
Evaluation Metrics Research for Explainable Artificial Intelligence Global Methods Using Synthetic Data

 ,
,
Abstract
:1. Introduction
- Determination of criteria for approaches to assessing XAI methods;
- Study of existing metrics for evaluating XAI methods;
- Selection of XAI evaluation metrics and their modification;
- Development of software for generating synthetic data and calculating metrics;
- Study of SHAP, LIME XAI methods using the developed software
2. Relevance. Overview of Analogues
2.1. Determination of Criteria for Evaluating Analogues
- Metrics based on technical specifications
- Metrics based on sociological and cognitive characteristics
2.2. Description of Analogues
- The method must be accuracy-oriented (proximity-guided)
- The method should focus on functionality (eng. focused on features)
- The method must be distributionally stable (eng. distributionally-faithful)
- The method must be instance-guided
- D, performance difference between models and XAI method execution;
- R, the number of rules in the model explanation (rule based);
- F, the number of features used to construct the explanation;
- S, the stability of the explanation of models;
- Explanation Goodness
- User satisfaction
- User Curiosity/Attention Engagement
- User Trust/Reliance
- User understanding
- Productivity/Productivity of use (English User Performance/Productivity)
- System Controllability/Interactivity
- Recovery Rate—determines the effectiveness of trigger detection
- Computational Cost—determines the cost of defining triggers
- Intersection of triggers in relation to their union (eng. Intersection over Union)—also determines the effectiveness of trigger detection
- Recovering Difference—determines the correctness of the rejection of triggers
- Metrics based on method application and user
- a.
- Subjective metrics
- i.
- User trust
- ii.
- User preference
- iii.
- User confidence
- b.
- Objective metrics (user psychological signals)
- i.
- Electrical activity of the skin (eng. Galvanic Skin Response)
- ii.
- Blood Volume Pulse
- Metrics based on functionality (for methods for evaluating artificial neural network models)
- a.
- Number of operations depending on model size
- b.
- Level of disagreement
- c.
- Interaction strength
2.3. Findings from the Comparison
2.4. Solution Method Choosing
- Taking into account the technical characteristics of the XAI method
- Accounting for heterogeneity of input data using synthetic data
- Availability of a methodical or mathematical description of each metric
- Ability to calculate metrics when running methods with different machine learning models
3. Experiments
3.1. Metrics Modification
- 1.
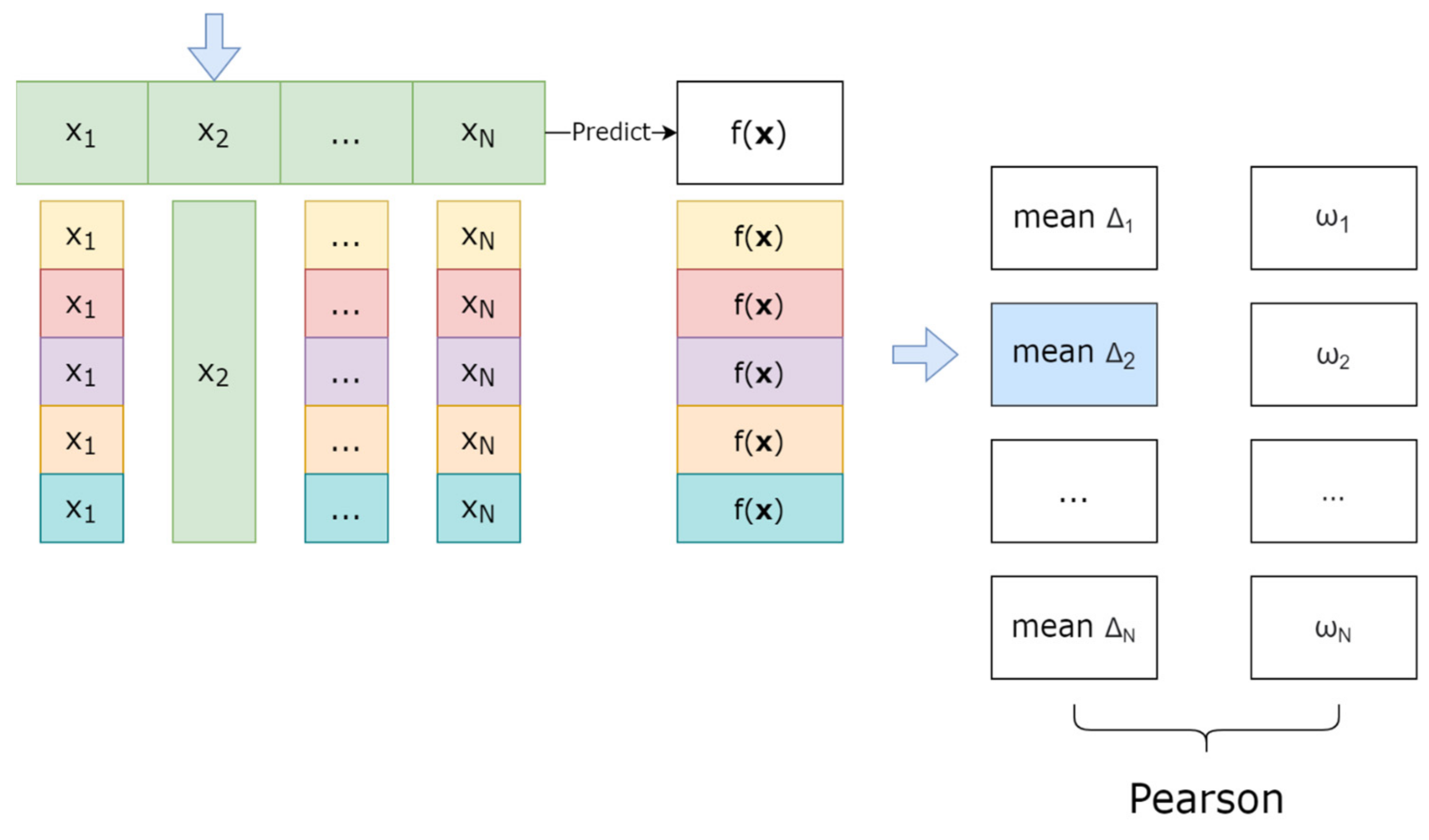
- Faithfulness metric. The faithfulness metric allows you to determine the degree of correspondence between the explanation of the importance of each individual feature and is determined by the Pearson sample correlation coefficient between the weights of the feature and its approximate contribution to the change in the model prediction when it is removed or fixed.
- 2.
- Monotonicity metric. The monotonicity metric is based on this concept and determines the correctness of a sequence of features, ordered by increasing their weight, obtained by XAI methods. If monotonicity is not observed, then the XAI method allowed a distortion of feature priorities: a feature with less influence received more weight, or vice versa. This metric also cannot assess the accuracy of the weight value of each feature, but it can assess the correctness of the distribution of weights between features.
- 3.
- Incompleteness metric. The Incompleteness metric determines the effect of noise perturbations of each feature on model predictions by calculating the difference between the weights and the difference between the original prediction and the predictions given by the noisy feature sets.
3.2. Synthetic Data
3.3. Implementing the Metrics Calculation Tool
- Synthetic data generation module. The synthetic data generation module includes classes that allow you to generate sets of features by sampling from various distributions (multivariate normal distribution, including conditional distribution according to the method described in paragraph 2.1), as well as markers for data sets using various methods (linear, piecewise -linear, non-linear function) for linear regression or classification models.
- Module for calculating metrics of XAI methods. Each metric is implemented as a separate class: Faithfulness, Infidelity, Monotonicity. When any of these classes are initialized, an instance of the CustomData class and an instance of the machine learning model are passed. Each of the metric classes implements the evaluate function, which takes as input the initial data set, the weights obtained from the XAI method, and a parameter that controls the number of additionally generated samples for calculating the metric.
- XAI methods application module. The module is responsible for initializing and applying the XAI methods. For the SHAP method, two classes are implemented that provide an interface for calling the shap.Explainer and shap.KernelExplainer classes included in the shap library. The library is the official implementation of the method, and its documentation contains many examples of applying the method to models of various types.
3.4. Results and Discussion
4. Conclusions
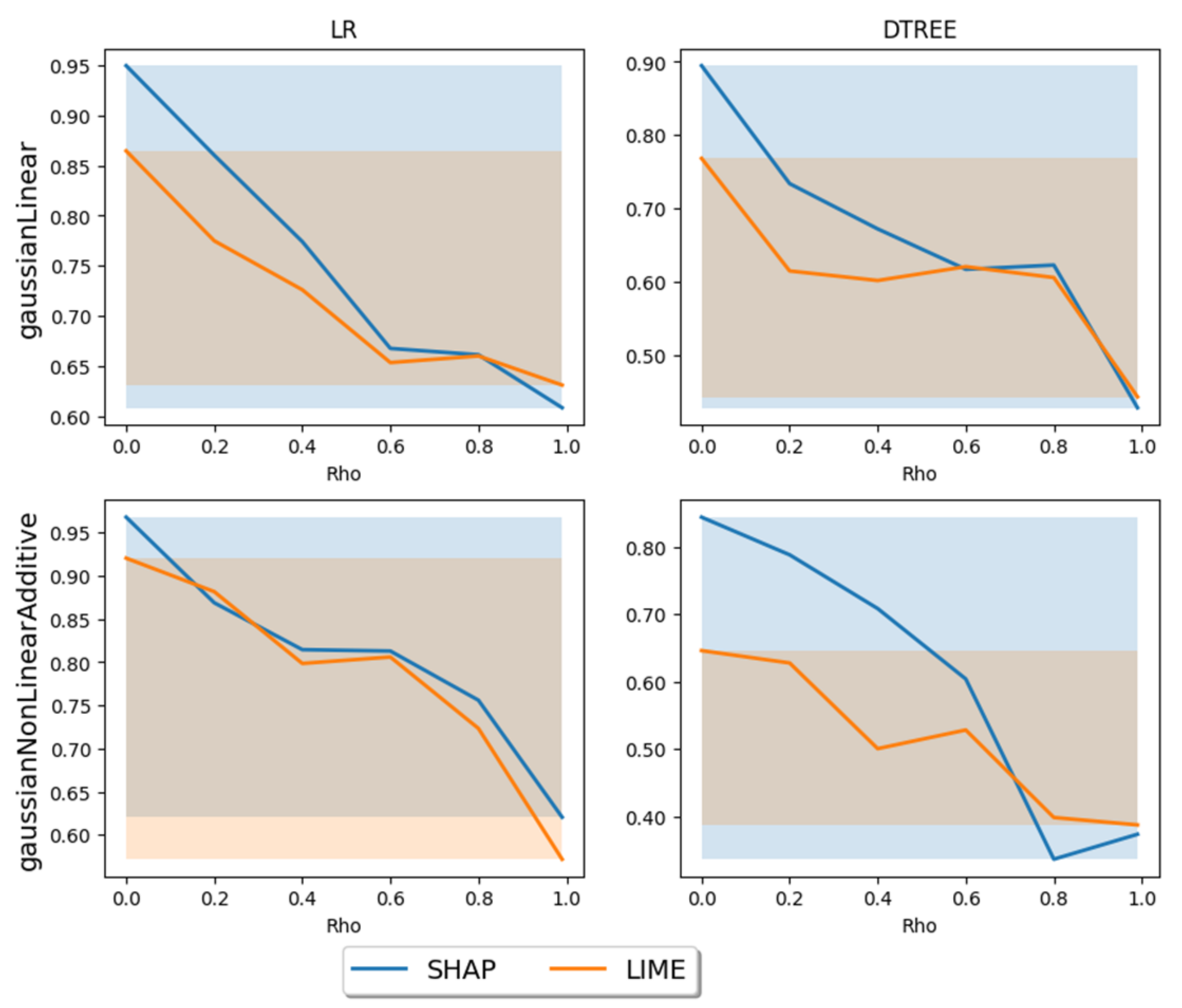
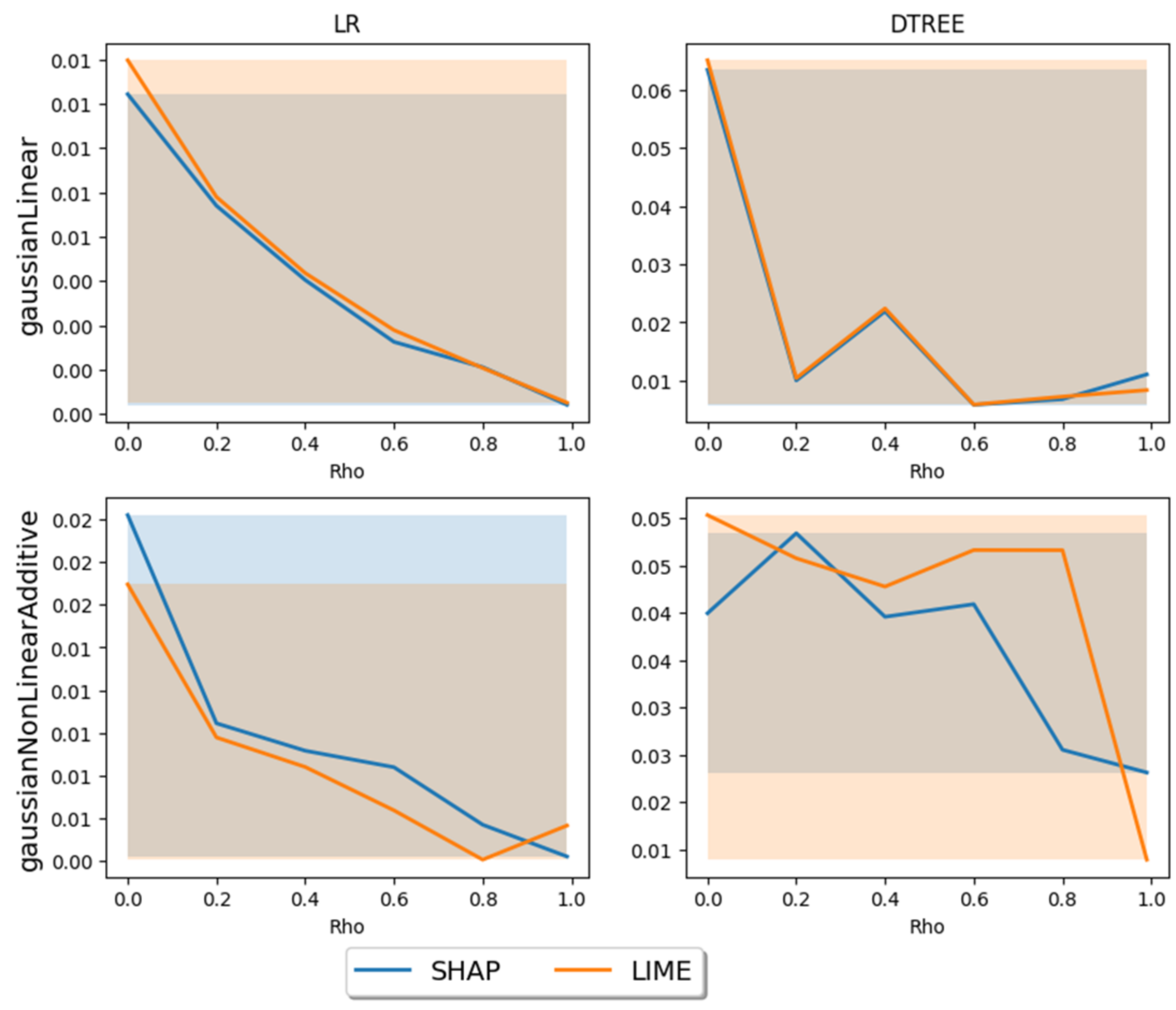
- SHAP and LIME methods are comparable in terms of accuracy of explanation.A study was conducted, using these metrics, which determined the degradation in the explanation quality of the SHAP and LIME methods with increasing correlation in the input data;
- The completeness of explanations of both methods is satisfactory, but the weights of each feature separately, as well as the order of increasing weights, largely depend on the input data and the machine learning model;
- Both methods provide less accurate explanations as the correlation coefficient of features in the input data increases, with a correlation of >0.5, the explanations of the methods are unstable and may be questioned;
- Both methods provide less accurate explanations when applied to decision tree models than when applied to linear regression models;
- The SHAP method shows comparable explanatory accuracy with a linear and non-linear marker function, while the LIME method is less accurate with a non-linear function;
- The execution time of the LIME method is more than 10 times the execution time of the SHAP method.
- Expansion of the list of XAI methods, for example, methods MAPLE, ER-SHAP, Breakdown;
- Study of evaluation metrics of XAI methods when applied to classification models;
- Study of dependence of SHAP method evaluation metrics on kernel parameters;
- Expansion of the list of machine learning models, for example, models of autoencoder, deep neural network, vector machines, convolutional neural network.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Poursabzi-Sangdeh, F.; Goldstein, D.G.; Hofman, J.M.; Wortman Vaughan, J.; Wallach, H. Manipulating and Measuring Model Interpretability. In Proceedings of the CHI ’21: CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021. [Google Scholar]
- Tulio Ribeiro, M.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the KDD ’16: The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Utkin, L.V.; Konstantinov, A.V. Ensembles of Random SHAPs. arXiv 2021, arXiv:2103.03302. [Google Scholar] [CrossRef]
- Utkin, L.V.; Konstantinov, A.V.; Vishniakov, K.A. An Imprecise SHAP as a Tool for Explaining the Class Probability Distributions under Limited Training Data. arXiv 2021, arXiv:2106.09111. [Google Scholar]
- Lundberg, S.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards A Rigorous Science of Interpretable Machine Learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Rosenfeld, A. Better Metrics for Evaluating Explainable Artificial Intelligence. In Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, Virtual Event, UK, 3–7 May 2021. [Google Scholar]
- Hsiao, J.H.-W.; Ngai, H.H.T.; Qiu, L.; Yang, Y.; Cao, C.C. Roadmap of Designing Cognitive Metrics for Explainable Artificial Intelligence (XAI). arXiv 2021, arXiv:2108.01737. [Google Scholar]
- Keane, M.T.; Kenny, E.M.; Delaney, E.; Smyth, B. If Only We Had Better Counterfactual Explanations: Five Key Deficits to Rectify in the Evaluation of Counterfactual XAI Techniques. arXiv 2021, arXiv:2103.01035. [Google Scholar]
- Lin, Y.-S.; Lee, W.-C.; Berkay Celik, Z. What Do You See? Evaluation of Explainable Artificial Intelligence (XAI) Interpretability through Neural Backdoors. arXiv 2020, arXiv:2009.10639. [Google Scholar]
- Zhou, J.; Gandomi, A.H.; Chen, F.; Holzinger, A. Evaluating the quality of machine learning explanations: A survey on methods and metrics. Electronics 2021, 10, 593. [Google Scholar] [CrossRef]
- Kim, M.-Y.; Atakishiyev, S.; Babiker, H.K.B.; Farruque, N.; Goebel, R.; Zaïane, O.R.; Motallebi, M.-H.; Rabelo, J.; Syed, T.; Yao, H.; et al. A Multi-Component Framework for the Analysis and Design of Explainable Artificial Intelligence. Mach. Learn. Knowl. Extr. 2021, 3, 900–921. [Google Scholar] [CrossRef]
- Vilone, G.; Longo, L. Classification of Explainable Artificial Intelligence Methods through Their Output Formats. Mach. Learn. Knowl. Extr. 2021, 3, 615–661. [Google Scholar] [CrossRef]
- Sarp, S.; Kuzlu, M.; Wilson, E.; Cali, U.; Guler, O. The Enlightening Role of Explainable Artificial Intelligence in Chronic Wound Classification. Electronics 2021, 10, 1406. [Google Scholar] [CrossRef]
- Petrauskas, V.; Jasinevicius, R.; Damuleviciene, G.; Liutkevicius, A.; Janaviciute, A.; Lesauskaite, V.; Knasiene, J.; Meskauskas, Z.; Dovydaitis, J.; Kazanavicius, V.; et al. Explainable Artificial Intelligence-Based Decision Support System for Assessing the Nutrition-Related Geriatric Syndromes. Appl. Sci. 2021, 11, 11763. [Google Scholar] [CrossRef]
- Emam, K.; Mosquera, L.; Hoptroff, R. Chapter 1: Introducing Synthetic Data Generation. In Practical Synthetic Data Generation: Balancing Privacy and the Broad Availability of Data; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2020; pp. 1–22. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; pp. 878–887. [Google Scholar]
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. Safe-level-smote: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Bangkok, Thailand, 27–30 April 2009; pp. 475–482. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Douzas, G.; Bacao, F.; Last, F. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE. Inf. Sci. 2018, 465, 1–20. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Siddani, B.; Balachandar, S.; Moore, W.C.; Yang, Y.; Fang, R. Machine learning for physics-informed generation of dispersed multiphase flow using generative adversarial networks. Theor. Comput. Fluid Dyn. 2021, 35, 807–830. [Google Scholar] [CrossRef]
- Coutinho-Almeida, J.; Rodrigues, P.P.; Cruz-Correia, R.J. GANs for Tabular Healthcare Data Generation: A Review on Utility and Privacy. In Discovery Science; Soares, C., Torgo, L., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 282–291. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic data for text localisation in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2315–2324. [Google Scholar]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. A review of feature selection methods on synthetic data. Knowl. Inf. Syst. 2013, 34, 483–519. [Google Scholar] [CrossRef]
- Frid-Adar, M.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. Synthetic data augmentation using GAN for improved liver lesion classification. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 289–293. [Google Scholar]
- Koch, B. Status and future of laser scanning, synthetic aperture radar and hyperspectral remote sensing data for forest biomass assessment. ISPRS J. Photogramm. Remote Sens. 2010, 65, 581–590. [Google Scholar] [CrossRef]
- Wu, X.; Liang, L.; Shi, Y.; Fomel, S. FaultSeg3D: Using synthetic data sets to train an end-to-end convolutional neural network for 3D seismic fault segmentation. Geophysics 2019, 84, IM35–IM45. [Google Scholar] [CrossRef]
- Nikolenko, S.I. Synthetic Data Outside Computer Vision. In Synthetic Data for Deep Learning; Springer: Berlin/Heidelberg, Germany, 2021; pp. 217–226. [Google Scholar]
- Pan, Z.; Yu, W.; Yi, X.; Khan, A.; Yuan, F.; Zheng, Y. Recent progress on generative adversarial networks (GANs): A survey. IEEE Access 2019, 7, 36322–36333. [Google Scholar] [CrossRef]
- Di Mattia, F.; Galeone, P.; De Simoni, M.; Ghelfi, E. A survey on gans for anomaly detection. arXiv 2019, arXiv:1906.11632. [Google Scholar]
- Saxena, D.; Cao, J. Generative adversarial networks (GANs) challenges, solutions, and future directions. ACM Comput. Surv. (CSUR) 2021, 54, 63. [Google Scholar]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Learning from synthetic data for crowd counting in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 8198–8207. [Google Scholar]
- Atapour-Abarghouei, A.; Breckon, T.P. Real-time monocular depth estimation using synthetic data with domain adaptation via image style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2800–2810. [Google Scholar]
- Liu, J.; Qu, F.; Hong, X.; Zhang, H. A small-sample wind turbine fault detection method with synthetic fault data using generative adversarial nets. IEEE Trans. Ind. Inform. 2018, 15, 3877–3888. [Google Scholar] [CrossRef]
- Zhang, L.; Gonzalez-Garcia, A.; Van De Weijer, J.; Danelljan, M.; Khan, F.S. Synthetic data generation for end-to-end thermal infrared tracking. IEEE Trans. Image Process. 2018, 28, 1837–1850. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Pixel-wise crowd understanding via synthetic data. Int. J. Comput. Vis. 2021, 129, 225–245. [Google Scholar] [CrossRef]
- Chen, Y.; Li, W.; Chen, X.; Gool, L.V. Learning semantic segmentation from synthetic data: A geometrically guided input-output adaptation approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1841–1850. [Google Scholar]
- Dunn, K.W.; Fu, C.; Ho, D.J.; Lee, S.; Han, S.; Salama, P.; Delp, E.J. DeepSynth: Three-dimensional nuclear segmentation of biological images using neural networks trained with synthetic data. Sci. Rep. 2019, 9, 18295. [Google Scholar] [CrossRef]
- Kim, K.; Myung, H. Autoencoder-combined generative adversarial networks for synthetic image data generation and detection of jellyfish swarm. IEEE Access 2018, 6, 54207–54214. [Google Scholar] [CrossRef]
- Torkzadehmahani, R.; Kairouz, P.; Paten, B. Dp-cgan: Differentially private synthetic data and label generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Name | Characteristic |
|---|---|
| Functionality-grounded | Theoretical, based on the description of the algorithm |
| Human-grounded | Experimental calculation |
| Application-grounded | User Experience Research |
| No | Criterion Name |
|---|---|
| 1 | The number of metrics that have a mathematical or methodological description |
| 2 | Number of evaluated technical characteristics |
| 3 | Accounting for heterogeneity of input data |
| 4 | Types of studies for calculating metrics |
| 5 | The amount of research required to calculate the metrics |
| Criterion/ Analog | The Number of Metrics with Mathematical or Methodological Description | Number of Evaluated Technical Characteristics | Accounting for Heterogeneity of Input Data | Types of Studies for Calculating Metrics | The Amount of Research Required to Calculate the Metrics |
|---|---|---|---|---|---|
| №1, Keane M. T. et al., 2021 | 0 | 4 | Yes | Functionality-, Human-grounded | Middle |
| №2, Rosenfeld A., 2021 | 4 | 4 | No | Human-grounded | Middle |
| №3, Hsiao J. H. et al., 2021 | 7 | 0 | Yes | Human-grounded | High |
| №4, Lin Y. S., Lee W. C., Celik Z. B., 2020 | 4 | 4 | No | Human-grounded | Middle |
| №5, Zhou J. et al., 2021 | 0 | 3 | Yes | All | Extremely high |
| Library Name | Description | Library Version |
|---|---|---|
| NumPy | A library that implements linear algebra operations, mathematical functions, elements of statistical analysis | 1.21.0 |
| Matplotlib | Library for plotting various types of graphs | 3.5.1 |
| Scipy | Library designed to perform scientific and engineering calculations | 1.8.0 |
| Pandas | Library for working with tabular data structures | 1.4.1 |
| Shap | Library with implementation of the XAI SHAP method | 0.40.0 |
| Lime | Library with the implementation of the XAI LIME method | 0.2.0.1 |
| Scikit-learn | Library with tools for designing and training models | 1.0.2 |
| Method | Marker Function | The Value of the Metric at the Correlation Coefficient | |||||
|---|---|---|---|---|---|---|---|
| 0.0 | 0.2 | 0.4 | 0.6 | 0.8 | 0.99 | ||
| SHAP | Linear | 0.94 | 0.86 | 0.77 | 0.66 | 0.66 | 0.6 |
| Non-linear | 0.96 | 0.87 | 0.81 | 0.81 | 0.76 | 0.62 | |
| LIME | Linear | 0.86 | 0.77 | 0.72 | 0.65 | 0.66 | 0.63 |
| Non-linear | 0.92 | 0.88 | 0.8 | 0.8 | 0.72 | 0.57 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oblizanov, A.; Shevskaya, N.; Kazak, A.; Rudenko, M.; Dorofeeva, A. Evaluation Metrics Research for Explainable Artificial Intelligence Global Methods Using Synthetic Data. Appl. Syst. Innov. 2023, 6, 26. https://doi.org/10.3390/asi6010026
Oblizanov A, Shevskaya N, Kazak A, Rudenko M, Dorofeeva A. Evaluation Metrics Research for Explainable Artificial Intelligence Global Methods Using Synthetic Data. Applied System Innovation. 2023; 6(1):26. https://doi.org/10.3390/asi6010026
Chicago/Turabian StyleOblizanov, Alexandr, Natalya Shevskaya, Anatoliy Kazak, Marina Rudenko, and Anna Dorofeeva. 2023. "Evaluation Metrics Research for Explainable Artificial Intelligence Global Methods Using Synthetic Data" Applied System Innovation 6, no. 1: 26. https://doi.org/10.3390/asi6010026
APA StyleOblizanov, A., Shevskaya, N., Kazak, A., Rudenko, M., & Dorofeeva, A. (2023). Evaluation Metrics Research for Explainable Artificial Intelligence Global Methods Using Synthetic Data. Applied System Innovation, 6(1), 26. https://doi.org/10.3390/asi6010026