
COVID-19 Host GenomeDB: A Comprehensive Database Related to COVID-19 Host Genetics




Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Acquisition
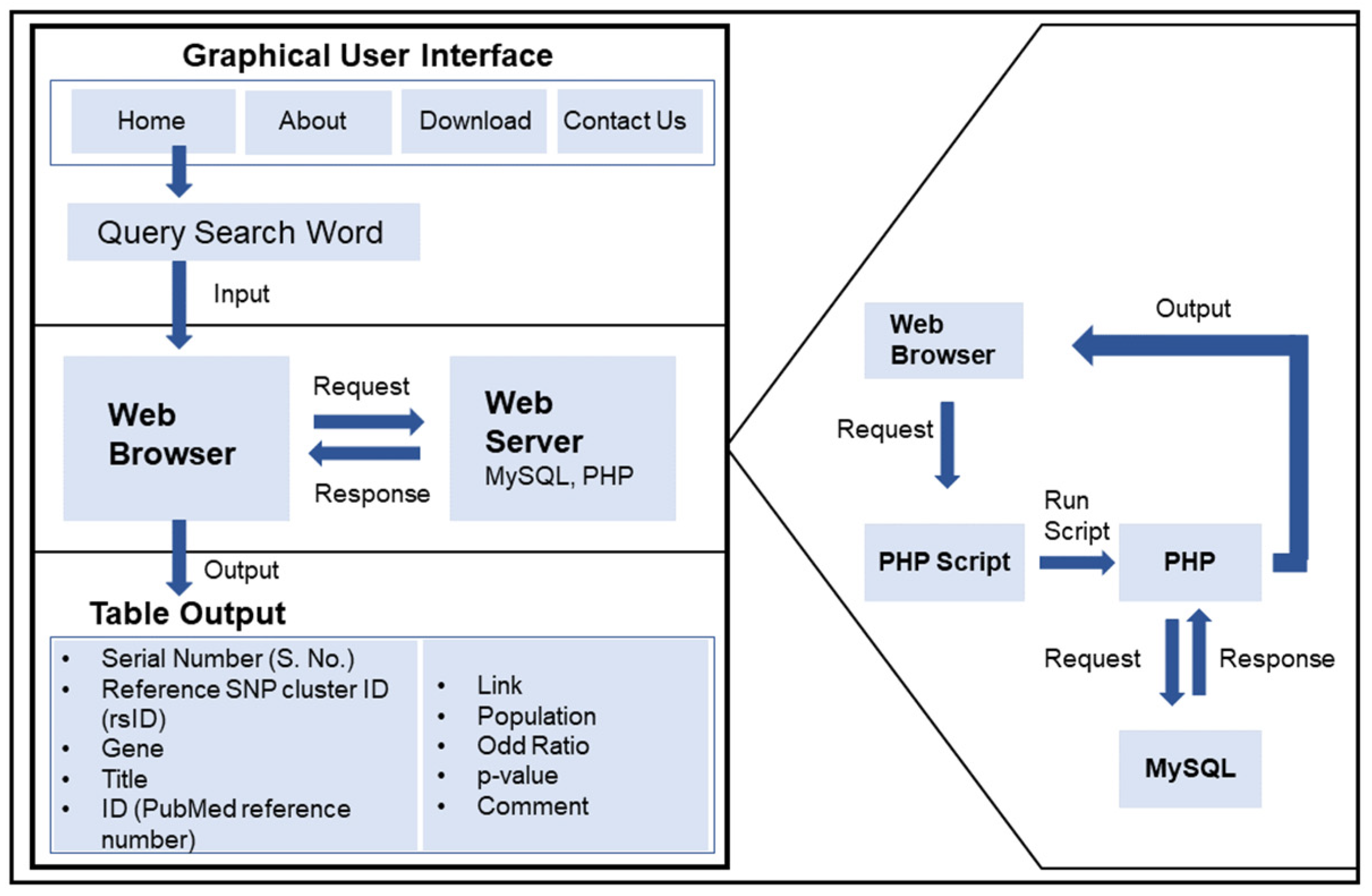
2.2. Database Structure
2.3. Search Methodology
3. Results
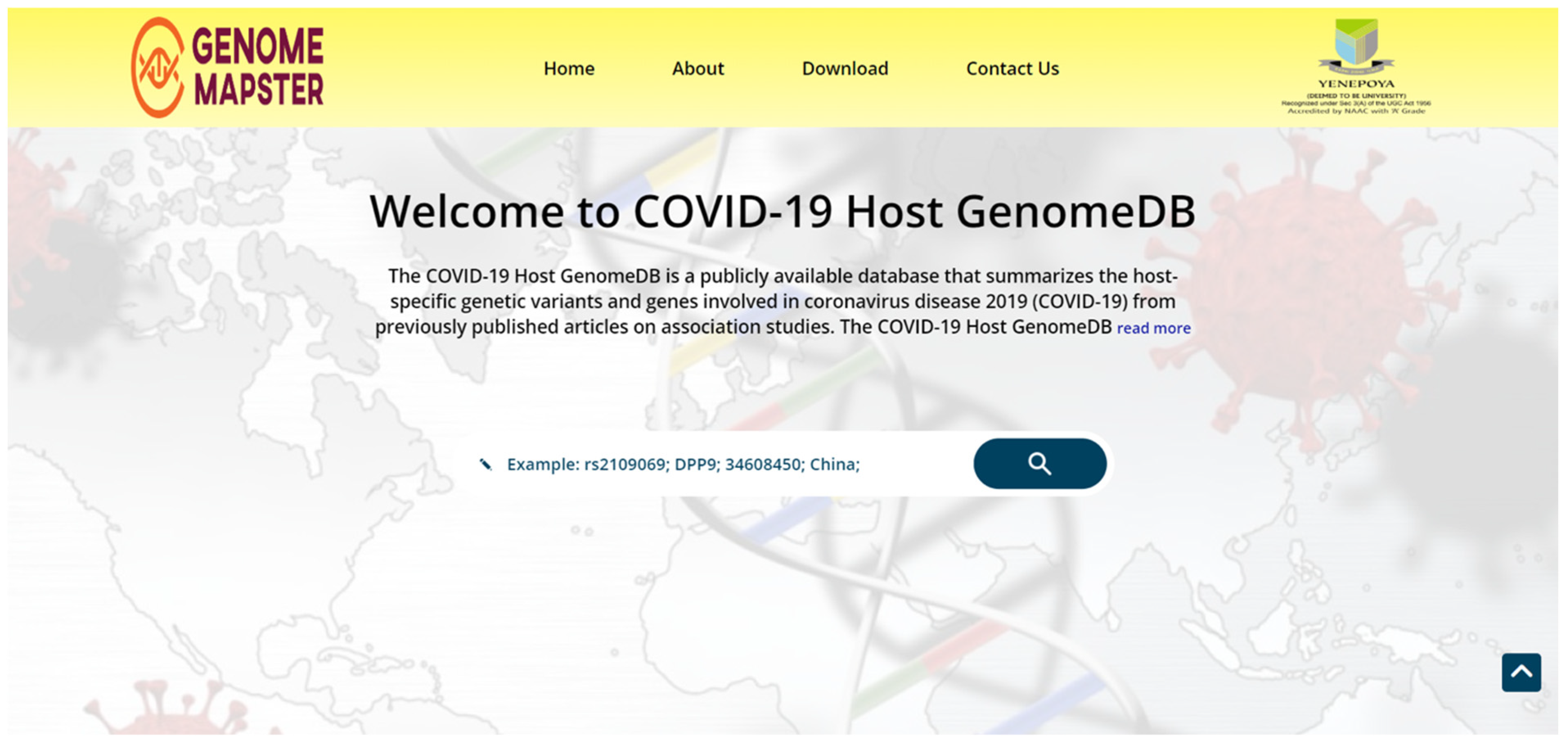
3.1. User Interface
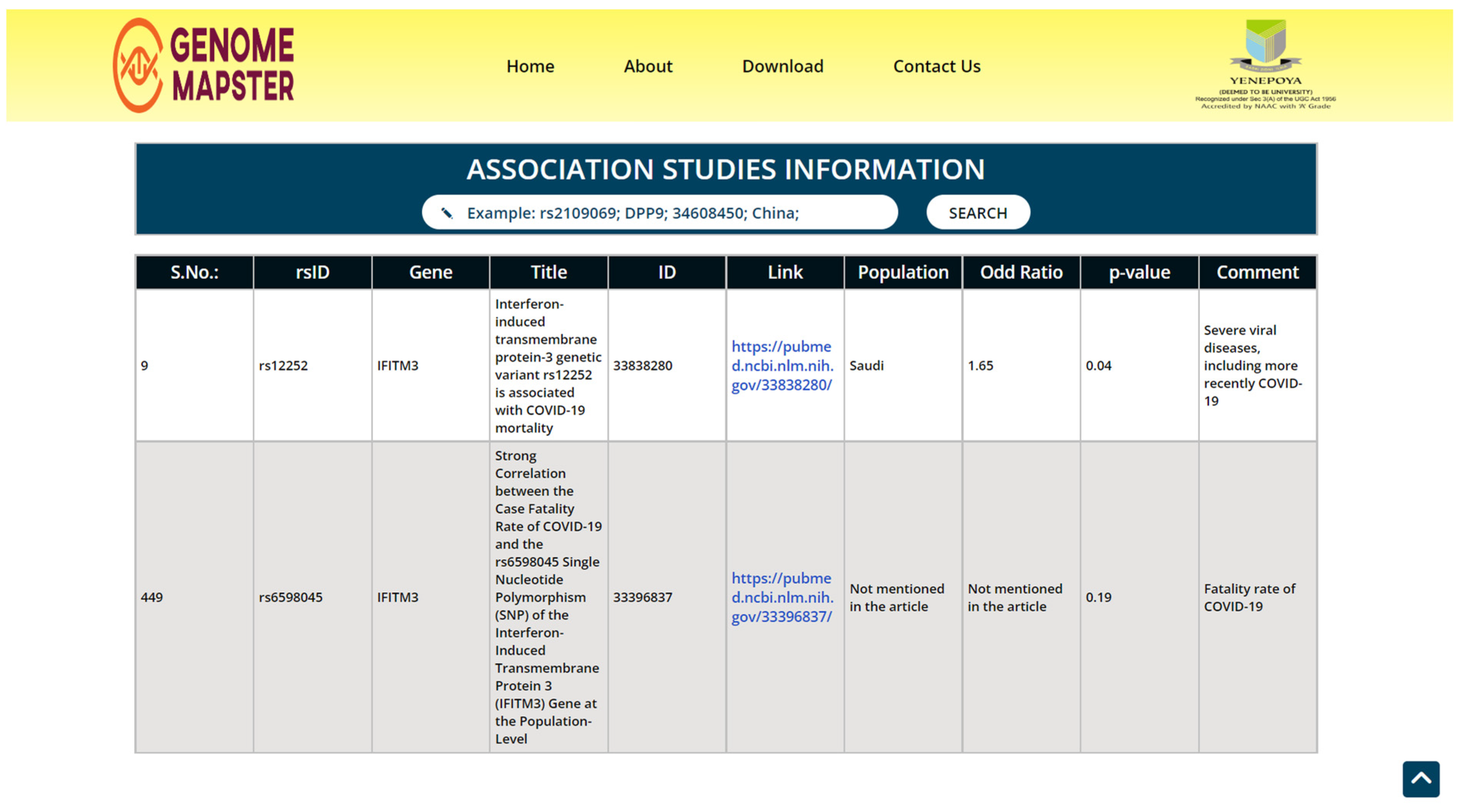
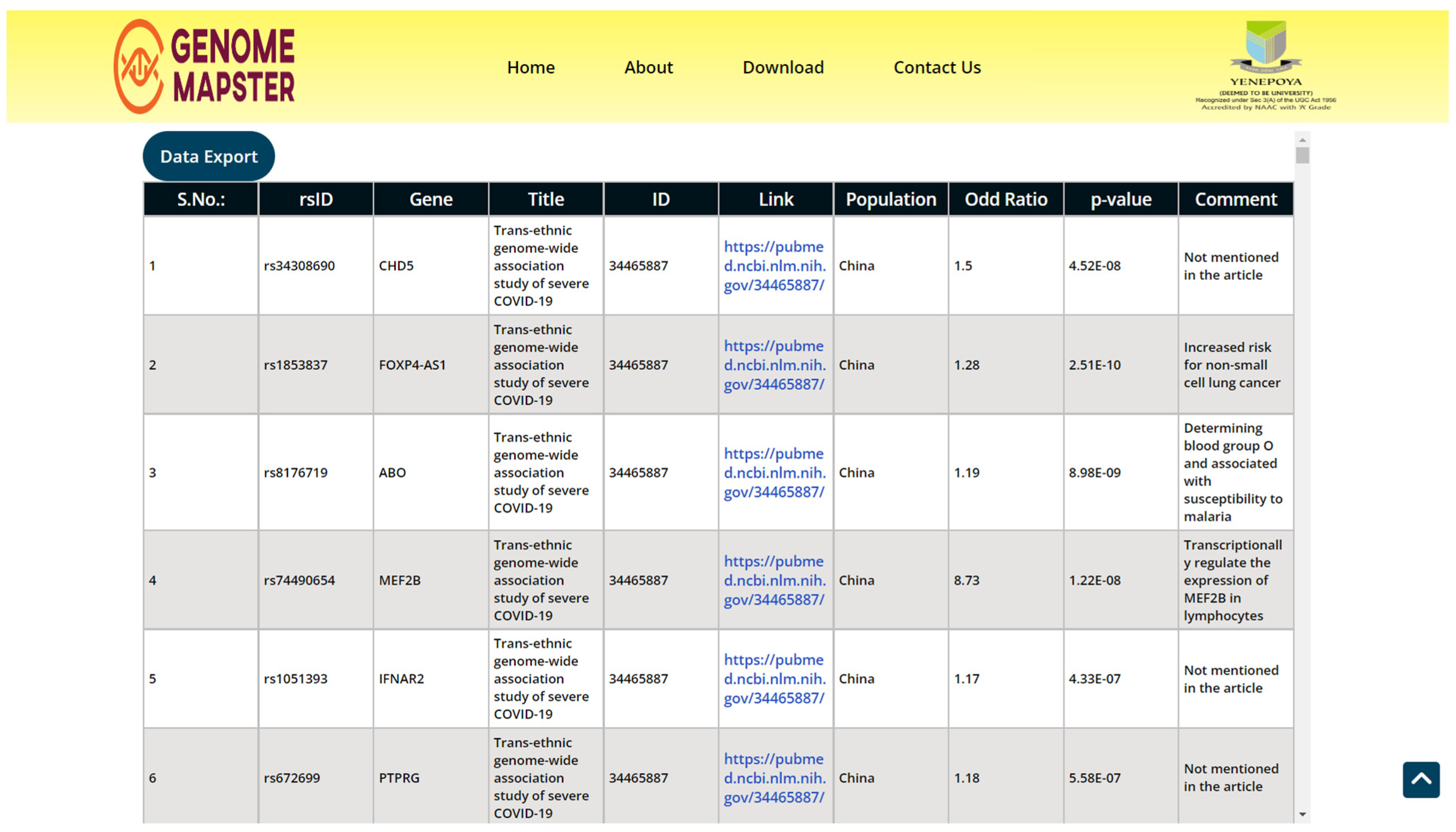
3.2. Output Information
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Beck, T.; Shorter, T.; Brookes, A.J. GWAS Central: A comprehensive resource for the discovery and comparison of genotype and phenotype data from genome-wide association studies. Nucleic Acids Res. 2020, 48, D933–D940. [Google Scholar] [CrossRef] [PubMed]
- Buniello, A.; MacArthur, J.; Cerezo, M.; Harris, L.W.; Hayhurst, J.; Malangone, C.; McMahon, A.; Morales, J.; Mountjoy, E.; Sollis, E.; et al. The NHGRI-EBI GWAS Catalog of published genome-wide association studies, targeted arrays and summary statistics 2019. Nucleic Acids Res. 2019, 47, D1005–D1012. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- MacArthur, J.; Bowler, E.; Cerezo, M.; Gil, L.; Hall, P.; Hastings, E.; Junkins, H.; McMahon, A.; Milano, A.; Morales, J.; et al. The new NHGRI-EBI Catalog of published genome-wide association studies (GWAS Catalog). Nucleic Acids Res. 2017, 45, D896–D901. [Google Scholar] [CrossRef] [PubMed]
- Ramos, E.M.; Hoffman, D.; Junkins, H.A.; Maglott, D.; Phan, L.; Sherry, S.T.; Feolo, M.; Hindorff, L.A. Phenotype-Genotype Integrator (PheGenI): Synthesizing genome-wide association study (GWAS) data with existing genomic resources. Eur. J. Hum. Genet. 2014, 22, 144–147. [Google Scholar] [CrossRef]
- Abel, O.; Powell, J.F.; Andersen, P.M.; Al-Chalabi, A. ALSoD: A user-friendly online bioinformatics tool for amyotrophic lateral sclerosis genetics. Hum. Mutat. 2012, 33, 1345–1351. [Google Scholar] [CrossRef] [PubMed]
- Yuan, J.; Chen, F.; Fan, D.; Jiang, Q.; Xue, Z.; Zhang, J.; Yu, X.; Li, K.; Qu, J.; Su, J. EyeDiseases: An integrated resource for dedicating to genetic variants, gene expression and epigenetic factors of human eye diseases. NAR Genom. Bioinform. 2021, 3, lqab050. [Google Scholar] [CrossRef] [PubMed]
- Lim, J.E.; Hong, K.W.; Jin, H.S.; Kim, Y.S.; Park, H.K.; Oh, B. Type 2 diabetes genetic association database manually curated for the study design and odds ratio. BMC Med. Inform. Decis. Mak. 2010, 10, 76. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Manjunath, M.; Zhang, Y.; Zhang, S.; Roy, S.; Perez-Pinera, P.; Song, J.S. ABC-GWAS: Functional Annotation of Estrogen Receptor-Positive Breast Cancer Genetic Variants. Front. Genet. 2020, 11, 730. [Google Scholar] [CrossRef] [PubMed]
- Tan, N.C.; Berkovic, S.F. The Epilepsy Genetic Association Database (epiGAD): Analysis of 165 genetic association studies, 1996–2008. Epilepsia 2010, 51, 686–689. [Google Scholar] [CrossRef] [PubMed]
- Greenfest-Allen, E.; Klamann, C.; Gangadharan, P.; Kuzma, A.; Leung, Y.Y.; Valladares, O.; Schellenberg, G.; Stoeckert, C.J.; Wang, L.S. NIAGADS Alzheimer’s GenomicsDB: A resource for exploring Alzheimer’s Disease genetic and genomic knowledge. bioRxiv 2021, 2020-09. [Google Scholar] [CrossRef]
- Grenn, F.P.; Kim, J.J.; Makarious, M.B.; Iwaki, H.; Illarionova, A.; Brolin, K.; Kluss, J.H.; Schumacher-Schuh, A.F.; Leonard, H.; Faghri, F.; et al. The Parkinson’s Disease Genome-Wide Association Study Locus Browser. Mov. Disord. 2020, 35, 2056–2067. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S.No. | Database | Disease-Specific (Yes/No) | Disease | Web Address |
|---|---|---|---|---|
| 1 | GWAS Central | No | All | https://www.gwascentral.org/ (accessed on 14 July 2022) |
| 2 | GWAS Catalog | No | All | https://www.ebi.ac.uk/gwas/ (accessed on 14 July 2022) |
| 3 | PhenGenI (Phenotype-Genotype Integrator) | No | All | https://www.ncbi.nlm.nih.gov/gap/phegeni (accessed on 14 July 2022) |
| 4 | ALSoD (Amyotrophic Lateral Sclerosis online Database) | Yes | Amyotrophic Lateral Sclerosis (ALS) | https://alsod.ac.uk/ (accessed on 14 July 2022) |
| 5 | EyeDiseases | Yes | Eye | https://eyediseases.bio-data.cn/ (accessed on 14 July 2022) |
| 6 | T2DGADB (Type 2 diabetes genetic association database) | Yes | Type 2 Diabetes | http://allie.dbcls.jp/pair/T2DGADB;type+2+diabetes+genetic+association+database.html (accessed on 14 July 2022) |
| 7 | ABC-GWAS (Analysis of Breast Cancer GWAS) | Yes | Breast Cancer | http://education.knoweng.org/abc-gwas/ (accessed on 14 July 2022) |
| 8 | epiGAD (Epilepsy Genetic Association Database) | Yes | Epilepsy | https://www.epigad.org/ (accessed on 14 July 2022) |
| 9 | GenomicsDB | Yes | Alzheimer’s Disease | https://www.niagads.org/genomics/ (accessed on 14 July 2022) |
| 10 | PD GWAS (Parkinson’s disease genome-wide association study) locus browser | Yes | Parkinson’s Disease | https://pdgenetics.shinyapps.io/GWASBrowser/ (accessed on 14 July 2022) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banjan, B.; Albeshr, M.F.; Mahboob, S.; Manzoor, I.; Das, R. COVID-19 Host GenomeDB: A Comprehensive Database Related to COVID-19 Host Genetics. Int. J. Transl. Med. 2022, 2, 355-363. https://doi.org/10.3390/ijtm2030028
Banjan B, Albeshr MF, Mahboob S, Manzoor I, Das R. COVID-19 Host GenomeDB: A Comprehensive Database Related to COVID-19 Host Genetics. International Journal of Translational Medicine. 2022; 2(3):355-363. https://doi.org/10.3390/ijtm2030028
Chicago/Turabian StyleBanjan, Bhavya, Mohammed F. Albeshr, Shahid Mahboob, Irfan Manzoor, and Ranajit Das. 2022. "COVID-19 Host GenomeDB: A Comprehensive Database Related to COVID-19 Host Genetics" International Journal of Translational Medicine 2, no. 3: 355-363. https://doi.org/10.3390/ijtm2030028
APA StyleBanjan, B., Albeshr, M. F., Mahboob, S., Manzoor, I., & Das, R. (2022). COVID-19 Host GenomeDB: A Comprehensive Database Related to COVID-19 Host Genetics. International Journal of Translational Medicine, 2(3), 355-363. https://doi.org/10.3390/ijtm2030028