1. Introduction
Electricity transmission infrastructure is one of the four main causes of bushfires alongside lightning, arson and accidental fire escape [
1,
2]. Fires caused by electricity transmission infrastructure can be divided into those caused by equipment failure and those caused by interactions between powerlines and the surrounding vegetation. Although bushfires initiated by powerline–vegetation interactions are relatively infrequent compared with the other main causes of bushfires, they tend to occur on days with extreme fire weather conditions and are initiated closer to population centres, thus leading to comparatively larger burned areas and greater damage to lives and property [
1,
3,
4,
5]. Consequently, implementing measures to reduce bushfire risk associated with powerline–vegetation interactions has become a top priority for electricity network service providers. Such measures include improvements to network infrastructure (e.g., covered conductors) and actively managing vegetation on and near powerlines. However, committing to and implementing any of these intervention mechanisms requires meticulous planning due to costs, legal and socio-cultural issues, and the associated complexity of the powerline–environment interactions [
6]. Vegetation management planning requires risk estimates that are calculated at sufficiently fine spatio-temporal scales to allow the risk variation over networks to be considered. Direct estimation of the risks posed by powerline–vegetation interactions is difficult due to the rarity of these events; however, the problem can be approached by modelling the probability of events that led to fire events as these preceding events have considerably greater frequency. Consequently, in this paper, we focus on modelling ignition events that can be considered to have been the result of vegetation–powerline interactions.
The literature includes several attempts to model ignition events with a variety of causes at a fine spatio-temporal resolution. The general approach has been to formulate the problem as a bernoulli process, where the two mutually exclusive outcomes are ignition and no ignition [
7]. One study [
8] explored the potential of Logistic Regression and Decision Tree algorithms to convert satellite-derived Live Fuel Moisture Content (LFMC) into ignition probability for the Iberian Peninsula territory of Spain. Authors stated that Logistic Regression model, a form of Generalised Linear Model (GLM), performed the best as measured by a popular metric, Area Under the Curve (AUC), of over 0.65 for a section of the peninsula and an AUC of over 0.8 for the rest of the peninsula. Another study [
9] compared the predictive performance of three such algorithms namely, GLM, Random Forest and Maximum Entropy (MaxEnt), using 16 years of ignition data and environmental data for the Huron-Maanistee National Forest in Michigan, USA. Authors found that the two machine learning algorithms (MaxEnt and Random Forest) performed slightly better than GLM, which is a statistical model. Another study [
10] explored factors leading to ignition in the Sydney basin using a probabilistic modelling approach where a Generalised Additive Model (GAM) with a binomial distribution was the algorithm of choice. Authors compared the differences between known ignition locations and a set of randomly selected non-ignition locations in terms of topographic, vegetation and fire weather variables. The ability of GAMs to take into account the non-linear relationships between predictor variables was the main reason for its selection. The authors of [
11] modelled both human-caused and lightning-caused ignitions in the Australian state of Victoria using Random Forest occurring in native vegetation and cleared/urbanized land. This study demonstrated the utility of machine learning models in identifying relationships between ignitions and patterns of landscape and weather variables, with the models achieving prediction accuracy of between 86.4% and 90.3%.
Among studies that explore ignition events at a fine spatio-temporal scale, there are a limited number of studies that specifically look at the probability of ignitions caused by electricity networks [
12,
13,
14,
15]. One such study [
12] used data collected from multiple electrical distribution networks in Australia to calculate fault and subsequent ignition rates under different electrical infrastructure, landscape and weather scenarios. The study used empirical detection rates calculated from data categorized by different levels of explanatory variables. The study found that the variables most strongly associated with fault rates were wind speed and vegetation type and that the variable most strongly associated with ignition was Fire Danger Rating (FDR) and that this relationship was influenced by the cause of the fault. The importance of wind speed in determining fault rates for powerlines was also investigated by [
13], who found that increased wind speed leads to considerable increase in outage probability. Another study [
15] conducted a study of ignition modelling using data from the Pacific Gas and Electricity (PG&E) franchise in California at the feeder and day level of spatio-temporal resolution. The study investigated the predictive performance of logistic regression, random forests and gradient boosted trees together with different methods for dealing with the large class imbalance present in the data. The study found that the most effective algorithm and class imbalance method for modelling ignition probability was a combination of gradient boosted trees and majority class down-sampling and that the most influential features were various daily weather summaries derived from the Gridded Surface Meteorological dataset (gridMET) and vegetation features, as well as feeder length [
15].
The objective of this study is to develop a modelling framework for the causal chain from weather events that occur in different landscape and network contexts through to events that are characterized by vegetation falling onto or blowing onto powerlines (vegetation events) and subsequent ignition events. The framework is intended to be implemented in network management and planning activities and as such should provide event probability predictions that are calibrated to the actual rate of events on the network and that are calculated at a spatio-temporal scale that is convenient for the management and planning activities carried out by electricity distributors. An additional objective of the study is to identify the weather, landscape and network features that are related to the probability of both vegetation and ignition events across the network and to investigate the utility of Light Detection and Ranging (LiDAR) derived features in predicting these events.
We found that although ignitions are rare events, we were able to generate reasonably well performing models through adopting a two-step conditional probability approach that involved modelling vegetation events first and then modelling ignition events for all data for which vegetation events were observed. For the approach to succeed we also required two other technical modelling adjustments namely: majority class down-sampling and rare event correction. The framework allows us to estimate vegetation event and ignition event probability at any point in the network under different weather conditions and as such can be used for estimating expected ignition risk over arbitrary spatio-temporal windows. In addition, we are able to simulate events from the framework and thereby investigate the range of probable vegetation and ignition event frequencies under different weather, landscape and network conditions. We find that the major factors influencing vegetation events are weather variables including wind speed and rain followed by landscape variables such as vegetation and soil type, while network engineering variables appear to have a small influence. The major factors influencing ignition events that follow vegetation events are landscape features such as vegetation and soil type features followed by weather features such as the McArthur’s Forest Fire Danger Index (FFDI) and rainfall. As with the vegetation event model, network engineering features have a smaller impact, with bay length being the most influential engineering feature.
2. Materials and Methods
2.1. Study Area
Endeavour Energy (Endeavour) operates a power distribution network that spans 24,800 square kilometers across Sydney’s Greater West, Illawarra and the South Coast, Blue Mountains and Southern Highlands (
Figure 1). This particular area in New South Wales, which is dominated by sclerophyll forests, generally is considered fire-prone [
10]. For example, the area was subject to the “black summer fires” of 2019–2020, a fire event that resulted in 7.9 Mha of burnt land across south-eastern Australia and directly resulted in 33 deaths [
16]. The network covers a wide variety of land-use types including urban, rural and native bushland. Much of the network is located at the interface of urban areas and native bushland and as such the network carries a significant risk of high-impact fire events.
2.2. The Event Modelling Scale
The vegetation and ignition events were modelled at the bay/day scale. Bay refers the unit of an electricity network that includes a conductor or set of conductors that are between two poles. A day refers to a given 24 h period. Therefore, the modelling was concerned with estimating the probability of vegetation and consequent ignition events occurring within any particular bay on the network during a given day.
2.3. Event Variables
There are two primary response variables, namely the vegetation event, which is simply defined as vegetation contacting powerlines in some way, and the ignition event, which is defined as a fire that started on the network as a result of a vegetation event.
Vegetation events can be roughly categorized as “fall-ins”, “blow-ins” and “grow-ins”. In this paper we focus on “fall-ins” or “blow-ins”, these are events that involve vegetation falling onto or blowing onto powerlines and can be distinguished from “grow-in” events which involve vegetation growing into powerlines. Vegetation grow-in events are typically much rarer because routine maintenance of powerline easements tends to greatly reduce their frequency of occurrence. For the remainder of the paper the term vegetation event refers to a vegetation–powerline interaction that can be characterized as either a “fall-in” or “blow-in” event.
Ignition events are characterized as events that involve some level of ignition of combustible material either on or immediately adjacent to the network. We do not distinguish between events that completely remain on the network (e.g., Pole top fires) or those that spread to surrounding vegetation. In this study we only consider ignition events that can reasonably be attributed to vegetation events as described above.
Vegetation events that were recorded between the dates of 1 July 2012 and 4 April 2021 were extracted from Endeavour’s Incident Reporting Database. All incidents were selected regardless of whether the event resulted in a customer interruption.
Ignition events that were recorded between 1 July 2012 and 4 April 2021 were extracted from Endeavour’s Fire Investigations Database. The ignitions were filtered by only including ignitions that were caused by network-vegetation interactions. The ignition events were then matched to the identified vegetation fall-in and blow-in events based on spatio-temporal proximity thresholds.
2.4. Input Features
The model input features can be divided into three main categories, these being landscape, weather and network features (
Table 1). The landscape features were extracted from: a whole of network LiDAR analysis undertaken by helicopter; a Digital Terrain Model (DTM) for the network; and from Australian Government soil type and vegetation community maps. The network features were obtained from Endeavour’s Geographic Information System (GIS) database and the weather features were derived from half-hourly weather data obtained from the Australian Bureau of Meteorology (BOM). The same set of input features was used for both the vegetation and ignition event models.
The raw data for the weather features were sourced from BOM half hourly weather data from 20 weather stations within and near the Endeavour franchise area. The data were summarized at a daily level to match the temporal resolution of the response variables. For each bay, the nearest weather station was identified using a spatial join, and the weather data from the matching stations were assigned to bays.
In addition to basic daily weather variable summaries, the McArthur’s Forest Fire Danger Index [
17] (FFDI) was calculated. The FFDI was calculated using daily aggregations of half-hourly weather data obtained from the BOM (maximum temperature, sum of half hourly precipitation and average dew point). The Keetch–Byram Drought Index (KBDI) [
18,
19] was used to provide an estimate of soil dryness and the dew point was used to calculate relative humidity, this information was combined to estimate daily FFDI feature.
2.5. Data Preparation for Modelling
2.5.1. Dealing with Class Imbalance
The modelling data have highly imbalanced labels for the two response variables: vegetation event and ignition event (
Table 2). This is demonstrated by comparing the number of events recorded in
Table 2 with the number of day/bay combinations where no vegetation event or vegetation ignition related event took place, which is typically around 168 million for any given year. Vegetation events are typically not rare events within the context of the entire network; however, they are highly outnumbered by the negative class, i.e., no vegetation event for a given bay/day.
In order to overcome this class imbalance, we used the rare event sampling and prior correction strategy recommended by [
20], that is:
Include all the positive (minority) class in the sample;
Down-sample the much larger negative class using a random sample from the entire negative class population; and
Adjust for the introduced sample bias using the prior correction method.
The prior correction method works by introducing bias to the unconditional model estimate of the event probability through down-sampling of the majority class. This down-sampling roughly equilibrates the positive and negative class numbers and allows us to obtain unbiased estimates for the model parameters. Model predictions obtained from the trained model are then adjusted by a constant to take into account the effect of the down-sampling on the average prediction probability. The adjusted probabilities are derived as follows:
where:
For the current study, this method served two purposes, firstly, it reduced the size of the model training set to one that is more reasonable for model fitting, secondly it removed any biases that may result from the high level of class imbalance in the data.
2.5.2. Defining Training and Test Sets
The full data were split into a training set for model training and validation and a separate test dataset. This allows us to train a model using just the training dataset, and independently verify if the model generalises well to unseen data by assessing its performance against a separate test dataset.
For the training/test split, we used an out-of-time test set approach with the training/validation set using data from 1 July 2012 through to 3 April 2020, and the test set including the final year of data (4 April 2020 to 4 April 2021). The out-of-time test set approach allows us to test the ability of the models to forecast future event distributions.
For the vegetation event model, the training set was obtained by:
Including all vegetation incidents within the training data period.
Randomly sampling a negative class sample of the same size as the positive class from all of the bay/day combinations that did not result in a vegetation incident.
For the ignition event model, the training set was obtained by:
2.6. Modelling Framework
To understand ignition risk across the network we require an estimate at the bay/day level of the probability of a bushfire ignition event that is caused by a vegetation event. Such an ignition event can be represented as the product of the probability of a vegetation event and an ignition event that is conditional on a vegetation event occurring. We make the assumption that vegetation and ignition events that co-occur within a small spatio-temporal window (bay/day) are causally related and that they occur in order of a vegetation event followed by an ignition event. This assumption is further supported by the fact that we only include ignition events that have a vegetation event listed as the cause. Consequently, for a given network bay on a given day we have the following two models:
Vegetation Event Model:
Ignition Event Model:
where V represents a vegetation event, I represents an ignition event and N, L and W represent network, landscape and weather features.
The dependence between the vegetation and ignition event probability models is implicitly included in this framework because they are conditioned on the same set of features. An additional benefit of the conditional dependence framework is that it allows us to reduce the amount of class imbalance by fitting a model for a more common event (vegetation event) and then conditioning on that event to fit a model for a genuinely rare event (ignition event).
2.7. Vegetation and Igntion Event Models
All modelling and data preparations were undertaken using R statistical software, with data and modelling pipelines developed using the targets [
21] package.
For both the vegetation and ignition event models, we fit a Gradient-boosted Machine (GBM) model [
22] with a logistic loss function using the gbm package in R. GBM models have demonstrated good performance in similar studies and are useful for quickly determining the potential performance of statistical regression models.
The GBM model encodes the relationship between the input variables and the probability of vegetation events based on the available historical data and as such allows the modelling framework to obtain predictions of the probability of vegetation and ignition events under different landscape, weather and network conditions. As GBM is a tree-based regression method, the relationships are encoded in a complex tree structure rather than estimating single weights for each input feature. The method allows us to extract the relative importance (relative proportion of explained variance attributable to each feature) of the input features and to investigate the directionality of the feature effects using marginal effect plots [
22]. It is important to note that while the observed relationships are useful in predicting vegetation events, we cannot necessarily assume that they are causal.
We trained a GBM model with an interaction depth set at 3 and the number of trees to include in the model determined using 5-fold cross validation on the training set. In total, 17 variables representing network infrastructure, landscape and weather were used as input features.
2.8. Model Performance Assessment
For testing the models, we defined a test set that includes the final year of data, which is 4 April 2020 through to 4 April 2021.
Model performance for the vegetation model was tested using the following methods:
Model performance for the ignition model was undertaken only using AUC as the number of ignitions in the data was too small to undertake the baseline vs. full model expected count comparison.
2.8.1. Model Assessment Using AUC
AUC is a standard classifier performance assessment method and gives an indication of how well the classifier orders different bay/day combinations with respect to the likelihood of event occurrence. A value of 0.5 indicates the classifier is no better than a random guess, whereas a value of 1 indicates a perfect classifier. The AUC value can be interpreted as the probability that a randomly selected positive class example ranks above a randomly selected negative class example.
2.8.2. Baseline vs. Full Model Expected Count Comparison
The baseline vs. full model expected count comparison allows us to test if the rare event correction results in a correct adjustment of the probabilities, and to see if the model has a significant amount of signal in comparison to a baseline model that applies a constant probability of vegetation incident across bays/days.
For each bay/day combination in the test set, 20 simulations were run to create 20 simulated years of data for the network. These simulations were undertaken using:
Baseline model. This simulation used an identical average probability of a vegetation event over every bay/day combination.
Full model. This simulation used the full model to predict the probability of a vegetation event based on the combination of bay landscape and network features and the weather features for the day.
The simulated number of incidents for both methods were summed over a pre-defined geographic aggregation at the sub-depot level (this divides the Endeavour franchise into 46 spatial regions) and divided by 20 to obtain an expected number of incidents at each sub-depot for the simulated test set year.
In addition, the actual number of incidents was summed over each sub-depot to obtain the actual number of incidents for each sub-depot for the test set year.
Correlations of actual incidents to predicted incidents using both the baseline and full models were then compared. This allowed assessment of the model signal and the rare event adjustment technique.
2.9. Event Prediction
Using the ignition event modelling framework set out above, we are able to extract various measures of ignition risk over any given spatio-temporal window. There are two main types of ignition risk measure, these being:
2.9.1. Expected Ignition Count
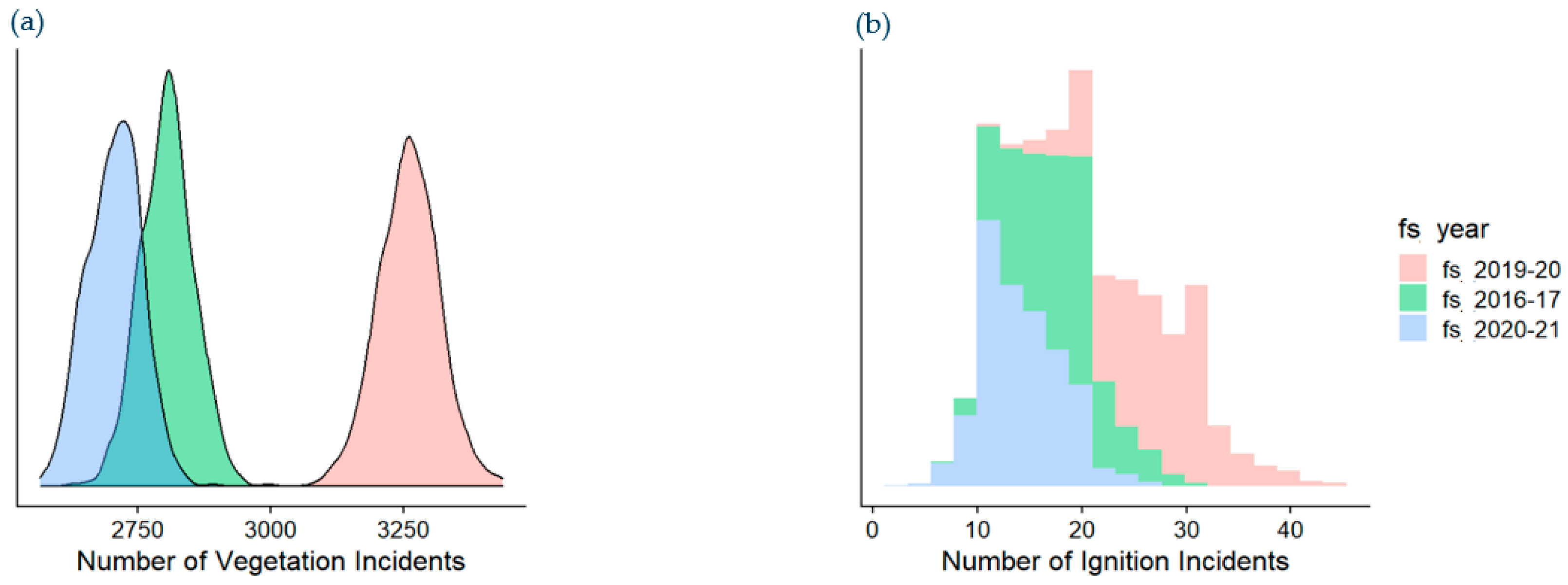
The expected ignition probability for any given bay/day combination provides a point estimate of ignition probability at a particular spatio-temporal location at the bay/day scale. When summed over any given spatio-temporal window we can derive a point estimate of the expected count of ignition events within that spatio-temporal region. These measures are useful for ranking risk and including in vegetation management decisioning tools. One drawback of this approach is that expected counts are point estimates and do not allow a full understanding of the ignition risk distribution, which may be quite complex.
2.9.2. Simulated Ignition Count Distributions
The simulated ignition probability distributions provide a full risk distribution over any defined spatio-temporal window. For example, they allow us to derive event and risk distributions for the entire Endeavour Energy franchise area for a given year. These simulations are useful for investigating rare events such as vegetation-related ignition events because they allow us to understand the possible range of events that may occur within a defined spatio-temporal window along with their probability of occurrence. This provides a much richer understanding of the ignition exposure risks in any given area, and how much they may be expected to vary.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}