
Internet Traffic Prediction with Distributed Multi-Agent Learning



Abstract
:1. Introduction
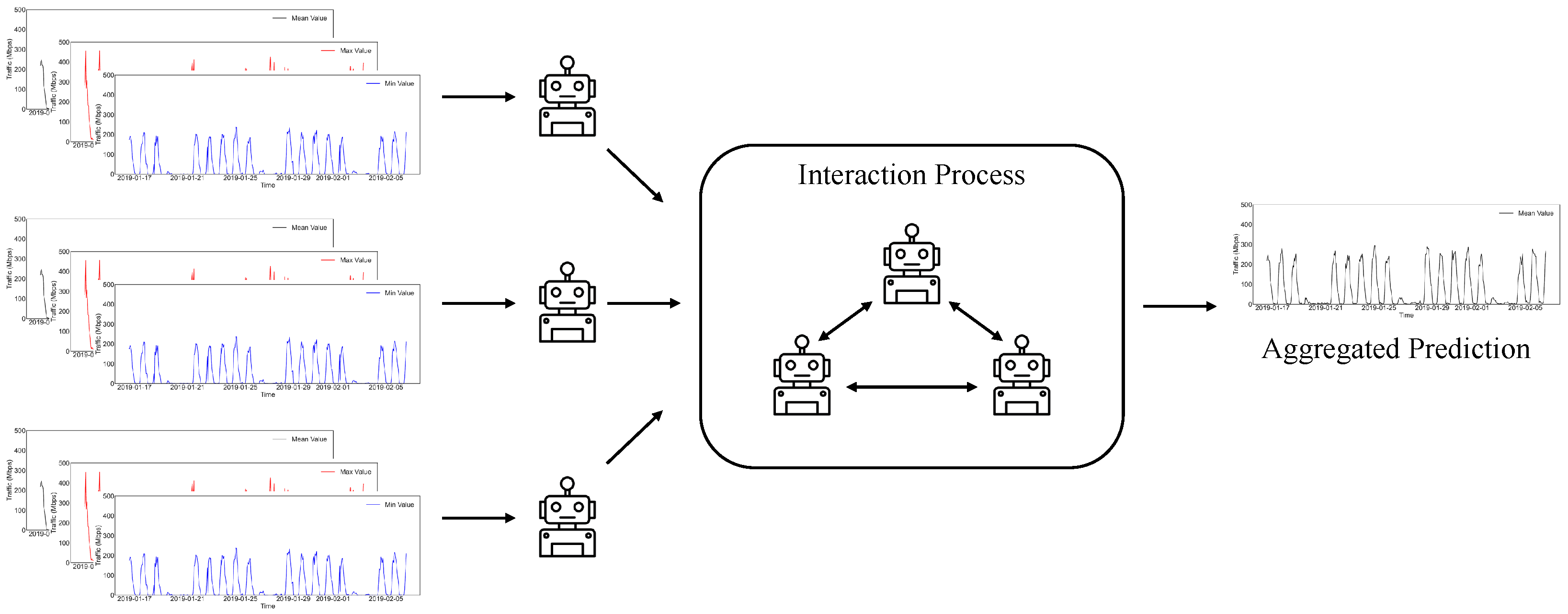
- To the best of our knowledge, this paper presents a pioneer work which predicts Internet traffic with a distributed multi-agent learning approach when Internet traffic prediction is modeled as a supervised learning problem and the base prediction models are trained cooperatively among different agents.
- An effective interaction process is used for coordinating the different agents in the distributed training step, which can be modeled and analyzed as an irreducible aperiodic Markov chain with a finite state, and the convergence property of the interaction process is proved.
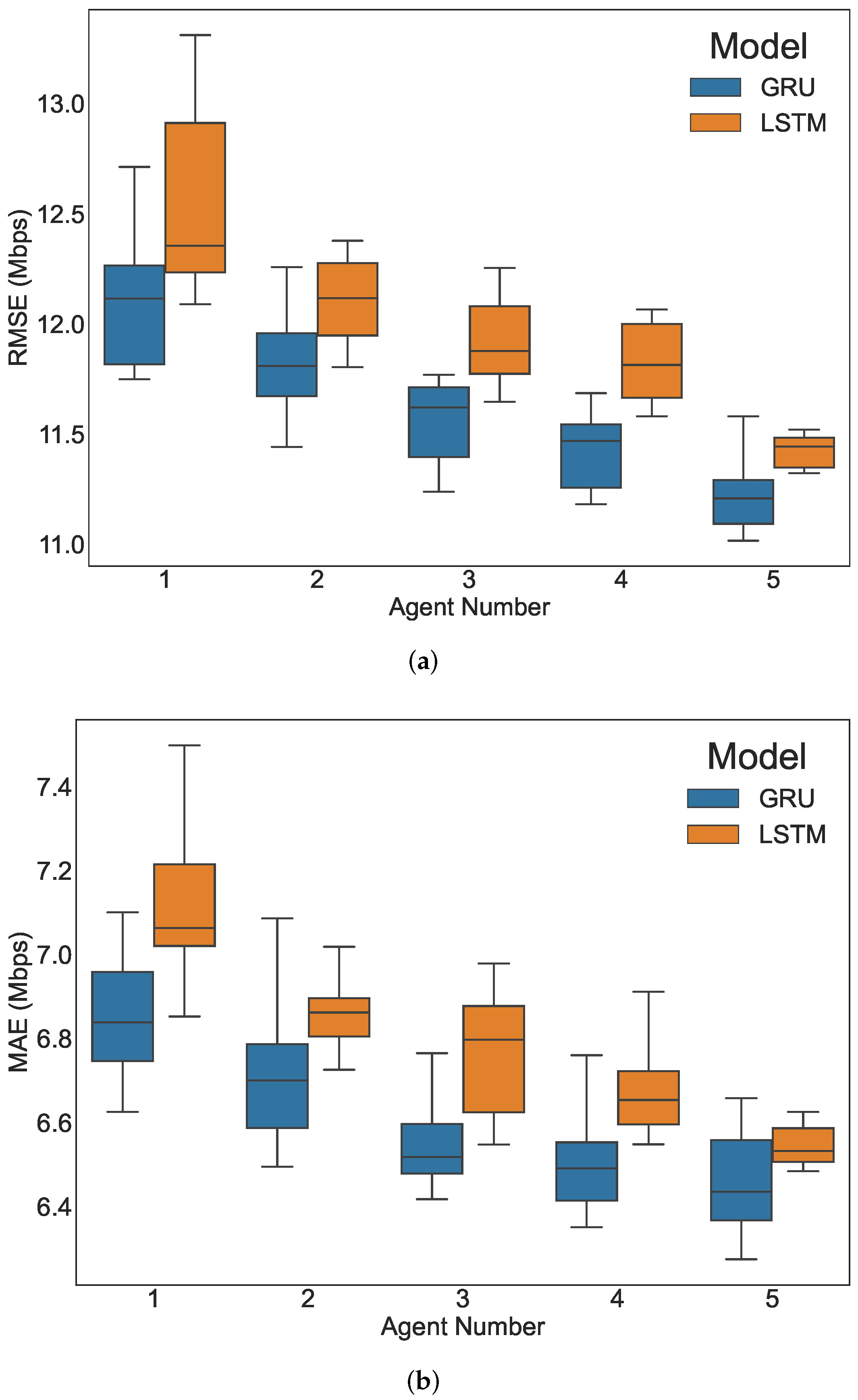
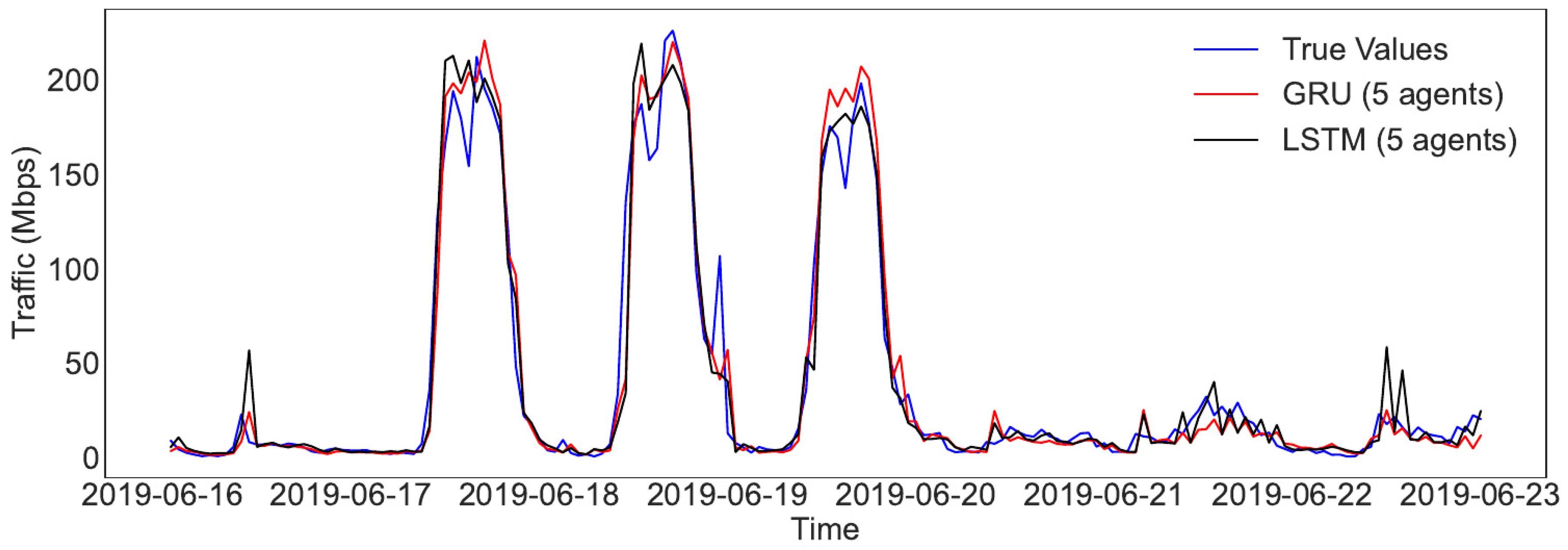
- The effectiveness of the proposed approach is validated with a real-world Internet traffic dataset collected at the State University of Ceará for half a year from 16 January 2019 to 15 July 2019, and the five-agent GRU-based distributed multi-agent learning scheme achieves state-of-the-art performance with the smallest prediction errors and outperforms several sophisticated deep learning models in terms of root mean square error (RMSE) and mean absolute error (MAE).
2. Related Work
2.1. Statistical Prediction Models
2.2. Machine Learning-Based Prediction Models
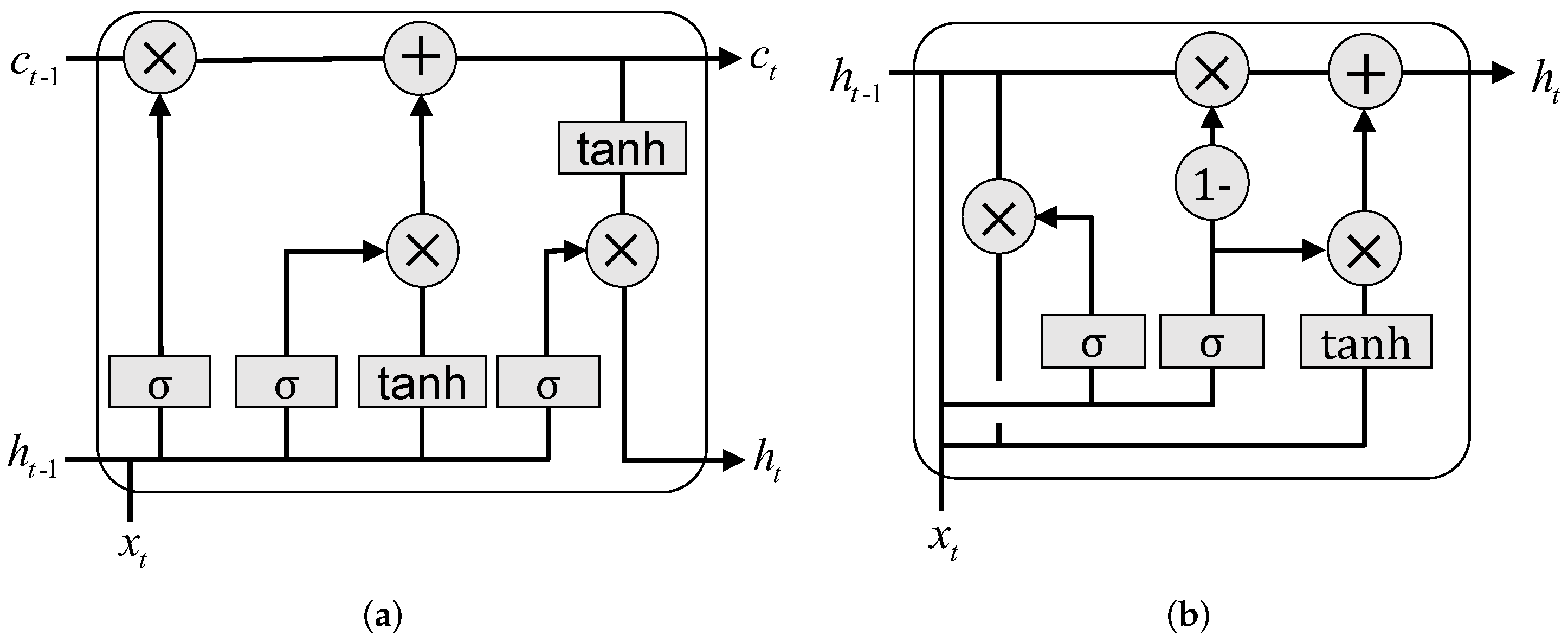
2.3. Deep Learning-Based Prediction Models
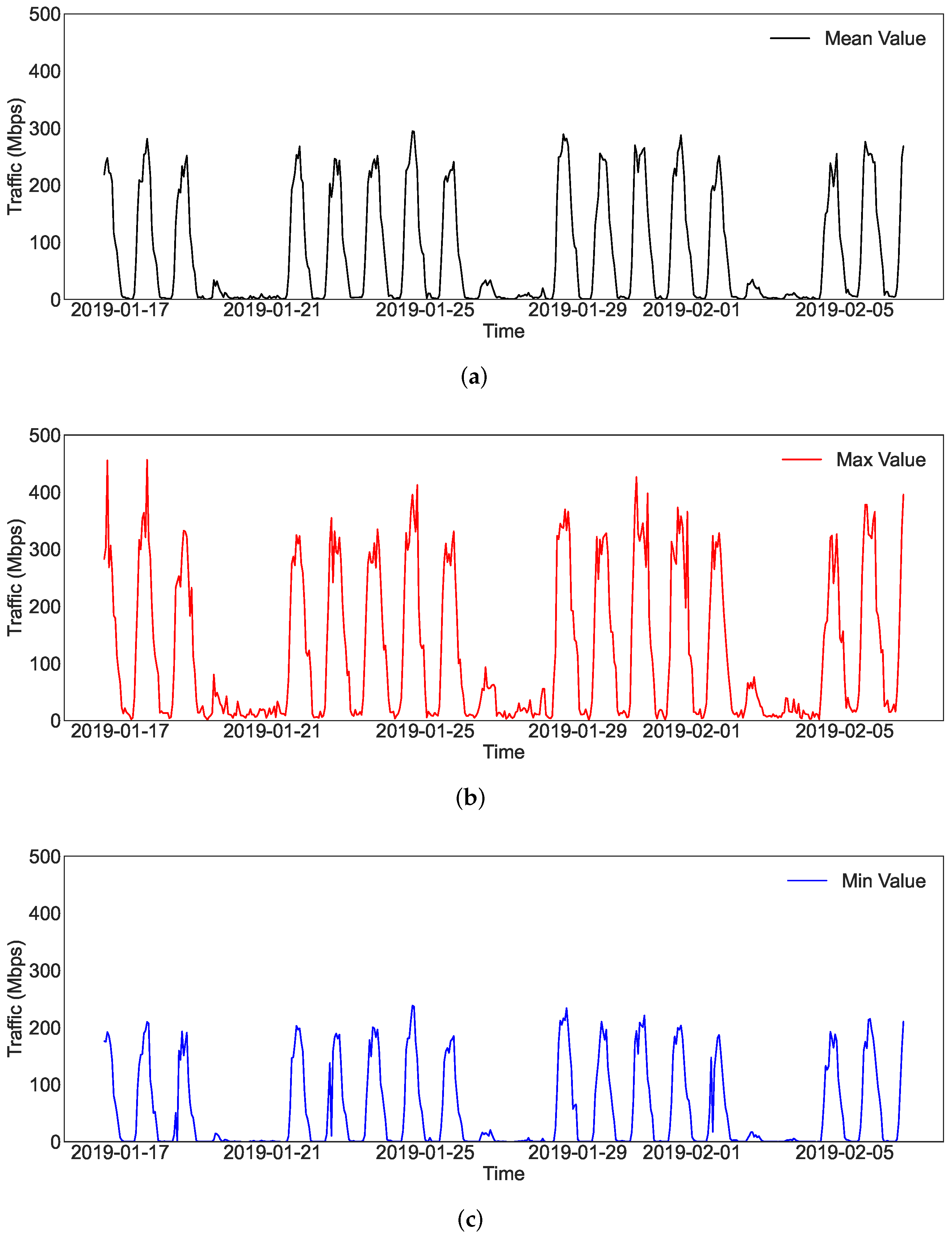
3. Dataset and Problem
4. Methodology
5. Experiment and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pugliese, R.; Regondi, S.; Marini, R. Machine learning-based approach: Global trends, research directions, and regulatory standpoints. Data Sci. Manag. 2021, 4, 19–29. [Google Scholar] [CrossRef]
- Zhang, Y.; Ren, G.; Liu, X.; Gao, G.; Zhu, M. Ensemble learning-based modeling and short-term forecasting algorithm for time series with small sample. Eng. Rep. 2022, 4, e12486. [Google Scholar] [CrossRef]
- Zhao, E.; Sun, S.; Wang, S. New developments in wind energy forecasting with artificial intelligence and big data: A scientometric insight. Data Sci. Manag. 2022, 5, 84–95. [Google Scholar] [CrossRef]
- He, M.; Gu, W.; Kong, Y.; Zhang, L.; Spanos, C.J.; Mosalam, K.M. Causalbg: Causal recurrent neural network for the blood glucose inference with IoT platform. IEEE Internet Things J. 2019, 7, 598–610. [Google Scholar] [CrossRef]
- Shankarnarayan, V.K.; Ramakrishna, H. Comparative study of three stochastic future weather forecast approaches: A case study. Data Sci. Manag. 2021, 3, 3–12. [Google Scholar] [CrossRef]
- Ramakrishnan, N.; Soni, T. Network traffic prediction using recurrent neural networks. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 187–193. [Google Scholar]
- Azzouni, A.; Pujolle, G. NeuTM: A neural network-based framework for traffic matrix prediction in SDN. In Proceedings of the NOMS 2018–2018 IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018; pp. 1–5. [Google Scholar]
- Jiang, W.; Zhang, L. Geospatial data to images: A deep-learning framework for traffic forecasting. Tsinghua Sci. Technol. 2018, 24, 52–64. [Google Scholar] [CrossRef]
- Jiang, W. Internet traffic matrix prediction with convolutional LSTM neural network. Internet Technol. Lett. 2022, 5, e322. [Google Scholar] [CrossRef]
- Duan, Y.; Chen, N.; Shen, S.; Zhang, P.; Qu, Y.; Yu, S. Fdsa-STG: Fully Dynamic Self-Attention Spatio-Temporal Graph Networks for Intelligent Traffic Flow Prediction. IEEE Trans. Veh. Technol. 2022, 71, 9250–9260. [Google Scholar] [CrossRef]
- Jiang, W.; Luo, J. Graph neural network for traffic forecasting: A survey. Expert Syst. Appl. 2022, 23, 117921. [Google Scholar] [CrossRef]
- Ke, S.; Liu, W. Distributed Multi-Agent Learning is More Effectively than Single-Agent. 2021. Available online: https://europepmc.org/article/ppr/ppr419060 (accessed on 1 November 2022).
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Jiang, W. Internet traffic prediction with deep neural networks. Internet Technol. Lett. 2022, 5, e314. [Google Scholar] [CrossRef]
- Shi, J.; Leau, Y.B.; Li, K.; Park, Y.J.; Yan, Z. Optimization and decomposition methods in network traffic prediction model: A review and discussion. IEEE Access 2020, 8, 202858–202871. [Google Scholar] [CrossRef]
- Lohrasbinasab, I.; Shahraki, A.; Taherkordi, A.; Delia Jurcut, A. From statistical-to machine learning-based network traffic prediction. Trans. Emerg. Telecommun. Technol. 2022, 33, e4394. [Google Scholar] [CrossRef]
- Jiang, W. Cellular traffic prediction with machine learning: A survey. Expert Syst. Appl. 2022, 201, 117163. [Google Scholar] [CrossRef]
- Tran, Q.T.; Hao, L.; Trinh, Q.K. A comprehensive research on exponential smoothing methods in modeling and forecasting cellular traffic. Concurr. Comput. Pract. Exp. 2020, 32, e5602. [Google Scholar] [CrossRef]
- Perveen, A.; Abozariba, R.; Patwary, M.; Aneiba, A. Dynamic traffic forecasting and fuzzy-based optimized admission control in federated 5G-open RAN networks. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Boutaba, R.; Salahuddin, M.A.; Limam, N.; Ayoubi, S.; Shahriar, N.; Estrada-Solano, F.; Caicedo, O.M. A comprehensive survey on machine learning for networking: Evolution, applications and research opportunities. J. Internet Serv. Appl. 2018, 9, 1–99. [Google Scholar] [CrossRef] [Green Version]
- Bayati, A.; Nguyen, K.K.; Cheriet, M. Multiple-step-ahead traffic prediction in high-speed networks. IEEE Commun. Lett. 2018, 22, 2447–2450. [Google Scholar] [CrossRef]
- Zhang, Q.; Mozaffari, M.; Saad, W.; Bennis, M.; Debbah, M. Machine learning for predictive on-demand deployment of UAVs for wireless communications. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Sun, S.C.; Guo, W. Forecasting wireless demand with extreme values using feature embedding in gaussian processes. In Proceedings of the 2021 IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Helsinki, Finland, 25–28 April 2021; pp. 1–6. [Google Scholar]
- Xia, H.; Wei, X.; Gao, Y.; Lv, H. Traffic prediction based on ensemble machine learning strategies with bagging and lightgbm. In Proceedings of the 2019 IEEE International Conference on Communications Workshops (ICC Workshops), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Aldhyani, T.H.; Joshi, M.R. Integration of time series models with soft clustering to enhance network traffic forecasting. In Proceedings of the 2016 Second International Conference on Research in Computational Intelligence and Communication Networks (ICRCICN), Kolkata, India, 23–25 September 2016; pp. 212–214. [Google Scholar]
- Qiu, C.; Zhang, Y.; Feng, Z.; Zhang, P.; Cui, S. Spatio-temporal wireless traffic prediction with recurrent neural network. IEEE Wirel. Commun. Lett. 2018, 7, 554–557. [Google Scholar] [CrossRef]
- Abdellah, A.R.; Muthanna, A.; Essai, M.H.; Koucheryavy, A. Deep Learning for Predicting Traffic in V2X Networks. Appl. Sci. 2022, 12, 10030. [Google Scholar] [CrossRef]
- Gao, Y.; Zhang, M.; Chen, J.; Han, J.; Li, D.; Qiu, R. Accurate load prediction algorithms assisted with machine learning for network traffic. In Proceedings of the 2021 International Wireless Communications and Mobile Computing (IWCMC), Harbin, China, 28 June–2 July 2021; pp. 1683–1688. [Google Scholar]
- Chien, W.C.; Huang, Y.M. A lightweight model with spatial–temporal correlation for cellular traffic prediction in Internet of Things. J. Supercomput. 2021, 77, 10023–10039. [Google Scholar] [CrossRef]
- Zhan, S.; Yu, L.; Wang, Z.; Du, Y.; Yu, Y.; Cao, Q.; Dang, S.; Khan, Z. Cell traffic prediction based on convolutional neural network for software-defined ultra-dense visible light communication networks. Secur. Commun. Netw. 2021, 2021, 9223965. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Shen, W.; Zhang, H.; Guo, S.; Zhang, C. Time-wise attention aided convolutional neural network for data-driven cellular traffic prediction. IEEE Wirel. Commun. Lett. 2021, 10, 1747–1751. [Google Scholar] [CrossRef]
- Wang, Z.; Wong, V.W. Cellular Traffic Prediction Using Deep Convolutional Neural Network with Attention Mechanism. In Proceedings of the ICC 2022—IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 2339–2344. [Google Scholar]
- Hu, Y.; Zhou, Y.; Song, J.; Xu, L.; Zhou, X. Citywide Mobile Traffic Forecasting Using Spatial-Temporal Downsampling Transformer Neural Networks. IEEE Trans. Netw. Serv. Manag. 2022. [Google Scholar] [CrossRef]
- Jiang, W. Graph-based deep learning for communication networks: A survey. Comput. Commun. 2022, 185, 40–54. [Google Scholar] [CrossRef]
- Wang, Z.; Hu, J.; Min, G.; Zhao, Z.; Chang, Z.; Wang, Z. Spatial-Temporal Cellular Traffic Prediction for 5 G and Beyond: A Graph Neural Networks-Based Approach. IEEE Trans. Ind. Inform. 2022. [Google Scholar] [CrossRef]
- Fang, Y.; Ergüt, S.; Patras, P. SDGNet: A Handover-Aware Spatiotemporal Graph Neural Network for Mobile Traffic Forecasting. IEEE Commun. Lett. 2022, 26, 582–586. [Google Scholar] [CrossRef]
- Abdullah, M.; He, J.; Wang, K. Weather-Aware Fiber-Wireless Traffic Prediction Using Graph Convolutional Networks. IEEE Access 2022, 10, 95908–95918. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, Y.; Li, Z.; Wang, X.; Zhao, J.; Zhang, Z. Large-scale cellular traffic prediction based on graph convolutional networks with transfer learning. Neural Comput. Appl. 2022, 34, 5549–5559. [Google Scholar] [CrossRef]
- Oliveira, D.H.; de Araujo, T.P.; Gomes, R.L. An Adaptive Forecasting Model for Slice Allocation in Softwarized Networks. IEEE Trans. Netw. Serv. Manag. 2021, 18, 94–103. [Google Scholar] [CrossRef]
- Zerveas, G.; Jayaraman, S.; Patel, D.; Bhamidipaty, A.; Eickhoff, C. A Transformer-based Framework for Multivariate Time Series Representation Learning. arXiv 2020, arXiv:2010.02803. [Google Scholar]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1578–1585. [Google Scholar]
- Fawaz, H.I.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.A.; Petitjean, F. Inceptiontime: Finding alexnet for time series classification. Data Min. Knowl. Discov. 2020, 34, 1936–1962. [Google Scholar] [CrossRef]
- Shao, Y.; Li, H.; Gu, X.; Yin, H.; Li, Y.; Miao, X.; Zhang, W.; Cui, B.; Chen, L. Distributed Graph Neural Network Training: A Survey. arXiv 2022, arXiv:2211.00216. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Agent Number | RMSE (Mbps) | MAE (Mbps) |
|---|---|---|---|
| TST [42] | N/A | 16.28 | 9.71 |
| MLP [43] | N/A | 14.81 | 8.51 |
| TCN [44] | N/A | 13.39 | 9.31 |
| FCN [45] | N/A | 12.79 | 8.10 |
| ResNet [45] | N/A | 11.68 | 7.16 |
| InceptionTime [46] | N/A | 11.65 | 7.07 |
| LSTM | 1 | 12.57 | 7.10 |
| 2 | 12.11 | 6.86 | |
| 3 | 11.93 | 6.77 | |
| 4 | 11.83 | 6.69 | |
| 5 | 11.43 | 6.54 | |
| GRU | 1 | 12.11 | 6.84 |
| 2 | 11.84 | 6.71 | |
| 3 | 11.56 | 6.55 | |
| 4 | 11.42 | 6.50 | |
| 5 | 11.22 | 6.45 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, W.; He, M.; Gu, W. Internet Traffic Prediction with Distributed Multi-Agent Learning. Appl. Syst. Innov. 2022, 5, 121. https://doi.org/10.3390/asi5060121
Jiang W, He M, Gu W. Internet Traffic Prediction with Distributed Multi-Agent Learning. Applied System Innovation. 2022; 5(6):121. https://doi.org/10.3390/asi5060121
Chicago/Turabian StyleJiang, Weiwei, Miao He, and Weixi Gu. 2022. "Internet Traffic Prediction with Distributed Multi-Agent Learning" Applied System Innovation 5, no. 6: 121. https://doi.org/10.3390/asi5060121
APA StyleJiang, W., He, M., & Gu, W. (2022). Internet Traffic Prediction with Distributed Multi-Agent Learning. Applied System Innovation, 5(6), 121. https://doi.org/10.3390/asi5060121