VisFormers—Combining Vision and Transformers for Enhanced Complex Document Classification



Abstract
:1. Introduction
- To develop a fast and efficient complex document classification model.
- To combine computer vision and natural language processing networks in a single model for complex document classification.
- Facilitating different types of inputs and enabling different optimizers in different parts of the network while training.
- To benchmark the performance with the state-of-the-art methods using the standard complex document classification dataset RVL-CDIP.
2. Related Works
3. Methodology
3.1. Data Collection
3.2. Optical Character Recognition
3.3. Text Preprocessing
3.4. Image Preprocessing
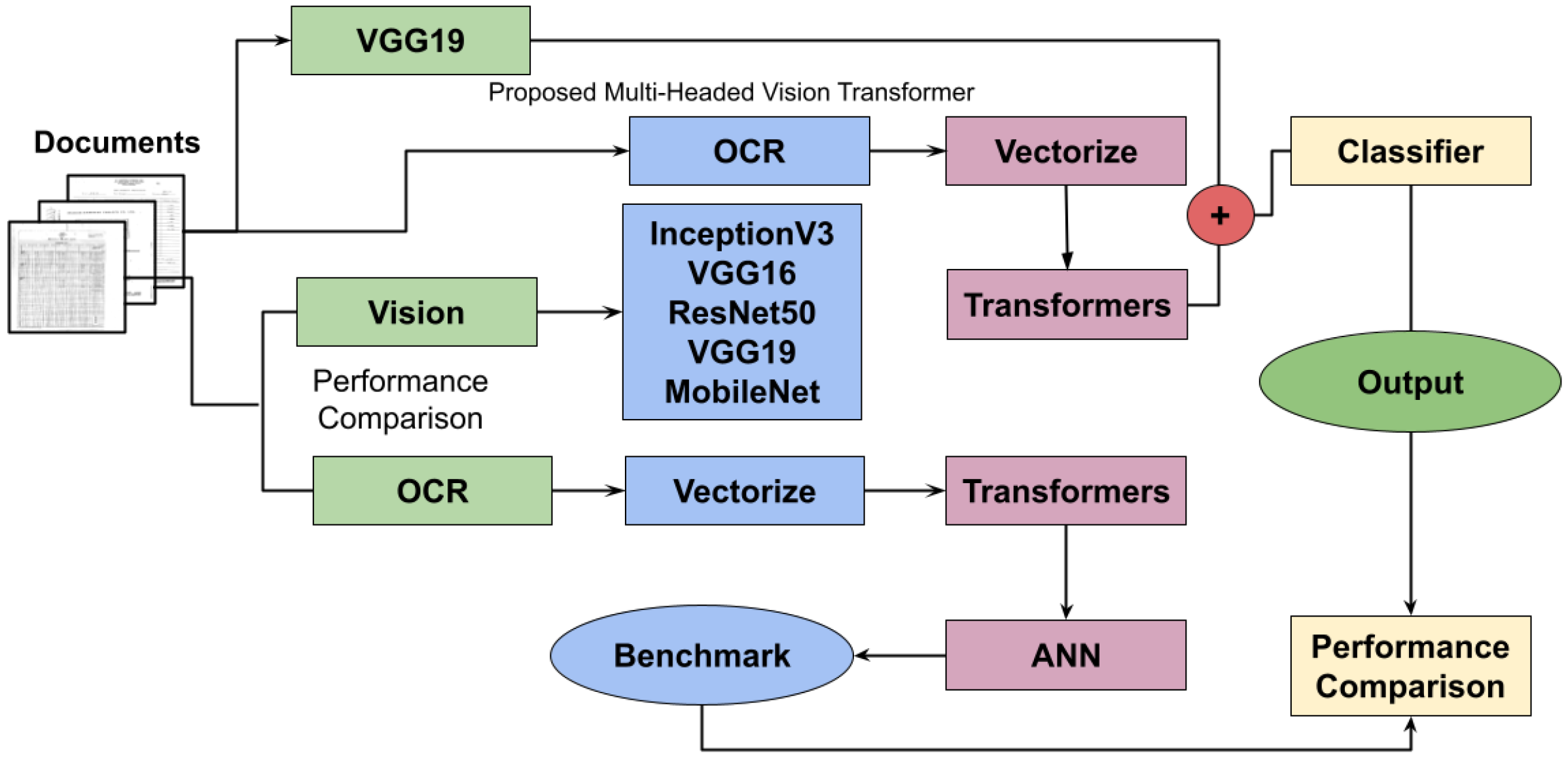
3.5. Proposed Multi-Headed Vision–Transformer Network
3.6. Comparitive Analysis with Transfer Learning and Natural Language Processing
4. Results
4.1. Heatmap Visualization for the Proposed Vision Transformer
4.2. Document Classification Performance for the Proposed Vision Transformer
5. Discussion
5.1. Document Classification Performance for Transformers with Optical Character Recognition and Natural Language Processing
5.2. Document Classification Performance for Vision-Based Transfer Learning
5.3. Comparison with the State of the Art
5.4. Limitations of the Proposed VisFormers Model
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Code Availability
Ethical Statement
References
- Audebert, N.; Herold, C.; Slimani, K.; Vidal, C. Multimodal deep networks for text and image-based document classification. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: International Workshops of ECML PKDD 2019, Würzburg, Germany, 16–20 September 2019; pp. 427–443. [Google Scholar]
- Adhikari, A.; Ram, A.; Tang, R.; Lin, J. Docbert: Bert for document classification. arXiv 2019, arXiv:1904.08398. [Google Scholar]
- Kim, D.; Seo, D.; Cho, S.; Kang, P. Multi-co-training for document classification using various document representations: TF–IDF, LDA, and Doc2Vec. Inf. Sci. 2019, 477, 15–29. [Google Scholar] [CrossRef]
- Bhagat, R.; Thosani, P.; Shah, N.; Shankarmani, R. Complex Document Classification and Integration with Indexing. In Proceedings of the 2021 Second International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 4–6 August 2021; pp. 1477–1484. [Google Scholar] [CrossRef]
- Biten, A.F.; Tito, R.; Gomez, L.; Valveny, E.; Karatzas, D. Ocr-idl: Ocr annotations for industry document library dataset. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23 October 2022; pp. 241–252. [Google Scholar]
- Aydin, Ö. Classification of documents extracted from images with optical character recognition methods. Comput. Sci. 2021, 6, 46–55. [Google Scholar]
- Jiang, M.; Hu, Y.; Worthey, G.; Dubnicek, R.C.; Underwood, T.; Downie, J.S. Impact of OCR quality on BERT embeddings in the domain classification of book excerpts. Ceur Proc. 2021, 1613, 0073. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Banerjee, S.; Akkaya, C.; Perez-Sorrosal, F.; Tsioutsiouliklis, K. Hierarchical transfer learning for multi-label text classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 6295–6300. [Google Scholar]
- Behera, B.; Kumaravelan, G.; Kumar, P. Performance evaluation of deep learning algorithms in biomedical document classification. In Proceedings of the 2019 11th International Conference on Advanced Computing (ICoAC), Hawaii, HI, USA, 18 March 2019; pp. 220–224. [Google Scholar]
- Zhao, Z.; Yang, S.; Zhao, D. A new framework for visual classification of multi-channel malware based on transfer learning. Appl. Sci. 2023, 13, 2484. [Google Scholar] [CrossRef]
- Baniata, L.H.; Kang, S. Transformer Text Classification Model for Arabic Dialects That Utilizes Inductive Transfer. Mathematics 2023, 11, 4960. [Google Scholar] [CrossRef]
- Singh, R.; Gildhiyal, P. An Innovation Development of Document Management and Security Model for Commercial Database Handling Systems. In Proceedings of the 2023 IEEE International Conference on Integrated Circuits and Communication Systems (ICICACS), Raichur, India, 24–25 February 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Finances Online. 71 Cloud File & Document Management Statistics You Must Know: 2021 Data Analysis & Market Share. 2024. Available online: https://financesonline.com/cloud-file-document-management-statistics (accessed on 10 February 2024).
- Pandey, M.; Arora, M.; Arora, S.; Goyal, C.; Gera, V.K.; Yadav, H. AI-based Integrated Approach for the Development of Intelligent Document Management System (IDMS). Procedia Comput. Sci. 2023, 230, 725–736. [Google Scholar] [CrossRef]
- Dutta, S.; Goswami, S.; Debnath, S.; Adhikary, S.; Majumder, A. If Human Can Learn from Few Samples, Why Can’t AI? An Attempt On Similar Object Recognition with Few Training Data Using Meta-Learning. In Proceedings of the 2023 IEEE North Karnataka Subsection Flagship International Conference (NKCon), Belagavi, India, 19–20 November 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Sajadfar, N.; Abdollahnejad, S.; Hermann, U.; Mohamed, Y. Text detection and classification of construction documents. In Proceedings of the ISARC, International Symposium on Automation and Robotics in Construction, Banff, AL, Canada, 24–24 May 2019; Volume 36, pp. 446–452. [Google Scholar]
- Guha, A.; Samanta, D. Real-time application of document classification based on machine learning. In Proceedings of the Intelligent Computing Paradigm and Cutting-Edge Technologies (ICICCT 2019), Istanbul, Turkey, 30–31 October 2019; pp. 366–379. [Google Scholar]
- Adhikary, S.; Dutta, S.; Dwivedi, A.D. Secret learning for lung cancer diagnosis—A study with homomorphic encryption, texture analysis and deep learning. Biomed. Phys. Eng. Express 2023, 10, 015011. [Google Scholar] [CrossRef]
- Muaad, A.Y.; Kumar, G.H.; Hanumanthappa, J.; Benifa, J.B.; Mourya, M.N.; Chola, C.; Pramodha, M.; Bhairava, R. An effective approach for Arabic document classification using machine learning. Glob. Transit. Proc. 2022, 3, 267–271. [Google Scholar] [CrossRef]
- Jiang, S.; Hu, J.; Magee, C.L.; Luo, J. Deep learning for technical document classification. IEEE Trans. Eng. Manag. 2022, 71, 1163–1179. [Google Scholar] [CrossRef]
- Dhanikonda, S.R.; Sowjanya, P.; Ramanaiah, M.L.; Joshi, R.; Krishna Mohan, B.; Dhabliya, D.; Raja, N.K. An efficient deep learning model with interrelated tagging prototype with segmentation for telugu optical character recognition. Sci. Program. 2022, 2022, 1059004. [Google Scholar] [CrossRef]
- Tote, A.S.; Pardeshi, S.S.; Patange, A.D. Automatic number plate detection using TensorFlow in Indian scenario: An optical character recognition approach. Mater. Today Proc. 2023, 72, 1073–1078. [Google Scholar] [CrossRef]
- Ali, I.; Mughal, N.; Khand, Z.H.; Ahmed, J.; Mujtaba, G. Resume classification system using natural language processing and machine learning techniques. Mehran Univ. Res. J. Eng. Technol. 2022, 41, 65–79. [Google Scholar] [CrossRef]
- Haghighian Roudsari, A.; Afshar, J.; Lee, W.; Lee, S. PatentNet: Multi-label classification of patent documents using deep learning based language understanding. Scientometrics 2022, 127, 207–231. [Google Scholar] [CrossRef]
- Ameer, I.; Bölücü, N.; Siddiqui, M.H.F.; Can, B.; Sidorov, G.; Gelbukh, A. Multi-label emotion classification in texts using transfer learning. Expert Syst. Appl. 2023, 213, 118534. [Google Scholar] [CrossRef]
- Yang, M.; Xu, S. A novel Degraded Document Binarization model through vision transformer network. Inf. Fusion 2023, 93, 159–173. [Google Scholar] [CrossRef]
- Rahali, A.; Akhloufi, M.A. End-to-end transformer-based models in textual-based NLP. AI 2023, 4, 54–110. [Google Scholar] [CrossRef]
- Pilicita, A.; Barra, E. Using of Transformers Models for Text Classification to Mobile Educational Applications. IEEE Lat. Am. Trans. 2023, 21, 730–736. [Google Scholar] [CrossRef]
- Jofche, N.; Mishev, K.; Stojanov, R.; Jovanovik, M.; Zdravevski, E.; Trajanov, D. Pharmke: Knowledge extraction platform for pharmaceutical texts using transfer learning. Computers 2023, 12, 17. [Google Scholar] [CrossRef]
- Alruily, M.; Manaf Fazal, A.; Mostafa, A.M.; Ezz, M. Automated Arabic long-tweet classification using transfer learning with BERT. Appl. Sci. 2023, 13, 3482. [Google Scholar] [CrossRef]
- Tang, Z.; Yang, Z.; Wang, G.; Fang, Y.; Liu, Y.; Zhu, C.; Zeng, M.; Zhang, C.; Bansal, M. Unifying vision, text, and layout for universal document processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19254–19264. [Google Scholar]
- Pande, S.D.; Jadhav, P.P.; Joshi, R.; Sawant, A.D.; Muddebihalkar, V.; Rathod, S.; Gurav, M.N.; Das, S. Digitization of handwritten Devanagari text using CNN transfer learning–A better customer service support. Neurosci. Inform. 2022, 2, 100016. [Google Scholar] [CrossRef]
- Harley, A.W.; Ufkes, A.; Derpanis, K.G. Evaluation of Deep Convolutional Nets for Document Image Classification and Retrieval. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015. [Google Scholar]
- Jayoma, J.M.; Moyon, E.S.; Morales, E.M.O. OCR based document archiving and indexing using PyTesseract: A record management system for dswd caraga, Philippines. In Proceedings of the 2020 IEEE 12th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM), Manila, Philippines, 3–7 December 2020; pp. 1–6. [Google Scholar]
- Camastra, F.; Razi, G. Italian text categorization with lemmatization and support vector machines. In Neural Approaches to Dynamics of Signal Exchanges; Springer: Berlin/Heidelberg, Germany, 2020; pp. 47–54. [Google Scholar]
- Wendland, A.; Zenere, M.; Niemann, J. Introduction to text classification: Impact of stemming and comparing TF-IDF and count vectorization as feature extraction technique. In Proceedings of the Systems, Software and Services Process Improvement: 28th European Conference, EuroSPI 2021, Krems, Austria, 1–3 September 2021; pp. 289–300. [Google Scholar]
- Adhikary, S. Fish Species Identification on Low Resolution-A Study with Enhanced Super Resolution Generative Adversarial Network (ESRGAN), YOLO and VGG-16. Res. Sq. 2022. [Google Scholar] [CrossRef]
- Groleau, A.; Chee, K.W.; Larson, S.; Maini, S.; Boarman, J. Augraphy: A data augmentation library for document images. arXiv 2022, arXiv:2208.14558. [Google Scholar]
- Rhanoui, M.; Mikram, M.; Yousfi, S.; Barzali, S. A CNN-BiLSTM model for document-level sentiment analysis. Mach. Learn. Knowl. Extr. 2019, 1, 832–847. [Google Scholar] [CrossRef]
- Dutta, S.; Adhikary, S. Evolutionary Swarming Particles To Speedup Neural Network Parametric Weights Updates. In Proceedings of the 2023 9th International Conference on Smart Computing and Communications (ICSCC), Kochi, India, 17–19 August 2023; pp. 413–418. [Google Scholar] [CrossRef]
- Dey, N.; Zhang, Y.D.; Rajinikanth, V.; Pugalenthi, R.; Raja, N.S.M. Customized VGG19 Architecture for Pneumonia Detection in Chest X-Rays. Pattern Recognit. Lett. 2021, 143, 67–74. [Google Scholar] [CrossRef]
- Liu, R.; Shi, Y.; Ji, C.; Jia, M. A survey of sentiment analysis based on transfer learning. IEEE Access 2019, 7, 85401–85412. [Google Scholar] [CrossRef]
- Pappagari, R.; Zelasko, P.; Villalba, J.; Carmiel, Y.; Dehak, N. Hierarchical transformers for long document classification. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 838–844. [Google Scholar]
- Tensmeyer, C.; Martinez, T. Analysis of convolutional neural networks for document image classification. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 388–393. [Google Scholar]
- Siddiqui, S.A.; Dengel, A.; Ahmed, S. Self-supervised representation learning for document image classification. IEEE Access 2021, 9, 164358–164367. [Google Scholar] [CrossRef]
- Larson, S.; Lim, Y.Y.G.; Ai, Y.; Kuang, D.; Leach, K. Evaluating Out-of-Distribution Performance on Document Image Classifiers. Adv. Neural Inf. Process. Syst. 2022, 35, 11673–11685. [Google Scholar]
- Kanchi, S.; Pagani, A.; Mokayed, H.; Liwicki, M.; Stricker, D.; Afzal, M.Z. EmmDocClassifier: Efficient multimodal document image classifier for scarce data. Appl. Sci. 2022, 12, 1457. [Google Scholar] [CrossRef]
- Bakkali, S.; Ming, Z.; Coustaty, M.; Rusiñol, M. Visual and textual deep feature fusion for document image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2020; pp. 562–563. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Source | Objective | Data Type | Algorithm | Remarks | Limitations |
|---|---|---|---|---|---|
| [20] | Arabic text classification using ML | Text data | MNB, BNB, SGD, LR, SVC, CNN | CNN with character-level model outperforms; applicability in various domains, particularly social media | Limited dataset size taken for classification. |
| [21] | Efficient tech document classification | Technical text | TechDoc architecture. | Improved tech document categorization and scalability for large tech companies. | Specific to tech documents; limited domain applicability |
| [22] | Digitization of handwritten Devanagari text | Text and image | CNN-based DHTR | Automated Devanagari script digitization; preservation of ancient knowledge | Specific to Devanagari script |
| [23] | Indian scenario number plate detection using TensorFlow | Image data | CNN-based model | Significant potential for road safety and theft prevention; real-world applications | Limited scalability, dataset size, and diversity |
| [24] | Resume classification using NLP and ML | Text data | Various ML algorithms, NLP | Efficient automation of resume categorization; improved accuracy and reliability | Focuses on resumes; limited scalability |
| [25] | Patent document classification using transfer learning | Text data | BERT, XLNet, RoBERTa, ELECTRA | Enhanced patent classification; improved state-of-the-art performance. | Limited to patent documents; specific to classification task |
| [26] | Multi-label emotion classification in texts | Text data | LSTMs, Transformers | Improved accuracy in multi-label emotion classification; outperforms existing benchmarks. | Focuses on social media text; limited to emotion classification |
| [33] | Digitization of handwritten Devanagari text | Text and image | CNN-based DHTR | Automated Devanagari script digitization; preservation of ancient knowledge | Specific to Devanagari scripts |
| Metrics | Proposed VisFormers Performance |
|---|---|
| Accuracy | 0.942 |
| Precision | 0.913 |
| Recall | 0.935 |
| F1 Score | 0.924 |
| Train Time (s) | 951 |
| Test Time (ms) | 287 |
| Metrics | SOTA OCR + NLP Performance | Proposed VisFormers |
|---|---|---|
| Accuracy | 0.83 | 0.942 |
| Precision | 0.87 | 0.913 |
| Recall | 0.85 | 0.935 |
| F1 Score | 0.85 | 0.924 |
| Train Time (s) | 58 | 951 |
| Test Time (ms) | 64 | 287 |
| Metrics | IncV3 | VGG16 | Res Net50 | VGG19 | Mobile Net | VisFormers |
|---|---|---|---|---|---|---|
| Accuracy | 0.79 | 0.89 | 0.87 | 0.9 | 0.85 | 0.94 |
| Precision | 0.81 | 0.85 | 0.88 | 0.91 | 0.88 | 0.91 |
| Recall | 0.79 | 0.83 | 0.86 | 0.87 | 0.86 | 0.94 |
| F1 Score | 0.79 | 0.83 | 0.86 | 0.88 | 0.86 | 0.92 |
| Train Time (s) | 785 | 802 | 792 | 855 | 779 | 951 |
| Test Time (ms) | 124 | 231 | 144 | 254 | 112 | 287 |
| Source | Vision | OCR | Accuracy | Train Time (s) |
|---|---|---|---|---|
| Tensmeyer et al. [45] | ✓ | X | <90% | >900 |
| Siddiqui et al. [46] | ✓ | X | <85% | >1200 |
| Larson et al. [47] | X | ✓ | <80% | >500 |
| Kanchi et al. [48] | ✓ | ✓ | <90% | >1500 |
| Bakkali et al. [49] | ✓ | ✓ | <92% | >1000 |
| Proposed VisFormers | ✓ | ✓ | >94% | 951 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dutta, S.; Adhikary, S.; Dwivedi, A.D. VisFormers—Combining Vision and Transformers for Enhanced Complex Document Classification. Mach. Learn. Knowl. Extr. 2024, 6, 448-463. https://doi.org/10.3390/make6010023
Dutta S, Adhikary S, Dwivedi AD. VisFormers—Combining Vision and Transformers for Enhanced Complex Document Classification. Machine Learning and Knowledge Extraction. 2024; 6(1):448-463. https://doi.org/10.3390/make6010023
Chicago/Turabian StyleDutta, Subhayu, Subhrangshu Adhikary, and Ashutosh Dhar Dwivedi. 2024. "VisFormers—Combining Vision and Transformers for Enhanced Complex Document Classification" Machine Learning and Knowledge Extraction 6, no. 1: 448-463. https://doi.org/10.3390/make6010023
APA StyleDutta, S., Adhikary, S., & Dwivedi, A. D. (2024). VisFormers—Combining Vision and Transformers for Enhanced Complex Document Classification. Machine Learning and Knowledge Extraction, 6(1), 448-463. https://doi.org/10.3390/make6010023