
Short-Term Precipitation Forecasting Based on the Improved Extreme Learning Machine Technique †





Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Improved Weighted Regularized Extreme Learning Machine (IWRELM)
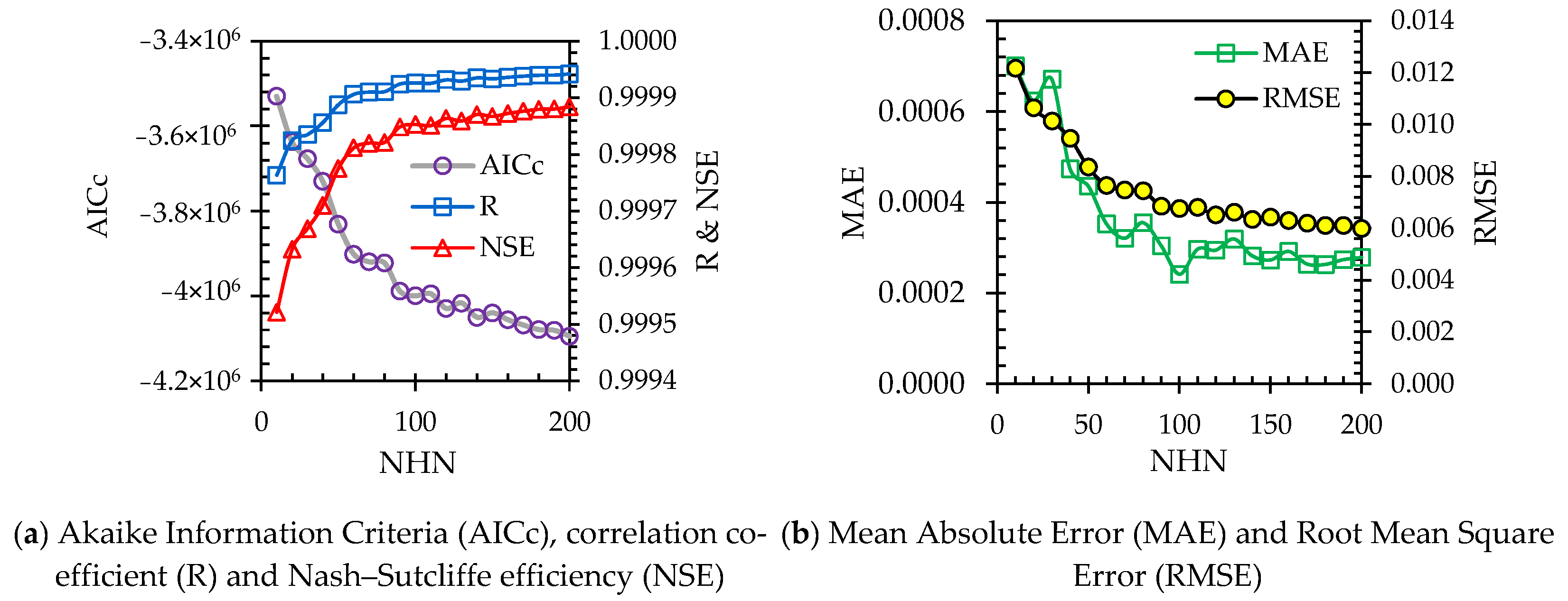
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ebtehaj, I.; Bonakdari, H. A comprehensive comparison of the fifth and sixth phases of the coupled model intercomparison project based on the Canadian earth system models in spatio-temporal variability of long-term flood susceptibility using remote sensing and flood frequency analysis. J. Hydrol. 2023, 617, 128851. [Google Scholar]
- Zaghloul, M.S.; Ghaderpour, E.; Dastour, H.; Farjad, B.; Gupta, A.; Eum, H.; Axhari, G.; Hassan, Q.K. Long Term Trend Analysis of River Flow and Climate in Northern Canada. Hydrology 2022, 9, 197. [Google Scholar] [CrossRef]
- Bonakdari, H.; Ebtehaj, I. A comparative study of extreme learning machines and support vector machines in prediction of sediment transport in open channels. Int. J. Eng. 2016, 29, 1499–1506. [Google Scholar]
- Bonakdari, H.; Ebtehaj, I.; Samui, P.; Gharabaghi, B. Lake Water-Level fluctuations forecasting using Minimax Probability Machine Regression, Relevance Vector Machine, Gaussian Process Regression, and Extreme Learning Machine. Water Resour. Manag. 2019, 33, 3965–3984. [Google Scholar] [CrossRef]
- Bonakdari, H.; Qasem, S.N.; Ebtehaj, I.; Zaji, A.H.; Gharabaghi, B.; Moazamnia, M. An expert system for predicting the velocity field in narrow open channel flows using self-adaptive extreme learning machines. Measurement 2020, 151, 107202. [Google Scholar] [CrossRef]
- Ebtehaj, I.; Bonakdari, H.; Moradi, F.; Gharabaghi, B.; Khozani, Z.S. An Integrated Framework of Extreme Learning Machines for Predicting Scour at Pile Groups in Clear Water Condition. Coastal Eng. 2018, 135, 1–15. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Ebtehaj, I.; Bonakdari, H. A reliable hybrid outlier robust non-tuned rapid machine learning model for multi-step ahead flood forecasting in Quebec, Canada. J. Hydrol. 2022, 614, 128592. [Google Scholar] [CrossRef]
- Ebtehaj, I.; Soltani, K.; Amiri, A.; Faramarzi, M.; Madramootoo, C.A.; Bonakdari, H. Prognostication of shortwave radiation using an improved No-Tuned fast machine learning. Sustainability 2021, 13, 8009. [Google Scholar] [CrossRef]
- Deng, W.; Zheng, Q.; Chen, L. Regularized extreme learning machine. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence and Data Mining, Nashville, TN, USA, 30 March–2 April 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 389–395. [Google Scholar]
- Ministère de l’Environnement et de la Lutte contre les changements climatiques, de la Faune et des Parcs. Données du Réseau de surveillance du climat du Québec, Direction de la qualité de l’air et du climat, Québec. 2022. Available online: https://www.environnement.gouv.qc.ca/ (accessed on 23 November 2022).
- Walton, R.; Binns, A.; Bonakdari, H.; Ebtehaj, I.; Gharabaghi, B. Estimating 2-year flood flows using the generalized structure of the Group Method of Data Handling. J. Hydrol. 2019, 575, 671–689. [Google Scholar] [CrossRef]
- Zeynoddin, M.; Ebtehaj, I.; Bonakdari, H. Development of a linear based stochastic model for daily soil temperature prediction: One step forward to sustainable agriculture. Comput. Electron. Agric. 2020, 176, 105636. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| No. | Function Definition |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ebtehaj, I.; Bonakdari, H.; Gharabaghi, B.; Khelifi, M. Short-Term Precipitation Forecasting Based on the Improved Extreme Learning Machine Technique. Environ. Sci. Proc. 2023, 25, 50. https://doi.org/10.3390/ECWS-7-14237
Ebtehaj I, Bonakdari H, Gharabaghi B, Khelifi M. Short-Term Precipitation Forecasting Based on the Improved Extreme Learning Machine Technique. Environmental Sciences Proceedings. 2023; 25(1):50. https://doi.org/10.3390/ECWS-7-14237
Chicago/Turabian StyleEbtehaj, Isa, Hossein Bonakdari, Bahram Gharabaghi, and Mohamed Khelifi. 2023. "Short-Term Precipitation Forecasting Based on the Improved Extreme Learning Machine Technique" Environmental Sciences Proceedings 25, no. 1: 50. https://doi.org/10.3390/ECWS-7-14237
APA StyleEbtehaj, I., Bonakdari, H., Gharabaghi, B., & Khelifi, M. (2023). Short-Term Precipitation Forecasting Based on the Improved Extreme Learning Machine Technique. Environmental Sciences Proceedings, 25(1), 50. https://doi.org/10.3390/ECWS-7-14237