
Cybersecurity for AI Systems: A Survey



Abstract
:1. Introduction
2. Literature Review
3. AI Attacks and Defense Mechanisms
- The need for better resources for self-upgradation of AI systems can be exploited by adversaries
- Implementation of malicious goals make the AI systems unfriendly
- Flaws in the user-friendly features
- Use of different techniques to make different stages of AI free from the boundaries of actions expose the AI systems to adversaries
3.1. Types of Failures
3.1.1. Categories of Unintentional Failures
- Reward Hacking: Reward hacking is a failure mode that an AI/ML system experiences when the underlying framework is a reinforcement learning algorithm. Reward hacking appears when an agent has more return as reward in an unexpected manner in a game environment [61]. This unexpected behavior unsettles the safety of the system. Yuan et al. [62] proposed a new multi-step reinforcement learning framework, where the reward function generates a discounted future reward and, thus, reduces the influence of immediate reward on the current state action pair. The proposed algorithm creates the defense mechanism to mitigate the effect of reward hacking in AI/ML systems.
- Distributed Shift: This type of mode appears when an AI/ML model that once performed well in an environment generates dismal performance when deployed to perform in a different environment. One such example is when the training and test data come from two different probability distributions [63]. The distribution shift is further subdivided into three types [64]:
- 1.
- Covariate Shift: The shifting problem arises due to the change in input features (covariates) over time, while the distribution of the conditional labeling function remains the same.
- 2.
- Label Shift: This mode of failure is complementary to covariate shift, such that the distribution of class conditional probability does not change but the label marginal probability distribution changes.
- 3.
- Concept Shift: Concept shift is a failure related to the label shift problem where the definitions of the label (i.e., the posteriori probability) experience spatial or temporal changes.
- Natural Adversarial Examples: The natural adversarial examples are real-world examples that are not intentionally modified. Rather, they occur naturally, and result in considerable loss of performance of the machine learning algorithms [68]. The instances are semantically similar to the input, legible and facilitate interpretation (e.g., image data) of the outcome [69]. Deep neural networks are susceptible to natural adversarial examples.
3.1.2. Categories of Intentional Failures
- 1
- Whiteb ox Attack: In this type of attack, the adversary has access to the parameters of the underlying architecture of the model, the algorithm used for training, weights, training data distribution, and biases [71,72]. The adversary uses this information to find the model’s vulnerable feature space. Later, the model is manipulated by modifying an input using adversarial crafting methods. An example of the whitebox attack and adversarial crafting methods are discussed in later sections. The researchers in [73,74] showed that adversarial training of the data, filled with some adversarial instances, actually helps the model/system become robust against whitebox attacks.
- 2
- Blackbox Attack: In blackbox attacks the attacker does not know anything about the ML system. The attacker has access to only two types of information. The first is the hard label, where the adversary obtained only the classifier’s predicted label, and the second is confidence, where the adversary obtained the predicted label along with the confidence score. The attacker uses information about the inputs from the past to understand vulnerabilities of the model [70]. Some blackbox attacks are discussed in later sections. Blackbox attacks can further be divided into three categories:
- Non-Adaptive Blackbox Attack: In this category of blackbox attack, the adversary has the knowledge of distribution of training data for a model, T. The adversary chooses a procedure, P, for a selected local model, T’, and trains the model on known data distribution using P for T’ to approximate the already learned T in order to trigger misclassification using whitebox strategies [53,75].
- Adaptive Blackbox Attack: In adaptive blackbox attack the adversary has no knowledge of the training data distribution or the model architecture. Rather, the attacker approaches the target model, T, as an oracle. The attacker generates a selected dataset with a label accessed from adaptive querying of the oracle. A training process, P, is chosen with a model, T’, to be trained on the labeled dataset generated by the adversary. The model T’ introduces the adversarial instances using whitebox attacks to trigger misclassification by the target model T [70,76].
- Strict Blackbox Attack: In this blackbox attack category, the adversary does not have access to the training data distribution but could have the labeled dataset (x, y) collected from the target model, T. The adversary can perturb the input to identify the changes in the output. This attack would be successful if the adversary has a large set of dataset (x, y) [70,71].
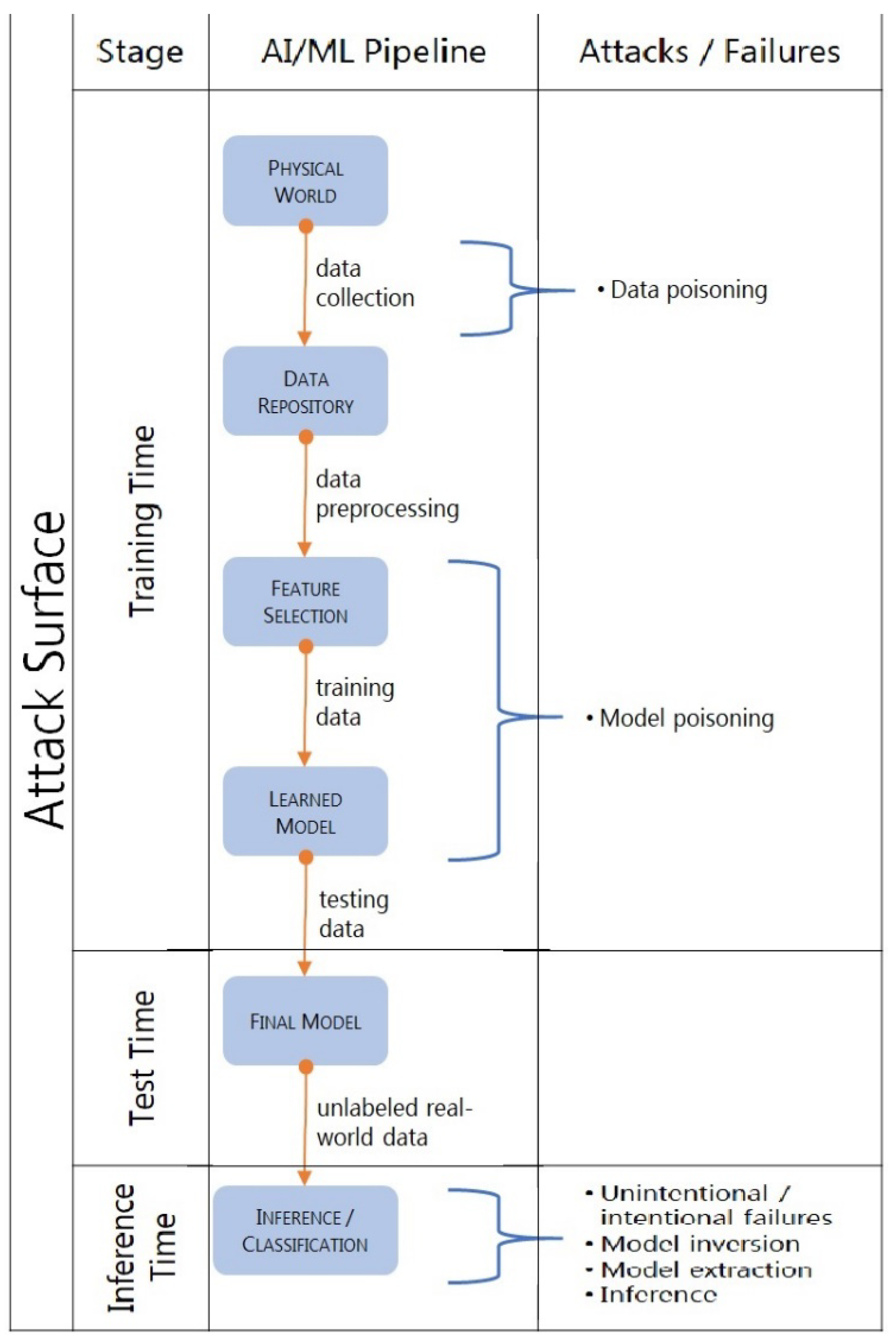
3.2. Anatomy of Cyberattacks
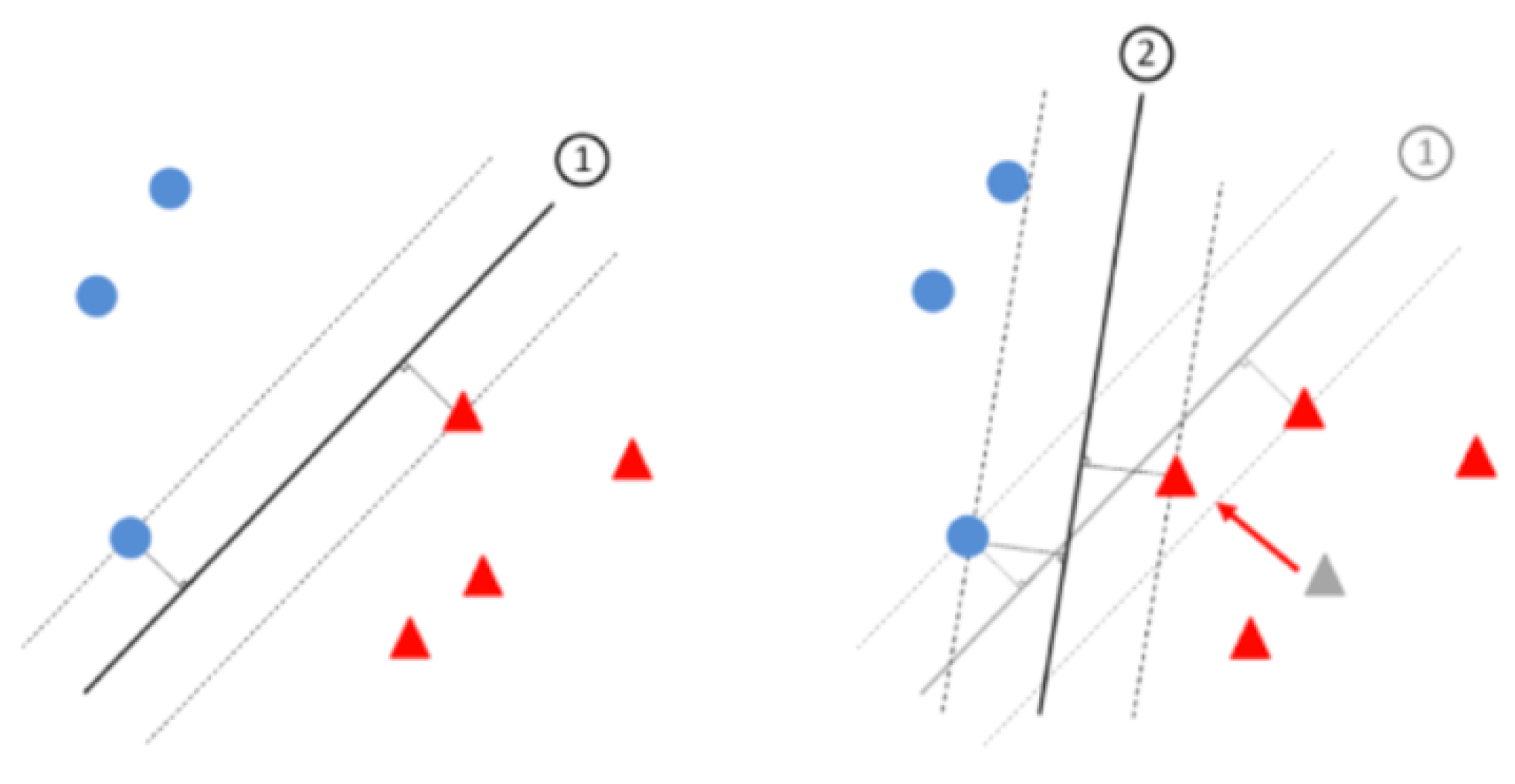
3.3. Poisoning Attack
3.3.1. Dataset Poisoning Attacks
- Data Modification: The adversary updates or deletes training data. Here, the attacker does not have access to the algorithm. They can only manipulate labels. For instance, the attacker can draw new labels at random from the training pool, or can optimize the labels to cause maximum disruption.
- Data Injection: Even if the adversary does not have access to the training data or learning algorithm, he or she can still inject incorrect data into the training set. This is similar to manipulation, but the difference is that the adversary introduces new malicious data into the training pool, not just labels.
- High Sensitive: An anomaly detector usually considers points as anomalous when the point is far off from its closest neighbors. The anomaly detector cannot identify a specific point as abnormal if it is surrounded by other points, even if that tiny cluster of points are far off from remaining points. So, if an adversary/attacker concentrates poison points in a few anomalous locations, then the anomalous location is considered benign by the detector.
- Low Sensitive: An anomaly detector drops all points away from the centroid by a particular distance. Whether the anomaly detector deems a provided point as abnormal does not vary much by addition or deletion of some points, until the centroid of data does not vary considerably.
3.3.2. Data Poisoning Defense Mechanisms
- 1.
- Adversarial Training: The goal of adversarial training is to inject instances generated by the adversary into the training set to increase the strength of the model [87,88]. The defender follows the same strategy, by generating the crafted samples, using the brute force method, and training the model by feeding the clean and the generated instances. Adversarial training is suitable if the instances are crafted on the original model and not on a locally-trained surrogate model [89,90].
- 2.
- Feature Squee zing: This defense strategy hardens the training models by diminishing the number of features and, hence, the complexity of data [91]. This, in turn, reduces the sensitivity of the data, which evades the tainted data marked by the adversary.
- 3.
- Transferability blocking: The true defense mechanism against blackbox attacks is to obstruct the transferability of the adversarial samples. The transferability enables the usage of adversarial samples in different models trained on different datasets. Null labeling [92] is a procedure that blocks transferability, by introducing null labels into the training dataset, and trains the model to discard the adversarial samples as null labeled data. This approach does not reduce the accuracy of the model with normal data instances.
- 4.
- MagNet: This scheme is used to arrest a range of blackbox attacks through the use of a detector and a reformer [93]. The detector identifies the differences between the normal and the tainted samples by measuring the distance between them with respect to a threshold. The reformer converts a tampered instance to a legitimate one by means of an autoencoder.
- 5.
- Defense-GAN: To stave off both blackbox and whitebox attacks, the capability of General Adversarial Network (GAN) [94] is leveraged [95]. GAN uses a generator to construct the input images by minimizing the reconstruction error. The reconstructed images are fed to the system as input, where the genuine instances are closer to the generator than the tainted instances. Hence, the performance of the attack degrades.
- 6.
- Local Intrinsic Dimensionality: Weerashinghe et al. [96] addressed resistance against data poisoning attack on SVM classifiers during training. They used Local Intrinsic Dimensionality (LID), a metric of computing dimension of local neighborhood sub-space for each data instance. They also used K-LID approximation for each sample to find the likelihood ratio of K-LID values from the distribution of benign samples to that from tainted samples. Next, the function of the likelihood ratio is fitted to predict the likelihood ratio for the unseen data points’ K-LID values. The technique showed stability against adversarial attacks on label flipping.
- 7.
- Reject On Negative Impact (RONI): The functioning of the RONI technique is very similar to that of the Leave-One-Out (LOO) validation procedure [97]. Although effective, this technique is computationally expensive and may suffer from overfitting if the training dataset used by the algorithm is small compared to the number of features. RONI defense is not well suited for applications that involve deep learning architectures, as those applications would demand a larger training dataset [39]. In [98], a defensive mechanism was proposed based on the k-Nearest Neighbors technique, which recommends relabeling possible malicious data points based on the labels of their neighboring samples in the training dataset. However, this strategy fails to detect attacks in which the subsets of poisoning points are close. An outlier detection scheme was proposed in [99] for classification tasks. In this strategy, the outlier detectors for each class are trained with a small fraction of trusted data points. This strategy is effective in attack scenarios where the hacker does not model specific attack constraints. For example, if the training dataset is poisoned only by flipping the labels, then this strategy can detect those poisoned data points which are far from the genuine ones. Here, it is important to keep in mind that outlier detectors used in this technique need to first be trained on small curated training points that are known to be genuine [99].
3.3.3. Model Poisoning Attacks
- 1.
- Outsource training attack, when training is outsourced, and
- 2.
- Transfer learning attack, when a pre-trained model is outsourced and used.
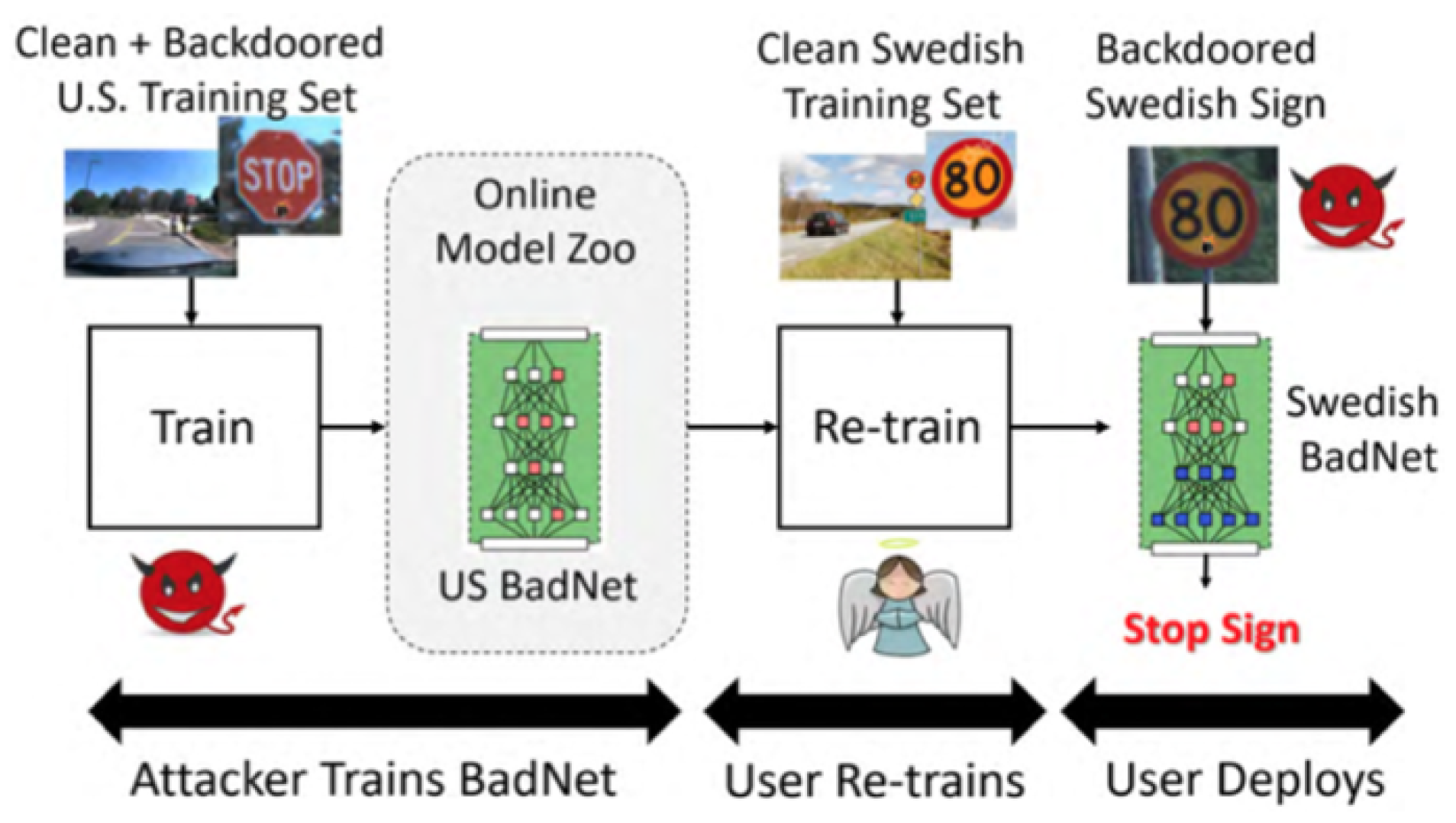
Outsourced Training Attack
- Securely hosting and disseminating pre-trained models in virtual repositories that guarantee integrity, to preclude benevolent models from being manipulated. The security is characterized by the fact that virtual archives should have digital signatures of the trainer on the pre-trained models with the public key cryptosystem [43].
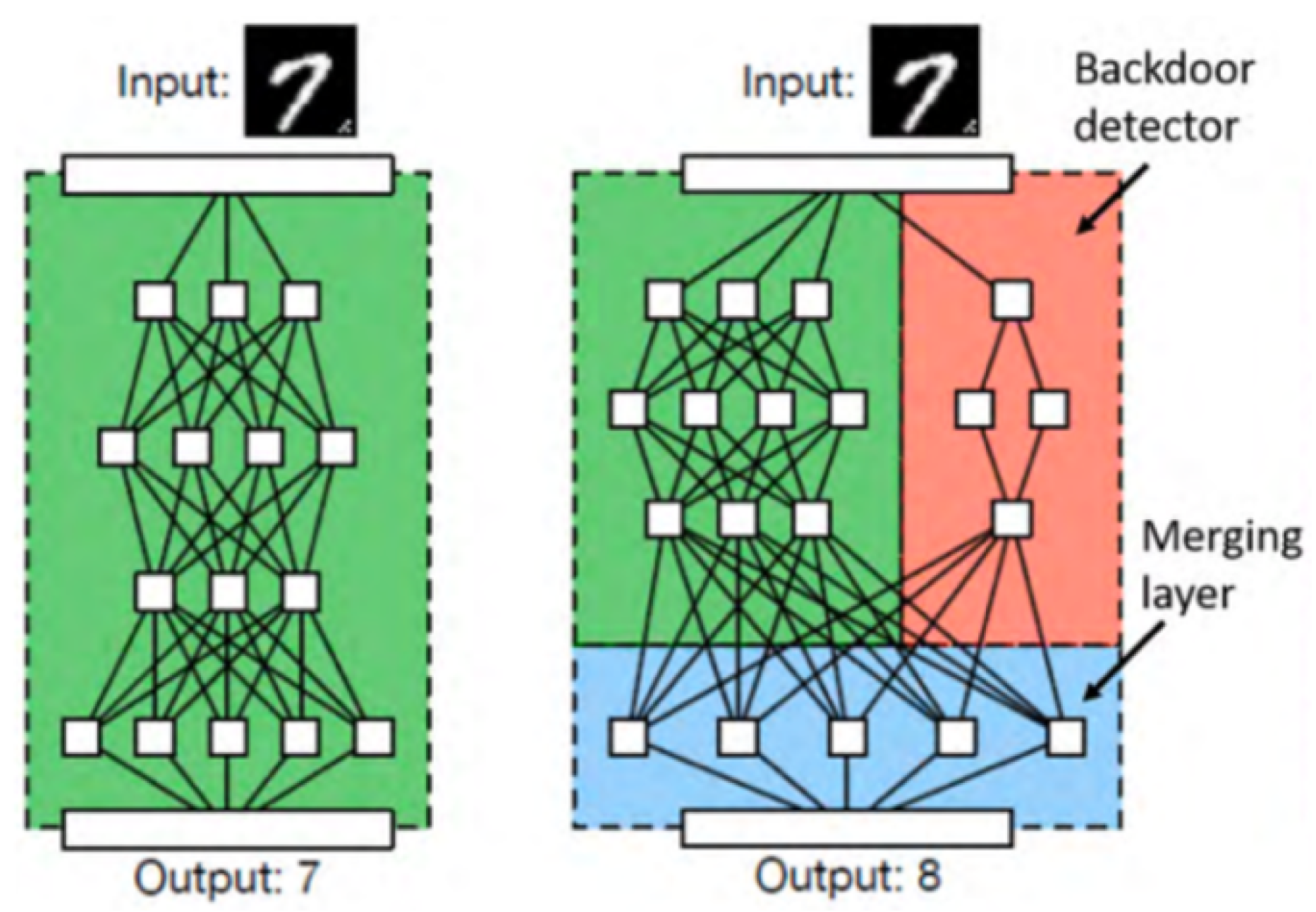
- Identifying backdoors in malevolently trained models acquired from an untrustworthy trainer by retraining or fine-tuning the untrusted model with some added computational cost [44,46]. These researchers considered fully outsourced training attacks. Another research [107], proposed a defense mechanism with an assumption that the user has access to both clean and backdoored instances.
Transfer Learning Attack
Attack on Federated Learning
- Explicit Boosting: The adversary updates the boosting steps to void the global aggregated effect of the individual models locally distributed over different devices. The attack is based on running of boosting steps of SGD until the attacker obtains the parameter weight vector, starting from the global weight, to minimize the training loss over the data and the class label. This enables the adversary to obtain the initial update, which is used to determine the final adversarial update. The final update is obtained by the product of the final adversarial update and the inverse of adversarial scaling (i.e., the boosting factor), so that the server cannot identify the adversarial effect.
- Alternating Minimization: The authors in [45] showed that, in an explicit boosting attack, the malicious updates on boosting steps could not evade the potential defense related to measuring accuracy. Alternating minimization was introduced to exploit the fact that it is updates related only to the targeted class that need to be boosted. This strategy improves adversarial attack that can bypass the defense mechanism with the goal of minimizing training loss and boosting parameter updates for the adversarial goals and achieved a high success rate.
- Robust aggregation methods: These methods incorporate security into federated learning by exploring different statistical metrics that could replace the average (mean) statistic, while aggregating the effects of the models, such as trimmed mean, geometric median, coordinate-median, etc. [47,111,113,114,115,116]. Introducing the new statistic while aggregating has the primary objective of staving off attacks during model convergence. Bernstein et al. [117] proposed a sign aggregation technique on the SGD algorithm, distributed over individual machines or devices. The devices interact with the server by communicating the signs of the gradients. The server aggregates the signs and sends this to the individual machines, which use it to update their model weights. The weight update rule can be expressed by the following equation:where is the weight update of the device i at time t. is the weight the server sent to the set of devices At at time t and is the server learning rate.
- Robust Learning Rate: Ozdayi, Katancioglu, and Gel [120] introduced the defense mechanism by making the model learning rate robust with a pre-specified boundary of malicious agents. With the help of the updated learning rate, the adversarial model weight approaches the direction of the genuine model weight. This work is an extension of the signed aggregation proposed in [117]. The authors proposed a parameter-learning threshold . The learning rate for the i-th dimension of the data can be represented as:
3.4. Model Inversion Attack
3.5. Model Extraction Attack
3.6. Inference Attack
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Comiter, M. Attacking Artificial Intelligence: AI’s Security Vulnerability and What Policymakers Can Do about It. Harv. Kennedy Sch. Belfer Cent. Sci. Int. Aff. 2019, pp. 1–90. Available online: https://www.belfercenter.org/sites/default/files/2019-08/AttackingAI/AttackingAI.pdf (accessed on 8 March 2023).
- Mcgraw, G.; Bonett, R.; Figueroa, H.; Shepardson, V. Security engineering for machine learning. IEEE Comput. 2019, 52, 54–57. [Google Scholar] [CrossRef]
- Ma, Y.; Xie, T.; Li, J.; Maciejewski, R. Explaining vulnerabilities to adversarial machine learning through visual analytics. IEEE Trans. Vis. Comput. Graph. 2019, 26, 1075–1085. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Park, N. Blockchain-based data-preserving AI learning environment model for AI cybersecurity systems in IoT service environments. Appl. Sci. 2020, 10, 4718. [Google Scholar] [CrossRef]
- Mozaffari-Kermani, M.; Sur-Kolay, S.; Raghunathan, A.; Jha, N.K. Systematic poisoning attacks on and defenses for machine learning in healthcare. IEEE J. Biomed. Health Inform. 2014, 19, 1893–1905. [Google Scholar] [CrossRef] [PubMed]
- Sadeghi, K.; Banerjee, A.; Gupta, S.K.S. A system-driven taxonomy of attacks and defenses in adversarial machine learning. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 4, 450–467. [Google Scholar] [CrossRef]
- Sagar, R.; Jhaveri, R.; Borrego, C. Applications in security and evasions in machine learning: A survey. Electronics 2020, 9, 97. [Google Scholar] [CrossRef]
- Pitropakis, N.; Panaousis, E.; Giannetsos, T.; Anastasiadis, E.; Loukas, G. A taxonomy and survey of attacks against machine learning. Comput. Sci. Rev. 2019, 34, 100199. [Google Scholar] [CrossRef]
- Cao, N.; Li, G.; Zhu, P.; Sun, Q.; Wang, Y.; Li, J.; Yan, M.; Zhao, Y. Handling the adversarial attacks. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 2929–2943. [Google Scholar] [CrossRef]
- Wang, X.; Li, J.; Kuang, X.; Tan, Y.; Li, J. The security of machine learning in an adversarial setting: A survey. J. Parallel Distrib. Comput. 2019, 130, 12–23. [Google Scholar] [CrossRef]
- Rouani, B.D.; Samragh, M.; Javidi, T.; Koushanfar, F. Safe machine learning and defeating adversarial attacks. IEEE Secur. 2019, 17, 31–38. [Google Scholar] [CrossRef]
- Qiu, S.; Liu, Q.; Zhou, S.; Wu, C. Review of artificial intelligence adversarial attack and defense technologies. Appl. Sci. 2019, 9, 909. [Google Scholar] [CrossRef]
- Biggio, B.; Roli, F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef]
- Sethi, T.S.; Kantardzic, M.; Lyu, L.; Chen, J. A dynamic-adversarial mining approach to the security of machine learning. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1245. [Google Scholar] [CrossRef]
- Chen, T.; Liu, J.; Xiang, Y.; Niu, W.; Tong, E.; Han, Z. Adversarial attack and defense in reinforcement learning-from AI security view. Cybersecurity 2019, 2, 1–22. [Google Scholar] [CrossRef]
- Li, G.; Ota, K.; Dong, M.; Wu, J.; Li, J. DeSVig: Decentralized swift vigilance against adversarial attacks in industrial artificial intelligence systems. IEEE Trans. Ind. Inform. 2019, 16, 3267–3277. [Google Scholar] [CrossRef]
- Garcia-Ceja, E.; Morin, B.; Aguilar-Rivera, A.; Riegler, M.A. A Genetic Attack Against Machine Learning Classifiers to Steal Biometric Actigraphy Profiles from Health Related Sensor Data. J. Med. Syst. 2020, 44, 1–11. [Google Scholar] [CrossRef]
- Biggio, B.; Russu, P.; Didaci, L.; Roli, F. Adversarial biometric recognition: A review on biometric system security from the adversarial machine-learning perspective. IEEE Signal Process. Mag. 2015, 32, 31–41. [Google Scholar] [CrossRef]
- Ren, Y.; Zhou, Q.; Wang, Z.; Wu, T.; Wu, G.; Choo, K.K.R. Query-efficient label-only attacks against black-box machine learning models. Comput. Secur. 2020, 90, 101698. [Google Scholar] [CrossRef]
- Wang, D.; Li, C.; Wen, S.; Nepal, S.; Xiang, Y. Man-in-the-middle attacks against machine learning classifiers via malicious generative models. IEEE Trans. Dependable Secur. Comput. 2020, 18, 2074–2087. [Google Scholar] [CrossRef]
- Qiu, J.; Du, L.; Chen, Y.; Tian, Z.; Du, X.; Guizani, M. Artificial intelligence security in 5G networks: Adversarial examples for estimating a travel time task. IEEE Veh. Technol. Mag. 2020, 15, 95–100. [Google Scholar] [CrossRef]
- Benzaid, C.; Taleb, T. AI for beyond 5G networks: A cyber-security defense or offense enabler? IEEE Networks 2020, 34, 140–147. [Google Scholar] [CrossRef]
- Apruzzese, G.; Andreolini, M.; Marchetti, M.; Colacino, V.G.; Russo, G. AppCon: Mitigating Evasion Attacks to ML Cyber Detectors. Symmetry 2020, 12, 653. [Google Scholar] [CrossRef]
- Zhang, S.; Xie, X.; Xu, Y. A brute-force black-box method to attack machine learning-based systems in cybersecurity. IEEE Access 2020, 8, 128250–128263. [Google Scholar] [CrossRef]
- Liu, K.; Yang, H.; Ma, Y.; Tan, B.; Yu, B.; Young, E.F.; Karri, R.; Garg, S. Adversarial perturbation attacks on ML-based cad: A case study on CNN-based lithographic hotspot detection. ACM Trans. Des. Autom. Electron. Syst. 2020, 25, 1–31. [Google Scholar] [CrossRef]
- Katzir, Z.; Elovici, Y. Quantifying the resilience of machine learning classifiers used for cyber security. Expert Syst. Appl. 2018, 92, 419–429. [Google Scholar] [CrossRef]
- Chen, S.; Xue, M.; Fan, L.; Hao, S.; Xu, L.; Zhu, H.; Li, B. Automated poisoning attacks and defenses in malware detection systems: An adversarial machine learning approach. Comput. Secur. 2018, 73, 326–344. [Google Scholar] [CrossRef]
- Gardiner, J.; Nagaraja, S. On the security of machine learning in malware c&c detection: A survey. ACM Comput. Surv. 2016, 49, 1–39. [Google Scholar]
- Dasgupta, P.; Collins, J. A survey of game theoretic approaches for adversarial machine learning in cybersecurity tasks. AI Mag. 2019, 40, 31–43. [Google Scholar] [CrossRef]
- Al-Rubaie, M.; Chang, J.M. Privacy-preserving machine learning: Threats and solutions. IEEE Secur. Priv. 2019, 17, 49–58. [Google Scholar] [CrossRef]
- Hansman, S.; Hunt, R. A taxonomy of network and computer attacks. Comput. Secur. 2005, 24, 31–43. [Google Scholar] [CrossRef]
- Gao, J.B.; Zhang, B.W.; Chen, X.H.; Luo, Z. Ontology-based model of network and computer attacks for security assessment. J. Shanghai Jiaotong Univ. 2013, 18, 554–562. [Google Scholar] [CrossRef]
- Gonzalez, L.M.; Lupu, E.; Emil, C. The secret of machine learning. ITNow 2018, 60, 38–39. [Google Scholar] [CrossRef]
- Mcdaniel, P.; Papernot, N.; Celik, Z.B. Machine learning in adversarial settings. IEEE Secur. Priv. 2016, 14, 68–72. [Google Scholar] [CrossRef]
- Barreno, M.; Nelson, B.; Joseph, A.D.; Tygar, J.D. The security of machine learning. Mach. Learn. 2010, 81, 121–148. [Google Scholar] [CrossRef]
- Barreno, M.; Nelson, B.; Sears, R.; Joseph, A.D.; Tygar, J.D. Can machine learning be secure? In Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security, Taipei, Taiwan, 21–24 March 2006; pp. 16–25. [Google Scholar]
- Biggio, B.; Fumera, G.; Roli, F. Security evaluation of pattern classifiers under attack. IEEE Trans. Knowl. Data Eng. 2013, 26, 984–996. [Google Scholar] [CrossRef]
- Muñoz-González, L.; Biggio, B.; Demontis, A.; Paudice, A.; Wongrassamee, V.; Lupu, E.C.; Roli, F. Towards poisoning of deep learning algorithms with back-gradient optimization. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 27–38. [Google Scholar]
- Nelson, B.; Barreno, M.; Chi, F.J.; Joseph, A.D.; Rubinstein, B.I.; Saini, U.; Sutton, C.; Tygar, J.D.; Xia, K. Exploiting machine learning to subvert your spam filter. In Proceedings of the First USENIX Workshop on Large Scale Exploits and Emergent Threats, San Francisco, CA, USA, 15 April 2008; Vulume 8, pp. 16–17. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning attacks against support vector machines. arXiv 2012, arXiv:1206.6389. [Google Scholar]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P.; Calo, S. Model poisoning attacks in federated learning. In Proceedings of the Workshop on Security in Machine Learning (SecML), Collocated with the 32nd Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7 December 2018. [Google Scholar]
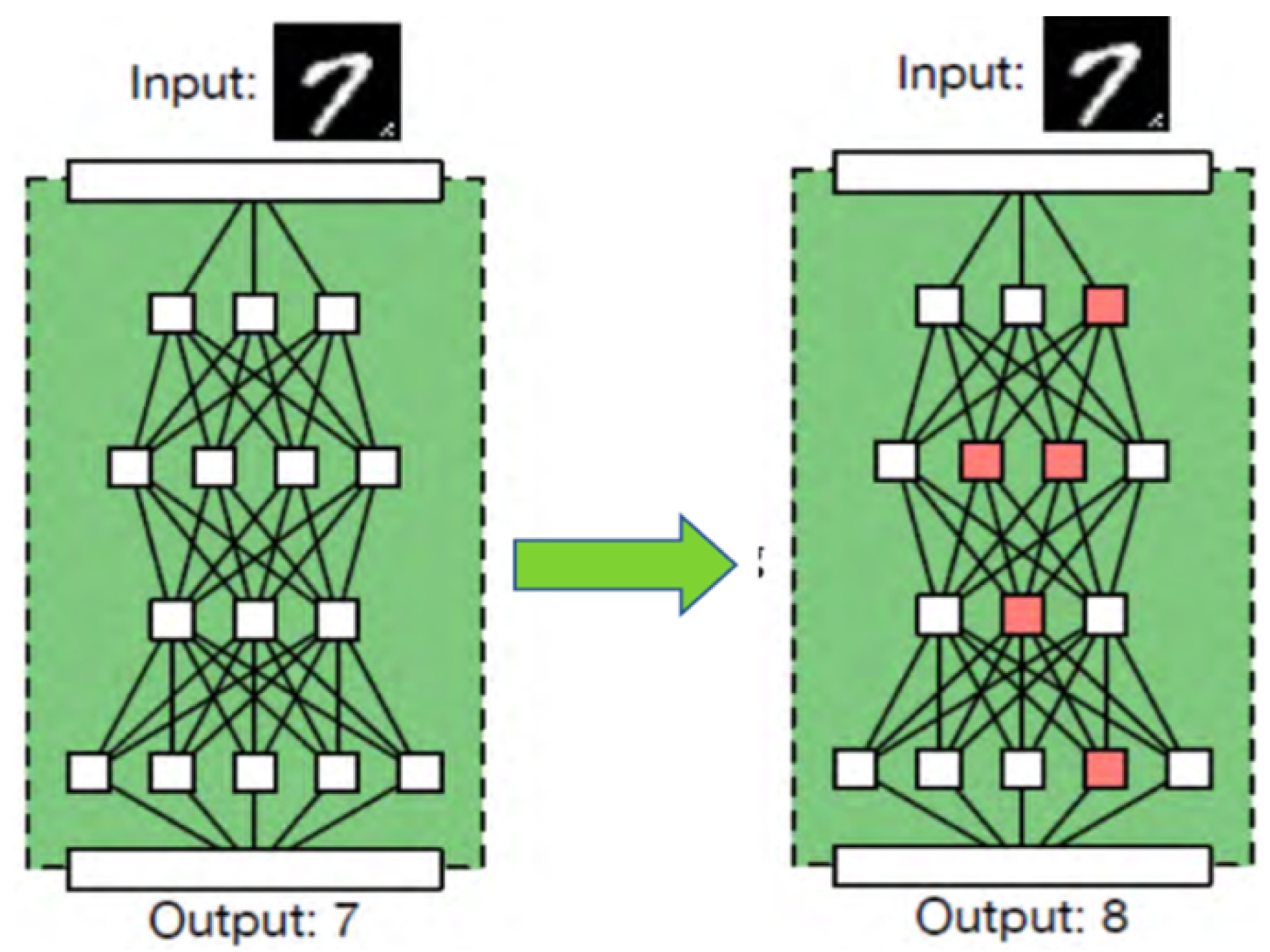
- Gu, T.; Liu, K.; Dolan-Gavitt, B.; Garg, S. Badnets: Evaluating backdooring attacks on deep neural networks. IEEE Access 2019, 7, 47230–47244. [Google Scholar] [CrossRef]
- Samuel, J.; Mathewson, N.; Cappos, J.; Dingledine, R. Survivable key compromise in software update systems. In Proceedings of the 17th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 4–8 October 2010; pp. 61–72. [Google Scholar]
- Liu, K.; Dolan-Gavitt, B.; Garg, S. Fine-pruning: Defending against backdooring attacks on deep neural networks. In Proceedings of the International Symposium on Research in Attacks, Intrusions, and Defenses, Heraklion, Crete, Greece, 10–12 September 2018; pp. 273–294. [Google Scholar]
- Gu, T.; Dolan-Gavitt, B.; Garg, S. Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv 2017, arXiv:1708.06733. [Google Scholar]
- Wang, B.; Yao, Y.; Shan, S.; Li, H.; Viswanath, B.; Zheng, H.; Zhao, B.Y. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 707–723. [Google Scholar]
- Mcmahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference of Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Online, 26–28 August 2020; pp. 2938–2948. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar]
- Salem, A.; Zhang, Y.; Humbert, M.; Berrang, P.; Fritz, M.; Backes, M. ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models. arXiv 2018, arXiv:1806.01246. [Google Scholar]
- Jia, J.; Salem, A.; Backes, M.; Zhang, Y.; Gong, N.Z. Memguard: Defending against black-box membership inference attacks via adversarial examples. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 259–274. [Google Scholar]
- Dwork, C.; Mcsherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. Theory Cryptogr. Conf. 2006, 3876, 265–284. [Google Scholar]
- Tramèr, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing machine learning models via prediction apis. USENIX Secur. Symp. 2016, 16, 601–618. [Google Scholar]
- Reith, R.N.; Schneider, T.; Tkachenko, O. Efficiently stealing your machine learning models. In Proceedings of the 18th ACM Workshop on Privacy in the Electronic Society, London, UK, 11 November 2019; pp. 198–210. [Google Scholar]
- Weinsberg, U.; Bhagat, S.; Ioannidis, S.; Taft, N. BlurMe: Inferring and obfuscating user gender based on ratings. In Proceedings of the Sixth ACM Conference on Recommender Systems, Dublin, Ireland, 9–13 September 2012; pp. 195–202. [Google Scholar]
- Kaloudi, N.; Li, J. The AI-based cyber threat landscape: A survey. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Turchin, A. A Map: AGI Failures Modes and Levels, 2023. Available online: https://www.lesswrong.com/posts/hMQ5iFiHkChqgrHiH/a-map-agi-failures-modes-and-levels (accessed on 8 March 2023).
- Turchin, A.; Denkenberger, D. Classification of global catastrophic risks connected with artificial intelligence. AI Soc. 2020, 35, 147–163. [Google Scholar] [CrossRef]
- Yampolskiy, R.V. Taxonomy of pathways to dangerous artificial intelligence. In Proceedings of the Workshops at the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–13 February 2016; pp. 143–158. [Google Scholar]
- Kumar, R.S.S.; Brien, D.O.; Albert, K.; Viljöen, S.; Snover, J. Failure Modes in Machine Learning. 2019. Available online: https://arxiv.org/ftp/arxiv/papers/1911/1911.11034.pdf (accessed on 8 March 2023).
- Hadfield-Menell, D.; Milli, S.; Abbeel, P.; Russell, S.; Dragan, A. Inverse Reward Design. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper/2017/hash/32fdab6559cdfa4f167f8c31b9199643-Abstract.html (accessed on 8 March 2023).
- Yuan, Y.; Yu, Z.L.; Gu, Z.; Deng, X.; Li, Y. A novel multi-step reinforcement learning method for solving reward hacking. Appl. Intell. 2019, 49, 2874–2888. [Google Scholar] [CrossRef]
- Leike, J.; Martic, M.; Krakovna, V.; Ortega, P.A.; Everitt, T.; Lefrancq, A.; Orseau, L.; Legg, S. AI safety Gridworlds. arXiv 2017, arXiv:1711.09883. [Google Scholar]
- Zhang, A.; Lipton, Z.C.; Li, M.; Smola, A. Dive into Deep Learning. arXiv 2021, arXiv:2106.11342. [Google Scholar]
- Subbaswamy, A.; Saria, S. From development to deployment: Dataset shift, causality, and shift-stable models in health AI. Biostatistics 2020, 21, 345–352. [Google Scholar] [CrossRef]
- Rojas-Carulla, M.; Schölkopf, B.; Turner, R.; Peters, J. Invariant models for causal transfer learning. J. Mach. Learn. Res. 2018, 19, 1309–1342. [Google Scholar]
- Rothenhäusler, D.; Meinshausen, N.; Bühlmann, P.; Peters, J. Anchor regression: Heterogeneous data meet causality. J. R. Stat. Soc. Ser. B 2021, 83, 215–246. [Google Scholar] [CrossRef]
- Gilmer, J.; Adams, R.P.; Goodfellow, I.; Andersen, D.; Dahl, G.E. Motivating the Rules of the Game for Adversarial Example Research. arXiv 2018, arXiv:1807.06732. [Google Scholar]
- Zhao, Z.; Dua, D.; Singh, S. Generating natural adversarial examples. arXiv 2017, arXiv:1710.11342. [Google Scholar]
- Chakraborty, A.; Alam, M.; Dey, V.; Chattopadhyay, A.; Mukhopadhyay, D. Adversarial attacks and defences: A survey. arXiv 2018, arXiv:1810.00069. [Google Scholar] [CrossRef]
- Hitaj, B.; Ateniese, G.; Perez-Cruz, F. Deep models under the GAN: Information leakage from collaborative deep learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 603–618. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; Mcdaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Papernot, N.; Mcdaniel, P.; Goodfellow, I. Transferability in Machine Learning: From Phenomena to Black-Box Attacks using Adversarial Samples. arXiv 2016, arXiv:1605.07277. [Google Scholar]
- Pang, R.; Zhang, X.; Ji, S.; Luo, X.; Wang, T. AdvMind: Inferring Adversary Intent of Black-Box Attacks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 1899–1907. [Google Scholar]
- Vivek, B.; Mopuri, K.R.; Babu, R.V. Gray-box adversarial training. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 203–218. [Google Scholar]
- Fenrich, K. Securing your control system. Power Eng. 2008, 112, 1–11. [Google Scholar]
- Ilmoi. Poisoning attacks on Machine Learning: A 15-year old security problem that’s making a comeback. Secur. Mach. Learn. 2019. Available online: https://towardsdatascience.com/poisoning-attacks-on-machine-learning-1ff247c254db (accessed on 8 March 2023).
- Rubinstein, B.I.; Bartlett, P.L.; Huang, L.; Taft, N. Learning in a large function space: Privacy-preserving mechanisms for SVM learning. J. Priv. Confidentiality 2012, 4, 65–100. [Google Scholar] [CrossRef]
- Steinhardt, J.; Koh, P.W.; Liang, P. Certified defenses for data poisoning attacks. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3520–3532. [Google Scholar]
- Mei, S.; Zhu, X. Using machine teaching to identify optimal training-set attacks on machine learners. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2871–2877. [Google Scholar]
- Kloft, M.; Laskov, P. Online anomaly detection under adversarial impact. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 405–412. [Google Scholar]
- Koh, P.W.; Steinhardt, J.; Liang, P. Stronger data poisoning attacks break data sanitization defenses. Mach. Learn. 2022, 111, 1–47. [Google Scholar] [CrossRef]
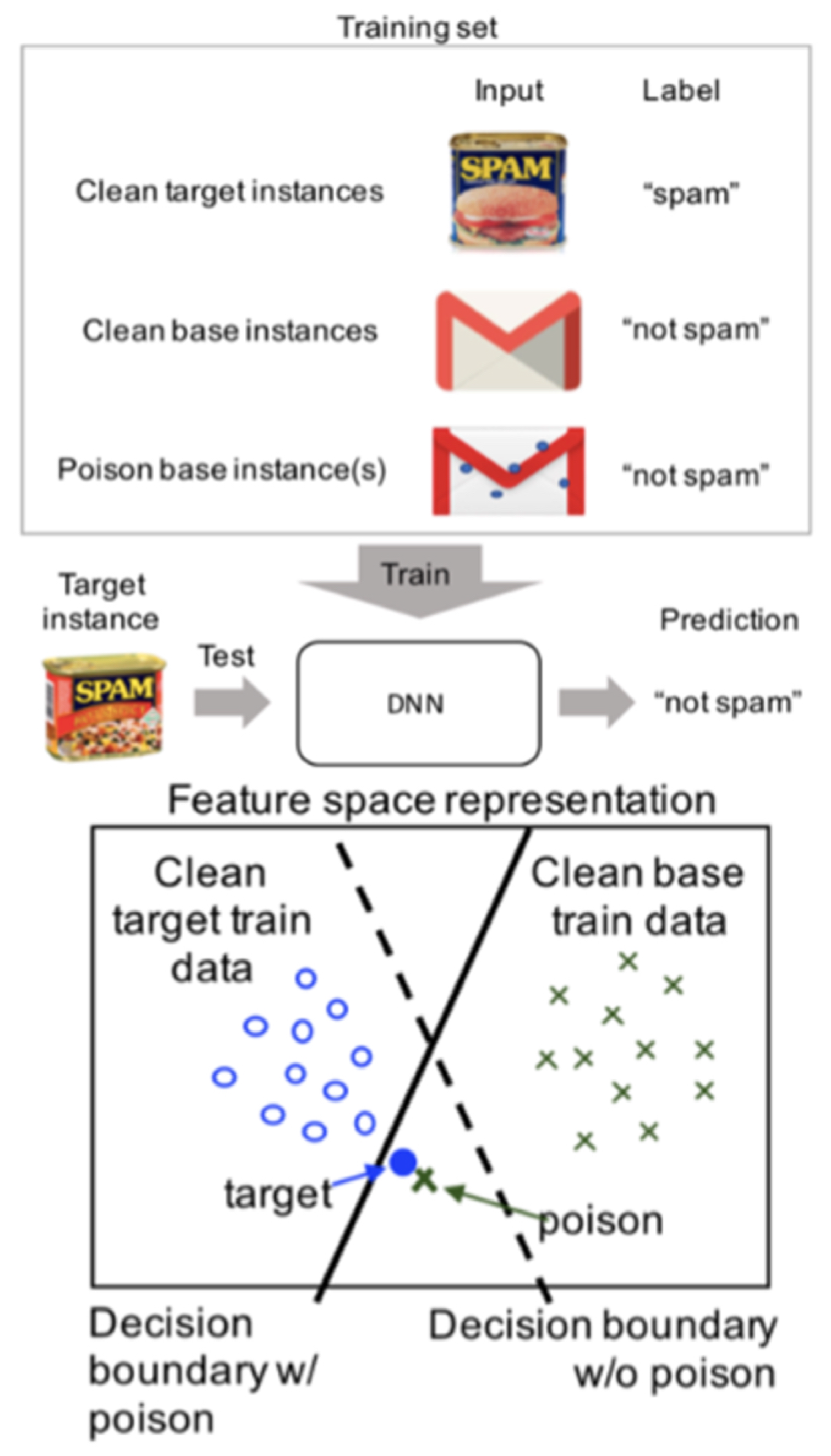
- Shafahi, A.; Huang, W.R.; Najibi, M.; Suciu, O.; Studer, C.; Dumitras, T.; Goldstein, T. Poison frogs! targeted clean-label poisoning attacks on Neural Networks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 6106–6116. [Google Scholar]
- Suciu, O.; Marginean, R.; Kaya, Y.; Daume, H.; Iii; Dumitras, T. When does machine learning {FAIL}? generalized transferability for evasion and poisoning attacks. In Proceedings of the 27th Security Symposium, USENIX, Baltimore, MD, USA, 15–17 August 2018; pp. 1299–1316. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Lyu, C.; Huang, K.; Liang, H.N. A unified gradient regularization family for adversarial examples. In Proceedings of the 2015 IEEE International Conference on Data Mining, Atlantic City, NJ, USA, 14–17 November 2015; pp. 301–309. [Google Scholar]
- Papernot, N.; Mcdaniel, P. Extending defensive distillation. arXiv 2017, arXiv:1705.05264. [Google Scholar]
- Papernot, N.; Mcdaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Hosseini, H.; Chen, Y.; Kannan, S.; Zhang, B.; Poovendran, R. Blocking transferability of adversarial examples in black-box learning systems. arXiv 2017, arXiv:1703.04318. [Google Scholar]
- Meng, D.; Chen, H. Magnet: A two-pronged defense against adversarial examples. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 135–147. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Samangouei, P.; Kabkab, M.; Chellappa, R. Defense-gan: Protecting classifiers against adversarial attacks using generative models. arXiv 2018, arXiv:1805.06605. [Google Scholar]
- Weerasinghe, S.; Alpcan, T.; Erfani, S.M.; Leckie, C. Defending Distributed Classifiers Against Data Poisoning Attacks. arXiv 2020, arXiv:2008.09284. [Google Scholar]
- Efron, B. The jackknife, the bootstrap and other resampling plans. In CBMS-NSF Regional Conference Series in Applied Mathematics; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1982. [Google Scholar]
- Paudice, A.; Muñoz-González, L.; Lupu, E.C. Label sanitization against label flipping poisoning attacks. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2018; pp. 5–15. [Google Scholar]
- Paudice, A.; Muñoz-González, L.; Gyorgy, A.; Lupu, E.C. Detection of adversarial training examples in poisoning attacks through anomaly detection. arXiv 2018, arXiv:1802.03041. [Google Scholar]
- Rubinstein, B.I.; Nelson, B.; Huang, L.; Joseph, A.D.; Lau, S.; Rao, S.; Taft, N.; Tygar, J.D. Antidote: Understanding and defending against poisoning of anomaly detectors. In Proceedings of the 9th ACM SIGCOMM Conference on Internet Measurement, Chicago, IL, USA, 4–6 November 2009; pp. 1–14. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Koh, P.W.; Liang, P. Understanding black-box predictions via influence functions. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 1885–1894. [Google Scholar]
- Liubchenko, N.; Podorozhniak, A.; Oliinyk, V. Research Application of the Spam Filtering and Spammer Detection Algorithms on Social Media. CEUR Workshop Proc. 2022, 3171, 116–126. [Google Scholar]
- Wang, Q.; Gao, Y.; Ren, J.; Zhang , B. An automatic classification algorithm for software vulnerability based on weighted word vector and fusion neural network. Comput. Secur. 2023, 126, 103070. [Google Scholar] [CrossRef]
- Peri, N.; Gupta, N.; Huang, W.R.; Fowl, L.; Zhu, C.; Feizi, S.; Goldstein, T.; Dickerson, J.P. Deep k-NN defense against clean-label data poisoning attacks. In Proceedings of the European Conference on Computer, Glasgow, UK, 23–28 August 2020; pp. 55–70. [Google Scholar]
- Natarajan, J. AI and Big Data’s Potential for Disruptive Innovation. Cyber secure man-in-the-middle attack intrusion detection using machine learning algorithms. In AI and Big Data’s Potential for Disruptive Innovation; IGI Global: Hershey, PA, USA, 2020; pp. 291–316. [Google Scholar]
- Tran, B.; Li, J.; Madry, A. Spectral Signatures in Backdoor Attacks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 8011–8021. [Google Scholar]
- Nguyen, G.; Dlugolinsky, S.; Bobak, M.; Tran, V.; Garcia, A.; Heredia, I.; Malik, P.; Hluchy, L. Machine Learning and Deep Learning frameworks and libraries for large-scale. Artif. Intell. Rev. 2019, 52, 77–124. [Google Scholar] [CrossRef]
- Wu, B.; Wang, S.; Yuan, X.; Wang, C.; Rudolph, C.; Yang, X. Defending Against Misclassification Attacks in Transfer Learning. arXiv 2019, arXiv:1908.11230. [Google Scholar]
- Polyak, A.; Wolf, L. Channel-level acceleration of deep face representations. IEEE Access 2015, 3, 2163–2175. [Google Scholar] [CrossRef]
- Blanchard, P.; Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. 31st Conf. Neural Inf. Process. Syst. 2017, 30, 118–128. [Google Scholar]
- Chen, Y.; Su, L.; Xu, J. Distributed statistical machine learning in adversarial settings: Byzantine gradient descent. Proc. Acm Meas. Anal. Comput. Syst. 2017, 1, 1–25. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Guerraoui, R.; Rouault, S. The hidden vulnerability of distributed learning in byzantium. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 3521–3530. [Google Scholar]
- Pillutla, K.; Kakade, S.M.; Harchaoui, Z. Robust aggregation for federated learning. IEEE Trans. Signal Process. 2022, 70, 1142–1154. [Google Scholar] [CrossRef]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5650–5659. [Google Scholar]
- Bernstein, J.; Wang, Y.X.; Azizzadenesheli, K.; Anandkumar, A. signSGD: Compressed optimisation for non-convex problems. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 560–569. [Google Scholar]
- Fung, C.; Yoon, C.J.; Beschastnikh, I. Mitigating sybils in federated learning poisoning. arXiv 2018, arXiv:1808.04866. [Google Scholar]
- Liu, Y.; Yi, Z.; Chen, T. Backdoor attacks and defenses in feature-partitioned collaborative learning. arXiv 2020, arXiv:2007.03608. [Google Scholar]
- Ozdayi, M.S.; Kantarcioglu, M.; Gel, Y.R. Defending against Backdoors in Federated Learning with Robust Learning Rate. 2020. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/17118/16925 (accessed on 8 March 2023).
- Yang, Z.; Zhang, J.; Chang, E.C.; Liang, Z. Neural network inversion in adversarial setting via background knowledge alignment. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 225–240. [Google Scholar]
- Fredrikson, M.; Lantz, E.; Jha, S.; Lin, S.; Page, D.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Hidano, S.; Murakai, T.; Katsumata, S.; Kiyomoto, S.; Hanaoka, G. Model inversion attacks for prediction systems: Without knowledge of non-sensitive attributes. In Proceedings of the 2017 15th Annual Conference on Privacy, Security and Trust (PST), Calgary, AB, Canada, 28–30 August 2017; pp. 115–11509. [Google Scholar]
- Wu, X.; Fredrikson, M.; Jha, S.; Naughton, J.F. A methodology for formalizing model-inversion attacks. In Proceedings of the 2016 IEEE 29th Computer Security Foundations Symposium (CSF), Lisbon, Portugal, 27 June–1 July 2016; pp. 355–370. [Google Scholar]
- Zhang, Y.; Jia, R.; Pei, H.; Wang, W.; Li, B.; Song, D. The secret revealer: Generative model-inversion attacks against deep neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 250–258. [Google Scholar]
- Ateniese, G.; Mancini, L.V.; Spognardi, A.; Villani, A.; Vitali, D.; Felici, G. Hacking smart machines with smarter ones: How to extract meaningful data from machine learning classifiers. Int. J. Secur. Networks 2015, 10, 137–150. [Google Scholar] [CrossRef]
- Juuti, M.; Szyller, S.; Marchal, S.; Asokan, N. PRADA: Protecting against DNN model stealing attacks. In Proceedings of the 2019 IEEE European Symposium on Security and Privacy (EuroS&P), Stockholm, Sweden, 17–19 June 2019; pp. 512–527. [Google Scholar]
- Wang, B.; Gong, N.Z. Stealing hyperparameters in machine learning. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–23 May 2018; pp. 36–52. [Google Scholar]
- Takemura, T.; Yanai, N.; Fujiwara, T. Model Extraction Attacks on Recurrent Neural Networks. J. Inf. Process. 2020, 28, 1010–1024. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Hsu, Y.C.; Hua, T.; Chang, S.; Lou, Q.; Shen, Y.; Jin, H. Language model compression with weighted low-rank factorization. arXiv 2022, arXiv:2207.00112. [Google Scholar] [CrossRef]
- Chandrasekaran, V.; Chaudhuri, K.; Giacomelli, I.; Jha, S.; Yan, S. Exploring connections between active learning and model extraction. In Proceedings of the 29th Security Symposium (USENIX), Boston, MA, USA, 12–14 August 2020; pp. 1309–1326. [Google Scholar]
- Lee, T.; Edwards, B.; Molloy, I.; Su, D. Defending against neural network model stealing attacks using deceptive perturbations. In Proceedings of the 2019 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 20–22 May 2019; pp. 43–49. [Google Scholar]
- Kesarwani, M.; Mukhoty, B.; Arya, V.; Mehta, S. Model extraction warning in MLaaS paradigm. In Proceedings of the 34th Annual Computer Security Applications Conference, San Juan, PR, USA, 3–7 December 2018; pp. 371–380. [Google Scholar]
- Fredrikson, M.; Lantz, E.; Jha, S.; Lin, S.; Page, D.; Ristenpart, T. Privacy in Pharmacogenetics: An End-to-End Case Study of Personalized Warfarin Dosing. Proc. Usenix Secur. Symp. 2014, 1, 17–32. [Google Scholar]
- Chaabane, A.; Acs, G.; Kaafar, M.A. You are what you like! information leakage through users’ interests. In Proceedings of the 19th Annual Network & Distributed System Security Symposium (NDSS), San Diego, CA, USA, 5–8 February 2012. [Google Scholar]
- Kosinski, M.; Stillwell, D.; Graepel, T. Private traits and attributes are predictable from digital records of human behavior. Proc. Natl. Acad. Sci. USA 2013, 110, 5802–5805. [Google Scholar] [CrossRef] [PubMed]
- Gong, N.Z.; Talwalkar, A.; Mackey, L.; Huang, L.; Shin, E.C.R.; Stefanov, E.; Shi, E.; Song, D. Joint link prediction and attribute inference using a social-attribute network. Acm Trans. Intell. Syst. Technol. 2014, 5, 1–20. [Google Scholar] [CrossRef]
- Reynolds, N.A. An Empirical Investigation of Privacy via Obfuscation in Social Networks, 2020. Available online: https://figshare.mq.edu.au/articles/thesis/An_empirical_investigation_of_privacy_via_obfuscation_in_social_networks/19434461/1 (accessed on 8 March 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attacks | AI System Development | Vulnerabilities | Defense Mechanisms |
|---|---|---|---|
| Poisoning attacks [1,37] | During training of the model | Weakness in the federated learning algorithms, resulting in stealing of the data and algorithm from individual user devices. | See list of defense mechanisms for both the data and model poisoning attacks. |
| Data poisoning attacks [38,39,40] | During the training stage | Tampering of the features and class information in the training dataset | Adversarial training, Feature squeezing, Transferability blocking, MagNet, Defense-GAN, Local intrinsic dimensionality, Reject On Negative Impact (RONI), L-2 Defense, Slab Defense, Loss Defense and K-NN Defense. |
| Model poisoning attacks [41,42,43,44] | During the training stage | Trust ability of the trainer, based on a privately held validation dataset. Use of pre-trained models that are corrupted. | Securely hosting and disseminating pre-trained models in virtual repositories that guarantee integrity to preclude benevolent models from being manipulated. Identifying backdoors in malevolently trained models acquired from untrustworthy trainers by fine-tuning untrusted models. |
| Transfer learning attacks [42,44,45,46] | During the training stage | Similarity of the model structures. | Obtain pre-trained models from trusted source. Employ activation-based pruning with different training examples. |
| Model poisoning in federated learning [41,45,47,48] | During the training stage | Obstruct the convergence of the execution of the distributed Stochastic Gradient Descent (SGD) algorithm, | Robust aggregation methods, robust learning rate. |
| Model inversion attack [49,50,51,52] | During Inference and/or testing stage | Models are typically trained on rather small, or imbalanced, training sets. | L2 Regularizer [49], Dropout and Model Staking [50], MemGuard [51] and Differential privacy [52]. |
| Model extraction attack [53,54] | During Inference and/or training stage | Models having similar characteristics (parameters, shape and size, similar features etc.) | Hiding or adding noises to the output probabilities while keeping the class label of the instances intact. Suppressing suspicious queries or input data. |
| Inference attack [55] | During Inferencing, Training, and Testing | Model Leaking information leading to inferences being made on private data. | Methods proposed in [55] have leveraged heuristic correlations between the records of the public data and attribute values to defending against inference attacks. Modifying the identified k entries that have large correlations with the attribute values to any given target users. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sangwan, R.S.; Badr, Y.; Srinivasan, S.M. Cybersecurity for AI Systems: A Survey. J. Cybersecur. Priv. 2023, 3, 166-190. https://doi.org/10.3390/jcp3020010
Sangwan RS, Badr Y, Srinivasan SM. Cybersecurity for AI Systems: A Survey. Journal of Cybersecurity and Privacy. 2023; 3(2):166-190. https://doi.org/10.3390/jcp3020010
Chicago/Turabian StyleSangwan, Raghvinder S., Youakim Badr, and Satish M. Srinivasan. 2023. "Cybersecurity for AI Systems: A Survey" Journal of Cybersecurity and Privacy 3, no. 2: 166-190. https://doi.org/10.3390/jcp3020010
APA StyleSangwan, R. S., Badr, Y., & Srinivasan, S. M. (2023). Cybersecurity for AI Systems: A Survey. Journal of Cybersecurity and Privacy, 3(2), 166-190. https://doi.org/10.3390/jcp3020010