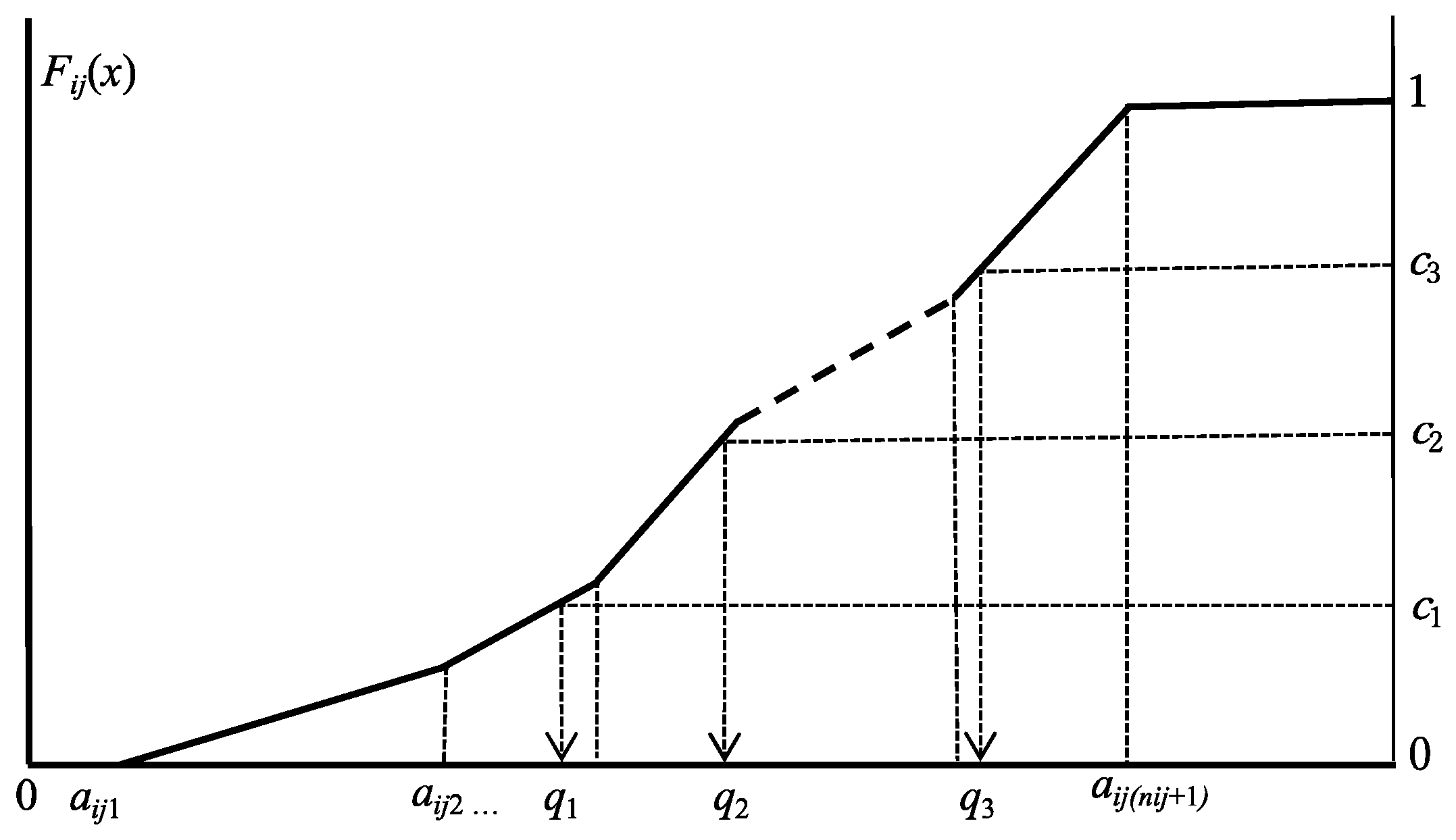
Figure 1.
Cumulative distribution function and cut point probabilities.
Figure 1.
Cumulative distribution function and cut point probabilities.
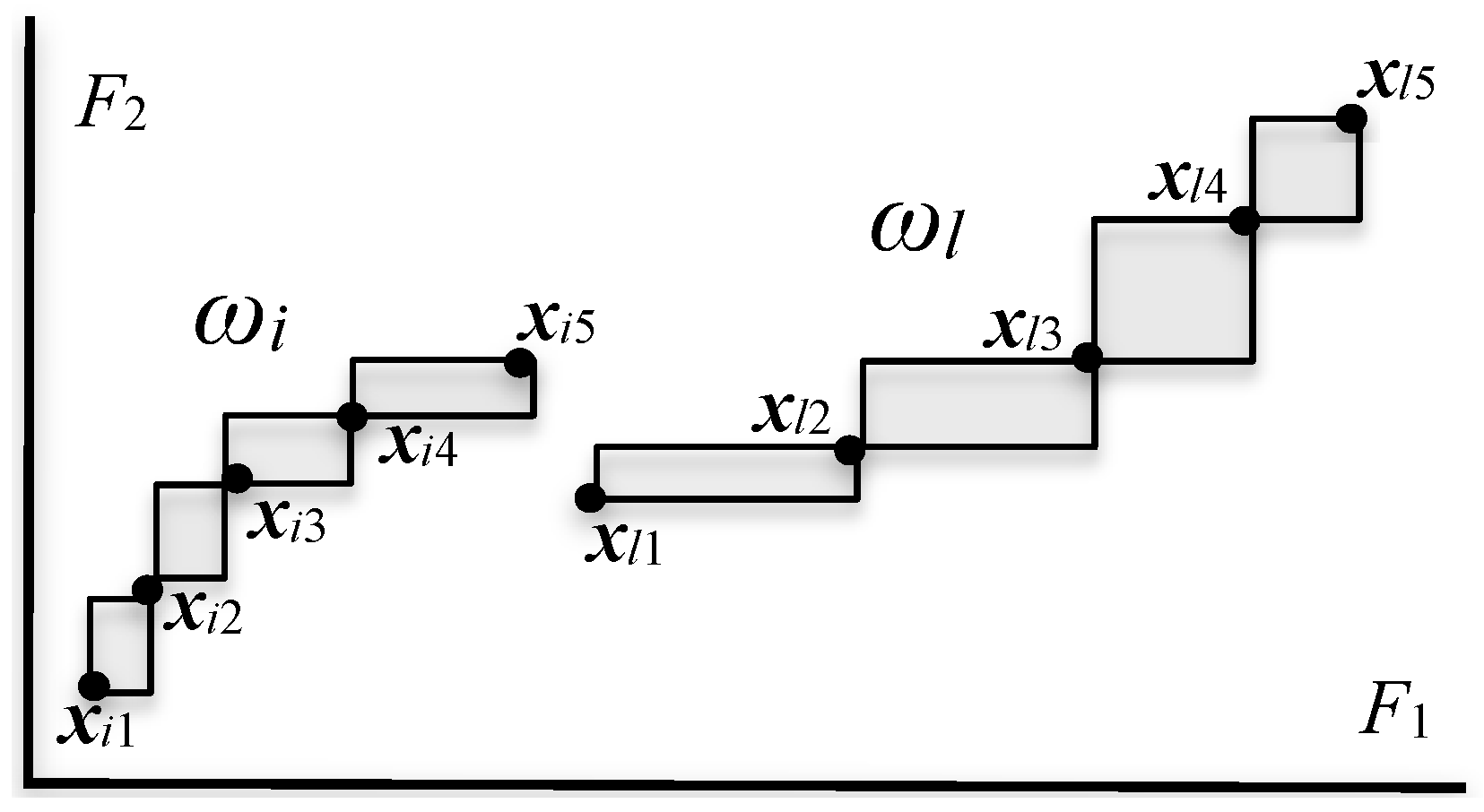
Figure 2.
Representation of objects and bin rectangles in the quartile case.
Figure 2.
Representation of objects and bin rectangles in the quartile case.
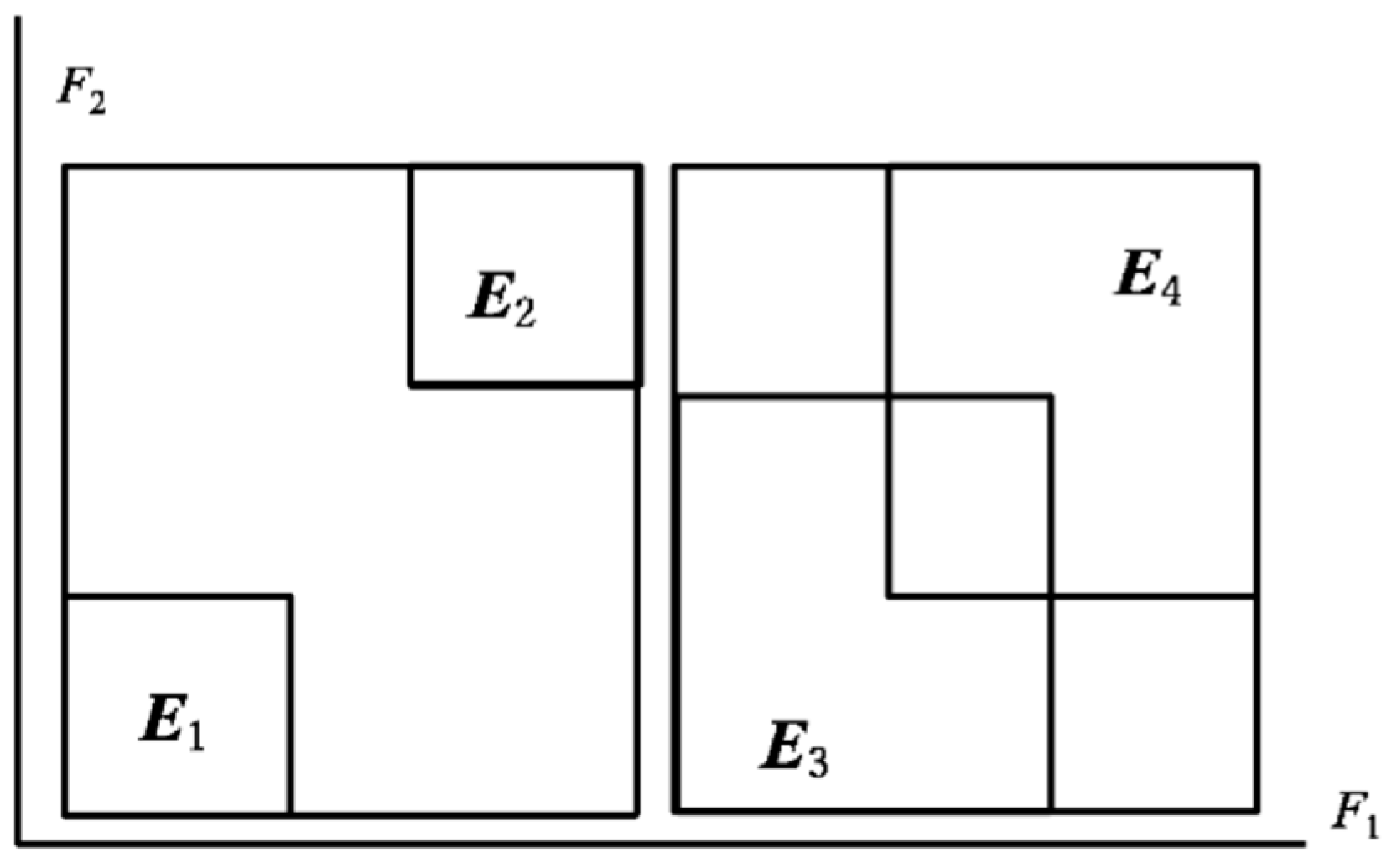
Figure 3.
A property of compactness.
Figure 3.
A property of compactness.
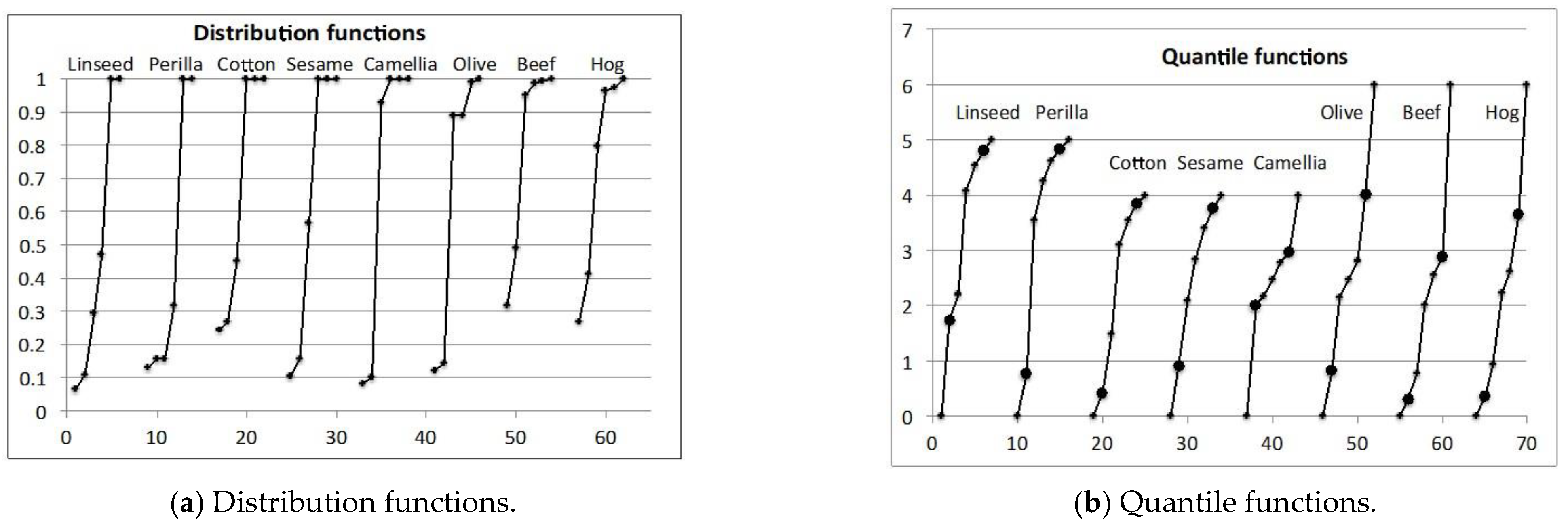
Figure 4.
Cumulative distribution functions and their corresponding quantile functions.
Figure 4.
Cumulative distribution functions and their corresponding quantile functions.
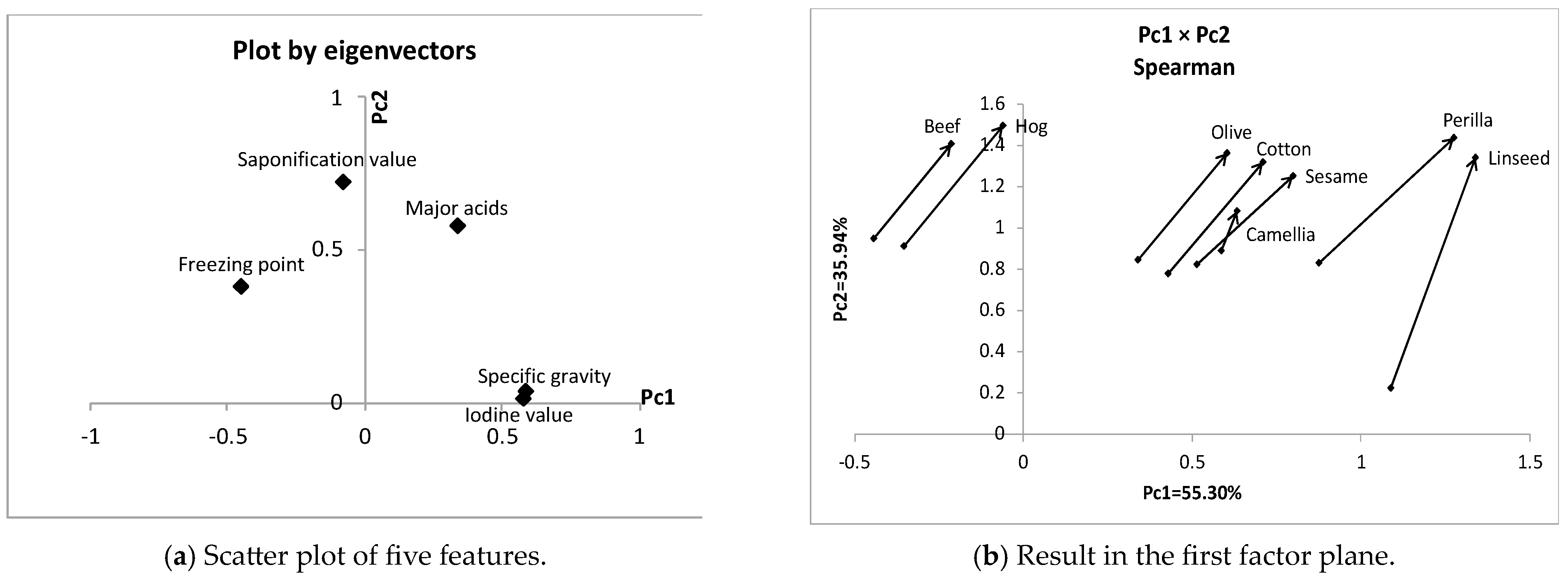
Figure 5.
Result of PCA for the interval-valued oil data.
Figure 5.
Result of PCA for the interval-valued oil data.
Figure 6.
Result of PCA for quartile case.
Figure 6.
Result of PCA for quartile case.
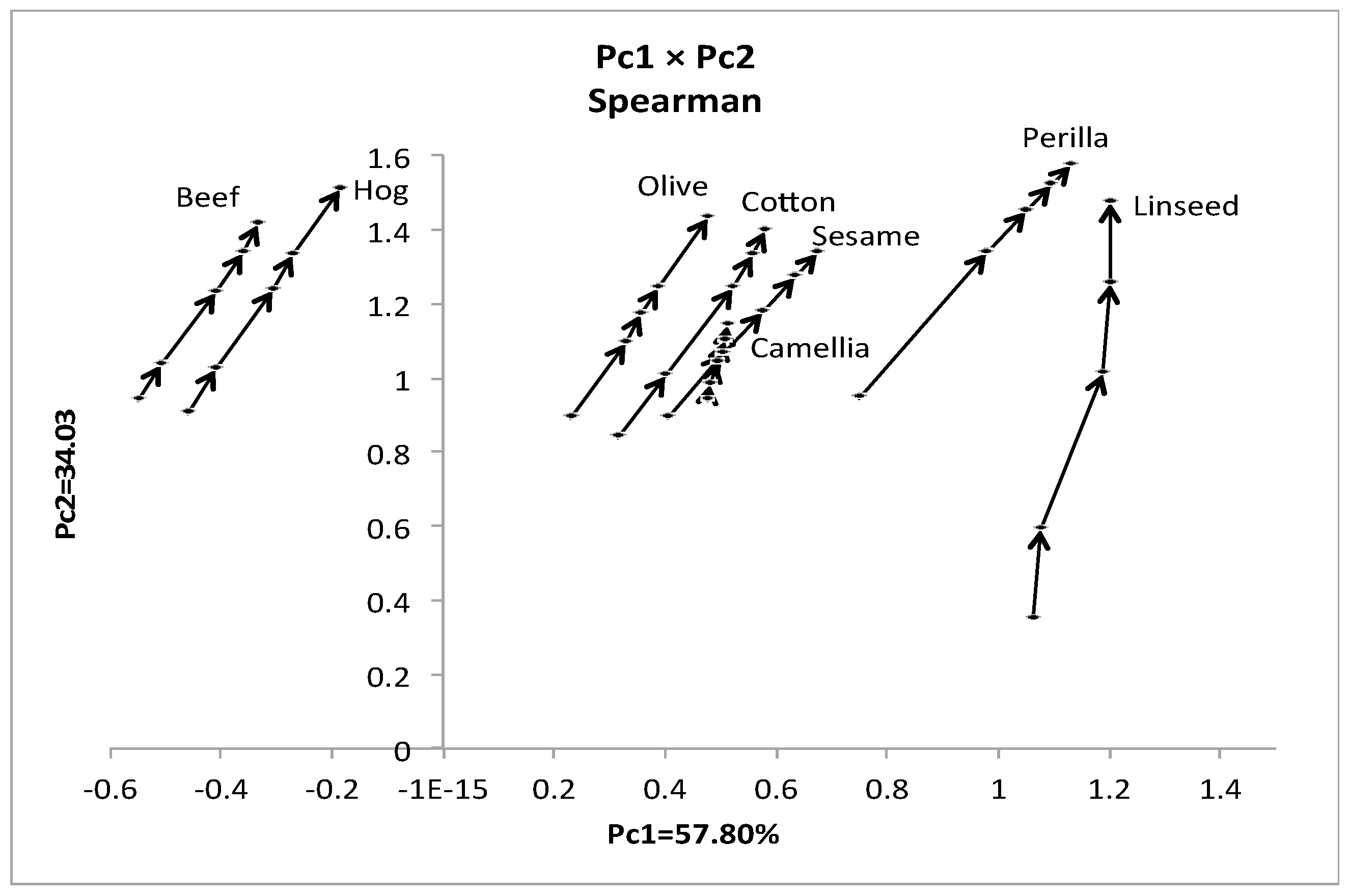
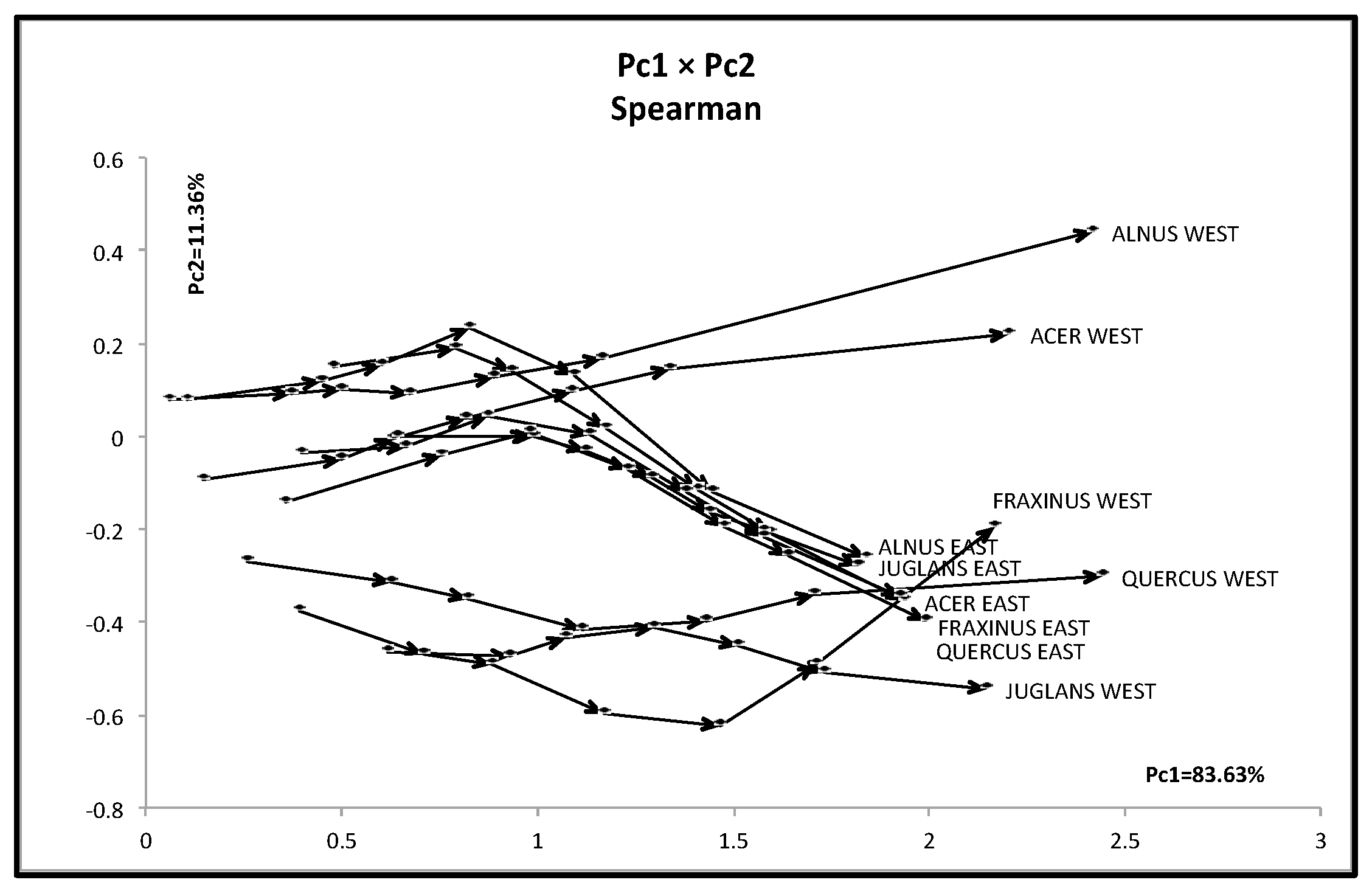
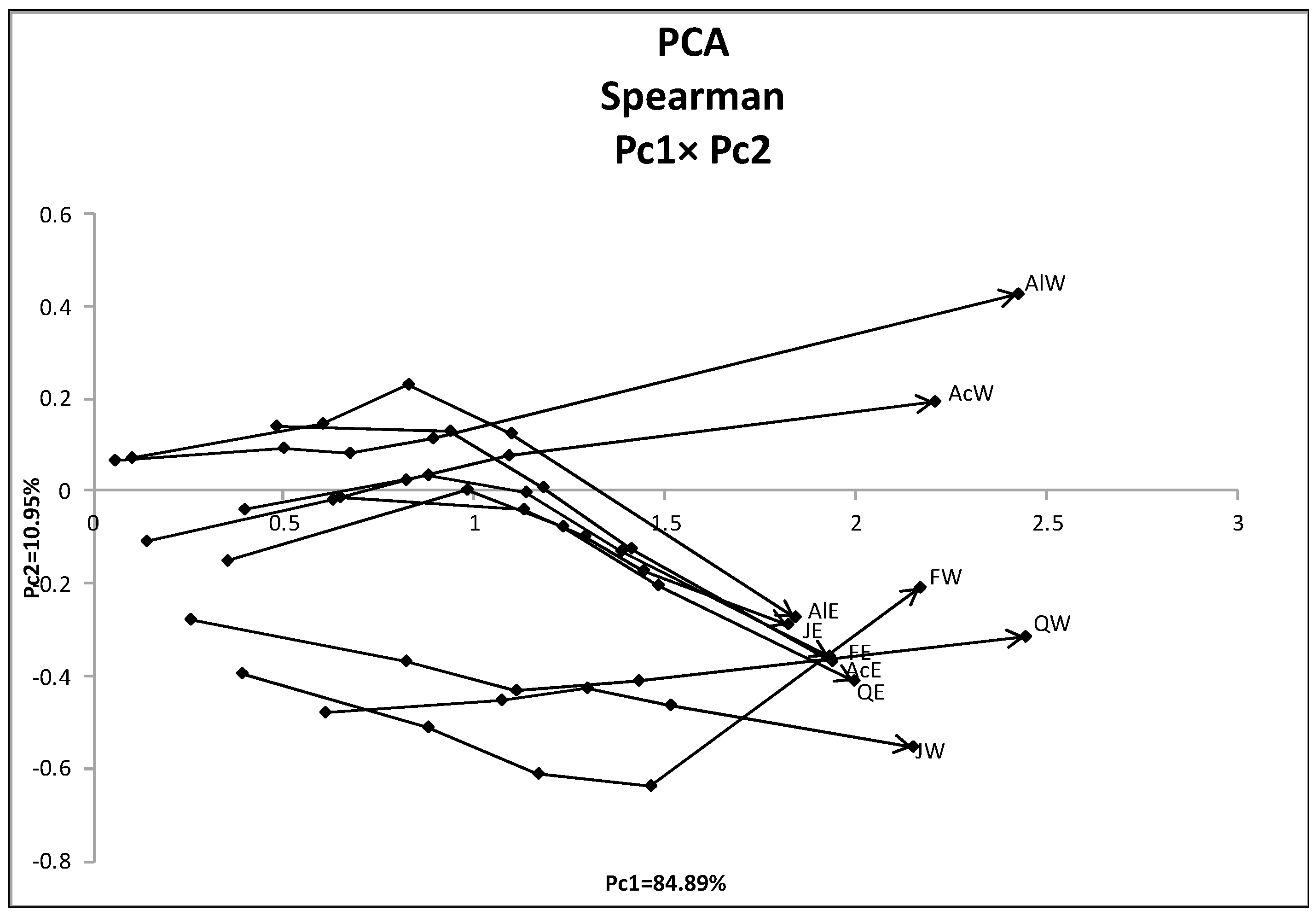
Figure 7.
Result of dual PCA for the oil data.
Figure 7.
Result of dual PCA for the oil data.
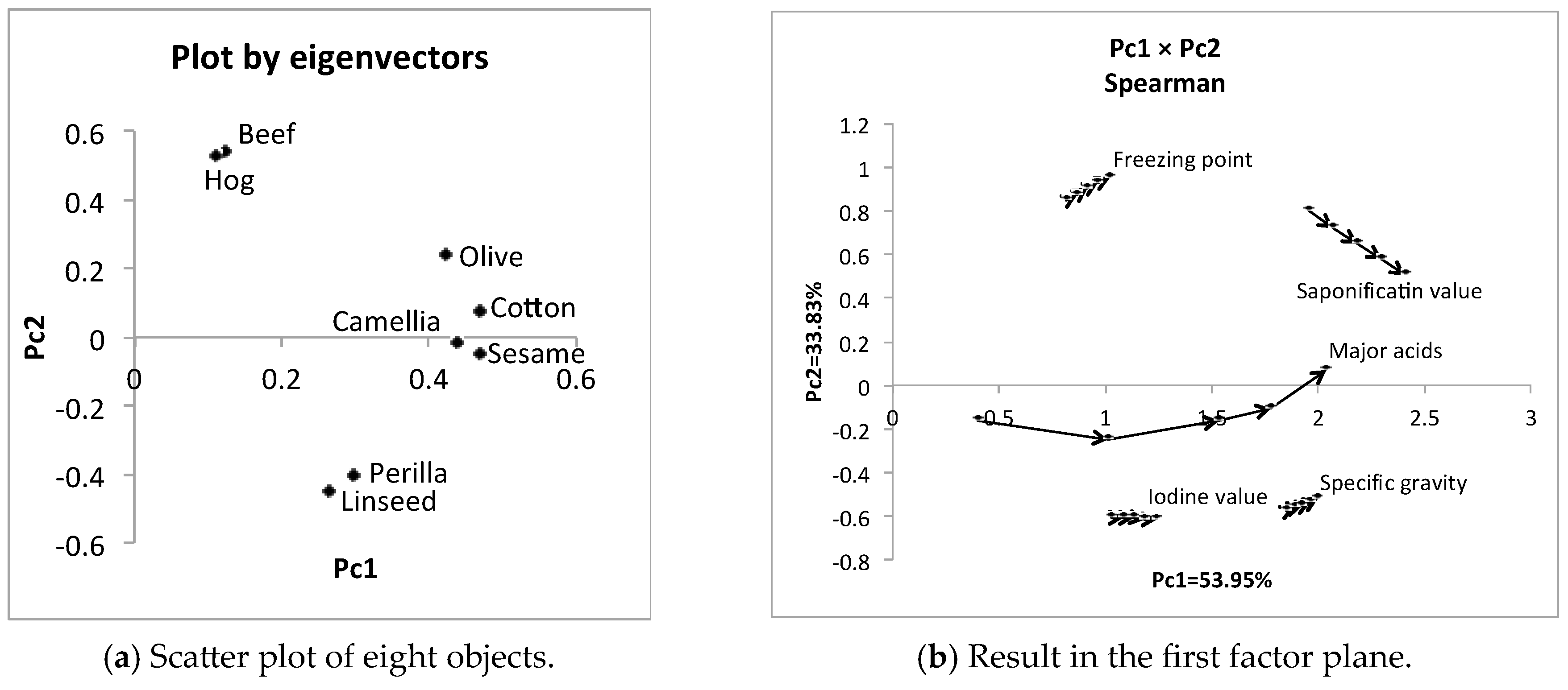
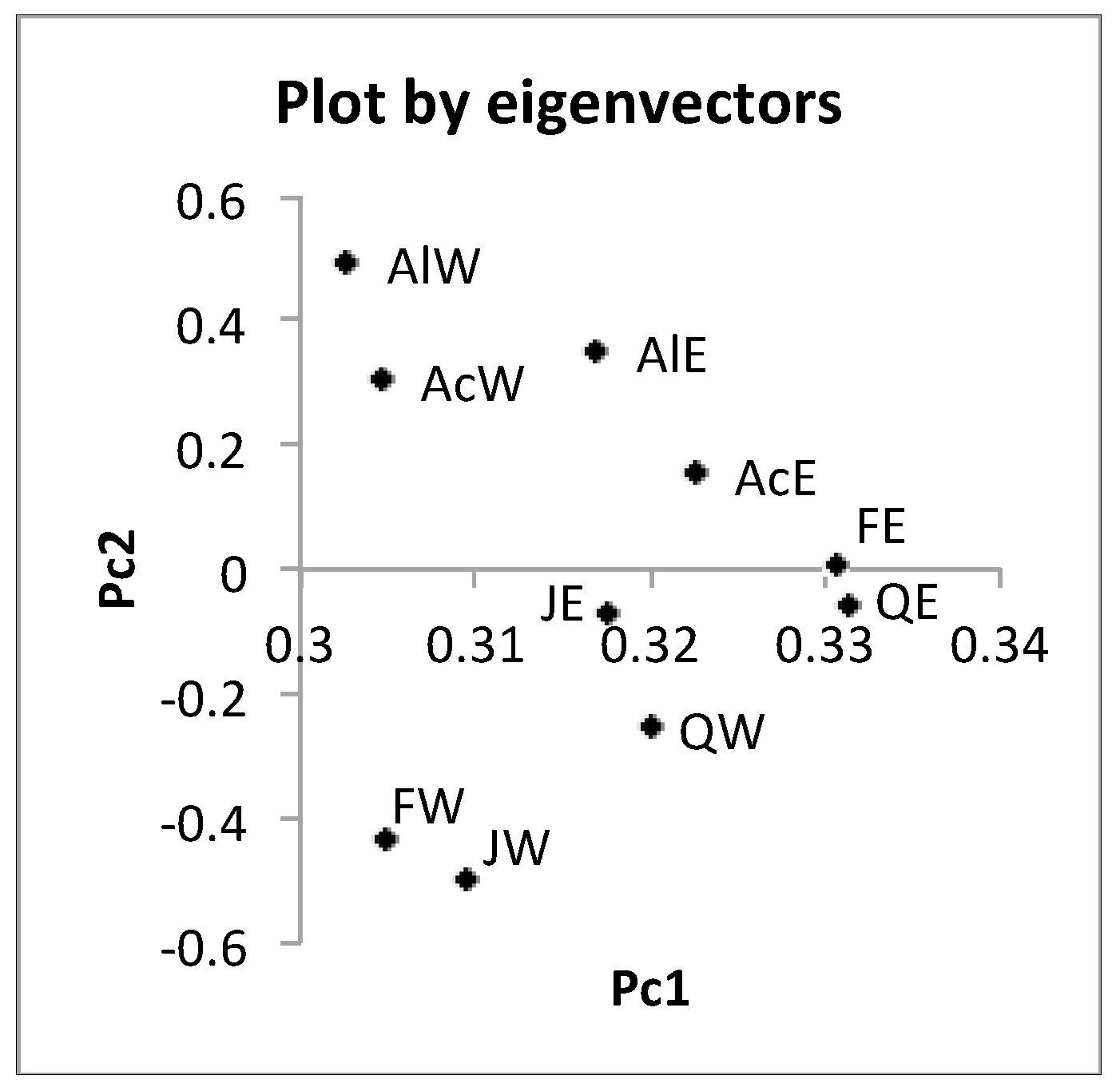
Figure 8.
Scatter plot of eight features by two eigenvectors.
Figure 8.
Scatter plot of eight features by two eigenvectors.
Figure 9.
Result of PCA for the hardwood data.
Figure 9.
Result of PCA for the hardwood data.
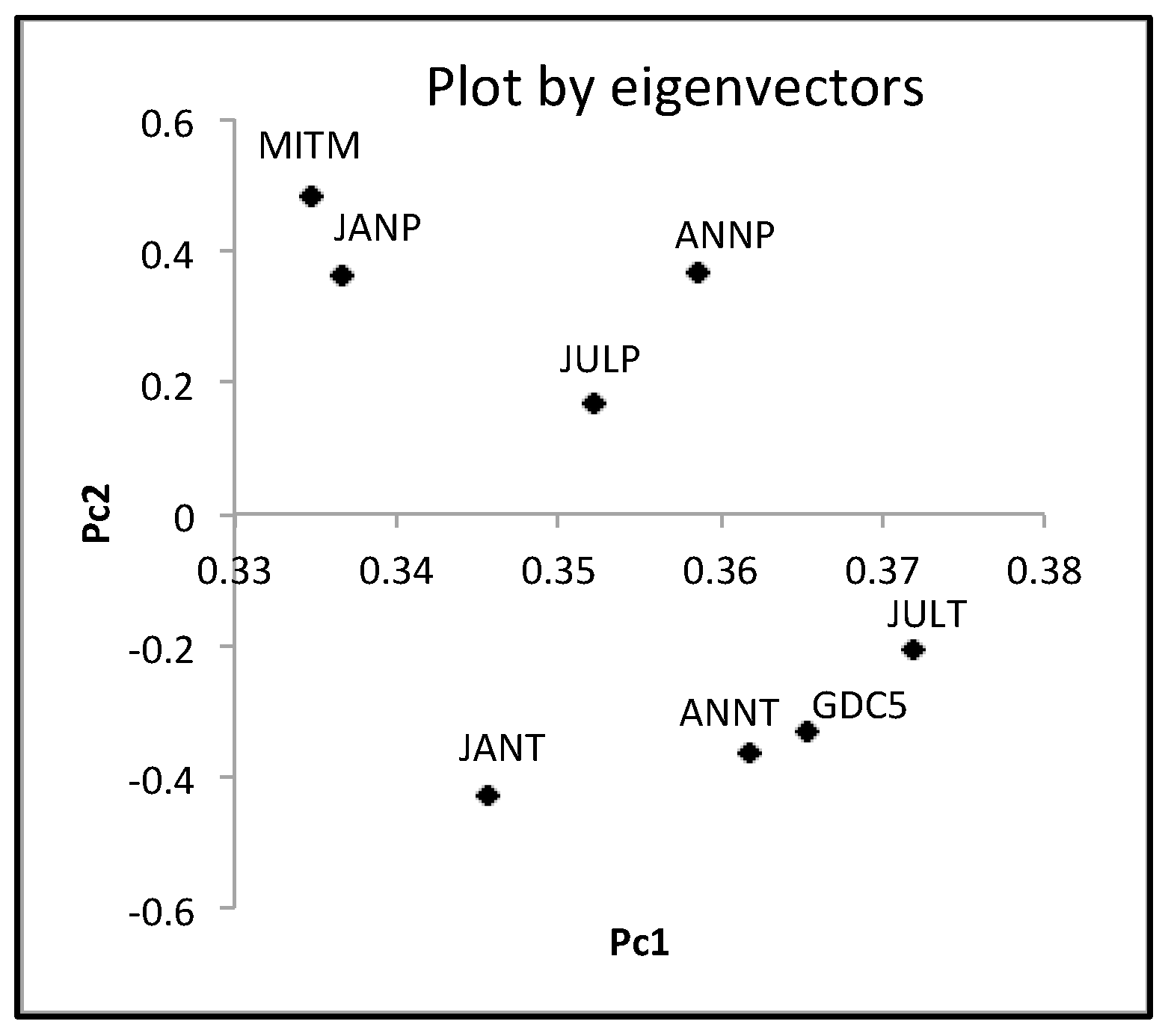
Figure 10.
Scatter plot of ten hardwoods by two eigenvectors.
Figure 10.
Scatter plot of ten hardwoods by two eigenvectors.
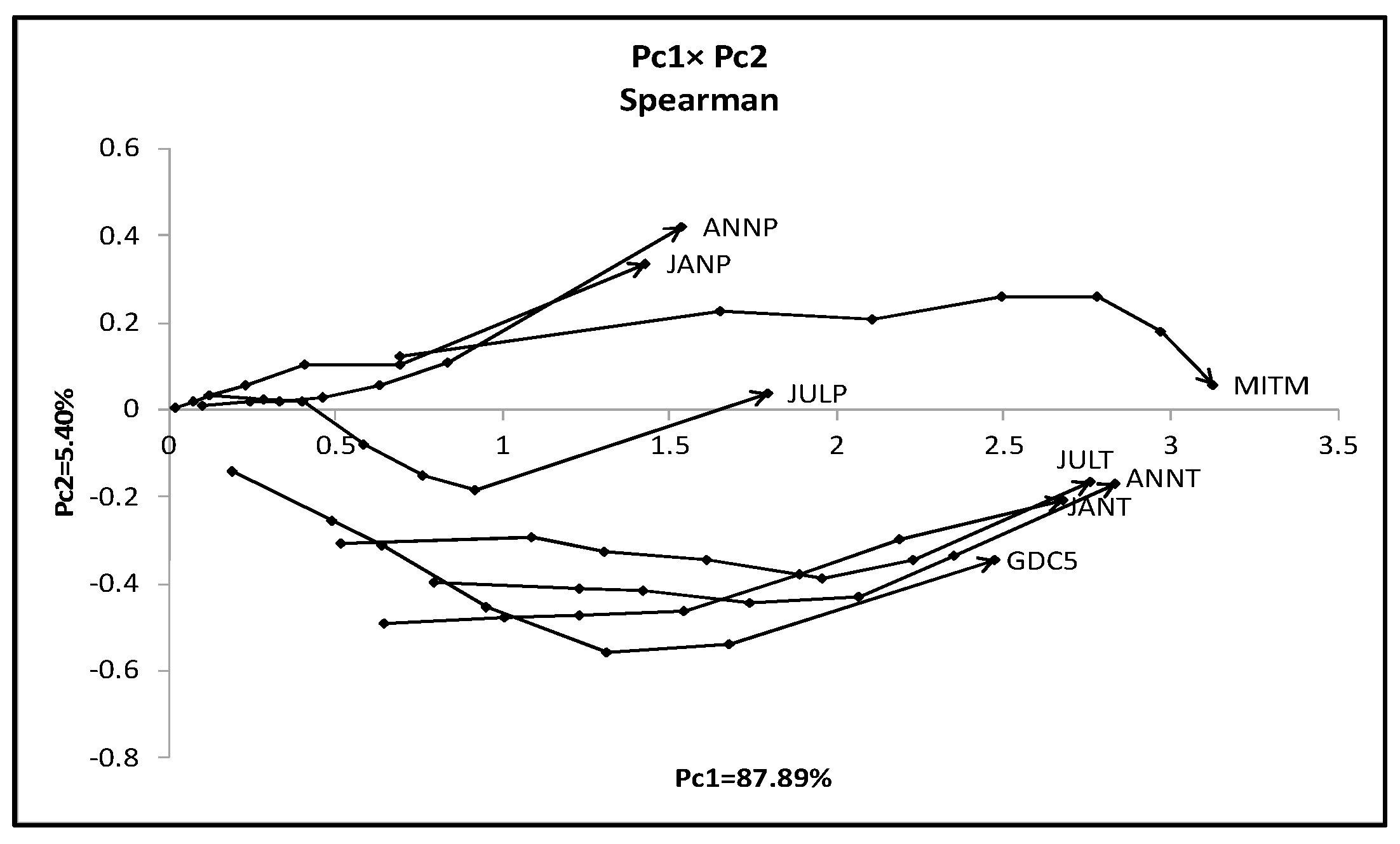
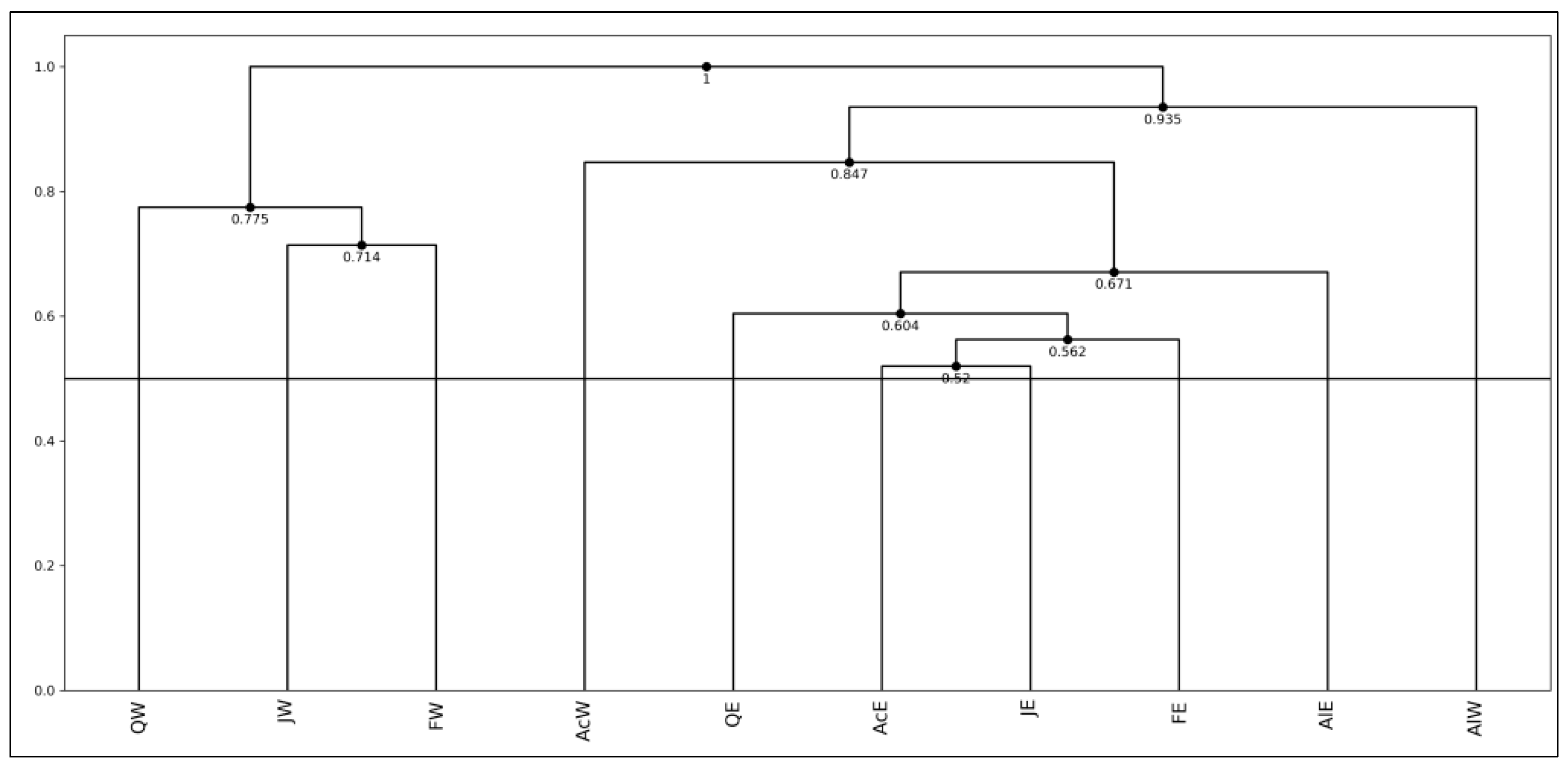
Figure 11.
Result of dual PCA for the hardwood data.
Figure 11.
Result of dual PCA for the hardwood data.
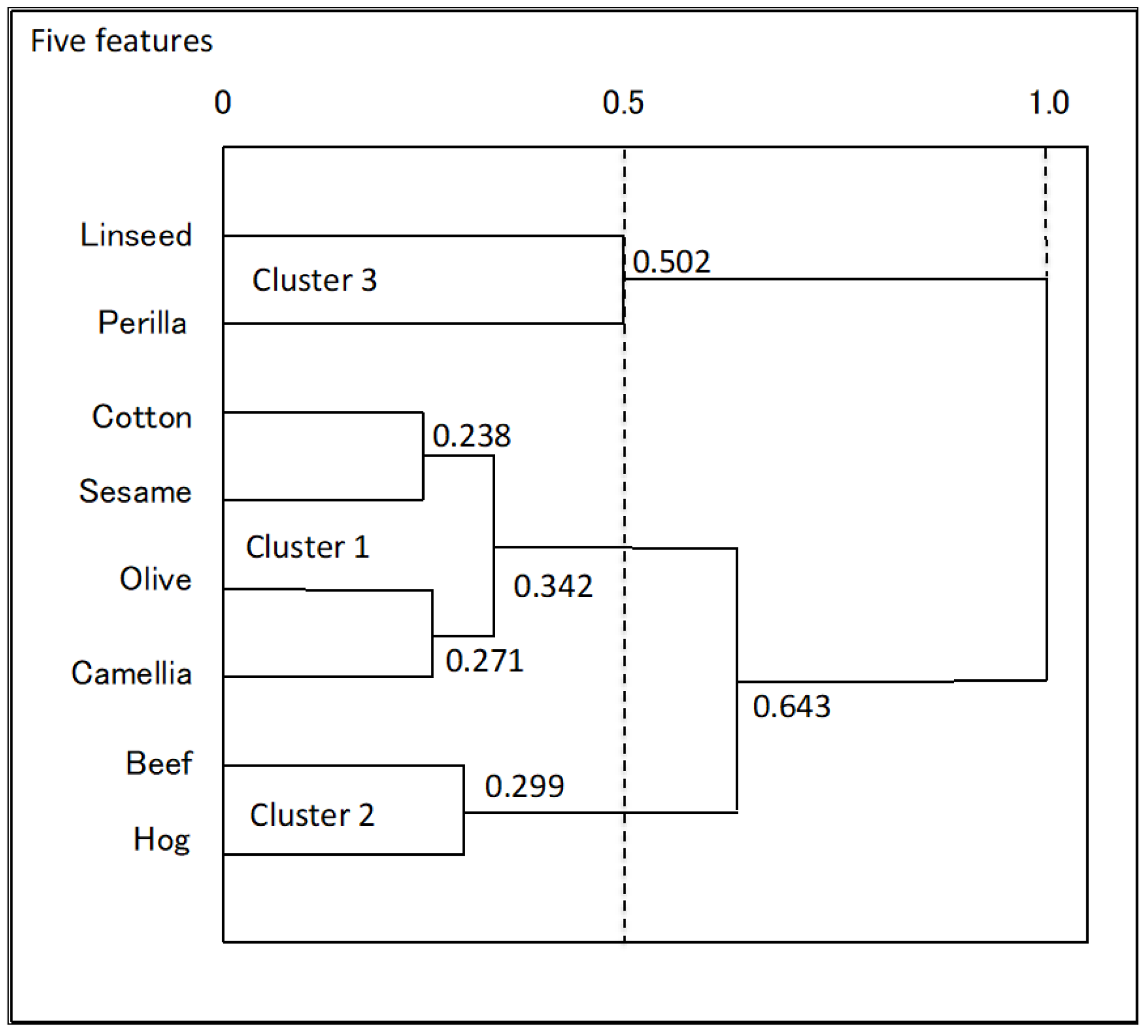
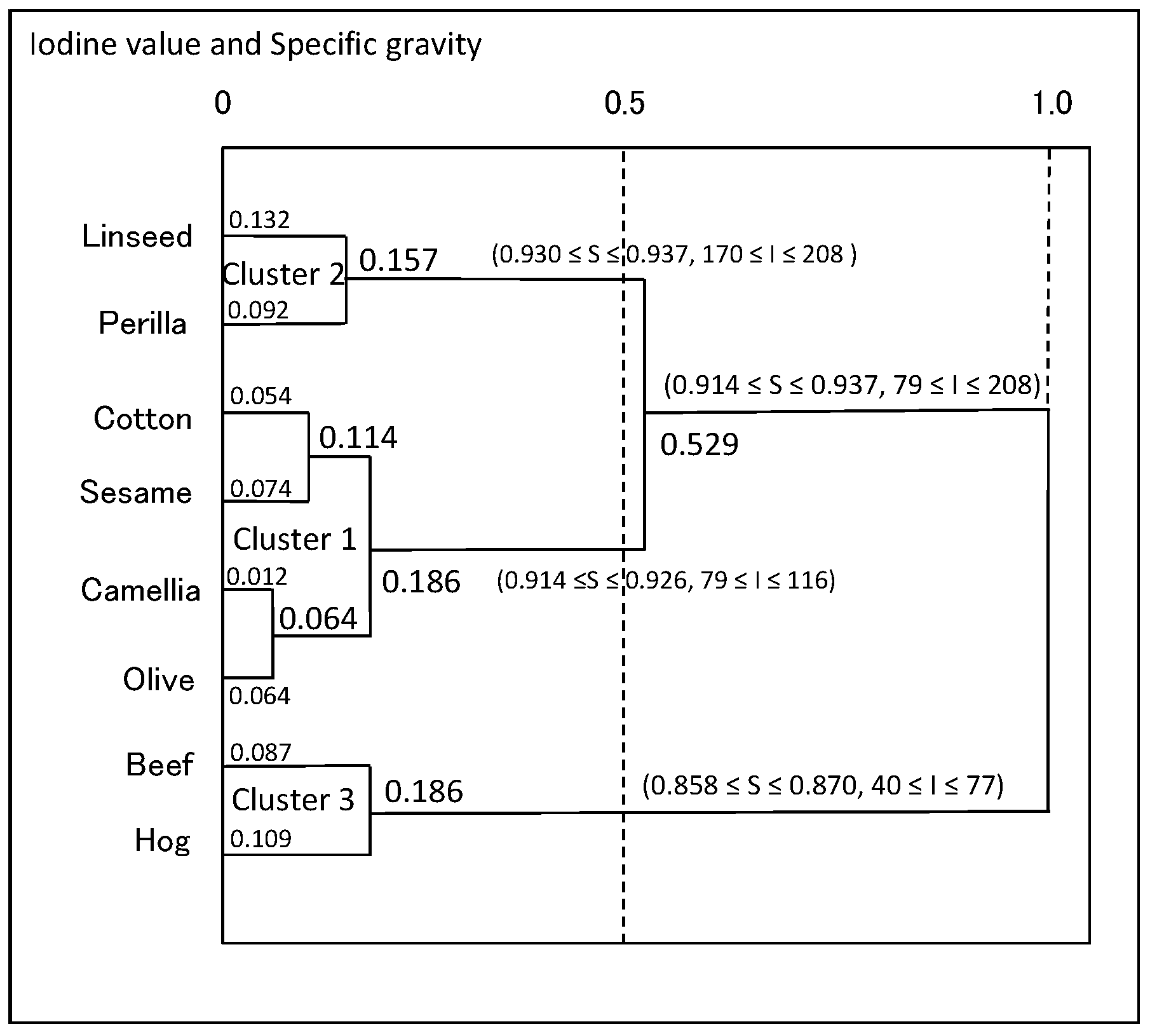
Figure 12.
Result of HCC for oil data (five features).
Figure 12.
Result of HCC for oil data (five features).
Figure 13.
Scatter diagram using two informative features.
Figure 13.
Scatter diagram using two informative features.
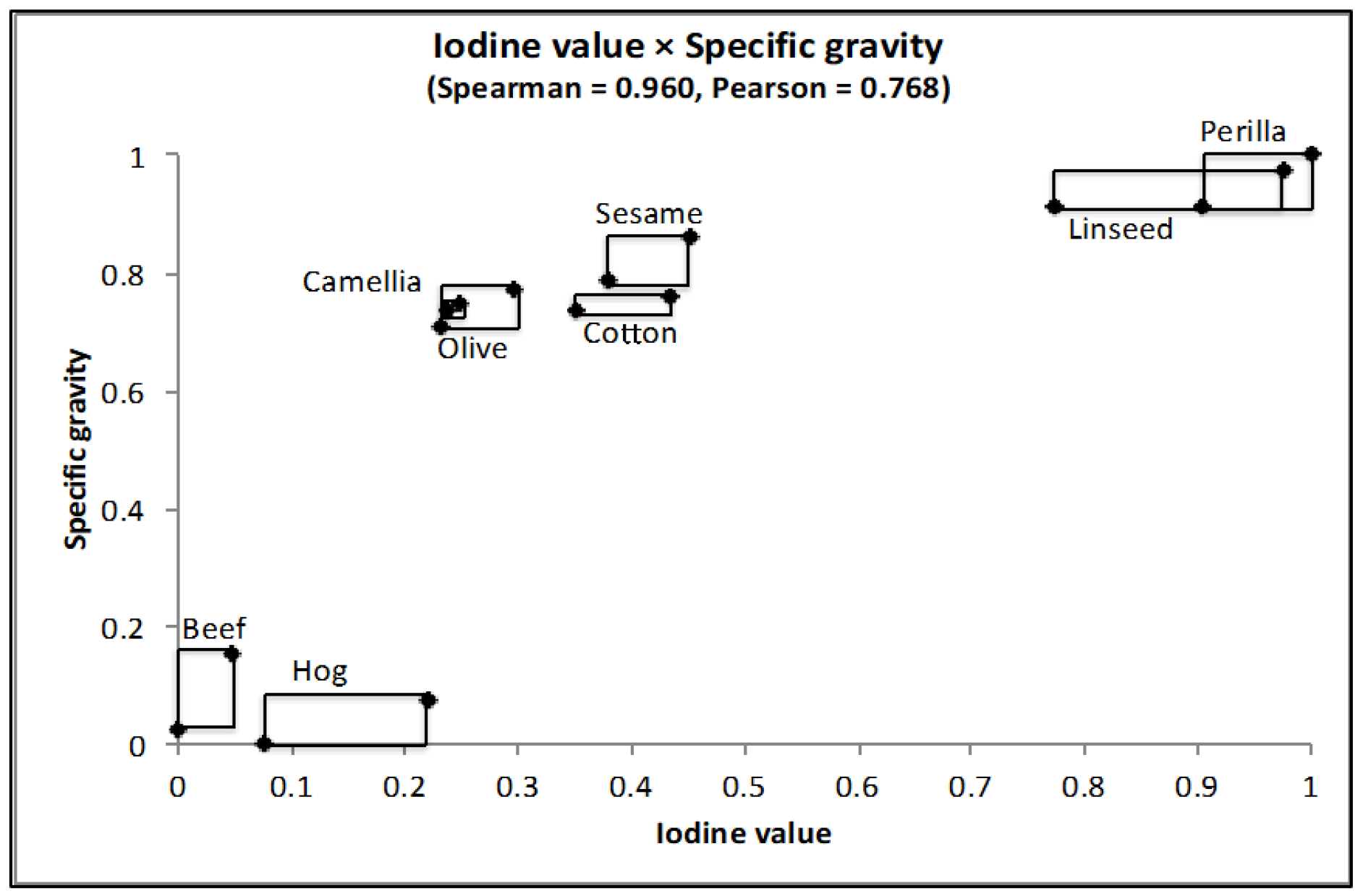
Figure 14.
Result of HCC for oil data using iodine value and specific gravity.
Figure 14.
Result of HCC for oil data using iodine value and specific gravity.
Figure 15.
Result of PCA for hardwood data (quartile case).
Figure 15.
Result of PCA for hardwood data (quartile case).
Figure 16.
Result of HCC for hardwood data (eight features).
Figure 16.
Result of HCC for hardwood data (eight features).
Figure 17.
Scatter diagrams for the selected informative features.
Figure 17.
Scatter diagrams for the selected informative features.
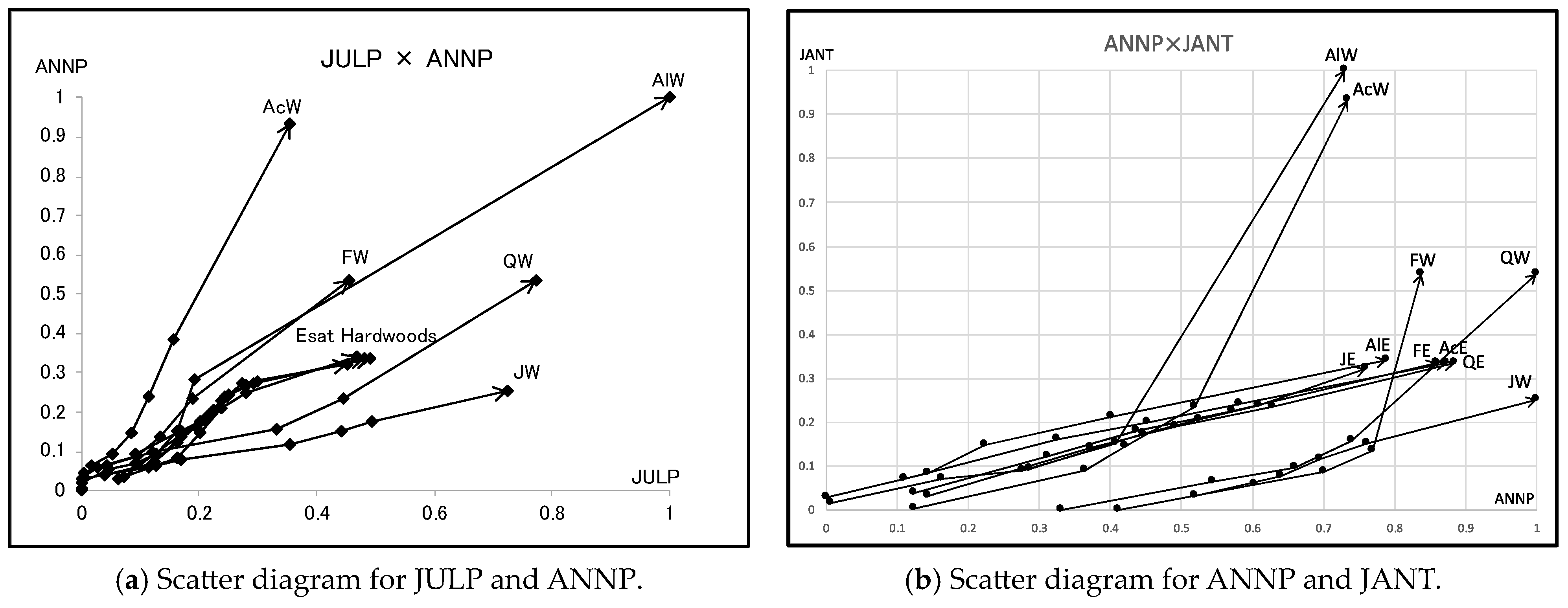
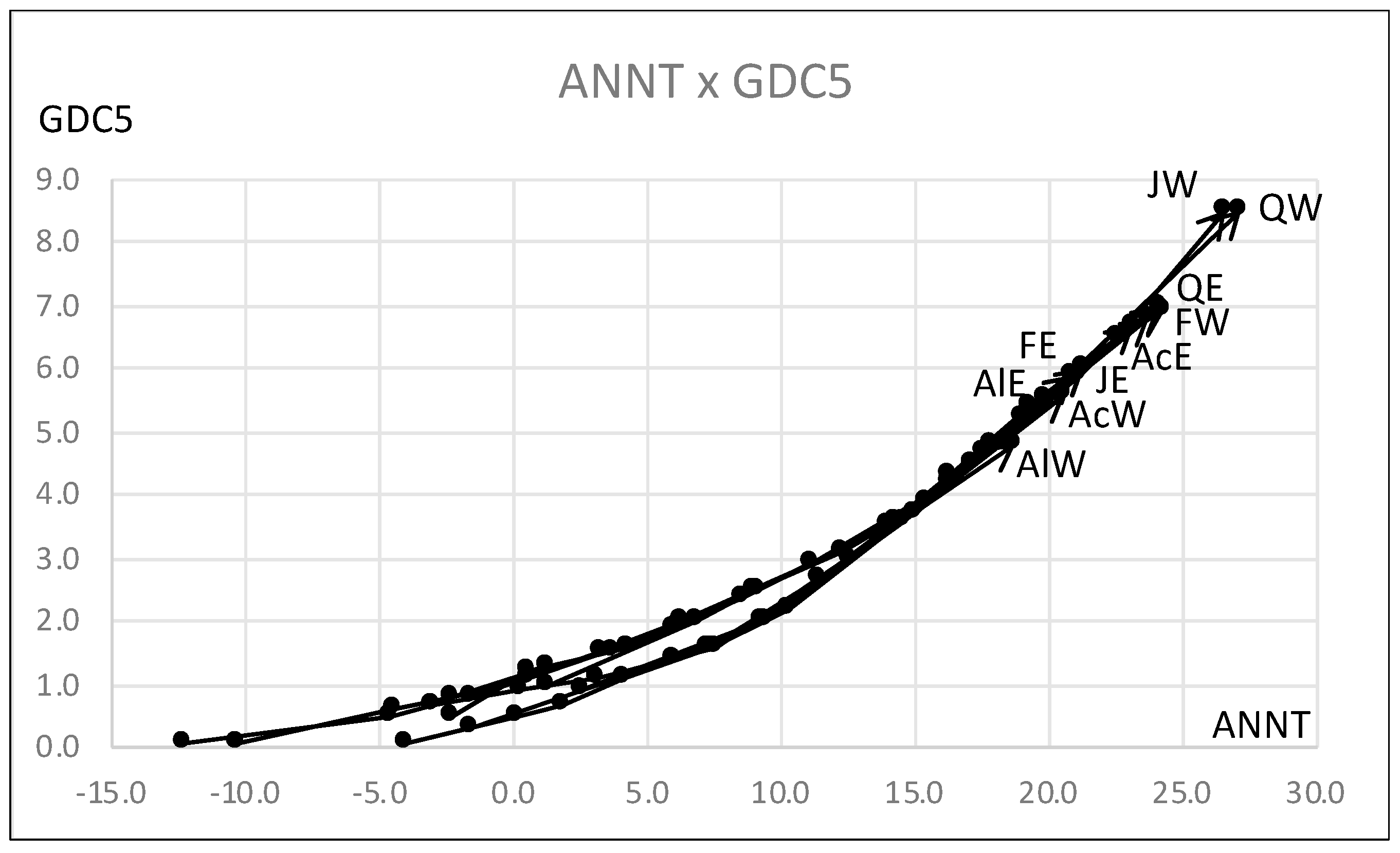
Figure 18.
Scatter diagram of hardwood data for ANNT and GDC5.
Figure 18.
Scatter diagram of hardwood data for ANNT and GDC5.
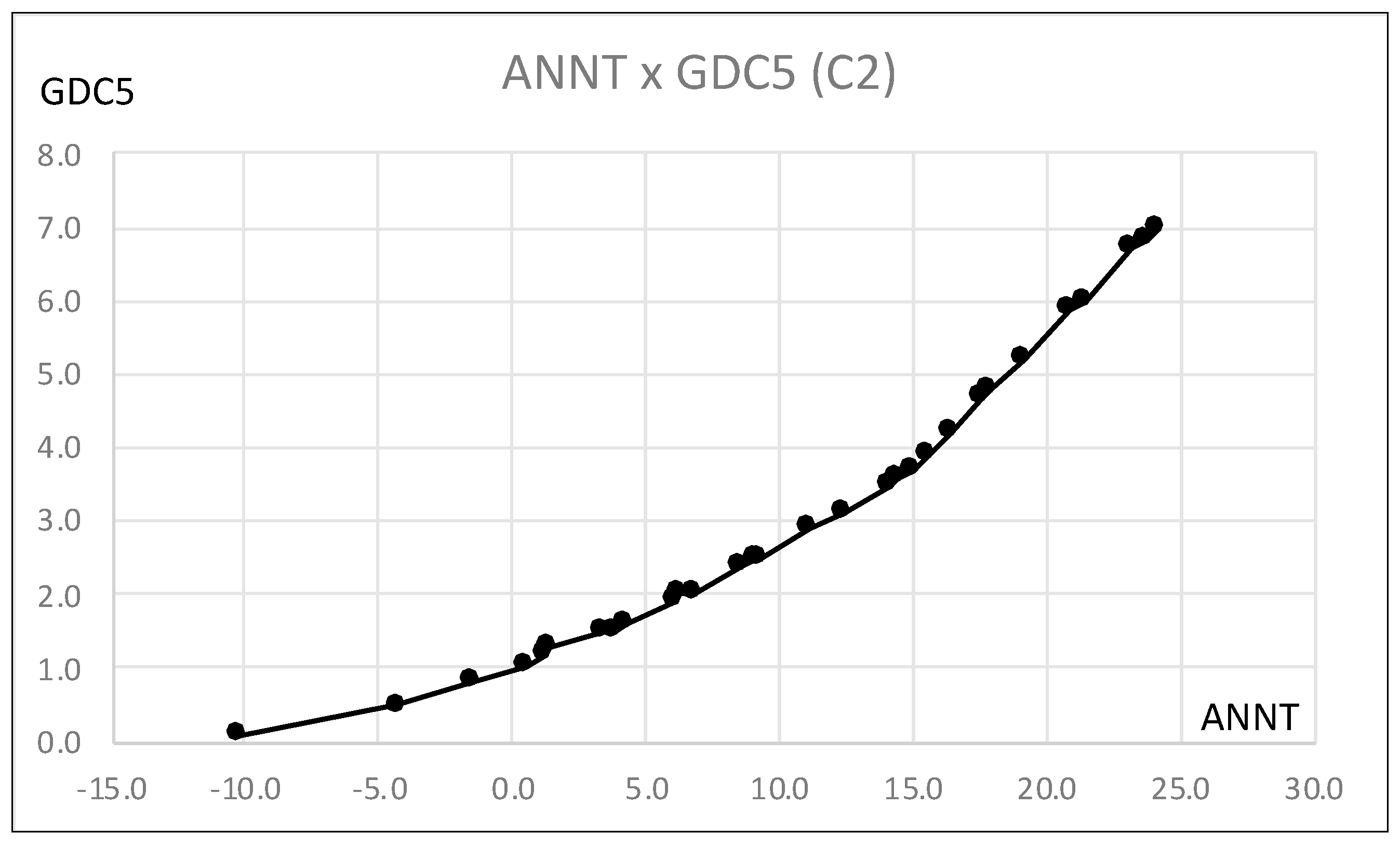
Figure 19.
Estimation of GDC5 by ANNT for cluster C2.
Figure 19.
Estimation of GDC5 by ANNT for cluster C2.
Table 1.
Oil data [
6,
7,
8,
9].
Table 1.
Oil data [
6,
7,
8,
9].
| Object | Specific Gravity | Freezing Point | Iodine Value | Saponification Value | Major Acids |
|---|
| Linseed | [0.930, 0.935] | [−27, −18] | [170, 204] | [118, 196] | L, Ln, O, P |
| Perilla | [0.930, 0.937] | [−5, −4] | [192, 208] | [188, 197] | L, Ln, P, S |
| Cotton | [0.916, 0.918] | [−6, −1] | [99, 113] | [189, 198] | L, O, P, S |
| Sesame | [0.920, 0.926] | [−6, −4] | [104, 116] | [187, 193] | L, O, P, S |
| Camellia | [0.914, 0.917] | [−21, −15] | [80, 82] | [189, 193] | L, O, P, S |
| Olive | [0.914, 0.919] | [0, 6] | [79, 90] | [187, 196] | Ln, O, P, S, A |
| Beef | [0.860, 0.870] | [30, 38] | [40, 48] | [190, 199] | L, Ln, O, P, S, A |
| Hog | [0.858, 0.864] | [22, 32] | [53, 77] | [190, 202] | L, Ln, O, P, S, A |
Table 2.
Composition table of major acids.
Table 2.
Composition table of major acids.
| Object | Palmitic Acid
C16:0 | Stearic Acid
C18:0 | Oleic Acid
C18:1 | Linoleic Acid
C18:2 | Linolenic Acid
C18:3 | Arachic Acid
C20:0 | [0, 10%, 25%, 50%, 75%, 90%, 100%] |
|---|
| Linseed | 0.07 | 0.04 | 0.19 | 0.17 | 0.53 | 0.00 | [0, 1.75, 2.21, 4.06, 4.53, 4.81, 5] |
| Perilla | 0.13 | 0.03 | 0.00 | 0.16 | 0.68 | 0.00 | [0, 0.77, 3.56, 4.26, 4.63, 4.85, 5] |
| Cotton | 0.24 | 0.02 | 0.18 | 0.55 | 0.00 | 0.00 | [0, 0.42, 1.50, 3.11, 3.56, 3.84, 4] |
| Sesame | 0.11 | 0.05 | 0.41 | 0.43 | 0.00 | 0.00 | [0, 0.91, 2.09, 2.83, 3.42, 3.77, 4] |
| Camellia | 0.08 | 0.02 | 0.82 | 0.07 | 0.00 | 0.00 | [0, 2.00, 2.18, 2.49, 2.79, 2.98, 4] |
| Olive | 0.12 | 0.02 | 0.74 | 0.00 | 0.10 | 0.01 | [0, 0.83, 2.15, 2.49, 2.82, 4.02, 6] |
| Beef | 0.32 | 0.17 | 0.46 | 0.03 | 0.01 | 0.01 | [0, 0.31, 0.78, 2.02, 2.57, 2.89, 6] |
| Hog | 0.27 | 0.14 | 0.38 | 0.17 | 0.01 | 0.03 | [0, 0.37, 0.93, 2.24, 2.63, 3.65, 6] |
Table 3.
Oil data described using five interval values.
Table 3.
Oil data described using five interval values.
| Object | Specific Gravity | Freezing Point | Iodine Value | Saponification Value | Major Acids |
|---|
| Linseed | [0.930, 0.935] | [−27, −18] | [170, 204] | [118, 196] | [1.75, 4.81] |
| Perilla | [0.930, 0.937] | [−5, −4] | [192, 208] | [188, 197] | [0.77, 4.85] |
| Cotton | [0.916, 0.918] | [−6, −1] | [99, 113] | [189, 198] | [0.42, 3.84] |
| Sesame | [0.920, 0.926] | [−6, −4] | [104, 116] | [187, 193] | [0.91, 3.77] |
| Camellia | [0.914, 0.917] | [−21, −15] | [80, 82] | [189, 193] | [2.00, 2.98] |
| Olive | [0.914, 0.919] | [0, 6] | [79, 90] | [187, 196] | [0.83, 4.02] |
| Beef | [0.860, 0.870] | [30, 38] | [40, 48] | [190, 199] | [0.31, 2.89] |
| Hog | [0.858, 0.864] | [22, 32] | [53, 77] | [190, 202] | [0.37, 3.65] |
Table 4.
The first two principal components for the oil data in
Table 3.
Table 4.
The first two principal components for the oil data in
Table 3.
| Spearman | Pc1 | Pc2 |
| Eigen values | 2.77 | 1.80 |
| Contribution(%) | 55.30 | 35.94 |
| Eigen vectors | Pc1 | Pc2 |
| Specific gravity | 0.584 | 0.034 |
| Freezing point | −0.448 | 0.379 |
| Iodine value | 0.578 | 0.012 |
| Saponification value | −0.077 | 0.721 |
| Major acids | 0.343 | 0.579 |
Table 5.
Part of the oil data by quartile representation.
Table 5.
Part of the oil data by quartile representation.
| Object | Specific Gravity | Freezing Point | Iodine Value | Saponification Value | Major Acids |
|---|
| Linseed 0 | 0.930 | −27.00 | 170.0 | 118.0 | 1.75 |
| 1 | 0.931 | −24.75 | 178.5 | 137.5 | 2.21 |
| 2 | 0.933 | −22.50 | 187.0 | 157.0 | 4.06 |
| 3 | 0.934 | −20.25 | 195.5 | 176.5 | 4.53 |
| 4 | 0.935 | −18.00 | 204.0 | 196.0 | 4.81 |
Table 6.
The first two principal components for the quartile case of the oil data.
Table 6.
The first two principal components for the quartile case of the oil data.
| Spearman | Pc1 | Pc2 |
| Eigen values | 2.89 | 1.70 |
| Contribution (%) | 57.80 | 34.03 |
| Eigen vectors | Pc1 | Pc2 |
| Specific gravity | 0.570 | 0.099 |
| Freezing point | −0.457 | 0.383 |
| Iodine value | 0.562 | 0.093 |
| Saponification value | −0.190 | 0.700 |
| Major acids | 0.339 | 0.588 |
Table 7.
The first two principal components for dual PCA of the oil data.
Table 7.
The first two principal components for dual PCA of the oil data.
| Spearman | Pc1 | Pc2 |
| Eigen values | 4.32 | 2.71 |
| Contribution (%) | 53.95 | 33.83 |
| Eigen vectors | Pc1 | Pc2 |
| Linseed | 0.26 | −0.45 |
| Perilla | 0.30 | −0.40 |
| Cotton | 0.47 | 0.08 |
| Sesame | 0.47 | −0.04 |
| Camellia | 0.44 | −0.02 |
| Olive | 0.42 | 0.24 |
| Beef | 0.12 | 0.54 |
| Hog | 0.11 | 0.53 |
Table 8.
The original quantile values for ANNT.
Table 8.
The original quantile values for ANNT.
| TAXON NAME | Mean Annual Temperature (°C) |
|---|
| 0% | 10% | 25% | 50% | 75% | 90% | 100% |
|---|
| ACER EAST | −2.3 | 0.6 | 3.8 | 9.2 | 14.4 | 17.9 | 24 |
| ACER WEST | −3.9 | 0.2 | 1.9 | 4.2 | 7.5 | 10.3 | 21 |
| ALNUS EAST | −10 | −4.4 | −2.3 | 0.6 | 6.1 | 15.0 | 21 |
| ALNUS WEST | −12 | −4.6 | −3.0 | 0.3 | 3.2 | 7.6 | 19 |
| FRAXINUS EAST | −2.3 | 1.4 | 4.3 | 8.6 | 14.1 | 17.9 | 23 |
| FRAXINUS WEST | 2.6 | 9.4 | 11.5 | 17.2 | 21.2 | 22.7 | 24 |
| JAGLANS EAST | 1.3 | 6.9 | 9.1 | 12.4 | 15.5 | 17.6 | 21 |
| JAGLANS WEST | 7.3 | 12.6 | 14.1 | 16.3 | 19.4 | 22.7 | 27 |
| QUERCUS EAST | −1.5 | 3.4 | 6.3 | 11.2 | 16.4 | 19.1 | 24 |
| QUERCUS WEST | −1.5 | 6.0 | 9.5 | 14.6 | 17.9 | 19.9 | 27 |
Table 9.
The first two principal components of the hardwood data.
Table 9.
The first two principal components of the hardwood data.
| Spearman | Pc1 | Pc2 |
| Eigen values | 6.6908 | 0.9086 |
| Contribution (%) | 83.6346 | 11.3573 |
| Eigen vectors | Pc1 | Pc2 |
| ANNT | 0.3618 | −0.3630 |
| JANT | 0.3456 | −0.4270 |
| JULT | 0.3718 | −0.2076 |
| ANNP | 0.3585 | 0.3695 |
| JANP | 0.3366 | 0.3648 |
| JULP | 0.3522 | 0.1697 |
| GDC5 | 0.3653 | −0.3312 |
| MITM | 0.3347 | 0.4845 |
Table 10.
The first two principal components of the dual hardwood data.
Table 10.
The first two principal components of the dual hardwood data.
| Spearman | Pc1 | Pc2 |
| Eigen values | 8.79 | 0.54 |
| Contribution (%) | 87.89 | 5.40 |
| Eigen vectors | Pc1 | Pc2 |
| AcE | 0.323 | 0.156 |
| AcW | 0.305 | 0.308 |
| AlE | 0.317 | 0.354 |
| AlW | 0.303 | 0.496 |
| FE | 0.331 | 0.008 |
| FW | 0.305 | −0.436 |
| JE | 0.318 | −0.071 |
| JW | 0.309 | −0.497 |
| QE | 0.331 | −0.056 |
| QW | 0.320 | −0.253 |
Table 11.
Average compactness of each feature in each clustering step.
Table 11.
Average compactness of each feature in each clustering step.
| Feature | Average Compactness for Each Clustering Step |
|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|
| Specific gravity | 0.066 | 0.080 | 0.091 | 0.099 | 0.114 | 0.131 | 0.475 | 1.000 |
| Freezing point | 0.090 | 0.099 | 0.154 | 0.178 | 0.204 | 0.338 | 0.631 | 1.000 |
| Iodine value | 0.090 | 0.095 | 0.109 | 0.137 | 0.185 | 0.222 | 0.339 | 1.000 |
| Saponification value | 0.202 | 0.224 | 0.254 | 0.283 | 0.327 | 0.405 | 0.560 | 1.000 |
| Major acids | 0.646 | 0.648 | 0.720 | 0.753 | 0.775 | 0.809 | 0.856 | 1.000 |
Table 12.
Average compactness of each feature in each clustering step.
Table 12.
Average compactness of each feature in each clustering step.
| Step | Average Compactness of Each Feature |
|---|
| ANNT | JANT | JULT | ANNP | JANP | JULP | GDC5 | MITM |
|---|
| 0 | 0.161 | 0.160 | 0.178 | 0.115 | 0.113 | 0.133 | 0.180 | 0.196 |
| 1 | 0.220 | 0.228 | 0.239 | 0.144 | 0.140 | 0.172 | 0.246 | 0.242 |
| 2 | 0.229 | 0.234 | 0.268 | 0.186 | 0.197 | 0.191 | 0.256 | 0.323 |
| 3 | 0.238 | 0.243 | 0.282 | 0.202 | 0.217 | 0.203 | 0.268 | 0.338 |
| 4 | 0.279 | 0.269 | 0.322 | 0.223 | 0.243 | 0.220 | 0.292 | 0.358 |
| 5 | 0.404 | 0.395 | 0.475 | 0.337 | 0.372 | 0.350 | 0.455 | 0.541 |
| 6 | 0.490 | 0.472 | 0.570 | 0.388 | 0.428 | 0.401 | 0.525 | 0.614 |
| 7 | 0.601 | 0.578 | 0.692 | 0.571 | 0.595 | 0.505 | 0.646 | 0.739 |
| 8 | 0.829 | 0.777 | 0.938 | 0.768 | 0.810 | 0.887 | 0.899 | 1.000 |
Table 13.
Quantile representation of oil data.
Table 13.
Quantile representation of oil data.
| Sub-Object | Specific Gravity | Freezing Point | Iodine Value | Saponification Value | Major Acids |
|---|
| Linseed 1 | 0.930 | −27 | 170 | 118 | 1.75 |
| Linseed 2 | 0.935 | −18 | 204 | 196 | 4.81 |
| Perilla 1 | 0.930 | −5 | 192 | 188 | 0.77 |
| Perilla 2 | 0.937 | −4 | 208 | 197 | 4.85 |
| Cotton 1 | 0.916 | −6 | 99 | 189 | 0.42 |
| Cotton 2 | 0.918 | −1 | 113 | 198 | 3.84 |
| Sesame 1 | 0.920 | −6 | 104 | 187 | 0.91 |
| Sesame 2 | 0.926 | −4 | 116 | 193 | 3.77 |
| Camellia 1 | 0.916 | −21 | 80 | 189 | 2.00 |
| Camellia 2 | 0.917 | −15 | 82 | 193 | 2.98 |
| Olive 1 | 0.914 | 0 | 79 | 187 | 0.83 |
| Olive 2 | 0.919 | 6 | 90 | 196 | 4.02 |
| Beef 1 | 0.860 | 30 | 40 | 190 | 0.31 |
| Beef 2 | 0.870 | 38 | 48 | 199 | 2.89 |
| Hog 1 | 0.858 | 22 | 53 | 190 | 0.37 |
| Hog 2 | 0.864 | 32 | 77 | 202 | 3.65 |
Table 14.
Monotone blocks segmentation (MBS) for oil data.
Table 14.
Monotone blocks segmentation (MBS) for oil data.
| Sub-Object | Iodine Value | Specific Grav. | Freezing p. | Saponific. v. | Major Acids |
|---|
| Beef 1 | 40 | 0.860 | 30 | 190 | 0.31 |
| Beef 2 | 48 | 0.870 | 38 | 199 | 2.89 |
| Hog 1 | 53 | 0.858 | 22 | 190 | 0.37 |
| Hog 2 | 77 | 0.864 | 32 | 202 | 3.65 |
| Olive 1 | 79 | 0.914 | 0 | 187 | 0.83 |
| Camellia 1 | 80 | 0.916 | −21 | 189 | 2.00 |
| Camellia 2 | 82 | 0.917 | −15 | 193 | 2.98 |
| Olive 2 | 90 | 0.919 | 6 | 196 | 4.02 |
| Cotton 1 | 99 | 0.916 | −6 | 189 | 0.42 |
| Sesame 1 | 104 | 0.920 | −6 | 187 | 0.91 |
| Cotton 2 | 113 | 0.918 | −1 | 198 | 3.84 |
| Sesame 2 | 116 | 0.926 | −4 | 193 | 3.77 |
| Linseed 1 | 170 | 0.930 | −27 | 118 | 1.75 |
| Perilla 1 | 192 | 0.930 | −5 | 188 | 0.77 |
| Linseed 2 | 204 | 0.935 | −18 | 196 | 4.81 |
| Perilla 2 | 208 | 0.937 | −4 | 197 | 4.85 |
Table 15.
Lookup table for oil data.
Table 15.
Lookup table for oil data.
| Iodine Value | Specific Gravity | Freezing Point | Major Acid |
|---|
| [40, 77] | [0.858, 0.870] | [22, 38] | |
| [40, 192] | | | [0.31, 4.02] |
| [79, 79] | [0.914, 0.914] | | |
| [79, 113] | [0.916, 0.920] | | |
| [79, 208] | | [−27, 6] | |
| [116, 116] | [0.926, 0.926] | | |
| [170, 192] | [0.930, 0.930] | | |
| [204, 204] | [0.935, 0.935] | | [4.81, 4.81] |
| [208, 208] | [0.937, 0.937] | | [4.85, 4.85] |
Table 16.
Estimated result using LTRM for oil data.
Table 16.
Estimated result using LTRM for oil data.
| Fats and Oils | Estimated by
Specific Gravity | Estimated by
Freezing Point | Estimated by
Major Acid | Actual Value |
|---|
| Linseed | [170, 204] | [79, 208] | [40, 204] | [170, 204] |
| Perilla | [170, 208] | [79, 208] | [40, 208] | [192, 208] |
| Cotton | [80, 113] | [79, 208] | [40, 192] | [99, 113] |
| Sesame | [113, 116] | [79, 208] | [40, 192] | [104, 116] |
| Camellia | [80, 113] | [79, 208] | [40, 192] | [80, 82] |
| Olive | [79, 113] | [79, 208] | [40, 192] | [79, 90] |
| Beef | [40, 77] | [40, 77] | [40, 192] | [40, 48] |
| Hog | [40, 77] | [40, 77] | [40, 192] | [53, 77] |
Table 17.
Lookup table of hardwood data.
Table 17.
Lookup table of hardwood data.
| GDC5 | ANNT | JANT | JULT |
|---|
| [0.1, 0.1] | | | [7.1, 7.1] |
| [0.1, 2.5] | [−12.2, 10.3] | | |
| [0.1, 4.2] | | [−30.9, 6.8] | |
| [0.3, 0.5] | | | [9.7, 11.5] |
| [0.6, 0.9] | | | [12.5, 14.8] |
| [1.0, 1.1] | | | [14.9, 15.2] |
| [1.1, 6.8] | | | [15.6, 30.4] |
| [2.7, 3.1] | [11.2, 12.6] | | |
| [3.5, 3.6] | [14.1, 14.6] | | |
| [3.7, 4.3] | [15.0, 16.4] | | |
| [4.3, 6.5] | | [7.0, 15.3] | |
| [4.5, 4.8] | [17.2, 18.7] | | |
| [5.2, 5.5] | [19.1, 19.9] | | |
| [5.6, 5.9] | [20.6, 21.2] | | |
| [6.0, 6.5] | [21.4, 22.7] | | |
| [6.5, 6.9] | | [16.9, 18.9] | |
| [6.7, 7.0] | [23.2, 24.4] | | |
| [6.9, 8.5] | | | [31.3, 33.8] |
| [7.0, 7.0] | | [19.6, 19.6] | |
| [8.5, 8.5] | [26.6, 27.2] | [26.2, 26.2] | |
Table 18.
Test data for the lookup table of hardwood data.
Table 18.
Test data for the lookup table of hardwood data.
| TAXON NAME | Quantiles (%) |
|---|
| 0 | 10 | 25 | 50 | 75 | 90 | 100 |
|---|
| BETURA | GDC5 | 0.0 | 0.3 | 0.6 | 0.9 | 1.5 | 3.2 | 5.7 |
| ANNT | −13.4 | −8.4 | −5.1 | −1.0 | 3.9 | 12.6 | 20.3 |
| CARYA | GDC5 | 1.4 | 2.1 | 2.6 | 3.4 | 4.5 | 5.2 | 6.7 |
| ANNT | 3.6 | 7.5 | 10.0 | 13.6 | 17.2 | 19.4 | 23.5 |
| CASTANEA | GDC5 | 1.4 | 2.2 | 2.8 | 3.7 | 4.6 | 5.2 | 6 |
| ANNT | 4.4 | 8.6 | 11.3 | 14.9 | 17.5 | 19.2 | 21.5 |
| CAPRINUS | GDC5 | 1 | 1.6 | 2 | 2.9 | 4.1 | 5.2 | 8.6 |
| ANNT | 1.2 | 4.4 | 7 | 11.4 | 16 | 19.2 | 28 |
| TILIA | GDC5 | 1.0 | 1.6 | 1.9 | 2.4 | 3.0 | 3.6 | 5.4 |
| ANNT | 1.1 | 3.8 | 5.8 | 8.8 | 12.0 | 14.4 | 19.9 |
| ULMUS | GDC5 | 0.8 | 1.3 | 1.7 | 2.6 | 3.9 | 5 | 6.8 |
| ANNT | −2.3 | 1.7 | 4.9 | 9.7 | 15.3 | 18.6 | 23.8 |
Table 19.
Estimated result for the test data.
Table 19.
Estimated result for the test data.
| TAXON NAME | Quantiles (%) |
|---|
| 0 | 10 | 25 | 50 | 75 | 90 | 100 |
|---|
| BETURA | GDC5 | 0.0 | 0.3 | 0.6 | 0.9 | 1.5 | 3.2 | 5.7 |
| Estimated | <0.1 | [0.1, 2.5] | | 3.1 | 5.6 |
| CARYA | GDC5 | 1.4 | 2.1 | 2.6 | 3.4 | 4.5 | 5.2 | 6.7 |
| Estimated | [0.1, 2.5] | | [3.1, 3.6] | 4.5 | [5.2, 5.5] | [6.7, 7.0] |
| CASTANEA | GDC5 | 1.4 | 2.2 | 2.8 | 3.7 | 4.6 | 5.2 | 6 |
| Estimated | [0.1, 2.5] | [2.7, 3.1] | 3.7 | [4.5, 4.8] | [5.2, 5.5] | [6.0, 6.5] |
| CAPRINUS | GDC5 | 1 | 1.6 | 2 | 2.9 | 4.1 | 5.2 | 8.6 |
| Estimated | [0.1, 2.5] | [2.7, 3.1] | [3.7, 4.3] | [5.2, 5.5] | 8.5< |
| TILIA | GDC5 | 1.0 | 1.6 | 1.9 | 2.4 | 3.0 | 3.6 | 5.4 |
| Estimated | [0.1, 2.5] | [2.7, 3.1] | [3.5, 3.6] | [5.2, 5.5] |
| ULMUS | GDC5 | 0.8 | 1.3 | 1.7 | 2.6 | 3.9 | 5 | 6.8 |
| Estimated | [0.1, 2.5] | [3.7, 4.3] | [4.5, 4.8] | [6.7, 7.0] |
Table 20.
Lookup table for cluster C1 = (AcW, AlW).
Table 20.
Lookup table for cluster C1 = (AcW, AlW).
| GDC5 | ANNT | JANT | JULT |
|---|
| [0.1, 0.1] | | | [7.1, 7.1] |
| [0.1, 0.9] | [−12.2, 1.9] | [−30.5, −10.1] | |
| [0.5, 0.5] | | | [11.3, 11.5] |
| [0.7, 0.7] | | | [11.8, 12.8] |
| [0.9, 1.1] | | | [14.4, 15.6] |
| [1.1, 1.1] | [3.2, 4.2] | [−7.6, −6.9] | |
| [1.6, 1.6] | [7.5, 7.6] | [−1.3, −0.8] | [17.5, 17.6] |
| [2.2, 2.2] | [10.3, 10.3] | [3.3, 3.3] | [19.9, 19.9] |
| [4.8, 4.8] | [18.7, 18.7] | [10.8, 10.8] | [28.3, 28.3] |
| [5.6, 5.6] | [20.5, 20.6] | [11.0, 11.0] | [29.2, 29.2] |
Table 21.
Lookup table for cluster C2 = (AcE, AlE, FE, JE, QE).
Table 21.
Lookup table for cluster C2 = (AcE, AlE, FE, JE, QE).
| GDC5 | ANNT | JANT | JULT |
|---|
| [0.1, 0.1] | [−10.2, −10.2] | | [7.1, 7.1] |
| [0.1, 0.6] | | [−30.9, −24.6] | |
| [0.5, 0.5] | | | [11.5, 11.5] |
| [0.5, 0.8] | [−4.4, −1.5] | | |
| [0.6, 0.6] | | | [13.2, 13.2] |
| [0.8, 0.8] | | [−23.8, −22.7] | [13.5, 14.8] |
| [1.0, 1.0] | | | [15.2, 15.2] |
| [1.0, 1.2] | [0.6, 1.3] | | |
| [1.0, 1.3] | | [−18.3, −14.6] | |
| [1.1, 1.1] | | | [16.5, 16.5] |
| [1.2, 1.2] | | | [16.6, 16.6] |
| [1.3, 1.3] | [1.4, 1.4] | | [17.4, 17.4] |
| [1.5, 1.5] | [3.4, 3.8] | | [18.2, 18.4] |
| [1.5, 1.6] | | [−14.5, −12.3] | |
| [1.6, 1.6] | [4.3, 4.3] | | [19.0, 19.0] |
| [1.9, 1.9] | [6.1, 6.1] | | [19.8, 19.8] |
| [1.9, 2.0] | | [−9.7, −8.0] | |
| [2.0, 2.0] | [6.3, 6.9] | | [20.3, 20.5] |
| [2.4, 2.4] | [8.6, 8.6] | [−6.0, −6.0] | |
| [2.4, 2.5] | | | [22.1, 22.2] |
| [2.5, 2.5] | [9.1, 9.2] | [−5.4, −5.1] | |
| [2.9, 2.9] | [11.2, 11.2] | [−2.8, −2.8] | [23.9, 23.9] |
| [3.1, 3.1] | [12.4, 12.4] | [−1.0, −1.0] | [24.7, 24.7] |
| [3.5, 3.5] | [14.1, 14.1] | [1.7, 1.7] | |
| [3.5, 3.7] | | | [25.7, 25.8] |
| [3.6, 3.6] | [14.4, 14.4] | [2.3, 2.3] | |
| [3.7, 3.7] | [15.0, 15.0] | [3.7, 3.7] | |
| [3.9, 3.9] | [15.5, 15.5] | [3.8, 3.8] | [26.4, 26.4] |
| [4.2, 4.2] | [16.4. 16.4] | [5.0, 5.0] | [26.9, 26.9] |
| [4.7, 4.7] | [17.6, 17.6] | [7.0, 7.0] | |
| [4.7, 4.8] | | | [27.3, 27.7] |
| [4.8, 4.8] | [17.9, 17.9] | [7.5, 7.9] | |
| [5.2, 5.2] | [19.1, 19.1] | [9.5, 9.5] | |
| [5.2, 6.8] | | | [28.0, 29.5] |
| [5.9, 5.9] | [20.9, 20.9] | | |
| [5.9, 6.0] | | [12.4, 14.1] | |
| [6.0, 6.0] | [21.4, 21.4] | | |
| [6.7, 6.7] | [23.2, 23.2] | [18.1, 18.1] | |
| [6.8, 6.8] | [23.8, 23.8] | [18.9, 18.9] | |
| [7.0, 7.0] | [24.2, 24.2] | [19.6, 19.6] | [31.8, 31.8] |
Table 22.
Lookup table for cluster C3 = (FW, JW, QW).
Table 22.
Lookup table for cluster C3 = (FW, JW, QW).
| GDC5 | ANNT | JANT | JULT |
|---|
| [0.3, 0.3] | [−1.5, −1.5] | [−12.0, −12.0] | [9.7, 9.7] |
| [0.9, 0.9] | [2.6,2.6] | [−7.4, −7.4] | [12.5, 12.5] |
| [1.4, 1.4] | [6.0, 6.0] | [−5.4, −5.4] | [16.2, 16.2] |
| [1.6, 1.6] | [7.3, 7.3] | [−1.3, −1.3] | [17.1, 17.1] |
| [2.0, 2.0] | [9.4, 9.5] | [−0.2, 0.2] | [18.0, 18.9] |
| [2.7, 2.7] | [11.5, 11.5] | | |
| [2.7, 3.0] | | [3.3, 3.5] | |
| [2.7, 3.6] | | | [20.0, 21.2] |
| [3.0, 3.0] | [12.6, 12.6] | | |
| [3.5, 3.5] | [14.1, 14.1] | [5.6, 5.6] | |
| [3.6, 3.6] | [14.6, 14.6] | [6.8, 6.8] | |
| [4.3, 4.3] | [16.3, 16.3] | [8.8, 8.8] | [22.7, 22.7] |
| [4.5, 4.5] | [17.2, 17.2] | [9.1, 9.1] | |
| [4.5, 4.8] | | | [24.2, 24.3] |
| [4.8, 4.8] | [17.9, 17.9] | [11.3, 11.3] | |
| [5.4, 5.4] | [19.4, 19.4] | [12.5, 12.5] | [25.3, 25.3] |
| [5.5, 5.5] | [19.9, 19.9] | | |
| [5.5, 6.5] | | [14.7, 15.3] | [27.4, 30.4] |
| [6.5, 6.5] | [22.7, 22.7] | [18.4, 18.4] | |
| [8.5, 8.5] | [26.6, 27.2] | [26.2, 26.2] | [31.3, 33.8] |
Table 23.
Estimated result for the test data by lookup table for cluster C2.
Table 23.
Estimated result for the test data by lookup table for cluster C2.
| TAXON NAME | Quantiles (%) |
|---|
| 0 | 10 | 25 | 50 | 75 | 90 | 100 |
|---|
| BETURA | GDC5 | 0.0 | 0.3 | 0.6 | 0.9 | 1.5 | 3.2 | 5.7 |
| Estimated | <0.1 | [0.1, 0.5] | 0.5 | [0.8, 1.0] | [1.5, 1.6] | [3.1, 3.5] | [5.2, 5.9] |
| CARYA | GDC5 | 1.4 | 2.1 | 2.6 | 3.4 | 4.5 | 5.2 | 6.7 |
| Estimated | 1.5 | [2.0, 2.4] | [2.5, 2.9] | [3.1, 3.5] | [4.2, 4.7] | [5.2, 5.9] | [6.7,6.8] |
| CASTANEA | GDC5 | 1.4 | 2.2 | 2.8 | 3.7 | 4.6 | 5.2 | 6.0 |
| Estimated | 1.6 | 2.4 | 2.9 | 3.7 | 4.7 | 5.2 | 6.0 |
| CAPRINUS | GDC5 | 1.0 | 1.6 | 2.0 | 2.9 | 4.1 | 5.2 | 8.6 |
| Estimated | [1.0, 1.2] | 1.6 | 2.0 | 2.9 | [3.9, 4.2] | 5.2 | >7.0 |
| TILIA | GDC5 | 1.0 | 1.6 | 1.9 | 2.4 | 3.0 | 3.6 | 5.4 |
| Estimated | [1.0, 1.2] | 1.5 | 1.9 | 2.4 | 3.1 | 3.6 | [5.2, 5.9] |
| ULMUS | GDC5 | 0.8 | 1.3 | 1.7 | 2.6 | 3.9 | 5 | 6.8 |
| Estimated | [0.5,0.8] | [1.3, 1.5] | [1.6, 1.9] | [2.5, 2.9] | [3.7, 3.9] | [4.8, 5.2] | 6.8 |






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}