
Mobility- and Energy-Aware Cooperative Edge Offloading for Dependent Computation Tasks †

 , , , , , ,
, , , , , ,  and
and 
Abstract
:1. Introduction
1.1. Motivation
1.2. Overview of Contributions and Structure of This Article
2. Related Work
2.1. General Cooperative Edge Computing Approaches
2.2. Mobility Models
2.3. Task Dependency Models
3. System Model
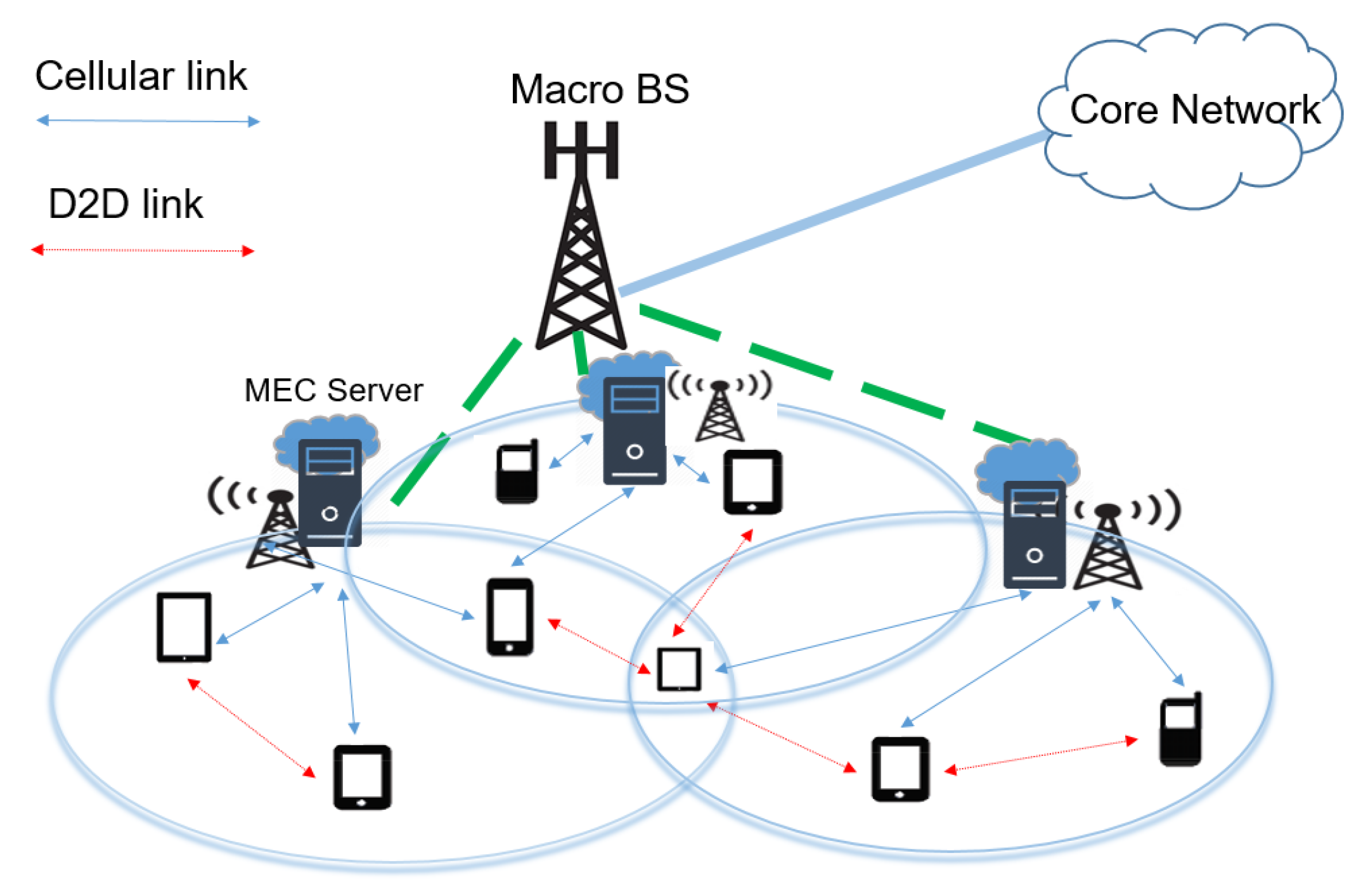
3.1. Overview
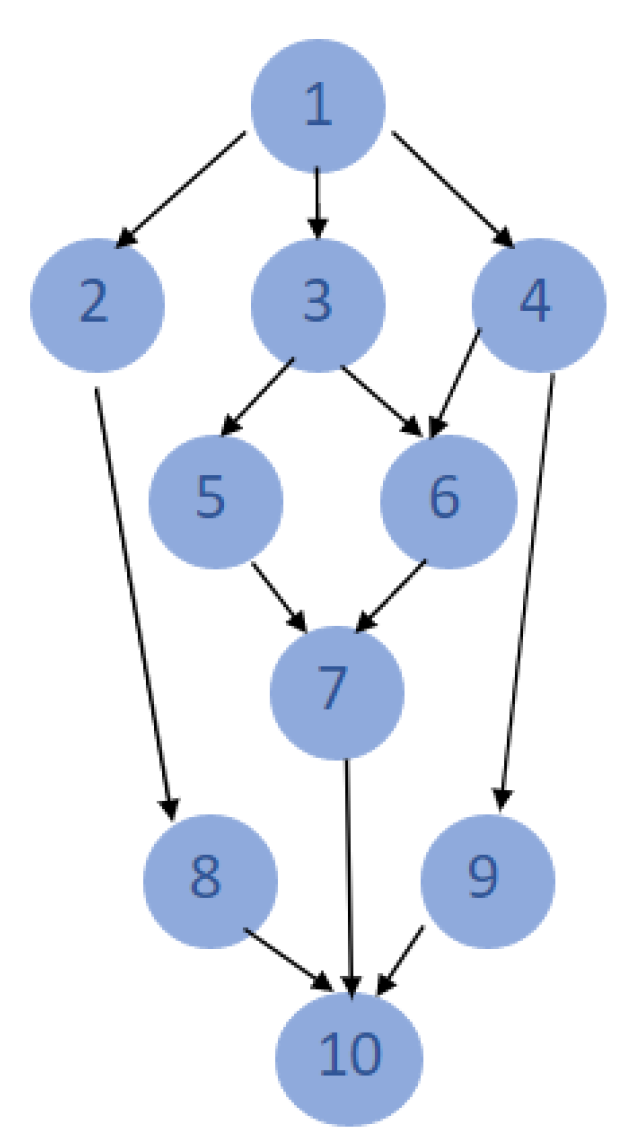
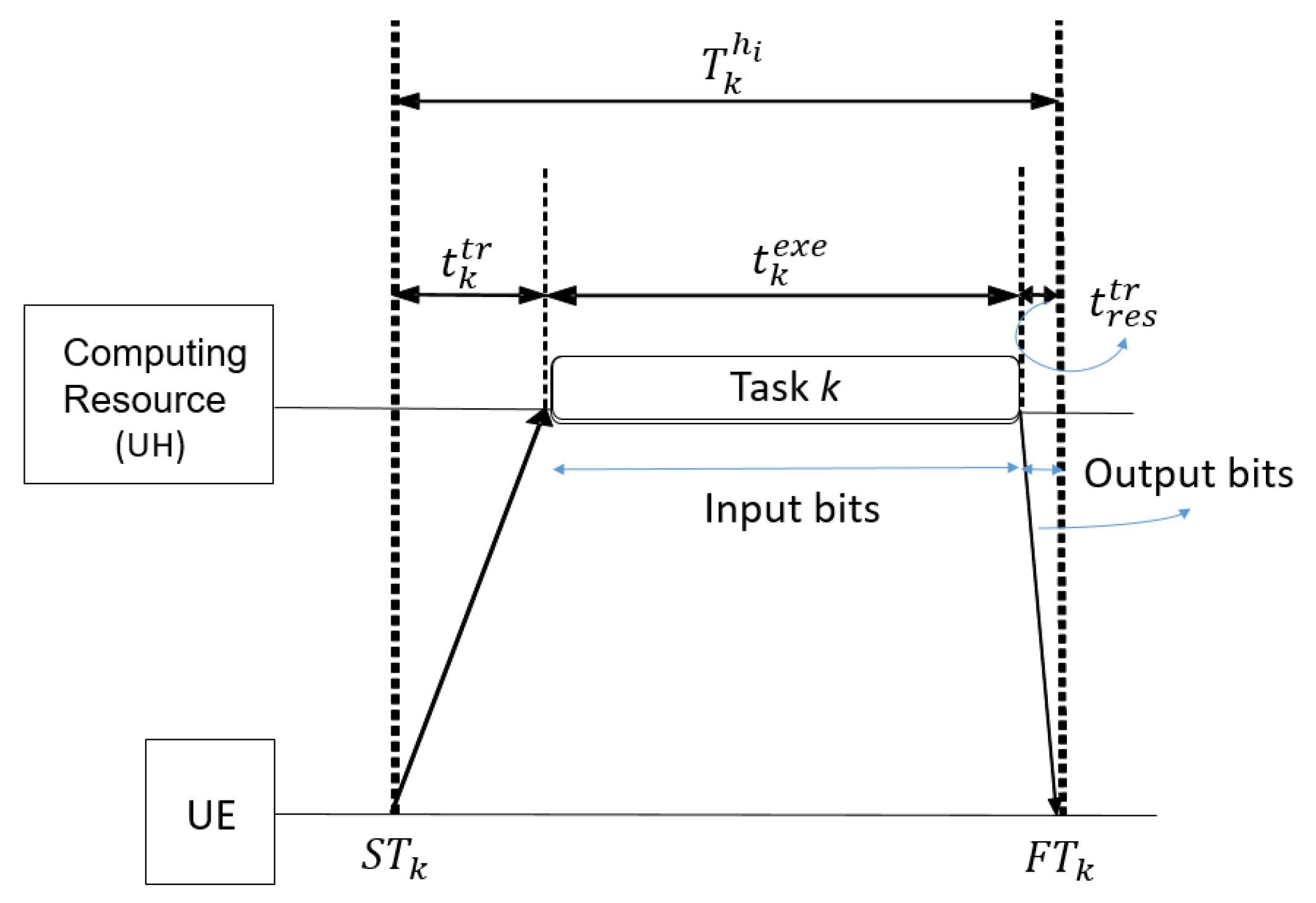
3.2. Task Model
- Finish time is the time instant of the execution completion of task k:whereby is the start time of task as defined next, and is the execution time (span) for task k.
- Start time is the time instant when the execution of task k can commence:whereby the set contains all predecessor tasks of task k. According to Equation (2), the execution of a task k without predecessors () can start immediately, while the start time of a task k that depends on predecessor tasks () equals the maximum finish time of the respective predecessor tasks .
3.3. Communication Model
3.4. Computation Model
3.4.1. Local Execution
3.4.2. Helper Execution
3.4.3. Server Execution
3.4.3.1. Direct Offloading from UE to MEC Server
3.4.3.2. Offloading from via Relay to MEC Server
3.5. Mobility Model
4. Dynamic Computation Offloading Problem Formulation
5. Solution of Dynamic Computation Offloading Optimization Problem
5.1. Conversion of into QCQP
5.2. Energy-Efficient Task Offloading (EETO) Algorithm
| Algorithm 1: Energy-Efficient Task Offloading (EETO) Algorithm |
 |
6. EETO Evaluation
6.1. Simulation Setup
6.2. Simulation Results
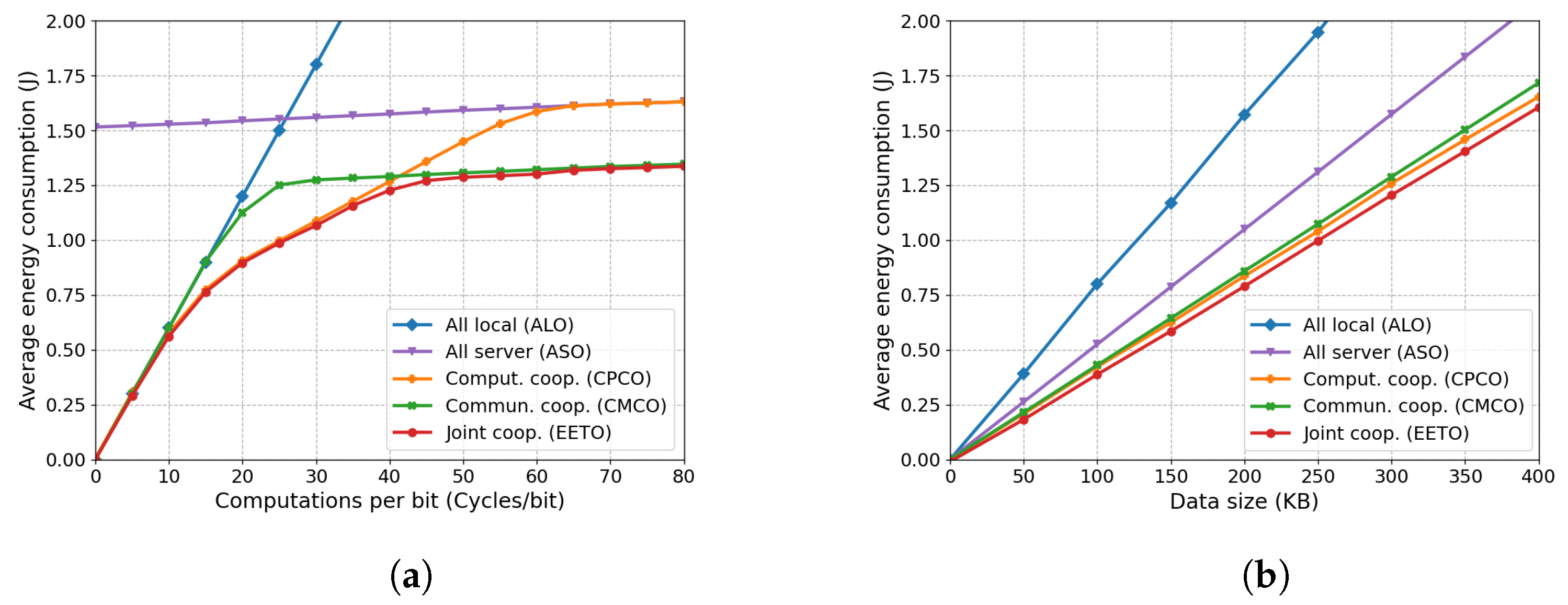
6.2.1. Impact of Task Complexity and Size
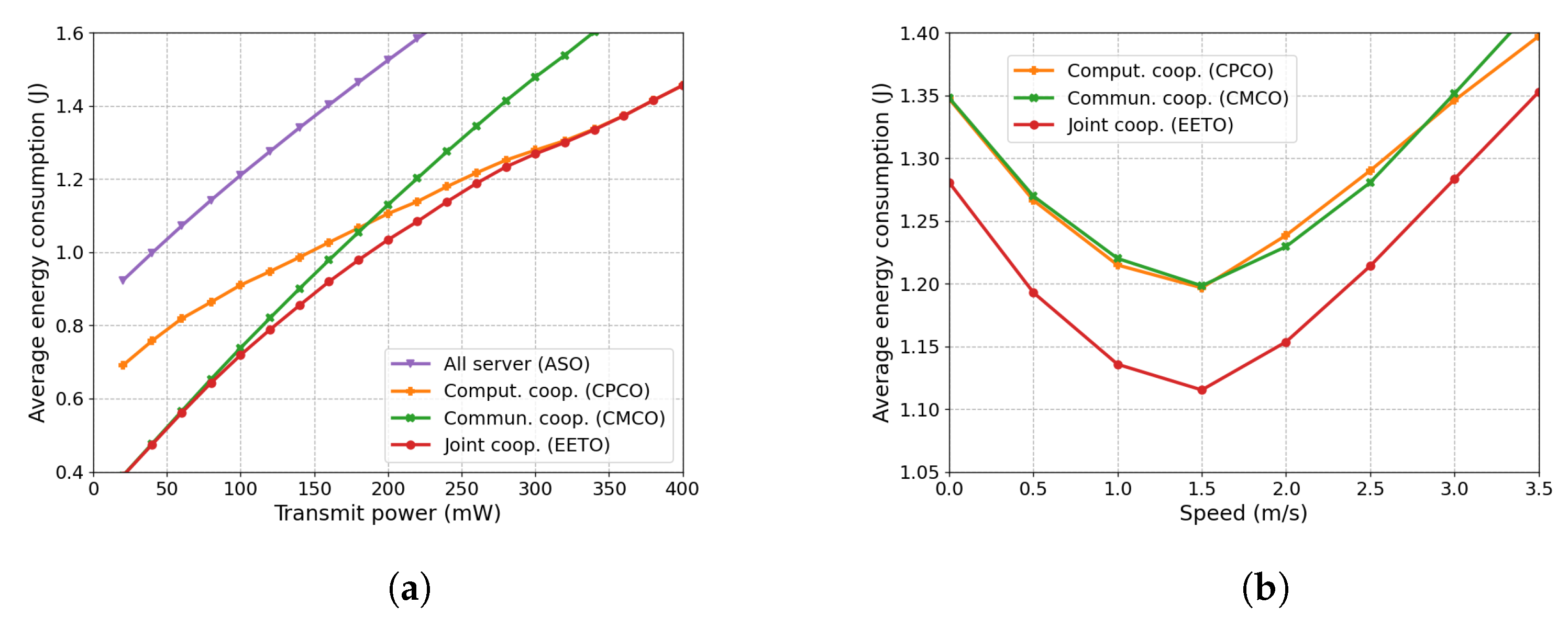
6.2.2. Impact of Transmission Power and UE Speed
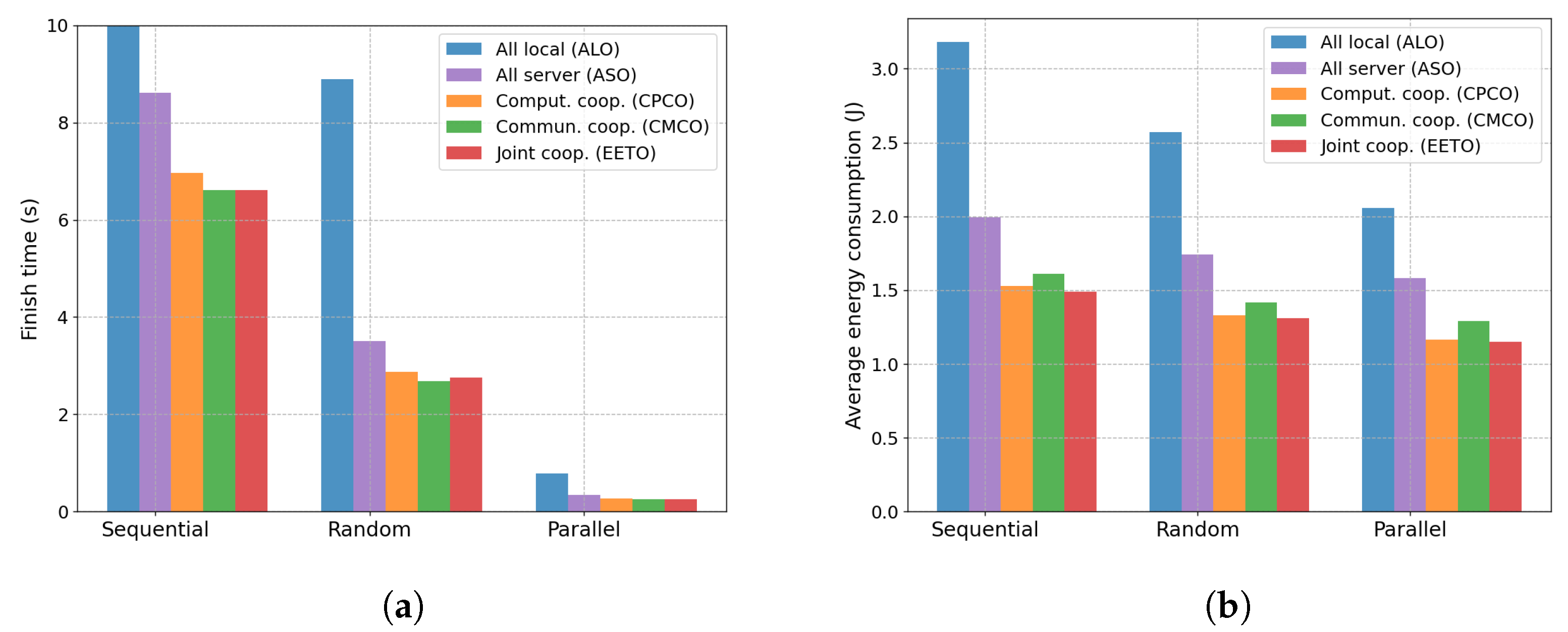
6.2.3. Impact of Task Dependency
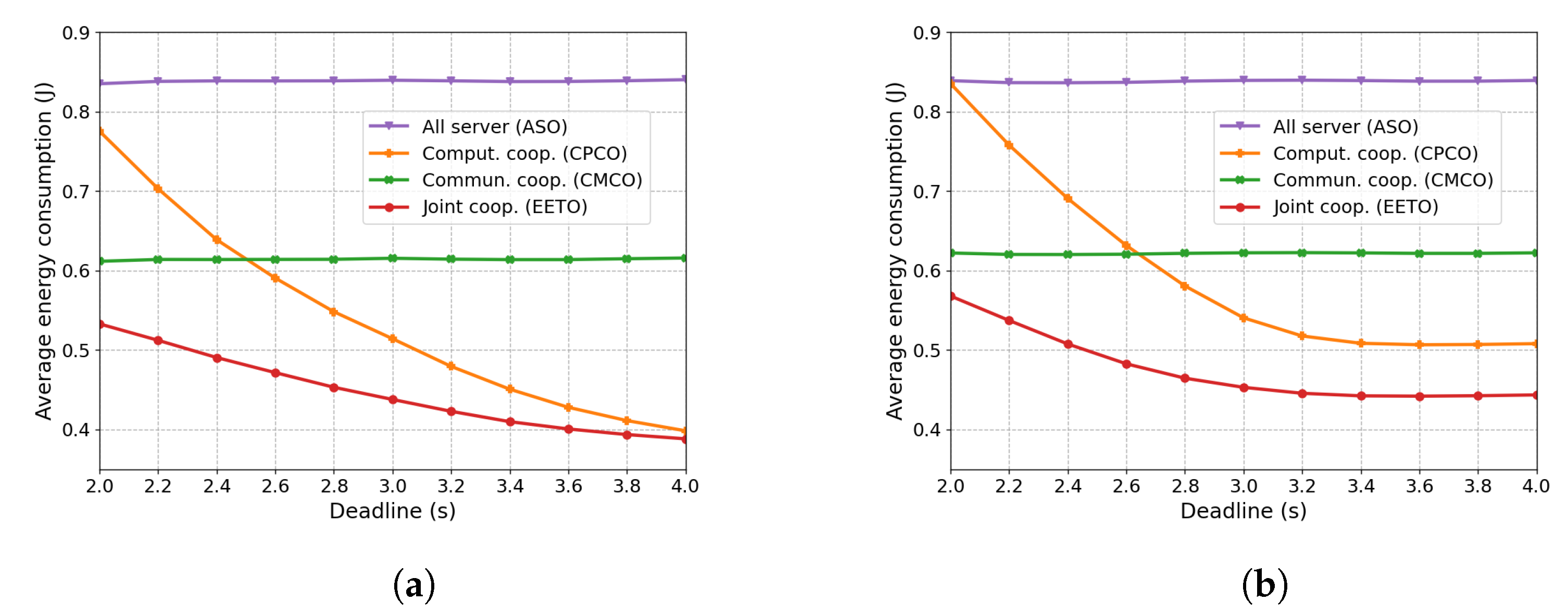
6.2.4. Impact of Task Deadline
7. Conclusions
7.1. Summary of This Article
7.2. Limitations and Future Research Directions
Author Contributions
Funding
Conflicts of Interest
References
- Fettweis, G.P. The tactile internet: Applications and challenges. IEEE Veh. Technol. Mag. 2014, 9, 64–70. [Google Scholar] [CrossRef]
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of things: A survey on enabling technologies, protocols, and applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Ateya, A.A.; Algarni, A.D.; Hamdi, M.; Koucheryavy, A.; Soliman, N.F. Enabling Heterogeneous IoT Networks over 5G Networks with Ultra-Dense Deployment—Using MEC/SDN. Electronics 2021, 10, 910. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, G.; Du, H.; Yuan, X.; Kadoch, M.; Cheriet, M. Real-Time Remote Health Monitoring System Driven by 5G MEC-IoT. Electronics 2020, 9, 1753. [Google Scholar] [CrossRef]
- Shariatmadari, H.; Ratasuk, R.; Iraji, S.; Laya, A.; Taleb, T.; Jäntti, R.; Ghosh, A. Machine-type communications: Current status and future perspectives toward 5G systems. IEEE Commun. Mag. 2015, 53, 10–17. [Google Scholar] [CrossRef] [Green Version]
- Ahvar, E.; Ahvar, S.; Raza, S.M.; Manuel Sanchez Vilchez, J.; Lee, G.M. Next Generation of SDN in Cloud-Fog for 5G and Beyond-Enabled Applications: Opportunities and Challenges. Network 2021, 1, 28–49. [Google Scholar] [CrossRef]
- Ruan, J.; Xie, D. Networked VR: State of the Art, Solutions, and Challenges. Electronics 2021, 10, 166. [Google Scholar] [CrossRef]
- Kang, K.D.; Chen, L.; Yi, H.; Wang, B.; Sha, M. Real-Time Information Derivation from Big Sensor Data via Edge Computing. Big Data Cogn. Comput. 2017, 1, 5. [Google Scholar] [CrossRef] [Green Version]
- Guan, S.; Boukerche, A. A Novel Mobility-aware Offloading Management Scheme in Sustainable Multi-access Edge Computing. IEEE Trans. Sustain. Comput. Print 2021. [Google Scholar] [CrossRef]
- Jin, Y.; Lee, H. On-Demand Computation Offloading Architecture in Fog Networks. Electronics 2019, 8, 1076. [Google Scholar] [CrossRef] [Green Version]
- Lan, Y.; Wang, X.; Wang, C.; Wang, D.; Li, Q. Collaborative Computation Offloading and Resource Allocation in Cache-Aided Hierarchical Edge-Cloud Systems. Electronics 2019, 8, 1430. [Google Scholar] [CrossRef] [Green Version]
- Ouyang, T.; Zhou, Z.; Chen, X. Follow Me at the Edge: Mobility-Aware Dynamic Service Placement for Mobile Edge Computing. IEEE J. Sel. Areas Commun. 2018, 36, 2333–2345. [Google Scholar] [CrossRef] [Green Version]
- Zhu, T.; Shi, T.; Li, J.; Cai, Z.; Zhou, X. Task scheduling in deadline-aware mobile edge computing systems. IEEE Internet Things J. 2018, 6, 4854–4866. [Google Scholar] [CrossRef]
- Hu, Y.C.; Patel, M.; Sabella, D.; Sprecher, N.; Young, V. Mobile edge computing—A key technology towards 5G. ETSI White Pap. 2015, 11, 1–16. [Google Scholar]
- Oliveira, A., Jr.; Cardoso, K.; Sousa, F.; Moreira, W. A Lightweight Slice-Based Quality of Service Manager for IoT. IoT 2020, 1, 49–75. [Google Scholar] [CrossRef]
- Nadeem, L.; Azam, M.A.; Amin, Y.; Al-Ghamdi, M.A.; Chai, K.K.; Khan, M.F.N.; Khan, M.A. Integration of D2D, Network Slicing, and MEC in 5G Cellular Networks: Survey and Challenges. IEEE Access 2021, 9, 37590–37612. [Google Scholar] [CrossRef]
- Bellavista, P.; Chessa, S.; Foschini, L.; Gioia, L.; Girolami, M. Human-enabled edge computing: Exploiting the crowd as a dynamic extension of mobile edge computing. IEEE Commun. Mag. 2018, 56, 145–155. [Google Scholar] [CrossRef] [Green Version]
- Mehrabi, M.; You, D.; Latzko, V.; Salah, H.; Reisslein, M.; Fitzek, F.H. Device-enhanced MEC: Multi-access edge computing (MEC) aided by end device computation and caching: A survey. IEEE Access 2019, 7, 166079–166108. [Google Scholar] [CrossRef]
- Ali, Z.; Khaf, S.; Abbas, Z.H.; Abbas, G.; Muhammad, F.; Kim, S. A Deep Learning Approach for Mobility-Aware and Energy-Efficient Resource Allocation in MEC. IEEE Access 2020, 8, 179530–179546. [Google Scholar] [CrossRef]
- Chen, S.; Zheng, Y.; Lu, W.; Varadarajan, V.; Wang, K. Energy-Optimal Dynamic Computation Offloading for Industrial IoT in Fog Computing. IEEE Trans. Green Commun. Netw. 2020, 4, 566–576. [Google Scholar] [CrossRef]
- Khan, P.W.; Abbas, K.; Shaiba, H.; Muthanna, A.; Abuarqoub, A.; Khayyat, M. Energy Efficient Computation Offloading Mechanism in Multi-Server Mobile Edge Computing—An Integer Linear Optimization Approach. Electronics 2020, 9, 1010. [Google Scholar] [CrossRef]
- Tang, L.; Hu, H. Computation Offloading and Resource Allocation for the Internet of Things in Energy-Constrained MEC-Enabled HetNets. IEEE Access 2020, 8, 47509–47521. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, W. Computation Offloading in Heterogeneous Mobile Edge Computing with Energy Harvesting. IEEE Trans. Green Commun. Netw. 2021, 5, 552–565. [Google Scholar] [CrossRef]
- Mehrabi, M.; Shen, S.; Latzko, V.; Wang, Y.; Fitzek, F. Energy-aware cooperative offloading framework for inter-dependent and delay-sensitive tasks. In Proceedings of the GLOBECOM 2020–2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Anajemba, J.H.; Yue, T.; Iwendi, C.; Alenezi, M.; Mittal, M. Optimal Cooperative Offloading Scheme for Energy Efficient Multi-Access Edge Computation. IEEE Access 2020, 8, 53931–53941. [Google Scholar] [CrossRef]
- Jia, Q.; Xie, R.; Tang, Q.; Li, X.; Huang, T.; Liu, J.; Liu, Y. Energy-efficient computation offloading in 5G cellular networks with edge computing and D2D communications. IET Commun. 2019, 13, 1122–1130. [Google Scholar] [CrossRef]
- Ouyang, W.; Chen, Z.; Wu, J.; Yu, G.; Zhang, H. Dynamic Task Migration Combining Energy Efficiency and Load Balancing Optimization in Three-Tier UAV-Enabled Mobile Edge Computing System. Electronics 2021, 10, 190. [Google Scholar] [CrossRef]
- Qiao, G.; Leng, S.; Zhang, Y. Online learning and optimization for computation offloading in D2D edge computing and networks. Mob. Netw. Appl. 2021. in print. [Google Scholar] [CrossRef]
- Cui, K.; Lin, B.; Sun, W.; Sun, W. Learning-Based Task Offloading for Marine Fog-Cloud Computing Networks of USV Cluster. Electronics 2019, 8, 1287. [Google Scholar] [CrossRef] [Green Version]
- Xing, H.; Liu, L.; Xu, J.; Nallanathan, A. Joint task assignment and resource allocation for D2D-enabled mobile-edge computing. IEEE Trans. Commun. 2019, 67, 4193–4207. [Google Scholar] [CrossRef] [Green Version]
- Ranji, R.; Mansoor, A.M.; Sani, A.A. EEDOS: An energy-efficient and delay-aware offloading scheme based on device to device collaboration in mobile edge computing. Telecommun. Syst. 2020, 73, 171–182. [Google Scholar] [CrossRef]
- Saleem, U.; Liu, Y.; Jangsher, S.; Tao, X.; Li, Y. Latency minimization for D2D-enabled partial computation offloading in mobile edge computing. IEEE Trans. Veh. Technol. 2020, 69, 4472–4486. [Google Scholar] [CrossRef]
- Sun, M.; Xu, X.; Tao, X.; Zhang, P. Large-scale user-assisted multi-task online offloading for latency reduction in D2D-enabled heterogeneous networks. IEEE Trans. Netw. Sci. Eng. 2020, 7, 2456–2467. [Google Scholar] [CrossRef]
- Yang, Y.; Long, C.; Wu, J.; Peng, S.; Li, B. D2D-Enabled Mobile-Edge Computation Offloading for Multi-user IoT Network. IEEE Internet Things J. 2021. in print. [Google Scholar]
- Fan, N.; Wang, X.; Wang, D.; Lan, Y.; Hou, J. A Collaborative Task Offloading Scheme in D2D-Assisted Fog Computing Networks. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Korea, 25–28 May 2020. [Google Scholar]
- Ko, H.; Pack, S. Distributed Device-to-Device Offloading System: Design and Performance Optimization. IEEE Trans. Mob. Comput. 2021. in print. [Google Scholar] [CrossRef]
- Shi, T.; Cai, Z.; Li, J.; Gao, H. CROSS: A crowdsourcing based sub-servers selection framework in D2D enhanced MEC architecture. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; pp. 1134–1144. [Google Scholar]
- Sun, M.; Xu, X.; Huang, Y.; Wu, Q.; Tao, X.; Zhang, P. Resource Management for Computation Offloading in D2D-Aided Wireless Powered Mobile-Edge Computing Networks. IEEE Internet Things J. 2021, 8, 8005–8020. [Google Scholar] [CrossRef]
- Tong, M.; Wang, X.; Wang, Y.; Lan, Y. Computation Offloading Scheme with D2D for MEC-enabled Cellular Networks. In Proceedings of the 2020 IEEE/CIC International Conference on Communications in China (ICCC Workshops), Xiamen, China, 28–30 July 2020; pp. 111–116. [Google Scholar]
- Wang, J.; Wu, W.; Liao, Z.; Jung, Y.W.; Kim, J.U. An Enhanced PROMOT Algorithm with D2D and Robust for Mobile Edge Computing. J. Internet Technol. 2020, 21, 1437–1445. [Google Scholar]
- Wan, L. Computation Offloading Strategy Based on Improved Auction Model in Mobile Edge Computing Network. J. Phys. Conf. Ser. 2021, 1852, 042047. [Google Scholar] [CrossRef]
- Zhang, X. Enhancing mobile cloud with social-aware device-to-device offloading. Comput. Commun. 2021, 168, 1–11. [Google Scholar] [CrossRef]
- Chen, X.; Zhou, Z.; Wu, W.; Wu, D.; Zhang, J. Socially-motivated cooperative mobile edge computing. IEEE Netw. 2018, 32, 177–183. [Google Scholar] [CrossRef]
- Li, Z.; Hu, H.; Hu, H.; Huang, B.; Ge, J.; Chang, V. Security and Energy-aware Collaborative Task Offloading in D2D communication. Future Gener. Comput. Syst. 2021, 118, 358–373. [Google Scholar] [CrossRef]
- Baek, H.; Ko, H.; Pack, S. Privacy-Preserving and Trustworthy Device-to-Device (D2D) Offloading Scheme. IEEE Access 2020, 8, 191551–191560. [Google Scholar] [CrossRef]
- Zhang, Y.; Qin, X.; Song, X. Mobility-Aware Cooperative Task Offloading and Resource Allocation in Vehicular Edge Computing. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), Seoul, Korea, 25–28 May 2020. [Google Scholar]
- Zhu, C.; Tao, J.; Pastor, G.; Xiao, Y.; Ji, Y.; Zhou, Q.; Li, Y.; Ylä-Jääski, A. Folo: Latency and Quality Optimized Task Allocation in Vehicular Fog Computing. IEEE Internet Things J. 2019, 6, 4150–4161. [Google Scholar] [CrossRef] [Green Version]
- Misra, S.; Bera, S. Soft-VAN: Mobility-Aware Task Offloading in Software-Defined Vehicular Network. IEEE Trans. Veh. Technol. 2020, 69, 2071–2078. [Google Scholar] [CrossRef]
- Selim, M.M.; Rihan, M.; Yang, Y.; Ma, J. Optimal task partitioning, Bit allocation and trajectory for D2D-assisted UAV-MEC systems. Peer-Netw. Appl. 2021, 14, 215–224. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Z.Y.; Min, L.; Tang, C.; Zhang, H.Y.; Wang, Y.H.; Cai, P. Task Offloading and Trajectory Control for UAV-Assisted Mobile Edge Computing Using Deep Reinforcement Learning. IEEE Access 2021, 9, 53708–53719. [Google Scholar] [CrossRef]
- Wu, C.; Peng, Q.; Xia, Y.; Lee, J. Mobility-Aware Tasks Offloading in Mobile Edge Computing Environment. In Proceedings of the 2019 Seventh International Symposium on Computing and Networking (CANDAR), Nagasaki, Japan, 26–29 November 2019; pp. 204–210. [Google Scholar]
- Jeon, Y.; Baek, H.; Pack, S. Mobility-Aware Optimal Task Offloading in Distributed Edge Computing. In Proceedings of the 2021 International Conference on Information Networking (ICOIN), Bangkok, Thailand, 12–15 January 2021; pp. 65–68. [Google Scholar]
- Wang, D.; Liu, Z.; Wang, X.; Lan, Y. Mobility-Aware Task Offloading and Migration Schemes in Fog Computing Networks. IEEE Access 2019, 7, 43356–43368. [Google Scholar] [CrossRef]
- Saleem, U.; Liu, Y.; Jangsher, S.; Li, Y.; Jiang, T. Mobility-Aware Joint Task Scheduling and Resource Allocation for Cooperative Mobile Edge Computing. IEEE Trans. Wirel. Commun. 2021, 20, 360–374. [Google Scholar] [CrossRef]
- Feng, Z.; Zhu, Y. A survey on trajectory data mining: Techniques and applications. IEEE Access 2016, 4, 2056–2067. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, Z.; Min, G.; Huang, X.; Ni, Q.; Wang, R. User mobility aware task assignment for mobile edge computing. Future Gener. Comput. Syst. 2018, 85, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Liu, F.; Huang, Z.; Wang, L. Energy-efficient collaborative task computation offloading in cloud-assisted edge computing for IoT sensors. Sensors 2019, 19, 1105. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Eldarrat, F.; Alqahtani, H.; Reznik, A.; De Foy, X.; Zhang, Y. Mobile edge cloud system: Architectures, challenges, and approaches. IEEE Syst. J. 2017, 12, 2495–2508. [Google Scholar] [CrossRef]
- Sarmiento, D.E.; Lebre, A.; Nussbaum, L.; Chari, A. Decentralized SDN Control Plane for a Distributed Cloud-Edge Infrastructure: A Survey. IEEE Commun. Surv. Tutor. 2021, 23, 256–281. [Google Scholar] [CrossRef]
- Mahmoodi, S.E.; Uma, R.; Subbalakshmi, K. Optimal joint scheduling and cloud offloading for mobile applications. IEEE Trans. Cloud Comput. 2019, 7, 301–313. [Google Scholar] [CrossRef]
- Hao, W.; Yang, S. Small cell cluster-based resource allocation for wireless backhaul in two-tier heterogeneous networks with massive MIMO. IEEE Trans. Veh. Technol. 2017, 67, 509–523. [Google Scholar] [CrossRef]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.L. Limits of predictability in human mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef] [Green Version]
- Mangalam, K.; Girase, H.; Agarwal, S.; Lee, K.H.; Adeli, E.; Malik, J.; Gaidon, A. It is not the journey but the destination: Endpoint conditioned trajectory prediction. In European Conference on Computer Vision; Lecture Notes in Computer Science; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Cham, Switzerland, 2020; Volume 12347, pp. 759–776. [Google Scholar]
- Karp, R.M. Reducibility among combinatorial problems. In Complexity of Computer Computations; Springer: Berlin/Heidelberg, Germany, 1972; pp. 85–103. [Google Scholar]
- O’Donoghue, B.; Chu, E.; Parikh, N.; Boyd, S. Conic optimization via operator splitting and homogeneous self-dual embedding. J. Optim. Theory Appl. 2016, 169, 1042–1068. [Google Scholar] [CrossRef] [Green Version]
- Deng, L.; Li, G.; Han, S.; Shi, L.; Xie, Y. Model compression and hardware acceleration for neural networks: A comprehensive survey. Proc. IEEE 2020, 108, 485–532. [Google Scholar] [CrossRef]
- Shantharama, P.; Thyagaturu, A.S.; Reisslein, M. Hardware-accelerated platforms and infrastructures for network functions: A survey of enabling technologies and research studies. IEEE Access 2020, 8, 132021–132085. [Google Scholar] [CrossRef]
- Liu, C.; Jiang, H.; Paparrizos, J.; Elmore, A.J. Decomposed bounded floats for fast compression and queries. Proc. VLDB Endow. 2021, 14, 2586–2598. [Google Scholar]
- Paparrizos, J.; Liu, C.; Barbarioli, B.; Hwang, J.; Edian, I.; Elmore, A.J.; Franklin, M.J.; Krishnan, S. VergeDB: A database for IoT analytics on edge devices. In Proceedings of the 11th Annual Conference on Innovative Data Systems Research (CIDR ‘21), Chaminade, CA, USA, 10–13 January 2021; pp. 1–8. [Google Scholar]
- Happ, D.; Bayhan, S.; Handziski, V. JOI: Joint placement of IoT analytics operators and pub/sub message brokers in fog-centric IoT platforms. Future Gener. Comput. Syst. 2021, 119, 7–19. [Google Scholar] [CrossRef]
- Marah, B.D.; Jing, Z.; Ma, T.; Alsabri, R.; Anaadumba, R.; Al-Dhelaan, A.; Al-Dhelaan, M. Smartphone architecture for edge-centric IoT analytics. Sensors 2020, 20, 892. [Google Scholar] [CrossRef] [Green Version]
- Deng, Y.; Han, T.; Ansari, N. FedVision: Federated video analytics with edge computing. IEEE Open J. Comput. Soc. 2020, 1, 62–72. [Google Scholar] [CrossRef]
- Ali, M.; Anjum, A.; Rana, O.; Zamani, A.R.; Balouek-Thomert, D.; Parashar, M. RES: Real-time video stream analytics using edge enhanced clouds. IEEE Trans. Cloud Comput. 2021. in print. [Google Scholar] [CrossRef]
- Rocha Neto, A.; Silva, T.P.; Batista, T.; Delicato, F.C.; Pires, P.F.; Lopes, F. Leveraging edge intelligence for video analytics in smart city applications. Information 2021, 12, 14. [Google Scholar] [CrossRef]
- Krishnan, S.; Elmore, A.J.; Franklin, M.; Paparrizos, J.; Shang, Z.; Dziedzic, A.; Liu, R. Artificial intelligence in resource-constrained and shared environments. ACM SIGOPS Oper. Syst. Rev. 2019, 53, 1–6. [Google Scholar] [CrossRef]
- Paparrizos, J.; Franklin, M.J. GRAIL: Efficient time-series representation learning. Proc. VLDB Endow. 2019, 12, 1762–1777. [Google Scholar] [CrossRef]
- Alshahrani, A.; Elgendy, I.A.; Muthanna, A.; Alghamdi, A.M.; Alshamrani, A. Efficient multi-player computation offloading for VR edge-cloud computing systems. Appl. Sci. 2020, 10, 5515. [Google Scholar] [CrossRef]
- Ameur, A.B.; Araldo, A.; Bronzino, F. On the deployability of augmented reality using embedded edge devices. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; pp. 1–6. [Google Scholar]
- Braud, T.; Zhou, P.; Kangasharju, J.; Hui, P. Multipath computation offloading for mobile augmented reality. In Proceedings of the 2020 IEEE International Conference on Pervasive Computing and Communications (PerCom), Austin, TX, USA, 23–27 March 2020; pp. 1–10. [Google Scholar]
- Chen, M.; Liu, W.; Wang, T.; Liu, A.; Zeng, Z. Edge intelligence computing for mobile augmented reality with deep reinforcement learning approach. Comput. Netw. 2021, 195, 108186. [Google Scholar] [CrossRef]
- Ren, P.; Qiao, X.; Huang, Y.; Liu, L.; Dustdar, S.; Chen, J. Edge-assisted distributed DNN collaborative computing approach for mobile web augmented reality in 5G networks. IEEE Netw. 2020, 34, 254–261. [Google Scholar] [CrossRef]
- Vidal-Balea, A.; Blanco-Novoa, O.; Picallo-Guembe, I.; Celaya-Echarri, M.; Fraga-Lamas, P.; Lopez-Iturri, P.; Azpilicueta, L.; Falcone, F.; Fernández-Caramés, T.M. Analysis, design and practical validation of an augmented reality teaching system based on microsoft HoloLens 2 and edge computing. Eng. Proc. 2020, 2, 52. [Google Scholar]
- Yang, X.; Luo, H.; Sun, Y.; Obaidat, M.S. Energy-efficient collaborative offloading for multiplayer games with cache-aided MEC. In Proceedings of the ICC 2020-2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–7. [Google Scholar]
- Rodriguez, J.; Radwan, A.; Barbosa, C.; Fitzek, F.H.P.; Abd-Alhameed, R.A.; Noras, J.M.; Jones, S.M.R.; Politis, I.; Galiotos, P.; Schulte, G.; et al. SECRET–Secure network coding for reduced energy next generation mobile small cells: A European Training Network in wireless communications and networking for 5G. In Proceedings of the 2017 Internet Technologies and Applications (ITA), Wrexham, UK, 12–15 September 2017; pp. 329–333. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| Set of helper/relay nodes UH; total # of helpers/relays | |
| Set of MEC servers ; total # of MEC servers | |
| Set of computation tasks; total # of tasks | |
| Data size [in bits] of task k; 200–400 KB (unif. random) | |
| Required computation per bit of task k; 30–50 cycles/bit (unif. random) | |
| Deadline for execution of set of K tasks; s | |
| B | Bandwidth of wireless channel; MHz |
| Wireless channel gain; for UE to UH, and for UH to server; | |
| for UE to server | |
| Transmission power for task k; W | |
| UE’s idle circuit power; W | |
| UE CPU cycle frequency allocated to task k; cycles/s | |
| CPU cycle frequency of helper node i; cycles/s | |
| CPU cycle frequency of MEC server m; cycles/s | |
| Set of helper node selection variables | |
| Set of MEC server selection variables | |
| Set of relays and MEC server selection variables | |
| , | Position of UE, helper/relay UH at time t |
| , | Coverage area radius of helper UH, server |
| UE sojourn time in coverage of helper node UH | |
| L | # of iterations of stochastic mapping in EETO alg.; |
| Comput. Cycles Per Bit | Finish Time of Last Task (s) | Data Size in KB | Finish Time of Last Task (s) |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 5 | 1.2155 | 50 | 1.6038 |
| 10 | 2.4201 | 100 | 3.248 |
| 15 | 3.6314 | 150 | 5.1438 |
| 20 | 4.8343 | 200 | 6.1856 |
| 25 | 6.0631 | 250 | 8.256 |
| 30 | 7.2743 | 300 | 9.9504 |
| 35 | 8.4917 | 350 | 11.5976 |
| 40 | 9.6840 | 400 | 12.9008 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mehrabi, M.; Shen, S.; Hai, Y.; Latzko, V.; Koudouridis, G.P.; Gelabert, X.; Reisslein, M.; Fitzek, F.H.P. Mobility- and Energy-Aware Cooperative Edge Offloading for Dependent Computation Tasks. Network 2021, 1, 191-214. https://doi.org/10.3390/network1020012
Mehrabi M, Shen S, Hai Y, Latzko V, Koudouridis GP, Gelabert X, Reisslein M, Fitzek FHP. Mobility- and Energy-Aware Cooperative Edge Offloading for Dependent Computation Tasks. Network. 2021; 1(2):191-214. https://doi.org/10.3390/network1020012
Chicago/Turabian StyleMehrabi, Mahshid, Shiwei Shen, Yilun Hai, Vincent Latzko, George P. Koudouridis, Xavier Gelabert, Martin Reisslein, and Frank H. P. Fitzek. 2021. "Mobility- and Energy-Aware Cooperative Edge Offloading for Dependent Computation Tasks" Network 1, no. 2: 191-214. https://doi.org/10.3390/network1020012
APA StyleMehrabi, M., Shen, S., Hai, Y., Latzko, V., Koudouridis, G. P., Gelabert, X., Reisslein, M., & Fitzek, F. H. P. (2021). Mobility- and Energy-Aware Cooperative Edge Offloading for Dependent Computation Tasks. Network, 1(2), 191-214. https://doi.org/10.3390/network1020012