1. Introduction
In today’s dynamic and interconnected world, the significance of information spans various critical domains, including legal, political, commercial, and individual perspectives, and many more. Recognizing the pivotal role that opinions play in shaping decisions and influencing outcomes, there is a growing need for automated tools to analyze sentiments effectively. Regarding this case, sentiment analysis emerges as a significant participant. Sentiment mining, or sentiment analysis, is a comprehensive natural language processing approach that can identify and classify textual data’s emotional tone and subjective content. People are beginning to communicate their thoughts more quickly and in a shorter time, making the manual processing of many viewpoints quite tricky. Therefore, sentiment analysis has proven extremely useful in this field [
1,
2,
3]. By employing the sentiment analysis technique, stakeholders can also navigate the intricate layers of precedents and decisions, enhancing their capacity for nuanced interpretation and contributing to more informed decision making and policy formulation [
2].
Recently, a significant amount of research has been conducted on opinion mining and sentiment analysis by applying machine learning and deep learning in various domains [
4,
5,
6]. Opinion and sentiment analysis activities have been improved with the application of several neural networks, such as convolutional neural networks (CNNs), gated recurrent unit (GRU) or long short-term memory (LSTM), and recurrent neural networks (RNNs) [
7]. Additionally, machine learning and deep learning models excel in analyzing short texts, leveraging abundant datasets from social networks to identify opinions quickly. However, tackling longer documents presents a more intricate challenge, given the higher word count and complex semantic links between sentences. Researchers are increasingly invested in developing advanced analysis techniques to extract nuanced points of view on specific subjects from this substantial data mass. Navigating through the intricacies of longer documents, they aim to enhance sentiment analysis accuracy and gain deeper insights into complex topics, reflecting the evolving landscape of text analysis. From a legal perspective, there is a discernible trend toward integrating cutting-edge technologies such as machine learning and sentiment analysis to enhance the analytical capabilities of legal practitioners. Rhanoui, et al. [
8] utilized the CNN-BiLSTM model to analyze press articles and blog posts and reported almost 90.66% accuracy. Similarly, Tripathy, et al. [
9] employed a hybrid machine model to classify document-level sentiment and claim positive feedback. Hence, this technological infusion holds particular promise in Canadian maritime case law, where the complexities of legal texts and the need for precise forecasting of court decisions pose significant challenges [
10].
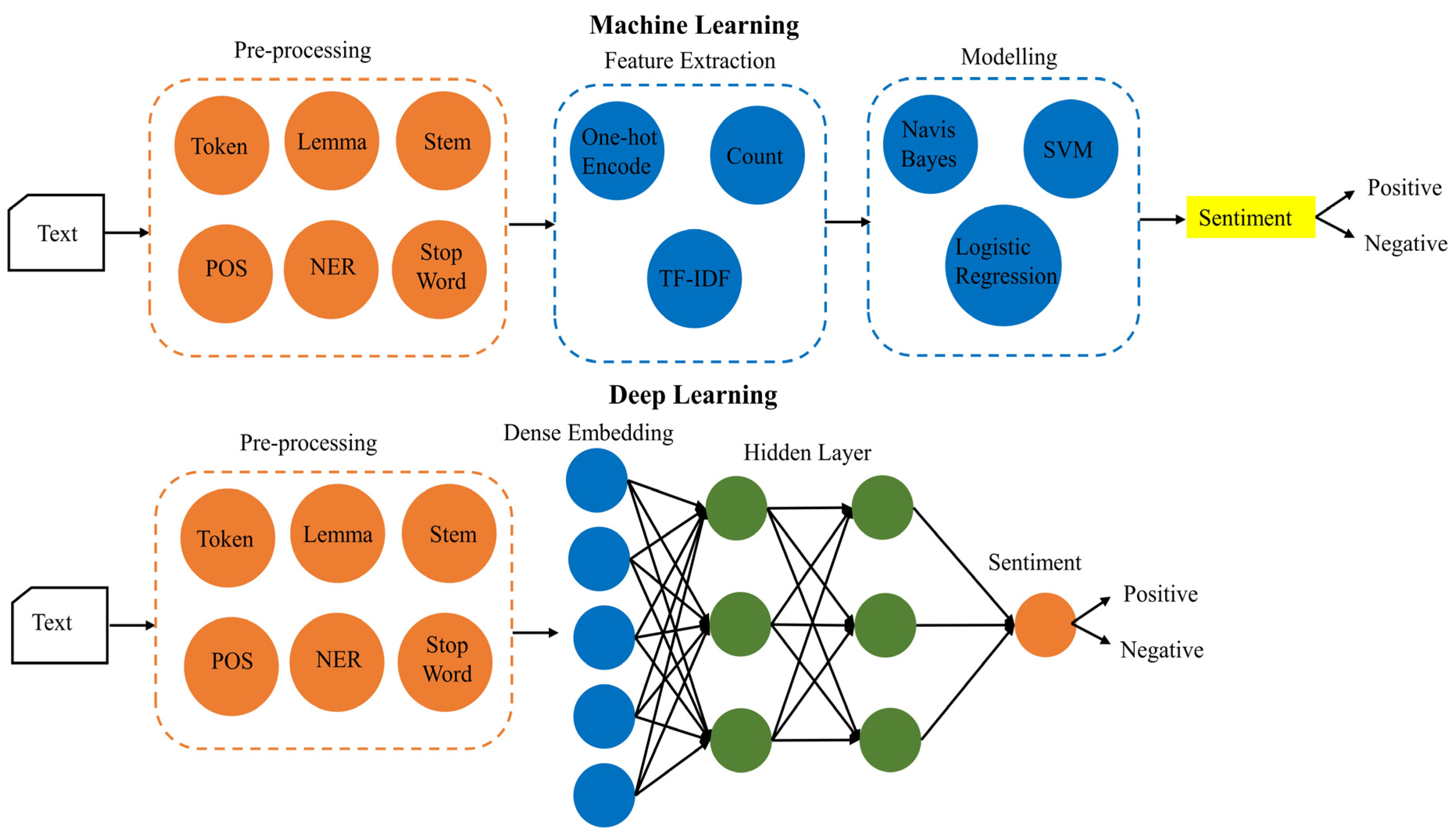
5. Proposed Model: CNN-LSTM and Doc2vec for Document-Level Sentiment Analysis
Cutting-edge methods in document-level sentiment analysis, like CNN-LSTM and Doc2Vec (see
Figure 2), leverage advanced techniques to extract valuable insights and sentiment information from extensive texts like reviews, articles, and reports. These methods aim to decipher the text’s underlying meaning and emotional nuances by employing deep learning and vector representations.
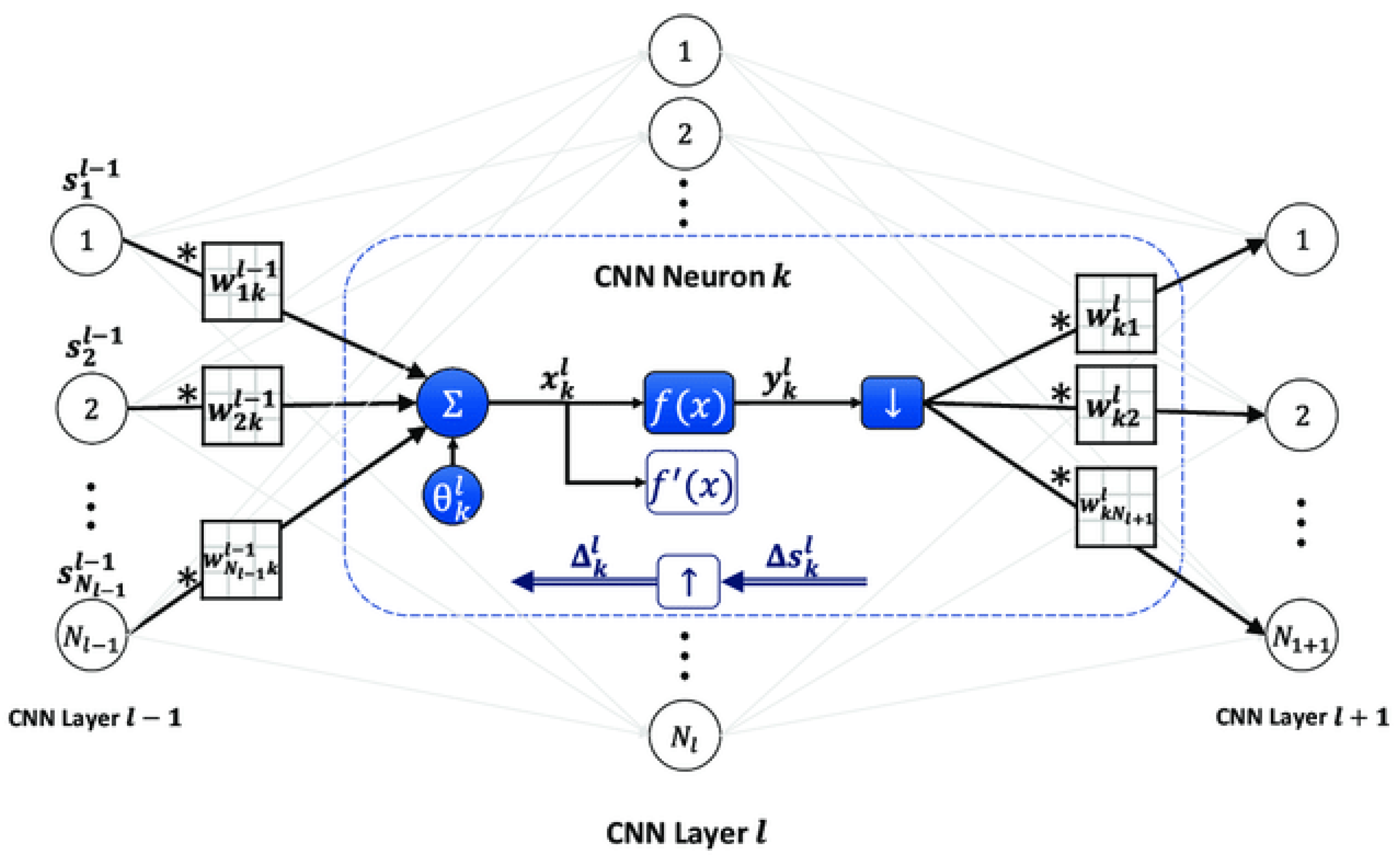
Convolution layer: Although some complexities like time and space complexity are associated with the size of the input image (or feature maps), the number of convolutional layers, and the size of the filters with image processing, CNNs can also be effectively trained for text analysis. Additionally, CNNs are highly efficient for processing grid-like data such as images (see
Figure 3).
In this context, CNNs are crucial in localizing receptive model captures of particular segments and global feelings, aided by max-pooling layers to preserve excessive feature loss. This approach benefits Canadian marine case law, providing a more accessible understanding of rulings and accommodating diverse perspectives. “LeNet” and “AlexNet,” two prominent CNNs, share linear neuron model principles. CNNs, unlike traditional MLPs, incorporate weight sharing and restricted connection in convolutional layers. Conv1D
The 1D forward propagation (1D-FP) expressions in each CNN layer are as follows:
presents the input, whereas
denotes the bias of the
kth neuron in layer l. Similarly,
illustrates the output of the ith neuron at layer l-1, and
exhibits the kernel from the ith neuron at layer l-1 to the kth neuron at layer l.
With
l = 1 as the input and l as the output, the back-propagation procedure begins at the MLP layer. There are N
L distinct types of data in the repository. In the output layer, we represent the mean squared error (
MSE) between an input vector
p and its target and output vectors,
and [
], as
’s derivative by each network parameter may be calculated using the delta error, k l = E × k l. To be more precise, the chain rule of derivatives may be used to update not just the bias of the current neuron but also the weights of all of the neurons in the layer above.
CNNs with several layers use both back-propagation and forward propagation (see
Figure 4).
Through forward and reverse propagation, the last hidden CNN layer is linked to the first hidden MLP layer (see
Figure 5)
- (1)
Initialize weights and biases (e.g., randomly, ~U(−0.1, 0.1)) of the network.
- (2)
For each BP iteration, DO:
FP: A layer’s neuron outputs may be found by forward propagation from the input layer to the output layer.
BP: Compute delta error at the output layer and back-propagate it to first hidden layer to compute the delta errors.
PP: Postprocess to compute the weight and bias.
Update: Update the weights and biases by the (accumulation of) sensitivities scaled with the learning factor.
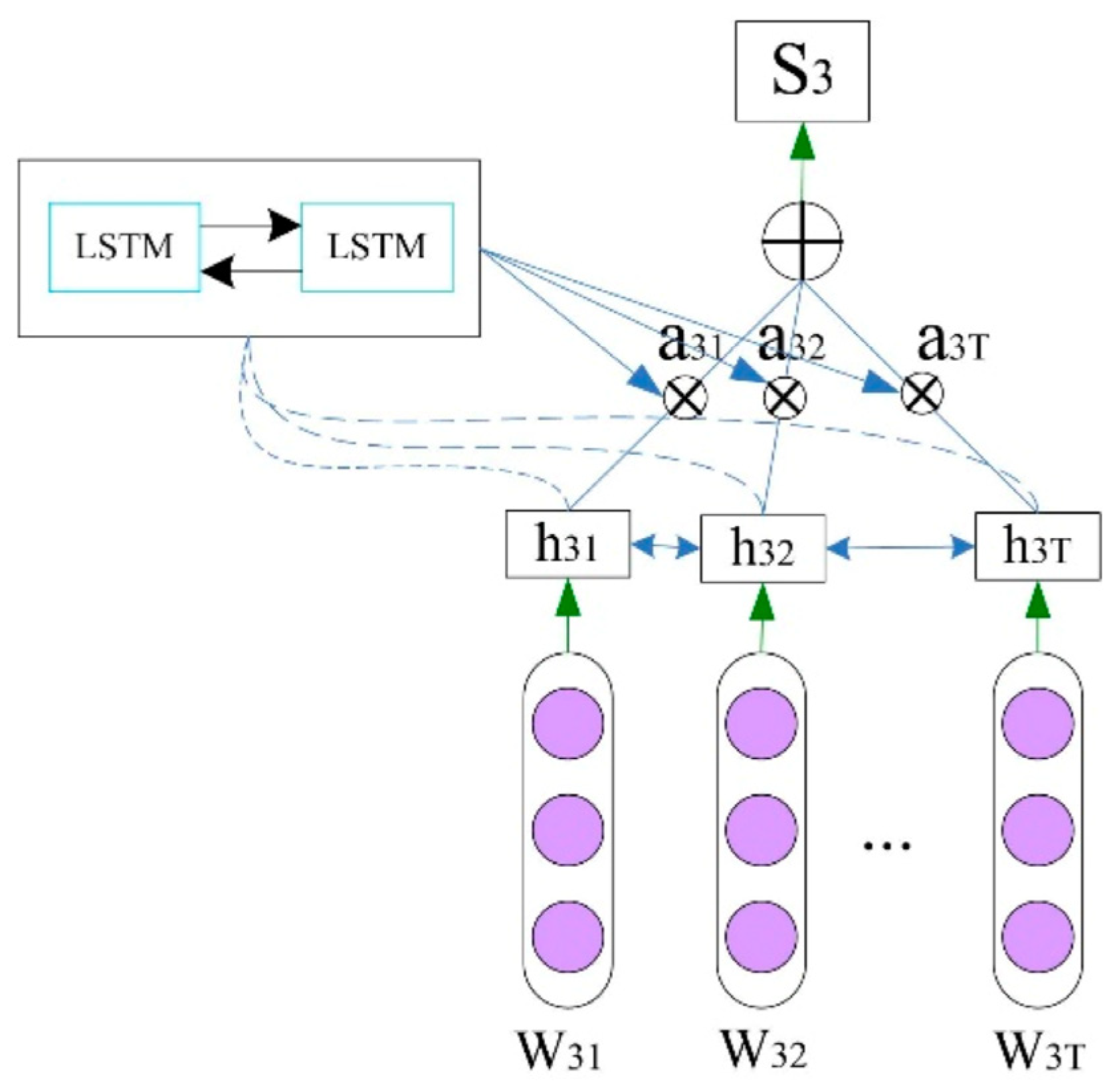
LSTM layer: Though there are circumstances in which problems with the sequence length (T), hidden state size (h), and number of LSTM layers occur, due to their better sequential data modeling skills, LSTMs are excellent at capturing the natural flow and context of text. However, LSTMs are crucial for extracting word and sentence dependencies in document-level sentiment analysis, allowing them to capture evolving attitudes throughout lengthy texts. Their ability to selectively retain and forget information over extended sequences ensures consistent and nuanced sentiment analysis, making LSTMs indispensable in natural language processing.
Gates:
LSTMs use three types of gates: (i) the forget gate (f), (ii) the input gate and (iii) the output gate (o).
These gates control the flow of information into and out of the cell state
a. Cell State
The cell state represents the memory of the LSTM. It can be updated and modified using the gates.
The cell state is updated using the forget gate, input gate, and a new candidate cell state .
b. Hidden State :
The hidden state carries information about the current time step’s input and the previous hidden state.
It is used to make predictions and updated using the output gate.
Here, σ represents the sigmoid activation function.
c. Input Gate
d. Candidate Cell State
e. Update Cell State
This equation combines the old and new candidate cells based on forgetting and input gates.
f. Output Gate
g. Hidden State
The output gate controls the information that is passed to the hidden state. However, here, represents the input at time step t; represents the hidden state at time step t − 1. Similarly, , and represent the weight matrices for the gates andbBias vectors for the gates, respectively. On the other hand, stands for the sigmoid activation function, whereas presents the hyperbolic tangent activation functions.
Activation layer: In the context of sentiment analysis applied to Canadian marine case law texts using CNN + LSTM architecture, the activation layer, also known as the activation function, is a pivotal element. Adding this nonlinear layer greatly enhances the model’s ability to capture complicated connections and produce precise predictions. By introducing nonlinearity, the model becomes adept at discerning complex patterns, enabling more accurate predictions and nuanced insights into sentiment from the nuanced language of legal documents. One of the most important parts of deep learning models is the activation layer, which helps to interpret complex legal documents’ sentiment patterns and other nuanced emotional expressions in the data they include. This essential layer is the linchpin for capturing and learning from recurring structures, decision making, and controlling gradient flow within the model. Despite its undeniable significance, the activation layer is not without challenges, with the specter of saturation looming as a potential impediment to the deep learning model’s learning speed and overall effectiveness. Nevertheless, its indispensability remains unassailable, as the success of deep learning models in the nuanced domain of sentiment analysis within legal texts is intricately tied to the adept functioning of the activation layer, as underscored by empirical evidence [
27].
Regularization: Combining deep learning methods, like CNN with LSTM models for sentiment analysis in Canadian marine case law, heavily employs regularization techniques to counteract overfitting. The complexity of legal language patterns makes accurate representation critical. An issue is overfitting, which occurs when a model performs exceptionally well on training data but poorly on new data. Regularization plays a crucial role in sentiment analysis to ensure that the model can handle the vast range of legal text patterns and the intricacies of the training data
5.1. Detailed Model Architecture and Training Procedure
Model Architecture and Hyperparameters
Our convolutional neural network (CNN)–long short-term memory (LSTM) architecture was meticulously designed to harness the strengths of both models for the sentiment analysis of Canadian maritime case law documents. The CNN component focuses on extracting salient features from textual data. At the same time, the LSTM part captures temporal dependencies, making the model particularly adept at understanding the context and sequence within a text.
CNN architecture: The CNN part of our model consists of two convolutional layers. The first layer has 32 filters with a kernel size of 3 × 3, followed by a max-pooling layer with a pool size 2 × 2 to reduce dimensionality and capture the most relevant features. The second convolutional layer increases the depth with 64 filters, enhancing the model’s ability to recognize more complex patterns in the data. Each convolutional layer is followed by a ReLU activation function to introduce nonlinearity.
LSTM architecture: Following the CNN layers, we integrated a bidirectional LSTM (BiLSTM) layer with 100 units to process the sequence data forward and backward, thus capturing context from both directions. This bidirectionality is crucial for understanding the nuanced legal language present in maritime case law documents.
Combination and output: The output from the CNN layers is flattened and then passed to the BiLSTM layer. The final output layer employs a softmax activation function to classify the sentiment into categories, reflecting the multiclass nature of our sentiment analysis task.
5.2. Document Representation
Training Procedure
Loss Function: Given the multiclass classification problem, we employed the categorical cross-entropy loss function. This choice was made because it effectively measures the discrepancy between the predicted sentiment distribution and the actual distribution in the training data.
Optimizer algorithm: We opted for the Adam optimizer for its adaptive learning rate capabilities, setting an initial learning rate of 0.001. Adam combines the benefits of two other extensions of stochastic gradient descent, adaptive gradient algorithm (AdaGrad) and root mean square propagation (RMSProp), making it well suited for our complex model architecture.
Training process: The dataset was meticulously divided into training (70%) and test (30%) sets, ensuring a balanced distribution of sentiments across both partitions. Our model underwent training for 50 epochs utilizing a batch size of 64, and early stopping with a patience of 5 epochs on validation loss was implemented to mitigate overfitting. Throughout the training process, model performance was consistently assessed using accuracy and loss metrics on both the training and validation datasets. The final model was chosen based on achieving the highest validation accuracy, ensuring robust performance across diverse sentiment representations.
Hyperparameter tuning: Preliminary experiments were conducted to determine the optimal architecture and training configurations. We experimented with different numbers of CNN and LSTM layers, kernel sizes, and filter counts, ultimately selecting the configuration that maximized validation accuracy while minimizing overfitting.
6. Experimental Results
6.1. Dataset
Legal documents in Canada are organized into several types, with maritime law legislation being just one example. Many techniques are employed for data classification, including text mining, document clustering, and machine learning algorithms. CNN is one of the models that is often used in the document classification process. The main tools were used to predict a judge or jury’s decisions and examine previous cases and decisions. However, in some instances, machine learning algorithms can make it easier to consider releasing a suspect on bail. This study examined two thousand cases from the Federal High Court’s website to find patterns in Canadian maritime law (see
Table 2). The final decision rendered in the case was categorized as either affirmed or reversed. An affirmed judgment indicates that the higher court upheld the lower court’s decision, while a reversed judgment signifies that the decision was overturned. The datasets were divided into training and test sets to evaluate the model’s performance on unseen data. Additionally, the data were collected manually, without using anonymization, from both the plaintiffs and defendants.
To enhance sentiment analysis within maritime law, this research strategically used the filter tool available on the Federal High Court website. This tool facilitated the identification of pertinent legislation and precedents from court rulings. However, by analyzing the most-used words and key phrases in the input text, outputs were generated that maintained relevance to the legal context while ensuring coherence and accuracy. Additionally, considering the input text’s length and structure, the generated outputs were tailored to meet the specific requirements of legal professionals, judges, and other stakeholders within the Canadian maritime law domain. A meticulous augmentation process was undertaken to bolster the sentiment analysis model, generating an additional 98,000 new samples through a random sample technique. This method deliberately addressed demographic disparities, ensuring a more even distribution of examples across emotion categories. The resultant effect was a marked improvement in the model’s precision and consistency. Notably, the model’s accuracy in categorizing emotions was fortified by incorporating Canadian marine case law. After collecting data and training completion, the model’s prediction was evaluated using a held-out test set. Specificity, representing the actual negative rate, is calculated by dividing the number of correctly identified negative sentiments by the total number of negative sentiments.
In contrast, sensitivity, representing the true positive rate, is calculated by dividing the number of correctly identified positive sentiments by the total number of actual positive sentiments. These metrics provide insights into how well the model could distinguish between positive and negative sentiments. Data augmentation and postprocessing methods were also used to balance representation across different groups and adjust the model’s performance. This deliberate and rigorous approach to data augmentation contributed significantly to the overall trustworthiness and precision of the sentiment analysis methodology employed in this study [
28].
6.2. Results
This study on case adjudication in Canadian maritime law revealed intriguing insights into the outcomes of trials based on the number of judges involved. When a case was assigned to a single judge, guilty judgment stood at 46%, while the likelihood of a not guilty result was approximately 51%. Strikingly, this indicated a remarkably even distribution of judgments, with approximately 3% of cases remaining undecided. Surprisingly, the incidence of indecisive verdicts did not significantly change when three judges were involved, as it increased marginally to 5%. These findings suggest that additional judges in the trial process did not substantially alter the proportion of undecided cases, highlighting a noteworthy consistency in judgment outcomes across varying judicial scenarios in the realm of Canadian maritime law. Surprisingly, the incidence of indecisive verdicts did not significantly shift when there were three judges.
Accuracy is the rate at which a model makes accurate predictions.
In Canadian maritime law, a significant shift occurred in citation practices, revealing 41% of citations in single-judge trials and 46% in multijudge cases. This evolving trend underscores the dynamic nature of the legal landscape. We employed advanced techniques for sentiment analysis of Canadian marine case law papers, including deep learning and traditional machine learning models. This analytical approach extends beyond statistics, offering valuable insights for informed decision making in judge selection and jury verdicts [
29]. Integrating technology into legal scholarship reflects a proactive response to contemporary challenges, enhancing the adaptability of legal practices.
Figure 6 is a comprehensive visual representation of a bar chart, elucidating the distribution of judgments and statuses throughout the dataset. Each bar’s height succinctly encapsulates the number of instances within its corresponding category, offering a clear and insightful overview of the dataset’s composition. This visualization lays a robust foundation for forthcoming legal sentiment analysis studies and provides vital insights into the dataset’s composition, knowing the predominance of judgments in Canadian marine case law [
30].
In the initial stages of model assessment (see
Figure 7a,b), the dataset was carefully split into training and test sets, with nonpredictive columns removed from the feature matrix X. The target variable y was appropriately labeled “target” for the subsequent binary classification task. To ensure repeatability, 30 percent of the dataset was reserved for thorough examination. Preceding sentiment analysis, the ‘Opinion’ text input underwent tokenization to achieve consistent sequence lengths in the CNN with LSTM model. The largest sequence in the dataset (max_len) was found, and the vocabulary size, which included all unique words in the ‘Opinion’ text data, was computed. These preprocessing steps were vital for the success of sentiment analysis performed on Canadian marine case law materials that required this preliminary processing [
30].
6.3. Comparison
This section compares CNN, LSTM, BiLSTM, and CNN-LSTM to the CNN-BiLSTM model.
This study examined the sentiment analysis of Canadian maritime case law using two machine learning models: deep learning (CNN + LSTM) and more traditional methods (logistic regression, multinomial naïve Bayes, linear support vector machine). This study’s success is credited with employing CNN and LSTM models to collect sentiment information from judicial documents. Gamage, et al. [
31] used different machine learning models for maritime surveillance to detect abnormal maritime vessels and reported 91% accuracy for the CNN model. Syed and Ahmed [
32] conducted research employing CNN, LSTM, BiLSTM, and CNN-LSTM models on marine surveillance, distinguishing between normal and abnormal vessel movement patterns and claimed CNN-LSTM exhibited the most accurate result (89%).
6.3.1. CNN Model
The ability of CNN models to extract local patterns and features from text input makes them particularly well suited to tasks that require recognizing nearby signals or characteristics. They can spot terms, phrases, or clauses in legal papers that convey emotion. CNNs provide computational efficiency during training because of their ability to learn local patterns quickly through utilizing shared weights across several input areas. The training time is drastically reduced, making them particularly suitable for big legal text datasets. In this case, CNNs are powerful feature extractors that can glean important information from texts, including patterns, structures, or even individual words. The local environment brief pieces of text are quickly captured by them, and they excel at identifying patterns within such sections. The effectiveness of a CNN model in detecting emotions in Canadian maritime case law papers was demonstrated by its 98% accuracy rate on the tests [
33].
6.3.2. LSTM Models
Long short-term memory (LSTM) models excel in understanding the context and sequence of words in text data, making them excellent for jobs requiring such an understanding. A thorough comprehension of the complex textual environment is essential in legal sentiment analysis. LSTMs are well suited to the level of detail needed to comprehend the nuanced sentiment patterns and intricate interconnections common in legal writings. LSTM models are more complex and have a more significant number of parameters than CNN models. However, they still achieved high accuracy rates, reflecting how well they red sentiment dynamics in Canadian maritime case law.
6.3.3. CNN-LSTM Model
This study assessed the efficacy of CNN and LSTM models over 50 training epochs using visual representations of loss and accuracy measurements. While the accuracy graph illustrates how well the model can classify data, the loss graph shows how well it can reduce inaccurate predictions. In addition, the loss graph reflects the model’s skill in minimizing prediction mistakes, whereas the accuracy graph depicts its skill in accurately incorporating labels into opinions. By making it more straightforward to visualize how the model evolved during training to integrate documents from Canada’s marine case law, the SE visuals add to the broader discussion on sentiment analysis in the law [
34].
For each CNN + LSTM model, we display loss and accuracy graphs across 50 iterations during training.
In a groundbreaking study of Canada’s maritime sector, convolutional neural network (CNN) and long short-term memory (LSTM) models were employed to analyze case law and identify patterns of emotion. The impressive successes in emotion categorization, as depicted in
Table 3, underscore the complexity of emotion in this intricate area of law. This research also showcases the effectiveness of advanced machine learning in navigating the challenging landscape of maritime law, where understanding and addressing emotions add a layer of complexity for legal professionals.
CNN and LSTM Model 1 achieved an impressive 98.01% test accuracy rate (see
Figure 8a), showcasing its dominance in sentiment categorization and understanding of the intricacies of Canadian maritime case law texts. On the other hand, Model 2 (see
Figure 8b), a descendant of Model 1, highlighted the robustness of the CNN + LSTM architecture with a test accuracy of 97.94%, proving its efficacy in extracting sentiment information from dense legal texts.
Similarly, Model 3 (see
Figure 8c) achieved a test accuracy rate of 98.05%, and the third model earned a test accuracy rate of 98.05%, demonstrating the approach’s resilience in predicting sentiment dynamics within Canadian maritime case law despite the continuously high accuracy rates of CNN and LSTM models.
This research illustrates the effectiveness of CNN + LSTM models in analyzing legal sentiment analysis. It demonstrates how these models can more accurately detect sentiment patterns in Canadian maritime case law papers and successfully grasp the nuances of legal language. Legal analytics, policymaking, and the creation of AI-powered legal tools all stand to benefit significantly from this breakthrough [
35]. Feizollah, et al. [
36] utilized CNN and LSTM algorithms to extract Twitter text and claimed 93.78% accuracy.
The sentiment analysis of Canadian maritime case law was conducted using multiple machine learning methods. With an average accuracy of 0.9805, CNN + LSTM models exhibited excellent precision in interpreting the nuances of legal documents (see
Figure 9). Logistic regression, multinomial naïve Bayes, and linear support vector machine (SVM) are classic models that have significantly contributed to our knowledge of sentiment analysis by emphasizing the trade-offs between complexity, interpretability, and performance.
Multinomial naïve Bayes is practical with text data, whereas logistic regression sheds light on the effect of model complexity. In linear SVM, the emphasis is on parameterization and dataset dimensionality. These additional data will help us select more suitable policymaking and legal analytics models. With this new information, we can better choose appropriate models for legal analytics and policy development [
37].
6.3.4. Precision and Recall Metrics
Upon re-examining our CNN-LSTM model’s performance on the sentiment analysis of Canadian maritime case law documents, we present additional evaluation metrics—precision and recall. These metrics are particularly informative for understanding the model’s performance across different sentiment classes, providing insights into its ability to minimize false positives (precision) and false negatives (recall).
Precision measures the model’s accuracy in predicting a specific sentiment class, calculated as the number of true positive predictions divided by the total number of positive predictions (true positives + false positives). On the other hand, recall measures the model’s ability to detect all relevant instances of a sentiment class, calculated as the number of true positive predictions divided by the total number of actual positives (true positives + false negatives).
Including these metrics addresses a critical aspect of model evaluation, especially in legal sentiment analysis, where the cost of misclassification can significantly impact the interpretation of legal documents and the subsequent legal analytics and policymaking processes.
The following table (
Table 4) summarizes the precision and recall metrics for our CNN-LSTM model across the identified sentiment categories:
These results demonstrate the model’s strong performance in accurately classifying sentiments (as previously evidenced by the accuracy metrics) and its precision and recall across different sentiment categories. The high precision indicates a low rate of false positives, while the high recall reflects the model’s effectiveness in identifying all relevant instances of each sentiment class.
By incorporating precision and recall metrics into our evaluation, we offer a more detailed and nuanced understanding of our CNN-LSTM model’s performance in Canadian maritime case law sentiment analysis. This comprehensive evaluation underscores the model’s efficacy and reliability, reinforcing its potential utility in legal analytics and policy formulation. We believe these additional metrics address the previous omission and enhance the manuscript’s contribution to the field.
6.4. Discussion
The CNN-BiLSTM with Doc2vec, a pretrained sentence/paragraph representation model, stood out when we compared its performance to that of other deep learning models.
Doc2Vec word embedding models’ accuracy ratings when using several neural network topologies, including convolutional neural networks (CNNs), long short-term memory (LSTM) networks, back-propagation neural networks (CNN-LSTMs), and convolutional neural networks (CNN-BiLSTMs), are offered. Document classification using Doc2Vec receives = d 90% on CNN, 88% on LSTM, 86.40% on BiLSTM, 91% on CNN-LSTM, and 93% on CNN-BiLSTM. Higher accuracy levels imply superior performance in sentiment analysis and text categorization [
38].
This research explored the integration of deep learning, specifically convolutional neural network (CNN) and long short-term memory (LSTM) models, for analyzing public opinion on maritime law in Canada. With a precision rate of 98%, this research highlights the revolutionary influence of artificial intelligence in the legal domain, stressing the mechanization of processes, interpretation of lengthy legal documents, and enhanced judgment.
The findings highlight both the benefits and drawbacks of these technologies, offering crucial insights for future applications. Significantly, sentiment analysis emerges as a valuable tool in various legal activities, including researching the law, investigating potential outcomes, preparing for court, interpreting precedent, and developing policies [
39]. This research is a foundational step toward enhanced AI integration in legal practices, paving the way for further exploration and refinement in maritime law and beyond.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}