1. Introduction
Modeling the behavior of electromagnetic waves in free space and also in complex media is well-known to be an involved procedure that requires the concurrent solution of Maxwell’s equations with the Schrödinger wave equation in order to fully capture the wave behavior under time-varying electron dynamics [
1,
2,
3,
4]. Various computational methods, such as the Finite-Difference Time-Domain (FDTD) Method, Finite Element Method, Method of Moments, Discontinuous Galerkin Method, etc., have been proposed for solving the Maxwell equations in simple and complex media [
5,
6,
7]. These methods vary in their success in capturing electromagnetic wave behavior in spatial and temporal domains through media that are simple and complex (bi-anisotropic, in-homogenous, nonlinear, etc.).
Under an interaction medium with slowly varying electron dynamics, solving the Maxwell equation is usually sufficient, in which case the electron dynamics can be modeled using the rate equations. The most commonly used method for dealing with complex media in microwave theory, optics, and photonics is the FDTD method. The FDTD method, besides being theoretically simple, is straightforward to implement computationally and can be applied to model wave dynamics in almost all kinds of complex media [
5]. However, the FDTD method is limited in its ability to model geometrically complex media or media with rough surfaces and significant shape irregularities. In this study, we will focus on using the FDTD method for modeling the light–matter interaction (LMI) process in nonlinear dispersive media, typically encountered in optics/photonics.
To model the behavior of light, we use the wave equation derived from Maxwell’s equations by substituting the equation for Ampere’s law into the equation for Faraday’s law [
5,
7]. The dynamics of the electrons are accounted for via the polarization term (also involved in the wave equation) [
8,
9,
10,
11,
12], which is modeled using the Lorentz dispersion equations [
5,
6]. The wave equation and the Lorentz dispersion equations are coupled to each other through the polarization term [
7]. Under a particle-based treatment of the electrons, the electron dynamics are modeled using the rate equations, helping to identify the population of electrons at each energy level in the medium [
5]. The set of all coupled differential equations is modeled based on the FDTD discretization. Importantly, the stability of the numerical solutions relies heavily on the preciseness of the spatial and temporal FDTD discretization. If the discretization step size is too large in the temporal domain, then the solutions can become unstable, meaning that the model can produce non-physical values that jump to infinity [
5,
6,
7]. Hence, for the stability of the numerical solutions, it is very important to choose a sufficiently small temporal step size. Note that the temporal step size must be selected in accordance with the spatial step size. This is because one would be interested in capturing every detail of the propagating light wave through the spatial domain of the involved medium, and for that, the spatial step size should be selected as small (how small depends on the medium properties and the desired resolution of the light wave). Once an adequately small spatial step size is determined, the corresponding temporal step size must satisfy the Courant stability criterion, which states that the temporal step size must be smaller than the spatial step size divided by the speed of light
c in free space
[
5,
6,
7]. Given this condition, one is left with the conclusion that in order to simulate and predict the light behavior in complex media with high spatial resolution over a long duration, one must select the temporal and spatial step sizes to be very small, which leads to an enormous computational cost [
10,
11,
12].
Here a major problem occurs because the wavelength of optical waves (mid-infrared–visible–ultraviolet–X-ray) is quite small, often less than 1 µm [
13,
14]. However, many optical phenomena, such as four-wave mixing and parametric amplification, produce a noticeable effect on the macroscale, which is usually much greater than 1 mm. In addition, some optical phenomena, such as interference and laser build-up in a cavity (
Figure 1), are only noticeable after relatively long durations (microseconds or milliseconds) [
15,
16]. In such cases, modeling wave dynamics is a substantial challenge [
17,
18] which demands the use of supercomputers even under the use of a simple computational algorithm such as FDTD. Therefore, this study aims to come up with a cost-effective alternative solution that extrapolates the solution after a small amount of simulation time.
To achieve this, we resort to deep learning, which can uncover all features of the underlying problem based on a given input-output dataset [
19,
20,
21,
22]. Here, we initially define and numerically solve a given problem using the FDTD method under an ultra-fine grid size to ensure stability. Then, for a given input dataset, we achieve an output dataset for a limited simulation duration. We use multilayer perceptrons to form a deep neural network whose coefficients evolve throughout the simulation. After identifying all the coefficients that connect the artificial neurons at each time step, we extrapolate the problem for longer durations by predicting the future values of the network coefficients from their temporal behavior and compare the extrapolated solution with the one that would be attained by running the simulation for the same amount of time for error quantification. Our deep learning model is based on a series of linear-time-invariant (LTI) system expansions that are based on the segmentation of the training data (partitioning of the entire signal data), assuming that the system response changes slowly in time with respect to the period/frequency of the analyzed light wave (which is usually the case in practice) over each of these segments. This is quite accurate because the mathematical model of a multilayer perceptron reduces to multiple LTI system expansions for slowly time-varying systems over segmented training data, where a system can also be approximated as linear [
5,
6]. Consequently, we use the identified LTI system coefficients at each layer and record their values for all times to extrapolate the wave behavior for longer durations and measure the corresponding extrapolation error by comparing the extrapolated results with the ones obtained via simulation.
Deep learning is based on multilayer neural networks that relate the input data to the output data through a series of coefficient values via inner-product operation [
23,
24,
25,
26,
27,
28,
29,
30,
31,
32]. Due to the dramatic increase in the processing power of computers, in the last few decades machine learning has been applied extensively in the field of optics and photonics as it has also been in many other fields [
27,
28,
29]. Over the years, a huge number of papers have focused on machine learning algorithms to uncover hidden physical models in electromagnetics [
23,
24,
25,
26,
27,
28,
29]. Notably, research papers that apply machine learning algorithms to predict the nonlinear dynamics of optical systems have received strong attention. These papers have successfully modeled optical systems as robust neural networks that can imitate the behavior of the underlying system with ultimate precision [
23,
24,
25,
26,
27,
28,
29,
30,
31,
32]. A striking observation in many of these papers is that the concern is to identify the originally unknown system within the duration of the performed experiments with no extrapolation of the system coefficients for predicting future system behavior. This is problematic because the input signal characteristics often change, leading to a response that differs from the trained model. This unpredictability forms the core challenge in forecasting system behavior, highlighting a crucial battle between traditional machine learning and advanced deep learning algorithms. Deep learning, distinguished from machine learning by its use of multiple layers, offers a solution to this challenge. Each additional layer in a deep learning model extracts more nuanced features of the underlying system, enhancing the model’s predictive capabilities. Predicting the future weights of each layer enables more accurate predictions of subsequent layers’ weights and, consequently, the future samples of an output dataset. This approach requires the adaptive identification of network coefficients over time, segment by segment, a process we refer to as dynamic deep learning. In this study, we will apply dynamic deep learning to both accelerate and predict complex light–matter interaction (LMI) scenarios where conventional prediction methods fall short, enabling accurate and cost-effective simulations in the field of optics and photonics.
2. Methods
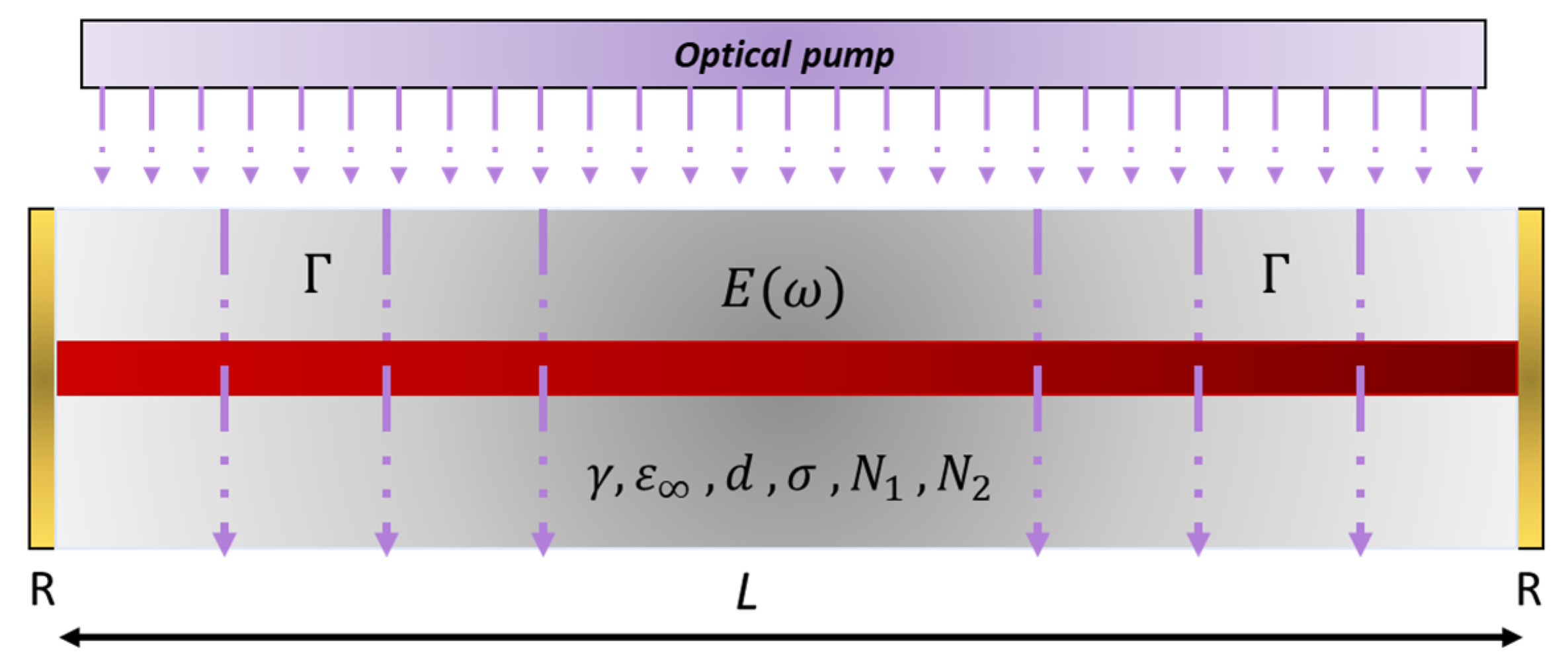
2.1. FDTD-Based LMI Model Based on Two Energy Levels
We first investigate the case where photons and electrons interact based on two energy levels with the corresponding frequencies
and
. In this case, there are only two transitions, which are
and
. Correspondingly, there is only one transition frequency, which is
. Hence, the polarization density goes into resonance only at this frequency. When the interaction material has a single electronic transition frequency, upon excitation of the interaction medium via an optical beam of electric field intensity E, the corresponding wave, polarization, and electron dynamics are modeled as follows [
5,
6,
7].
E: Electric field, μ0: Free space permeability, ε∞: Background permittivity, t: Time, h: Planck constant, σ: Conductivity, P: Polarization density, γR: Polarization damping rate, ωR: Angular resonance frequency, N1: Electron density at the first level, N2: Electron density at the second level, τ21: Transition lifetime (level 2 to level 1), d: Atom diameter, me: Electron mass, e: Elementary charge, and Γ: Electron pump rate.
Here, Equation (1) represents the electric field wave equation for isotropic media that can be easily derived from equations representing Ampere’s Law and Faraday’s Law (also known as Maxwell’s First and Second Equations) [
5]. Equation (2) is the famous Lorentz dispersion equation, which governs the temporal behavior of the polarization density of bound electrons under electric field excitation. The Lorentz dispersion equation is analogous to the spring model, which describes the position of a mass that is attached to a spring on which a certain amount of force is exerted. In this case, the electrons are under damped oscillation due to the force that is exerted by the atomic nucleus and the electric field. The damping occurs mainly due to collisions with other electrons. Equations (3) and (4) represent the electron populations at level 1 (ground level) and level 2 (excited level). Since the polarization density in Equation (2) is created by the electron population difference between level 1 and level 2, and since the electric field intensity in Equation (1) depends on the polarization density (which is the source term), Equations (1)–(4) are coupled to each other and must be solved simultaneously. The situation is more complicated in an interaction medium with more energy levels (see next section).
2.2. FDTD-Based LMI Model Based on Three Energy Levels
If there are three energy levels involved in the electron/photon dynamics, then the interaction medium can have six different electron transitions and three electron transition frequencies (, , and ). In this case, the associated LMI process is governed by modified versions of Equations (1)–(4), which are given as follows:
Notice that in this case, the electric field wave equation (Equation (5)) is stimulated by three different polarization terms () which are governed by Equations (6)–(8), representing the dynamics of bound charge polarization densities as induced by each electronic transition. The electron populations at each level are modeled via Equations (9)–(11), which are coupled to the Lorentz dispersion equations (Equations (6)–(8)) through the source term and the nonlinear polarization terms. Hence, to solve for the electric field intensity, one must solve all seven equations (Equations (5)–(11)).
2.3. Numerical Discretization
The numerical discretization is carried out in 1D space, considering the case of a single transition based on two-level electron dynamics, using the FDTD method. The discretization for the three-level case is similar and straightforward. Here the electric field and the associated polarization density are discretized in space and time, whereas the electron populations are discretized only in time as it is assumed that the interaction medium is homogenous in density over space. The FDTD discretization of Equations (1)–(4) is carried out as follows [
5]:
Notice that we are using the central difference approximation for the first derivatives in time and space and applying the standard formulation for the second derivatives.
These discretized equations are solved together with the initial and boundary conditions of a given problem, which will be stated in the analyzed cases in
Section 3. For the stability of the numerical solutions, the time step
must be chosen to be smaller than the spatial step divided by the speed of light in free space (
, which is known as the Courant condition [
5].
2.4. Multilayer-Perceptron-Based Neural Networks for Modeling 1D Light-Matter Interaction under the Slowly Varying Envelope Approximation
The FDTD simulations generate an output dataset for each input dataset given by the user. To process these input/output datasets for modeling the underlying system, we consider the simplest neural network that can be mathematically expressed through plain matrix multiplication between the network weights and the input data. In matrix notation, the output data
of a single-layer neural network are expressed in terms of the given input data x (we use brackets for representing network weights and parenthesis for input/output data).
where
is the coefficient matrix containing the weights that connect/relate the network nodes, and the activation operator
can be either a linear or a nonlinear operator that transforms the elements of the result vector of the matrix multiplication to fit within a certain range in accordance with the analyzed problem and the underlying system.
For a given output sample
, Equation (16) can also be expressed via the following summation term:
In system theory, Equation (17) represents the response of a nonlinear time-varying (NTV) system [
33,
34]. For slowly (time) varying systems, an NTV system can be approximated as a linear time-invariant (LTI) system within narrow time intervals, in which case Equation (17) can be expressed by the time shift between the input and output samples in the form of a convolution operation [
34]:
which can be rewritten as a matrix equation (
is now an identity operator):
Equation (19) has much fewer unknowns to solve for (compared to Equation (16)), as the weight (unknown) matrix can now be vectorized as a time shift vector. For this reason, the LTI system approximation provides a great reduction in the computational cost for slowly time-varying systems that are trained gradually over small data segments [
35,
36,
37,
38] (see
Section 2.5).
In this study, we extend the formulation in Equation (19) for a three-layer neural network, which is considered as a deep learning network with two hidden layers. The use of hidden layers provides more accuracy in determining all features of a given system. In this case, the input–output relationship is modified as follows:
Based on Equation (20), one can deduce that each output sample is related to the input samples through the following mathematical relation:
Just as in the case for a single-layer network, assuming a slowly time-varying system and using small segments of training data, Equation (21) can be expressed in terms of the time shift between the input and output samples over each given training segment (LTI system approximation), which is represented as a serial convolution operation between the network weights and the input data:
in which case the activation functions are identity operators. In this study, we will base our approach on Equation (22) to train a 3-layer network for identifying the systems that govern an LMI process.
2.5. Segmentation of a Given Input/Output Dataset for Neural Network Training
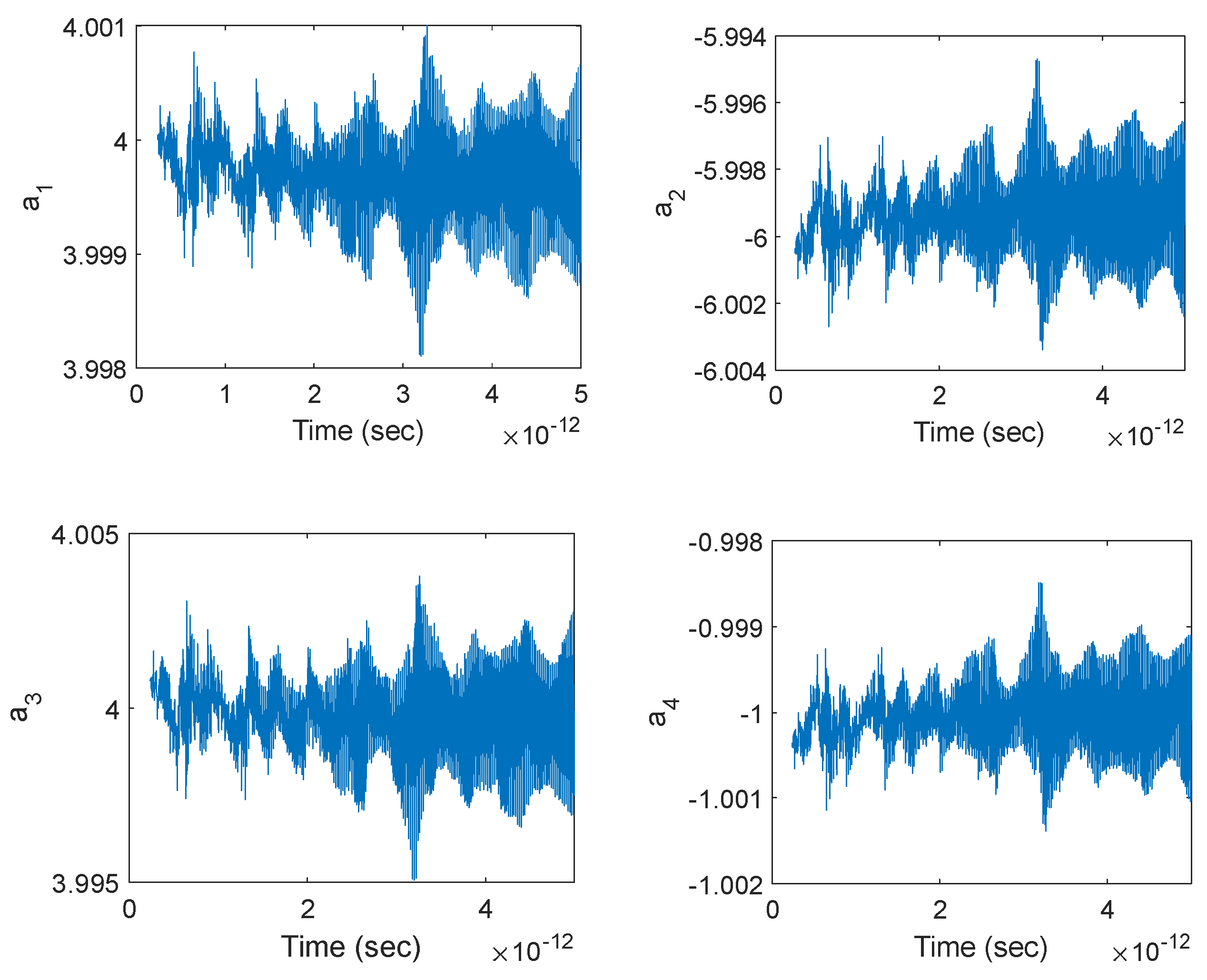
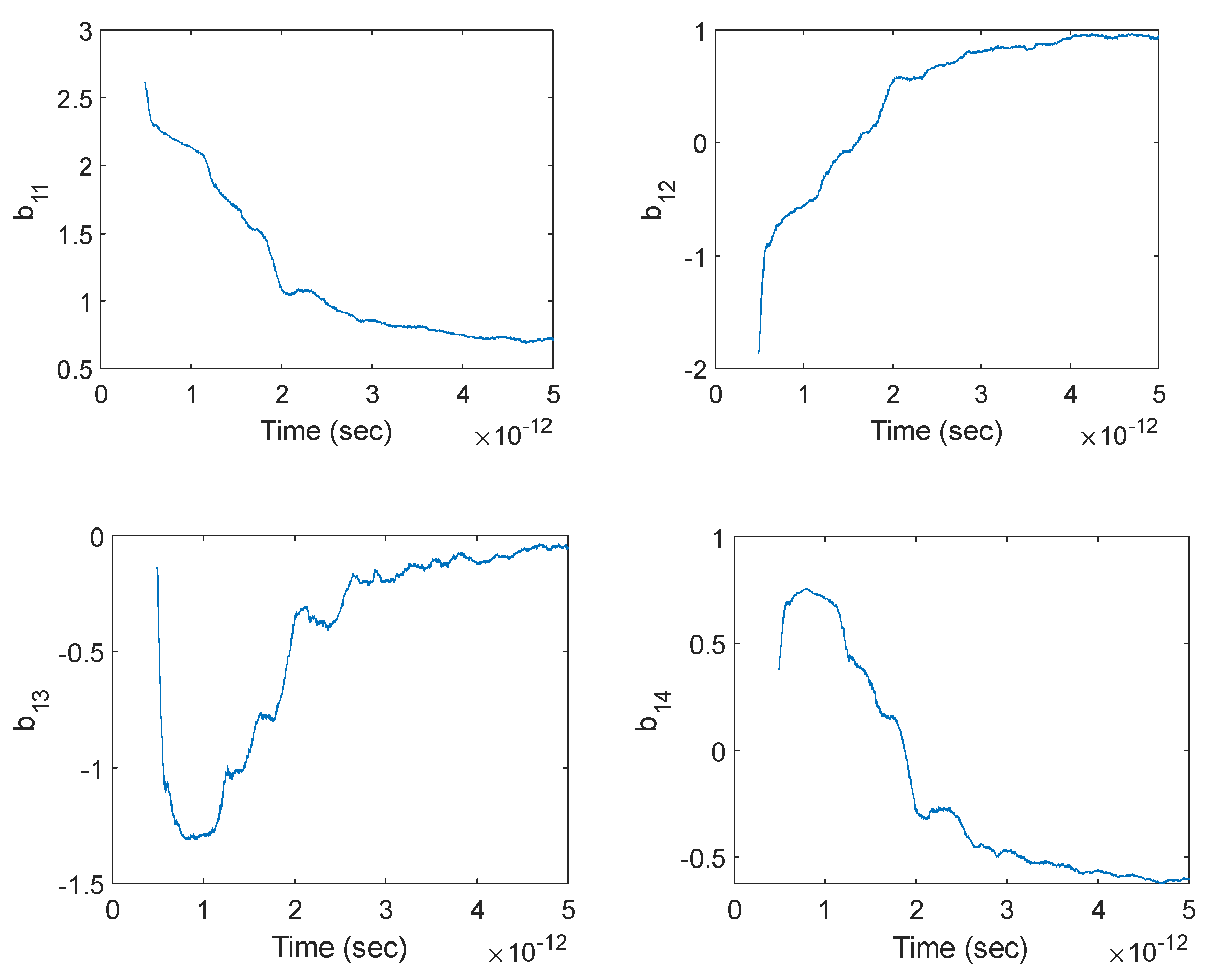
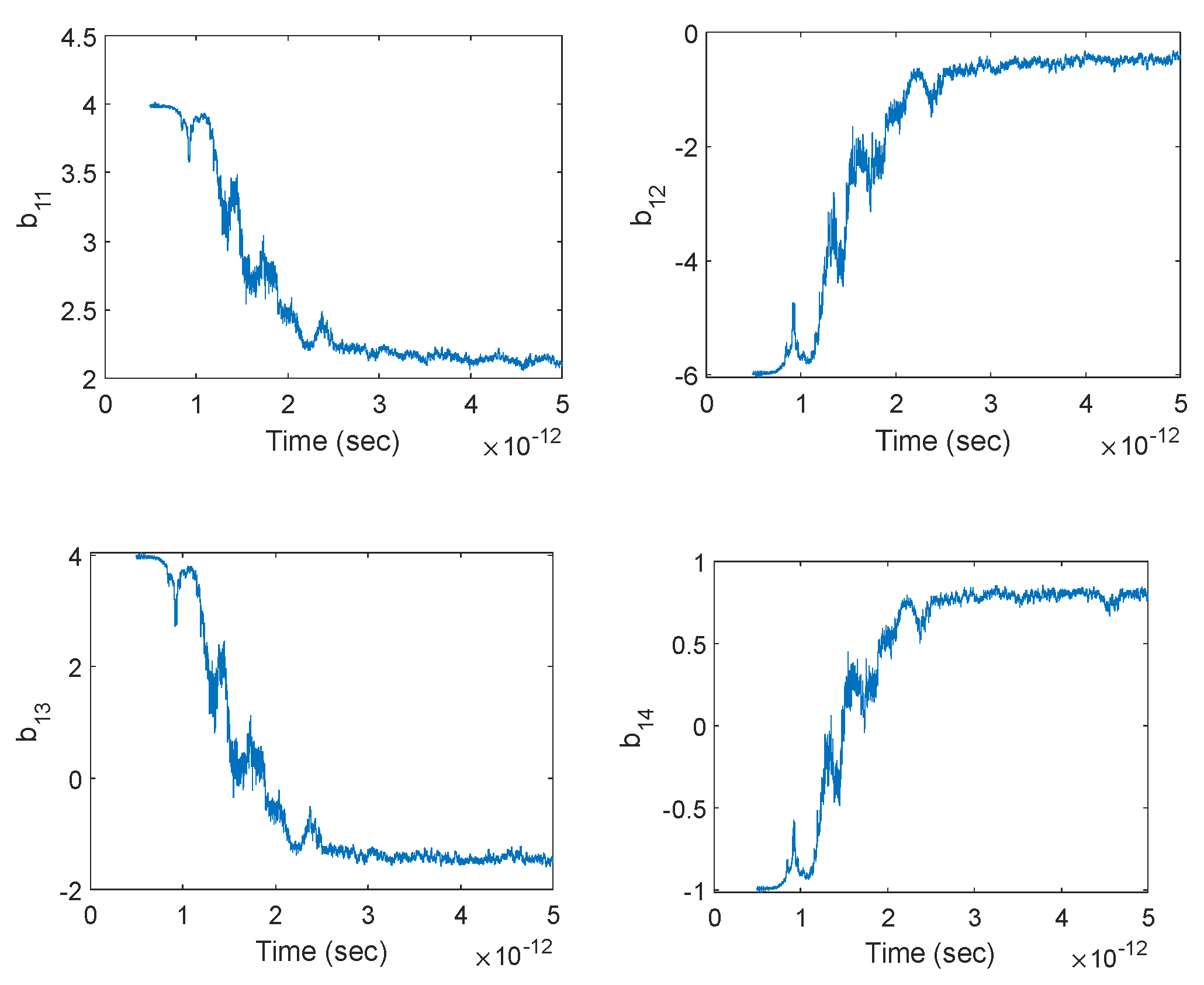
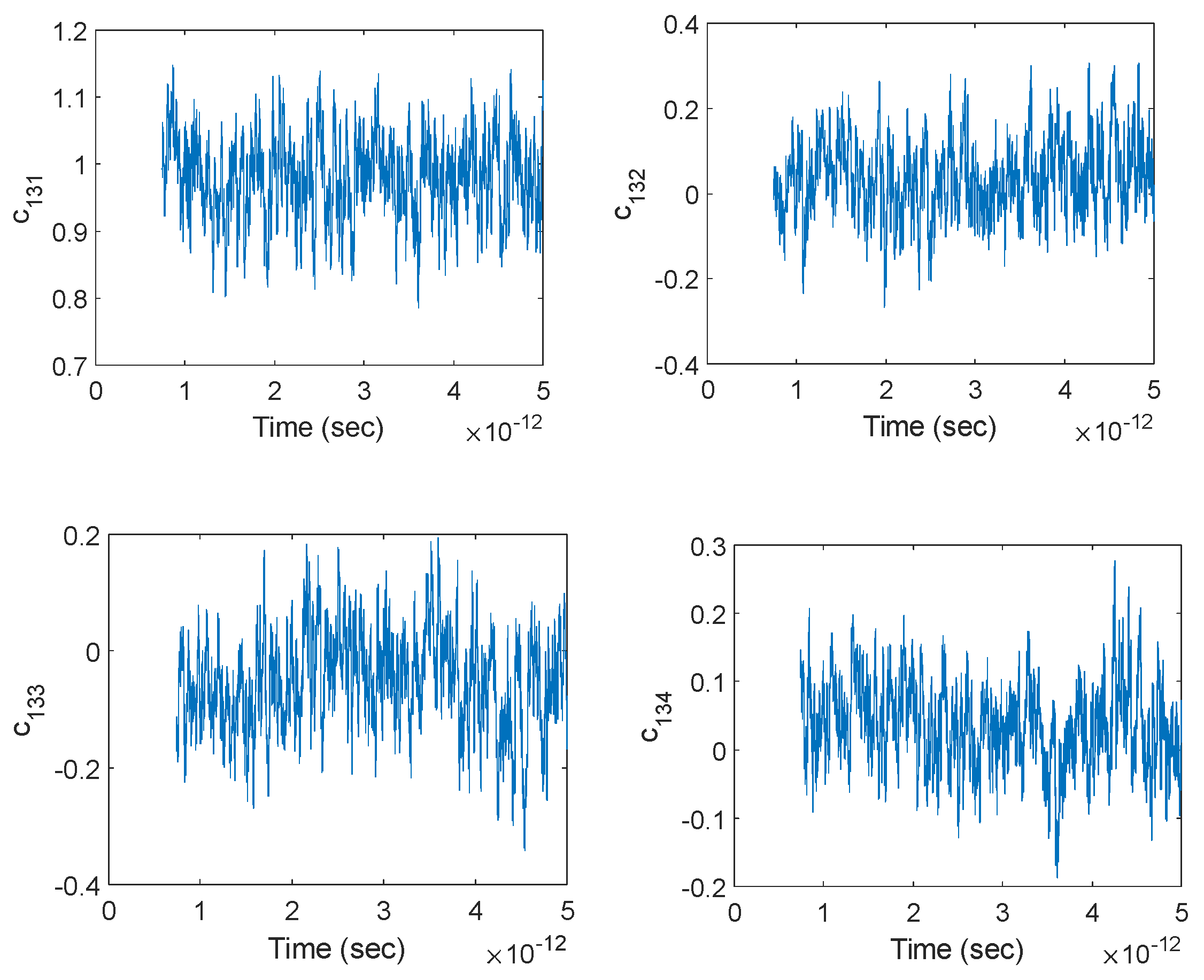
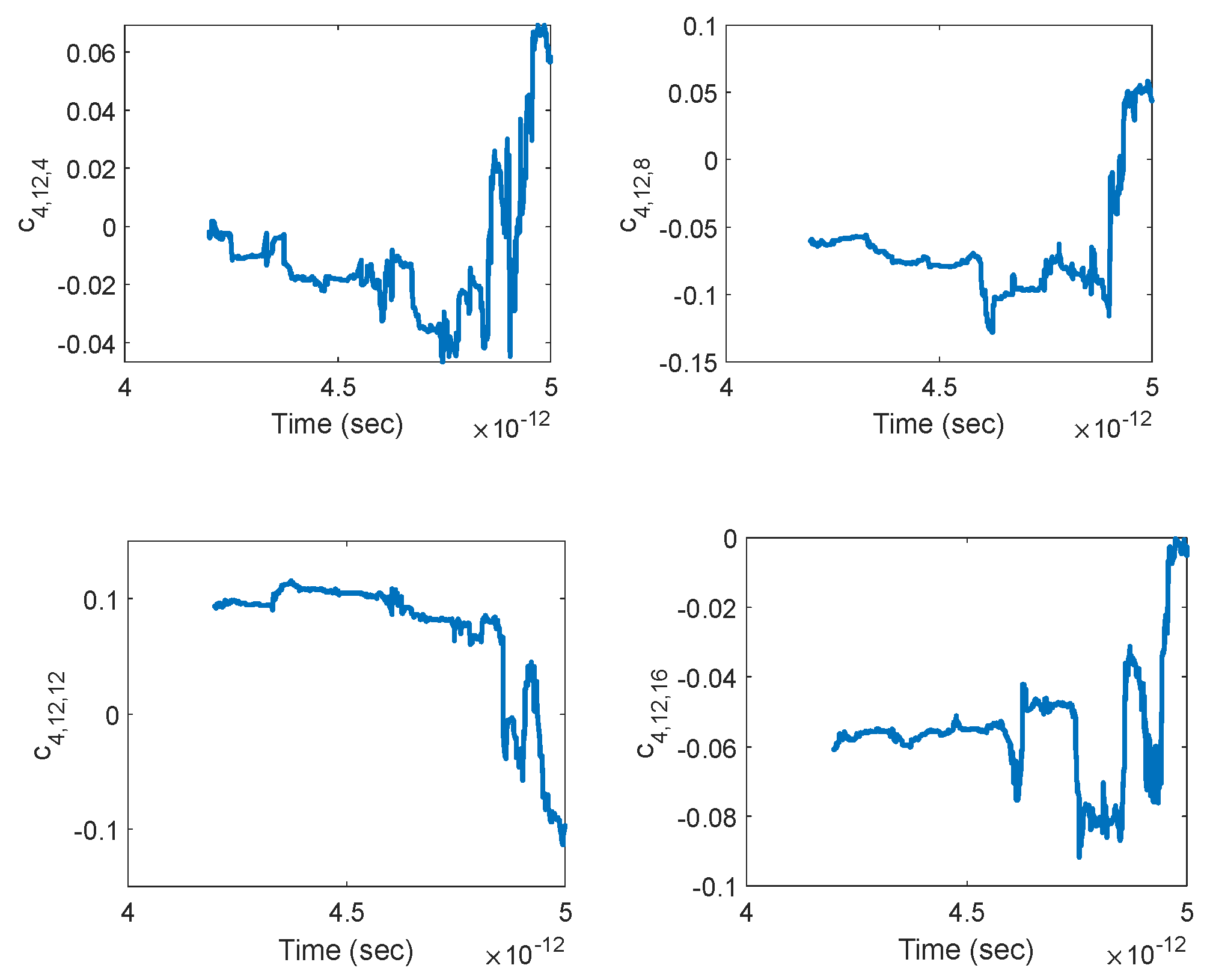
In order to evaluate the weights of the three-layer neural network adaptively using many narrow time intervals, one has to divide a given signal into many small segments, each containing M samples that can be used to train the neural network for identifying the local behavior of the underlying system. Each segment should be small compared to the size of the entire signal so that both the linearity and the slowly time-varying system approximation can be made. By computing the coefficients of a 3-layer network at each and every segment and then combining them, one can determine the temporal evolution of the coefficients (thus the network) through the duration of the entire signal, thereby performing dynamic deep learning that facilitates a self-learning network for precise prediction of future output values even under very limited input data. The segmentation can be performed in different ways, as stated below.
Under this segmentation, all segments are adjacent to each other and there is no overlap between them. If the entire signal
is divided into
P segments, this is stated as follows:
For this case, the segments may or may not be overlapping depending on N and M:
If N < M, the overlap ratio is
. Whereas if N > M, then the overlap ratio is zero. However, if N is much larger than M, then many samples remain idle, which leads to an inefficient use of data. Hence, if no overlap is desired, one should choose N = M.
Here, the overlap ratio is . This means that each subsequent segment is nearly identical to its neighbor but not completely the same. This is an efficient use of data in cases where the underlying system is strongly time-variant. Whereas if the system is weakly time-variant, this can cause the unnecessary creation of new segments, which would bring little new information about the system (a slow update of the neural network weights would be sufficient) at the cost of drastically increased computation time.
In this scenario, each consecutive segment differs only through a single sample shift. This means that subsequent segments totally overlap with each other, except for a single sample such that
This form of segmentation (
Figure 2) enables a very efficient use of data under fast time-variation of the system coefficients. Despite our assumption of a slowly time-varying system, we will make use of this segmentation for a sample-by-sample computation of the neural network coefficients in order to see their temporal evolution in full resolution.
Under such sample-by-sample segmentation, to predict the upcoming samples of the output vector y, one has to solve for the set of coefficients at each layer and for each estimated sample. This means that to predict N future samples, the coefficient vectors
must be solved based on Equation (22), which can be expanded as three consecutive matrix multiplications:
where
x is the input vector and {
q,
z} are intermediate outputs that ultimately yield the output vector y. Simplified forms of Equations (26)–(29) will be referred to for carrying out the dynamic coefficient (system) identification procedures in the next section based on the least-squares method, using sample-by-sample segmentation under the use of linear operators. Note that Equations (26)–(28) imply
.
2.6. Training of the Multilayer Perceptron over Each Data Segment Based on Output Data
The system coefficients can be evaluated solely based on past samples of the output data
. Hence, one does not necessarily need the input data to perform a prediction. Also, one can simply use Equation (22) over each training segment where nonlinear operators are not required due to the limited size of the involved segment. By re-labeling the coefficients as a, b, and c, Equation (22) can be rewritten as follows (note that
x[m] is replaced with
y[m] as past samples of the output data are considered input signal samples in the case of prediction):
Using the following operational tricks, Equation (29) can be converted into Equation (36):
The good thing about Equation (36) is that it can be nicely decoupled into the following three equations:
where the output signal can be directly expressed in terms of its past values in a single equation.
Equations (37)–(39) can be rewritten using matrix equations that describe the prediction of N upcoming samples based on the past M samples (segmental training data):
Using Equation (40), one can solve for the set of
coefficients for the first layer via the least-squares method. The same goes for the second- and third-layer coefficients. The coefficient matrices always depend on the past values of the coefficients of the previous layer (
coefficients for the second layer and
coefficients for the first layer). Once all the coefficients for each layer are solved, future samples of y(n) can be predicted using sequential matrix updates and multiplication. However, Equations (40)–(42) do not yield the time-dependent values of the coefficients, which prevents the prediction of future values of the coefficients and hinders the adaptive prediction of future output samples. For a self-learning or self-adaptive neural network, the coefficients must evolve with each and every new sample so that the future values of the coefficients can also be predicted from their time series, enabling more accurate output signal prediction under the limited availability of input data. This enables a dynamic evolution of multilayer perceptrons through segmental training where each segment differs only via a single sample shift so that the coefficients are instantly adapted for an “infinitesimal” (unit sample) change. To attain the matrices that contain the time variation (past values) of the coefficients, every set of coefficients needs to be solved per new sample. Therefore, over each segment, the training of the network should be carried out as follows:
Using Equations (43)–(45), one can perform an adaptive prediction at every instantaneous sample of the output signal based on the 3-layer network. This requires the instantaneous solution of each set of coefficients through the least-squares method, as follows:
Therefore, once the coefficients over a certain segment are identified, the future samples of the output signal y can be predicted via Equation (48):
Note that the coefficient matrices are constructed from past samples of the coefficients themselves. Hence, once a certain coefficient vector (a, b) is solved, its coefficient matrix (A, B) is known, which enables the prediction in Equation (48).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




















