
Breathe out the Secret of the Lung: Video Classification of Exhaled Flows from Normal and Asthmatic Lung Models Using CNN-Long Short-Term Memory Networks



Abstract
:1. Introduction
- (1)
- Develop normal and diseased lung models with mild and severe constrictions.
- (2)
- Record exhalation flows from the normal and diseased lung casts using a high-speed camera at 20, 15, and 10 L/min and analyze the flow videos using PIVlab.
- (3)
- Train two CNN-LSTM networks based on videos acquired at 20 L/min and test the networks using videos acquired at 20, 15, and 10 L/min.
- (4)
- Compare the classification performances based on videos and still images.
- (5)
- Calculate the categorial occlusion sensitivity for AlexNet and GoogLeNet.
2. Materials and Methods
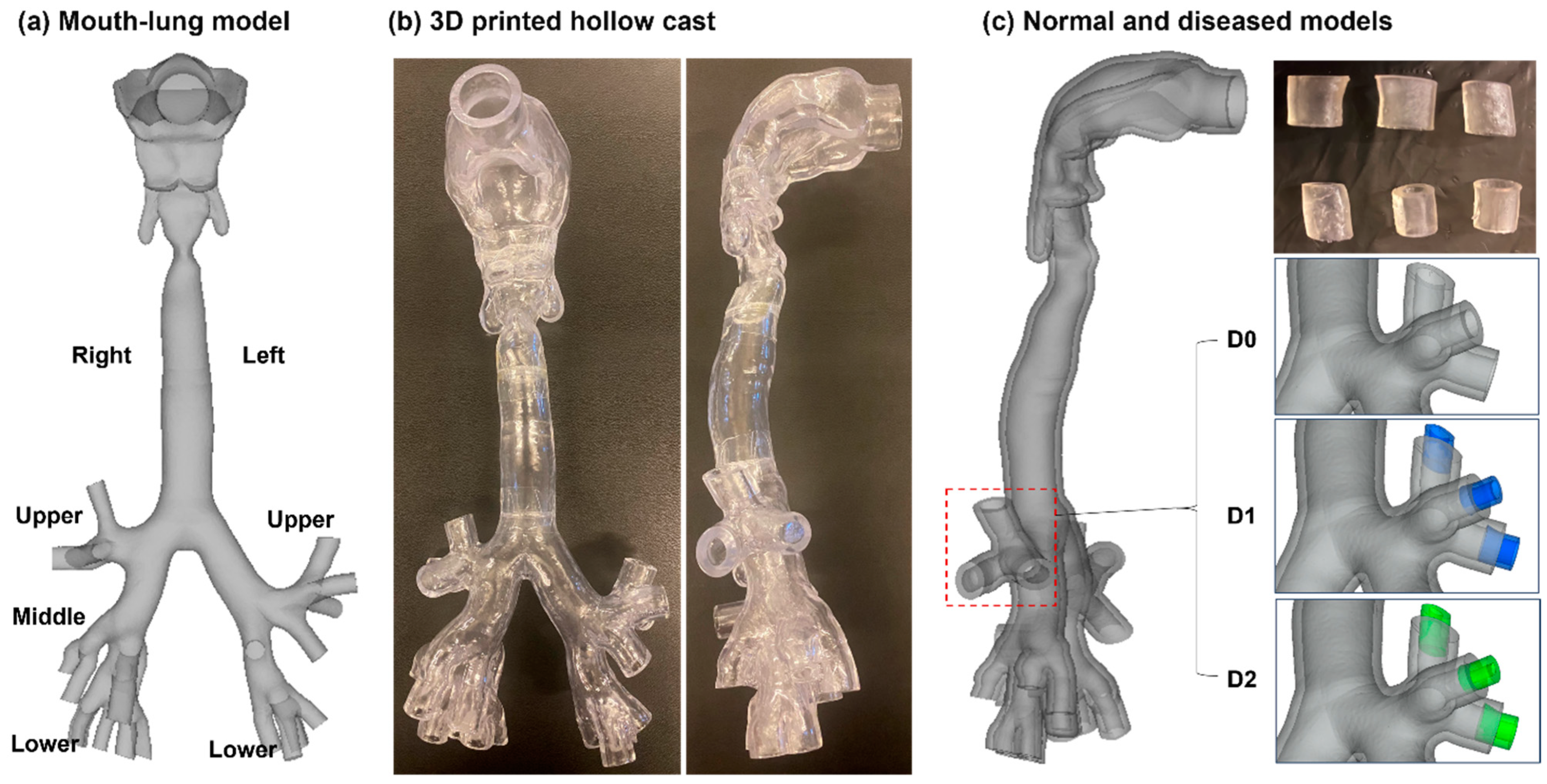
2.1. Normal and Diseased Lung Models
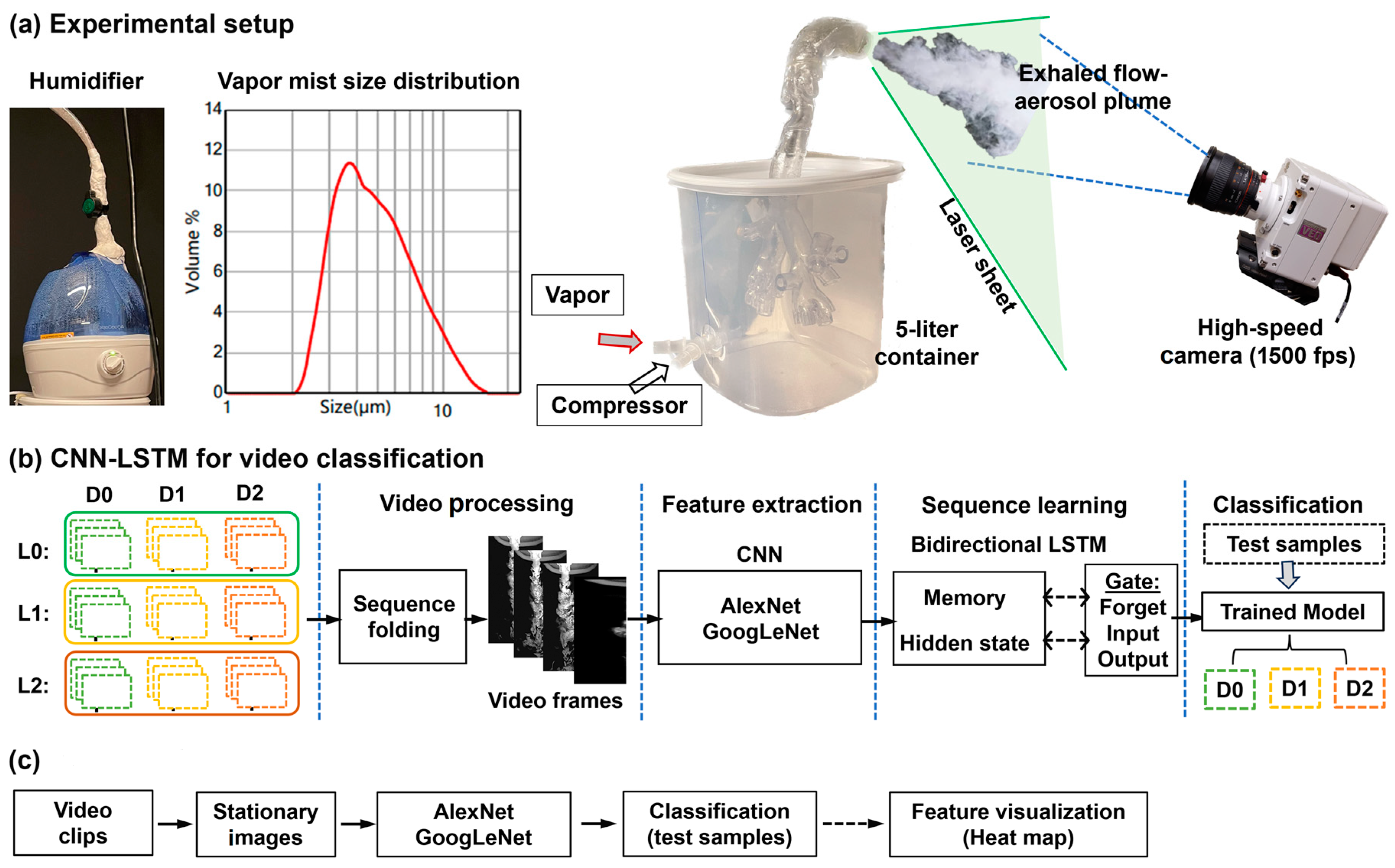
2.2. Experimental Setup
2.3. CNN-LSTM Networks for Video Classification
2.3.1. CNN Models
2.3.2. LSTM
2.3.3. Training Configuration and Performance Matrices
2.3.4. Heat Map
2.4. Study Design
3. Results
3.1. High-Speed Recording of Expiratory Flows
3.2. PIVlab Analyses of Videos
3.2.1. Velocity and Vorticity
3.2.2. Vortex Locations
3.3. Video Classification
3.3.1. AlexNet-LSTM
3.3.2. GoogLeNet-LSTM
3.3.3. Comparison between AlexNet-LSTM and GoogLeNet-LSTM
3.4. Sequential Effects in Classification
3.4.1. Time Shifting in Video Classification
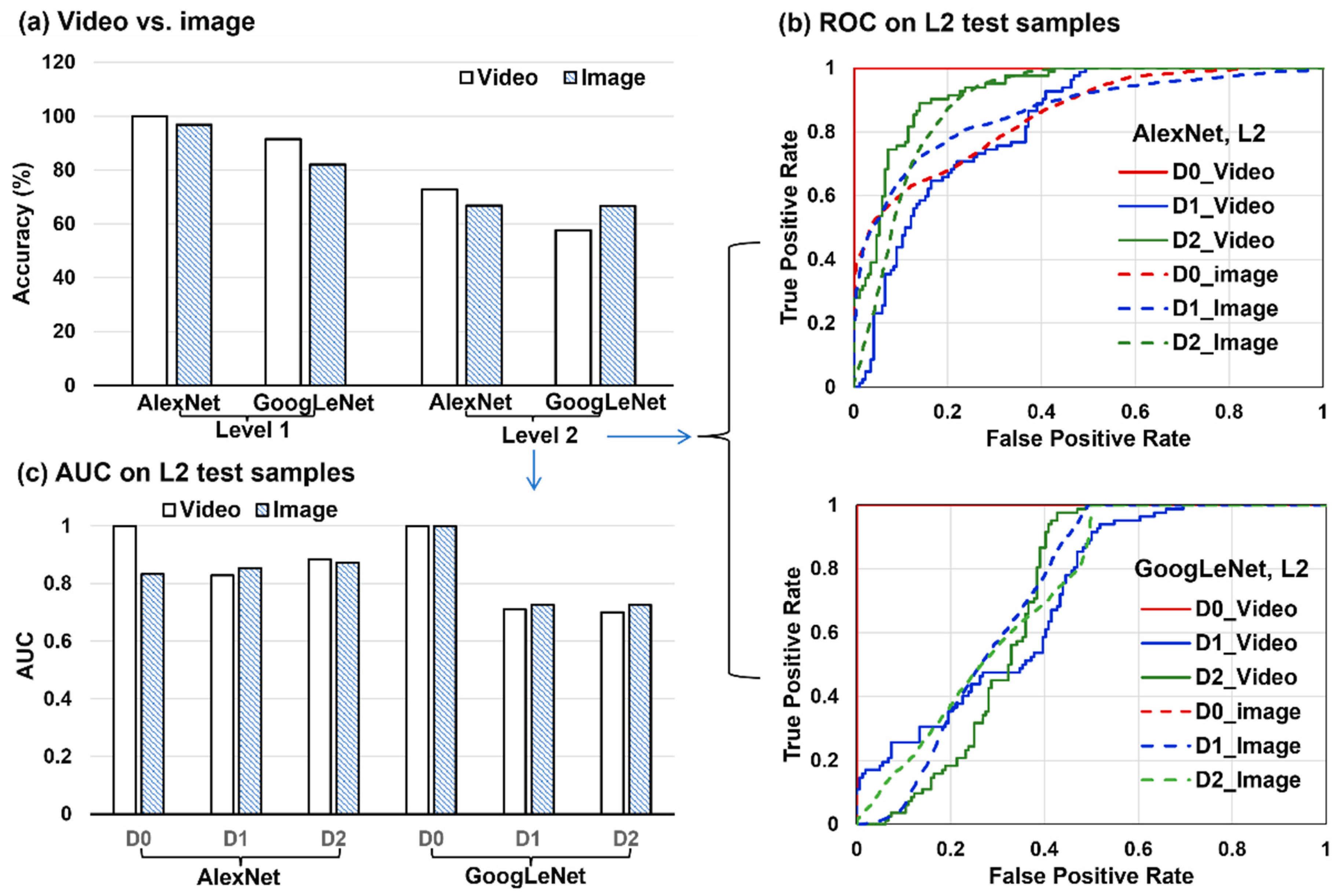
3.4.2. Videos vs. Still Images
3.5. CNN Learned Spatial Features from Still Images
3.5.1. AlexNet
3.5.2. GoogLeNet
4. Discussion
4.1. AlexNet-LSTM vs. GoogLeNet-LSTM
4.2. Video-Based vs. Image-Based Classifications
4.3. Lung Diagnosis Using Exhaled Flows vs. Other Methods
4.4. Limitations and Future Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ibrahim, W.; Carr, L.; Cordell, R.; Wilde, M.J.; Salman, D.; Monks, P.S.; Thomas, P.; Brightling, C.E.; Siddiqui, S.; Greening, N.J. Breathomics for the clinician: The use of volatile organic compounds in respiratory diseases. Thorax 2021, 76, 514–521. [Google Scholar] [CrossRef]
- Miekisch, W.; Schubert, J.K.; Noeldge-Schomburg, G.F.E. Diagnostic potential of breath analysis—Focus on volatile organic compounds. Clin. Chim. Acta 2004, 347, 25–39. [Google Scholar] [CrossRef]
- Kostikas, K.; Koutsokera, A.; Papiris, S.; Gourgoulianis, K.I.; Loukides, S. Exhaled breath condensate in patients with asthma: Implications for application in clinical practice. Clin. Exp. Allergy 2008, 38, 557–565. [Google Scholar] [CrossRef] [PubMed]
- Loukides, S.; Bakakos, P.; Kostikas, K. Oxidative Stress in Patients with COPD. Curr. Drug Targets 2011, 12, 469–477. [Google Scholar] [CrossRef] [PubMed]
- Colombo, C.; Faelli, N.; Tirelli, A.S.; Fortunato, F.; Biffi, A.; Claut, L.; Cariani, L.; Dacco, V.; Prato, R.; Conese, M. Analysis of inflammatory and immune response biomarkers in sputum and exhaled breath condensate by a multi-parametric biochip array in cystic fibrosis. Int. J. Immunopathol. Pharmacol. 2011, 24, 423–432. [Google Scholar] [CrossRef]
- Vijverberg, S.J.H.; Koenderman, L.; Koster, E.S.; van der Ent, C.K.; Raaijmakers, J.A.M.; Maitland-van der Zee, A.H. Biomarkers of therapy responsiveness in asthma: Pitfalls and promises. Clin. Exp. Allergy 2011, 41, 615–629. [Google Scholar] [CrossRef] [PubMed]
- Mazzone, P.J. Analysis of volatile organic compounds in the exhaled breath for the diagnosis of lung cancer. J. Thorac. Oncol. 2008, 3, 774–780. [Google Scholar] [CrossRef]
- Buszewski, B.; Kesy, M.; Ligor, T.; Amann, A. Human exhaled air analytics: Biomarkers of diseases. Biomed. Chromatogr. 2007, 21, 553–566. [Google Scholar] [CrossRef] [PubMed]
- Horvath, I.; Lazar, Z.; Gyulai, N.; Kollai, M.; Losonczy, G. Exhaled biomarkers in lung cancer. Eur. Respir. J. 2009, 34, 261–275. [Google Scholar] [CrossRef]
- Phillips, M.; Cataneo, R.N.; Cummin, A.R.C.; Gagliardi, A.J.; Gleeson, K.; Greenberg, J.; Maxfield, R.A.; Rom, W.N. Detection of lung cancer with volatile markers in the breath. Chest 2003, 123, 2115–2123. [Google Scholar] [CrossRef]
- Khoubnasabjafari, M.; Mogaddam, M.R.A.; Rahimpour, E.; Soleymani, J.; Saei, A.A.; Jouyban, A. Breathomics: Review of sample collection and analysis, data modeling and clinical applications. Crit. Rev. Anal. Chem. 2022, 52, 1461–1487. [Google Scholar] [CrossRef] [PubMed]
- Blanchard, J.D. Aerosol bolus dispersion and aerosol-derived airway morphometry: Assessment of lung pathology and response to therapy, Part 1. J. Aerosol Med.-Depos. Clear. Eff. Lung 1996, 9, 183–205. [Google Scholar] [CrossRef] [PubMed]
- Goo, J.; Kim, C.S. Analysis of aerosol bolus dispersion in a cyclic tube flow by finite element method. Aerosol Sci. Technol. 2001, 34, 321–331. [Google Scholar] [CrossRef]
- Lee, D.; Lee, J. Dispersion of aerosol bolus during one respiratory cycle in a model lung airway. J. Aerosol Sci. 2002, 33, 1219. [Google Scholar] [CrossRef]
- Schulz, H.; Eder, G.; Heyder, J. Lung volume is a determinant of aerosol bolus dispersion. J. Aerosol Med. 2003, 16, 255–262. [Google Scholar] [CrossRef] [PubMed]
- Kohlhäufl, M.; Brand, P.; Scheuch, G.; Meyer, T.; Schulz, H.; Häussinger, K.; Heyder, J. Aerosol morphometry and aerosol bolus dispersion in patients with CT-determined combined pulmonary emphysema and lung fibrosis. J. Aerosol Med. 2000, 13, 117–124. [Google Scholar] [CrossRef]
- Shaker, S.B.; Maltbaek, N.; Brand, P.; Haeussermann, S.; Dirksen, A. Quantitative computed tomography and aerosol morphometry in COPD and alpha1-antitrypsin deficiency. Eur. Respir. J. 2005, 25, 23–30. [Google Scholar] [CrossRef]
- Sturm, R. Theoretical diagnosis of emphysema by aerosol bolus inhalation. Ann. Transl. Med. 2017, 5, 154. [Google Scholar]
- Brand, P.; App, E.M.; Meyer, T.; Kur, F.; Müller, C.; Dienemann, H.; Reichart, B.; Fruhmann, G.; Heyder, J. Aerosol bolus dispersion in patients with bronchiolitis obliterans after heart-lung and double-lung transplantation. The Munich Lung Transplantation Group. J. Aerosol Med. 1998, 11, 41–53. [Google Scholar] [CrossRef]
- Kohlhäufl, M.; Brand, P.; Rock, C.; Radons, T.; Scheuch, G.; Meyer, T.; Schulz, H.; Pfeifer, K.J.; Häussinger, K.; Heyder, J. Noninvasive diagnosis of emphysema. Aerosol morphometry and aerosol bolus dispersion in comparison to HRCT. Am. J. Respir. Crit. Care Med. 1999, 160, 913–918. [Google Scholar] [CrossRef]
- Hardy, K.G.; Gann, L.P.; Tennal, K.B.; Walls, R.; Hiller, F.C.; Anderson, P.J. Sensitivity of aerosol bolus behavior to methacholine-induced bronchoconstriction. Chest 1998, 114, 404–410. [Google Scholar] [CrossRef]
- Si, X.; Xi, J.S.; Talaat, M.; Donepudi, R.; Su, W.-C.; Xi, J. Evaluation of impulse oscillometry in respiratory airway casts with varying obstruction phenotypes, locations, and complexities. J. Respir. 2022, 2, 44–58. [Google Scholar] [CrossRef]
- Erfanian Ebadi, S.; Krishnaswamy, D.; Bolouri, S.E.S.; Zonoobi, D.; Greiner, R.; Meuser-Herr, N.; Jaremko, J.L.; Kapur, J.; Noga, M.; Punithakumar, K. Automated detection of pneumonia in lung ultrasound using deep video classification for COVID-19. Inform. Med. Unlocked. 2021, 25, 100687. [Google Scholar] [CrossRef]
- Shea, D.E.; Kulhare, S.; Millin, R.; Laverriere, Z.; Mehanian, C.; Delahunt, C.B.; Banik, D.; Zheng, X.; Zhu, M.; Ji, Y.; et al. Deep learning video classification of lung ultrasound features associated with pneumonia. In Proceedings of the 2023 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)(CVPRW), Vancouver, BC, Canada, 17–24 June 2023; pp. 3103–3112. [Google Scholar]
- Bruno, A.; Ignesti, G.; Salvetti, O.; Moroni, D.; Martinelli, M. Efficient lung ultrasound classification. Bioengineering 2023, 10, 555. [Google Scholar] [CrossRef]
- Chui, K.T.; Gupta, B.B.; Liu, R.W.; Zhang, X.; Vasant, P.; Thomas, J.J. Extended-range prediction model Using NSGA-III optimized RNN-GRU-LSTM for driver stress and drowsiness. Sensors 2021, 21, 6412. [Google Scholar] [CrossRef]
- Barros, B.; Lacerda, P.; Albuquerque, C.; Conci, A. Pulmonary COVID-19: Learning spatiotemporal features combining CNN and LSTM networks for lung ultrasound video classification. Sensor 2021, 21, 5486. [Google Scholar] [CrossRef] [PubMed]
- Xi, J.; Si, X.A.; Kim, J.; Mckee, E.; Lin, E.-B. Exhaled aerosol pattern discloses lung structural abnormality: A sensitivity study using computational modeling and fractal analysis. PLoS ONE 2014, 9, e104682. [Google Scholar] [CrossRef] [PubMed]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Zhang, X.; Yang, Y.; Shen, Y.W.; Zhang, K.R.; Ma, L.T.; Ding, C.; Wang, B.Y.; Meng, Y.; Liu, H. Quality of online video resources concerning patient education for neck pain: A YouTube-based quality-control study. Front. Public Health 2022, 10, 972348. [Google Scholar] [CrossRef]
- ur Rehman, A.; Belhaouari, S.B.; Kabir, M.A.; Khan, A. On the use of deep learning for video classification. Appl. Sci. 2023, 13, 2007. [Google Scholar] [CrossRef]
- Chen, J.; Wang, J.; Yuan, Q.; Yang, Z. CNN-LSTM model for recognizing video-recorded actions performed in a traditional chinese exercise. IEEE J. Transl. Eng. Health Med. 2023, 11, 351–359. [Google Scholar] [CrossRef] [PubMed]
- Senyurek, V.Y.; Imtiaz, M.H.; Belsare, P.; Tiffany, S.; Sazonov, E. A CNN-LSTM neural network for recognition of puffing in smoking episodes using wearable sensors. Biomed. Eng. Lett. 2020, 10, 195–203. [Google Scholar] [CrossRef]
- Gilik, A.; Ogrenci, A.S.; Ozmen, A. Air quality prediction using CNN+LSTM-based hybrid deep learning architecture. Environ. Sci. Pollut. Res. Int. 2022, 29, 11920–11938. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Zhang, Y.; Weng, Y.; Wang, B.; Li, Z. Natural language processing applications for computer-aided diagnosis in oncology. Diagnostics 2023, 13, 286. [Google Scholar] [CrossRef] [PubMed]
- Whata, A.; Chimedza, C. Deep Learning for SARS COV-2 Genome Sequences. IEEE Access 2021, 9, 59597–59611. [Google Scholar] [CrossRef] [PubMed]
- Khatun, M.A.; Yousuf, M.A.; Ahmed, S.; Uddin, M.Z.; Alyami, S.A.; Al-Ashhab, S.; Akhdar, H.F.; Khan, A.; Azad, A.; Moni, M.A. Deep CNN-LSTM with self-attention model for human activity recognition using wearable sensor. IEEE J. Transl. Eng. Health Med. 2022, 10, 2700316. [Google Scholar] [CrossRef] [PubMed]
- Qin, P.; Li, H.; Li, Z.; Guan, W.; He, Y. A CNN-LSTM car-following model considering generalization ability. Sensors 2023, 23, 660. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Di, L.; Sun, Z.; Shen, Y.; Lai, Z. County-level soybean yield prediction using deep CNN-LSTM model. Sensors 2019, 19, 4363. [Google Scholar] [CrossRef] [PubMed]
- Gao, G.; Wang, C.; Wang, J.; Lv, Y.; Li, Q.; Ma, Y.; Zhang, X.; Li, Z.; Chen, G. CNN-Bi-LSTM: A complex environment-oriented cattle behavior classification network based on the fusion of CNN and Bi-LSTM. Sensors 2023, 23, 7714. [Google Scholar] [CrossRef]
- Lu, W.; Rui, H.; Liang, C.; Jiang, L.; Zhao, S.; Li, K. A method based on GA-CNN-LSTM for daily tourist flow prediction at scenic spots. Entropy 2020, 22, 261. [Google Scholar] [CrossRef]
- Guangyu, H. Analysis of sports video intelligent classification technology based on neural network algorithm and transfer Learning. Comput. Intell. Neurosci. 2022, 2022, 7474581. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, M.; Cui, W.; Liu, C.; Li, X. An attention based CNN-LSTM approach for sleep-wake detection with heterogeneous sensors. IEEE J. Biomed. Health Inform. 2021, 25, 3270–3277. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, L.; Dai, M.; Zhou, Y.; Sun, L. Intelligent automatic sleep staging model based on CNN and LSTM. Front. Public Health 2022, 10, 946833. [Google Scholar] [CrossRef] [PubMed]
- Megalmani, D.R.; Shailesh, B.G.; Rao, M.V.A.; Jeevannavar, S.S.; Ghosh, P.K. Unsegmented heart sound classification using hybrid CNN-LSTM neural networks. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2021, 2021, 713–717. [Google Scholar] [PubMed]
- Maitre, J.; Bouchard, K.; Gaboury, S. Fall detection with UWB radars and CNN-LSTM architecture. IEEE J. Biomed. Health Inform. 2021, 25, 1273–1283. [Google Scholar] [CrossRef] [PubMed]
- Xi, J.; Kim, J.; Si, X.A.; Zhou, Y. Diagnosing obstructive respiratory diseases using exhaled aerosol fingerprints: A feasibility study. J. Aerosol Sci. 2013, 64, 24–36. [Google Scholar] [CrossRef]
- Si, X.; Talaat, M.; Xi, J. SARS COV-2 virus-laden droplets coughed from deep lungs: Numerical quantification in a single-path whole respiratory tract geometry. Phys. Fluids 2021, 33, 023306. [Google Scholar]
- Xie, S.; Zheng, X.; Chen, Y.; Xie, L.; Liu, J.; Zhang, Y.; Yan, J.; Zhu, H.; Hu, Y. Artifact removal using improved GoogLeNet for sparse-view CT reconstruction. Sci. Rep. 2018, 8, 6700. [Google Scholar] [CrossRef]
- Talaat, M.; Si, X.; Xi, J. Multi-level training and testing of CNN models in diagnosing multi-center COVID-19 and pneumonia X-ray images. Appl. Sci. 2023, 13, 10270. [Google Scholar] [CrossRef]
- Xi, J.; Zhao, W. Correlating exhaled aerosol images to small airway obstructive diseases: A study with dynamic mode decomposition and machine learning. PLoS ONE 2019, 14, e0211413. [Google Scholar] [CrossRef]
- Bickel, S.; Popler, J.; Lesnick, B.; Eid, N. Impulse oscillometry: Interpretation and practical applications. Chest 2014, 146, 841–847. [Google Scholar] [CrossRef]
- Chetta, A.; Facciolongo, N.; Franco, C.; Franzini, L.; Piraino, A.; Rossi, C. Impulse oscillometry, small airways disease, and extra-fine formulations in asthma and chronic obstructive pulmonary disease: Windows for new opportunities. Ther. Clin. Risk Manag. 2022, 18, 965–979. [Google Scholar] [CrossRef] [PubMed]
- Gholizadeh, A.; Black, K.; Kipen, H.; Laumbach, R.; Gow, A.; Weisel, C.; Javanmard, M. Detection of respiratory inflammation biomarkers in non-processed exhaled breath condensate samples using reduced graphene oxide. RSC Adv. 2022, 12, 35627–35638. [Google Scholar] [CrossRef] [PubMed]
- Kiss, H.; Örlős, Z.; Gellért, Á.; Megyesfalvi, Z.; Mikáczó, A.; Sárközi, A.; Vaskó, A.; Miklós, Z.; Horváth, I. Exhaled biomarkers for point-of-care diagnosis: Recent advances and new challenges in breathomics. Micromachines 2023, 14, 391. [Google Scholar] [CrossRef]
- Si, X.A.; Xi, J. Deciphering exhaled aerosol fingerprints for early diagnosis and personalized therapeutics of obstructive respiratory diseases in small airways. J. Nanotheranostics 2021, 2, 94–117. [Google Scholar] [CrossRef]
- Talaat, M.; Si, X.; Xi, J. Datasets of simulated exhaled aerosol images from normal and diseased lungs with multi-level similarities for neural network training/testing and continuous learning. Data 2023, 8, 126. [Google Scholar] [CrossRef]
- Talaat, M.; Xi, J.; Tan, K.; Si, X.A.; Xi, J. Convolutional neural network classification of exhaled aerosol images for diagnosis of obstructive respiratory diseases. J. Nanotheranostics 2023, 4, 228–247. [Google Scholar] [CrossRef]
- Si, X.; Wang, J.; Dong, H.; Xi, J. Data-driven discovery of anomaly-sensitive parameters from uvula wake flows using wavelet analyses and Poincaré maps. Acoustics 2023, 5, 1046–1065. [Google Scholar] [CrossRef]
- Yamamoto, Y.; Sato, H.; Kanada, H.; Iwashita, Y.; Hashiguchi, M.; Yamasaki, Y. Relationship between lip motion detected with a compact 3D camera and swallowing dynamics during bolus flow swallowing in Japanese elderly men. J. Oral Rehabil. 2020, 47, 449–459. [Google Scholar] [CrossRef]
- Xi, J.; Yang, T. Variability in oropharyngeal airflow and aerosol deposition due to changing tongue positions. J. Drug Deliv. Sci. Technol. 2019, 49, 674–682. [Google Scholar] [CrossRef]
- Bafkar, O.; Rosengarten, G.; Patel, M.J.; Lester, D.; Calmet, H.; Nguyen, V.; Gulizia, S.; Cole, I.S. Effect of inhalation on oropharynx collapse via flow visualisation. J. Biomech. 2021, 118, 110200. [Google Scholar] [CrossRef]
- Chien, C.Y.; Chen, J.W.; Chang, C.H.; Huang, C.C. Tracking dynamic tongue motion in ultrasound images for obstructive sleep apnea. Ultrasound. Med. Biol. 2017, 43, 2791–2805. [Google Scholar] [CrossRef] [PubMed]
- Xi, J.; Si, X.; Dong, H.; Zhong, H. Effects of glottis motion on airflow and energy expenditure in a human upper airway model. Eur. J. Mech. B Fluids 2018, 72, 23–37. [Google Scholar] [CrossRef]
- Yagi, N.; Nagami, S.; Lin, M.K.; Yabe, T.; Itoda, M.; Imai, T.; Oku, Y. A noninvasive swallowing measurement system using a combination of respiratory flow, swallowing sound, and laryngeal motion. Med. Biol. Eng. Comput. 2017, 55, 1001–1017. [Google Scholar] [CrossRef] [PubMed]
- Chu, Y.; Yue, X.; Yu, L.; Sergei, M.; Wang, Z. Automatic image captioning based on ResNet50 and LSTM with soft attention. Wirel. Commun. Mob. Comput. 2020, 2020, 8909458. [Google Scholar] [CrossRef]
- Srinivas, K.; Gagana Sri, R.; Pravallika, K.; Nishitha, K.; Polamuri, S.R. COVID-19 prediction based on hybrid Inception V3 with VGG16 using chest X-ray images. Multimed. Tools Appl. 2023, 1–18. [Google Scholar] [CrossRef]
- Michele, A.; Colin, V.; Santika, D.D. MobileNet convolutional neural networks and support vector machines for palmprint recognition. Procedia Comput. Sci. 2019, 157, 110–117. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking model. scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| All | D0 | D1 | D2 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (%) | Accu | Prec | Sens | Spec | F1-S | Prec | Sens | Spec | F1-S | Prec | Sens | Spec | F1-S |
| L0 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| L1 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| L1-1s | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| L2 | 72.8 | 82.8 | 100 | 89.6 | 90.6 | 58.0 | 70.7 | 74.4 | 63.7 | 83.0 | 47.6 | 95.1 | 60.5 |
| All | D0 | D1 | D2 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (%) | Accu | Prec | Sens | Spec | F1-S | Prec | Sens | Spec | F1-S | Prec | Sens | Spec | F1-S |
| L0 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| L1 | 91.5 | 100 | 100 | 100 | 100 | 73.1 | 100 | 89 | 84.5 | 100 | 78.1 | 100 | 87.7 |
| L1-1s | 91.9 | 98.8 | 98.8 | 99.2 | 98.8 | 76.2 | 100 | 90.7 | 76.2 | 98.5 | 80.3 | 99.2 | 88.5 |
| L2 | 57.7 | 95.4 | 100 | 97.6 | 97.6 | 40.4 | 53.7 | 60.4 | 46.1 | 31.4 | 19.5 | 78.7 | 24.1 |
| All | D0 | D1 | D2 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (%) | Accu | Prec | Sens | Spec | F1-S | Prec | Sens | Spec | F1-S | Prec | Sens | Spec | F1-S |
| L0 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| L1 | 96.9 | 98.3 | 100 | 98.9 | 99.1 | 99.2 | 88.5 | 98.9 | 93.5 | 94.3 | 98.8 | 96.3 | 96.5 |
| L2 | 66.8 | 64.8 | 65.8 | 82.2 | 65.3 | 63.7 | 79.9 | 77.3 | 70.9 | 74.7 | 54.7 | 63.2 | 59.3 |
| All | D0 | D1 | D2 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (%) | Accu | Prec | Sens | Spec | F1-S | Prec | Sens | Spec | F1-S | Prec | Sens | Spec | F1-S |
| L0 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| L1 | 82.1 | 100 | 100 | 100 | 100 | 57.3 | 86.3 | 80.8 | 68.9 | 88.3 | 61.6 | 94.9 | 72.6 |
| L2 | 66.7 | 100 | 100 | 100 | 100 | 50.1 | 90.7 | 54.7 | 64.5 | 50.5 | 9.5 | 95.4 | 16.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Talaat, M.; Si, X.; Xi, J. Breathe out the Secret of the Lung: Video Classification of Exhaled Flows from Normal and Asthmatic Lung Models Using CNN-Long Short-Term Memory Networks. J. Respir. 2023, 3, 237-257. https://doi.org/10.3390/jor3040022
Talaat M, Si X, Xi J. Breathe out the Secret of the Lung: Video Classification of Exhaled Flows from Normal and Asthmatic Lung Models Using CNN-Long Short-Term Memory Networks. Journal of Respiration. 2023; 3(4):237-257. https://doi.org/10.3390/jor3040022
Chicago/Turabian StyleTalaat, Mohamed, Xiuhua Si, and Jinxiang Xi. 2023. "Breathe out the Secret of the Lung: Video Classification of Exhaled Flows from Normal and Asthmatic Lung Models Using CNN-Long Short-Term Memory Networks" Journal of Respiration 3, no. 4: 237-257. https://doi.org/10.3390/jor3040022
APA StyleTalaat, M., Si, X., & Xi, J. (2023). Breathe out the Secret of the Lung: Video Classification of Exhaled Flows from Normal and Asthmatic Lung Models Using CNN-Long Short-Term Memory Networks. Journal of Respiration, 3(4), 237-257. https://doi.org/10.3390/jor3040022