1. Introduction
Early Japanese books are a cultural heritage, have stored the wisdom of our ancestors, and contain much information about Japanese politics, economy, culture, etc. These early Japanese books are described by Kuzushi-ji, a kind of old Japanese character style, and are also one of the essential factors to symbolize early Japanese books. However, Kuzushi-ji is not used in the present day, causing only few experts of classical Japanese can read Kuzushi-ji and understand the contents of the books. To re-organize and preserve this cultural heritage, researchers have digitalized the early Japanese books and applied the combining Kuzushi-ji and Optical Character Recognition(OCR) to recognize the Kuzushi-ji [
1,
2,
3]. Humanities research intuition such as the Center for Open Data(CODH) [
4] and Art Research Center(ARC) of Ritsumeikan [
5] digitize the early Japanese books and re-organize them for the database to prevent degradation and prompt combine computer science with humanities. Currently, lots of researchers apply deep learning and machine learning methods for cultural heritage protection, organization, etc. Literature organization is one of the hot topics in this area, such as the re-organization of OBI [
6,
7], Kuzushi-ji [
1,
2,
8], and Rubbing [
9]. In detail, Yue et al. aim to achieve a good accuracy recognition for Oracle Bone Inscription, which is ancient characters described on the tortoises’ shells and animals’ bones. Zhang et al. combine simple deep learning models and lexical analysis to recognize rubbing characters described on the bones from 3000 to 100 years ago. Lyu et al. use deep learning and image processing method for detecting and recognizing Kuzushi-ji. It is also the target literature of this paper.
However, the early Japanese books have been damaged, and some Kuzushi-ji is scratched and faded due to deterioration over the years. The damage increases the difficulty of Kuzushi-ji recognition and prevents early Japanese book re-organization accuracy. In the worst case, it causes the loss of some cultural heritage. Hence, the damaged Kuzushi-ji restoration becomes an emergency research topic for preserving cultural heritage.
Nowadays, we can realize high-quality and objective restoration thanks to developing generative models using deep learning. Generative Adversarial Nets(GANs) [
10] are generative models that balance sampling speed and quality well. Image-to-Image translation based on GANs is thereby effective, and it has been studied in many different cases. GAN-based ancient characters restoration is focused on supervised image-to-image translation for inpainting damaged characters [
11,
12]. Su et al. inpainted masked characters in the book of Qing dynasty and Yi, handwritten ancient Chinese characters, with unmasked images and applied them to the practical ancient text. Wenjun et al. inpainted large-area damaged characters in the ancient Yongle Encyclopedia with ground truth and examples of them. To our knowledge, this is the first time the practical restoration of Kuzushi-ji and the early Japanese books using deep learning. When applying supervised image-to-image translation for Kuzushi-ji, the various types of damaged and distorted letter styles make it hard to prepare train data. Moreover, most damaged characters are weak damages, which makes GANs training difficult.
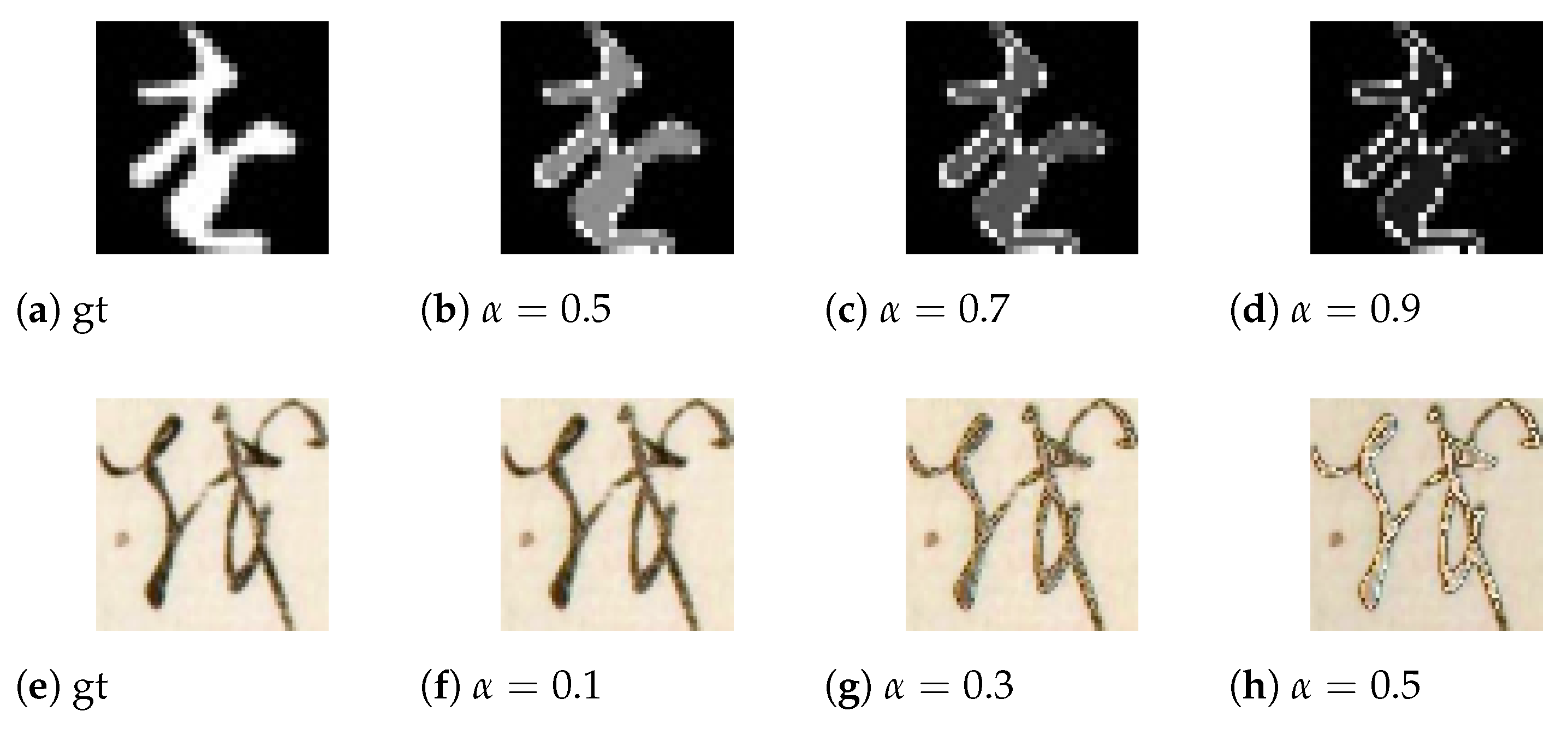
The problems are shown in
Figure 1a, a piece of Early Japanese Books, which has several levels of deterioration such as faded ink, global, partial, and scratches, are expanded listed in
Figure 1c.
To solve these problems, we propose an enhanced CycleGAN and aim to realize the restoration of deteriorated early Japanese books. An example of restoration through our proposal is shown in
Figure 1b,d. In detail, we employ CycleGAN [
13], unsupervised
1 image-to-image translation based on GANs, for the training with only authentic damaged images and undamaged images. Then, we propose a robust CycleGAN for weak damages, which combines a domain discriminator [
14] and augmented identity loss. The augmented identity loss improves the identity mapping loss for CycleGAN. The enhanced CycleGAN provides truth restoration and high readability for early Japanese books. The contribution detail of this paper is:
We employ a domain discriminator for the restoration of deteriorated characters. It leads to improving the degree of restoration.
We propose the augmented identity loss, which lets the generator learn the identity mapping by a large number of images and generalized images. The enhanced CycleGAN, combining the domain discriminator and augmented identity loss, realizes high-quality damage restoration. It is proved by the quantitative results using PSNR and SSIM.
We indicate that image enhancement using image processing and CycleGAN increases the accuracy of Kuzushi-ji recognition. The proposed method is more effective than traditional image processing for the Kuzushi-ji expressed as RGB.
3. Approach
We propose CycleGAN with a domain discriminator and augmented identity loss for early Japanese book restoration. Our method is a practical approach for applying existent data from early Japanese books. However, there is partial and weak deterioration rather than a highly noticeable deterioration. The standard CycleGAN has a limitation for weak damage restoration. To solve it, we adopt the domain discriminator to increase the degrees of transformation by penalizing non-transform clearly in
Figure 2. Then, the augmented identity loss improves the preservation of character shapes because it is equal to the identity mapping loss with enough and sufficient data. This proposed loss function combined with the domain discriminator is our proposed enhanced CycleGAN for character restoration and its structure shown in
Figure 3. The two additional functions make higher quality restoration.
3.1. CycleGAN
We apply CycleGAN to restore damaged characters. CycleGAN is image transformation in two domains. In this paper, we describe domain
X as the damaged domain and
Y as the undamaged domain, and
as the damage restoration. CycleGAN includes two discriminators
and
and two generators
and
. The adversarial loss with a least square error [
13,
25] between
and
is as follow:
denotes an expectation for data distribution
. The object function of Equation (
1) is:
Cycle-consistency loss enforce
and
to correlate inputs and outputs. The cycle-consistency loss is defined as:
In addition, the identity mapping loss is employed in CycleGAN as a help objective function. Identity loss helps to preserve features between the input and output, such as the color composition [
13,
26]. The identity loss is:
The full objective included the adversarial loss, the cycle-consistency loss, and the identity loss is:
3.2. Domain Discriminator
Kim et al. [
14] introduce a domain discriminator (domain-d) to guide generated images following target domain distribution rather than the source domain. The domain-d learns the source domain as generated images. The reason why the standard CycleGAN occurs identity transformation is the images included with
X and
Y are satisfied with the loss functions of that CycleGAN as shown in the left of
Figure 2. The high similarity between weak damaged and undamaged characters applies to them. The identity transformation of GXY and GYX is described as
or
mathematically. When
,
is not penalized by the adversarial loss, and
does not transform
x. Therefore, we employ domain discrimination which distinguishes
for the penalty for
.
The adversarial loss attached the domain-d with a least square error using
and
is:
In this study, we employ the domain-d for both and because this implementation improves the quality of generated images experimentally.
3.3. Augmented Identity Loss
In this section, we pay attention to the identity mapping loss(id loss) in CycleGAN. The id loss helps to keep the input’s color composition and shapes [
13,
26]. For this reason, it is suitable to preserve an author’s font styles and old book texture in the early Japanese books. According to Xu et al. [
27], however, the id loss can constrain the degree of transformation. In addition, decreasing of id loss is less than other loss functions of CycleGAN, such as cycle-consistency loss and adversarial loss, when increasing the train data. We present the problem of id loss as follows:
A larger amount of train data is necessary to decrease the id-loss sufficiently.
When an image is appropriate, the identity mapping loss enforces the generator to learn incorrect identity transformation. In particular, the identity transformation learning of overlapping-domain images conflicts with image transformation to the other domain.
Therefore, We propose augmented identity loss(aid loss) as:
where
. For the dynamic training of
and
, generated images for the first epochs are not high-quality. For this reason, we decide
increases linearly with epoch following with [
28].
and
are new generators of GANs.
close input to the distribution of domain-X, and
close input to the distribution of domain-Y. The generated images are abundant and gradually change every epoch because
and
are trained simultaneously as the CycleGAN training.
Then, we use the two domain discriminators, domain- and domain-, to learn the adversarial loss of and . The domain discriminators guarantee that outputs of and are independent domain images.
Thereby, the object function of domain-d combined with aid loss is as below:
3.4. Full Objective
Based on our changes, the full objective of enhanced CycleGAN is:
The overall structure of enhanced CycleGAN is shown in
Figure 3.
5. Conclusions
We proposed deteriorated characters restoration using enhanced CycleGAN with the domain discriminator and the augmented identity loss. This enhanced CycleGAN enables high-quality restoration compared with the standard CycleGAN and binarization in the actual early Japanese book. Furthermore, it provides the revitalization of ancient documents and high readability. Our proposal encourages more accurate recognition of deep learning models in the actual book. In other words, high-quality restoration makes them readable for us as well as artificial intelligence. In this paper, we achieve slight-to-moderate damage restoration on a specific early Japanese book. However, our method has a limitation for complete damage because the damaged character is few, and it is based on CycleGAN. Furthermore, the early Japanese books have multiple types of deterioration and color configuration, and paper texture. In terms of future work, we aim to realize a high degree of freedom restoration for ancient documents.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}