
Impact of Nature of Medical Data on Machine and Deep Learning for Imbalanced Datasets: Clinical Validity of SMOTE Is Questionable


Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
2.2. Machine and Deep Learning
3. Results

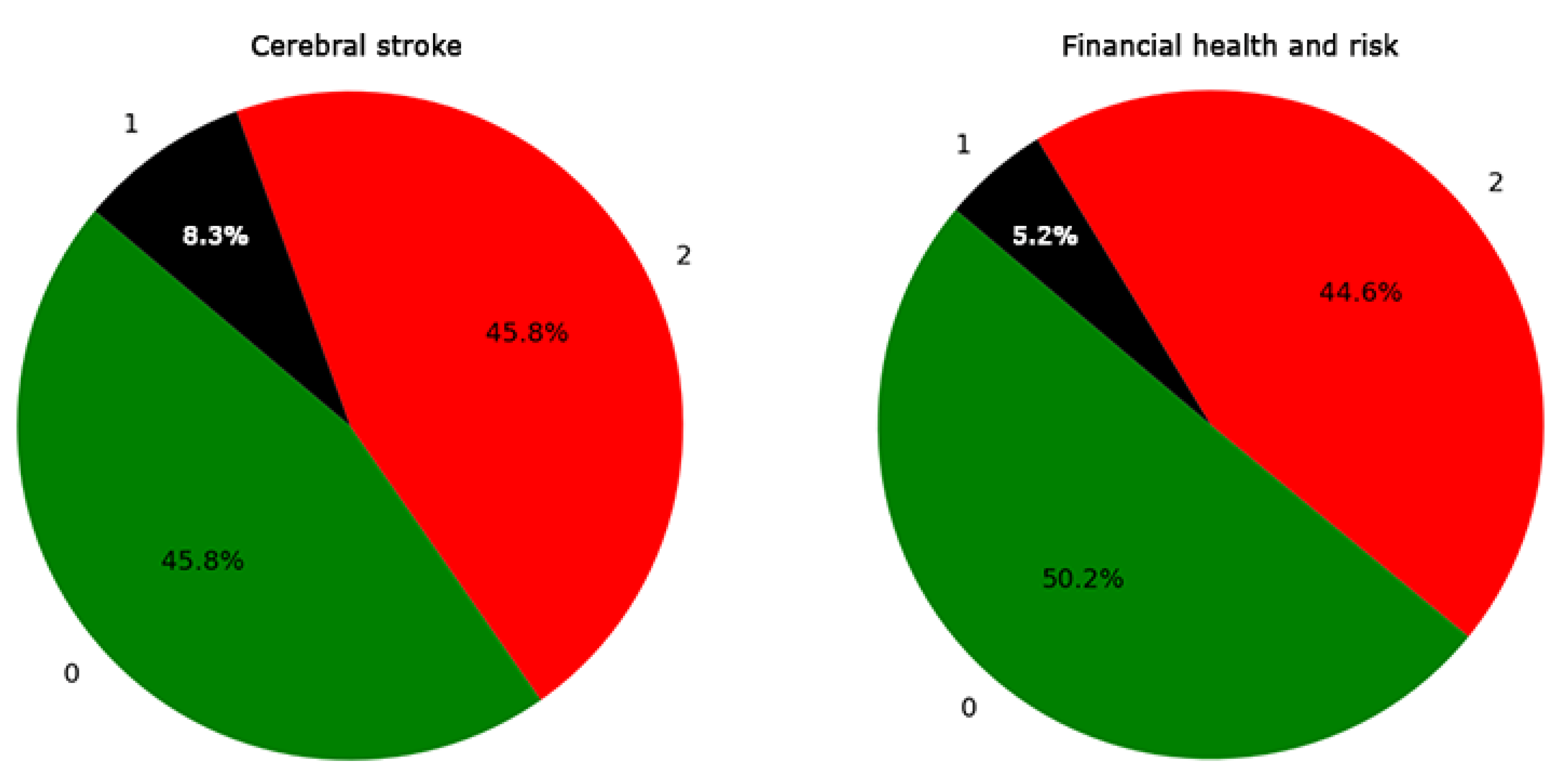{kind=link}
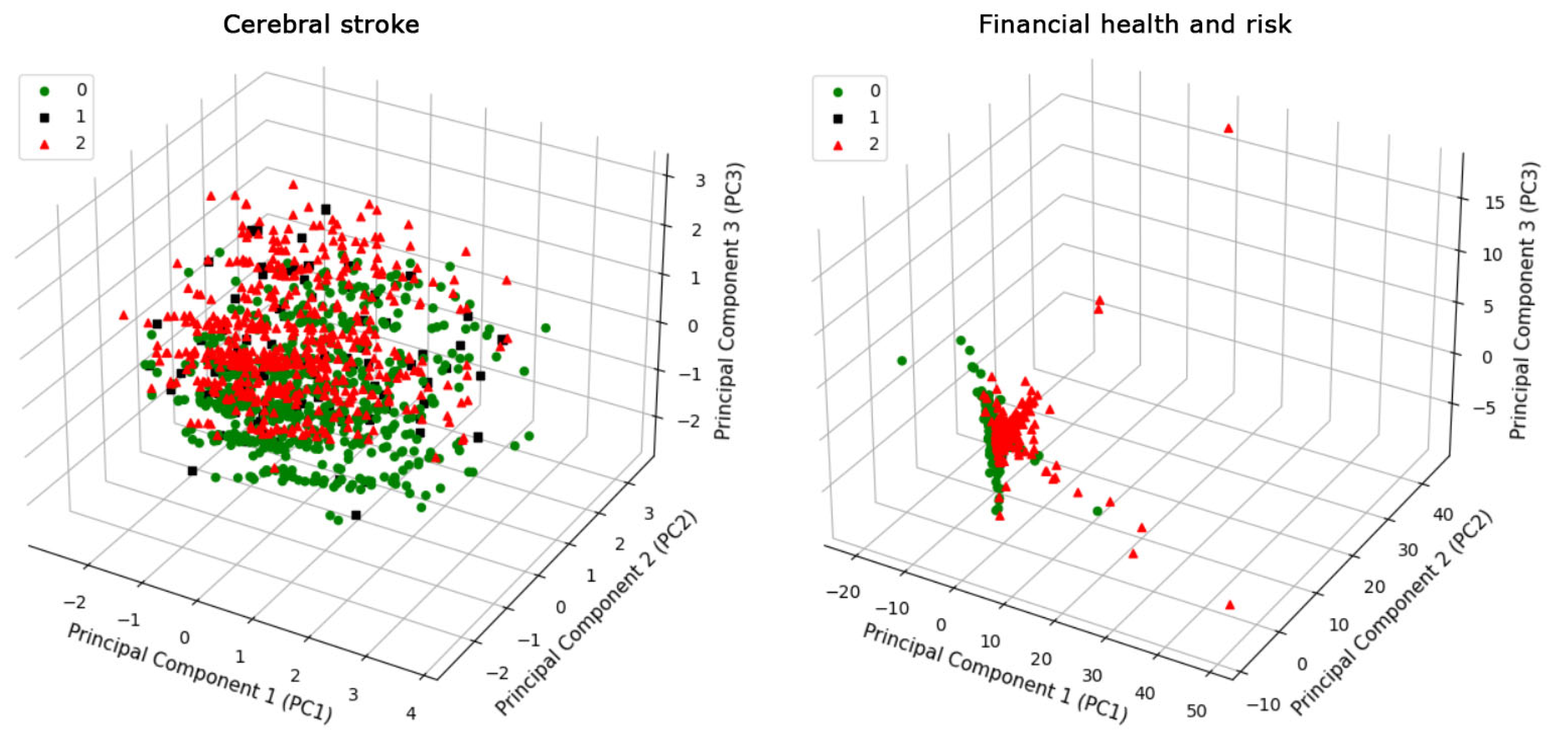{kind=link}
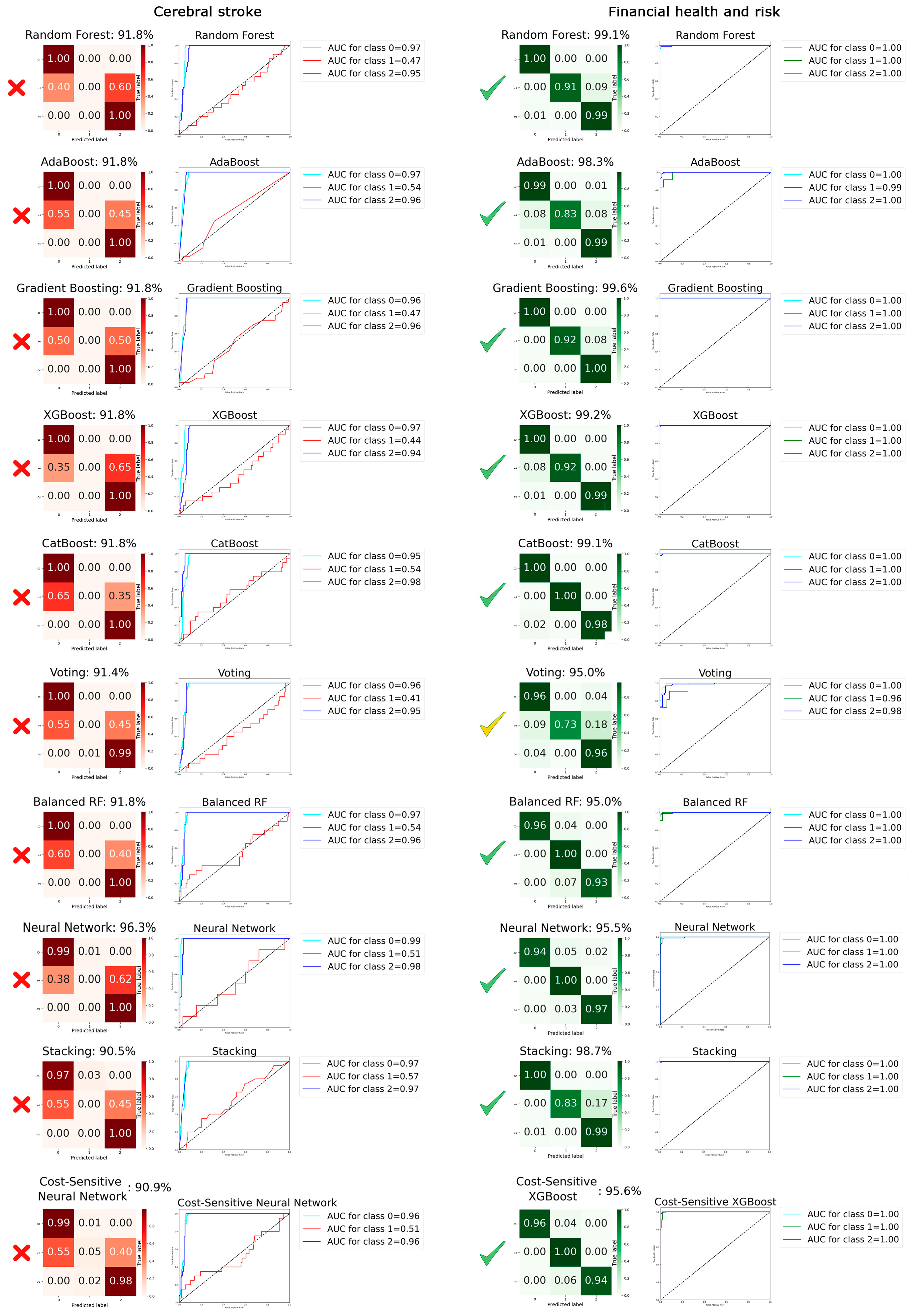{kind=link}
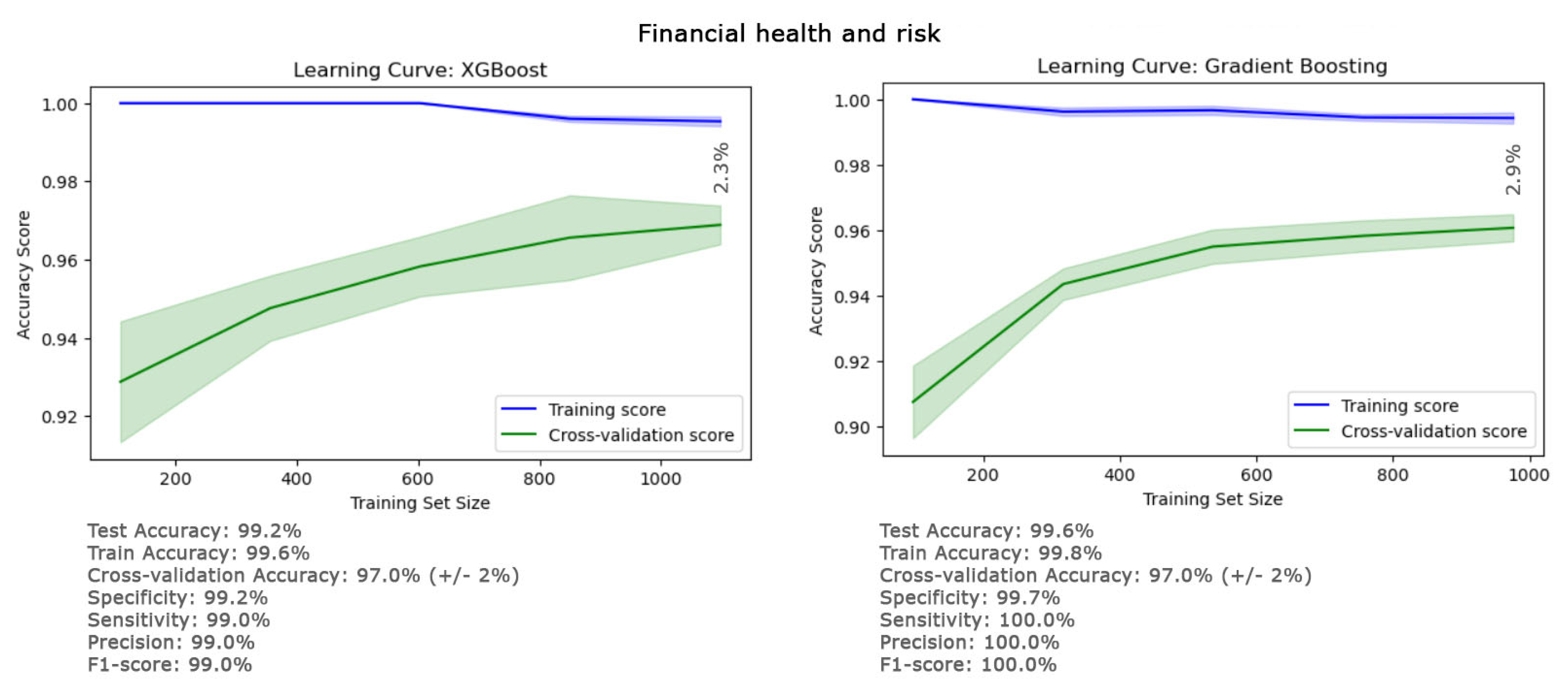{kind=link}
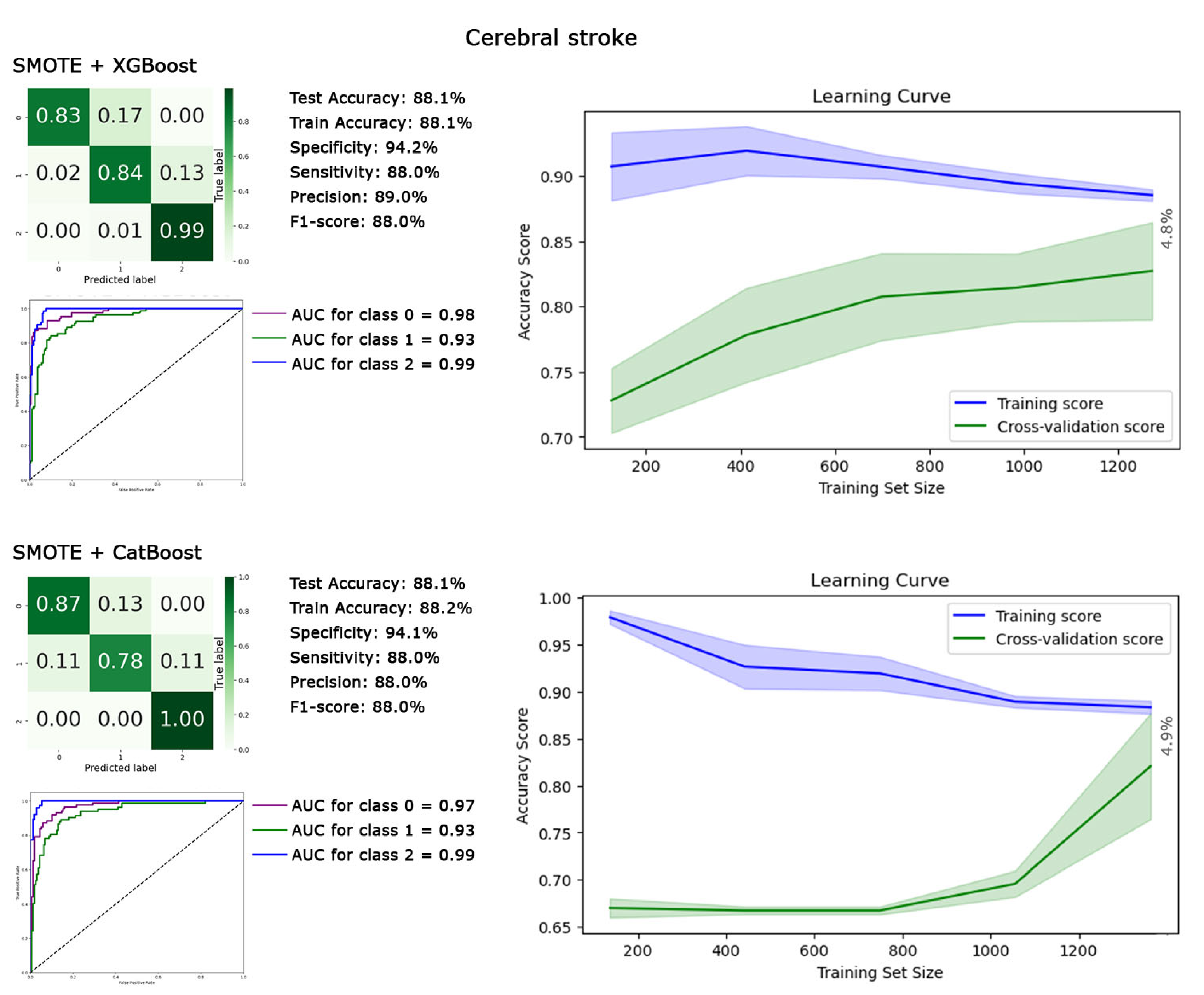{kind=link}
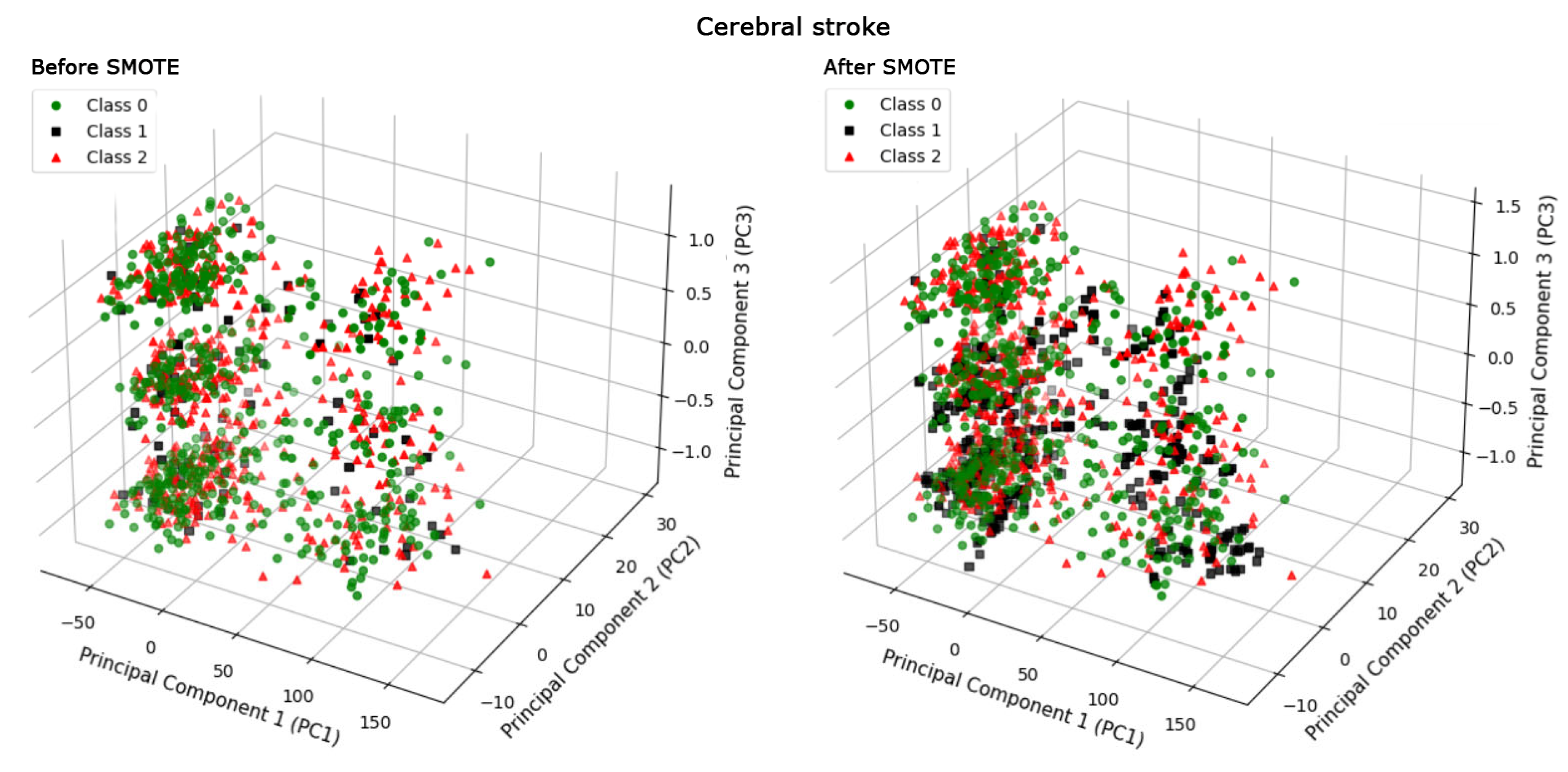{kind=link}
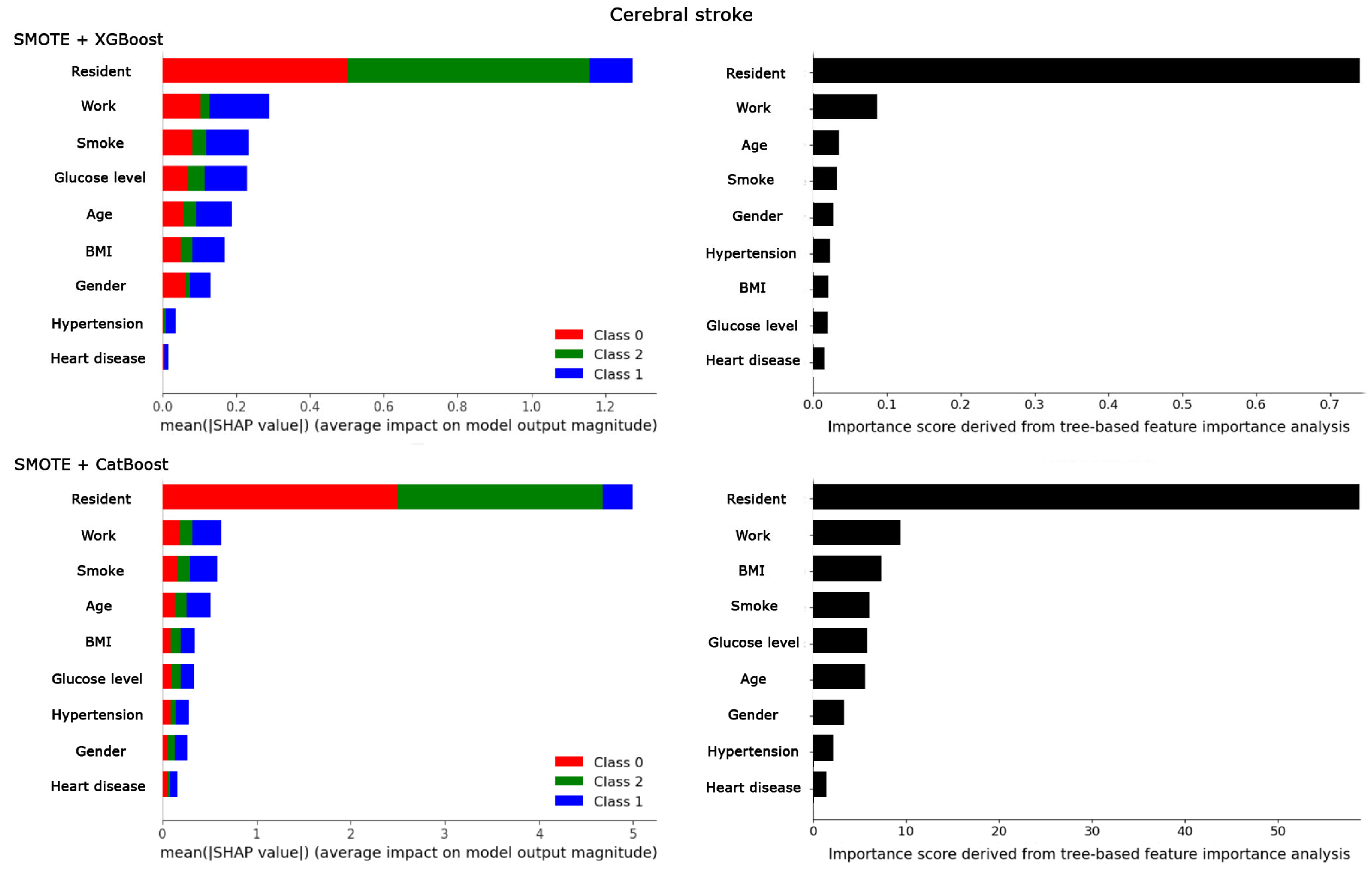{kind=link}
| Algorithm Name | Algorithm Description |
|---|---|
| Random Forest | An ensemble learning method that operates by constructing a multitude of decision trees at training time to output the mode of the classes of the individual trees. |
| AdaBoost | A boosting algorithm that combines multiple weak learners (a single tree) to create a strong learner. It sequentially adjusts the weights of incorrectly classified instances so they are correctly classified in subsequent rounds. |
| Gradient Boosting | An ensemble technique that builds models sequentially, with each new model correcting errors made by previous models. It minimizes loss via gradient descent, enhancing prediction accuracy for diverse datasets. |
| XGBoost | Stands for extreme gradient boosting, an optimized distributed gradient boosting library designed to be highly efficient, flexible, and portable. |
| CatBoost | A gradient boosting algorithm on decision trees was developed to provide high performance with categorical data. It generally reduces overfitting and is effective across a broad range of datasets and problems. |
| Voting | An ensemble machine learning model that combines predictions from multiple models. In our project, it integrates the outputs of the two classifiers that had the best individual performance. Then, it predicts the class based on the majority vote for classification or the average of predicted probabilities. |
| Balanced Random Forest | A variant of the random forest algorithm that adjusts weights inversely proportional to class frequencies in the input data or specified by the user. This classifier should be generally useful for addressing imbalanced datasets. |
| Neural network (Multilayer perceptron) | A foundational deep learning algorithm, MLP models complex relationships between features and targets using a multilayer network of neurons. An MLP includes an input layer, several hidden layers, and an output layer. Connections between neurons across layers are adjusted during training via backpropagation—calculating loss function gradients—to minimize prediction errors. |
| Stacking | An ensemble learning technique that combines multiple classification models via a meta-classifier. In our project, it combines the outputs of the two classifiers that demonstrated the best individual performance. First, the base-level models are trained using a complete dataset. Then, the meta-model is trained on the outputs of the base-level models as features. |
| Cost-sensitive | Adjusts the classification algorithms to emphasize the minority class, aiming to improve prediction accuracy in imbalanced datasets by modifying error weights or altering the decision threshold. |
4. Discussion

5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fotouhi, S.; Asadi, S.; Kattan, M.W. A comprehensive data level analysis for cancer diagnosis on imbalanced data. J. Biomed. Inform. 2019, 90, 103089. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Huang, M.; Liu, G.; Jiang, C. A hybrid method with dynamic weighted entropy for handling the problem of class imbalance with overlap in credit card fraud detection. Expert Syst. Appl. 2021, 175, 114750. [Google Scholar] [CrossRef]
- Wu, X.; Meng, S. E-commerce customer churn prediction based on improved SMOTE and AdaBoost. In Proceedings of the 2016 13th International Conference on Service Systems and Service Management (ICSSSM), Kunming, China, 24–26 June 2016; pp. 1–5. [Google Scholar]
- Guo, H.; Li, Y.; Jennifer, S.; Gu, M.; Huang, Y.; Gong, B. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Ghosh, K.; Bellinger, C.; Corizzo, R.; Branco, P.; Krawczyk, B.; Japkowicz, N. The class imbalance problem in deep learning. Mach. Learn. 2022, 111, 1–57. [Google Scholar] [CrossRef]
- Waterstraat, G.; Dehghan, A.; Gholampour, S. Optimization of Number and Range of Shunt Valve Performance Levels in Infant Hydrocephalus: A Machine Learning Analysis. Front. Bioeng. Biotechnol. 2024, 12, 1352490. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.X.; Japkowicz, N. Boosting support vector machines for imbalanced data sets. Knowl. Inf. Syst. 2010, 25, 1–20. [Google Scholar] [CrossRef]
- Koziarski, M.; Krawczyk, B.; Woźniak, M. Radial-based oversampling for noisy imbalanced data classification. Neurocomputing 2019, 343, 19–33. [Google Scholar] [CrossRef]
- Lin, C.; Tsai, C.-F.; Lin, W.-C. Towards hybrid over-and under-sampling combination methods for class imbalanced datasets: An experimental study. Artif. Intell. Rev. 2023, 56, 845–863. [Google Scholar] [CrossRef]
- Vairetti, C.; Assadi, J.L.; Maldonado, S. Efficient hybrid oversampling and intelligent undersampling for imbalanced big data classification. Expert Syst. Appl. 2024, 246, 123149. [Google Scholar] [CrossRef]
- Alamri, M.; Ykhlef, M. Hybrid Undersampling and Oversampling for Handling Imbalanced Credit Card Data. IEEE Access 2024, 12, 14050–14060. [Google Scholar] [CrossRef]
- Liu, Y.; Zhu, L.; Ding, L.; Sui, H.; Shang, W. A hybrid sampling method for highly imbalanced and overlapped data classification with complex distribution. Inf. Sci. 2024, 661, 120117. [Google Scholar] [CrossRef]
- Chawla, N.V.; Cieslak, D.A.; Hall, L.O.; Joshi, A. Automatically countering imbalance and its empirical relationship to cost. Data Min. Knowl. Discov. 2008, 17, 225–252. [Google Scholar] [CrossRef]
- Ahmed, S.; Mahbub, A.; Rayhan, F.; Jani, R.; Shatabda, S.; Farid, D.M. Hybrid methods for class imbalance learning employing bagging with sampling techniques. In Proceedings of the 2017 2nd International Conference on Computational Systems and Information Technology for Sustainable Solution (CSITSS), Bengaluru, India, 21–23 December 2017; pp. 1–5. [Google Scholar]
- Beckmann, M.; Ebecken, N.F.; Pires de Lima, B.S. A KNN undersampling approach for data balancing. J. Intell. Learn. Syst. Appl. 2015, 7, 104–116. [Google Scholar] [CrossRef]
- Yu, H.; Ni, J.; Zhao, J. ACOSampling: An ant colony optimization-based undersampling method for classifying imbalanced DNA microarray data. Neurocomputing 2013, 101, 309–318. [Google Scholar] [CrossRef]
- Sáez, J.A.; Krawczyk, B.; Woźniak, M. Analyzing the oversampling of different classes and types of examples in multi-class imbalanced datasets. Pattern Recognit. 2016, 57, 164–178. [Google Scholar] [CrossRef]
- Yun, Z.; Nan, M.; Da, R.; Bing, A. An effective over-sampling method for imbalanced data sets classification. Chin. J. Electron. 2011, 20, 489–494. [Google Scholar]
- Gong, J.; Kim, H. RHSBoost: Improving classification performance in imbalance data. Comput. Stat. Data Anal. 2017, 111, 1–13. [Google Scholar] [CrossRef]
- Alejo, R.; Valdovinos, R.M.; García, V.; Pacheco-Sanchez, J.H. A hybrid method to face class overlap and class imbalance on neural networks and multi-class scenarios. Pattern Recognit. Lett. 2013, 34, 380–388. [Google Scholar] [CrossRef]
- Birla, S.; Kohli, K.; Dutta, A. Machine learning on imbalanced data in credit risk. In Proceedings of the 2016 IEEE 7th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 13–15 October 2016; pp. 1–6. [Google Scholar]
- Viloria, A.; Lezama, O.B.P.; Mercado-Caruzo, N. Unbalanced data processing using oversampling: Machine learning. Procedia Comput. Sci. 2020, 175, 108–113. [Google Scholar] [CrossRef]
- Tarawneh, A.S.; Hassanat, A.B.; Altarawneh, G.A.; Almuhaimeed, A. Stop oversampling for class imbalance learning: A review. IEEE Access 2022, 10, 47643–47660. [Google Scholar] [CrossRef]
- Kumari, A.; Behera, R.K.; Sahoo, K.S.; Nayyar, A.; Kumar Luhach, A.; Prakash Sahoo, S. Supervised link prediction using structured-based feature extraction in social network. Concurr. Comput. Pract. Exp. 2022, 34, e5839. [Google Scholar] [CrossRef]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Azhar, N.A.; Pozi, M.S.M.; Din, A.M.; Jatowt, A. An investigation of smote based methods for imbalanced datasets with data complexity analysis. IEEE Trans. Knowl. Data Eng. 2022, 35, 6651–6672. [Google Scholar] [CrossRef]
- Bao, Y.; Yang, S. Two novel SMOTE methods for solving imbalanced classification problems. IEEE Access 2023, 11, 5816–5823. [Google Scholar] [CrossRef]
- Guan, H.; Zhang, Y.; Xian, M.; Cheng, H.-D.; Tang, X. SMOTE-WENN: Solving class imbalance and small sample problems by oversampling and distance scaling. Appl. Intell. 2021, 51, 1394–1409. [Google Scholar] [CrossRef]
- Raghuwanshi, B.S.; Shukla, S. Classifying imbalanced data using SMOTE based class-specific kernelized ELM. Int. J. Mach. Learn. Cybern. 2021, 12, 1255–1280. [Google Scholar] [CrossRef]
- Hosenie, Z.; Lyon, R.; Stappers, B.; Mootoovaloo, A.; McBride, V. Imbalance learning for variable star classification. Mon. Not. R. Astron. Soc. 2020, 493, 6050–6059. [Google Scholar] [CrossRef]
- Pérez-Ortiz, M.; Gutiérrez, P.A.; Tino, P.; Hervás-Martínez, C. Oversampling the minority class in the feature space. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 1947–1961. [Google Scholar] [CrossRef] [PubMed]
- Islam, S.; Sara, U.; Kawsar, A.; Rahman, A.; Kundu, D.; Dipta, D.D.; Karim, A.; Hasan, M. Sgbba: An efficient method for prediction system in machine learning using imbalance dataset. Int. J. Adv. Sci. Comput. Appl. 2021, 12, 430–441. [Google Scholar] [CrossRef]
- Jeyalakshmi, K. Weighted Synthetic Minority Over-Sampling Technique (WSMOTE) Algorithm and Ensemble Classifier for Hepatocellular Carcinoma (HCC) In Liver Disease System. Turk. J. Comput. Math. Educ. (TURCOMAT) 2021, 12, 7473–7487. [Google Scholar]
- Wang, C.; Deng, C.; Wang, S. Imbalance-XGBoost: Leveraging weighted and focal losses for binary label-imbalanced classification with XGBoost. Pattern Recognit. Lett. 2020, 136, 190–197. [Google Scholar] [CrossRef]
- Devi, D.; Biswas, S.K.; Purkayastha, B. Correlation-based oversampling aided cost sensitive ensemble learning technique for treatment of class imbalance. J. Exp. Theor. Artif. Intell. 2022, 34, 143–174. [Google Scholar] [CrossRef]
- Abedin, M.Z.; Guotai, C.; Hajek, P.; Zhang, T. Combining weighted SMOTE with ensemble learning for the class-imbalanced prediction of small business credit risk. Complex Intell. Syst. 2023, 9, 3559–3579. [Google Scholar] [CrossRef]
- Kaisar, S.; Chowdhury, A. Integrating oversampling and ensemble-based machine learning techniques for an imbalanced dataset in dyslexia screening tests. ICT Express 2022, 8, 563–568. [Google Scholar] [CrossRef]
- Khuat, T.T.; Le, M.H. Evaluation of sampling-based ensembles of classifiers on imbalanced data for software defect prediction problems. SN Comput. Sci. 2020, 1, 108. [Google Scholar] [CrossRef]
- Werner de Vargas, V.; Schneider Aranda, J.A.; dos Santos Costa, R.; da Silva Pereira, P.R.; Victória Barbosa, J.L. Imbalanced data preprocessing techniques for machine learning: A systematic mapping study. Knowl. Inf. Syst. 2023, 65, 31–57. [Google Scholar] [CrossRef] [PubMed]
- Chamlal, H.; Kamel, H.; Ouaderhman, T. A hybrid multi-criteria meta-learner based classifier for imbalanced data. Knowl. Based Syst. 2024, 285, 111367. [Google Scholar] [CrossRef]
- Chen, Z.; Duan, J.; Kang, L.; Qiu, G. Class-imbalanced deep learning via a class-balanced ensemble. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 5626–5640. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Pineau, J. Online bagging and boosting for imbalanced data streams. IEEE Trans. Knowl. Data Eng. 2016, 28, 3353–3366. [Google Scholar] [CrossRef]
- Liu, T.; Fan, W.; Wu, C. A hybrid machine learning approach to cerebral stroke prediction based on imbalanced medical dataset. Artif. Intell. Med. 2019, 101, 101723. [Google Scholar] [CrossRef] [PubMed]
- El Khoury, R.; Al Beaïno, R. Classifying manufacturing firms in Lebanon: An application of Altman’s model. Procedia Soc. Behav. Sci. 2014, 109, 11–18. [Google Scholar]
- Gholampour, S.; Fatouraee, N.; Seddighi, A.; Seddighi, A. Numerical simulation of cerebrospinal fluid hydrodynamics in the healing process of hydrocephalus patients. J. Appl. Mech. Tech. Phys. 2017, 58, 386–391. [Google Scholar] [CrossRef]
- Gholampour, S.; Fatouraee, N.; Seddighi, A.S.; Seddighi, A. Evaluating the effect of hydrocephalus cause on the manner of changes in the effective parameters and clinical symptoms of the disease. J. Clin. Neurosci. 2017, 35, 50–55. [Google Scholar] [CrossRef] [PubMed]
- Gholampour, S. FSI simulation of CSF hydrodynamic changes in a large population of non-communicating hydrocephalus patients during treatment process with regard to their clinical symptoms. PLoS ONE 2018, 13, e0196216. [Google Scholar] [CrossRef] [PubMed]
- Gholampour, S. Feasibility of assessing non-invasive intracranial compliance using FSI simulation-based and MR elastography-based brain stiffness. Sci. Rep. 2024, 14, 6493. [Google Scholar] [CrossRef] [PubMed]
- Gholampour, S.; Mehrjoo, S. Effect of bifurcation in the hemodynamic changes and rupture risk of small intracranial aneurysm. Neurosurg. Rev. 2021, 44, 1703–1712. [Google Scholar] [CrossRef] [PubMed]
- Hajirayat, K.; Gholampour, S.; Sharifi, I.; Bizari, D. Biomechanical simulation to compare the blood hemodynamics and cerebral aneurysm rupture risk in patients with different aneurysm necks. J. Appl. Mech. Tech. Phys. 2017, 58, 968–974. [Google Scholar] [CrossRef]
- Gholampour, S.; Droessler, J.; Frim, D. The role of operating variables in improving the performance of skull base grinding. Neurosurg. Rev. 2022, 45, 2431–2440. [Google Scholar] [CrossRef]
- Gholampour, S.; Gholampour, H. Correlation of a new hydrodynamic index with other effective indexes in Chiari I malformation patients with different associations. Sci. Rep. 2020, 10, 15907. [Google Scholar] [CrossRef] [PubMed]
- Gholampour, S.; Taher, M. Relationship of morphologic changes in the brain and spinal cord and disease symptoms with cerebrospinal fluid hydrodynamic changes in patients with Chiari malformation type I. World Neurosurg. 2018, 116, e830–e839. [Google Scholar] [CrossRef] [PubMed]
- Beinecke, J.; Heider, D. Gaussian noise up-sampling is better suited than SMOTE and ADASYN for clinical decision making. BioData Mining 2021, 14, 49. [Google Scholar] [CrossRef] [PubMed]
- Ganaie, M.; Tanveer, M. Fuzzy least squares projection twin support vector machines for class imbalance learning. Appl. Soft Comput. 2021, 113, 107933. [Google Scholar] [CrossRef]
- Boehme, A.K.; Esenwa, C.; Elkind, M.S. Stroke risk factors, genetics, and prevention. Circ. Res. 2017, 120, 472–495. [Google Scholar] [CrossRef] [PubMed]
- Arboix, A. Cardiovascular risk factors for acute stroke: Risk profiles in the different subtypes of ischemic stroke. World J. Clin. Cases WJCC 2015, 3, 418. [Google Scholar] [CrossRef] [PubMed]
- Webb, A.J.; Werring, D.J. New insights into cerebrovascular pathophysiology and hypertension. Stroke 2022, 53, 1054–1064. [Google Scholar] [CrossRef]
- Phillips, S.J. Pathophysiology and management of hypertension in acute ischemic stroke. Hypertension 1994, 23, 131–136. [Google Scholar] [CrossRef] [PubMed]
- Sidhu, N.S.; Kaur, S. Cerebrovascular Disease and Hypertension. In Cerebrovascular Diseases-Elucidating Key Principles; IntechOpen: London, UK, 2021. [Google Scholar]
- Gorgui, J.; Gorshkov, M.; Khan, N.; Daskalopoulou, S.S. Hypertension as a risk factor for ischemic stroke in women. Can. J. Cardiol. 2014, 30, 774–782. [Google Scholar] [CrossRef] [PubMed]
- Han, L.; Wu, Q.; Wang, C.; Hao, Y.; Zhao, J.; Zhang, L.; Fan, R.; Liu, Y.; Li, R.; Chen, Z. Homocysteine, ischemic stroke, and coronary heart disease in hypertensive patients: A population-based, prospective cohort study. Stroke 2015, 46, 1777–1786. [Google Scholar] [CrossRef] [PubMed]
- Graor, R.A.; Hetzer, N.R. Current Concepts of Cerebrovascular Disease and Stroke. Stroke 1988, 19, 869–872. [Google Scholar]
- Zhang, S.; Song, X.-Y.; Xia, C.-Y.; Ai, Q.-D.; Chen, J.; Chu, S.-F.; He, W.-B.; Chen, N.-H. Effects of cerebral glucose levels in infarct areas on stroke injury mediated by blood glucose changes. RSC Adv. 2016, 6, 93815–93825. [Google Scholar] [CrossRef]






| Features of Cerebral Stroke Dataset | Mean | Variance | Features of Financial Health and Risk Dataset | Mean | Variance | |
|---|---|---|---|---|---|---|
| 1 | Gender | --- | --- | Price-to-earnings ratio | −2.35 | 1.65 |
| 2 | Age | 80.9 | 0.7 | Return on assets | −0.65 | 3.07 |
| 3 | Hypertension | --- | --- | Return on investment | 11.87 | 6.53 |
| 4 | Heart disease | --- | --- | Quick ratio | 3.46 | 0.57 |
| 5 | Work | --- | --- | Receivable turnover ratio | −64.89 | 3.89 |
| 6 | Resident | --- | --- | Enterprise value to sales | 1890.83 | 3813.01 |
| 7 | Average glucose level | 122.5 | 3322.0 | Enterprise value to EBIT ratio | 2.00 | 1.06 |
| 8 | Body mass index (BMI) | 27.7 | 29.2 | Equity ratio | 6.37 | 6.13 |
| 9 | Smoke | --- | --- | Cash return on assets | −0.42 | 4.27 |
| 10 | --- | --- | --- | Total liabilities to total assets ratio | 0.57 | 2.22 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gholampour, S. Impact of Nature of Medical Data on Machine and Deep Learning for Imbalanced Datasets: Clinical Validity of SMOTE Is Questionable. Mach. Learn. Knowl. Extr. 2024, 6, 827-841. https://doi.org/10.3390/make6020039
Gholampour S. Impact of Nature of Medical Data on Machine and Deep Learning for Imbalanced Datasets: Clinical Validity of SMOTE Is Questionable. Machine Learning and Knowledge Extraction. 2024; 6(2):827-841. https://doi.org/10.3390/make6020039
Chicago/Turabian StyleGholampour, Seifollah. 2024. "Impact of Nature of Medical Data on Machine and Deep Learning for Imbalanced Datasets: Clinical Validity of SMOTE Is Questionable" Machine Learning and Knowledge Extraction 6, no. 2: 827-841. https://doi.org/10.3390/make6020039
APA StyleGholampour, S. (2024). Impact of Nature of Medical Data on Machine and Deep Learning for Imbalanced Datasets: Clinical Validity of SMOTE Is Questionable. Machine Learning and Knowledge Extraction, 6(2), 827-841. https://doi.org/10.3390/make6020039