

Reliability of Extreme Wind Speeds Predicted by Extreme-Value Analysis


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- That the generalized extreme value distribution (GEV) for epoch maxima and its corollary for peak-over-threshold data, the generalized Pareto distribution (GPD), are suitable to represent extreme winds because they empirically fit the observed sub-asymptotic characteristics. The consequential prediction of a maximum upper limit to the wind speed is sometimes taken to be real (as incorporated into the Australian wind code) although no physical constraints exist to support the limit values.
- That GEV and GPD are unsuitable because:
- GEV and GPD are asymptotic models, and is too small [4] for convergence.
- EV theory predicts that wind observations fall into the domain of attraction of the Gumbel distribution [5], which is unlimited in the upper tail.
- A better GEV/GPD fit to observed or synthetic wind speeds is purely empirical and only valid within the fitted range. Extrapolations to MRI beyond the record length converge towards the wrong asymptote.
2. Materials and Methods
2.1. Bootstrap Simulations
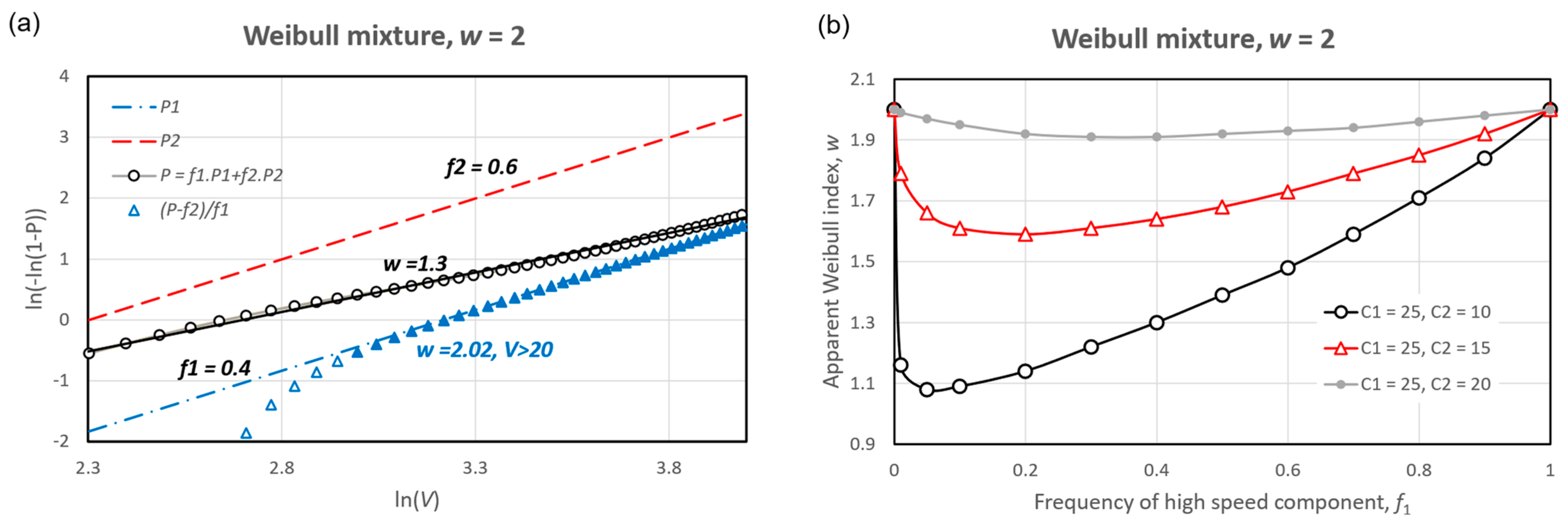
2.1.1. Source Distributions
2.1.2. Epoch Maxima
2.1.3. POT Values
2.2. The Extreme-Value Models
2.2.1. Asymptotic Distributions
2.2.2. Penultimate Distribution
2.3. Some Example Model Fits
3. Results
3.1. Bootstrap Trials: Phase 1
3.1.1. Source Parameters
3.1.2. Expectation of Results
3.1.3. Reliability of Predictions
Bias Errors
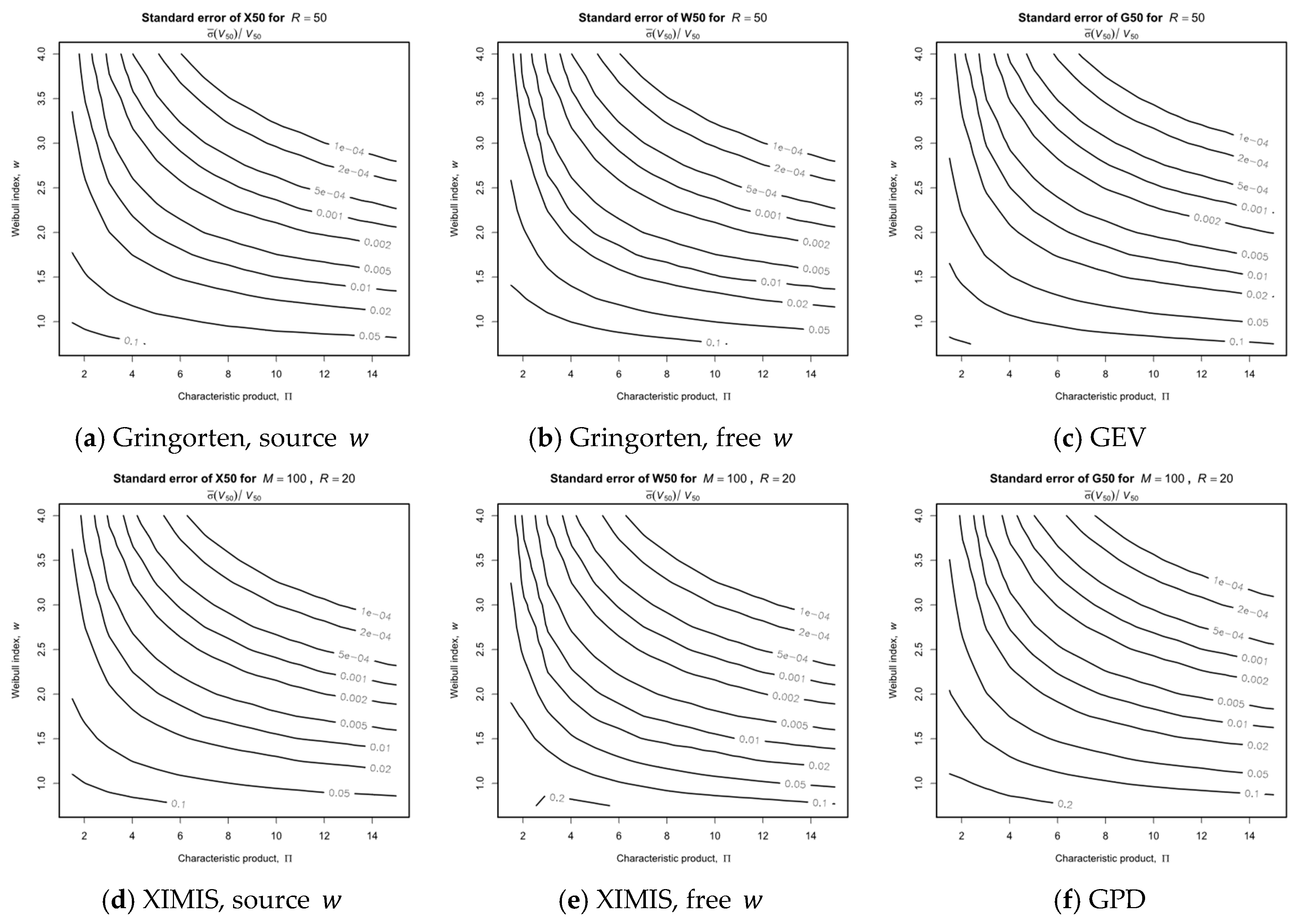
Standard Errors
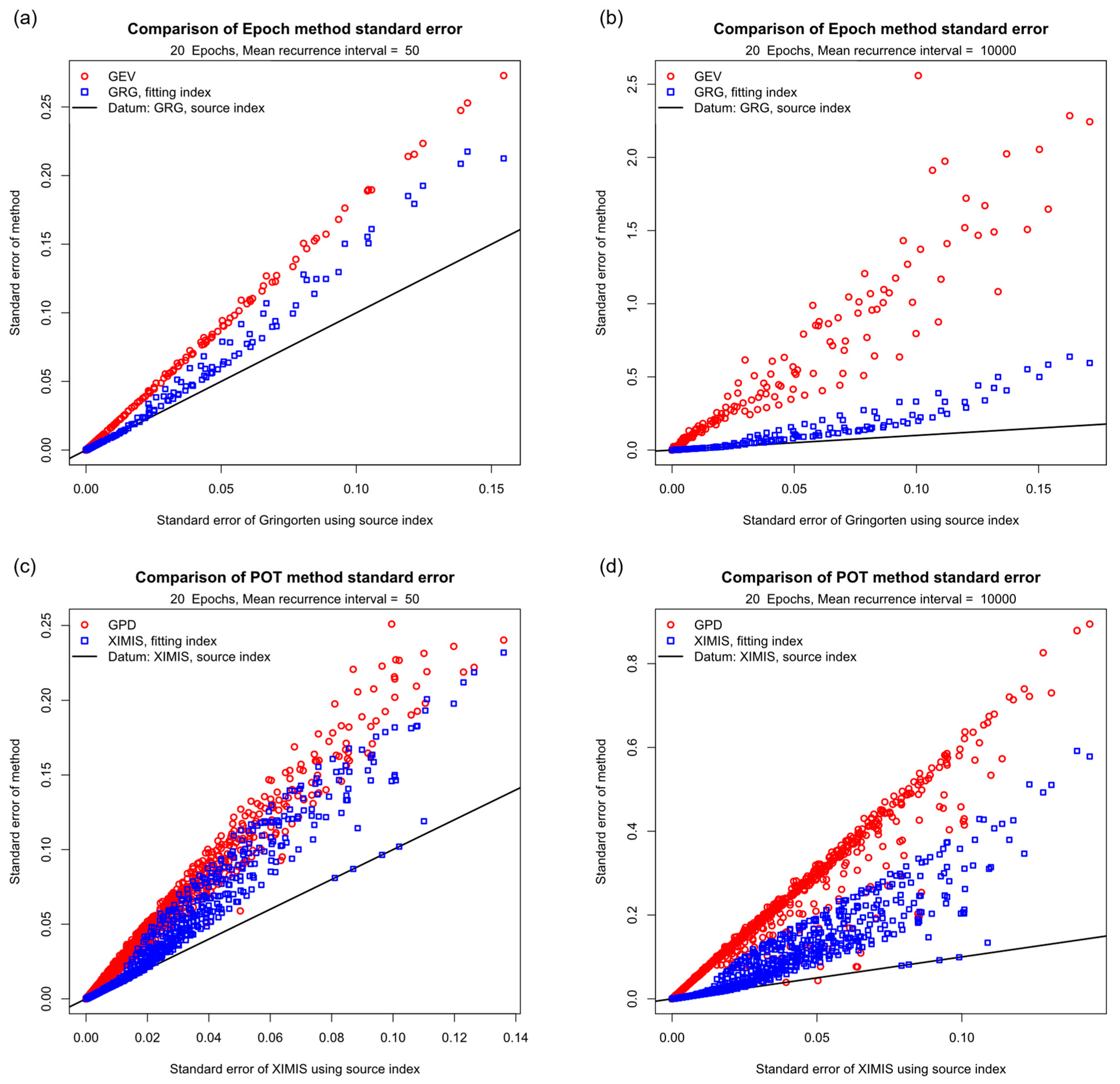
3.1.4. Performance Overview
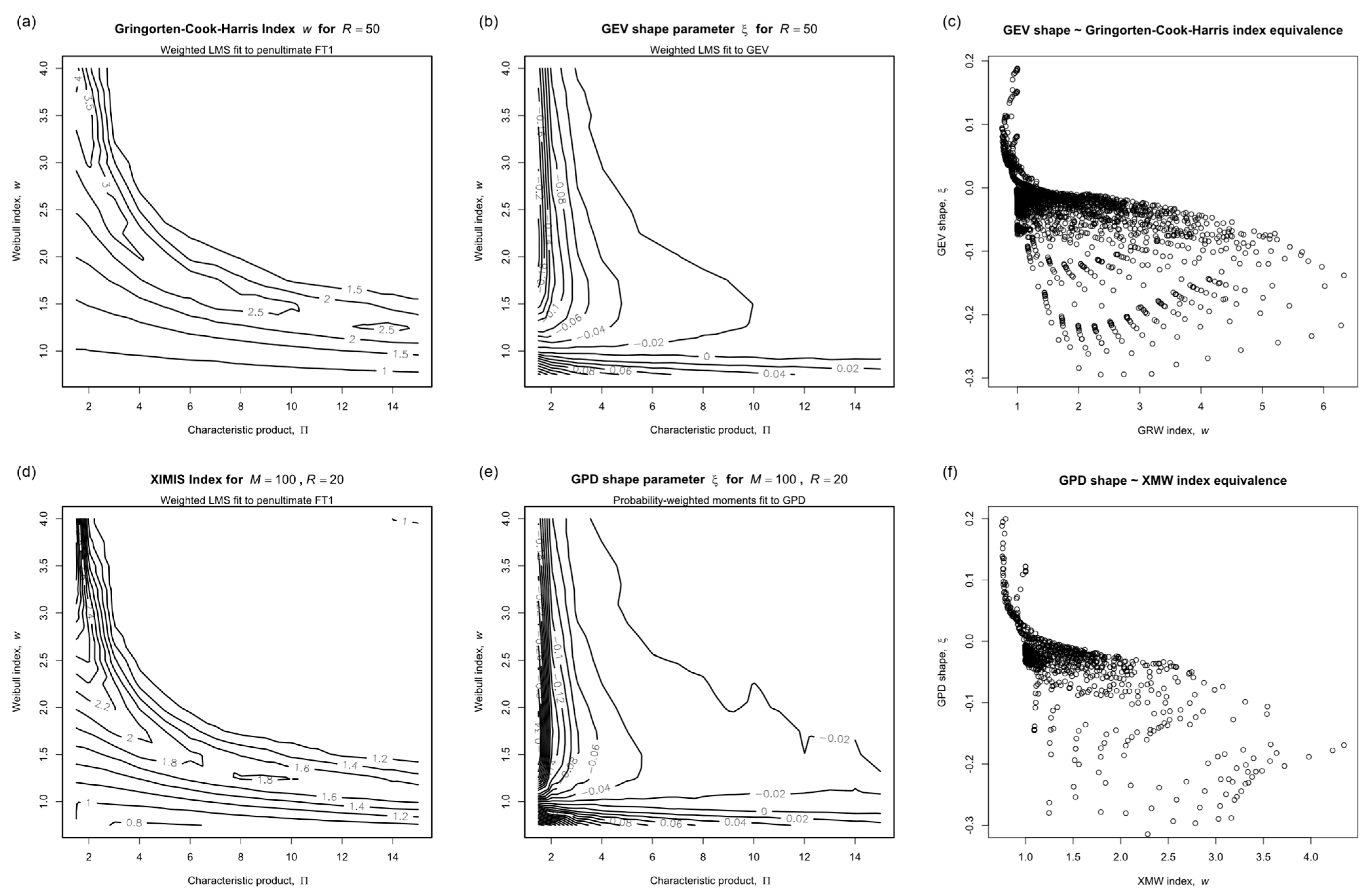
3.1.5. Shape Parameter
3.2. Bootstrap Trials: Phase 2
3.2.1. Preamble
3.2.2. Peak over Threshold Observations
3.2.3. Reliability of Shape Parameter Estimates
3.2.4. Standard Errors for XIMIS Preconditioning Options
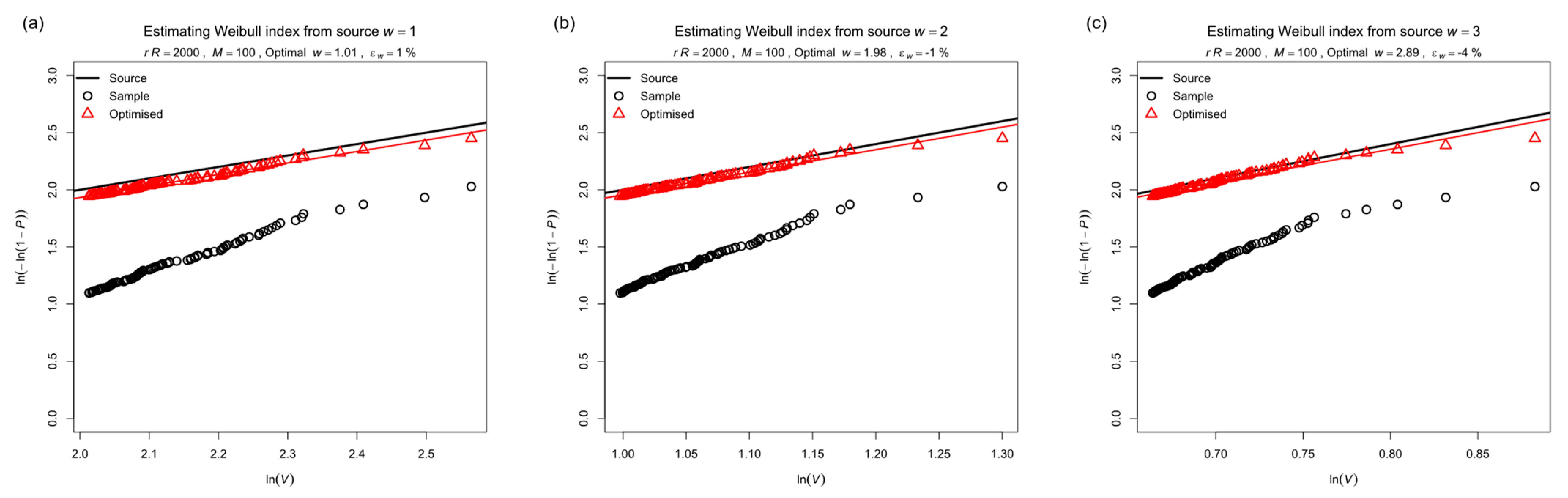
- Fitting the top values to the Weibull distribution where in (15) is the POT population, , or has been directly counted by identifying independent events.
- Optimizing for the value of that gives the best fit to the Weibull distribution.
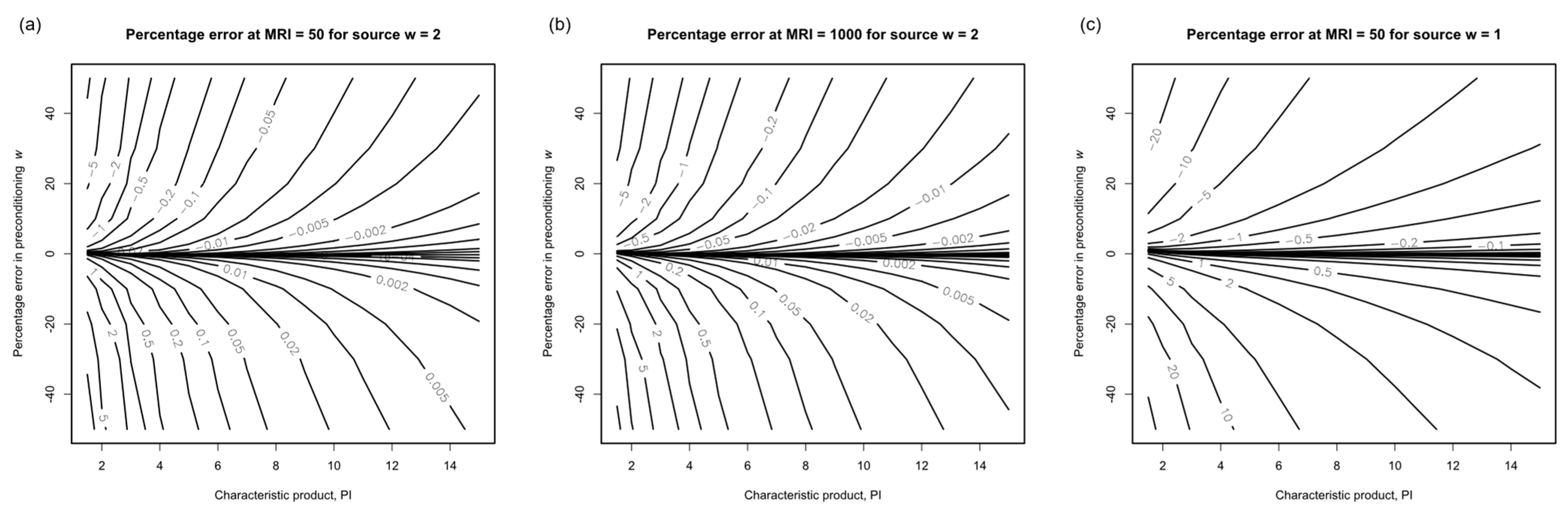
3.2.5. Characteristic Product
3.2.6. Sensitivity of XIMIS Predictions to the Shape Parameter,
3.3. Bootstrap Trials: Phase 3
3.3.1. Preamble
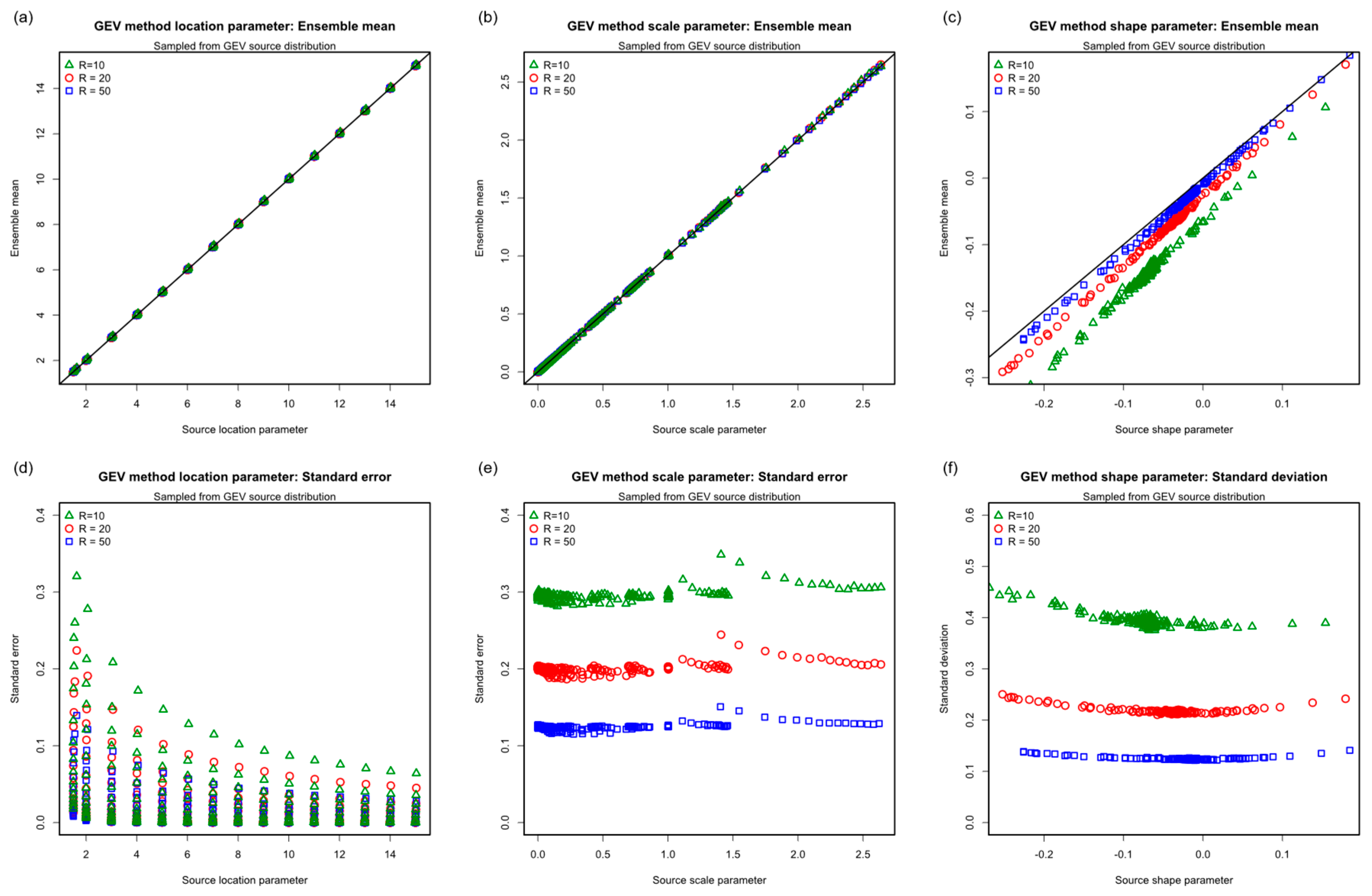
3.3.2. Source and Fitted GEV Parameters
3.3.3. Bias Errors
3.3.4. Standard Errors
3.3.5. Performance Overview
4. Discussion and Prospects
- Locating the ASOS anemometers with good (WMO Class 1 or 2) exposures [28];
- Curating the ASOS data to detect, remove or repair errors and artefacts [29] for these sites;
- Classifying all gust events exceeding 20 kn [27] and separating into disjoint components by causal mechanism; and
- Determining the effect that the “Test 10” ASOS real-time quality control algorithm has in erroneously culling valid observations since its introduction in 2014, and the impact this has on the assessment of extreme gusts [30].
5. Conclusions
- Peak-over-threshold methods are shown to always be more reliable than epoch methods due to the additional sub-epoch data.
- Predictions from the generalized asymptotic methods are always less reliable than those from the sub-asymptotic methods by a factor that increases with the mean recurrence interval.
- These conclusions reinforce the previously published theoretical and statistical arguments for using the sub-asymptotic Type 1 model and against using the GEV/GPD for assessing extreme wind speeds.
- A new two-step Weibull-XIMIS hybrid sub-asymptotic method is shown to have superior reliability.
Supplementary Materials
Funding
Data Availability Statement
Conflicts of Interest
References
- Efron, B.; Tibshirani, R. An Introduction to the Bootstrap. In Monographs on Statistics and Applied Probability; Chapman & Hall: New York, NY, USA, 1993; ISBN 978-0-412-04231-7. [Google Scholar]
- Cook, N.J. Towards Better Estimation of Extreme Winds. J. Wind. Eng. Ind. Aerodyn. 1982, 9, 295–323. [Google Scholar] [CrossRef]
- Simiu, E.; Heckert, N.A. Extreme Wind Distribution Tails: A “Peaks over Threshold” Approach. J. Struct. Eng. 1996, 122, 539–547. [Google Scholar] [CrossRef] [Green Version]
- Galambos, J.; Macri, N. Classical Extreme Value Model and Prediction of Extreme Winds. J. Struct. Eng. 1999, 125, 792–794. [Google Scholar] [CrossRef]
- Castillo, E. Extreme Value Theory in Engineering; Academic Press: San Diego, CA, USA, 1988. [Google Scholar]
- Harris, R.I. XIMIS, a Penultimate Extreme Value Method Suitable for All Types of Wind Climate. J. Wind. Eng. Ind. Aerodyn. 2009, 97, 271–286. [Google Scholar] [CrossRef]
- Harris, R.I.; Cook, N.J. The Parent Wind Speed Distribution: Why Weibull? J. Wind. Eng. Ind. Aerodyn. 2014, 131, 72–87. [Google Scholar] [CrossRef]
- Cook, N.J.; Harris, R.I. Exact and General FT1 Penultimate Distributions of Extreme Wind Speeds Drawn from Tail-Equivalent Weibull Parents. Struct. Saf. 2004, 26, 391–420. [Google Scholar] [CrossRef]
- Gumbel, E.J. Statistics of Extremes; Columbia University Press: New York, NY, USA, 1958; ISBN 978-0-231-02190-6. [Google Scholar]
- Gringorten, I.I. A Plotting Rule for Extreme Probability Paper. J. Geophys. Res. 1963, 68, 813–814. [Google Scholar] [CrossRef]
- Cook, N.J.; Harris, R.I. The Gringorten Estimator Revisited. Wind. Struct. 2013, 16, 355–372. [Google Scholar] [CrossRef]
- Cook, N. Designers’ Guide to EN 1991-1-4: Eurocode 1 Actions on Structures, General Actions; Eurocode designers’ guide series; Thomas Telford Publishing: London, UK, 2007; ISBN 978-0-7277-3152-4. [Google Scholar]
- Cook, N.J. The OEN Mixture Model for the Joint Distribution of Wind Speed and Direction: A Globally Applicable Model with Physical Justification. Energy Convers. Manag. 2019, 191, 141–158. [Google Scholar] [CrossRef]
- Zhang, S.; Solari, G.; Yang, Q.; Repetto, M.P. Extreme Wind Speed Distribution in a Mixed Wind Climate. J. Wind. Eng. Ind. Aerodyn. 2018, 176, 239–253. [Google Scholar] [CrossRef]
- Torrielli, A.; Repetto, M.P.; Solari, G. Extreme Wind Speeds from Long-Term Synthetic Records. J. Wind. Eng. Ind. Aerodyn. 2013, 115, 22–38. [Google Scholar] [CrossRef]
- Gomes, L.; Vickery, B.J. Extreme Wind Speeds in Mixed Wind Climates. J. Wind. Eng. Ind. Aerodyn. 1978, 2, 331–344. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Mitra, D. Left Truncated and Right Censored Weibull Data and Likelihood Inference with an Illustration. Comput. Stat. Data Anal. 2012, 56, 4011–4025. [Google Scholar] [CrossRef]
- Holmes, J.D.; Moriarty, W.W. Application of the Generalized Pareto Distribution to Extreme Value Analysis in Wind Engineering. J. Wind. Eng. Ind. Aerodyn. 1999, 83, 1–10. [Google Scholar] [CrossRef]
- Cook, N.J.; Harris, R.I. Postscript to “Exact and General FT1 Penultimate Distributions of Extreme Wind Speeds Drawn from Tail-Equivalent Weibull Parents”. Struct. Saf. 2008, 30, 1–10. [Google Scholar] [CrossRef]
- Cook, N.J. A Statistical Model of the Seasonal-Diurnal Wind Climate at Adelaide. Aust. Meteorol. Oceanogr. J. 2015, 65, 206–232. [Google Scholar] [CrossRef]
- Cook, N.J. Parameterizing the Seasonal–Diurnal Wind Climate of Rome: Fiumicino and Ciampino. Meteorol. Appl. 2020, 27, e1848. [Google Scholar] [CrossRef] [Green Version]
- Davenport, A.G. The Dependence of Wind Loads on Meteorological Parameters. In Proceedings of the Second International Conference on Wind Effects, Ottawa, Canada, 11–15 September 1967; University of Toronto Press: Toronto, ON, Canada, 1967. [Google Scholar]
- Vallis, M.B.; Loredo-Souza, A.M.; Ferreira, V.; Nascimento, E.D.L. Classification and Identification of Synoptic and Non-Synoptic Extreme Wind Events from Surface Observations in South America. J. Wind. Eng. Ind. Aerodyn. 2019, 193, 103963. [Google Scholar] [CrossRef]
- Chen, G.; Lombardo, F.T. An Automated Classification Method of Thunderstorm and Non-Thunderstorm Wind Data Based on a Convolutional Neural Network. J. Wind. Eng. Ind. Aerodyn. 2020, 207, 104407. [Google Scholar] [CrossRef]
- Solari, G.; Burlando, M.; Repetto, M.P. Detection, Simulation, Modelling and Loading of Thunderstorm Outflows to Design Wind-Safer and Cost-Efficient Structures. J. Wind. Eng. Ind. Aerodyn. 2020, 200, 104142. [Google Scholar] [CrossRef]
- Arul, M.; Kareem, A.; Burlando, M.; Solari, G. Machine Learning Based Automated Identification of Thunderstorms from Anemometric Records Using Shapelet Transform. J. Wind. Eng. Ind. Aerodyn. 2022, 220, 104856. [Google Scholar] [CrossRef]
- Cook, N.J. Automated Classification of Gust Events in the Contiguous USA. J. Wind. Eng. Ind. Aerodyn. 2023, 234, 105330. [Google Scholar] [CrossRef]
- Cook, N.J. Locating the Anemometers of the US ASOS Network and Classifying Their Local Shelter. Weather 2022, 77, 256–263. [Google Scholar] [CrossRef]
- Cook, N.J. Curating the TD6405 Database of 1-Min Interval Wind Observations across the USA for Use in Wind Engineering Studies. J. Wind. Eng. Ind. Aerodyn. 2022, 224, 104961. [Google Scholar] [CrossRef]
- Cook, N.J. Impact of ASOS real-time quality control on convective gust extremes in the USA. Meteorology 2023, 2, 276–294. [Google Scholar] [CrossRef]




















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cook, N.J. Reliability of Extreme Wind Speeds Predicted by Extreme-Value Analysis. Meteorology 2023, 2, 344-367. https://doi.org/10.3390/meteorology2030021
Cook NJ. Reliability of Extreme Wind Speeds Predicted by Extreme-Value Analysis. Meteorology. 2023; 2(3):344-367. https://doi.org/10.3390/meteorology2030021
Chicago/Turabian StyleCook, Nicholas John. 2023. "Reliability of Extreme Wind Speeds Predicted by Extreme-Value Analysis" Meteorology 2, no. 3: 344-367. https://doi.org/10.3390/meteorology2030021
APA StyleCook, N. J. (2023). Reliability of Extreme Wind Speeds Predicted by Extreme-Value Analysis. Meteorology, 2(3), 344-367. https://doi.org/10.3390/meteorology2030021