Building a Taiwan Law Ontology Based on Automatic Legal Definition Extraction


Abstract
:1. Introduction
- We design an efficient approach to structuring law information and extracting legal keywords and their relative definitions automatically using data mining and automatic methods.
- A user-friendly, graphical user interface (GUI) that adopts our proposed approach is implemented to allow users to access legal keywords effectively.
- We consider the related attributes and relationships among keywords to retrieve not only the legal terms, but also the relevant definitions by integrating the patterns discovered by law experts into our extraction process.
- The proposed method aims to enhance the usage of legal knowledge by using ontology technology. In the evaluation section, we show that our approach compared with the conventional methods which only provide keyword searching in statutes is able to provide in-depth legal term retrievals.
2. Related Work
2.1. Chinese Word Segmentation
2.2. Chinese Word Segmentation
2.3. Ontology
2.3.1. The Definition of Ontology
- Classes, also called sets, collections, or concepts, are the core component of an ontology. Classes present the concepts in the field.
- Attributes, also called aspects, properties, features, characteristics, or parameters, actually act as conceptual components of class.
- Individuals are also called instances or objects. An individual is a thing or entity in reality.
- Relations are used by classes or individuals to relate to one another.
2.3.2. The Ontology Construction Methods
2.3.3. Ontology Language and Ontology Editor
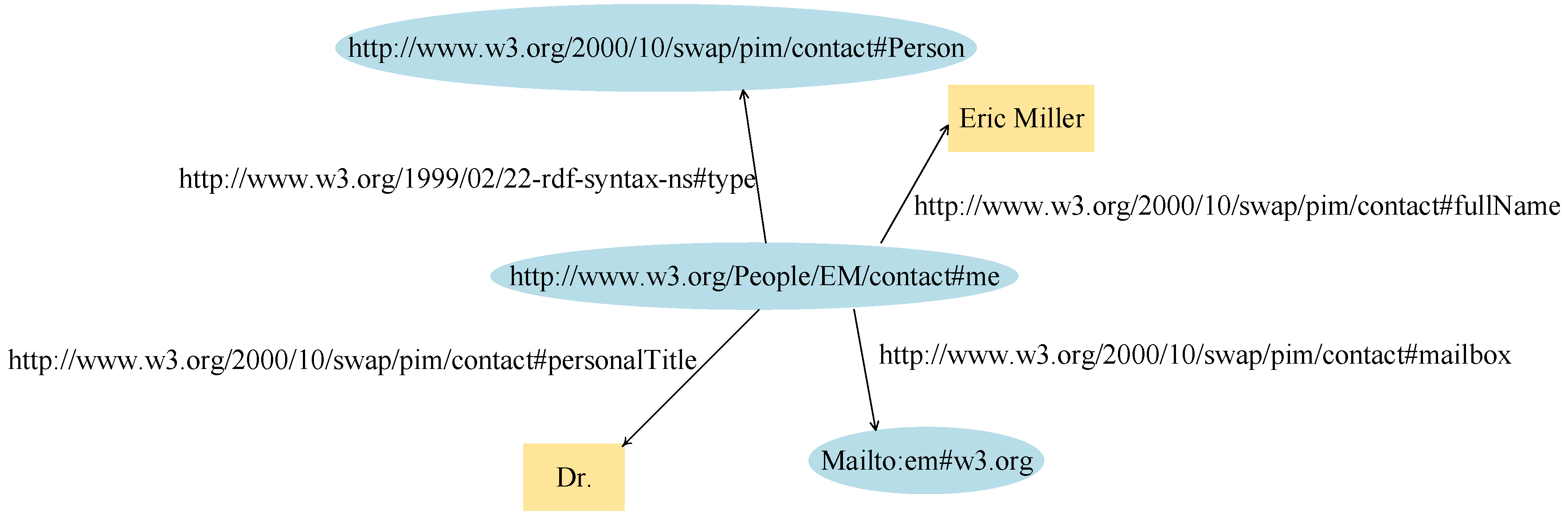
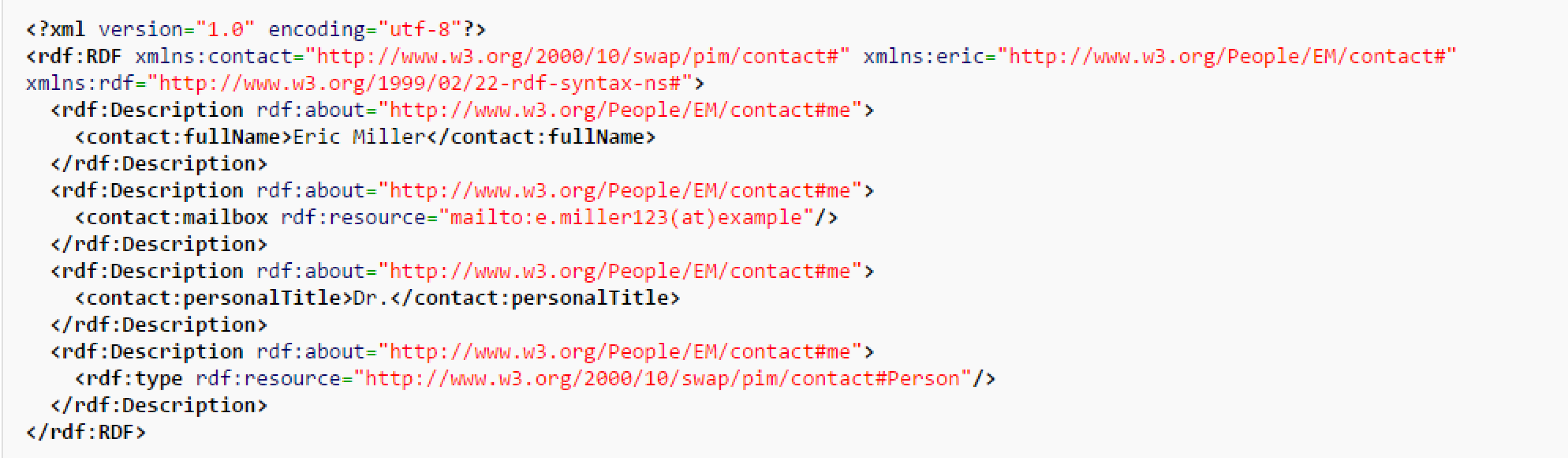
- "Eric Miller" (with a predicate "whose name is").
- "mailto:e.miller123@example" (with a predicate "whose email address is").
- "Dr." (with a predicate "whose title is").
3. System Architecture
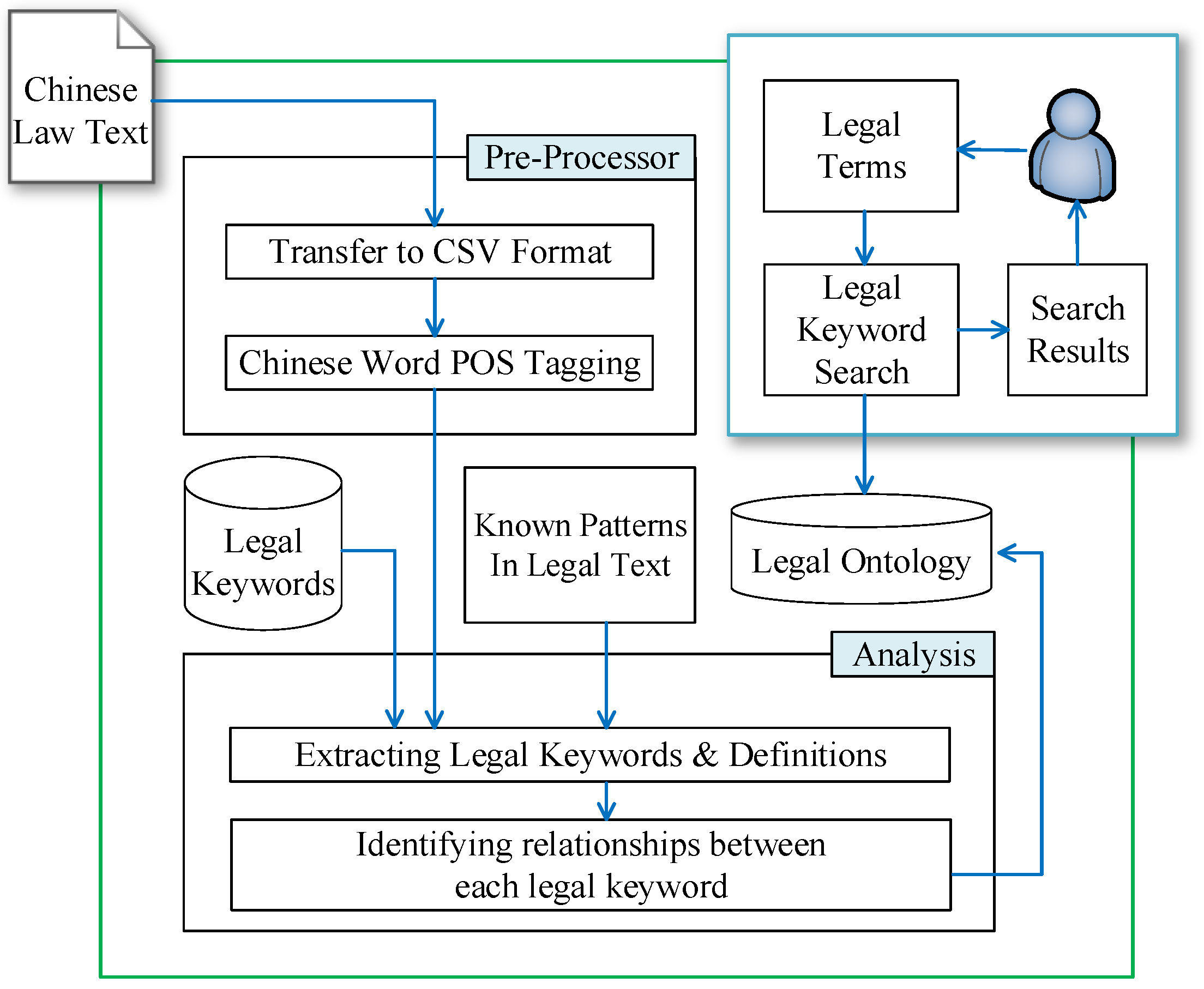
3.1. System Overview
3.2. The Pre-Processing of the Data
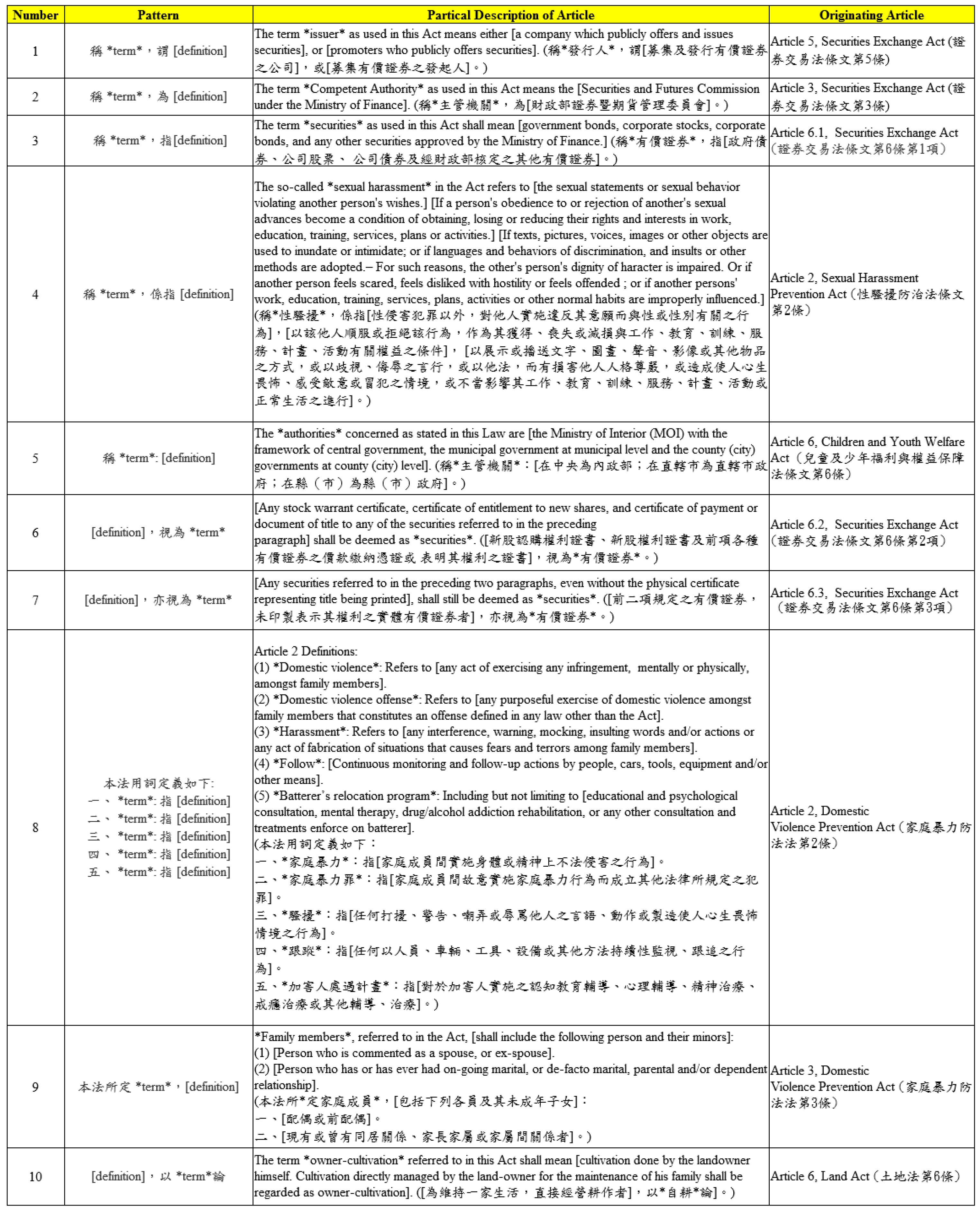
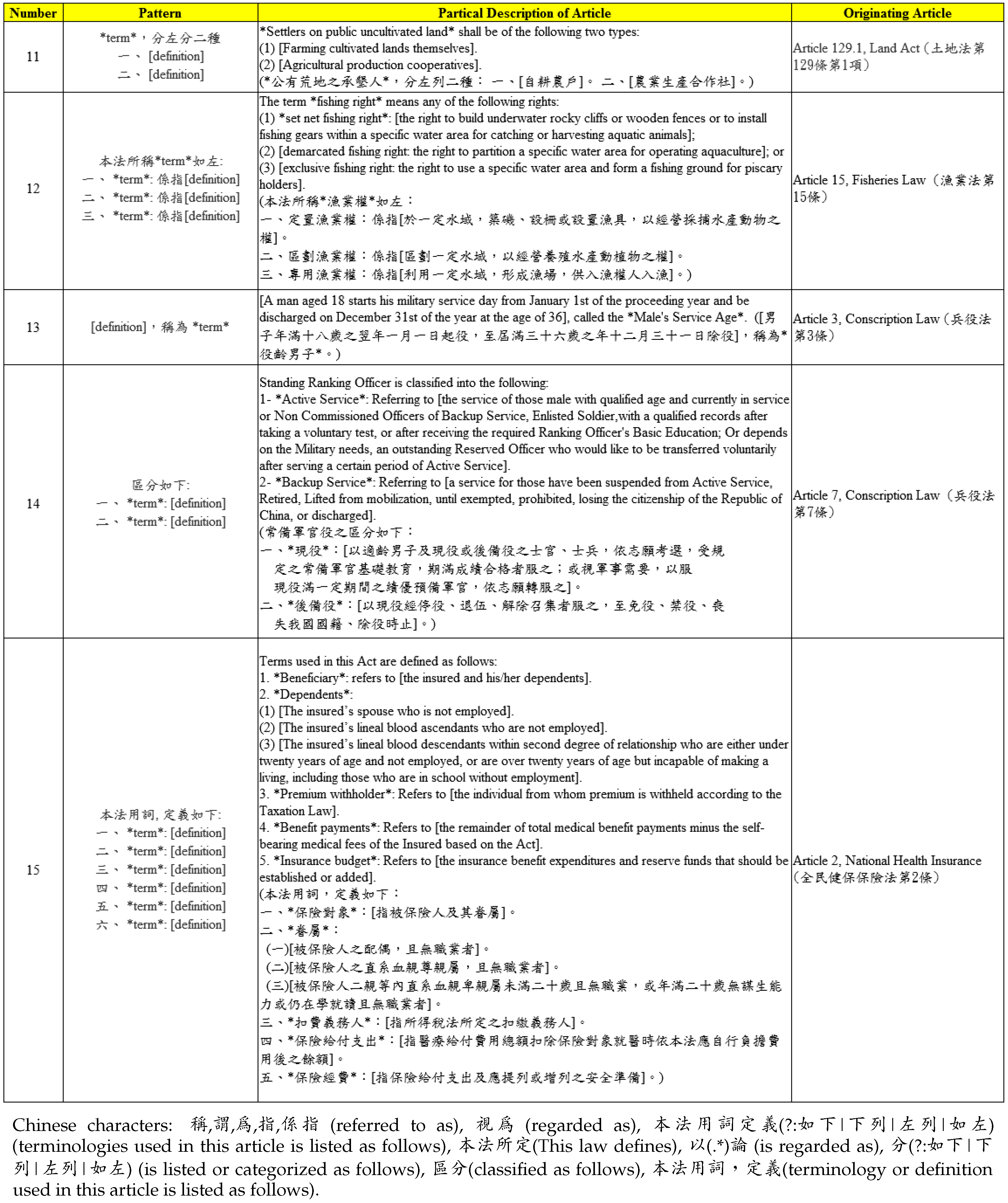
3.3. Patterns of Legal Definitions
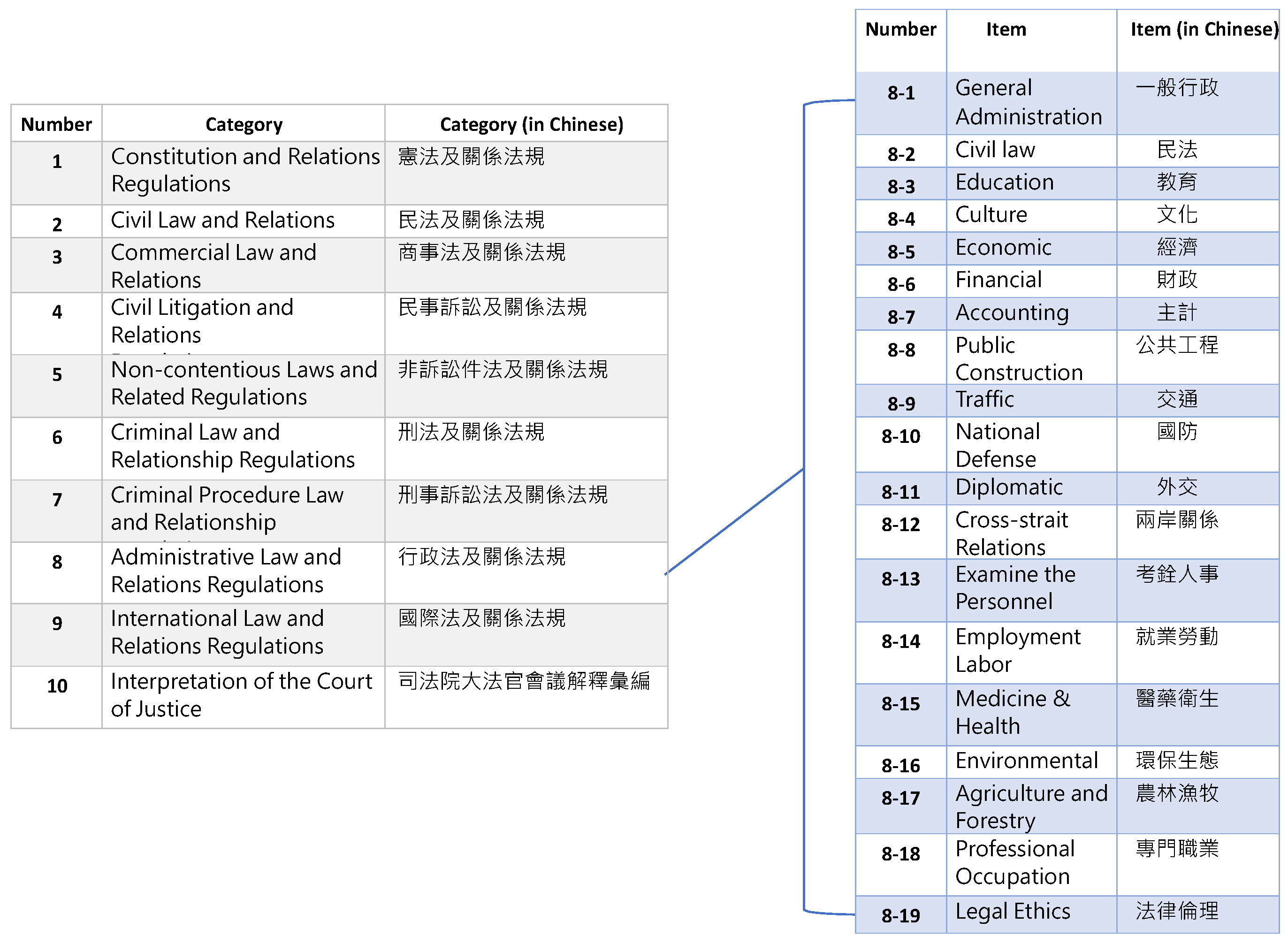
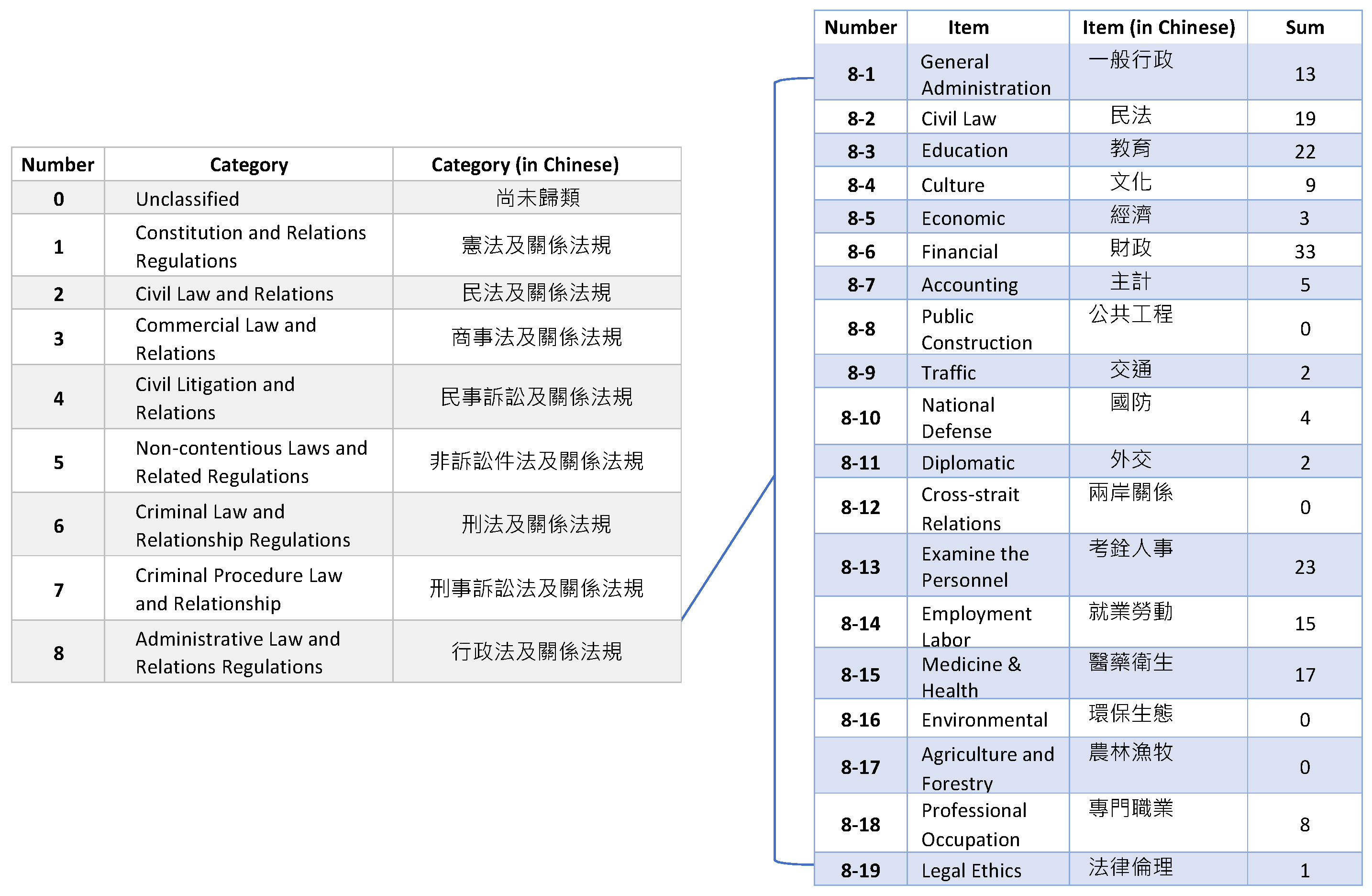
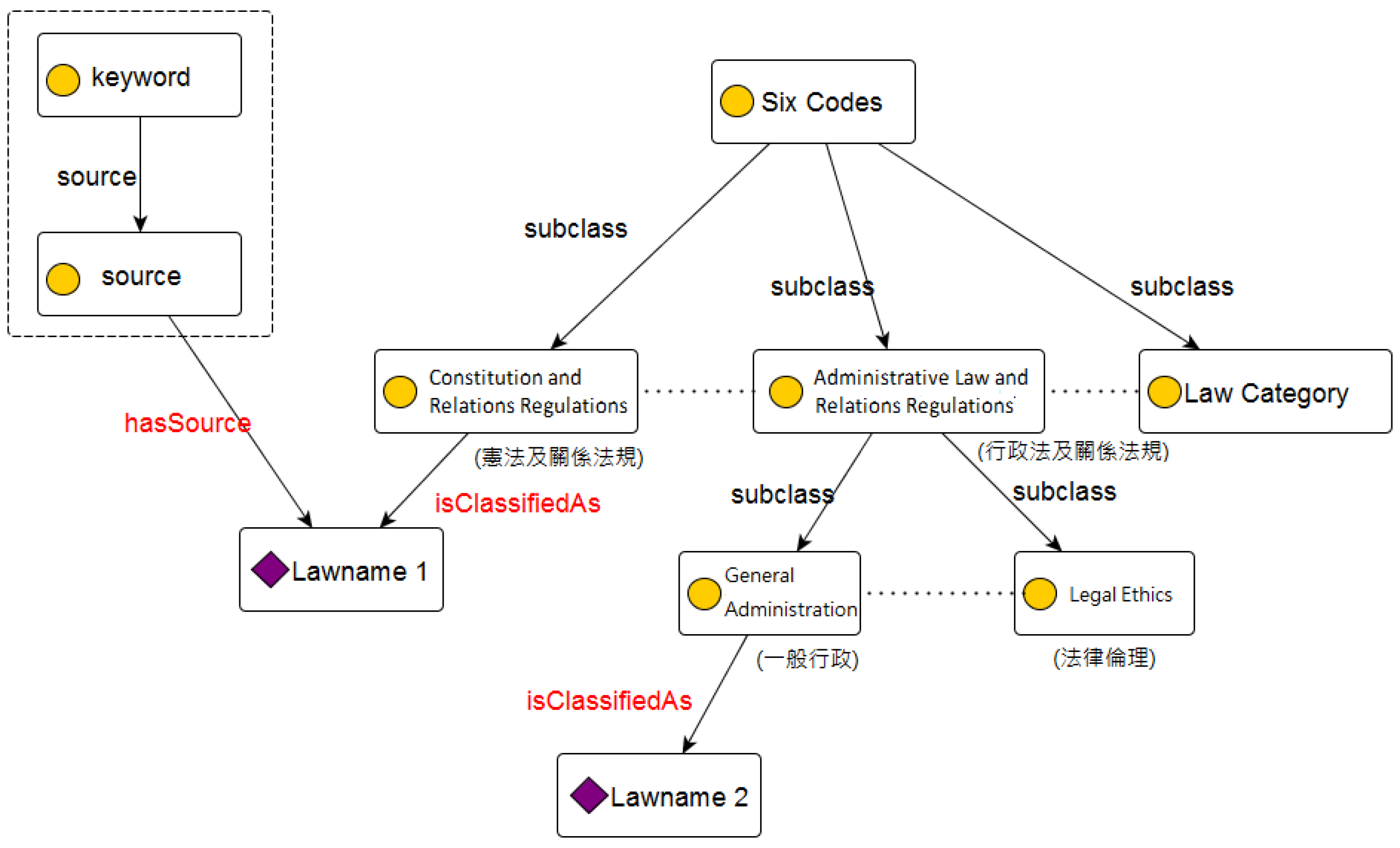
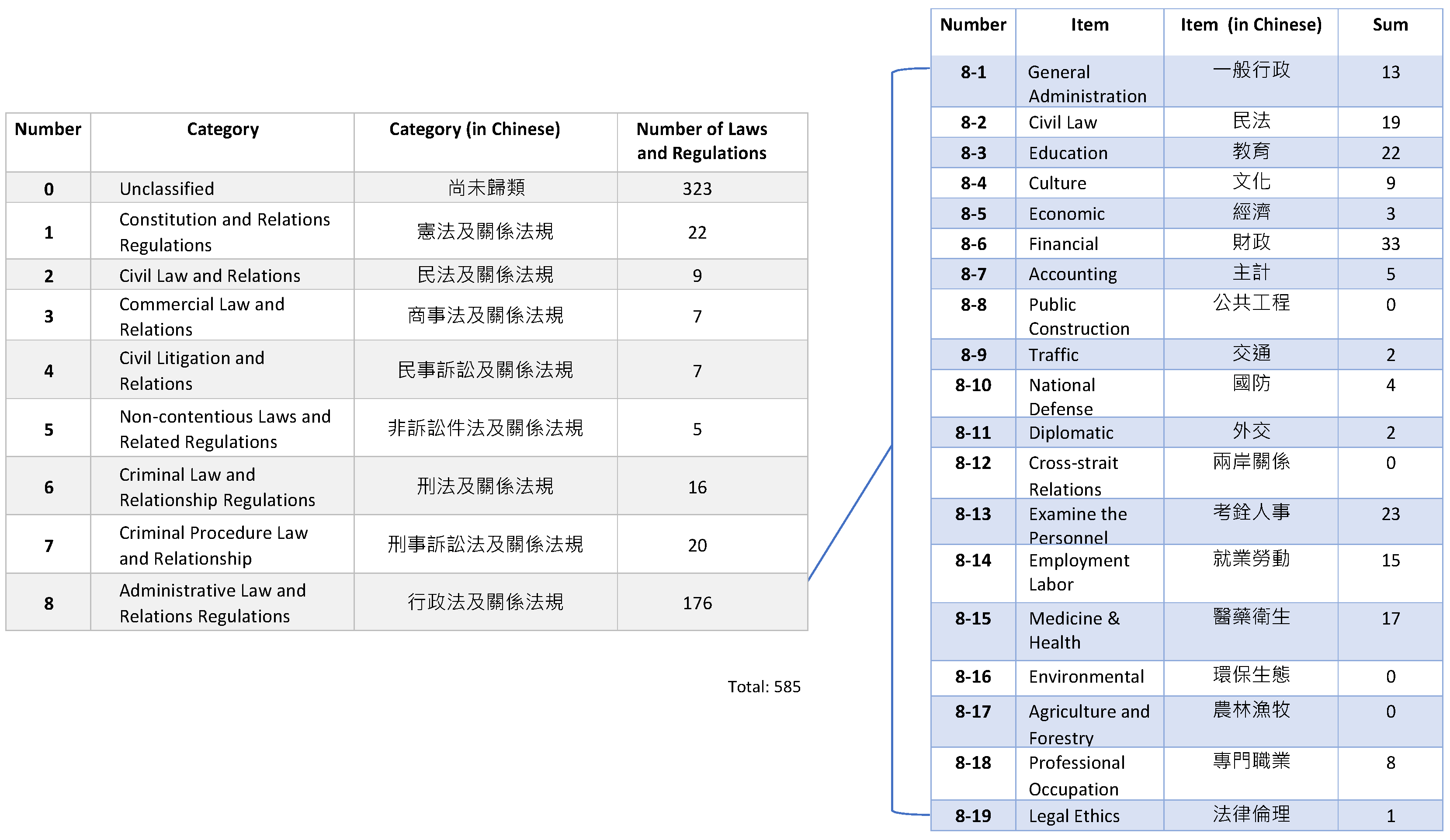
3.4. The Taiwan Six Codes Structure
- Remove category 9 and category 10 which are unsuitable for our classification structure.
- Add category 0 to collect those laws and regulations that cannot be classified into any other category. For example, The Indigenous People’s Basic Law (原住民基本法) cannot to be classified into any of the existing categories, so it can be categorized into category 0.
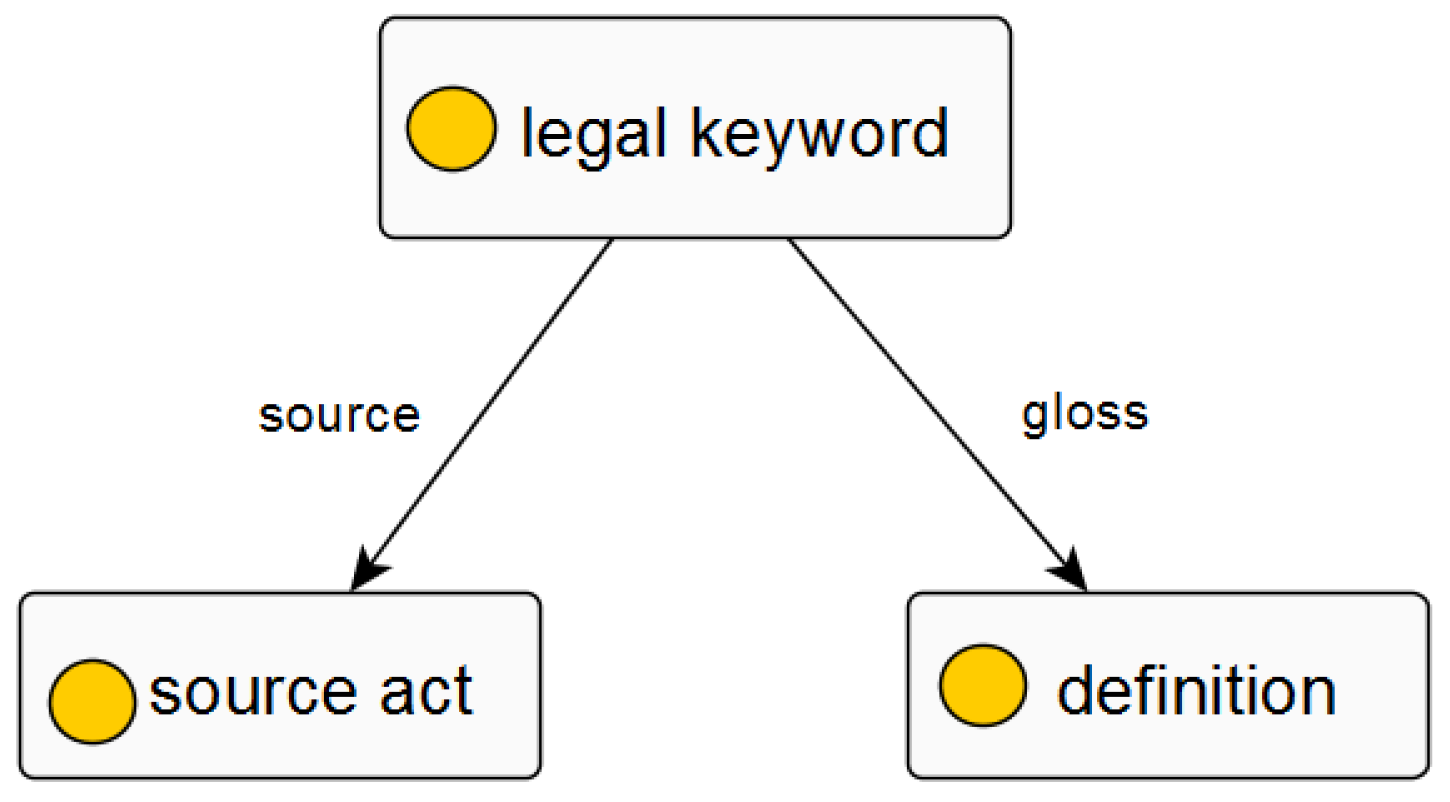
3.5. Ontology Data Model
4. Approach Implementation and Evaluation
4.1. Extracting Legal Keywords and Definitions
4.2. Law Ontology Construction and Storage
4.3. The Web-Based Service
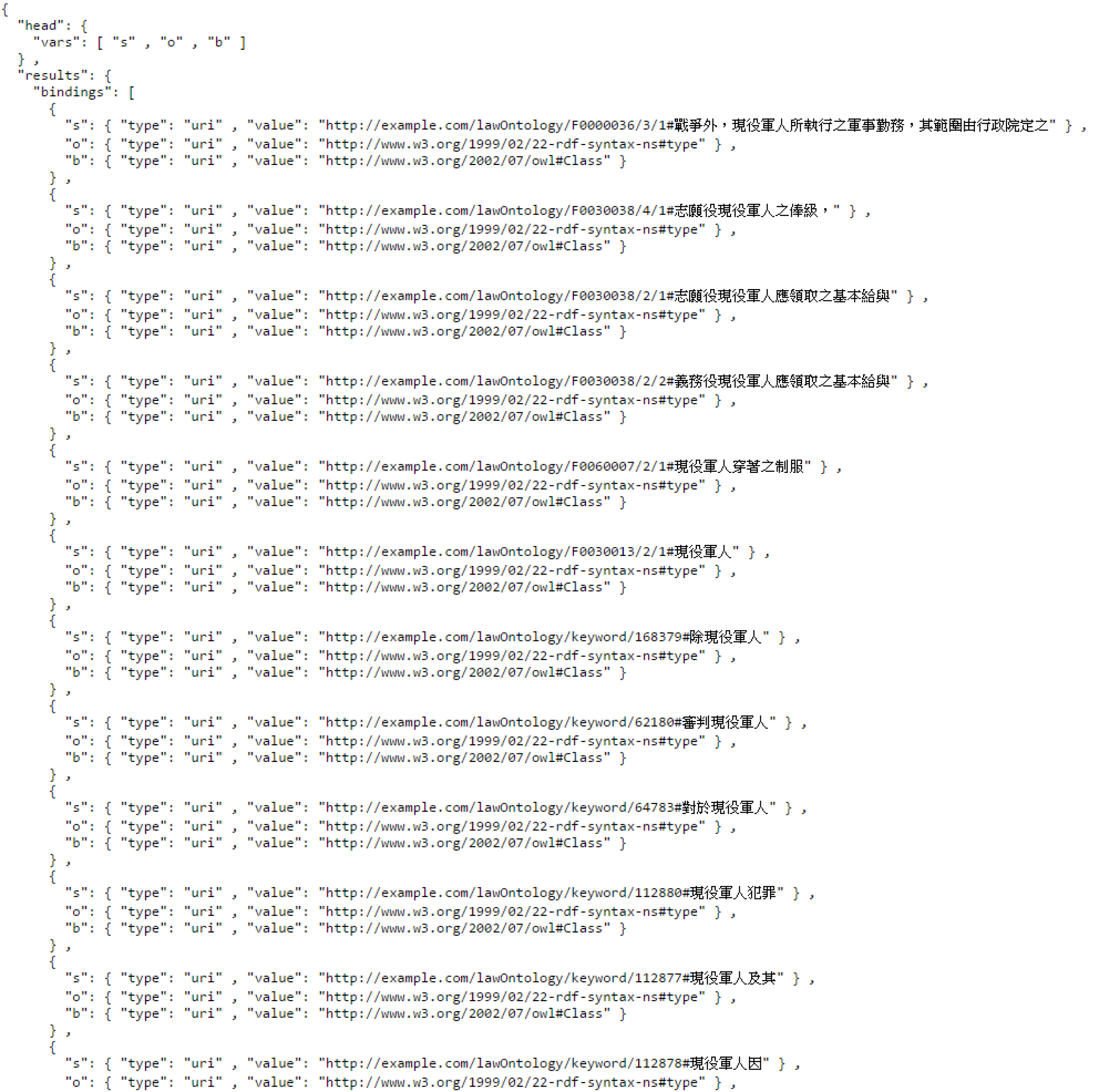
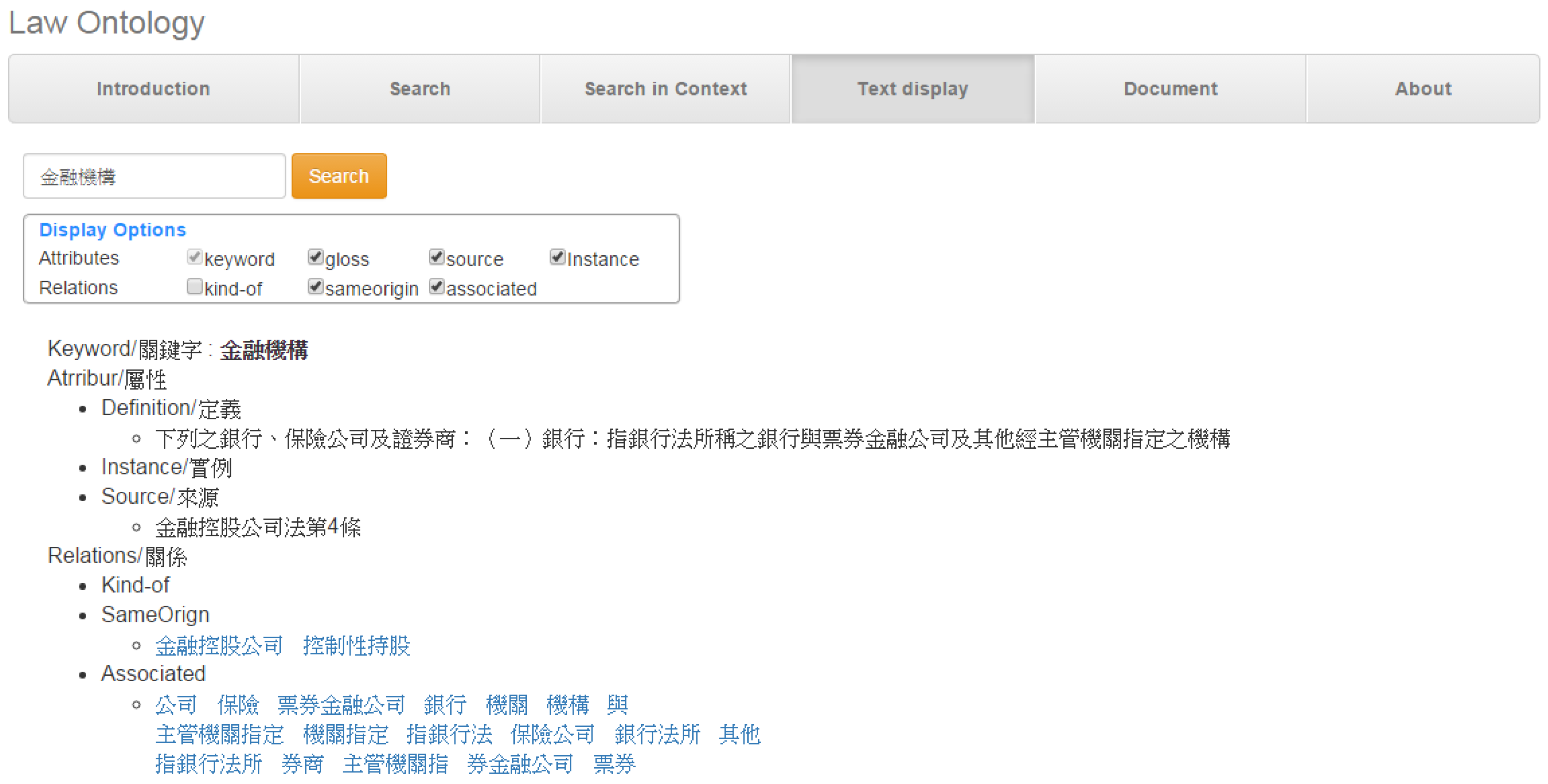
4.3.1. Query Processing Engine
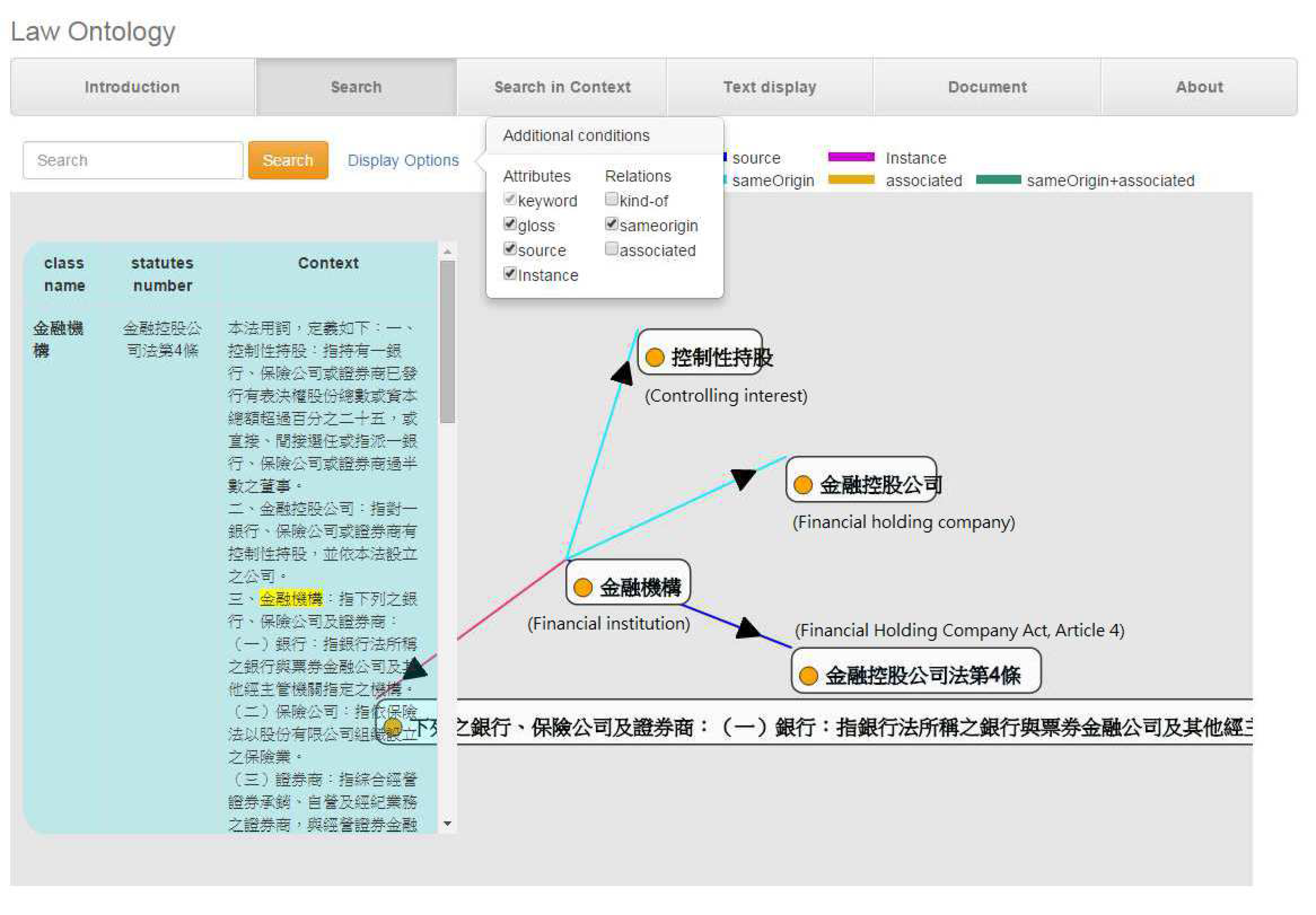
4.3.2. The Graphical Interface
4.3.3. The Text Interface
4.4. The Evaluation of Keyword Extraction
5. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Central Regulation Standard Act. Available online: http://law.moj.gov.tw/eng/LawClass/LawAll.aspx?PCode=A0030133 (accessed on 20 June 2018).
- Laws & Regulations Database of The Republic of China. Available online: http://law.moj.gov.tw/Eng/ (accessed on 20 June 2018).
- Semantic Web. Available online: http://en.wikipedia.org/wiki/Semantic_Web#cite_note-1 (accessed on 20 June 2018).
- Ontology. Available online: http://en.wikipedia.org/wiki/Ontology (accessed on 20 June 2018).
- Ontology (Information Science). Available online: http://en.wikipedia.org/wiki/Ontology_(information_science) (accessed on 20 June 2018).
- Chen, C. Automatic Keyword Extraction and Chinese-English Word Alignment based on Law Database. Master’s Thesis, National Chung Cheng University, Chia-Yi, Taiwan, 2014. [Google Scholar]
- Natural Language Processing. Available online: http://en.wikipedia.org/wiki/Natural_language_processing (accessed on 20 June 2018).
- Huh, J.-H.; Seo, K. Hybrid advanced metering infrastructure design for micro grid using the game theory model. Int. J. Softw. Eng. Appl. 2015, 9, 257–268. [Google Scholar] [CrossRef]
- Huh, J.-H.; Otgonchimeg, S.; Seo, K. Advanced metering infrastructure design and test bed experiment using intelligent agents: Focusing on the plc network base technology for smart grid system. J. Supercomput. 2016, 72, 1862–1877. [Google Scholar] [CrossRef]
- Huh, J.-H. Smart grid framework test bed using opnet and power line communication. Adv. Comput. Electr. Eng. IGI Glob. USA 2017, 1–425. [Google Scholar] [CrossRef]
- Huh, J.-H. Plc-based design of monitoring system for ict-integrated vertical fish farm. Hum.-Cent. Comput. Inf. Sci. 2017, 7, 1–19. [Google Scholar] [CrossRef]
- Text Segmentation. Available online: http://en.wikipedia.org/wiki/Text_segmentation (accessed on 20 June 2018).
- Part-of-Speech Tagging. Available online: http://en.wikipedia.org/wiki/Part-of-speech_tagging (accessed on 20 June 2018).
- CKIP. Available online: http://ckip.iis.sinica.edu.tw/CKIP/index.htm (accessed on 20 June 2018).
- ICTCLAS. Available online: http://ictclas.nlpir.org/ (accessed on 20 June 2018).
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef] [Green Version]
- WordNet. Available online: http://wordnet.princeton.edu/ (accessed on 20 June 2018).
- The Gene Ontology. Available online: http://www.geneontology.org/ (accessed on 20 June 2018).
- BabelNet. Available online: http://lcl.uniroma1.it/babelnet/ (accessed on 20 June 2018).
- Ontology Development 101: A Guide to Creating Your First Ontology. Available online: http://protege.stanford.edu/publications/ontology_development/ontology101-noy-mcguinness.html (accessed on 20 June 2018).
- Huh, J.-H. Big data analysis for personalized health activities: Machine learning processing for automatic keyword extraction approach. Symmetry 2018, 10, 1–30. [Google Scholar] [CrossRef]
- Ghosh, M.E.; Naja, H.; Abdulrab, H.; Khalil, M. Ontology learning process as a bottom-up strategy for building domain-specific ontology from legal texts. In Proceedings of the 9th International Conference on Agents and Artificial Intelligence (ICAART), Porto, Portugal, 24–26 February 2017. [Google Scholar]
- Kiong, Y.C.; Palaniappan, S.; Yahaya, N.A. Health ontology system. In Proceedings of the 2011 IEEE 7th International Conference on Information Technology in Asia (CITA 11), Sarawak, Malaysia, 12–13 July 2011; pp. 1–4. [Google Scholar]
- Johnson, J.R.; Miller, A.; Khan, L. Law enforcement ontology for identification of related information of interest across free text dcouments. In Proceedings of the 2011 IEEE European Intelligence and Security Informatics Conference (EISIC), Athens, Greece, 12–14 September 2011; pp. 19–27. [Google Scholar]
- Deng, L.; Wang, X. Context-based semantic approach to ontology creation of maritime information in Chinese. In Proceedings of the IEEE International Conference on Granular Computing (GrC), San Jose, CA, USA, 14–16 August 2010; pp. 133–138. [Google Scholar]
- Jo, D.W.; Kim, M.H. Web-based semantic web retrieval service for law ontology. In Proceedings of the 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing (HPCC_EUC), Zhangjiajie, China, 13–15 November 2013; pp. 666–673. [Google Scholar]
- CycL. Available online: http://en.wikipedia.org/wiki/CycL (accessed on 20 June 2018).
- DOGMA, Short for Developing Ontology-Grounded Methods and Applications. Available online: http://en.wikipedia.org/wiki/DOGMA#References (accessed on 20 June 2018).
- Ontology Language. Available online: http://en.wikipedia.org/wiki/Ontology_language (accessed on 20 June 2018).
- SHOE Base Ontology. Available online: http://www.w3.org/2000/04shoe-swell/base-ns.html (accessed on 20 June 2018).
- DAML + OIL Web Ontology Language. Available online: http://www.w3.org/Submission/2001/12/ (accessed on 20 June 2018).
- OWL Web Ontology Language. Available online: http://www.w3.org/TR/owl-guide/ (accessed on 20 June 2018).
- Extensible Markup Language (XML). Available online: http://www.w3.org/XML/ (accessed on 20 June 2018).
- Resource Description Framework (RDF). Available online: http://www.w3.org/RDF/ (accessed on 20 June 2018).[Green Version]
- RDF Schema. Available online: http://www.w3.org/TR/rdf-schema/ (accessed on 20 June 2018).
- RDF Primer. Available online: http://www.w3.org/TR/rdf-primer/ (accessed on 20 June 2018).
- Eric Miller Contact Infromation. Available online: http://www.w3.org/People/EM/contact#me (accessed on 20 June 2018).
- SPARQL Protocol and RDF Query Language. Available online: http://www.w3.org/TR/rdf-sparql-query/ (accessed on 20 June 2018).
- Protégé. Available online: http://protege.stanford.edu/ (accessed on 20 June 2018).
- Knoodl. Available online: http://semanticweb.org/wiki/Knoodl. (accessed on 20 June 2018).
- OntoEdit. Available online: http://www.lt-world.org/kb/ipr-and-products/products/obj_76702 (accessed on 20 June 2018).
- Apache Jena. Available online: https://jena.apache.org/index.html (accessed on 20 June 2018).
- The Core RDF API. Available online: https://jena.apache.org/documentation/rdf/index.html (accessed on 20 June 2018).
- Jena Ontology API. Available online: https://jena.apache.org/documentation/ontology/ (accessed on 20 June 2018).
- Apache Jena Fuseki. Available online: https://jena.apache.org/documentation/fuseki2/index.html (accessed on 20 June 2018).
- Apache Jena TDB. Available online: https://jena.apache.org/documentation/tdb/ (accessed on 20 June 2018).
- D3.js (Data-Driven Documents). Available online: http://d3js.org/ (accessed on 20 June 2018).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Act | Penal Act | Special Act | Comprehensive Act |
|---|---|---|---|---|
| Laws | 353 | 0 | 216 | 16 |
| Regular Expression | Pattern Number |
|---|---|
| ⌃稱(.*),(?:謂|為|指|係指)(.*) | 1.2.3.4 |
| ⌃稱(.*?):(.*) | 5 |
| (.*),(?:|亦)視為(.*) | 6.7 |
| ⌃本法用詞定義(?:如下|下列|左列|如左):(.*) | 8 |
| 本法所定(.*?),(.*) | 9 |
| (.*),以(.*)論 | 10 |
| (.*),分(?:如下|下列|左列|如左)(?:一|二|三|四| 五|六|七|八|九|十)種:(.*) | 11 |
| ⌃稱(.*)(?:如下|下列|左列|如左):(.*) | 12 |
| (.*),稱為(.*) | 13 |
| (.*)區分(?:如下|下列|左列|如左):(.*) | 14 |
| ⌃本法用詞,定義(?:如下|下列|左列|如左):(.*) | 15 |
| Pattern Number | Regular Expression | First Statistics | Second Statistics |
|---|---|---|---|
| 1 | ⌃稱(.*),謂(.*) | 138 | 138 |
| 2 | ⌃稱(.*),為(.*) | 17 | 17 |
| 3 | ⌃稱(.*),指(.*) | 188 | 188 |
| 4 | ⌃稱(.*),係指(.*) | 101 | 101 |
| 5 | ⌃稱(.*?):(.*) | 95 | 95 |
| 6 | (.*),視為(.*) | 393 | 393 |
| 7 | (.*),亦視為(.*) | 2 | 2 |
| 8 | ⌃本法用詞定義(?:如下|下列|左列|如左):(.*) | 20 | 99 |
| 9 | 本法所定(.*?),(.*) | 141 | 141 |
| 10 | (.*),以(.*)論 | 0 | 0 |
| 11 | (.*),分(?:如下|下列|左列|如左)(?:一|二|三|四|五|六|七|八|九|十)種:(.*) | 2 | 2 |
| 12 | ⌃稱(.*)(?:如下|下列|左列|如左):(.*) | 20 | 20 |
| 13 | (.*),稱為(.*) | 16 | 16 |
| 14 | (.*)區分(?:如下|下列|左列|如左):(.*) | 15 | 15 |
| 15 | ⌃本法用詞,定義(?:如下|下列|左列|如左):(.*) | 25 | 106 |
| Total | 1173 | 1333 | |
| The Ontology Class | Number of Classes |
|---|---|
| Definition patterns extracted class | 1114 |
| Competent authorities class | 81 |
| SVM judged keyword class | 168,020 |
| Classes in law ontology | 169,215 |
| The Type of Relation | The Number of Relation |
|---|---|
| <kind-of> | 10 |
| <associated> | 27,412 |
| <same-origin> | 1100 |
| <sub-class> | 28 |
| <is-Classified-As> | 585 |
| <has-Source> | 1319 |
| SPARQL | SELECT * WHERE { ?s ?o ?b . FILTER regex(str(?s), “the search words”). } |
| Pattern Number | Total | Correct | Not Regarded | Incorrect |
|---|---|---|---|---|
| 1 | 138 | 127 | 6 | 5 |
| 2 | 17 | 17 | 0 | 0 |
| 3 | 188 | 178 | 6 | 4 |
| 4 | 101 | 95 | 2 | 4 |
| 5 | 95 | 85 | 6 | 4 |
| 6 | 393 | 152 | 220 | 21 |
| 7 | 2 | 2 | 0 | 0 |
| 8 | 99 | 98 | 1 | 0 |
| 9 | 141 | 52 | 75 | 14 |
| 10 | 0 | 0 | 0 | 0 |
| 11 | 2 | 0 | 2 | 0 |
| 12 | 20 | 3 | 15 | 2 |
| 13 | 16 | 12 | 1 | 3 |
| 14 | 15 | 4 | 9 | 2 |
| 15 | 106 | 102 | 0 | 4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, R.-H.; Hsueh, Y.-L.; Chang, Y.-T. Building a Taiwan Law Ontology Based on Automatic Legal Definition Extraction. Appl. Syst. Innov. 2018, 1, 22. https://doi.org/10.3390/asi1030022
Hwang R-H, Hsueh Y-L, Chang Y-T. Building a Taiwan Law Ontology Based on Automatic Legal Definition Extraction. Applied System Innovation. 2018; 1(3):22. https://doi.org/10.3390/asi1030022
Chicago/Turabian StyleHwang, Ren-Hung, Yu-Ling Hsueh, and Yu-Ting Chang. 2018. "Building a Taiwan Law Ontology Based on Automatic Legal Definition Extraction" Applied System Innovation 1, no. 3: 22. https://doi.org/10.3390/asi1030022
APA StyleHwang, R. -H., Hsueh, Y. -L., & Chang, Y. -T. (2018). Building a Taiwan Law Ontology Based on Automatic Legal Definition Extraction. Applied System Innovation, 1(3), 22. https://doi.org/10.3390/asi1030022