Human-Centric Aggregation via Ordered Weighted Aggregation for Ranked Recommendation in Recommender Systems

 , ,
, ,  and
and
Abstract
:1. Introduction
2. Human-Centric Aggregation
Ordered Weighted Aggregation (OWA)
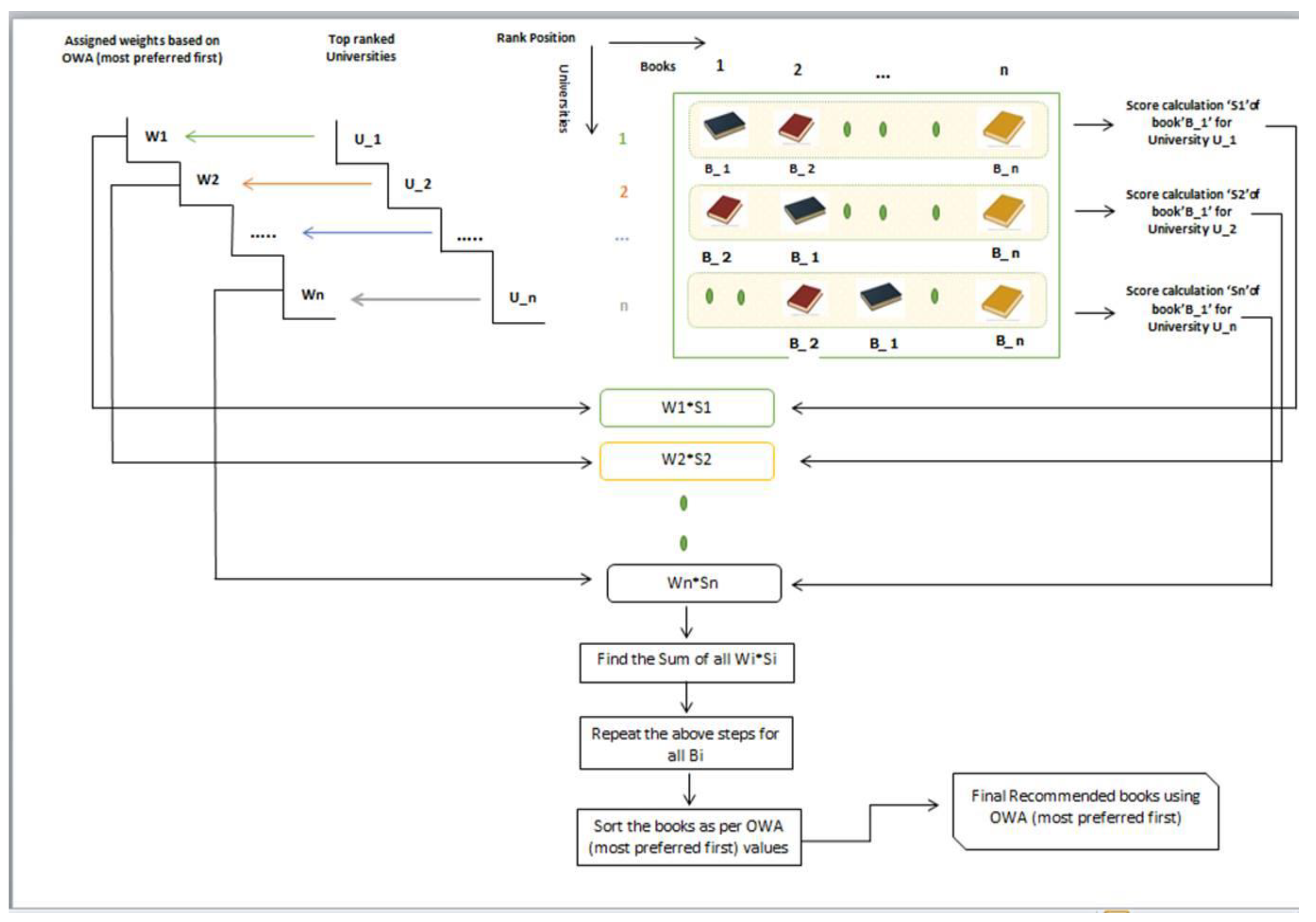
3. Proposed Recommendation Strategy Using OWA (Most Preferred First)
 ’ shows the course is available and ‘
’ shows the course is available and ‘ ’ indicates non-availability.
’ indicates non-availability.4. Results and Discussions
4.1. Evaluation Metrics
- i.
- P@10
- ii.
- FPR@10
- iii.
- FNR@10
- iv.
- Mean Average Precision (MAP)
- v.
- Mean Absolute Error (MAE)
- vi.
- Mean Reciprocal Rank (MRR)
- vii.
- Root Mean Square Error (RMSE)
- viii.
- Modified Spearman’s Rank Correlation Coefficient (MSRCC)
4.1.1. P@10
4.1.2. FPR@10
4.1.3. FNR@10
4.1.4. Mean Average Precision
4.1.5. Mean Absolute Error
4.1.6. Mean Reciprocal Rank
4.1.7. Root Mean Square Error
4.1.8. Modified Spearman’s Rank Correlation Coefficient
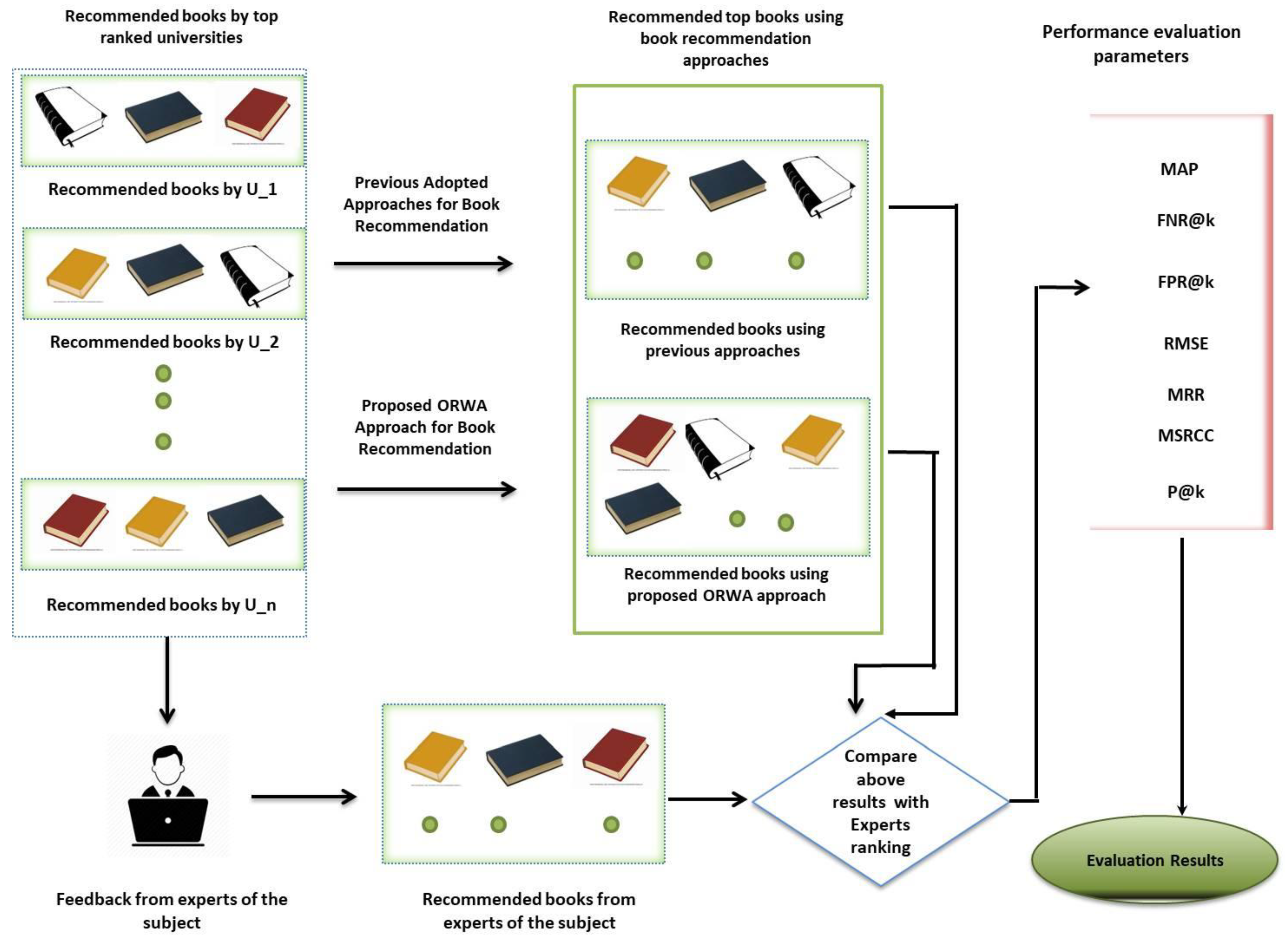
4.2. Experimental Results
Performance Evaluation Mechanism
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kacprzyk, J.; Yager, R.R.; Merigo, J.M. Towards human-centric aggregation via ordered weighted aggregation operators and linguistic data summaries: A new perspective on zadeh’s inspirations. IEEE Comput. Intell. Mag. 2019, 14, 16–30. [Google Scholar] [CrossRef]
- Qin, Y.; Qi, Q.; Shi, P.; Lou, S.; Scott, P.J.; Jiang, X. Multi-Attribute Decision-Making Methods in Additive Manufacturing: The State of the Art. Processes 2023, 11, 497. [Google Scholar] [CrossRef]
- Ahamad, G.; Naqvi, S.K.; Beg, M.M.S. An OWA-Based Model for Talent Enhancement in Cricket. Int. J. Intell. Syst. 2015, 31, 763–785. [Google Scholar] [CrossRef]
- Lee, M.-C.; Chang, J.-F.; Chen, J.-F. Fuzzy preference relations in group decision making problems based on ordered weighted averaging operators. Int. J. Artif. Intell. Appl. Smart Devices 2014, 2, 11–22. [Google Scholar]
- Yager, R. On ordered weighted averaging aggregation operators in multicriteria decisionmaking. IEEE Trans. Syst. Man Cybern. 1988, 18, 183–190. [Google Scholar] [CrossRef]
- Rinner, C.; Malczewski, J. Web-enabled spatial decision analysis using Ordered Weighted Averaging (OWA). J. Geogr. Syst. 2002, 4, 385–403. [Google Scholar] [CrossRef]
- Yager, R.R.; Kacprzyk, J.; Beliakov, G. Recent Developments in the Ordered Weighted Averaging Operators: Theory and Practice; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Yager, R.R.; Kacprzyk, J. The Ordered Weighted Averaging Operators: Theory and Applications; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Zhou, L.; Chen, H. A generalization of the power aggregation operators for linguistic environment and its application in group decision making. Knowl.-Based Syst. 2012, 26, 216–224. [Google Scholar] [CrossRef]
- Du, X.; Lu, K.; Nie, Y.; Qiu, S. Information Fusion Model of Group Decision Making Based on a Combinatorial Ordered Weighted Average Operator. IEEE Access 2023, 11, 4694–4702. [Google Scholar] [CrossRef]
- Sohail, S.S.; Siddiqui, J.; Ali, R. An OWA-Based Ranking Approach for University Books Recommendation. Int. J. Intell. Syst. 2017, 33, 396–416. [Google Scholar] [CrossRef]
- Yager, R.R. Using fuzzy measures for modeling human perception of uncertainty in artificial intelligence. Eng. Appl. Artif. Intell. 2019, 87, 103228. [Google Scholar] [CrossRef]
- Yager, R.R. OWA aggregation with an uncertainty over the arguments. Inf. Fusion 2019, 52, 206–212. [Google Scholar] [CrossRef]
- Ahn, B.S. The OWA Aggregation With Uncertain Descriptions on Weights and Input Arguments. IEEE Trans. Fuzzy Syst. 2007, 15, 1130–1134. [Google Scholar] [CrossRef]
- Kacprzyk, J.; Zadrożny, S. Towards a general and unified characterization of individual and collective choice functions under fuzzy and nonfuzzy preferences and majority via the ordered weighted average operators. Int. J. Intell. Syst. 2008, 24, 4–26. [Google Scholar] [CrossRef]
- Emrouznejad, A.; Marra, M. Ordered Weighted Averaging Operators 1988-2014: A Citation-Based Literature Survey. Int. J. Intell. Syst. 2014, 29, 994–1014. [Google Scholar] [CrossRef] [Green Version]
- Malczewski, J.; Rinner, C. Exploring multicriteria decision strategies in GIS with linguistic quantifiers: A case study of residential quality evaluation. J. Geogr. Syst. 2005, 7, 249–268. [Google Scholar] [CrossRef]
- Herrera, F.; Herrera-Viedma, E.; Verdegay, J. A model of consensus in group decision making under linguistic assessments. Fuzzy Sets Syst. 1996, 78, 73–87. [Google Scholar] [CrossRef]
- Yager, R.R. Multicriteria Decision-Making Using Fuzzy Measures. Cybern. Syst. 2015, 46, 150–171. [Google Scholar] [CrossRef]
- Kacprzyk, J.; Zadrożny, S. Linguistic summarization of the contents of Web server logs via the Ordered Weighted Averaging (OWA) operators. Fuzzy Sets Syst. 2016, 285, 182–198. [Google Scholar] [CrossRef]
- Yager, R.R. Applications and extensions of OWA aggregations. Int. J. Man-Mach. Stud. 1992, 37, 103–122. [Google Scholar] [CrossRef]
- Beg, M.S. A subjective measure of web search quality. Inf. Sci. 2005, 169, 365–381. [Google Scholar] [CrossRef]
- Beg, M.S. User feedback based enhancement in web search quality. Inf. Sci. 2005, 170, 153–172. [Google Scholar] [CrossRef]
- Yager, R.R. Fuzzy logic methods in recommender systems. Fuzzy Sets Syst. 2003, 136, 133–149. [Google Scholar] [CrossRef]
- Yager, R.R. Intelligent social network analysis using granular computing. Int. J. Intell. Syst. 2008, 23, 1197–1219. [Google Scholar] [CrossRef]
- Malczewski, J. Ordered weighted averaging with fuzzy quantifiers: GIS-based multicriteria evaluation for land-use suitability analysis. Int. J. Appl. Earth Obs. Geoinf. 2006, 8, 270–277. [Google Scholar] [CrossRef]
- Rasmussen, B.M.; Melgaard, B.; Kristensen, B.; GIS for Decision Support Designation of Potential Wetlands. In Danish with English Summary; 2002. Available online: https://www.researchgate.net/publication/266078073_GIS_for_decision_support_designation_of_potential_wetlands_In_Danish_with_English_summary (accessed on 1 March 2023).
- Zabihi, H.; Alizadeh, M.; Langat, P.K.; Karami, M.; Shahabi, H.; Ahmad, A.; Said, M.N.; Lee, S. GIS Multi-Criteria Analysis by Ordered Weighted Averaging (OWA): Toward an Integrated Citrus Management Strategy. Sustainability 2019, 11, 1009. [Google Scholar] [CrossRef] [Green Version]
- Sohail, S.S.; Siddiqui, J.; Ali, R. Book Recommender System using Fuzzy Linguistic Quantifier and Opinion Mining. In ISTA 2016: Intelligent Systems Technologies and Applications; Advances in Intelligent Systems and, Computing; Corchado Rodriguez, J., Mitra, S., Thampi, S., El-Alfy, E.S., Eds.; Springer: Cham, Switzerland, 2016; Volume 530. [Google Scholar] [CrossRef]
- Merigó, J.M.; Gil-Lafuente, A.M. Decision making with the OWA operator in sport management. Expert Syst. Appl. 2011, 38, 10408–10413. [Google Scholar] [CrossRef]
- Yager, R. Multiple objective decision-making using fuzzy sets. Int. J. Man-Mach. Stud. 1977, 9, 375–382. [Google Scholar] [CrossRef]
- Xu, Z.S.; Yager, R.R. Dynamic intuitionistic fuzzy multi-attribute decision making. Int. J. Approx. Reason. 2008, 48, 246–262. [Google Scholar] [CrossRef] [Green Version]
- Yager, R. OWA Aggregation Over a Continuous Interval Argument With Applications to Decision Making. IEEE Trans. Syst. Man Cybern. Part B 2004, 34, 1952–1963. [Google Scholar] [CrossRef]
- Yager, R.R.; Gumrah, G.; Reformat, M.Z. Using a web Personal Evaluation Tool—PET for lexicographic multi-criteria service selection. Knowl.-Based Syst. 2011, 24, 929–942. [Google Scholar] [CrossRef]
- Makropoulos, C.; Butler, D. Spatial ordered weighted averaging: Incorporating spatially variable attitude towards risk in spatial multi-criteria decision-making. Environ. Model. Softw. 2006, 21, 69–84. [Google Scholar] [CrossRef]
- Ishibuchi, H.; Nozaki, K.; Yamamoto, N.; Tanaka, H. Selecting fuzzy if-then rules for classification problems using genetic algorithms. IEEE Trans. Fuzzy Syst. 1995, 3, 260–270. [Google Scholar] [CrossRef] [Green Version]
- Fernandez, A.; Herrera, F.; Cordon, O.; del Jesus, M.J.; Marcelloni, F. Evolutionary Fuzzy Systems for Explainable Artificial Intelligence: Why, When, What for, and Where to? IEEE Comput. Intell. Mag. 2019, 14, 69–81. [Google Scholar] [CrossRef]
- Couso, I.; Borgelt, C.; Hullermeier, E.; Kruse, R. Fuzzy Sets in Data Analysis: From Statistical Foundations to Machine Learning. IEEE Comput. Intell. Mag. 2019, 14, 31–44. [Google Scholar] [CrossRef]
- Wilbik, A.; Vanderfeesten, I.; Bergmans, D.; Heines, S.; Turetken, O.; van Mook, W. Towards a Flexible Assessment of Compliance with Clinical Protocols Using Fuzzy Aggregation Techniques. Algorithms 2023, 16, 109. [Google Scholar] [CrossRef]
- Zhou, S.-M.; Chiclana, F.; John, R.I.; Garibaldi, J.M. Type-1 OWA operators for aggregating uncertain information with uncertain weights induced by type-2 linguistic quantifiers. Fuzzy Sets Syst. 2008, 159, 3281–3296. [Google Scholar] [CrossRef] [Green Version]
- Zhou, S.-M.; John, R.I.; Chiclana, F.; Garibaldi, J.M. On aggregating uncertain information by type-2 OWA operators for soft decision making. Int. J. Intell. Syst. 2010, 25, 540–558. [Google Scholar] [CrossRef] [Green Version]
- Merigo, J.M. Probabilities in the OWA operator. Expert Syst. Appl. 2012, 39, 11456–11467. [Google Scholar] [CrossRef]
- Zhou, L.; Chen, H.; Liu, J. Generalized power aggregation operators and their applications in group decision making. Comput. Ind. Eng. 2012, 62, 989–999. [Google Scholar] [CrossRef]
- Hussain, W.; Merigo, J.M.; Gao, H.; Alkalbani, A.M.; A Rabhi, F. Integrated AHP-IOWA, POWA Framework for Ideal Cloud Provider Selection and Optimum Resource Management. IEEE Trans. Serv. Comput. 2021, 370–382. [Google Scholar] [CrossRef]
- Hussain, W.; Merigó, J.M.; Gil-Lafuente, J.; Gao, H. Complex nonlinear neural network prediction with IOWA layer. Soft Comput. 2023, 1–11. [Google Scholar] [CrossRef]
- Xu, Z.; Yager, R.R. Power-Geometric Operators and Their Use in Group Decision Making. IEEE Trans. Fuzzy Syst. 2009, 18, 94–105. [Google Scholar] [CrossRef]
- Sohail, S.S.; Siddiqui, J.; Ali, R. Book Recommendation technique using rank based scoring method. In Proceedings of the National Conference on Recent Innovations & Advancements in Information Technology (RIAIT-2014), BGSBU, Rajouri, India, 26–27 November 2014; pp. 140–146. [Google Scholar]
- Sohail, S.S.; Siddiqui, J.; Ali, R. A Novel Approach for Book Recommendation using Fuzzy based Aggregation. Indian J. Sci. Technol. 2017, 10, 1–30. [Google Scholar] [CrossRef] [Green Version]
- QS World Ranking. QS World University Rankings by Subject 2015—Computer Science & Information Systems. Available online: https://www.topuniversities.com/university-rankings/university-subject-rankings/2015/computer-science-information-systems (accessed on 20 February 2023).
- Sohail, S.S.; Siddiqui, J.; Ali, R. A comprehensive approach for the evaluation of recommender systems using implicit feedback. Int. J. Inf. Technol. 2018, 11, 549–567. [Google Scholar] [CrossRef]
- Sohail, S.S.; Siddiqui, J.; Ali, R. Feature-Based Opinion Mining Approach (FOMA) for Improved Book Recommendation. Arab. J. Sci. Eng. 2018, 43, 8029–8048. [Google Scholar] [CrossRef]
- Sohail, S.S.; Siddiqui, J.; Ali, R. Book recommendation system using opinion mining technique. In Proceedings of the 2013 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Mysore, India, 22–25 August 2013; pp. 1609–1614. [Google Scholar]
- Bylinskii, Z.; Judd, T.; Oliva, A.; Torralba, A.; Durand, F. What do different evaluation metrics tell us about saliency models? IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 740–757. [Google Scholar] [CrossRef] [Green Version]
- Shani, G.; Gunawardana, A. Evaluating Recommendation Systems. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Kantor, P., Eds.; Springer: Boston, MA, USA, 2011; pp. 257–297. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank Position | University Name |
|---|---|
| 1 | IIT, Bombay |
| 2 | IIT, Delhi |
| 3 | IIT, Kanpur |
| 4 | IIT, Madras |
| 5 | IISC, Bangalore |
| 6 | IIT, Kharagpur |
| 7 | IIT, Roorkee |
| Sequence | Course Title | Univ_1 | Univ_2 | Univ_3 | Univ_4 | Univ_5 | Univ_6 | Univ_7 |
|---|---|---|---|---|---|---|---|---|
| 1. | Artificial Intelligence | | | | | | | |
| 2. | Compiler Design | | | | | | | |
| 3. | Computer Networks | | | | | | | |
| 4. | Discrete Mathematics | | | | | | | |
| 5. | Data Structure | | | | | | | |
| 6. | Graphics | | | | | | | |
| 7. | Operating Systems | | | | | | | |
| 8. | Principles of Database Systems | | | | | | | |
| 9. | Software Engineering | | | | | | | |
| 10. | Theory of Computation | | | | | | | |
| Rank Position | U1 | U2 | U3 | U4 | U5 | U6 | U7 |
|---|---|---|---|---|---|---|---|
| 1st | DS1 | DS2 | DS4 | DS9 | DS12 | DS9 | DS15 |
| 2nd | x | DS3 | DS5 | DS1 | DS8 | DS14 | DS16 |
| 3rd | x | x | DS6 | DS10 | DS13 | DS10 | x |
| 4th | x | x | DS7 | DS11 | DS3 | x | x |
| 5th | x | x | DS8 | x | x | x | x |
| 6th | x | x | x | x | x | x | x |
| 7th | x | x | x | x | x | x | x |
| 8th | x | x | x | x | x | x | x |
| 9th | x | x | x | x | x | x | x |
| 10th | x | x | x | x | x | x | x |
| Book Code | U1 | U2 | U3 | U4 | U5 | U6 | U7 |
|---|---|---|---|---|---|---|---|
| DS.1 | 1 | 0 | 0 | 0.9375 | 0 | 0 | 0 |
| DS.2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| DS.3 | 0 | 0.9375 | 0 | 0 | 0.8125 | 0 | 0 |
| DS.4 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| DS.5 | 0 | 0 | 0.9375 | 0 | 0 | 0 | 0 |
| DS.6 | 0 | 0 | 0.875 | 0 | 0 | 0 | 0 |
| DS.7 | 0 | 0 | 0.8125 | 0 | 0 | 0 | 0 |
| DS.8 | 0 | 0 | 0.75 | 0 | 0.9375 | 0 | 0 |
| DS.9 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| DS.10 | 0 | 0 | 0 | 0.875 | 0 | 0.875 | 0 |
| DS.11 | 0 | 0 | 0 | 0.8125 | 0 | 0 | 0 |
| DS.12 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| DS.13 | 0 | 0 | 0 | 0 | 0.875 | 0 | 0 |
| DS.14 | 0 | 0 | 0 | 0 | 0 | 0.9375 | 0 |
| DS.15 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| DS.16 | 0 | 0 | 0 | 0 | 0 | 0 | 0.9375 |
| Ranked University | Weights Assigned |
|---|---|
| Univ_1 | W1 = 0.25 |
| Univ_2 | W2 = 0.21428 |
| Univ_3 | W3 = 0.17857 |
| Univ_4 | W4 = 0.14285 |
| Univ_5 | W5 = 0.10714 |
| Univ_6 | W6 = 0.07142 |
| Univ_7 | W7 = 0.03571 |
| Rank Position | Book Code | Score Obtained Using OWA (Most Preferred First) Techniques |
|---|---|---|
| 1st | DS.9. | 0.4642 |
| 2nd | DS.1. | 0.450813 |
| 3rd | DS.3. | 0.408413 |
| 4th | DS.10. | 0.406175 |
| 5th | DS.8. | 0.395025 |
| 6th | DS.4. | 0.25 |
| 7th | DS.12. | 0.25 |
| 8th | DS.15. | 0.25 |
| 9th | DS.5. | 0.234375 |
| 10th | DS.14. | 0.234375 |
| 11th | DS.16. | 0.234375 |
| 12th | DS.6. | 0.21875 |
| 13th | DS.13. | 0.21875 |
| 14th | DS.2. | 0.2142 |
| 15th | DS.7. | 0.203125 |
| 16th | DS.11. | 0.203125 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sohail, S.S.; Aziz, A.; Ali, R.; Hasan, S.H.; Madsen, D.Ø.; Alam, M.A. Human-Centric Aggregation via Ordered Weighted Aggregation for Ranked Recommendation in Recommender Systems. Appl. Syst. Innov. 2023, 6, 36. https://doi.org/10.3390/asi6020036
Sohail SS, Aziz A, Ali R, Hasan SH, Madsen DØ, Alam MA. Human-Centric Aggregation via Ordered Weighted Aggregation for Ranked Recommendation in Recommender Systems. Applied System Innovation. 2023; 6(2):36. https://doi.org/10.3390/asi6020036
Chicago/Turabian StyleSohail, Shahab Saquib, Asfia Aziz, Rashid Ali, Syed Hamid Hasan, Dag Øivind Madsen, and M. Afshar Alam. 2023. "Human-Centric Aggregation via Ordered Weighted Aggregation for Ranked Recommendation in Recommender Systems" Applied System Innovation 6, no. 2: 36. https://doi.org/10.3390/asi6020036
APA StyleSohail, S. S., Aziz, A., Ali, R., Hasan, S. H., Madsen, D. Ø., & Alam, M. A. (2023). Human-Centric Aggregation via Ordered Weighted Aggregation for Ranked Recommendation in Recommender Systems. Applied System Innovation, 6(2), 36. https://doi.org/10.3390/asi6020036