
Robustness and Sensitivity Tuning of the Kalman Filter for Speech Enhancement


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
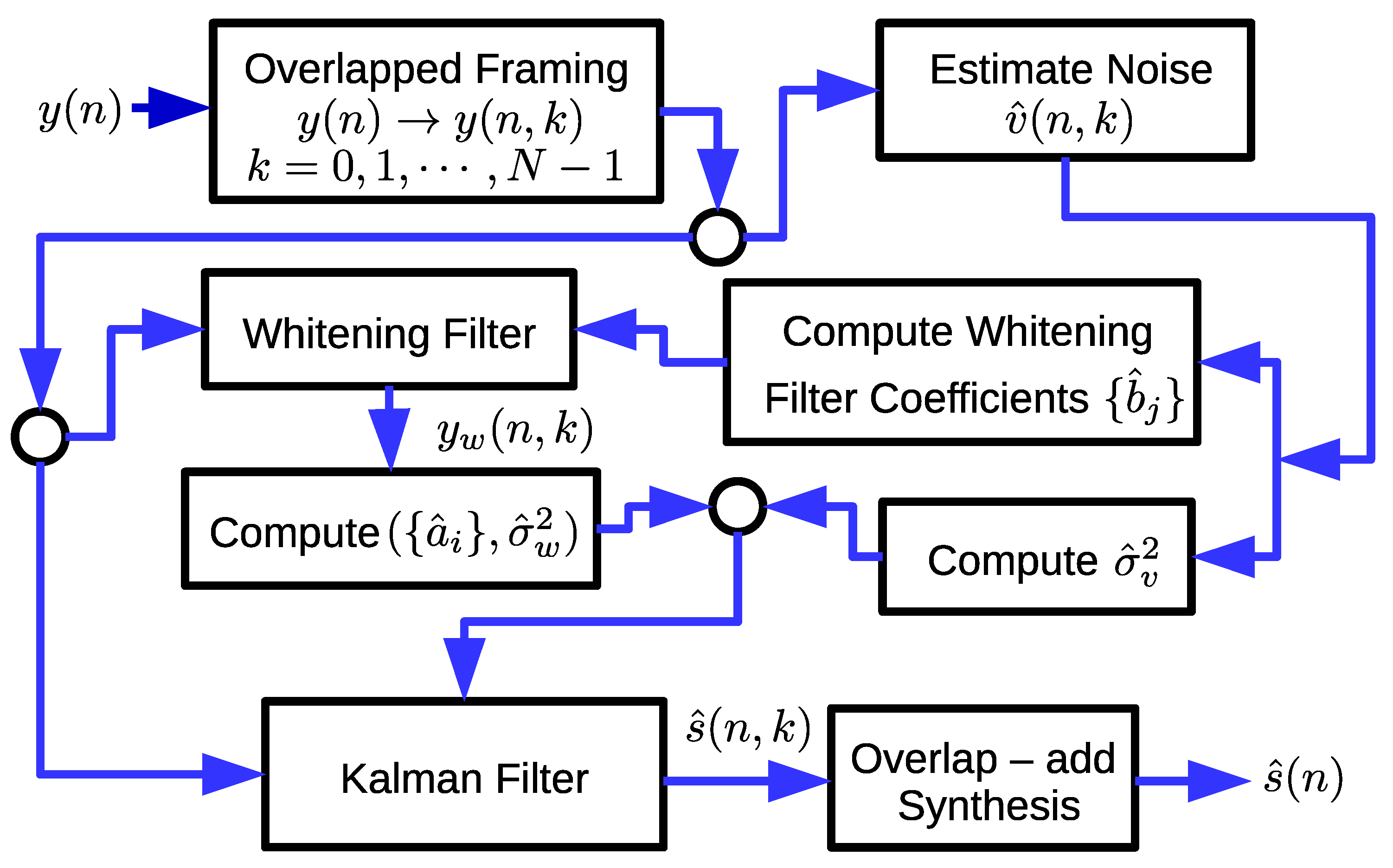
2. Kalman Filter for Speech Enhancement
- is a state vector at sample n, given by:
- is a state transition matrix, represented as:
- and are the measurement vectors for the excitation noise and observation, written as:
- is the observed noisy speech at sample n.
2.1. Paradigm Shift of Recursive Equations
2.2. Impact of Biased on KF-Based Speech Enhancement in WGN Condition
2.3. Impact of Biased on KF-Based Speech Enhancement in Real-Life Noise Conditions
3. Proposed Speech Enhancement Algorithm
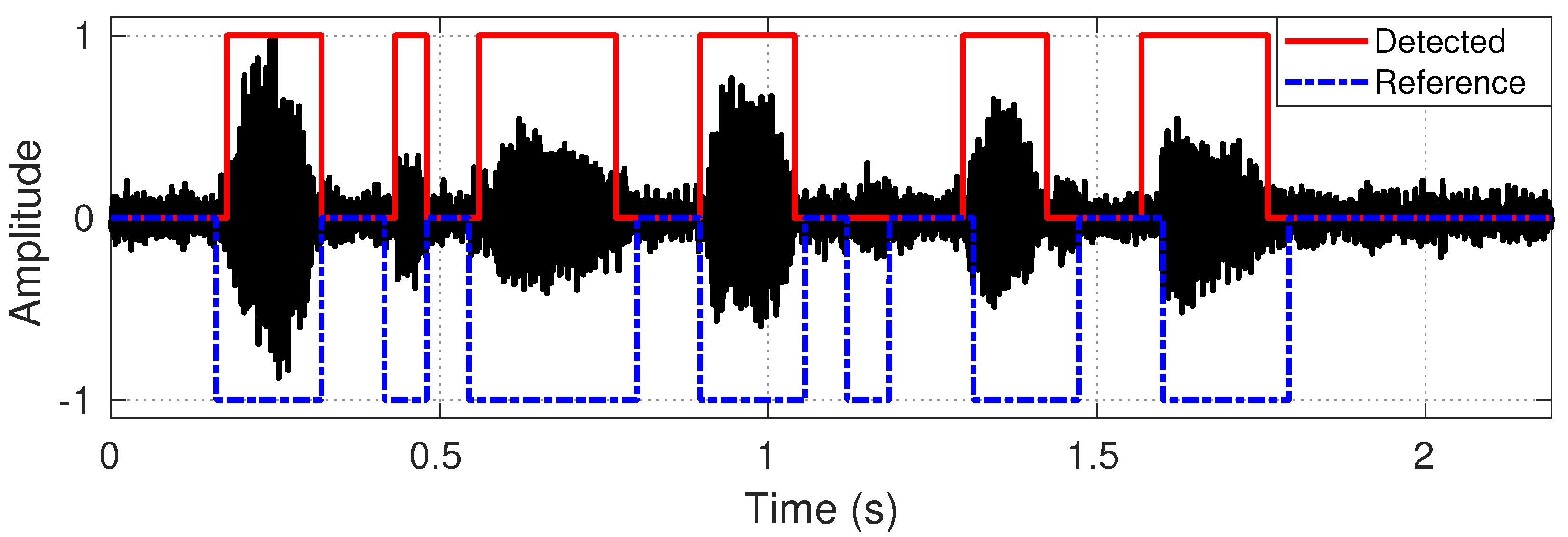
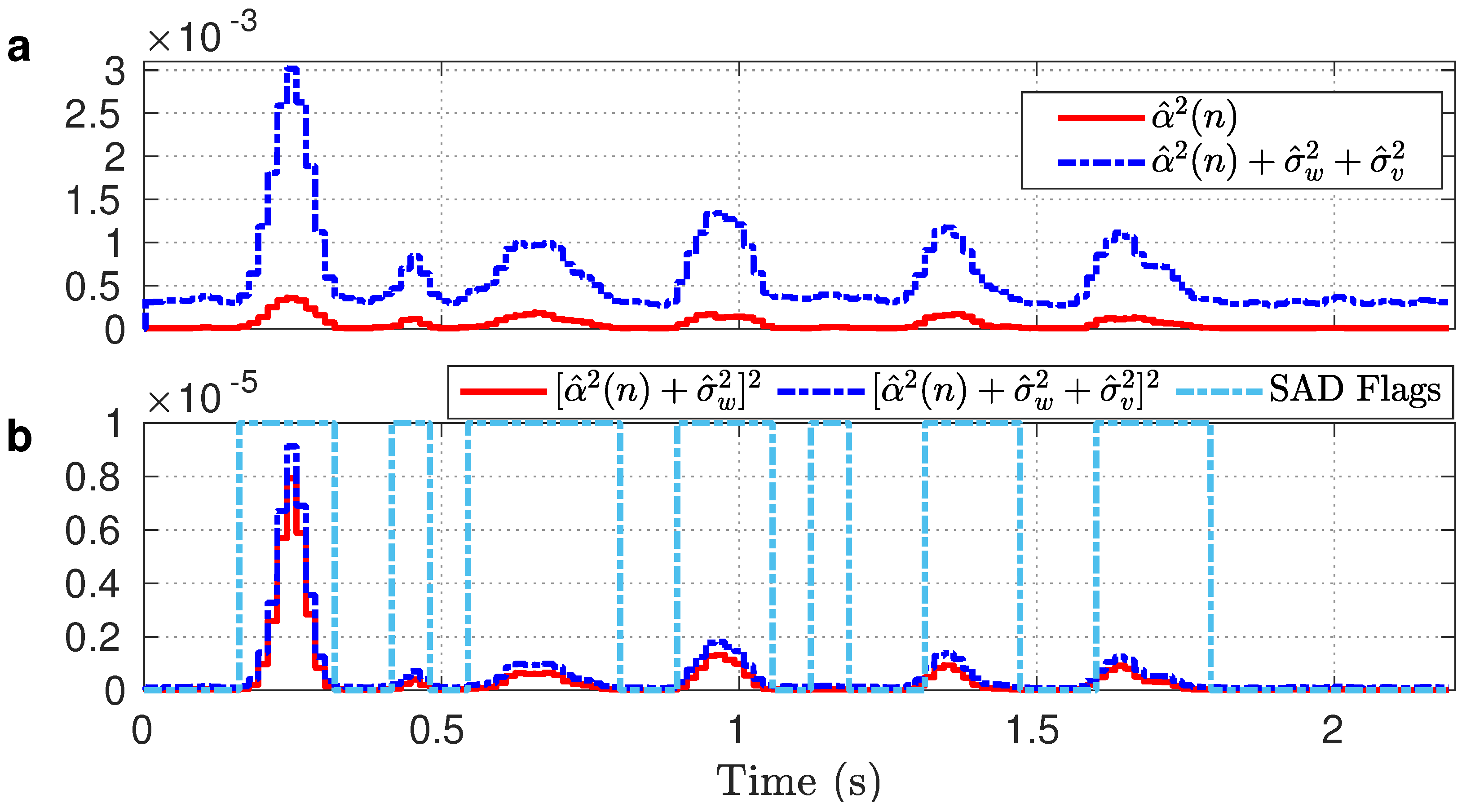
3.1. Parameter Estimation
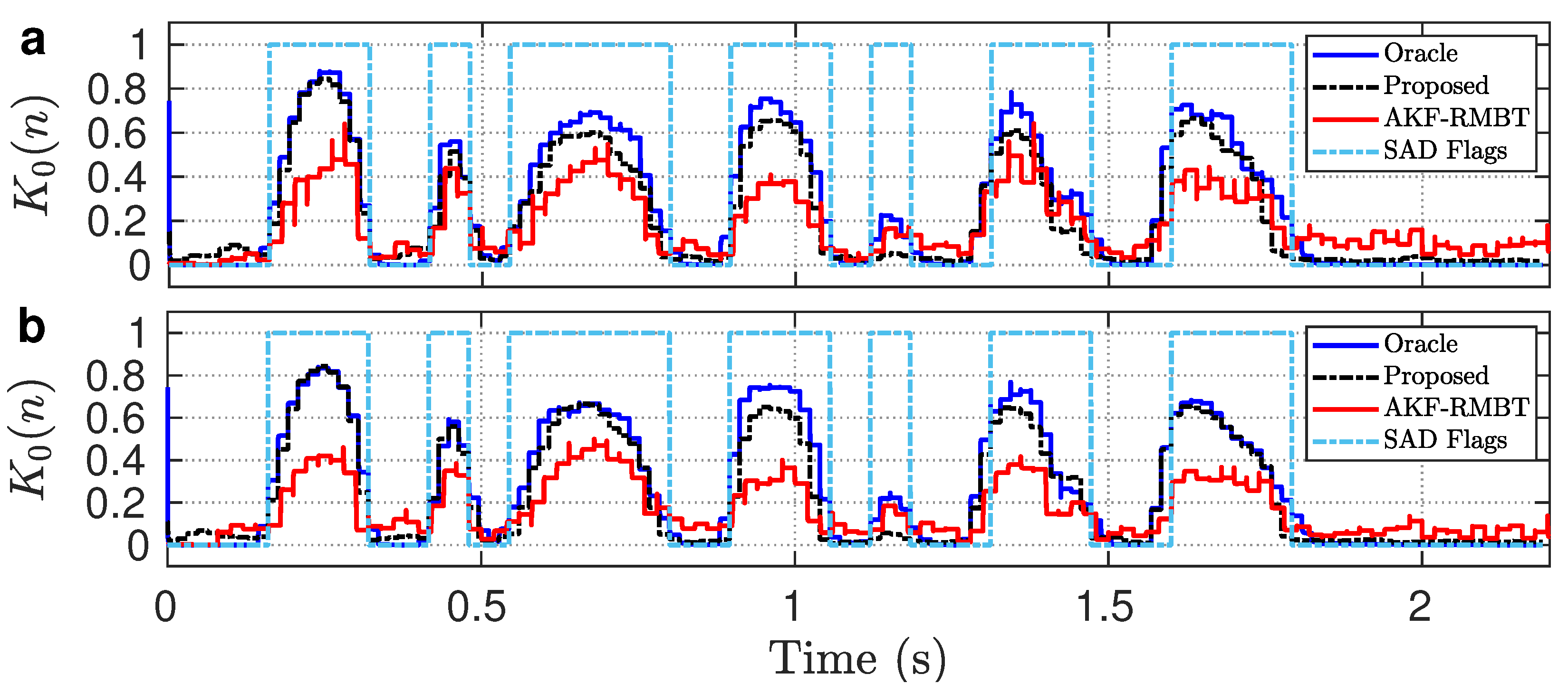
3.2. Proposed Estimation Method
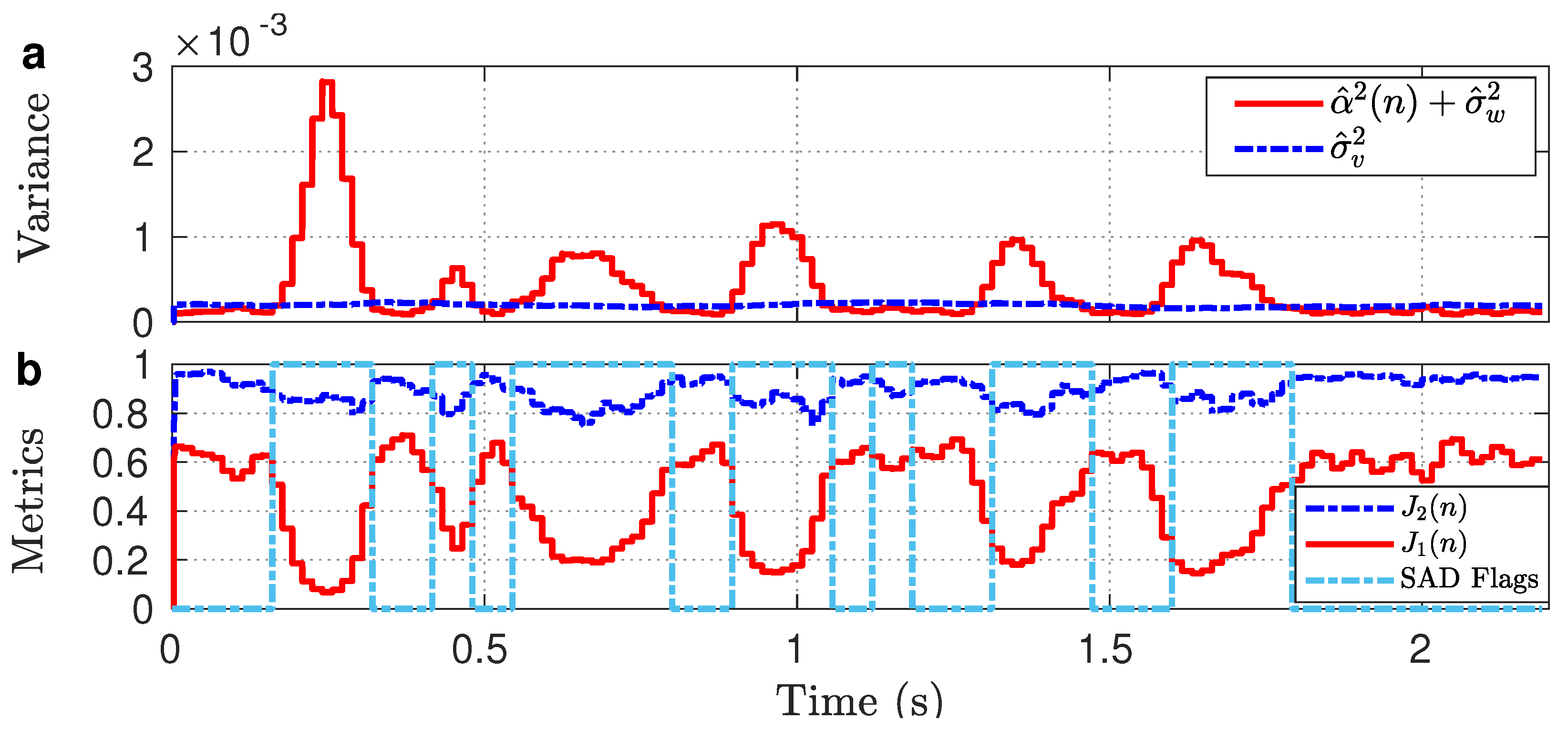
3.3. Proposed Tuning Method
4. Speech Enhancement Experiment
4.1. Corpus
4.2. Objective Evaluation
- Perceptual Evaluation of Speech Quality (PESQ) for objective quality evaluation [28]. The PESQ score ranged between −0.5 and 4.5. A higher PESQ score indicates better speech quality;
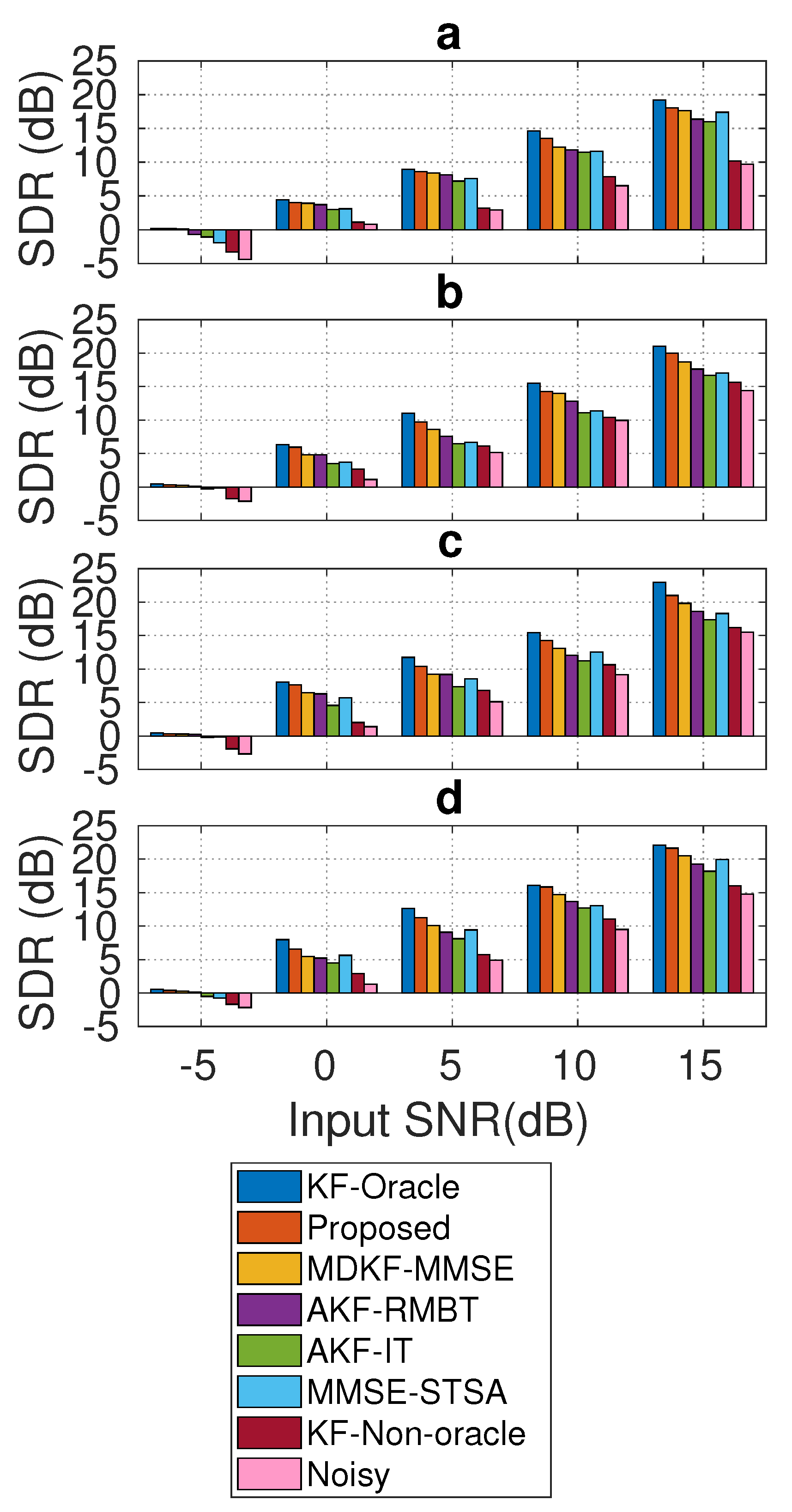
- Signal to distortion ratio (SDR) for objective quality evaluation [29]. The SDR score ranged between and . A higher SDR score indicates better speech quality;
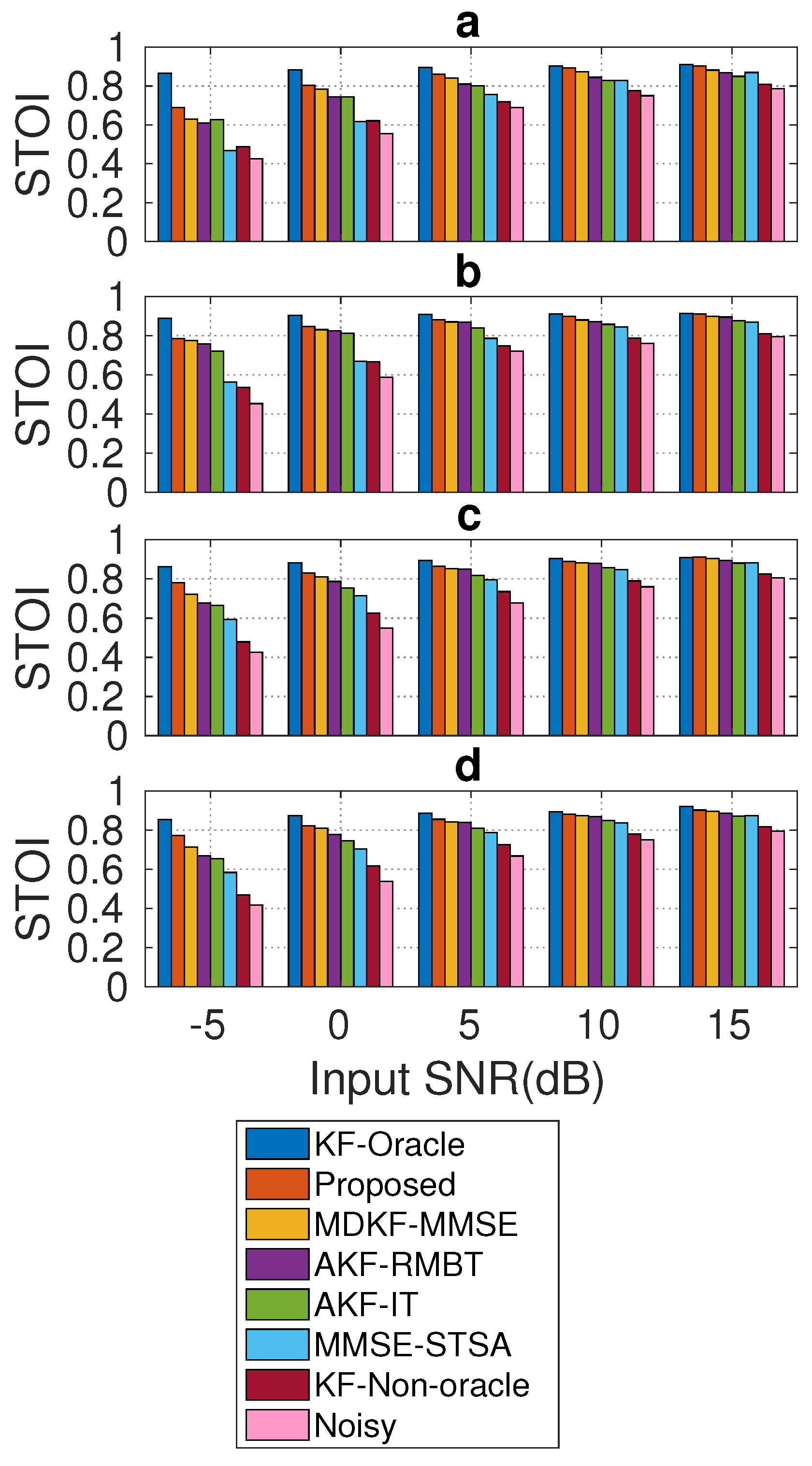
- Short-time objective intelligibility (STOI) measure for objective intelligibility evaluation [30]. It ranged between 0 and 1 (or 0 and 100%). A higher STOI score indicates better speech intelligibility.
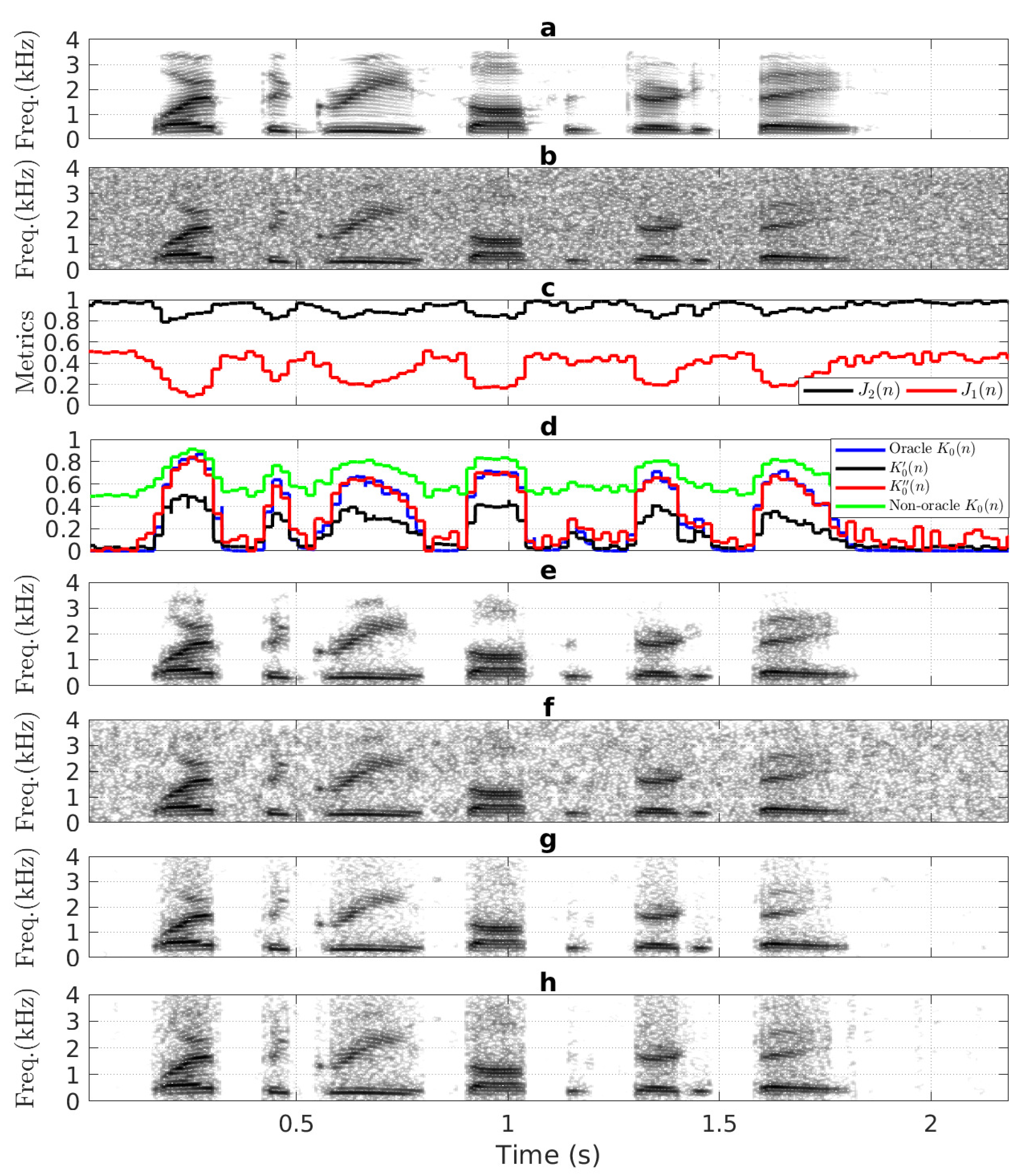
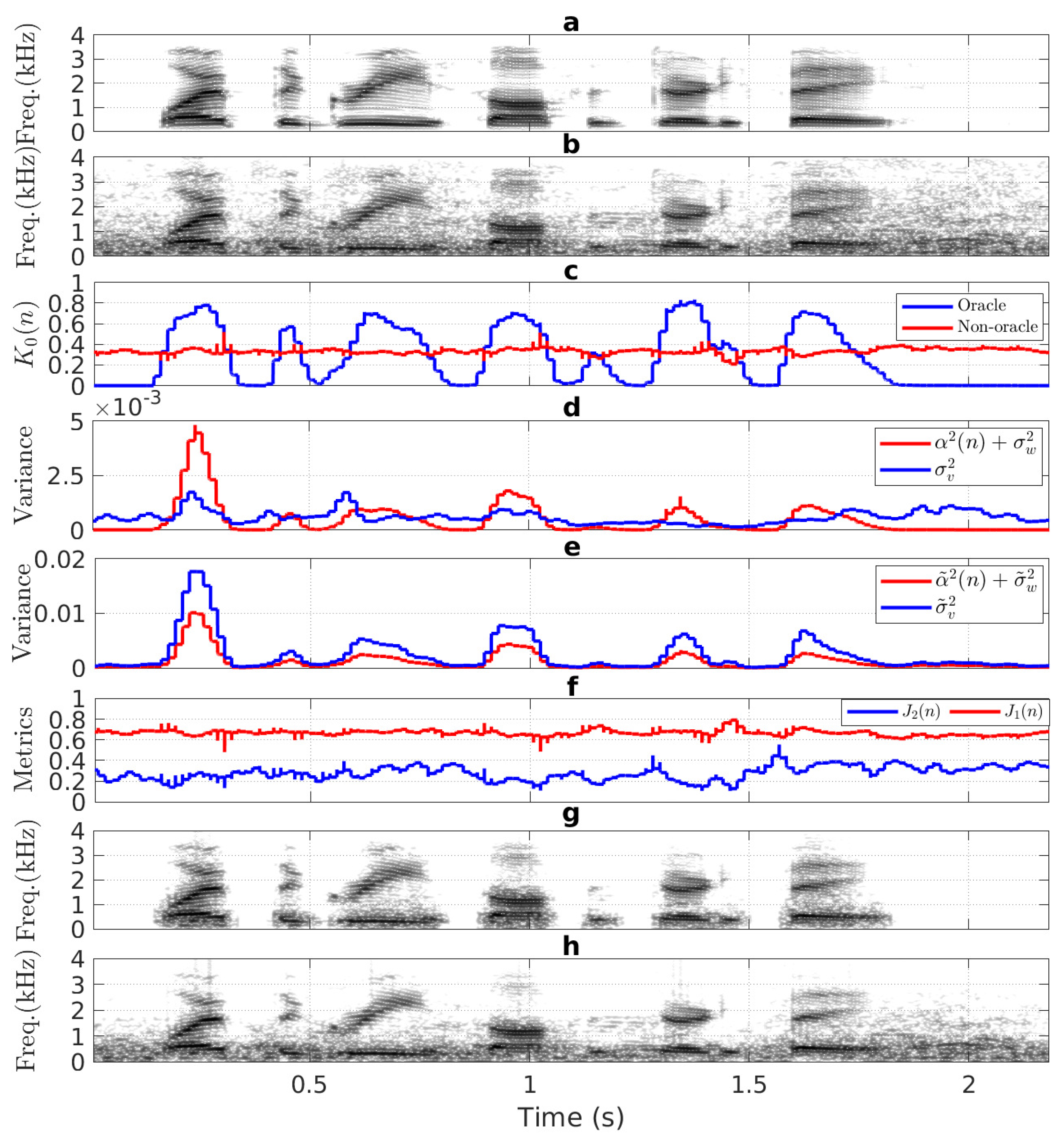
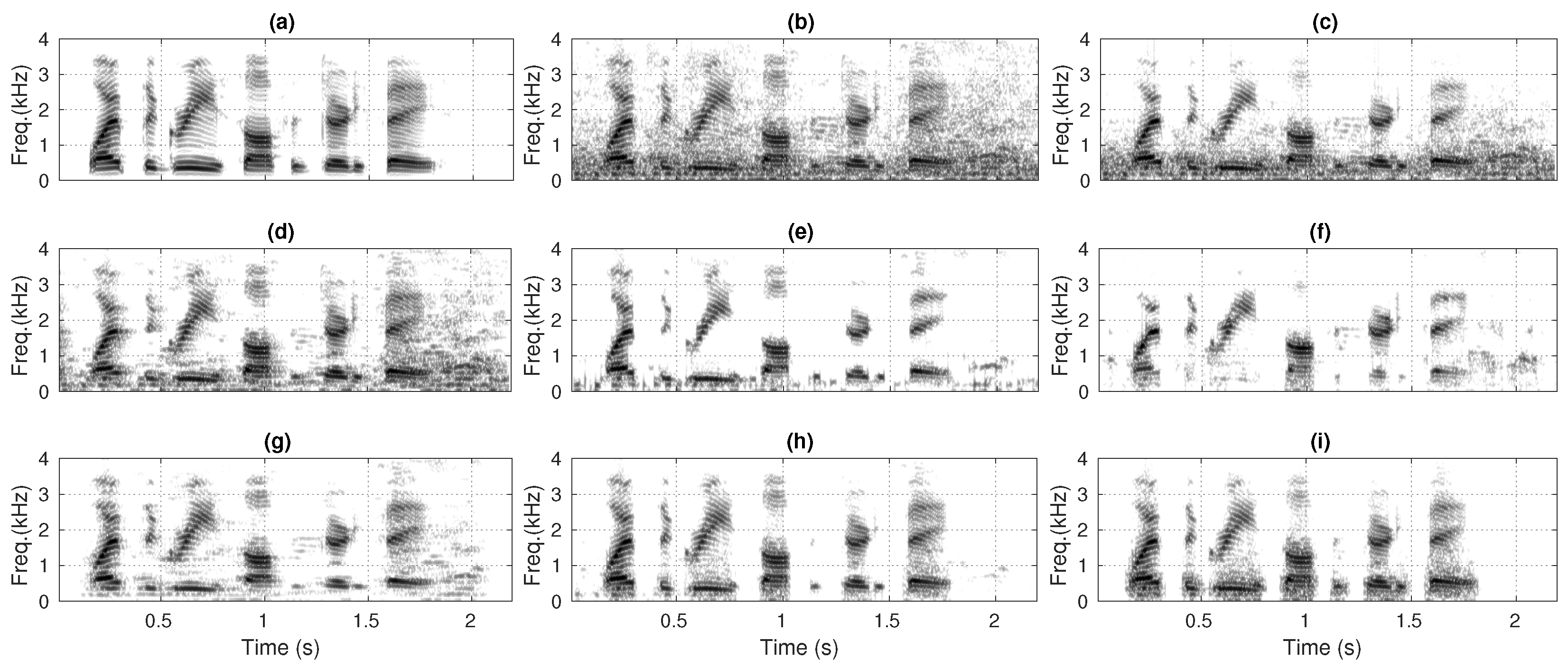
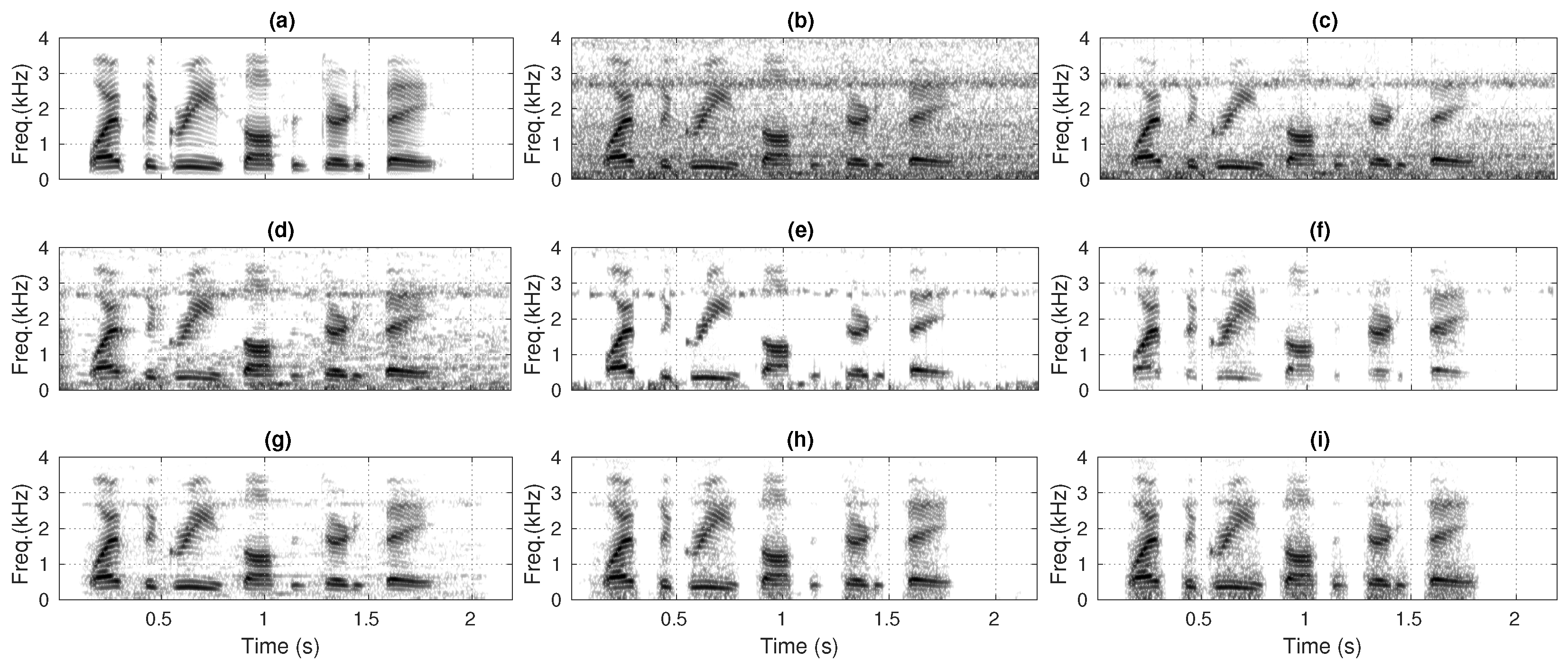
4.3. Spectrogram Evaluation
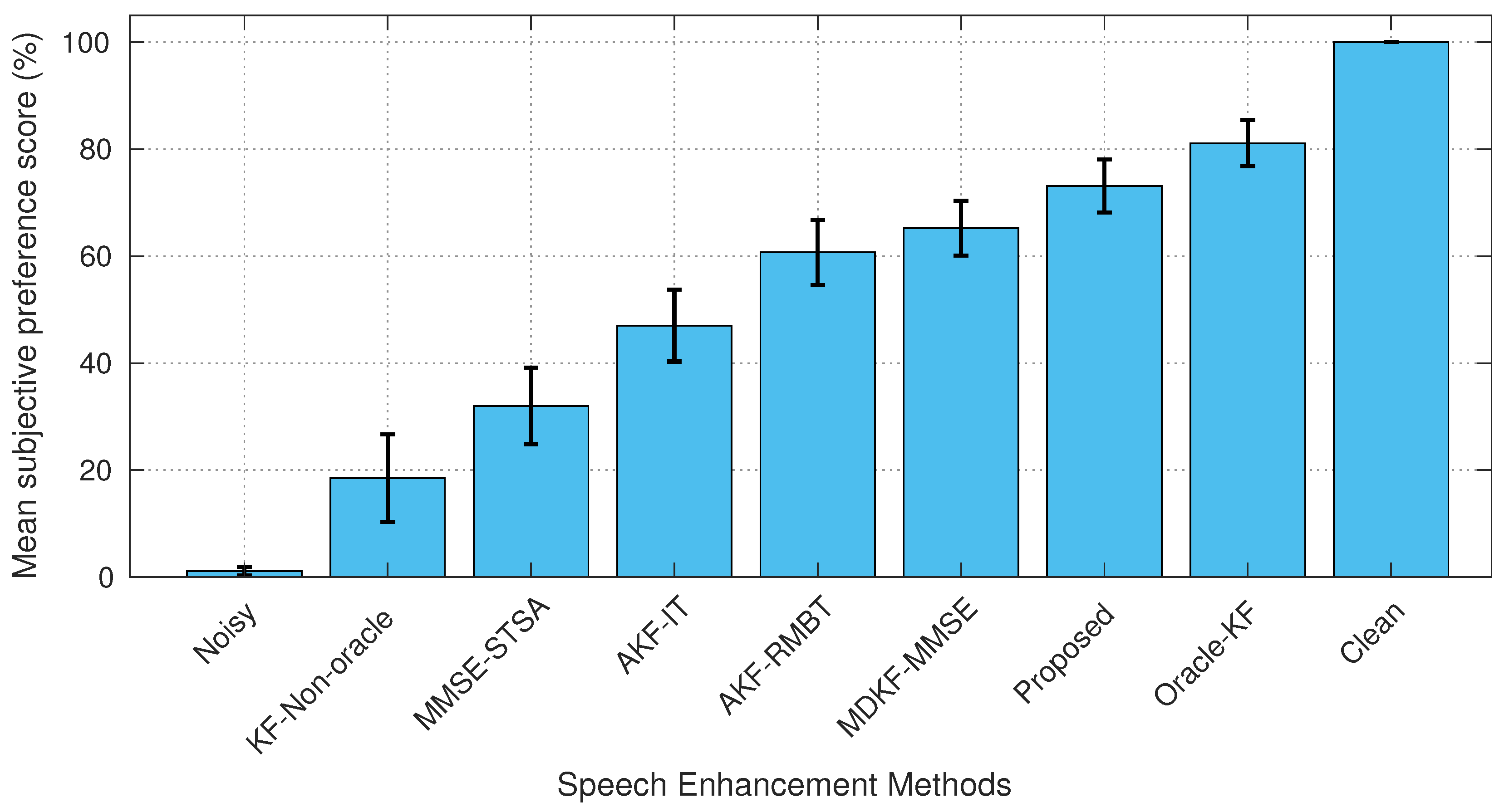
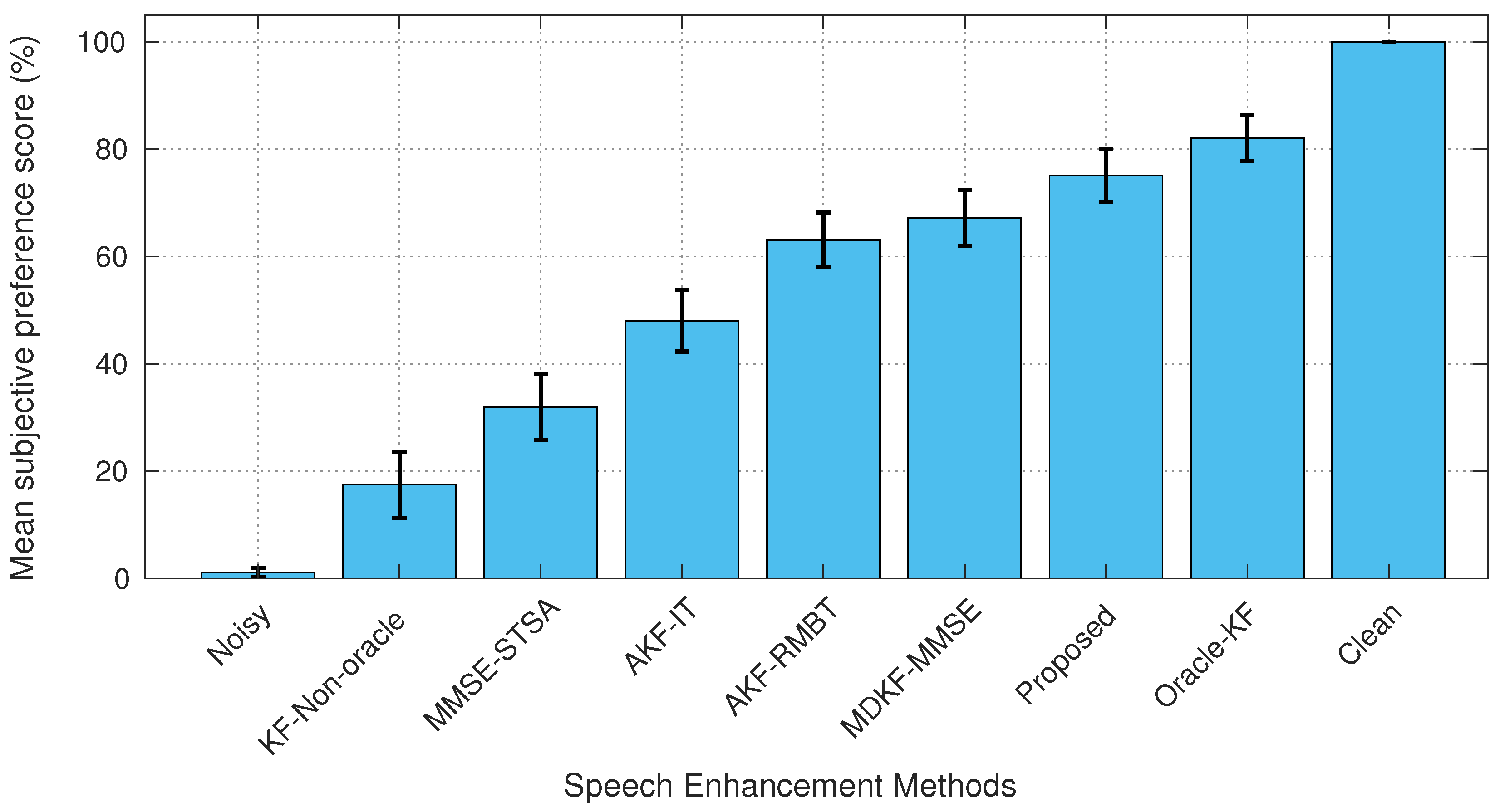
4.4. Subjective Evaluation
4.5. Specifications of the Competitive SEAs
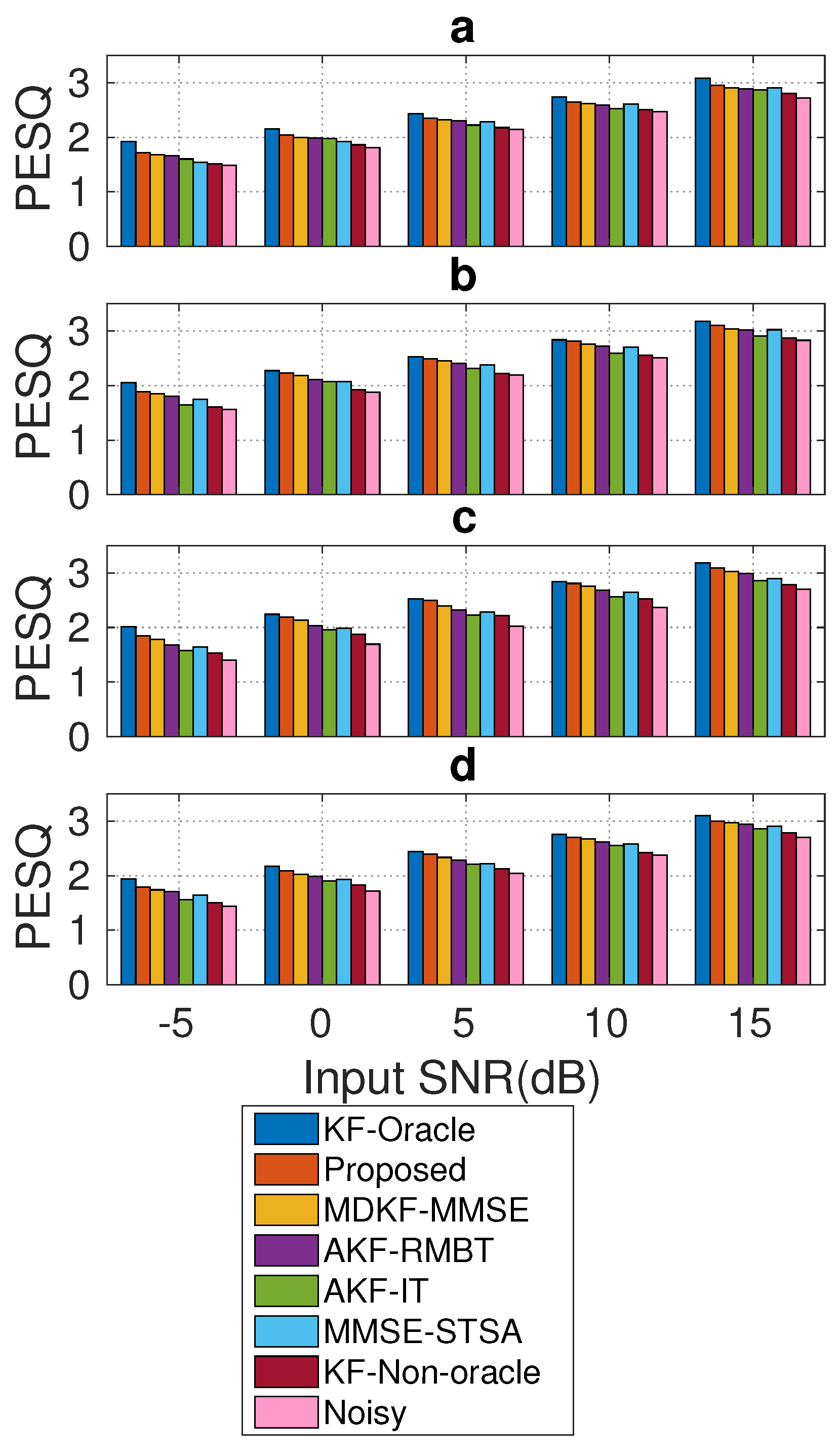
- Noisy: No enhancement (speech corrupted with noise);
- KF-oracle: KF, where (, ) and are computed from the clean speech and the noise signal, , ms, ms, and a rectangular window is used for framing;
- KF-Non-oracle: KF, where (, ) and are computed from the noisy speech, , ms, ms, and rectangular window is used for framing;
- MMSE-STSA [9]: It used ms, ms, and Hamming window for framing;
- AKF-IT [13]: AKF operates with two iterations, where initial (, ) and (, ) are computed from the noisy speech followed by re-estimation of them from the processed speech after first iteration, , noise LPC order , ms, ms, and rectangular window is used for framing;
- AKF-RMBT [22]: Robustness metric-based tuning of the AKF, where (, ) and (, ) are computed from the pre-whitened speech and initial silent frames, , , ms, ms, and rectangular window is used for framing;
- Proposed: Robustness and sensitivity tuning of the KF, where (, ) and are computed from the pre-whitened speech and estimated noise, , , ms, ms, rectangular window is used for time-domain frames, and Hamming window is used for acoustic frames.
5. Results and Discussion
5.1. Objective Quality Evaluation
5.2. Objective Intelligibility Evaluation
5.3. Spectrogram Analysis of the SEAs
5.4. Subjective Evaluation by AB Listening Test
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Loizou, P.C. Speech Enhancement: Theory and Practice, 2nd ed.; CRC Press Inc.: Boca Raton, FL, USA, 2013. [Google Scholar]
- Boll, S. Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans. Acoust. Speech Signal Process. 1979, 27, 113–120. [Google Scholar] [CrossRef] [Green Version]
- Berouti, M.; Schwartz, R.; Makhoul, J. Enhancement of speech corrupted by acoustic noise. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Washington, DC, USA, 2–4 April 1979; Volume 4, pp. 208–211. [Google Scholar] [CrossRef] [Green Version]
- Kamath, S.; Loizou, P. A Multi-Band Spectral Subtraction Method for Enhancing Speech Corrupted by Colored Noise. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 13–17 May 2002; Volume 4, pp. 4160–4164. [Google Scholar] [CrossRef]
- Paliwal, K.; Wójcicki, K.; Schwerin, B. Single-channel Speech Enhancement Using Spectral Subtraction in the Short-time Modulation Domain. Speech Commun. 2010, 52, 450–475. [Google Scholar] [CrossRef]
- Lim, J.S.; Oppenheim, A.V. Enhancement and bandwidth compression of noisy speech. Proc. IEEE 1979, 67, 1586–1604. [Google Scholar] [CrossRef]
- Scalart, P.; Filho, J.V. Speech enhancement based on a priori signal to noise estimation. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings, Atlanta, GA, USA, 9 May 1996; Volume 2, pp. 629–632. [Google Scholar]
- Plapous, C.; Marro, C.; Mauuary, L.; Scalart, P. A two-step noise reduction technique. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; Volume 1, pp. 289–292. [Google Scholar]
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 1109–1121. [Google Scholar] [CrossRef] [Green Version]
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum mean-square error log-spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1985, 33, 443–445. [Google Scholar] [CrossRef]
- Paliwal, K.; Schwerin, B.; Wójcicki, K. Speech enhancement using a minimum mean-square error short-time spectral modulation magnitude estimator. Speech Commun. 2012, 54, 282–305. [Google Scholar] [CrossRef]
- Paliwal, K.; Basu, A. A speech enhancement method based on Kalman filtering. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Dallas, TX, USA, 6–9 April 1987; Volume 12, pp. 177–180. [Google Scholar] [CrossRef]
- Gibson, J.D.; Koo, B.; Gray, S.D. Filtering of colored noise for speech enhancement and coding. IEEE Trans. Signal Process. 1991, 39, 1732–1742. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, D. Towards Scaling Up Classification-Based Speech Separation. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1381–1390. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Du, J.; Dai, L.; Lee, C. An Experimental Study on Speech Enhancement Based on Deep Neural Networks. IEEE Signal Process. Lett. 2014, 21, 65–68. [Google Scholar] [CrossRef]
- Williamson, D.S.; Wang, Y.; Wang, D. Complex Ratio Masking for Monaural Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 483–492. [Google Scholar] [CrossRef] [Green Version]
- So, S.; Paliwal, K.K. Modulation-domain Kalman filtering for single-channel speech enhancement. Speech Commun. 2011, 53, 818–829. [Google Scholar] [CrossRef]
- Roy, S.K.; Zhu, W.P.; Champagne, B. Single channel speech enhancement using subband iterative Kalman filter. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Montreal, QC, Canada, 22–25 May 2016; pp. 762–765. [Google Scholar] [CrossRef]
- Saha, M.; Ghosh, R.; Goswami, B. Robustness and Sensitivity Metrics for Tuning the Extended Kalman Filter. IEEE Trans. Instrum. Meas. 2014, 63, 964–971. [Google Scholar] [CrossRef]
- So, S.; George, A.E.W.; Ghosh, R.; Paliwal, K.K. A non-iterative Kalman filtering algorithm with dynamic gain adjustment for single-channel speech enhancement. Int. J. Signal Process. Syst. 2016, 4, 263–268. [Google Scholar] [CrossRef]
- So, S.; George, A.E.W.; Ghosh, R.; Paliwal, K.K. Kalman Filter with Sensitivity Tuning for Improved Noise Reduction in Speech. Circuits Syst. Signal Process. 2017, 36, 1476–1492. [Google Scholar] [CrossRef]
- George, A.E.; So, S.; Ghosh, R.; Paliwal, K.K. Robustness metric-based tuning of the augmented Kalman filter for the enhancement of speech corrupted with coloured noise. Speech Commun. 2018, 105, 62–76. [Google Scholar] [CrossRef]
- Vaseghi, S.V. Linear prediction models. In Advanced Digital Signal Processing and Noise Reduction; John Wiley & Sons: Hoboken, NJ, USA, 2009; Chapter 8; pp. 227–262. [Google Scholar]
- Varga, A.; Steeneken, H.J. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- Oppenheim, A.V.; Schafer, R.W. Discrete-Time Signal Processing, 3rd ed.; Prentice Hall Press: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Gerkmann, T.; Hendriks, R.C. Unbiased MMSE-Based Noise Power Estimation With Low Complexity and Low Tracking Delay. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 1383–1393. [Google Scholar] [CrossRef]
- Pearce, D.; Hirsch, H. The aurora experimental framework for the performance evaluation of speech recognition systems under noisy conditions. In Proceedings of the Sixth International Conference on Spoken Language Processing, ICSLP 2000/INTERSPEECH 2000, Beijing, China, 16–20 October 2000; pp. 29–32. [Google Scholar]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)—A new method for speech quality assessment of telephone networks and codecs. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (Cat. No.01CH37221), Salt Lake City, UT, USA, 7–11 May 2001; Volume 2, pp. 749–752. [Google Scholar] [CrossRef]
- Vincent, E.; Gribonval, R.; Fevotte, C. Performance measurement in blind audio source separation. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1462–1469. [Google Scholar] [CrossRef] [Green Version]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An Algorithm for Intelligibility Prediction of Time–Frequency Weighted Noisy Speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]














Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roy, S.K.; Paliwal, K.K. Robustness and Sensitivity Tuning of the Kalman Filter for Speech Enhancement. Signals 2021, 2, 434-455. https://doi.org/10.3390/signals2030027
Roy SK, Paliwal KK. Robustness and Sensitivity Tuning of the Kalman Filter for Speech Enhancement. Signals. 2021; 2(3):434-455. https://doi.org/10.3390/signals2030027
Chicago/Turabian StyleRoy, Sujan Kumar, and Kuldip K. Paliwal. 2021. "Robustness and Sensitivity Tuning of the Kalman Filter for Speech Enhancement" Signals 2, no. 3: 434-455. https://doi.org/10.3390/signals2030027
APA StyleRoy, S. K., & Paliwal, K. K. (2021). Robustness and Sensitivity Tuning of the Kalman Filter for Speech Enhancement. Signals, 2(3), 434-455. https://doi.org/10.3390/signals2030027