This section’s main objective is to illustrate how a specific OCP can be solved through the intermediary of the quasi-optimal trajectory generated by an MbA. Moreover, we are not aiming to solve a specific OCP and compare our solution with other authors’ approaches, but rather to exemplify the newly proposed method on a benchmark problem.
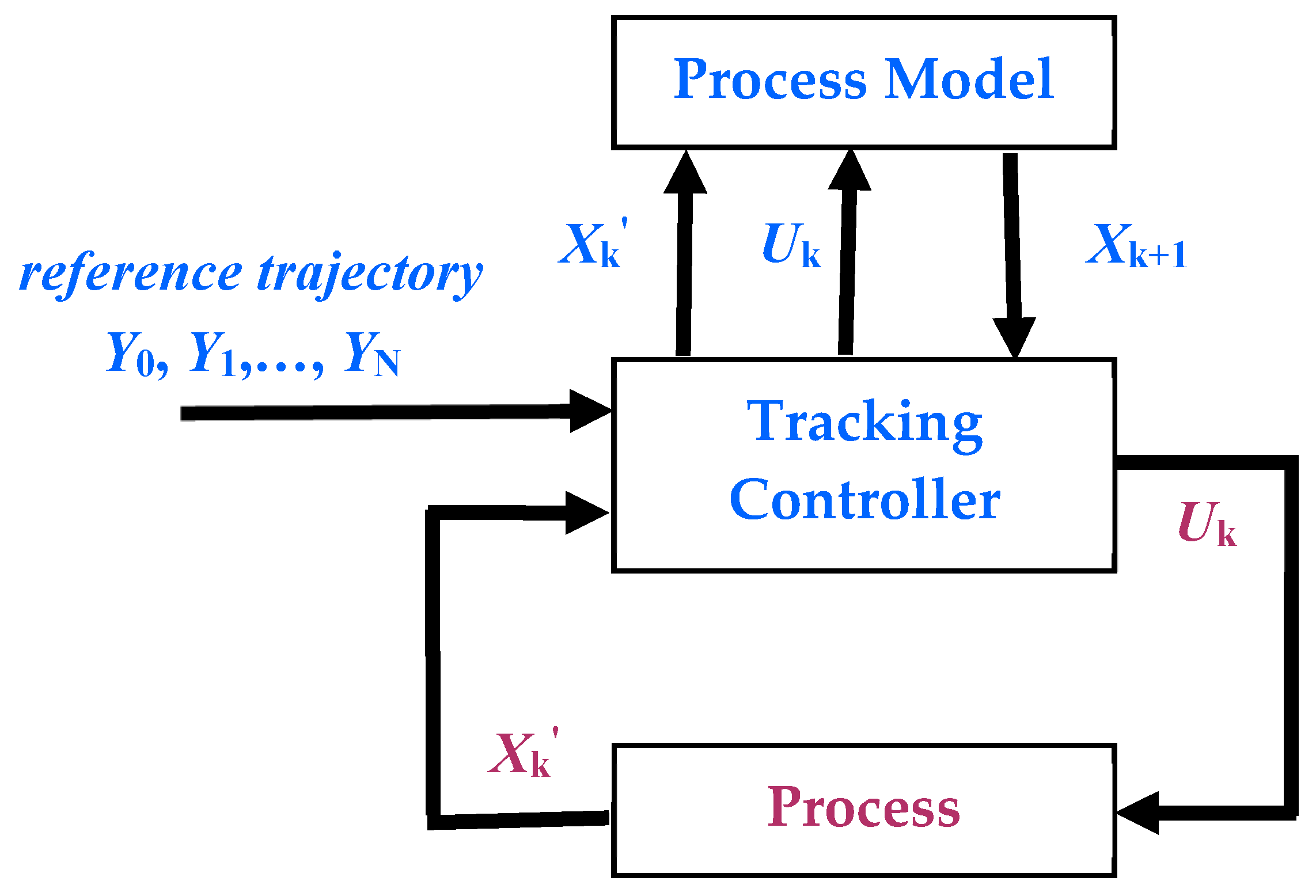
The implementation of the TC and the simulation of the closed-loop were carried out using the MATLAB language and system. To simulate the real process evolution, we have used the special functions devoted to integrating differential equations.
4.1. TC’s Implementation Using Simulated Annealing Algorithm
This section presents the TC’s implementation and the closed-loop simulation using the well-known simulated annealing algorithm (SAA). Let us consider SAA as a function that is symbolically called as bellow:
The searching process refers to that has to minimize the performance index. It is naturally coded as a real vector having the components of the control input. SAA evaluates calling an objective function (scripts: SAh1, eval_SA; see the folder TC_SA) that calculates the performance index (6). This function performs two actions:
- -
the numerical integration of the process over the interval [k, k+1] to calculate the next state using the current ;
- -
the computation of the distance .
Only a candidate solution meeting the constraint (8) is accepted before applying the Metropolis Rule, which will set the iterative process’ current solution:
SAA has two ways to stop the solution’s improvement. The first one is the convergence of the searching process, which can be declared when two conditions are met:
- -
the objective function had no improvement since a certain iterations number, and
- -
the annealing temperature is less than a minimum value.
The second corresponds to the situation when the convergence cannot be ascertained after a pre-established large number of iterations.
The first simulation series’ objective was to evaluate the TC’s behavior when the initial state is different from that considered in the OCP statement (see “influenceX01.m” inside the folder TC_SA). In our example, the initial state is
(see (A3)).
is obtained from
to which a normally distributed noise is added:
The noise is generated by a function normrnd (the same name as the MATLAB function) that generates a vector of random numbers chosen from a normal distribution with mean “Mean” and standard deviation “StDev”. For the real process, we have considered an RPM identical to PM.
Table 1 presents the simulation’s results for six noises having different mean values. These values are quite big compared to the variables’ values
and
, for example, on the interval
.
It is important to see what the tracking’s precision is. The absolute error at the moment
can be calculated using the following formula:
where
is the Euclidean norm. The relative error at the moment
can be expressed as follows:
The columns of
Table 1 give the following values, respectively: the minimum, average, and maximum relative tracking error, the relative error in the final state (Rerr(
N)), the reference and current performance index. In lines #1 and #2, the performance index determined by TC with SA has superior values to
J*. The explanation is related to the reference trajectory’s quasi-optimal character, namely the value
J* is not the optimum.
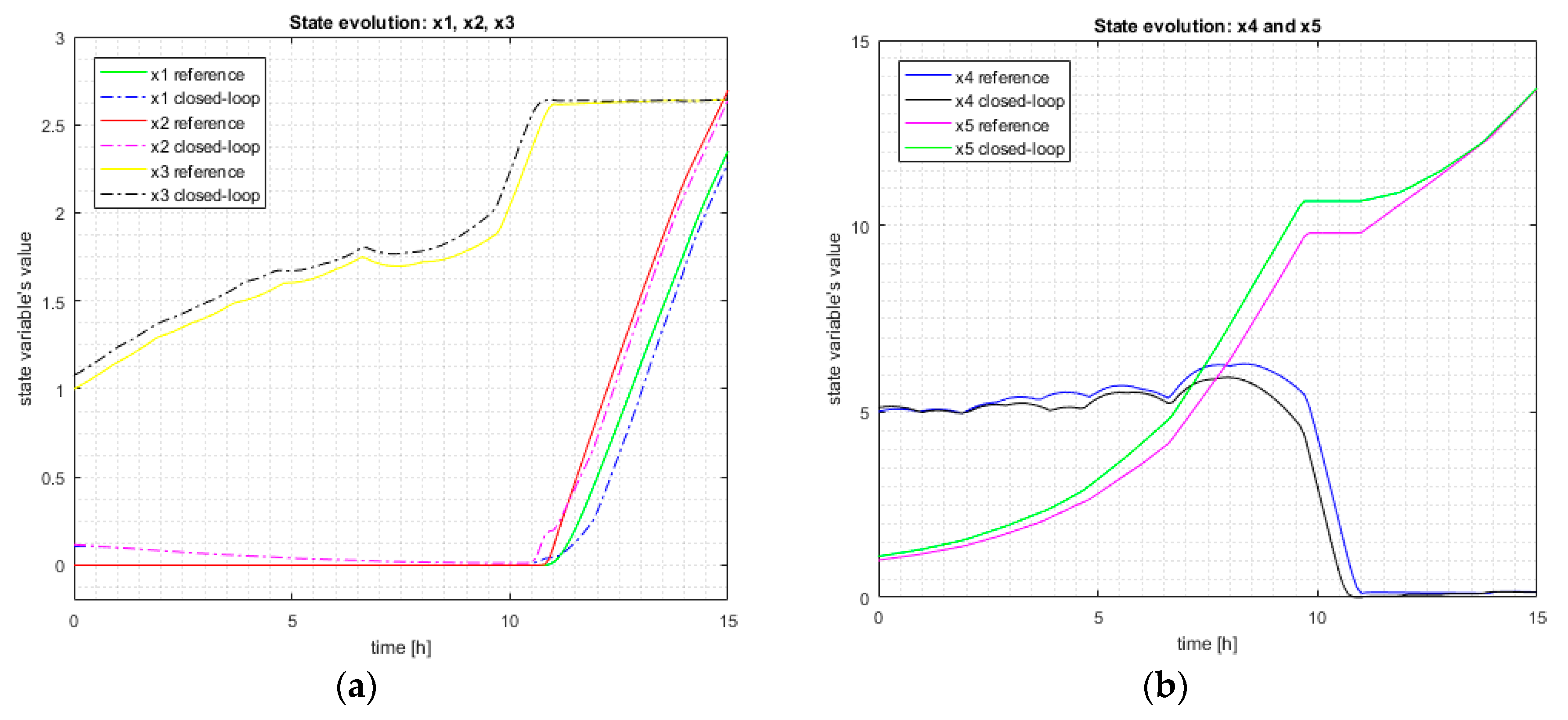
Figure 4 presents comparatively the state evolution in the reference case and the closed-loop control system with TC using SAA. The medium value of the noise is Mean = 0.1, which is very big for our process especially for the variables
and
. The relative error of the final state, which is more important for the terminal penalty, is only 0.76%. This fact is reflected in the relative error of the performance index,
= 3.81%.
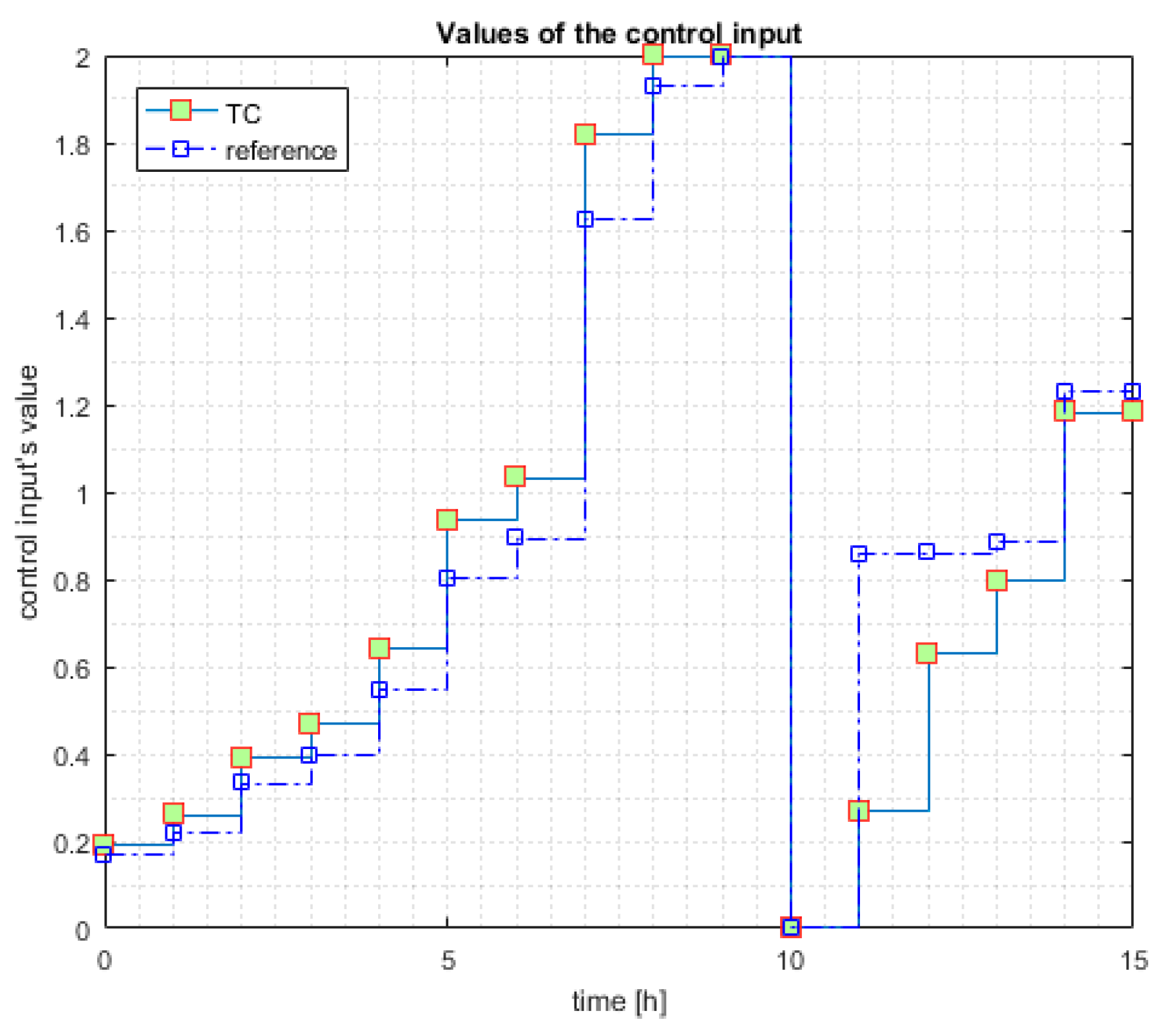
The control input’s value is depicted in
Figure 5 in the two cases. It is interesting to see that the control input given by the TC has relatively the same pattern.
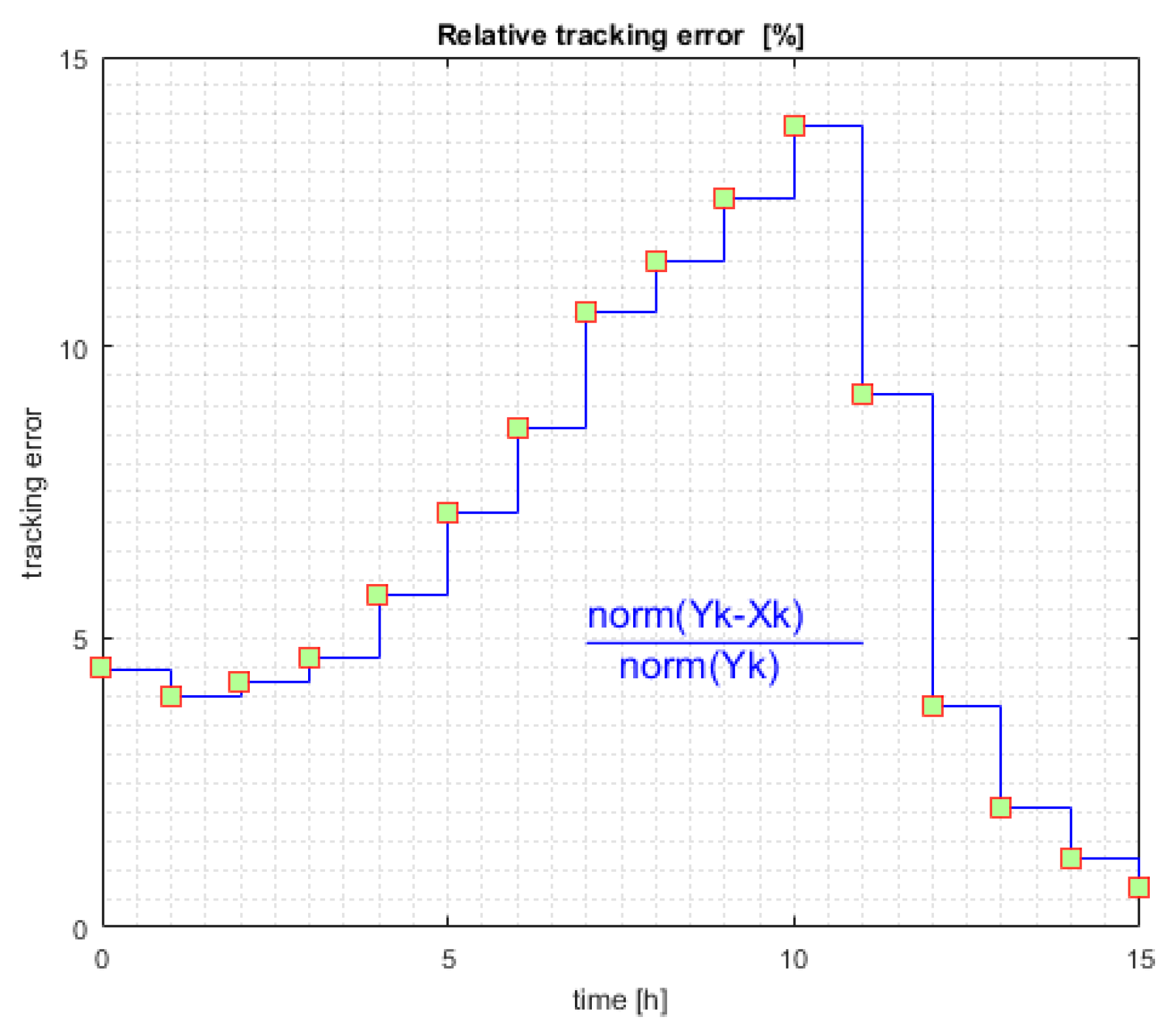
Figure 6 shows the evolution of the relative tracking error over the control horizon. Let us note that the tracking error is already near 5% initially, which is a big value.
To simulate the real process, we have considered that the RPM is equivalent to the PM to which a normally distributed noise is added. The latter one is a random variable having a normal distribution like in Equation (9). In this way, the state variables
and
,
, are different:
We have implemented a similar program as before, to simulate the closed-loop functioning with TC and RPM. The only difference is that the state variables are adjusted using Equations (9) and (11) (see TC_SA_h1_MEAN0_04.m). The values characterizing the normal noise are Mean = 0.04 and StDev = 0.01. The resulting simulation program has a stochastic character; therefore, we cannot conclude after a single execution. We have to repeat the execution more times to give consistency to statistical parameters in such a situation.
That is why the second simulation series will repeat 30 times the closed-loop simulation program.
Table 2 gives some statistical parameters characterizing the 30 executions of the closed-loop simulation program. For the relative error of the performance index (
, see Equation (7)), the minimum, average, maximum values, and the standard deviation are indicated. The relative tracking error in the final state, Rerr(
N), is computed according to the Equation (10).
Table 2 shows its minimum, average, and maximum value over the simulation series. The particular simulation among the 30, whose performance index is the closest to the average, can be considered typical execution. Its performance index is 29.96, which means the relative error has an acceptable value of 7.1%.
Remark 1: We can make a peculiar simulation of the closed-loop, taking = , and RPM PM (without noise). Obviously, the theoretical solution is trivial: the sequence of control input values calculated by the TC is just , and the sequence of the process’ states is just Y0, Y1,…, YN−1, YN. This solution is found on the condition that the MA used for local optimization (SAA in our case) works very well and finds . Setting these conditions, the simulation (see TC_SA_X00_NONOISE.m) has proved that our SAA’s implementation works very well. Generally speaking, this is a method to test the correctness of the MA’s implementation.
4.2. TC’s Implementation Using an Evolutionary Algorithm
The TC’s implementation can use another MA. In this section, we use an evolutionary algorithm called EA2 that is different from EA1.
NB: EA1 and EA2 are two distinct implementations of the evolutionary metaheuristic. EA1 searches the optimal solution of the OCP described in
Appendix A, while EA2 solves the TP presented before. There are two different elements that characterize the two OCPs:
the performance index is (A5) for EA1, and (6) for EA2;
the control horizon is for EA1, and , for EA2. EA1 is executed one time to solve its problem, while EA2 is called for every sample period to solve local optimization problems.
These basic elements further involve many other implementation differences, such as solution encoding and genetic operators. Let us consider EA2 as a function that is symbolically called as below:
The optimization process refers to that has to minimize the same performance index (6). It is naturally coded as a real vector having the components of the control input. In our case Uk is a scalar. EA2 evaluates using an objective function (implemented inside the program TC_EA_h1_NOISE.m; see the folder TC_EA2) that calculates the performance index (6). This function performs two actions: the numerical integration of the process using the current and the computation of the distance .
The constraint (8) is implemented when the initial population is generated and any time the solution’s value is modified (e.g., inside the mutation operator).
EA2 stops the solution’s search after a certain number of generations (40 in our implementation) while the population evolves. This number is tuned according the preliminary tests of the program.
For our peculiar TP, every chromosome of the solution’s population encodes the value of
. So, the length of the solution vector is
h = 1 (control horizon). EA2 having the parameters given by
Table 3 uses a direct encoding with real (non-binary) values. It has the usual characteristics listed below:
The population of each generation has μ individuals.
The offspring population has λ individuals ().
NGen is the number of generations in which the population is evolving.
The selection strategy is based on Stochastic Universal Sampling using the rank of individuals, which is scaled linearly using selection pressure.
No crossover operator, because each chromosome encodes a single control input value (whatever the value m is). In our peculiar TP, the solution vector has a single component, i.e., a scalar.
The mutation operator uses global variance adaptation ([
1,
2]) of the mutation step. The adaptation is made according to the “1/5 success rule”.
The replacement strategy: the offspring replace the λ worst parents of the generation.
We have simulated the closed-loop system using a program whose MA is EA2. A sketch of the simulation program is given in
Table 4.
Nt denotes the length of the control horizon as a sampling period number. Instructions #1 and #3 suggest the connection with the real process, in real-time. The state variable is read or estimated, and the control input is sent toward the process. In our simulation, instruction #3 means that is memorized for further simulations.
The RPM has been implemented, like in the previous section, using a normally distributed noise. For example, we have chosen Mean = 0.04 and StDev = 0.01. The single running’s results of this program are presented in
Table 5.
Remark 2: Although the results from
Table 5 are a bit better than those from
Table 2, one can assert that the two TC (using SAA or EA2) lead practically toward similar results.
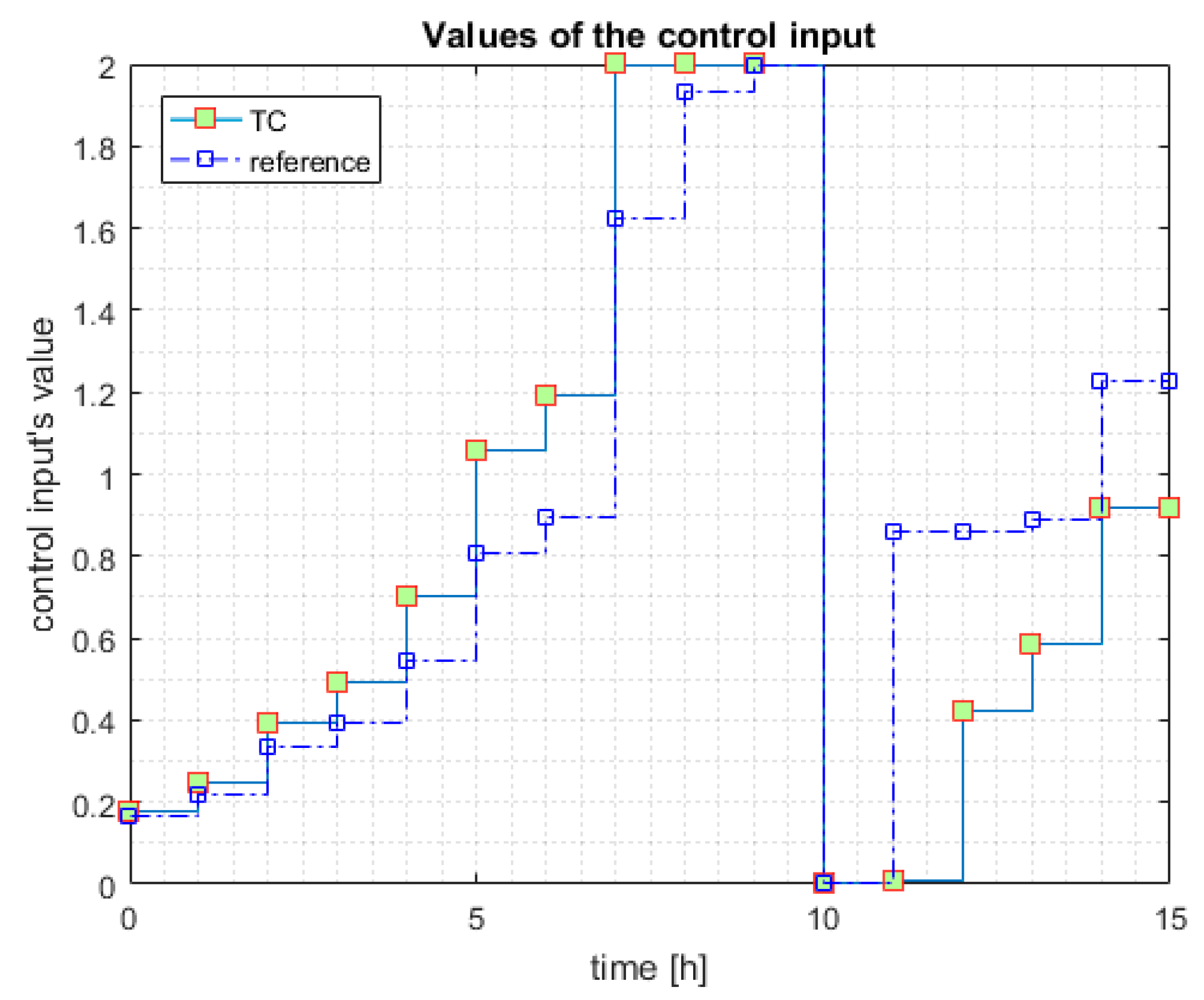
The discrete control input yielded by the TC is depicted in
Figure 7. The evolution’s pattern is similar to a large extent to that one presented in
Figure 5.
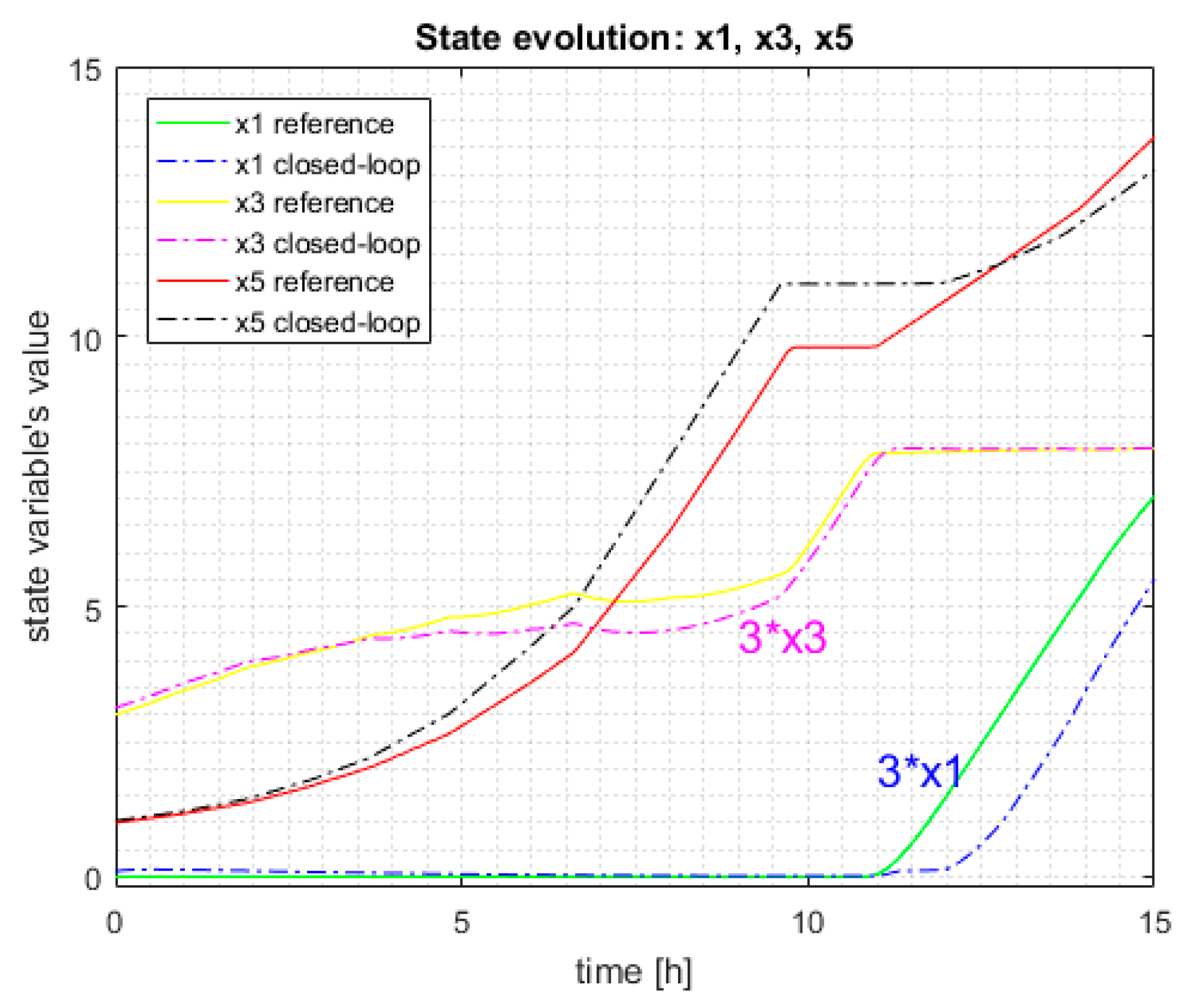
Figure 8 presents the comparative evolution of the state variable
x1,
x3, and
x5 in the two cases: the reference trajectory and the closed-loop system with TC using EA2. The values of
x1 and
x3 are multiplied by 3, to render distinguishable the 4 curves.
Remark 3: The state evolutions from
Figure 4 and
Figure 8 have the same look, a fact that is comprehensible because the two algorithms (SAA and EA2) correctly execute their local optimization task and do not leave their mark on the system evolution.
We have also simulated the closed-loop system for different mean values and using lots of 30 executions. The results are presented in
Table 6, where lines correspond to the means of different noises. For each mean’s value, a lot of 30 program executions were carried out. The data from the last four columns describes only the typical execution of the lot. In lines #2 and #3, the performance index determined by TC with EA2 has superior values to
J*. The explanation is the same as that given for lines #1 and #2 of
Table 1.
Line #1 corresponds to the peculiar simulation of the closed-loop, when = , and RPM PM (without noise, see TC_EA_h1_NONOISE.m). This simulation is the test that we mentioned in the previous section. It proves that our EA’s implementation works very well, because the sequence of the process’ states is just Y0, Y1,…,YN−1, YN and the sequence of control input values is just .




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







