



Analysis and Multiobjective Optimization of a Machine Learning Algorithm for Wireless Telecommunication



Abstract
:1. Introduction
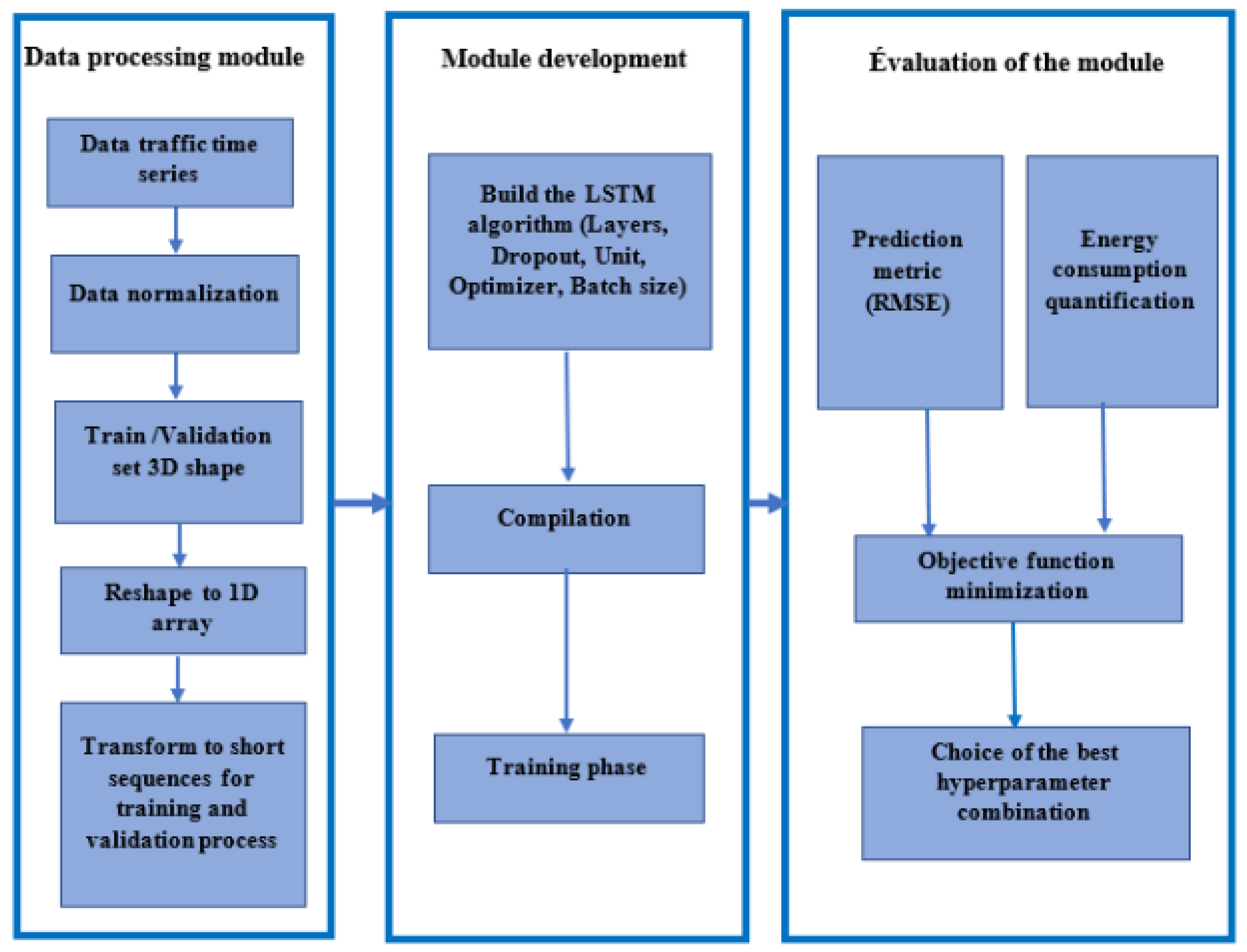
2. Materials and Methods
2.1. Data Processing Module
2.1.1. Dataset
- Cell ID (57 cells).
- Date and time: timestamp of the traffic measurement.
- Traffic: cell-specific traffic at each timestamp.
2.1.2. Data Normalization and Transformation
2.2. Module Development
2.2.1. Grid Search
2.2.2. Long Short-Term Memory (LSTM)
2.2.3. The Learning Algorithm
Optimizers
Dropout
Batch Size
Hidden Layers
Number of Units Per Layer
| Alglgorithm 1: Algorithm of the Proposed Method | ||||||
| 1 | Input: Traffic data | |||||
| 2 | Output: The minimized objective function | |||||
| 3 | Data preparation | |||||
| 4 | Split Data (training set/validation set) | |||||
| 5 | Defining min-max scaler | |||||
| 6 | Fitting with min-max scaler | |||||
| 7 | Reshaping data | |||||
| 8 | EPOCH: 120 | |||||
| 9 | Create the LSTM network | |||||
| 10 | For number layers from 1 to 4 do | |||||
| 11 | For Optimizer = [Adam, RMSProp, Nadam] do | |||||
| 12 | For the Batch size in the range [32, 512, 32] do | |||||
| 13 | For Unite in the range [8, 256, 8] do | |||||
| 14 | For dropout in the range [0.1, 0.3, 0.1] do | |||||
| 15 | Fit the LSTM network | |||||
| 16 | Make predictions with train and Validation datasets | |||||
| 17 | Calculate the root mean square error and quantify the energy consumed | |||||
| 18 | Calculate the objective function | |||||
| 19 | End | |||||
| 20 | End | |||||
| 21 | End | |||||
| 22 | End | |||||
| 23 | End | |||||
| 24 | Choice of hypermeters for which the objective function is minimal | |||||
2.3. Evaluation Module
2.3.1. Evaluation Metrics with RMSE
2.3.2. Measurement of Energy Consumption
2.3.3. Objective Function Minimization
3. Results and Discussion
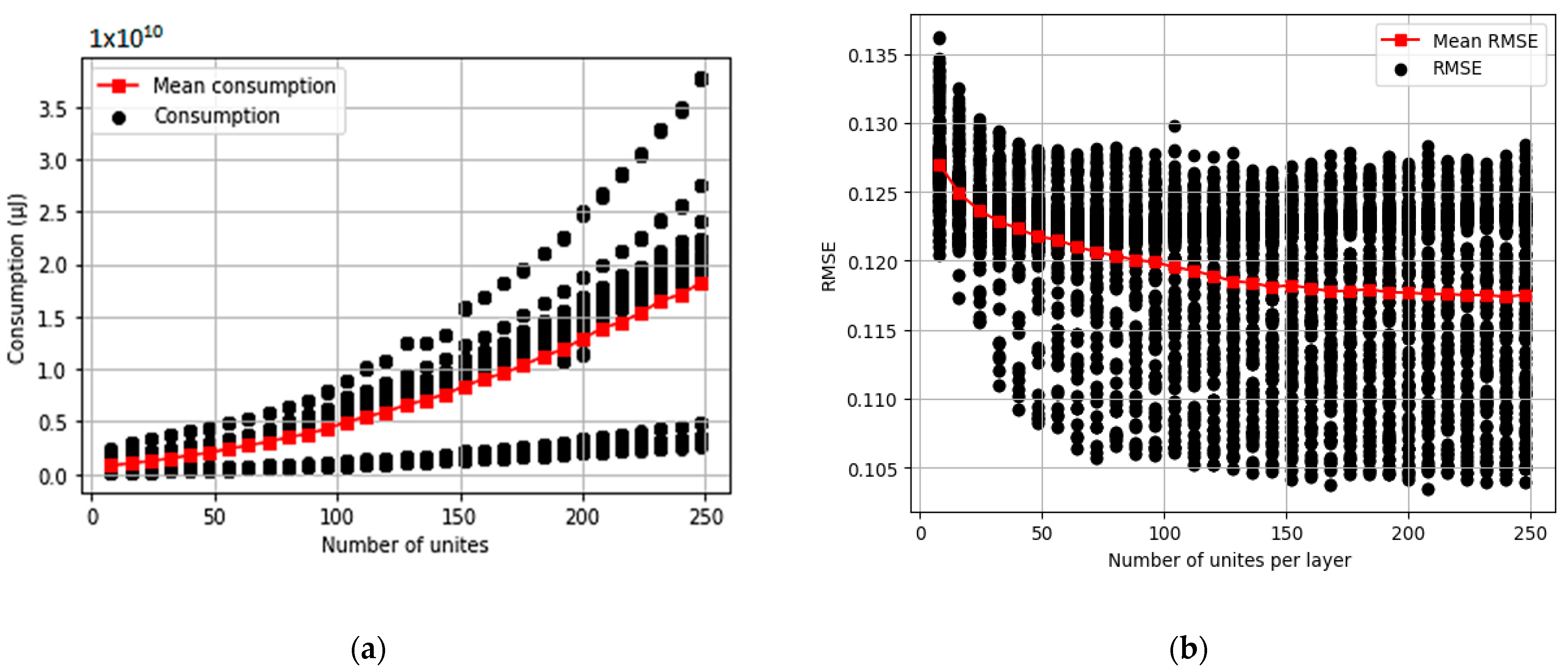
3.1. Exploiting the Influence of the Number of Units per Layer on the Energy Consumption and Performance of the Model
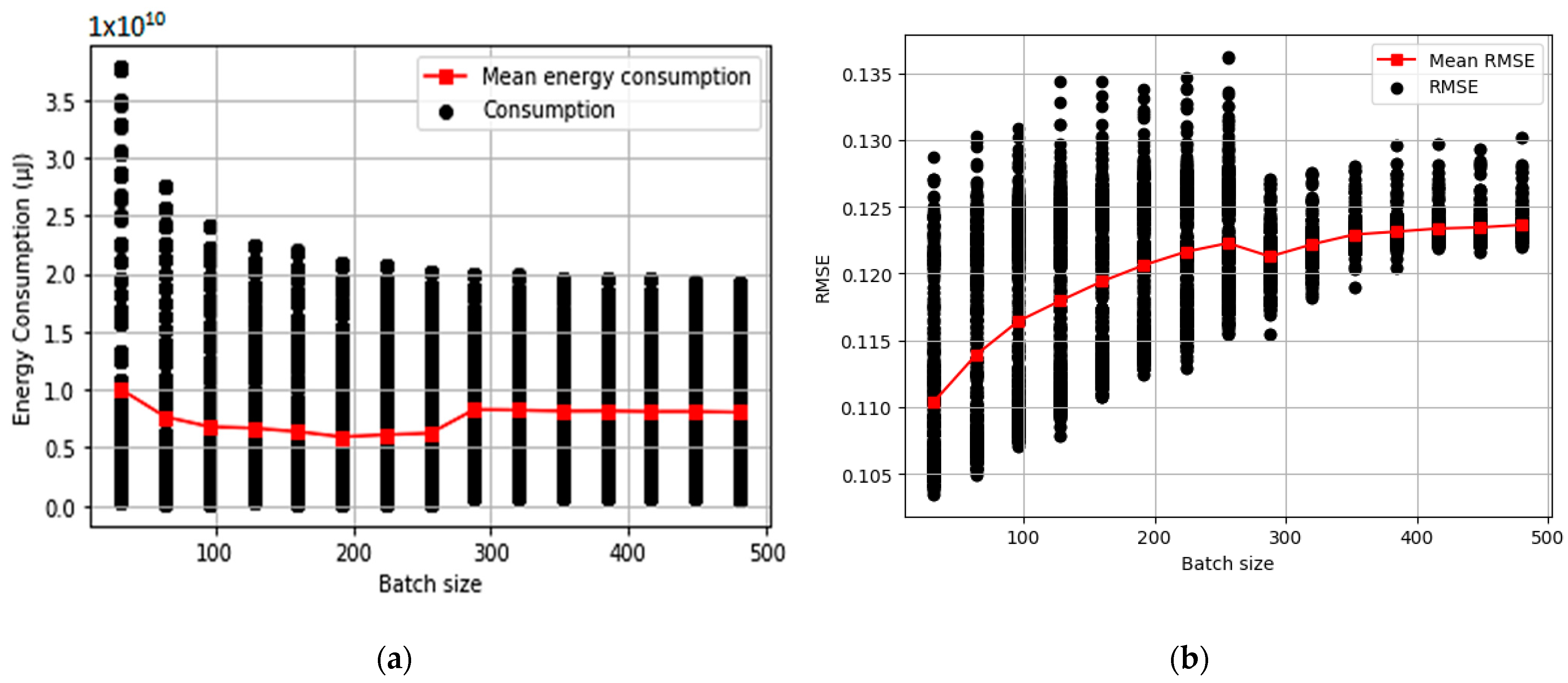
3.2. Exploitation of the Influence of the Batch Size on Energy Consumption and Model Performance
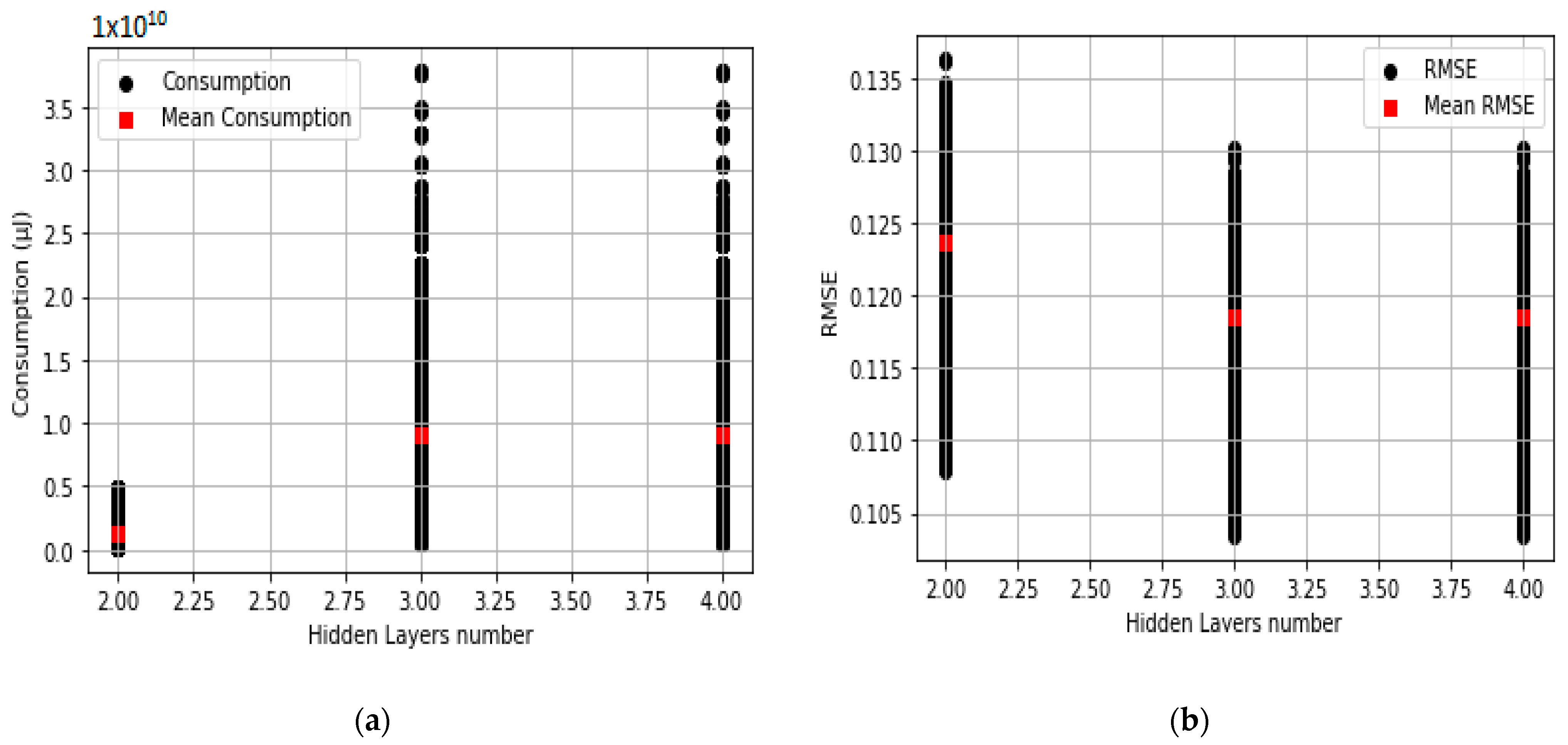
3.3. Impact of the Number of Layers on the Energy Consumption and Performance
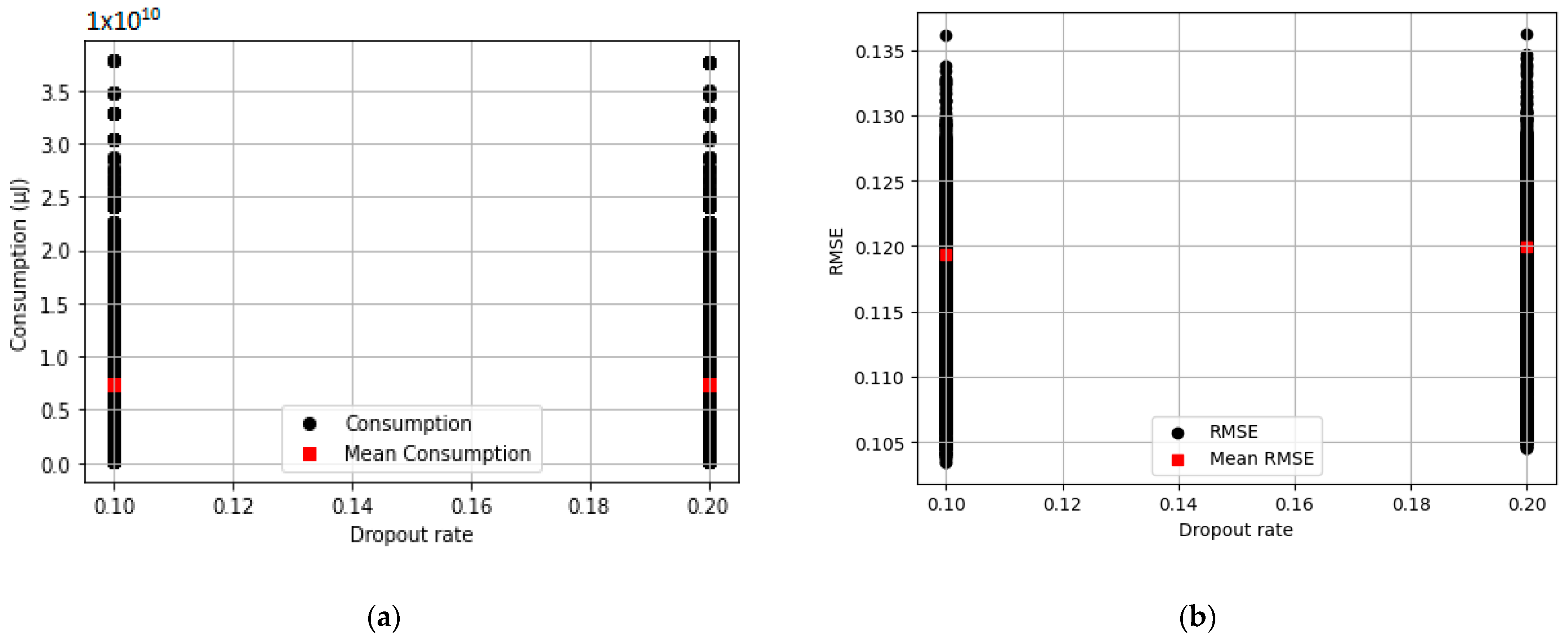
3.4. Exploiting the Impact of Dropout Rate on Energy Consumption and Model Performance
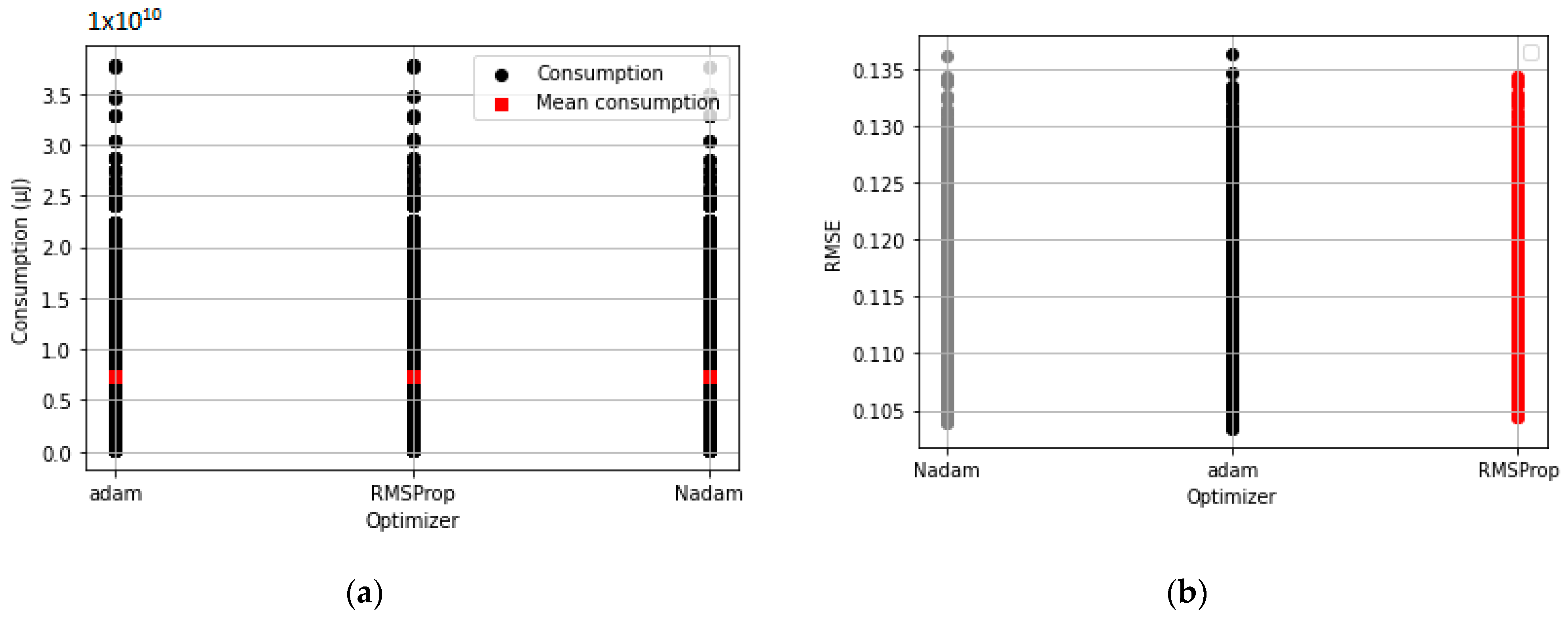
3.5. Examining the Influence of Optimizer Type on Energy Consumption and Model Performance
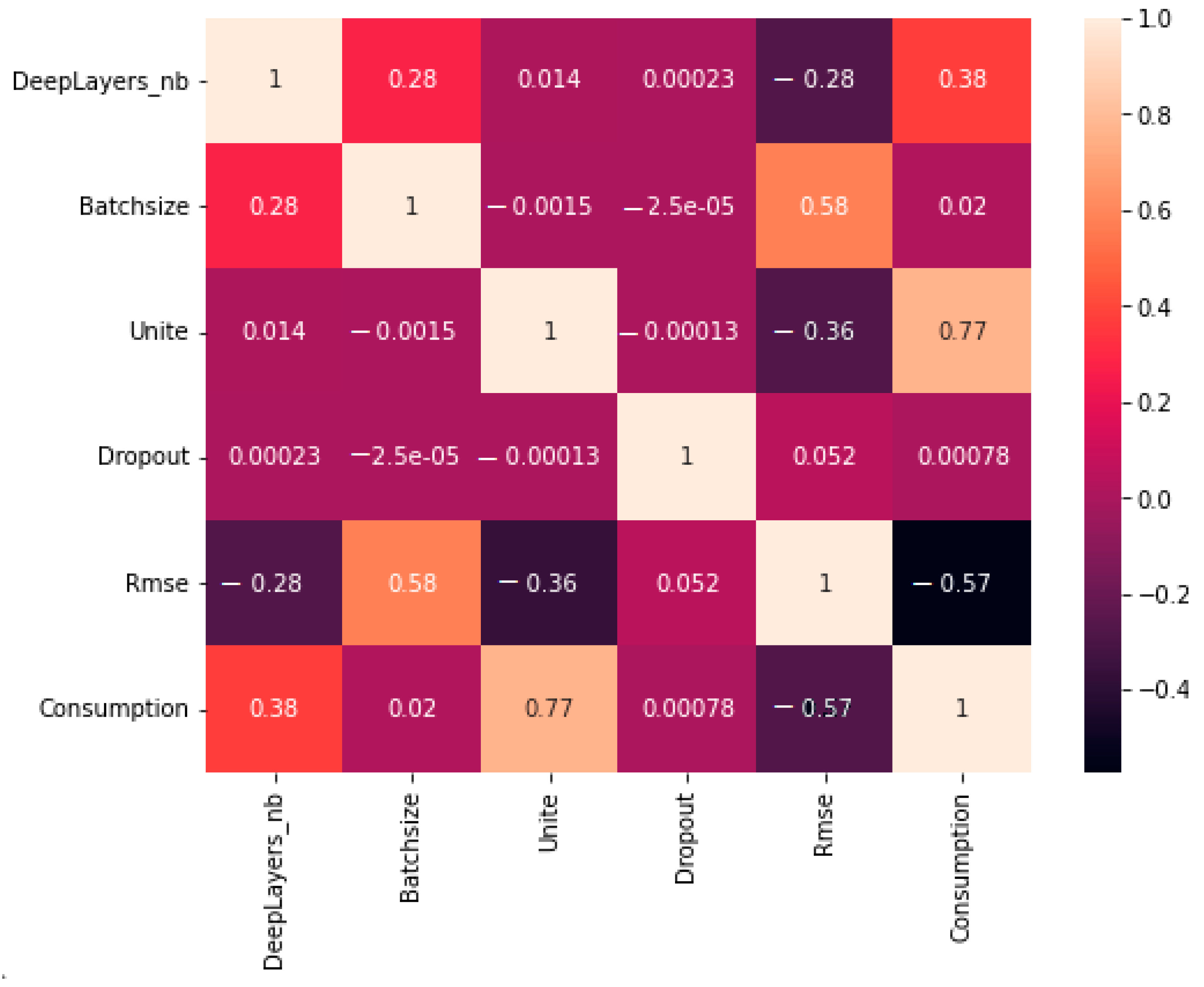
3.6. Correlation Matrix
3.7. The Best Hyperparameters
4. Related Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hill, K. Connected Devices will be 3x the Global Population by 2023, Cisco Says. RCR Wireless News, 18 February 2020. Available online: https://www.rcrwireless.com/20200218/internet-of-things/connected-devices-will-be-3x-the-global-population-by-2023-cisco-says(accessed on 26 October 2022).
- 5G and Its Impact on the Internet of Things—Stardust Testing. Available online: https://www2.stardust-testing.com/en/5g-and-impact-on-iots (accessed on 26 October 2022).
- You, X.; Zhang, C.; Tan, X.; Jin, S.; Wu, H. AI for 5G: Research directions and paradigms. Sci. China Inf. 2019, 62, 21301. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, Y.; Zukerman, M.; Yung, E.K. Energy-efficient base-stations sleep-mode techniques in green cellular networks: A survey. IEEE Commun. Surv. Tutor. 2015, 17, 803–826. [Google Scholar] [CrossRef]
- Richter, F.; Fettweis, G.; Gruber, M.; Blume, O. Micro base stations in load constrained cellular mobile radio networks. In Proceedings of the IEEE 21st International Symposium on Personal, Indoor and Mobile Radio Communications Workshops, Istanbul, Turkey, 17 December 2010; pp. 357–362. [Google Scholar]
- Shu, Y.; Yu, M.; Liu, J.; Yang, O.W.W. Wireless traffic modeling and prediction using seasonal ARIMA models. IEICE Trans. Commun. 2005, 88, 3992–3999. [Google Scholar] [CrossRef]
- Zhang, D.; Liu, L.; Xie, C.; Yang, B.; Liu, Q. Citywide cellular traffic prediction based on a hybrid spatiotemporal network. Algorithms 2020, 13, 20. [Google Scholar] [CrossRef]
- Liang, D.; Zhang, J.; Jiang, S.; Zhang, X.; Wu, J.; Sun, Q. Mobile traffic prediction based on densely connected CNN for cellular networks in highway scenarios. In Proceedings of the IEEE 11th International Conference on Wireless Communications and Signal Processing, Xi’an, China, 23–25 October 2019; pp. 1–5. [Google Scholar]
- Zhang, C.; Zhang, H.; Yuan, D.; Zhang, M. Citywide cellular traffic prediction based on densely connected convolutional neural networks. IEEE Commun. Lett. 2018, 22, 1656–1659. [Google Scholar] [CrossRef]
- Chen, R.; Liang, C.; Hong, W.; Gu, D. Forecasting holiday daily tourist flow based on seasonal support vector regression with adaptive genetic algorithm. Appl. Soft Comput. 2015, 26, 435–443. [Google Scholar] [CrossRef]
- Jnr, M.D.; Gadze, J.D.; Anipa, D. Short-term traffic volume prediction in UMTS networks using the Kalman filter algorithm. Int. J. Mob. Netw. Commun. Telemat. 2013, 3, 31–40. [Google Scholar]
- Nie, L.; Jiang, D.; Yu, S.; Song, H. Network traffic prediction based on deep belief network in wireless mesh backbone networks. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017; pp. 1–5. [Google Scholar]
- Qiu, C.; Zhang, Y.; Feng, Z.; Zhang, P.; Cui, S. Spatio-temporal wireless traffic prediction with recurrent neural network. IEEE Wirel. Commun. Lett. 2018, 7, 554–557. [Google Scholar] [CrossRef]
- Global Emissions. Center for Climate and Energy Solutions. 24 March 2022. Available online: https://www.c2es.org/content/international-emissions/ (accessed on 26 October 2022).
- IEA. Digitalization and Energy-Analysis, IEA. Available online: https://www.iea.org/reports/digitalisation-and-energy (accessed on 26 October 2022).
- García-Martín, E.; Rodrigues, C.F.; Riley, G.; Grahn, H. Estimation of energy consumption in machine learning. J. Parallel Distrib. Comput. 2019, 134, 75–88. [Google Scholar] [CrossRef]
- Lacoste, A.; Luccioni, A.; Schmidt, V.; Dandres, T. Quantifying the carbon emissions of machine learning. arXiv 2019, arXiv:1910.09700. [Google Scholar]
- Strubell, E.; Ganesh, A.; Mccallum, A. Energy and policy considerations for deep learning in NLP. arXiv 2019, arXiv:1906.02243. [Google Scholar]
- Anthony, L.F.; Wolff, K.B.; Selvan, R. Carbontracker: Tracking and predicting the carbon footprint of training deep learning models. arXiv 2020, arXiv:2007.03051. [Google Scholar]
- Stamoulis, D.; Cai, E.; Juan, D.; Juan, D.; Marculescu, D. Hyperpower: Power-and memory-constrained hyper-parameter optimization for neural networks. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 19–24. [Google Scholar]
- Canziani, A.; Paszke, A.; Culurciello, E. An analysis of deep neural network models for practical applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]
- Rodrigues, C.F.; Riley, G.; Luján, M. SyNERGY: An energy measurement and prediction framework for Convolutional Neural Networks on Jetson TX1. In Proceedings of the International Conference on Parallel and Distributed Processing Techniques and Applications (PDPTA), Las Vegas, NV, USA, 13–16 July 1998; The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp): Las Vegas, NV, USA, 2018; pp. 375–382. [Google Scholar]
- Yang, T.-J.; Chen, Y.; Sze, V. Designing energy-efficient convolutional neural networks using energy-aware pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5687–5695. [Google Scholar]
- Brownlee, A.E.; Adair, J.; Haraldsson, S. Exploring the accuracy—Energy trade-off in machine learning. In Proceedings of the 2021 IEEE/ACM International Workshop on Genetic Improvement (GI), Madrid, Spain, 30 May 2021; pp. 11–18. [Google Scholar]
- Dai, X.; Zhang, P.; Wu, B.; Yin, H.; Sun, F.; Wang, Y. Chamnet: Towards efficient network design through platform-aware model adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11398–11407. [Google Scholar]
- Brownlee, A.E.I.; Burles, N.; Swan, J. Search-based energy optimization of some ubiquitous algorithms. IEEE Trans. Emerg. Top. Comput. Intell. 2017, 1, 188–201. [Google Scholar] [CrossRef]
- Alsaade, F.W.; Hmoud Al-Adhaileh, M. Cellular traffic prediction based on an intelligent model. Mob. Inf. Syst. 2021, 2021, 6050627. [Google Scholar] [CrossRef]
- Borkin, D.; Némethová, A.; Michaľčonok, G. Impact of data normalization on classification model accuracy. Res. Pap. Fac. Mater. Sci. Technol. Slovak Univ. Technol. 2019, 27, 79–84. [Google Scholar] [CrossRef]
- Khadem, S.A.; Bensebaa, F.; Pelletier, N. Optimized feed-forward neural networks to address CO2-equivalent emissions data gaps—Application to emissions prediction for unit processes of fuel life cycle inventories for Canadian provinces. J. Clean. Prod. 2022, 332, 130053. [Google Scholar] [CrossRef]
- Belete, D.M.; Huchaiah, M.D. Grid search in hyperparameter optimization of machine learning models for prediction of HIV/AIDS test results. Int. J. Comput. Appl. 2022, 44, 875–886. [Google Scholar] [CrossRef]
- Arulampalam, G.; Bouzerdoum, A. A generalized feedforward neural network architecture for classification and regression. Neural Netw. 2003, 16, 561–568. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Brownlee, J. Difference between a Batch and an Epoch in a Neural Network, Machine Learning Mastery. 15 August 2022. Available online: https://machinelearningmastery.com/difference-between-a-batch-and-anepoch (accessed on 26 October 2022).
- Pyrapl, PyPI. Available online: https://pypi.org/project/pyRAPL/ (accessed on 26 October 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Values |
|---|---|
| Optimizer | [Adam, RMSProp, Nadam] |
| Batch size | [32–512 with a step of 32] |
| Layers number | [1, 2, 3, 4] |
| Number of Neurons in each layer | [8–256 with step of 8] |
| Dropout rate | [0.1, 0.2] |
| Epoch | 120 |
| Activation function | ReLu |
| Weights | Layers | Batch Size | Number of Units | Optimizer | Dropout | |
|---|---|---|---|---|---|---|
| W1 = W2 = 0.5 | 3 | 64 | 184 | RMSprop | 0.1 | 0.39397401 |
| W1 = 0.7 W2 = 0.3 | 3 | 64 | 184 | Nadam | 0.1 | 0.24012428 |
| W1 = 0.3 W2 = 0.7 | 3 | 32 | 72 | Nadam | 0.1 | 0.54496929 |
| References | Machine Learning Algorithms | Dataset | Approaches |
|---|---|---|---|
| [24] | Multilayer perceptron | Medical data set (diabetes, glass, ionosphere, iris) | Explored the tradeoff between energy consumption and accuracy for different hyperparameter configurations of a popular machine learning framework |
| [25] | Neural network | ImageNet | This approach leverages existing efficient network building blocks and focuses on exploiting hardware characteristics and adapting computational resources to accommodate target latency and/or power constraints. |
| [20] | Neural Networks | Not stated | HyperPower, a framework that enables efficient Bayesian optimization and random search in the context of power- and memory-constrained |
| [26] | Multilayer perceptron | Not stated | Tool for measuring the energy consumption of JVM programs using a bytecode level model of energy cost. |
| [16] | Convolutional neural network Data stream mining | Poker-Hand Forest Cover type | The goal is to provide useful guidelines to the machine learning community, giving them the fundamental knowledge to use and build specific energy estimation methods for machine learning algorithms. |
| Proposed work | Recurrent neural network (LSTM) | Traffic data set | Exploring and optimizing the hyperparameters of machine learning algorithms employed in cellular traffic prediction. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Temim, S.; Talbi, L.; Bensebaa, F. Analysis and Multiobjective Optimization of a Machine Learning Algorithm for Wireless Telecommunication. Telecom 2023, 4, 219-235. https://doi.org/10.3390/telecom4020013
Temim S, Talbi L, Bensebaa F. Analysis and Multiobjective Optimization of a Machine Learning Algorithm for Wireless Telecommunication. Telecom. 2023; 4(2):219-235. https://doi.org/10.3390/telecom4020013
Chicago/Turabian StyleTemim, Samah, Larbi Talbi, and Farid Bensebaa. 2023. "Analysis and Multiobjective Optimization of a Machine Learning Algorithm for Wireless Telecommunication" Telecom 4, no. 2: 219-235. https://doi.org/10.3390/telecom4020013
APA StyleTemim, S., Talbi, L., & Bensebaa, F. (2023). Analysis and Multiobjective Optimization of a Machine Learning Algorithm for Wireless Telecommunication. Telecom, 4(2), 219-235. https://doi.org/10.3390/telecom4020013