1. Introduction
It is increasingly recognized that soils and their functions have a part to play in the large existential challenges that have been recognized for the sustainable development of humanity and planet Earth [
1]. Addressing such challenges needs to appropriately informing local and global decision making, which requires a knowledge of soils at fine resolution and global extent [
2]. Digital Soil Mapping (DSM) [
3,
4] has been proposed as a methodology for reaching this requirement. Various applications of DSM across the globe [
5] demonstrated that DSM can now operationally produce sets of high resolution images representing the spatial variations of the most currently required soil properties or “primary soil properties” (e.g., soil textural fractions, soil carbon content, available water capacity, etc.).
In spite of these substantial efforts for moving to operationality, DSM has still not fully matched the initial objective. A new step is to shift from mapping primary soil properties to mapping soil functions. After the pioneering paper of Carré et al. [
6] that advocated for digital soil assessment approaches, there has been abundant literature providing conceptual advances for the description of soil functions and the related ecosystem services [
7] and also on the valuations of soil services [
8]. Greiner et al. [
9] recently proposed a set of soil function assessment (SFA) methods that cover the multiple functionalities of soils and are applicable to ecosystem service supply assessments. These SFA methods use as inputs a minimum set of primary soil properties and pedotransfer functions which makes them largely applicable provided that the spatial data on primary soil properties are made available. This carries implicitly the idea that (digital) soil mapping and soil function assessment methods are two independent processes that can be only loosely coupled through a straightforward transfer of data. This is this idea that we want to question in this paper.
Beyond their differences, all the SFA methods share a similar data flow. They provide a single output—the valuation of the soil function—from a set of soil properties that characterize different soil layers.
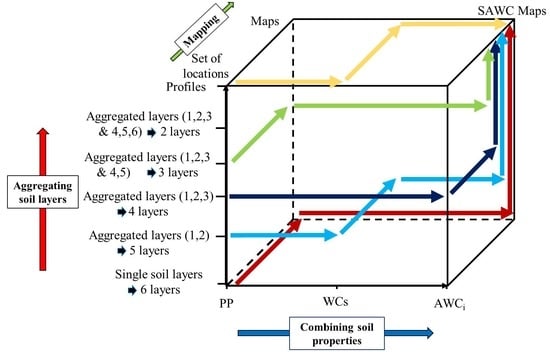
Figure 1 represents in a three-dimensional space the different possible inference trajectories that can be envisaged for producing an SFA output, with the inclusion of the mapping process in these trajectories. The inference trajectories may differ in the order with which “combining primary soil properties”, “aggregating soil layers across depths”, and “mapping” are executed to provide the common targeted SFA output. The commonly followed approach, i.e., mapping first then combining soil property and aggregating soil layers, is one of the possible trajectories (shown in green on
Figure 1), but many others exist. Mapping could be the last executed process after having combined the soil properties and the soil layers over the soil input dataset (“mapping last” in blue on
Figure 1). Combining first the soil properties at each single soil layer, then mapping and lastly aggregating SFA outputs is an intermediate inference trajectory (shown in red on
Figure 1) that can be envisaged too. Apart from these three examples, one can imagine a large number of other inference trajectories since both partial combinations of soil properties and partial aggregations of soil layers can be envisaged.
Considering that SFA could be applied following these different mapping trajectories, the following question comes; “which inference trajectory provides the most accurate SFA output?” Recently, Laborczi et al. [
10] provided a partial response to this question. They compared two inference trajectories for mapping sand, silt and clay content at 0–30 cm depth, which consisted of either first aggregating the GlobalSoilMap layers (0–5 cm, 5–15 cm, and 15–30 cm) then mapping or first mapping each individual layer and then aggregating the layers. They obtained significantly different outputs between the different trajectories, the former trajectory providing slightly worse predictions than the latter one. To our knowledge, such a comparison has not been extended yet to a more generic case study involving the whole inference trajectories for computing soil functions.
In this paper, we address the above evoked question by taking as an example the mapping of the soil available water capacity (SAWC) of a soil profile. Although SAWC cannot be considered as a soil function per se, it shares the same issues of the choice of inference trajectories. Furthermore, SAWC is involved in the assessment of several ecosystem services [
7], either provisioning services—food, fuel, and fiber production—or regulating services—climate and gas regulation, water regulation, or erosion and flood control. SAWC is mapped over the Languedoc–Roussillon region using the same inputs as earlier DSM papers dealing with the same region [
11,
12].
2. The Problem
SAWC is a well-known concept that has been used for a long time to express the capacity of soils to store water for plants [
13]; SAWC is computed using a classic expression:
where SAWC is the soil available water capacity (cm),
= thickness of the
ith horizon (cm),
= bulk density of the
ith horizon,
= coarse fragment content of the
ith horizon (% volumetric), and
and
are soil water contents at field capacity (FC) and at permanent wilting point (PWP) of the
ith horizon (cm
3.cm
−3), respectively.
When the mapping of SAWC is targeted, some modifications to Equation (1) are necessary.
First, bulk density, soil water contents at FC and at PWP are expensive to measure soil properties that are rarely available in current soil databases, which prevent their mapping. The alternative solution is to estimate these data from more easily mappable primary soil properties (e.g., particle size fractions and organic carbon) by using pedotransfer functions (PTFs) [
14]. Many PTFs have been developed for estimating the soil properties required for computing SAWC [
15,
16]. In particular, PTFs can be used to calculate volumetric water contents at FC and PWP (e.g., Wösten et al. [
15]), which embeds the bulk density information and avoids using a specific PTF to estimate bulk density. Volumetric water contents are estimated as follows
where
= volumetric soil water content at FC (cm
3.cm
−3),
volumetric soil water content at PWP (cm
3.cm
−3),
= the coefficient of the model,
is the value of the selected primary soil properties as input, and
is an estimated error.
A second modification of Equation (1) is the replacement of horizons whose thicknesses are variable across locations by soil layers with fixed depths. This has been introduced in digital soil mapping as a simple way for dealing with soil variability across depths [
17]. The general principle is to fit a continuous depth function (spline) of a given property onto the values of the property for the successive horizons, which allows further estimations of the soil properties for any possible layer defined by a user-fixed interval of depth [
18]. This enables the harmonization of soil depths intervals across DSM input locations, which greatly facilitates further mapping. A discretization into six layers (0–5, 5–15, 15–30, 30–60, and 60–100 cm) has been adopted in the specifications of the GlobalSoilMap project [
19], which has made this discretization the most commonly applied.
When PTFs and fixed depth soil layers are introduced in the SAWC formula, we obtain the following formula.
where
is the thickness of soil layers fixed by soil depth interval for
when the specifications of the GlobalSoilMap project are followed.
From Equation (4), the variety of possible inference trajectories for mapping SAWC can be represented as an implementation of
Figure 1 (
Figure 2). The blue axis shows three different ways to combine soil properties (the most straightforward ones, among others): (1) considering primary property (PP), i.e., no combination; (2) considering the volumetric soil water contents at FC and PWP (WCs), i.e., application of PTFs first; and (3) considering the available water capacity of a given soil layer
i (AWCi), i.e., whole application of Equation (4) first. On the red axis, we have six possibilities for soil discretization across depths (the most straightforward, among others): from considering the six GlobalSoilMap-fixed soil layers, i.e., no combination, to a full aggregation of soil layers, i.e., aggregating layers to soil profile first. Four other possibilities are considered by merging an increasing number of layers (
Figure 2).
From
Figure 2, it is possible to define 18 possible inference trajectories for mapping SAWC, i.e., three modalities of property combinations x six modalities of combining soil layers. For the sake of readability, only five out of these 18 trajectories are presented in
Figure 2. It must be noted that the most classic inference trajectory (mapping first then aggregating properties and layers), which fully dissociate mapping and SAWC computing, was included among the 18 tested strategies.
In this paper, we investigated whether these different inference trajectories provided similar results or not, the input data and the underlying formula (Equation (4)) being the same for all trajectories. If not, we also wanted to know which trajectory provided the best mapping performance.
2.1. The Case Study
2.1.1. Study Area
Languedoc–Roussillon is one of the 22 former administrative regions in France (
Figure 3), and is now part of the country’s newest region, Occitanie, which resulted from the merging of Languedoc Roussillon and Midi-Pyrénées. Located in Southern France, it covers 27,236 km² of land and stretches from the Mediterranean Sea to the Pyrenees and to the Massif Central Mountains. The region includes a wide variety of climates, parent materials and landscapes: low sedimentary plains with vineyards and/or cereals, dry limestone plateaus with scrublands and evergreen oak forests, slopes of Paleozoic mountains covered by forests, and volcanic and granitic highlands with grasslands. The soil cover of the region is consequently very diverse, including 18 WRB major soil groups that represent 56% and 75% of the total number of the soil group populations in the world and in Europe, respectively.
2.1.2. Soil Data Input
In this study, we used a legacy dataset of 640 measured soil profiles selected from the 2024 used in Vaysse and Lagacherie [
11,
12]. This selection was made to ensure that the same input data was used by all of the inference trajectories. This motivated to select only the profiles that were fully documented for each soil property and for each layer. Indeed, this restrictive condition was necessary for providing non-null inputs for applying the “combine first” inference trajectory (i.e., combining all soil properties and for all soil layers before mapping). Finally, the density of this dataset of the study area was one soil profile for each 41 km².
Documenting Soil Layer Thickness
The soil layer thicknesses (Equation (4)) that were initially defined through the fixed interval depth, 5, 10, 15, 30, 40, and 100 cm for layers 1 to 6, respectively, needed to be updated to account for soils having a depth less than 200 cm. This was done from the following formula.
where SD is the soil depth,
is the soil thickness of the soil layer and,
and
are the upper and lower limits of the considered soil layer, respectively.
Equation (5) requires first to document the soil depth (SD), i.e., the distance (in cm) from the soil surface to the bedrock or a paralithic contact [
20]. This was done by a prior classification tree that determined whether or not the bottom horizon could be considered as bedrock or as a paralithic contact.
Figure 4 shows the decision tree that was used for classifying the bottom horizon. The type of soil horizon was first used to identify lithic (R, M or D) vs. pedological horizons. Since the horizon type, C, remained ambiguous with respect to the targeted classification, additional soil variables were used (types of structure, compaction, and weathering), which allowed for the identification of paralithic horizons vs. pedological horizons.
From this classification of horizons, the soil depths were determined by applying the following rules:
If the bottom horizon is lithic or paralithic, then the soil depth is the upper depth of the bottom horizon.
If the bottom horizon is still a pedological one, the soil depth cannot be determined and thus the site is not selected. A total of 760 measured soil profiles were removed for this reason, which corresponded to 55% of the total removal of sites.
Documenting Layers with the Other Required Soil Properties
As the described pedological horizons available in the soil database were defined by variable soil depths, a prior interpolation was required to document the soil layers. Spline functions work as an interpolator, respecting the average values of the target soil property, and assuming a continuous variation with depth [
13]. As an outcome, spline functions deliver a set of interpolated values at specific depths which are, in our study, the depth intervals provided by
GlobalSoilMap.net specifications (0–5, 5–15, 15–30, 30–60, 60–100, and 100–200 cm). Then, the mass-preserving spline functions were applied to clay, silt, sand, and coarse fragment contents.
The values of the soil properties for the tested aggregated layers (see
Figure 2) were derived from their values at the six depth intervals using a weighted mean by soil layer thickness.
Local Continuous PTFs
As presented in
Section 2, the common way to obtain soil water contents, that partially drives AWC (i.e., soil water contents at FC and PWP), is to use pedotransfer functions. The continuous PTFs used in this study are obtained from an investigation based on the analysis of a dataset of 294 pedological horizons belonging to 115 soil profiles located in the Hérault River Valley in the former Languedoc Roussillon region [
21]. The dataset contained soil water volumetric contents at FC (10 kPa) and at PWP (1500 kPa), particle size fractions (clay, silt, and sand), bulk density, and organic carbon content. Before starting the investigation, bulk density and organic carbon were discarded from the dataset because not all horizons of the STIPA database reported their values, making PTFs inapplicable for local prediction. PTFs were fitted using a point estimation approach based on multiple linear regression carried out with the stats R package [
22]. Model variables were selected using the Akaike’s information criterion (AIC) [
23] applied to a backward/forward stepwise procedure. Linearity was visually analyzed on linear model graphs, then tested with the RESET test for nonlinearity [
24]. Linear models that fitted to the data set are reported in
Table 1. Since particle size fractions are compositional data, stepwise selection will always remove at least one of them from the model. In this case, clay was selected for both models, sand better explained water content at field capacity predictions, and silt, water content at permanent wilting point predictions. Performance assessments showed great performances for both PTFs, with a certain advantage for PWP’s PTF.
2.1.3. Soil Covariates
The DSM process used in this study is based on the well-known scorpan model [
3] that uses quantitative relationships between targeted soil property and environmental variables also called “covariates”.
The selection of the landscape covariates (
Table 2) had been performed for a previous DSM application in the region [
11]. It was based on two criteria: (i) the covariates could be derived from freely available geodatasets, at least at the French national level, and (ii) they have a logical and deterministic relationship to the soil properties, according to the literature.
Classical geomorphometric indicators found in the DSM literature were computed from the global Shuttle Radar Topographic Mission (SRTM) digital elevation model (DEM): the elevation, slope, plan curvature, profile curvature, set of multiresolution valley bottom flatness (MRVBF), set of multiresolution ridge top flatness (MRRTF), topographic position index, and topographic wetness index.
The parent materials were characterized from the National Geological 1:50,000 map obtained from the French Geological Survey [
25]. This map was translated into three parent material soil covariates, namely, the hardness, mineralogy and texture of alteration materials, following a mixed approach that involved both our pedologic knowledge and the measured legacy profiles described above (see details in Vaysse and Lagacherie [
11]).
Land use was mapped across the region by a manual interpretation of Landsat 7 images from 2006. The initial classification into 43 land use types was condensed into nine types that were considered to be correlated with soil variations (e.g., artificial areas, greenhouse cultivation, permanent crops and orchards, forests, heathlands and pastures, scrublands, wetlands, complex territories composed of natural and agricultural areas, and forests in transition).
The basic climate data (maximum temperature, minimum temperature, and precipitation) were extracted from the Global Climate Database at a resolution of 1 km
2 [
26]. Two aridity indexes were derived from these data, namely, the De Martonne index and the Emberger index (see details in Vaysse and Lagacherie [
11]).
Additionally, we added to the covariate set the regional-scale soil map (1:250,000) that regroups the major landscape types across the region.
5. Discussion
5.1. Level of Performances and Limitations
5.1.1. Level of Performances in Predicting Primary Soil Properties
In this study, we considered inference trajectories that involved mapping of soil primary properties by using a DSM model. The partial results presented in
Section 4.2 can then be compared to those of previous studies in similar conditions. The performances delivered for particle size fractions were slightly worse than those provided recently by Román Dobarco et al. [
36] for all of France (R² = 0.27, 0.43, and 0.46 for clay, silt, and sand content, respectively) with, however, the same hierarchy between sand, silt, and clay mapping performances. Vaysse and Lagacherie [
11] obtained in the same study area better mapping performances for particle size fractions (between 0.19 and 0.36) but the same poor performances for thickness and coarse fragment, however, with another validation technique (independent validation test instead of cross validation). A comparison with results from Vaysse and Lagacherie [
12] that used a cross validation confirmed the previous results for a given soil property (clay content for the 5–15 cm layer). The performance gap could be explained by the reduction in the size of the input dataset between Vaysse and Lagacherie [
12] applications and this study (from 1945 to 640).
5.1.2. Level of Performance in Predicting SAWC
Among the 18 inference trajectories, the most appropriate for predicting SAWC was the one considering four soil layers (e.g., 0–30, 30–60, 60–100, and 100–200 cm) to directly predict SAWC. This trajectory obtained much better results than any mapping of SAWC components, i.e., individual soil properties at a given depth. This can be explained by the removal of intraprofile variabilities and noise that did not play any more when SAWC is considered.
In addition, this inference trajectory exhibited similar results to those obtained by Leenhardt et al. [
21] with a R² ranges from 0.36 to 0.45 according to the scale of the SAWC map chosen. Except for this study, evaluation of SAWC mapping has rarely been applied and this paper is, to our knowledge, among the first that has performed such an evaluation. However, this evaluation remains incomplete since we did not take into account the error of the PTFs coefficient applied. However, Román Dobarco [
36] found that PTF error played a minor role in SAWC mapping error.
5.2. Drivers of the Variability in Performance between Trajectories
The results exhibited substantial differences of mapping performance across the tested inference trajectories (
Table 9). The most important differences in performance were observed when different numbers of soil layers were considered. The best performances were obtained when highly correlated soil layers (correlation >0.9 between layers 1, 2, and 3, cf.
Table 5) were merged before mapping whereas the worst ones were obtained when fewer correlated soil layers were merged (correlation < 0.80 between layers,
Table 5). The former came from averaging the DSM model inputs, which may decrease the input errors of the DSM models whereas the latter forced the DSM models to cope with contradictory drivers of the combined soil layer, which could negatively impact the performance. This result is partially in accordance with Heuvelink & Pebesma [
37] who advocated a mapping first trajectory since it “enables a more efficient use of the spatial characteristics of the individual inputs”. We however brought a nuance to this statement by considering a correlation threshold beyond which combining first could be a better solution. These differences were not modified by the further combination of the soil layer maps for calculating the final SAWC since no noticeable differences were observed in mapping error correlations (
Table 8) that could have created differences in error propagation through this additive operation [
34].
The differences in performance observed between trajectories that mapped different soil properties (primary soil properties, hydraulic properties, or SAWC) were more difficult to interpret. First the differences in mapping performance were much smaller than previously observed. Furthermore, in contrast to the combination of soil layers, the combination of soil properties is multiplicative (Equation (4)). Therefore, the impacts of the correlations between soil properties and between their mapping errors could be very different.
More comparisons of such inference trajectories involving contrasted mapping results and a larger range of soil function expressions would be necessary for a full understanding and an ex ante prediction of the hierarchy of performances across the trajectories.
Finally, it must be noticed that the comparisons of the inference trajectories “all things being equal” required considering the same number of measured soil profiles across trajectories. This corresponded to the number of fully complete measured soil profiles that were necessary for mapping SAWC after combining all soil properties and all soil layers. However, other less restrictive inference strategies could use more locations for mapping some of the SAWC components. Indeed, mapping separately the soil properties at each soil layer would allow an increase in the amount of input data which could increase the mapping performance of some SAWC components and, in turn, might have a positive effect on the overall performances. However, this reasoning does not hold for the depth prediction that is still limited by the soil input, whatever the trajectories. The value added provided to the final mapping of SAWC should therefore be investigated in the future.
5.3. Toward Soil Spatial Information Systems
Digital mapping of soil function introduces an additional degree of complexity relative to the usually practiced monovariate digital soil mapping. Different inference trajectories could be envisaged and we showed that the decision of selecting one or another could substantially impact the performance of the soil function mapping.
This can provide motivation to develop tools that would select the best possible trajectories from a prior knowledge of error propagation mechanisms and of causes of mapping errors. Such tools may refer to the ideas of soil inference systems applied to the building of pedotransfer functions [
38] that were further extended to digital soil mapping by Lagacherie and McBratney [
39].
This could imply a revision of the strategies of diffusion of the digital soil mapping products since we showed that the current practice, i.e., providing a set of spatial layers of soil properties that could be further combined for obtaining soil function maps could not be the optimal one. An alternative could be to provide to the users the soil spatial inference system of a given region so that they could produce the best possible soil function map by themselves.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}