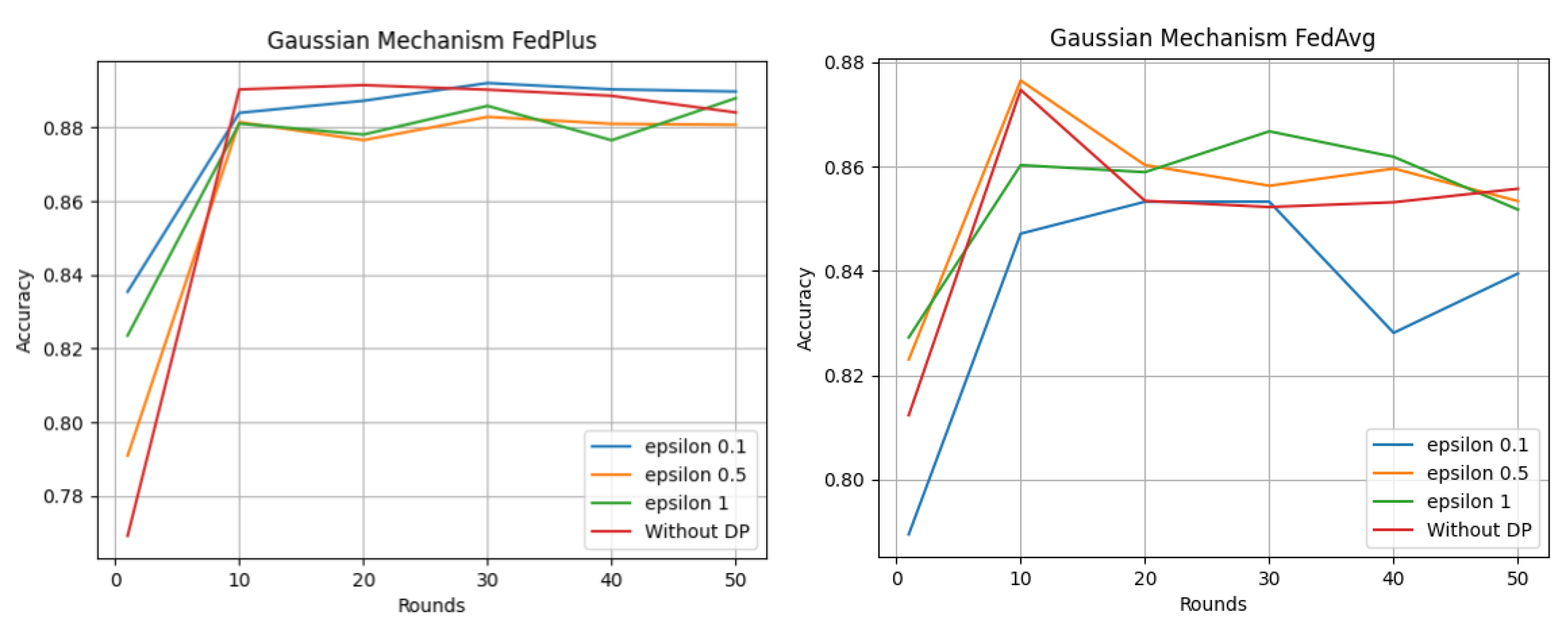
- Fed+—With this method, the clients have to start each training round with the local model gradients of the previous round. In this way, the local model features do not get lost after the aggregation step. This is why the usage of one global model is not required. This allows the aggregation to be organized in a hybrid manner—using Fel+ with other methods, e.g., FedAvg [25]. Pedro Ruzafa-Alcázar et al. [26] compared differential privacy approaches using two aggregation methods—Fed+ and FedAvg. In Figure 8, it can be seen that Fed+ reaches more stable and better results in comparison to the FedAvg method when the number of training rounds is increased. Epsilon denotes the privacy level of the training—the smaller the epsilon, the more private the training. The task of the models was to classify the intrusion type in IoT networks, e.g., DoS (Denial-of-Service) attacks using an open dataset;
- FedPAQ—Reisizadeh et al. [27] presented the method in which the aggregation rounds are created periodically, but the local model gradients are updated constantly. In order to decrease the delay that is created when the nodes are exchanging the model results and in order to make the model converge faster, client model results are quantized before sending them to the server. The authors analyzed the resulting training time for the new method by comparing it to the FedAvg approach. For all quantization levels that were used, the proposed approach allowed the model to converge faster in comparison to FedAvg;
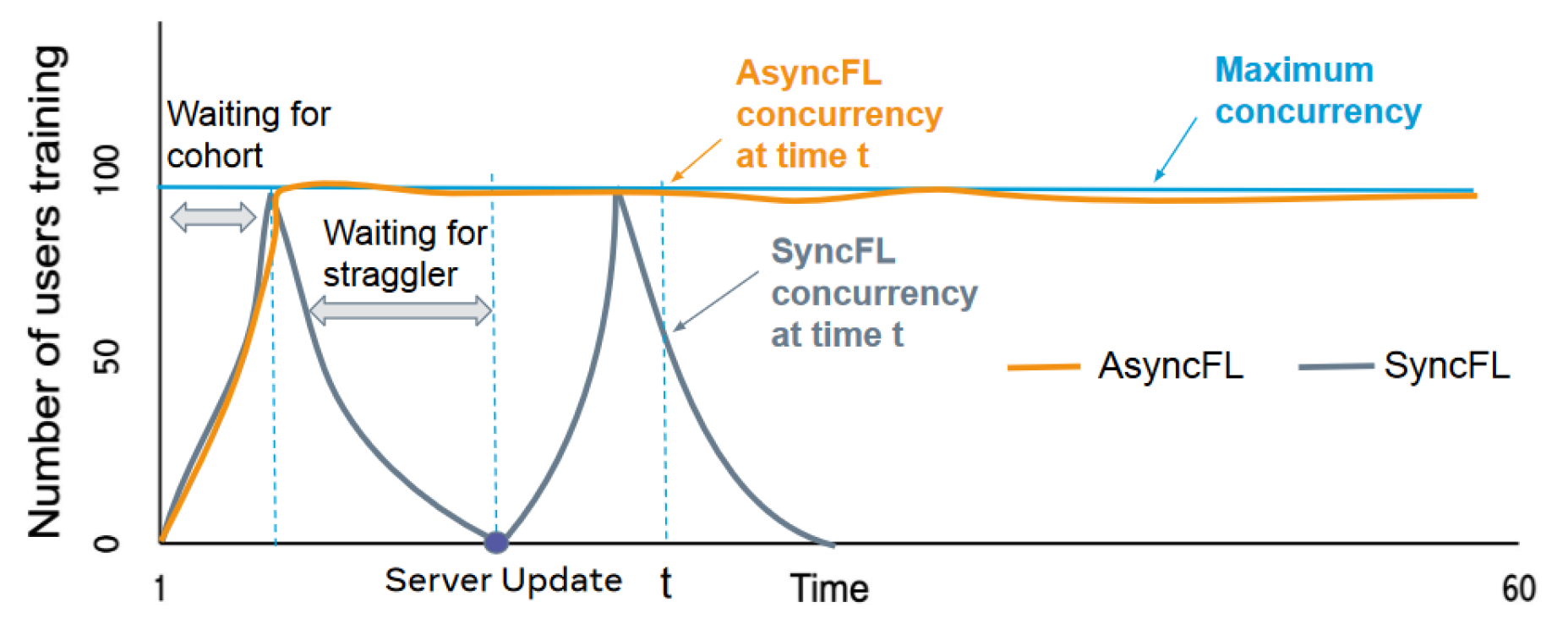
- FedBuff—This is an asynchronous FL aggregation method that aggregates the client gradients at the server with increased security by saving their gradients in a secure buffer, e.g., a trusted execution environment. In Table 1, a performance comparison between FedBuff, FedAvg, and FedProx can be seen. Three datasets were used—CelebA, Send140, and CIFAR-10. The precision column shows the achievable precision for each dataset. The columns for aggregation methods describe the necessary communication time count between the clients and the server. One unit represents 1000 trips. Table 1 shows that with FedBuff, we obtain an approximately 8.5x speedup in comparison to other methods for CelebA, a 5.7x speedup in comparison to FedAvg, and a 4.3x speedup in comparison to FedProx for CIFAR-10. Lastly, FedBuff achieved the goal precision for Send140 with 124,700 communication trips, while FedAvg and FedProx did not manage to reach the goal precision in the predefined limit (600,000 times) [22].
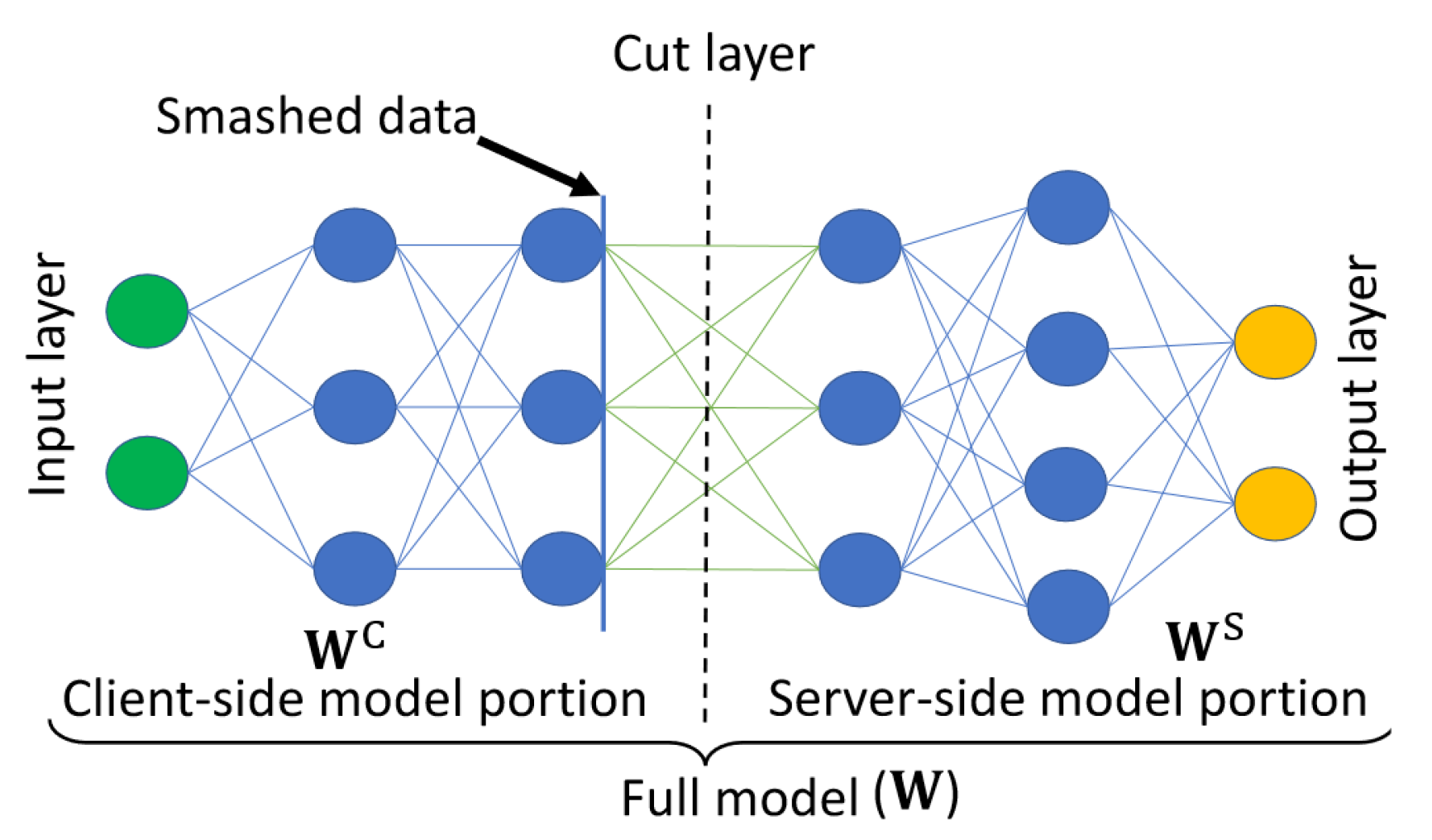
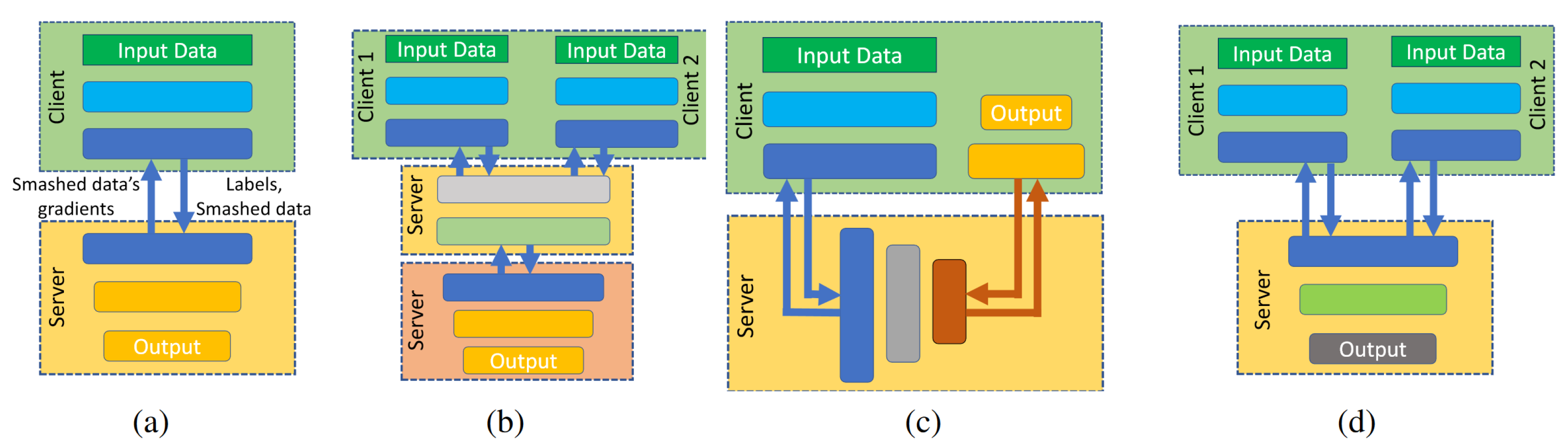
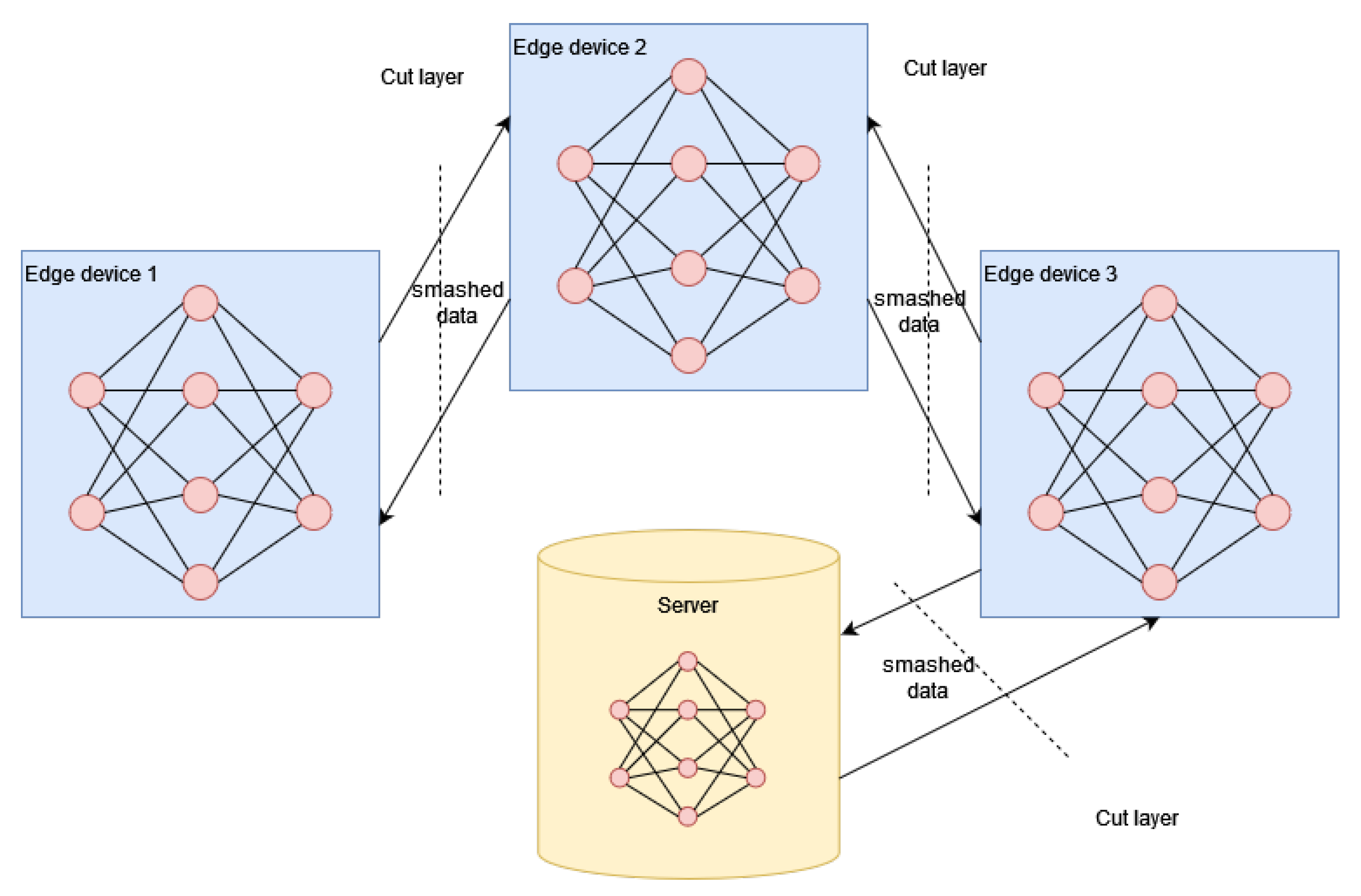
3.2. Split Learning
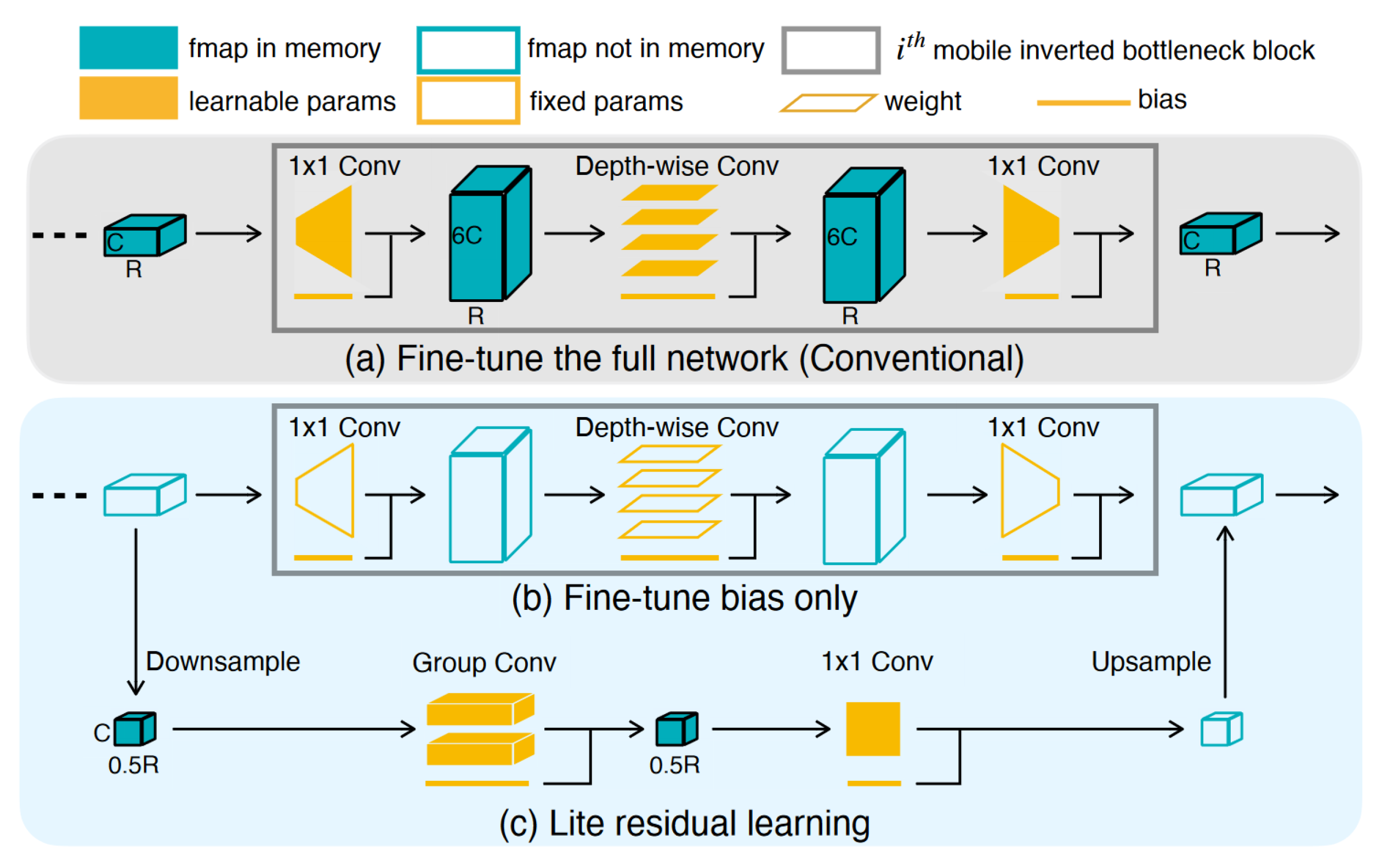
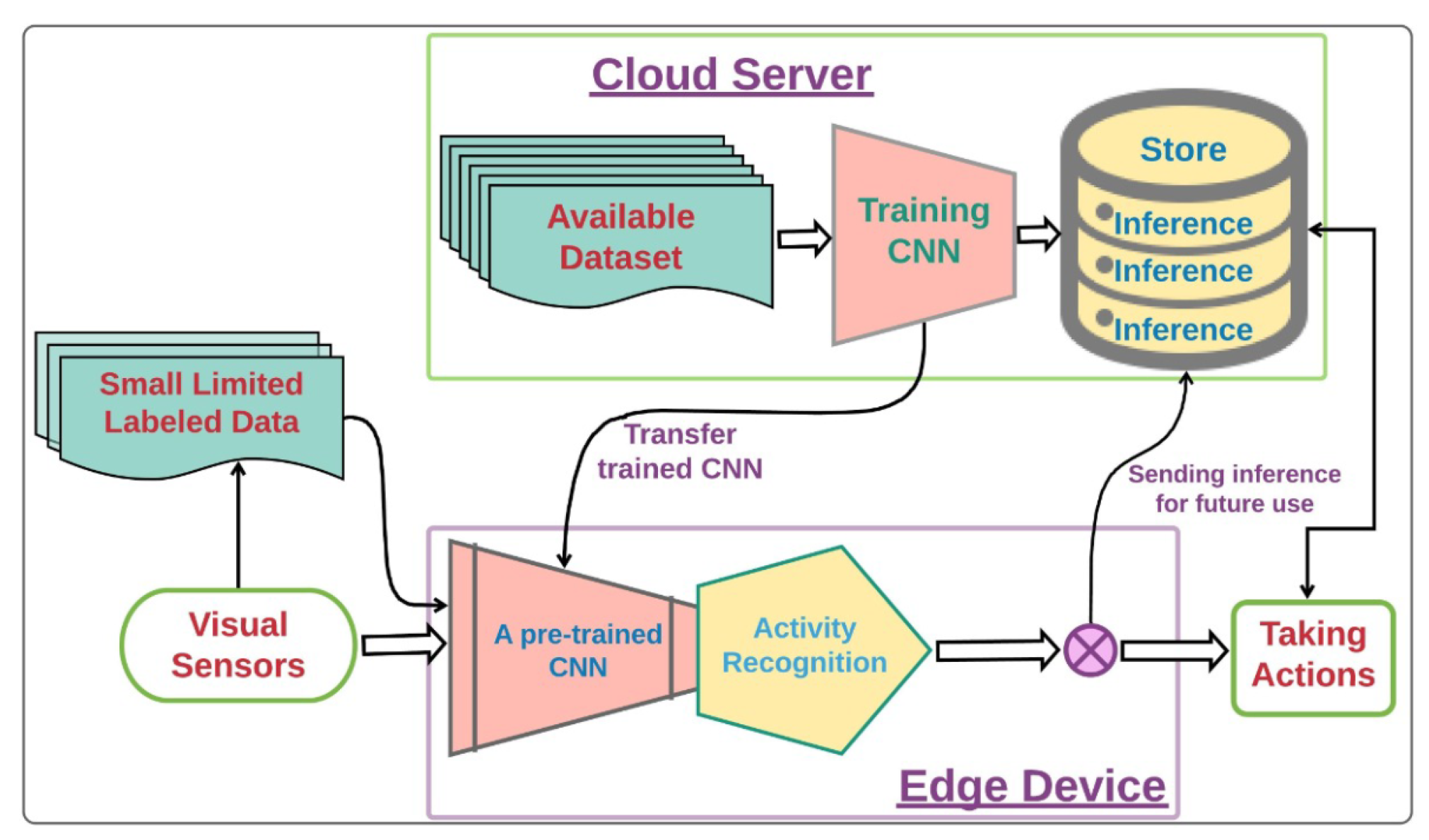
4. Transfer Learning
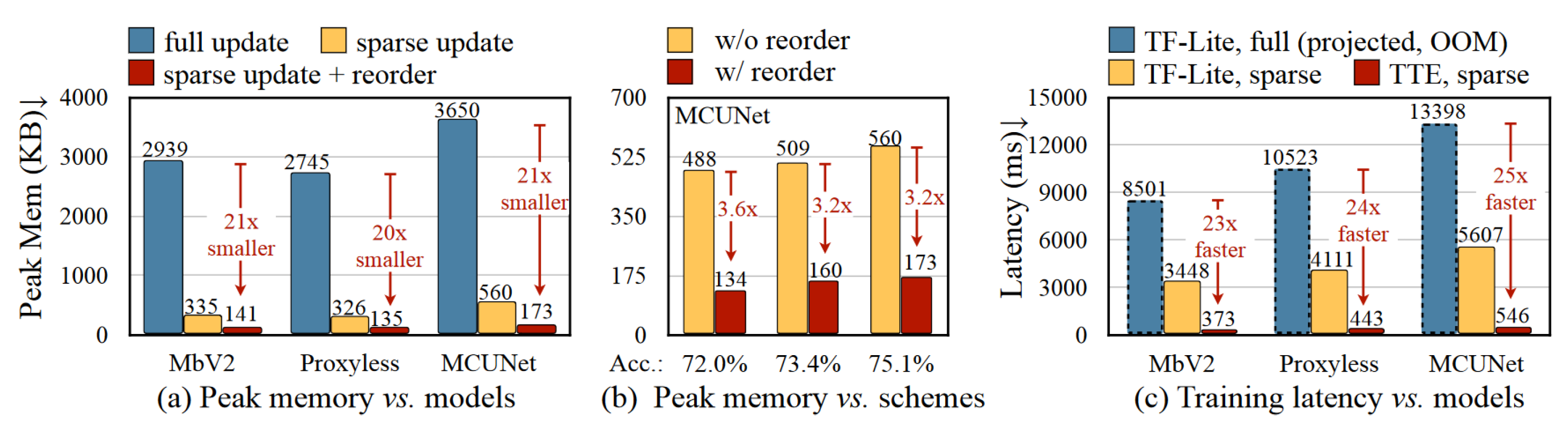
- Tiny Training Engine—The authors found the optimal training method, which includes reducing the runtime overhead, by moving parts of the computational tasks to compilation time;
- Quantization-aware-scaling—Gradients were automatically scaled with different levels of precision;
- Operator reordering—Model gradients were reordered in order to be able to apply gradient updates directly without needing to complete, e.g., the whole backpropagation cycle;
- Pruning—Model size was reduced by removing less important weights from the model;
- Sparse update—During the model training process, only the key layers were updated to reduce the new gradient impact on the whole computational load.
5. Method Combinations
6. Attack Vectors
6.1. Attacks on Federated Learning
6.2. Attacks on Split Learning
6.3. Attacks on Transfer Learning
7. Attack Mitigation
7.1. Secure Aggregation
7.1.1. Secure Multi-Party Computation
- Secret sharing—In a (t, n)-secret sharing scheme, we split the secret s into n shares, where any t − 1 shares reveal no information about s, while any t shares allow the reconstruction of the secret s. In this scheme, t could also be equal to n, resulting in (n, n)-secret sharing schemes, where all n shares would be required to reconstruct the secret [75];
- Random oracle—This is a heuristic model for security of hash functions, treating them as public, idealized random functions. In this model, all parties have access to the public function H: →, implemented as a stateful oracle. On input x , H looks up its history calls. If H(x) had never been called, H chooses a random , remembers the pair x, , and returns . If H(x) had been called before, H returns . As a result, this method is a randomly-chosen function → [75].
7.1.2. Homomorphic Encryption
- Partially Homomorphic Encryption (PHE)—Allows the execution of one type of operation an unlimited amount of times;
- Somewhat Homomorphic Encryption (SWHE)—Allows the execution of a few operations a limited amount of times;
- Fully Homomorphic Encryption (FHE)—Allows the execution of any operation an unlimited amount of times [82].
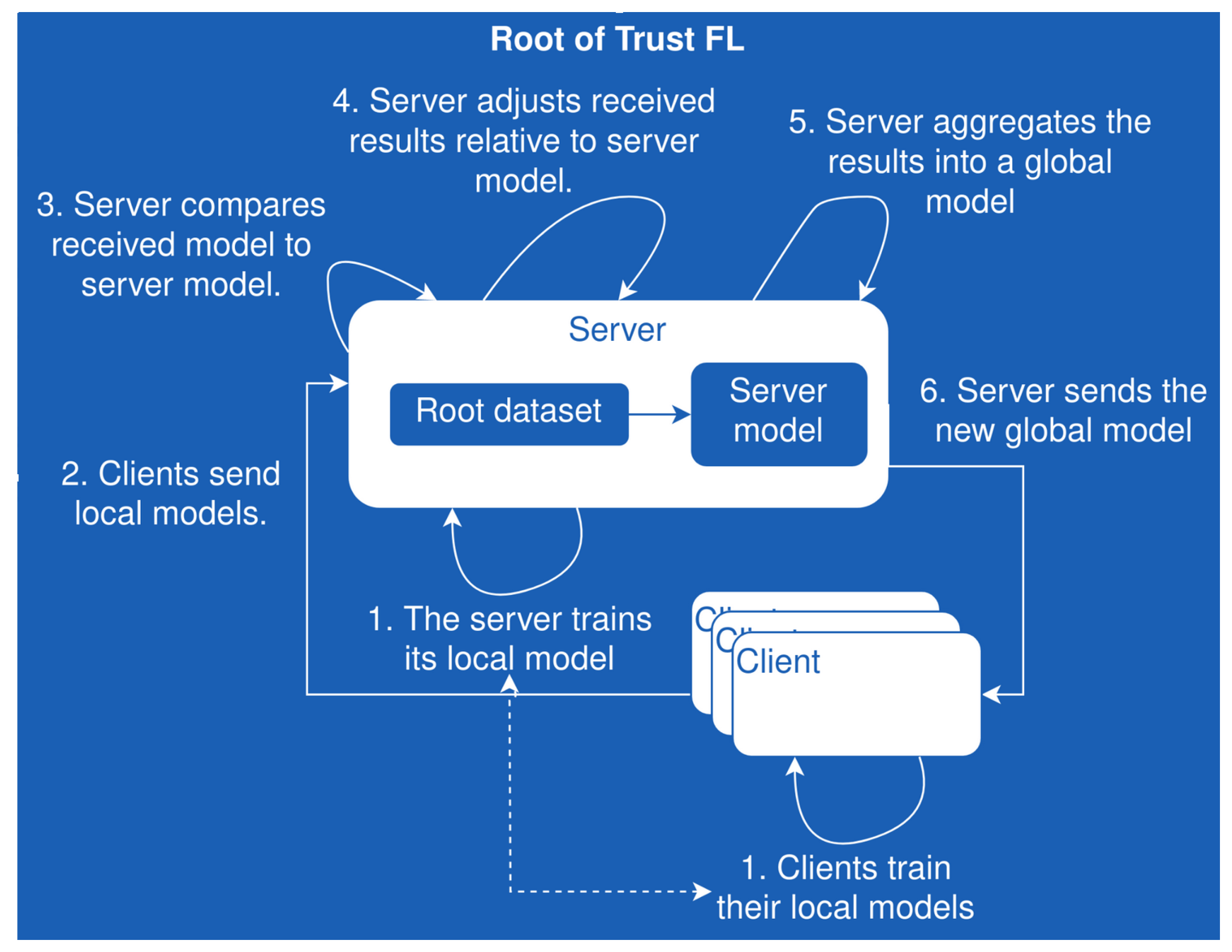
7.2. Robust Aggregation
- Transactions—The data to be stored on the chain, sent from one of the nodes in the network;
- Shared ledger—An accounting mechanism of all verified transactions in the blockchain network;
- Consensus mechanism—In order to verify a transaction, a network consensus has to be reached in which network nodes agree upon whether or not to accept a transaction;
- Peer-to-peer (P2P) networking—Decentralized communication mechanism;
- On-chain and off-chain storage—Data that are kept on-chain are usually smaller in size in order for the chain not to become too large, e.g., metadata about transactions. That is why off-chain storage is used, e.g., the interplanetary file system (IPFS), for storing large data such as ML models, as is the case in FL [93,94].
7.3. Differential Privacy
- ()-DP—The original DP method with the most robust privacy rules. This method is defined as follows:The probability of acquiring a result, part of S, where , when using a mechanism M on a given dataset x is less than or equal to or approximately , multiplied by the probability of acquiring a result, that is part of the same S, applying the same mechanism M on an adjacent dataset x’, where the difference between datasets x and x’ is at most one record. Here, there is only one parameter to tune——where, the smaller the , the more private the end result, because the difference between adjacent datasets will be smaller. Best practices describe choosing the . However, this method adds too much noise to the result, which is why this method is not used in ML use cases, because of the high perturbation level resulting in too high utility loss [100,101];
- ()-DP—To make DP more friendly to ML use cases, a relaxation of ()-DP was proposed, by adding an extra parameter , such that the definition changes toIn this format, the new parameter adds the possibility of incorporating less noise during the application of the mechanism, resulting in better utility. It follows that an adversary can successfully identify records. For this reason, the recommendation for the new parameter is to set , where n is the dataset size. In addition, the definition holds for . However, usually in practice, smaller values are chosen such as below eight or even smaller [100,101].
- Global differential privacy (GDP)—In this approach, there is one node that applies DP to the data, e.g., the global model in FL, and other nodes just send and request data from this node. For example, in FL GDP, clients would send their models without adding DP locally, and the aggregator server would add DP to the aggregated model and send the global model back to the clients [101];
- Local differential privacy (LDP)—Not adding the DP noise locally creates potential privacy leakage because the data can be intercepted on its way to the node that applies DP. That is why LDP was proposed in order for the data owners to apply DP locally; however, this results in higher utility costs because the composite noise level increases in comparison to GDP [13,101,102]. Even without DP, the FL method may not converge in the training process if the data distribution varies largely from clients [13]. Thus, by adding DP, and especially LDP, the resulting convergence rate could decrease substantially. However, some articles research the idea of shuffling the sent data before handing it over to the aggregator. This results in a higher privacy level with a less or equal amount of noise [103]. Nevertheless, LDP is popular among FL implementations, and many articles can be found that use the LDP method in addition to FL [29,104,105,106,107,108,109]. For example, Arachchige et al. proposed a framework that uses FL, DP, blockchain, and smart contracts for ML in Industrial IoT. Here, the DP was used to obfuscate the model in a local data-owner device before encrypting it. After that, it was placed in an off-chain storage medium [106]. Meanwhile, Lichao Sun et al. proposed a new LDP method optimization technique in order to fight the DP noise explosion, arising from model weight high dimensionality, as well as to fight different model weight ranges in different layers [109].
8. Tools
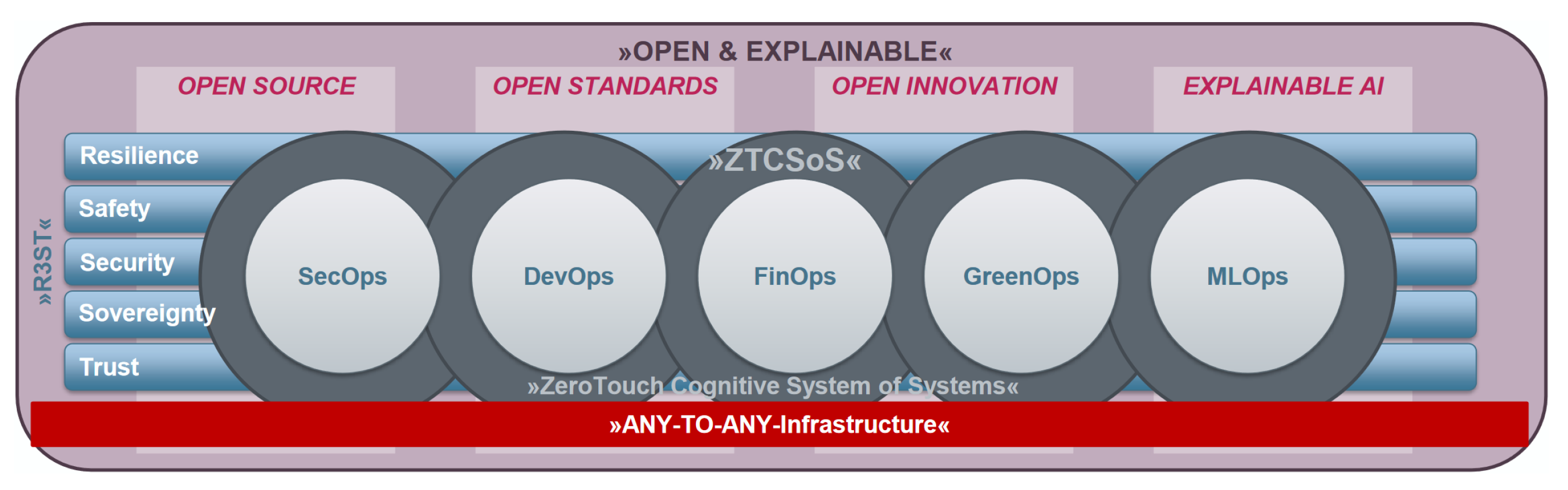
9. Discussion and Future Directions
10. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Moreschini, S.; Pecorelli, F.; Li, X.; Naz, S.; Hästbacka, D.; Taibi, D. Cloud Continuum: The definition. IEEE Access 2022, 10, 131876–131886. [Google Scholar] [CrossRef]
- Bittencourt, L.; Immich, R.; Sakellariou, R.; Fonseca, N.; Madeira, E.; Curado, M.; Villas, L.; DaSilva, L.; Lee, C.; Rana, O. The internet of things, fog and cloud continuum: Integration and challenges. Internet Things 2018, 3, 134–155. [Google Scholar] [CrossRef]
- Kampars, J.; Tropins, D.; Matisons, R. A review of application layer communication protocols for the IoT edge cloud continuum. In Proceedings of the 2021 62nd International Scientific Conference on Information Technology and Management Science of Riga Technical University (ITMS), Riga, Latvia, 14–15 October 2021. [Google Scholar]
- S-Julián, R.; Lacalle, I.; Vaño, R.; Boronat, F.; Palau, C.E. Self-* Capabilities of Cloud-Edge Nodes: A Research Review. Sensors 2023, 23, 2931. [Google Scholar] [CrossRef] [PubMed]
- Khalyeyev, D.; Bureš, T.; Hnětynka, P. Towards characterization of edge-cloud continuum. In Proceedings of the European Conference on Software Architecture, Prague, Czech Republic, 19–23 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 215–230. [Google Scholar]
- Ullah, A.; Kiss, T.; Kovács, J.; Tusa, F.; Deslauriers, J.; Dagdeviren, H.; Arjun, R.; Hamzeh, H. Orchestration in the Cloud-to-Things compute continuum: Taxonomy, survey and future directions. J. Cloud Comput. 2023, 12, 135. [Google Scholar] [CrossRef]
- Bendechache, M.; Svorobej, S.; Takako Endo, P.; Lynn, T. Simulating resource management across the cloud-to-thing continuum: A survey and future directions. Future Internet 2020, 12, 95. [Google Scholar] [CrossRef]
- Gkonis, P.; Giannopoulos, A.; Trakadas, P.; Masip-Bruin, X.; D’Andria, F. A Survey on IoT-Edge-Cloud Continuum Systems: Status, Challenges, Use Cases, and Open Issues. Future Internet 2023, 15, 383. [Google Scholar] [CrossRef]
- Rodrigues, D.O.; de Souza, A.M.; Braun, T.; Maia, G.; Loureiro, A.A.; Villas, L.A. Service Provisioning in Edge-Cloud Continuum Emerging Applications for Mobile Devices. J. Internet Serv. Appl. 2023, 14, 47–83. [Google Scholar] [CrossRef]
- IECC Description. Available online: https://eucloudedgeiot.eu/ (accessed on 24 April 2023).
- Fritz, M. General Challenges for a Computing Continuum. 2023. Available online: https://eucloudedgeiot.eu/wp-content/uploads/2023/05/AIOps_merged.pdf (accessed on 13 June 2023).
- Bernstein, D.J.; Lange, T. Post-quantum cryptography. Nature 2017, 549, 188–194. [Google Scholar] [CrossRef]
- Li, W.; Hacid, H.; Almazrouei, E.; Debbah, M. A Review and a Taxonomy of Edge Machine Learning: Requirements, Paradigms, and Techniques. arXiv 2023, arXiv:2302.08571. [Google Scholar] [CrossRef]
- Kholod, I.; Yanaki, E.; Fomichev, D.; Shalugin, E.; Novikova, E.; Filippov, E.; Nordlund, M. Open-source federated learning frameworks for IoT: A comparative review and analysis. Sensors 2020, 21, 167. [Google Scholar] [CrossRef]
- Huang, C.; Huang, J.; Liu, X. Cross-Silo Federated Learning: Challenges and Opportunities. arXiv 2022, arXiv:2206.12949. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Bellwood, L.; McCloud, S. Google Federated Learning Illustration. Available online: https://federated.withgoogle.com/ (accessed on 10 April 2023).
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Briggs, C.; Fan, Z.; Andras, P. A review of privacy-preserving federated learning for the Internet-of-Things. In Federated Learning Systems: Towards Next-Generation AI; Springer: Cham, Switerland, 2021; pp. 21–50. [Google Scholar]
- McMahan, B.D.R. Google FL Description. Available online: https://ai.googleblog.com/2017/04/federated-learning-collaborative.html (accessed on 10 April 2023).
- Rabbat, M. Meta FL Research Presentation. Available online: https://semla.polymtl.ca/wp-content/uploads/2022/11/Rabbat-AsyncFL-SEMLA22.pdf (accessed on 15 April 2023).
- Nguyen, J.; Malik, K.; Zhan, H.; Yousefpour, A.; Rabbat, M.; Malek, M.; Huba, D. Federated learning with buffered asynchronous aggregation. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Virtual Event, 28–30 March 2022; pp. 3581–3607. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Kundu, A.; Yu, P.; Wynter, L.; Lim, S.H. Robustness and Personalization in Federated Learning: A Unified Approach via Regularization. In Proceedings of the 2022 IEEE International Conference on Edge Computing and Communications (EDGE), Barcelona, Spain, 10–16 July 2022; pp. 1–11. [Google Scholar]
- Ruzafa-Alcázar, P.; Fernández-Saura, P.; Mármol-Campos, E.; González-Vidal, A.; Hernández-Ramos, J.L.; Bernal-Bernabe, J.; Skarmeta, A.F. Intrusion detection based on privacy-preserving federated learning for the industrial IoT. IEEE Trans. Ind. Inform. 2021, 19, 1145–1154. [Google Scholar] [CrossRef]
- Reisizadeh, A.; Mokhtari, A.; Hassani, H.; Jadbabaie, A.; Pedarsani, R. Fedpaq: A communication-efficient federated learning method with periodic averaging and quantization. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Online, 26–28 August 2020; pp. 2021–2031. [Google Scholar]
- da Silva, L.G.F.; Sadok, D.F.; Endo, P.T. Resource Optimizing Federated Learning for use with IoT: A Systematic Review. J. Parallel Distrib. Comput. 2023, 175, 92–108. [Google Scholar] [CrossRef]
- Xu, Q.; Zhao, L.; Su, Z.; Fang, D.; Li, R. Secure Federated Learning in Quantum Autonomous Vehicular Networks. IEEE Netw. 2023, 1–8. [Google Scholar] [CrossRef]
- Zhang, H.; Zou, Y.; Yin, H.; Yu, D.; Cheng, X. CCM-FL: Covert communication mechanisms for federated learning in crowd sensing IoT. Digit. Commun. Netw. 2023. [Google Scholar] [CrossRef]
- Caldarola, D.; Caputo, B.; Ciccone, M. Improving generalization in federated learning by seeking flat minima. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 654–672. [Google Scholar]
- Wang, J.; Liu, Q.; Liang, H.; Joshi, G.; Poor, H.V. Tackling the objective inconsistency problem in heterogeneous federated optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 7611–7623. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic controlled averaging for federated learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 5132–5143. [Google Scholar]
- Dinsdale, N.K.; Jenkinson, M.; Namburete, A.I. FedHarmony: Unlearning scanner bias with distributed data. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 695–704. [Google Scholar]
- Kim, J.; Kim, G.; Han, B. Multi-level branched regularization for federated learning. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 11058–11073. [Google Scholar]
- Tan, Y.; Long, G.; Liu, L.; Zhou, T.; Lu, Q.; Jiang, J.; Zhang, C. Fedproto: Federated prototype learning across heterogeneous clients. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 8432–8440. [Google Scholar]
- Zhang, R.; Hidano, S.; Koushanfar, F. Text revealer: Private text reconstruction via model inversion attacks against transformers. arXiv 2022, arXiv:2209.10505. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 3–18. [Google Scholar]
- Walskaar, I.; Tran, M.C.; Catak, F.O. A Practical Implementation of Medical Privacy-Preserving Federated Learning Using Multi-Key Homomorphic Encryption and Flower Framework. Cryptography 2023, 7, 48. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, X.; Shen, X.; Sun, H. A federated learning framework for smart grids: Securing power traces in collaborative learning. arXiv 2021, arXiv:2103.11870. [Google Scholar]
- Stripelis, D.; Saleem, H.; Ghai, T.; Dhinagar, N.; Gupta, U.; Anastasiou, C.; Ver Steeg, G.; Ravi, S.; Naveed, M.; Thompson, P.M.; et al. Secure neuroimaging analysis using federated learning with homomorphic encryption. In Proceedings of the 17th International Symposium on Medical Information Processing and Analysis, Campinas, Brazil, 17–19 November 2021; Volume 12088, pp. 351–359. [Google Scholar]
- Shaheen, M.; Farooq, M.S.; Umer, T.; Kim, B.S. Applications of federated learning; Taxonomy, challenges, and research trends. Electronics 2022, 11, 670. [Google Scholar] [CrossRef]
- Thapa, C.; Chamikara, M.; Camtepe, S.A. Advancements of federated learning towards privacy preservation: From federated learning to split learning. arXiv 2020, arXiv:2011.14818. [Google Scholar]
- Liu, J.; Lyu, X. Clustering Label Inference Attack against Practical Split Learning. arXiv 2022, arXiv:2203.05222. [Google Scholar]
- Duan, Q.; Hu, S.; Deng, R.; Lu, Z. Combined federated and split learning in edge computing for ubiquitous intelligence in internet of things: State-of-the-art and future directions. Sensors 2022, 22, 5983. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Hu, Z.; Wu, B.; Chen, C. SLPerf: A Unified Framework for Benchmarking Split Learning. arXiv 2023, arXiv:2304.01502. [Google Scholar]
- Gupta, O.; Raskar, R. Distributed learning of deep neural network over multiple agents. arXiv 2018, arXiv:1810.06060. [Google Scholar] [CrossRef]
- Hu, Y.; Niu, D.; Yang, J.; Zhou, S. FDML: A collaborative machine learning framework for distributed features. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2232–2240. [Google Scholar]
- Usynin, D.; Ziller, A.; Makowski, M.; Braren, R.; Rueckert, D.; Glocker, B.; Kaissis, G.; Passerat-Palmbach, J. Adversarial interference and its mitigations in privacy-preserving collaborative machine learning. Nat. Mach. Intell. 2021, 3, 749–758. [Google Scholar] [CrossRef]
- Kopparapu, K.; Lin, E. Tinyfedtl: Federated transfer learning on tiny devices. arXiv 2021, arXiv:2110.01107. [Google Scholar]
- Lin, J.; Zhu, L.; Chen, W.M.; Wang, W.C.; Gan, C.; Han, S. On-device training under 256kb memory. Adv. Neural Inf. Process. Syst. 2022, 35, 22941–22954. [Google Scholar]
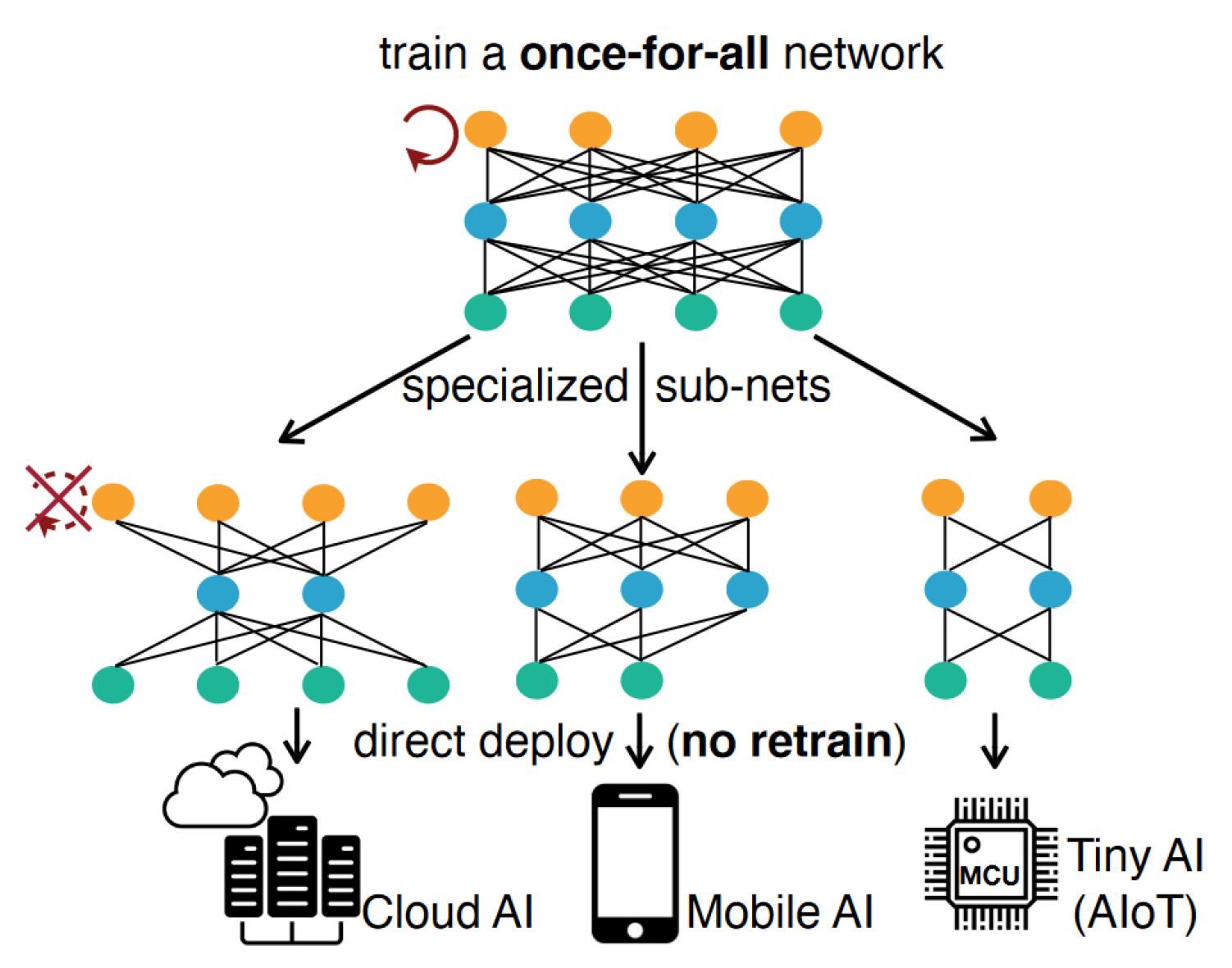
- Cai, H.; Gan, C.; Zhu, L.; Han, S. Tinytl: Reduce memory, not parameters for efficient on-device learning. Adv. Neural Inf. Process. Syst. 2020, 33, 11285–11297. [Google Scholar]
- Cai, H.; Gan, C.; Wang, T.; Zhang, Z.; Han, S. Once-for-all: Train one network and specialize it for efficient deployment. arXiv 2019, arXiv:1908.09791. [Google Scholar]
- TinyML Description. Available online: https://tinyml.mit.edu/ (accessed on 3 October 2023).
- Llisterri Giménez, N.; Monfort Grau, M.; Pueyo Centelles, R.; Freitag, F. On-device training of machine learning models on microcontrollers with federated learning. Electronics 2022, 11, 573. [Google Scholar] [CrossRef]
- Sufian, A.; You, C.; Dong, M. A Deep Transfer Learning-based Edge Computing Method for Home Health Monitoring. arXiv 2021, arXiv:2105.02960. [Google Scholar]
- Thapa, C.; Arachchige, P.C.M.; Camtepe, S.; Sun, L. Splitfed: When federated learning meets split learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 8485–8493. [Google Scholar]
- Nair, A.K.; Raj, E.D.; Sahoo, J. A robust analysis of adversarial attacks on federated learning environments. Comput. Stand. Interfaces 2023, 103723. [Google Scholar] [CrossRef]
- Xie, C.; Huang, K.; Chen, P.Y.; Li, B. Dba: Distributed backdoor attacks against federated learning. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Shejwalkar, V.; Houmansadr, A.; Kairouz, P.; Ramage, D. Back to the drawing board: A critical evaluation of poisoning attacks on production federated learning. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 23–25 May 2022; pp. 1354–1371. [Google Scholar]
- Lianga, J.; Wang, R.; Feng, C.; Chang, C.C. A survey on federated learning poisoning attacks and defenses. arXiv 2023, arXiv:2306.03397. [Google Scholar]
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–22 May 2019; pp. 739–753. [Google Scholar]
- Fang, M.; Cao, X.; Jia, J.; Gong, N. Local model poisoning attacks to {Byzantine-Robust} federated learning. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 1605–1622. [Google Scholar]
- Rigaki, M.; Garcia, S. A survey of privacy attacks in machine learning. Acm Comput. Surv. 2023, 56, 1–34. [Google Scholar] [CrossRef]
- Fan, M.; Chen, C.; Wang, C.; Zhou, W.; Huang, J. On the Robustness of Split Learning against Adversarial Attacks. arXiv 2023, arXiv:2307.07916. [Google Scholar]
- Tajalli, B.; Ersoy, O.; Picek, S. On Feasibility of Server-side Backdoor Attacks on Split Learning. In Proceedings of the 2023 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 25 May 2023; pp. 84–93. [Google Scholar]
- Pasquini, D.; Ateniese, G.; Bernaschi, M. Unleashing the tiger: Inference attacks on split learning. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, Republic of Korea, 15–19 November 2021; pp. 2113–2129. [Google Scholar]
- Li, O.; Sun, J.; Yang, X.; Gao, W.; Zhang, H.; Xie, J.; Smith, V.; Wang, C. Label leakage and protection in two-party split learning. arXiv 2021, arXiv:2102.08504. [Google Scholar]
- Wang, B.; Yao, Y.; Viswanath, B.; Zheng, H.; Zhao, B.Y. With great training comes great vulnerability: Practical attacks against transfer learning. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 1281–1297. [Google Scholar]
- Zhang, Y.; Song, Y.; Liang, J.; Bai, K.; Yang, Q. Two sides of the same coin: White-box and black-box attacks for transfer learning. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 23–27 August 2020; pp. 2989–2997. [Google Scholar]
- Jiang, X.; Meng, L.; Li, S.; Wu, D. Active poisoning: Efficient backdoor attacks on transfer learning-based brain–computer interfaces. Sci. China Inf. Sci. 2023, 66, 1–22. [Google Scholar] [CrossRef]
- Wang, S.; Nepal, S.; Rudolph, C.; Grobler, M.; Chen, S.; Chen, T. Backdoor attacks against transfer learning with pre-trained deep learning models. IEEE Trans. Serv. Comput. 2020, 15, 1526–1539. [Google Scholar] [CrossRef]
- Zou, Y.; Zhang, Z.; Backes, M.; Zhang, Y. Privacy analysis of deep learning in the wild: Membership inference attacks against transfer learning. arXiv 2020, arXiv:2009.04872. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- Evans, D.; Kolesnikov, V.; Rosulek, M. A pragmatic introduction to secure multi-party computation. Found. Trends® Priv. Secur. 2018, 2, 70–246. [Google Scholar] [CrossRef]
- Lindell, Y. Secure multiparty computation. Commun. ACM 2020, 64, 86–96. [Google Scholar] [CrossRef]
- Byrd, D.; Polychroniadou, A. Differentially private secure multi-party computation for federated learning in financial applications. In Proceedings of the First ACM International Conference on AI in Finance, New York, NY, USA, 15–16 October 2020; pp. 1–9. [Google Scholar]
- Mugunthan, V.; Polychroniadou, A.; Byrd, D.; Balch, T.H. Smpai: Secure multi-party computation for federated learning. In Proceedings of the NeurIPS 2019 Workshop on Robust AI in Financial Services, Vancouver, BC, Canada , 8–14 December 2019; MIT Press: Cambridge, MA, USA, 2019; pp. 1–9. [Google Scholar]
- Kanagavelu, R.; Li, Z.; Samsudin, J.; Yang, Y.; Yang, F.; Goh, R.S.M.; Cheah, M.; Wiwatphonthana, P.; Akkarajitsakul, K.; Wang, S. Two-phase multi-party computation enabled privacy-preserving federated learning. In Proceedings of the 2020 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), Melbourne, Australia, 11–14 May 2020; pp. 410–419. [Google Scholar]
- Fereidooni, H.; Marchal, S.; Miettinen, M.; Mirhoseini, A.; Möllering, H.; Nguyen, T.D.; Rieger, P.; Sadeghi, A.R.; Schneider, T.; Yalame, H.; et al. SAFELearn: Secure aggregation for private federated learning. In Proceedings of the 2021 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 27 May 2021; pp. 56–62. [Google Scholar]
- Truex, S.; Baracaldo, N.; Anwar, A.; Steinke, T.; Ludwig, H.; Zhang, R.; Zhou, Y. A hybrid approach to privacy-preserving federated learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security, London, UK, 15 November 2019; pp. 1–11. [Google Scholar]
- Acar, A.; Aksu, H.; Uluagac, A.S.; Conti, M. A survey on homomorphic encryption schemes: Theory and implementation. ACM Comput. Surv. (Csur) 2018, 51, 1–35. [Google Scholar] [CrossRef]
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic encryption for arithmetic of approximate numbers. In Advances in Cryptology–ASIACRYPT 2017, Proceedings of the 23rd International Conference on the Theory and Applications of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; Proceedings, Part I 23; Springer: Berlin/Heidelberg, Germany, 2017; pp. 409–437. [Google Scholar]
- Ma, J.; Naas, S.A.; Sigg, S.; Lyu, X. Privacy-preserving federated learning based on multi-key homomorphic encryption. Int. J. Intell. Syst. 2022, 37, 5880–5901. [Google Scholar] [CrossRef]
- Sanon, S.P.; Reddy, R.; Lipps, C.; Schotten, H.D. Secure Federated Learning: An Evaluation of Homomorphic Encrypted Network Traffic Prediction. In Proceedings of the 2023 IEEE 20th Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 8–11 January 2023; pp. 1–6. [Google Scholar]
- Zhang, L.; Saito, H.; Yang, L.; Wu, J. Privacy-preserving federated transfer learning for driver drowsiness detection. IEEE Access 2022, 10, 80565–80574. [Google Scholar] [CrossRef]
- Pereteanu, G.L.; Alansary, A.; Passerat-Palmbach, J. Split HE: Fast secure inference combining split learning and homomorphic encryption. arXiv 2022, arXiv:2202.13351. [Google Scholar]
- Khan, T.; Nguyen, K.; Michalas, A.; Bakas, A. Love or hate? share or split? privacy-preserving training using split learning and homomorphic encryption. arXiv 2023, arXiv:2309.10517. [Google Scholar]
- Lee, S.; Lee, G.; Kim, J.W.; Shin, J.; Lee, M.K. HETAL: Efficient Privacy-preserving Transfer Learning with Homomorphic Encryption. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Walch, R.; Sousa, S.; Helminger, L.; Lindstaedt, S.; Rechberger, C.; Trügler, A. CryptoTL: Private, efficient and secure transfer learning. arXiv 2022, arXiv:2205.11935. [Google Scholar]
- Gilad-Bachrach, R.; Dowlin, N.; Laine, K.; Lauter, K.; Naehrig, M.; Wernsing, J. Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 201–210. [Google Scholar]
- Cao, X.; Fang, M.; Liu, J.; Gong, N.Z. Fltrust: Byzantine-robust federated learning via trust bootstrapping. arXiv 2020, arXiv:2012.13995. [Google Scholar]
- Witt, L.; Heyer, M.; Toyoda, K.; Samek, W.; Li, D. Decentral and incentivized federated learning frameworks: A systematic literature review. IEEE Internet Things J. 2022, 10, 3642–3663. [Google Scholar] [CrossRef]
- Ali, M.; Karimipour, H.; Tariq, M. Integration of blockchain and federated learning for Internet of Things: Recent advances and future challenges. Comput. Secur. 2021, 108, 102355. [Google Scholar] [CrossRef]
- Qu, Y.; Uddin, M.P.; Gan, C.; Xiang, Y.; Gao, L.; Yearwood, J. Blockchain-enabled federated learning: A survey. ACM Comput. Surv. 2022, 55, 1–35. [Google Scholar] [CrossRef]
- Choquette-Choo, C.A.; Tramer, F.; Carlini, N.; Papernot, N. Label-only membership inference attacks. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 1964–1974. [Google Scholar]
- Sun, Z.; Kairouz, P.; Suresh, A.T.; McMahan, H.B. Can you really backdoor federated learning? arXiv 2019, arXiv:1911.07963. [Google Scholar]
- Miao, L.; Yang, W.; Hu, R.; Li, L.; Huang, L. Against backdoor attacks in federated learning with differential privacy. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 2999–3003. [Google Scholar]
- Dwork, C. Differential privacy. In Automata, Languages and Programming, Proceedings of the 33rd International Colloquium, ICALP 2006, Venice, Italy, 10–14 July 2006; Proceedings, Part II 33; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–12. [Google Scholar]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. J. Priv. Confid. 2016, 7, 17–51. [Google Scholar]
- Ponomareva, N.; Hazimeh, H.; Kurakin, A.; Xu, Z.; Denison, C.; McMahan, H.B.; Vassilvitskii, S.; Chien, S.; Thakurta, A.G. How to dp-fy ml: A practical guide to machine learning with differential privacy. J. Artif. Intell. Res. 2023, 77, 1113–1201. [Google Scholar] [CrossRef]
- Bebensee, B. Local differential privacy: A tutorial. arXiv 2019, arXiv:1907.11908. [Google Scholar]
- Yang, M.; Lyu, L.; Zhao, J.; Zhu, T.; Lam, K.Y. Local differential privacy and its applications: A comprehensive survey. arXiv 2020, arXiv:2008.03686. [Google Scholar] [CrossRef]
- Seif, M.; Tandon, R.; Li, M. Wireless federated learning with local differential privacy. In Proceedings of the 2020 IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020; pp. 2604–2609. [Google Scholar]
- Anastasakis, Z.; Psychogyios, K.; Velivassaki, T.; Bourou, S.; Voulkidis, A.; Skias, D.; Gonos, A.; Zahariadis, T. Enhancing Cyber Security in IoT Systems using FL-based IDS with Differential Privacy. In Proceedings of the 2022 Global Information Infrastructure and Networking Symposium (GIIS), Argostoli, Kefalonia Island, Greece, 26–28 September 2022; pp. 30–34. [Google Scholar]
- Arachchige, P.C.M.; Bertok, P.; Khalil, I.; Liu, D.; Camtepe, S.; Atiquzzaman, M. A trustworthy privacy preserving framework for machine learning in industrial IoT systems. IEEE Trans. Ind. Inform. 2020, 16, 6092–6102. [Google Scholar] [CrossRef]
- Shen, X.; Liu, Y.; Zhang, Z. Performance-enhanced federated learning with differential privacy for internet of things. IEEE Internet Things J. 2022, 9, 24079–24094. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, X.; Feng, J.; Yang, X. A comprehensive survey on local differential privacy toward data statistics and analysis. Sensors 2020, 20, 7030. [Google Scholar] [CrossRef]
- Sun, L.; Qian, J.; Chen, X. LDP-FL: Practical private aggregation in federated learning with local differential privacy. arXiv 2020, arXiv:2007.15789. [Google Scholar]
- Gawron, G.; Stubbings, P. Feature space hijacking attacks against differentially private split learning. arXiv 2022, arXiv:2201.04018. [Google Scholar]
- Abuadbba, S.; Kim, K.; Kim, M.; Thapa, C.; Camtepe, S.A.; Gao, Y.; Kim, H.; Nepal, S. Can we use split learning on 1d cnn models for privacy preserving training? In Proceedings of the 15th ACM Asia Conference on Computer and Communications Security, Taipei, Taiwan, 5–9 October 2020; pp. 305–318. [Google Scholar]
- Yang, X.; Sun, J.; Yao, Y.; Xie, J.; Wang, C. Differentially private label protection in split learning. arXiv 2022, arXiv:2203.02073. [Google Scholar]
- Xu, H.; Dutta, A.; Liu, W.; Li, X.; Kalnis, P. Denoising Differential Privacy in Split Learning. OpenReview.net 2023. [Google Scholar]
- Wu, M.; Cheng, G.; Li, P.; Yu, R.; Wu, Y.; Pan, M.; Lu, R. Split Learning with Differential Privacy for Integrated Terrestrial and Non-Terrestrial Networks. IEEE Wirel. Commun. 2023. [Google Scholar] [CrossRef]
- Luo, Z.; Wu, D.J.; Adeli, E.; Fei-Fei, L. Scalable differential privacy with sparse network finetuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5059–5068. [Google Scholar]
- Blanco-Justicia, A.; Sanchez, D.; Domingo-Ferrer, J.; Muralidhar, K. A critical review on the use (and misuse) of differential privacy in machine learning. Acm Comput. Surv. 2022, 55, 1–16. [Google Scholar] [CrossRef]
- Shiri, I.; Salimi, Y.; Maghsudi, M.; Jenabi, E.; Harsini, S.; Razeghi, B.; Mostafaei, S.; Hajianfar, G.; Sanaat, A.; Jafari, E.; et al. Differential privacy preserved federated transfer learning for multi-institutional 68Ga-PET image artefact detection and disentanglement. Eur. J. Nucl. Med. Mol. Imaging 2023, 51, 40–53. [Google Scholar] [CrossRef]
- Li, Y.; Tsai, Y.L.; Yu, C.M.; Chen, P.Y.; Ren, X. Exploring the benefits of visual prompting in differential privacy. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 5158–5167. [Google Scholar]
- Zhao, J. Distributed deep learning under differential privacy with the teacher-student paradigm. In Proceedings of the Workshops at the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Shiri, I.; Vafaei Sadr, A.; Akhavan, A.; Salimi, Y.; Sanaat, A.; Amini, M.; Razeghi, B.; Saberi, A.; Arabi, H.; Ferdowsi, S.; et al. Decentralized collaborative multi-institutional PET attenuation and scatter correction using federated deep learning. Eur. J. Nucl. Med. Mol. Imaging 2023, 50, 1034–1050. [Google Scholar] [CrossRef]
- Xiong, X.; Liu, S.; Li, D.; Cai, Z.; Niu, X. A comprehensive survey on local differential privacy. Secur. Commun. Netw. 2020, 2020, 8829523. [Google Scholar] [CrossRef]
- Tensorflow Privacy. Available online: https://github.com/tensorflow/privacy (accessed on 19 October 2023).
- PyTorch Privacy. Available online: https://github.com/pytorch/opacus (accessed on 19 October 2023).
- Google Privacy. Available online: https://github.com/google/differential-privacy (accessed on 19 October 2023).
- Li, Y.; Liu, Y.; Li, B.; Wang, W.; Liu, N. Towards practical differential privacy in data analysis: Understanding the effect of epsilon on utility in private erm. Comput. Secur. 2023, 128, 103147. [Google Scholar] [CrossRef]
- Zhou, T. Hierarchical federated learning with gaussian differential privacy. In Proceedings of the 4th International Conference on Advanced Information Science and System, Sanya, China, 25–27 November 2022; pp. 1–6. [Google Scholar]
- Tramer, F.; Terzis, A.; Steinke, T.; Song, S.; Jagielski, M.; Carlini, N. Debugging differential privacy: A case study for privacy auditing. arXiv 2022, arXiv:2202.12219. [Google Scholar]
- Zanella-Béguelin, S.; Wutschitz, L.; Tople, S.; Salem, A.; Rühle, V.; Paverd, A.; Naseri, M.; Köpf, B.; Jones, D. Bayesian estimation of differential privacy. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 40624–40636. [Google Scholar]
- Ligett, K.; Neel, S.; Roth, A.; Waggoner, B.; Wu, S.Z. Accuracy first: Selecting a differential privacy level for accuracy constrained erm. Adv. Neural Inf. Process. Syst. 2017, 30, 2563–2573. [Google Scholar]
- Guendouzi, B.S.; Ouchani, S.; Assaad, H.E.; Zaher, M.E. A systematic review of federated learning: Challenges, aggregation methods, and development tools. J. Netw. Comput. Appl. 2023, 220, 103714. [Google Scholar] [CrossRef]
- Rodríguez-Barroso, N.; Stipcich, G.; Jiménez-López, D.; Ruiz-Millán, J.A.; Martínez-Cámara, E.; González-Seco, G.; Luzón, M.V.; Veganzones, M.A.; Herrera, F. Federated Learning and Differential Privacy: Software tools analysis, the Sherpa. ai FL framework and methodological guidelines for preserving data privacy. Inf. Fusion 2020, 64, 270–292. [Google Scholar] [CrossRef]
- Ziller, A.; Trask, A.; Lopardo, A.; Szymkow, B.; Wagner, B.; Bluemke, E.; Nounahon, J.M.; Passerat-Palmbach, J.; Prakash, K.; Rose, N.; et al. Pysyft: A library for easy federated learning. In Federated Learning Systems: Towards Next-Generation AI; Springer: Cham, Switerland, 2021; pp. 111–139. [Google Scholar]
- Beutel, D.J.; Topal, T.; Mathur, A.; Qiu, X.; Fernandez-Marques, J.; Gao, Y.; Sani, L.; Li, K.H.; Parcollet, T.; de Gusmão, P.P.B.; et al. Flower: A Friendly Federated Learning Framework. arXiv 2022, arXiv:2007.14390v. [Google Scholar]
- He, C.; Li, S.; So, J.; Zeng, X.; Zhang, M.; Wang, H.; Wang, X.; Vepakomma, P.; Singh, A.; Qiu, H.; et al. Fedml: A research library and benchmark for federated machine learning. arXiv 2020, arXiv:2007.13518. [Google Scholar]
- Judvaitis, J.; Balass, R.; Greitans, M. Mobile iot-edge-cloud continuum based and devops enabled software framework. J. Sens. Actuator Netw. 2021, 10, 62. [Google Scholar] [CrossRef]
- PaddleFL Github Repository. Available online: https://github.com/PaddlePaddle/PaddleFL (accessed on 23 October 2023).
- PySyft Github Repository. Available online: https://github.com/OpenMined/PySyft (accessed on 23 October 2023).
- Yuan, X.; Pu, L.; Jiao, L.; Wang, X.; Yang, M.; Xu, J. When Computing Power Network Meets Distributed Machine Learning: An Efficient Federated Split Learning Framework. arXiv 2023, arXiv:2305.12979. [Google Scholar]
- Zhou, W.; Qu, Z.; Zhao, Y.; Tang, B.; Ye, B. An efficient split learning framework for recurrent neural network in mobile edge environment. In Proceedings of the Conference on Research in Adaptive and Convergent Systems, Aizuwakamatsu, Japan, 3–6 October 2022; pp. 131–138. [Google Scholar]
- Neptune AI Github Repository. Available online: https://github.com/neptune-ai/neptune-client (accessed on 23 October 2023).
- Hymel, S.; Banbury, C.; Situnayake, D.; Elium, A.; Ward, C.; Kelcey, M.; Baaijens, M.; Majchrzycki, M.; Plunkett, J.; Tischler, D.; et al. Edge Impulse: An MLOps Platform for Tiny Machine Learning. arXiv 2022, arXiv:2212.03332. [Google Scholar]
- X-Cube-AI STM Library. Available online: https://www.st.com/en/embedded-software/x-cube-ai.html (accessed on 2 May 2023).
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.Y.; Li, Z.; Gupta, B.B.; Chen, X.; Wang, X. A survey of deep active learning. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Klein, S. IoT Solutions in Microsoft’s Azure IoT Suite; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Azure IoT AI. Available online: https://learn.microsoft.com/en-us/azure/architecture/guide/iot-edge-vision/machine-learning (accessed on 23 October 2023).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Precision | FedBuff | FedAvg | FedProx |
|---|---|---|---|---|
| CelebA | 90% | 31.9 | 231 (8.5x) | 228 (8.4x) |
| Sent140 | 69% | 124.7 | >600 | >600 |
| CIFAR-10 | 60% | 67.5 | 386.7 (5.7x) | 292.7 (4.3x) |
| Method | Load per Client | Total Load |
|---|---|---|
| SL with client weight sharing | ||
| SL without client weight sharing | ||
| FL |
| Client Count | Load per Client in SL (TFlops) | Load per Client in FL (TFlops) |
|---|---|---|
| 100 | 0.1548 | 29.4 |
| 500 | 0.03 | 5.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arzovs, A.; Judvaitis, J.; Nesenbergs, K.; Selavo, L. Distributed Learning in the IoT–Edge–Cloud Continuum. Mach. Learn. Knowl. Extr. 2024, 6, 283-315. https://doi.org/10.3390/make6010015
Arzovs A, Judvaitis J, Nesenbergs K, Selavo L. Distributed Learning in the IoT–Edge–Cloud Continuum. Machine Learning and Knowledge Extraction. 2024; 6(1):283-315. https://doi.org/10.3390/make6010015
Chicago/Turabian StyleArzovs, Audris, Janis Judvaitis, Krisjanis Nesenbergs, and Leo Selavo. 2024. "Distributed Learning in the IoT–Edge–Cloud Continuum" Machine Learning and Knowledge Extraction 6, no. 1: 283-315. https://doi.org/10.3390/make6010015
APA StyleArzovs, A., Judvaitis, J., Nesenbergs, K., & Selavo, L. (2024). Distributed Learning in the IoT–Edge–Cloud Continuum. Machine Learning and Knowledge Extraction, 6(1), 283-315. https://doi.org/10.3390/make6010015