1. Introduction
The evolution of technology has allowed the banking sector to offer most of its services via the Internet. Currently, a person can register, make money transfers, and even take out loans without direct interaction with a bank employee [
1]. For a person to have access to the online services of a banking institution, they must first go through the digital onboarding (DO) stage. In the context of online banking, DO encompasses the identification process in which a person enters their personal data into the bank’s system through a series of steps, essentially allowing anyone with Internet access and a mobile device to create a bank account at any time at any place.
Although this paradigm of online interaction between banks and customers is beneficial to both, it is up to banks and financial organisations to ensure a reliable, secure, and fraud-free environment for banking services [
2]. The availability of these services on the Internet brought with it great challenges in terms of combating fraud since fraudsters have access to digital tools and technologies designed to try to exploit security flaws in banking systems [
2,
3].
Considering that DO is essentially the gateway to the services of a banking system, its protection is crucial for preserving the integrity of any digital bank. One type of common fraud is identity fraud, in which fraudsters, armed with personal data obtained illegally, try to impersonate other people in order to gain access to banking services illicitly. Manually checking each person’s documents that go through the DO stage of a bank can be very time- and resource-consuming and frankly not feasible depending on the volume of onboarding requests.
To prevent this type of identity fraud in DO, institutions can also rely on new digital tools, technologies, and the detailed data they have on their services [
4]. A possible solution could be the application of computer vision approaches to try to assess the validity of users’ documents sent during the DO stage by analysing factors such as image quality, document quality, or whether the document owner’s photo corresponds to a selfie, for example. Another possibility is the application of a biometric analysis of users, that is, a financial institution could verify the identity of a customer in the onboarding [
5] process by trying to match their fingerprint from a database of people’s fingerprints. There is also a nondisruptive type of approach, which does not require any extra action from users in DO called behavioural analysis, which proposes to identify and measure patterns in the way that fraudulent users and legitimate users interact with their devices in order to find possible differences in behaviour between the two [
6].
DO dynamics are defined by several stakeholders within an organisation considering the context and goals of the application. Nevertheless, there are a set of rules and activities that are executed given the modelling envisioned by collaborators. Given this business view, one can profit from the vast literature on data-driven analysis of business processes [
4]. Process mining (PM) is the area dedicated to the extraction of knowledge from event data generated from the recording of the execution of business processes [
7]. PM offers a plethora of techniques to provide process-related insights, creating solutions that are specifically tailored for business processes and their stakeholders [
8]. For that, PM lies at the intersection between data mining and business process management since it provides a data-driven approach to finding patterns in event data from business environments. Traditionally, PM focuses on leveraging a model considering the relationships between activities within a process. The model discovery is a valuable product for stakeholders as they can analyse how the process is being enacted in reality. As stated by Teinemaa et al. [
9], a classical process monitoring analysis delivers dashboards reporting the performance of a business process. However, it falls short in the sense that such techniques are offline, only reflecting historical behaviour, thus with a limited range (i.e., mitigation is not always possible). Particularly, predictive process monitoring (PPM) aims to fill this gap by predicting the future behaviour of process instances, enabling actors to take actions according to the forecasted scenarios. PPM contains many subtasks, such as predicting the remaining time of a given instance or the next activity to be executed [
10]. In this work, we focus on outcome-oriented PPM, i.e., the prediction of the last state of a business instance. For instance, in a loan application, the bank would be interested in identifying which users are prone to accept an offer. Therefore, in applying outcome-oriented PPM, the organisation assesses to which extent a user might achieve an expected outcome.
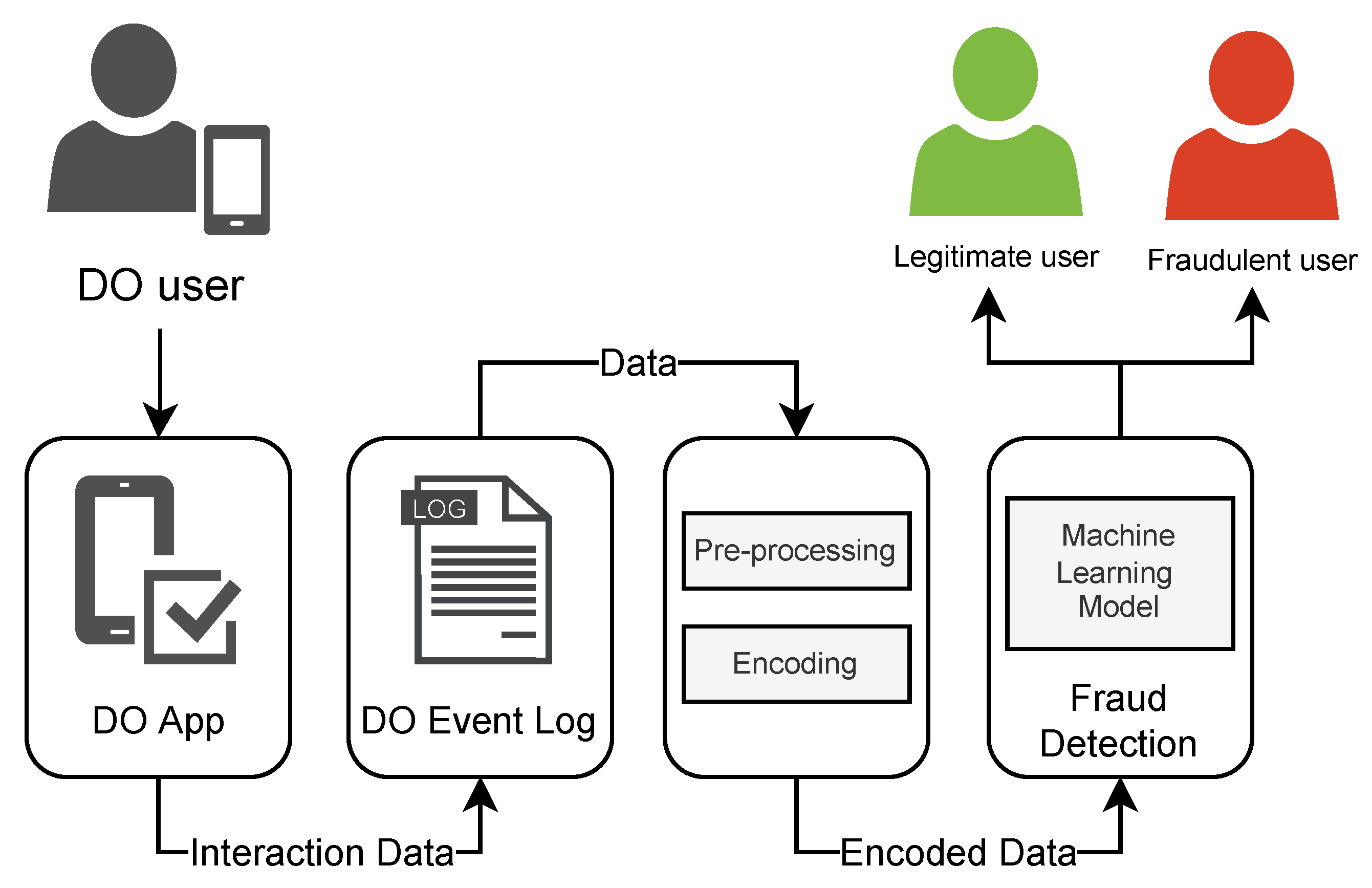
This work aims to propose the usage of PM to mitigate identity fraud in DO. The approach consists of three steps: a combination of event-level and trace-level analysis techniques in a labelled dataset to identify a common sequence of activities done by fraudulent and legitimate users; a representation of these sequences in a vector space using the word2vec algorithm, where similar sequences are closer together; and finally, the classification of embedded vectors with a machine learning (ML) algorithm. The approach used by this work is capable of identifying fraudulent accounts by their DO data with an accuracy of 80% with both random forest (RF) and XGboost (XGB) ML models.
An important contribution of this work is the use of process discovery in DO. By leveraging PM techniques, our approach elucidates the underlying behaviour of fraudulent users of DO. This means treating DO as a sequence of processes gives the ability to classify users in a nondisruptive way to the DO process itself, as it does not require direct user actions such as taking a selfie or collecting a fingerprint. Furthermore, the approach is designed to protect user privacy and personal information, as it only requires data about their interaction with the system, without the need for personal data collection. A side result we obtained is the creation of a dataset of the event logs from the DO process carried out by fraudulent or legitimate fintech accounts.
The remainder of this paper is organised as follows.
Section 2 brings a review of related works on the use of PM for fraud detection in the literature.
Section 3 provides the necessary background on predictive process monitoring for this work.
Section 4 describes in depth the dataset developed for the production of this work, in addition to the processing performed on the analysed data.
Section 5 presents the results obtained.
Section 6 brings important discussions regarding the obtained results and finally,
Section 7 concludes the work.
2. Related Work
PM has a wide range of potential applications in financial systems. It can be used to identify patterns and bottlenecks in processes, optimise workflows, and detect fraudulent activities [
4]. In particular, process mining can be applied to improve customer experience by analysing customer behaviour and identifying areas where processes can be streamlined to reduce wait times or improve service quality [
11]. In addition, process mining can be used to improve compliance with regulatory requirements, such as anti-money-laundering regulations, by identifying and analysing suspicious transaction patterns [
12]. Furthermore, process mining can be used to optimise backoffice processes, such as account reconciliations and invoice processing, by identifying inefficiencies and opportunities for automation. These are just a few examples of the potential applications of process mining in financial systems, and as the technology continues to advance, there may be even more opportunities to improve financial processes and services.
Although works that specifically use PM to mitigate identity fraud in DO of financial systems were not found in the literature, there are several other interesting cases of the use of PM and data mining techniques to detect fraud in different domains, such as the work of Alvarenga et al. [
13], which proposed the use of PM and hierarchical clustering in network intrusion alerts generated by intrusion detection systems (IDS). The approach aimed to extract information about the behaviour of attackers in the context of cybersecurity and elucidate the underlying strategies used by attackers to compromise networks in a friendly high-level way. As in our proposal, the work of Alvarenga et al. [
13] was capable of modelling unwanted behaviours in its domain; however, its scope was limited to only viewing behaviours identified as unwanted by third parties, while our proposal goes further by training classifiers to identify new instances as fraudulent or legitimate.
In the context of financial systems, the work by Sarno et al. [
14] proposed a hybrid method between association rule learning (ARL) and PM to create an automated solution for detecting credit card fraud based on historical data. The proposed method used data-aware PM to extract not only activities (e.g., “made”) but also a value associated with that activity (e.g., “amount of loan requested”). After applying PM, there was a validation stage with an expert who identified fraudulent behaviour in the data extracted by PM. Based on behaviours extracted by PM and identified as fraudulent by the expert, association rules were used to classify new cases.
In the study conducted by Werner et al. [
15], they explored the integration of process mining into the audit of financial statements. The audit of financial statements is a highly specialised and complex process, and the increasing digitisation and automation of transaction processing have created new challenges for auditors, as the human component in the manual audit procedures can introduce a vulnerability to error and fraud. A field study was conducted to examine the impact process mining can have if incorporated into contemporary audits by analysing relevant audit standards. The results showed that process mining could be successfully integrated into financial statement audits in compliance with contemporary audit standards and accepted practices, providing a more reliable and robust audit evidence by replacing manual audit procedures.
The work of Jans et al. [
12] conducted a case study on applying PM to discover transactional fraud in internal purchase orders of a financial institution. A process diagnosis was carried out, which basically consisted of a series of extensive analyses executed with the help of experts and the ProM [
16] tool to infer not only the actual structure of the purchase order process but also to identify potential vulnerabilities. The second stage of the case study was responsible for validating different aspects of the structures inferred in the first stage. Unlike our proposal, the objective of Jans et al. [
12] was not to model the behaviour of the user as they went through a fixed process, but rather to create rules and controls that were robust enough so that orders that did skip or violate a step in the designed process could be considered fraudulent (e.g., an order above a certain amount was placed without receiving an approval first).
Despite all of these applications, there is still a gap when it comes to the application of PM for fraud detection in DO. By analysing the event logs generated during the DO process, process mining algorithms can identify patterns and anomalies in the user behaviour, such as the use of fake documents or the manipulation of data, that may indicate fraudulent activity. Process mining can also provide insights into the effectiveness of fraud prevention measures, such as identity verification methods and screening processes. By detecting potential fraud early on, financial institutions can prevent losses and avoid reputational damage. Overall, process mining can provide valuable support for fraud detection in DO, helping financial institutions to identify and mitigate risk more effectively.
3. Predictive Process Monitoring
PM is a body of knowledge, foundations, and techniques that propose a data-driven approach to extract insights about organisational business processes [
7]. Being a data-based approach, methods take as inputs event data that store the execution of activities within a process. A unique
event records the enacting of an
activity along with several possible attributes, such as timestamp, resources, and costs, among others. Note that an activity is also an event attribute. It is important to consider that a business instance may contain several events which can be grouped. Events belonging to the same instance are recognised by their
case identifier. It follows that all events affiliated with the same business process compose an
event log.
Definition 1 (Event, Attribute, Case, Event log). Let Σ be the event universe, i.e., the set of all possible event identifiers. denotes the set of all sequences over Σ. Events may have various attributes, such as a timestamp, activity, resource, cost, and others. Let be the set of attribute names. For any event and an attribute , is the value of attribute A for event e. Let C be the case universe, that is, the set of all possible identifiers of a business case execution. C is the domain of an attribute CASE . An event log L can be viewed as a set of cases , where each event appears only once in the log, i.e., for any two different cases, the intersection of their events is empty.
Naturally, a case contains the sequence of activities executed in a process instance, i.e., its trace. Different cases may share the same trace, hence having the same activity sequence. Each unique trace is considered a variant of the process. Therefore, a process may contain one or multiple trace variants with different frequencies.
Definition 2 (Trace). A trace is a nonempty sequence of events , where each event appears only once and time is nondecreasing, i.e., for . With an abuse of notation, we refer to the activity name of an event as the event itself. Thus, denotes a trace of three subsequent events.
Predictive process monitoring (PPM) is a branch of PM that focuses on forecasting the future of an ongoing case [
10]. It follows that there are several tasks within PPM. For instance, one can predict the remaining time of an ongoing case [
17], the next activity to come [
18], or the outcome of a given instance [
10]. PPM has seen a major uptake in both industry and academia in the last few years mostly due to the compatibility between predictive techniques grounded in data mining and ML in combination with process science [
19]. Furthermore, the area has benefited from using deep learning techniques that inherently capture the sequential data’s characteristic, which is also a common aspect in event data [
20].
In this work, we target outcome-oriented PPM, i.e., the task of predicting the outcome of a given process instance. For example, in a reimbursement process, the user is interested in knowing if the request was accepted (positive outcome) or rejected (negative outcome). For that, capturing the relationships between process attributes is fundamental to correctly mapping the correlations between trace behaviour and expected outcomes. Therefore, properly encoding event data becomes a crucial aspect of outcome-oriented PPM. As stated by Fani et al. [
19], the fundamental component shared among PPM approaches is the transformation method used to obtain a fixed-length representation of process instances. The importance of encoding techniques was also assessed by Barbon et al. [
21]. The authors used several candidate encoding techniques in the context of anomaly detection, which, similarly to outcome-oriented prediction, is a classification problem. The main insight was that there is no unique encoding technique that can be applied to all event logs; however, carefully choosing the transformation method may leverage the quality of posterior techniques applied in the pipeline.
In traditional PPM applications, the goal lies in predicting the future context of incomplete case instances [
9]. For this particular application, we aim at predicting the nature of a complete case. This problem is valuable due to the context of the application. New users creating an account may be submitted to a manual inspection (performed by experts) to verify if the user is a fraud suspect. Considering that expert knowledge is resource-consuming and oftentimes not available, our goal is filtering possible fraudulent behaviour and freeing expert time. PPM is an important tool for fraud prevention in today’s digital age. By analysing patterns and trends in past data, PPM is able to make predictions about future behaviour and identify potential fraudulent activity before it occurs. It also provides a powerful and efficient way to monitor complex digital processes, such as DO, and quickly detect any anomalies or irregularities [
22], which allows companies to stay one step ahead of fraudsters and protect their customers’ data and financial security.
We built upon the traditional PPM prefix function:
Definition 3 (Prefix function [
9]).
Given a trace and a positive integer , . Consequently, in our application, l is always equals n. Given a trace, outcome-oriented PPM aims to forecast its associated label, i.e., its class.
Definition 4 (Labelling function [
9]).
A labelling function is a function that maps a trace σ to its class label with being the domain of the class labels. For outcome predictions, is a finite set of categorical outcomes. As stated previously, outcome-oriented PPM techniques heavily rely on ML-based classifiers. A traditional classifier takes as input a set of features describing the phenomena’s behaviour (independent variables) and their associated labels (dependent variable). Hence, it is necessary to transform event data to a format that is expected by classifiers.
Definition 5 (Encoding function). Let an event log L, the encoding is a function that maps L to a feature space, i.e., where is an n-dimensional real vector space.
The encoding technique may then capture trace behaviour (i.e., relationships between the sequence of activities) and also additional trace attributes. Since additional trace attributes contain important information about the underlying process nature, we take advantage of the timestamp attribute as it may characterise frauds. Given the transformed event space, a classifier assigns a label to a feature vector.
Definition 6 (Classifier [
9]).
A classifier is a function that takes an encoded n-dimensional sequence and estimates its class label. The induction of a classifier is performed by providing the encoded event data and its corresponding classes, known as the training phase. Given a new case, first, the case is projected into the transformed feature space, then the classifier indicates to which class the process instance belongs, i.e., in our application scenario, normal or fraudulent behaviour.
5. Results
We organised our results considering two perspectives: PM (
Section 5.1) and fraud detection performance (
Section 5.2). Both perspectives comprise achievements and performance metrics to support our claimed contribution. The discussions and insights provided are organised in
Section 6.
5.1. PM Perspective
Not in vain, the most researched area within PM is process discovery [
18]. Process discovery techniques aim to capture the relationships between activities and produce a model that can be easily interpreted by humans. Stakeholders benefit from discovery methods by understanding how in reality the process is being executed, uncovering its underlying behaviour. To discover the model for our study case, we chose the heuristic miner (HM) algorithm [
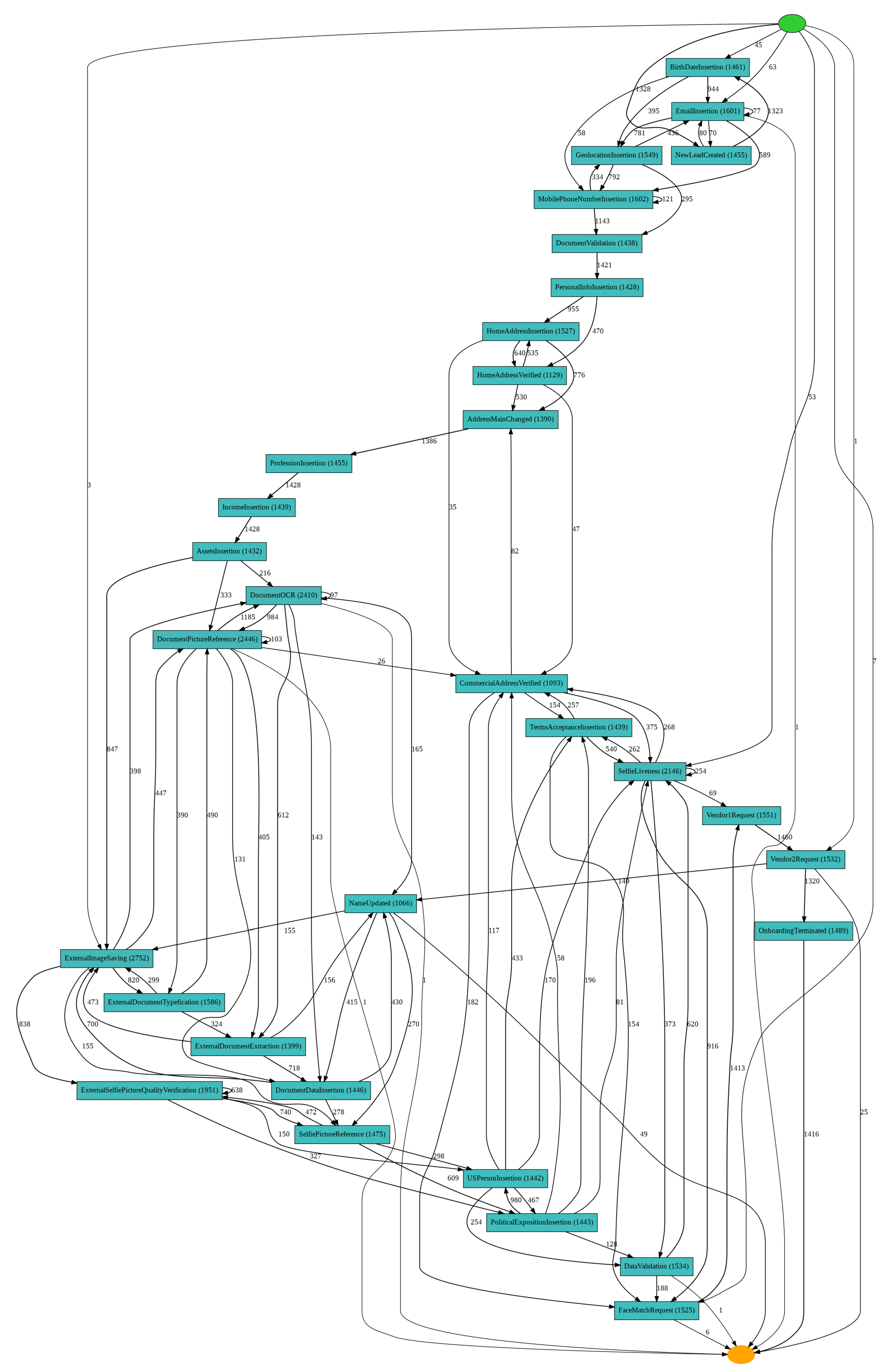
31] given its wide use in research and industry. HM takes frequencies into account and hypothesises that infrequent transitions should not be presented in the model (as they are often outlier behaviour). For that, the algorithm first discovers the directly follows graph representing the activities transitions. Then, using frequencies, a dependency measure is derived and used to guide the creation of a dependency graph. Transitions below a threshold are excluded from the dependency graph. Finally, splits and joins are introduced to represent concurrency.
Figure 2 demonstrates the resulting model after submitting the event log to HM. As we can see, the model had a considerable complexity given the number of transitions between several activities. Nevertheless, many patterns could be identified. For instance, the
NewLeadCreated activity appeared as the most frequent starting activity (1328 cases out of 1500). This kind of analysis is relevant to fraud prevention as it provides important insights regarding users during DO. Stakeholders could use this information to better investigate deviations such as the five cases starting with
ExternalSelfieLivenessGetProcessDivergent or the three cases starting with
ExternalImageSaving. This infrequent behaviour might reveal inconsistencies within the application or possible fraudulent users. The same logic applies for the ending activity, where 1068 cases terminated with
OnboardingTerminated. The one case finishing with
SelfieAndDocumentFailure or the eleven finishing with
DocumentFailure could lead to stakeholders redesigning viable manners to retain a user that goes through failures in the account creation process.
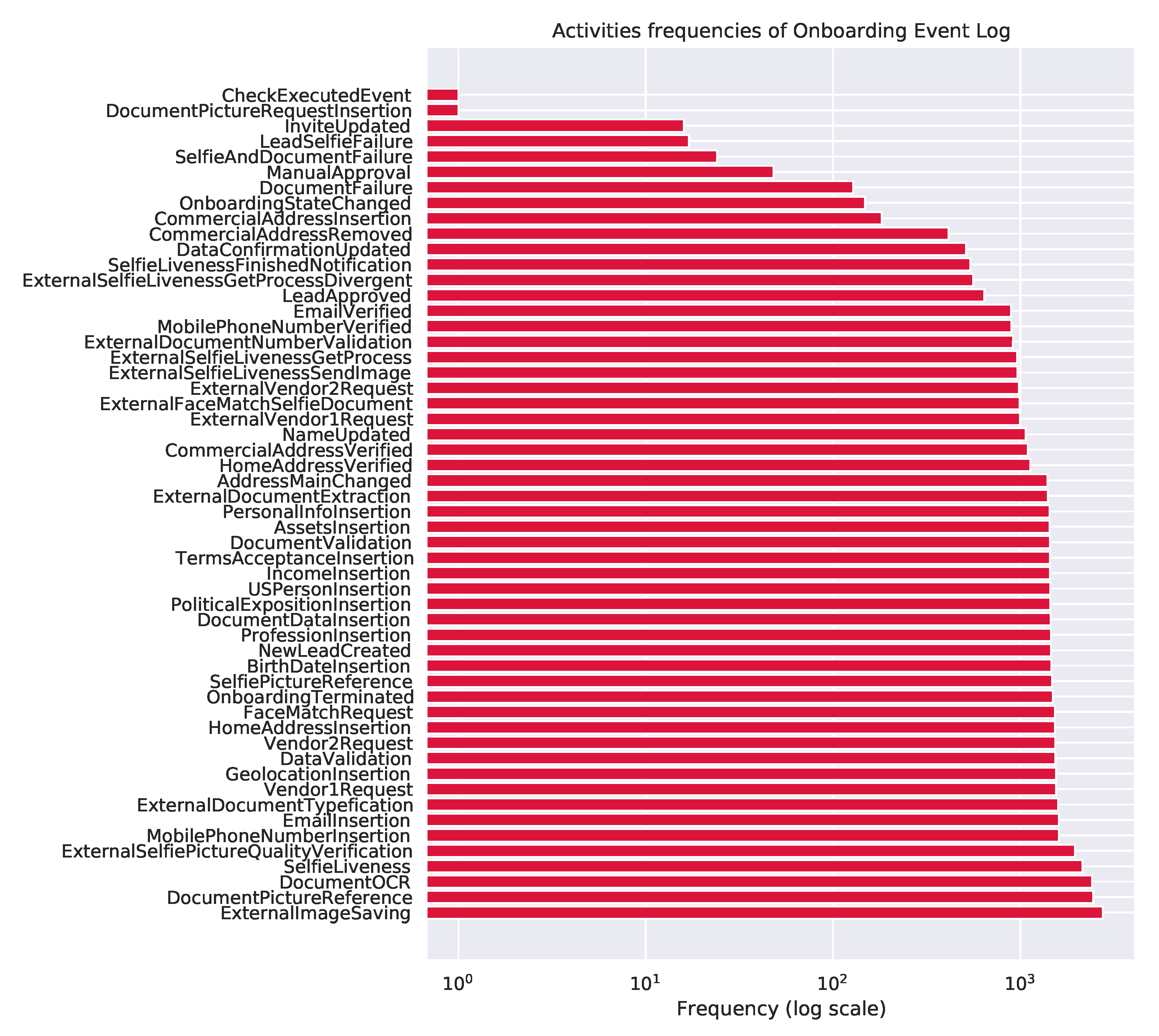
In terms of activity frequencies, significant insights could also be extracted. For instance, the
DocumentPictureRequestInsertion and
CheckExecutedEvent activities were executed only once in the complete event log. Therefore, stakeholders could simplify the process considering that these activities are corner cases that are difficult to deal with and do not necessarily add value to the process. Making the process simpler is helpful to the whole chain, from stakeholders to system maintainers and users. The most frequent activities represented as EventTypes values found in the base are presented in
Figure 3. General process dynamics can also be captured in this representation. Activities
MobilePhoneNumberVerified and
DocumentValidation seemed to be executed concomitantly after
MobilePhoneNumberInsertion. Both also led to
PersonalInfoInsertion, heavily indicating that this behaviour was concurrent. Detecting long-term relationships and loops is also valid for system designers that can then improve the software pipeline. Although the directly follows representation is limited in representing some process-related behaviours such as fraud [
32], its simple construction allows for nonexperts to better grasp process dynamics and improve the overall service quality.
5.2. Fraud Detection
In the context of fraud detection, the results obtained could be divided between the analysis of the classification models for detecting fraud in the acquired dataset and their interpretability (i.e., their capacity to provide insights into the way the algorithms identify fraud).
The first type of analysis began with the application of a 10-fold cross-validation to compare the RF and XGB ability to identify fraud, this meant that the embedded dataset was split into subsets. Then, the subsets were randomly selected to either test a model or to be grouped back together with the rest of the subsets in order to train the classifier and generate a model. A model must be able to map patterns between attribute values and the class of each instance used in its training, while also being able to do it in future new instances [
33]. The selection of folds was repeated ten times, in accordance with the number of folds, where each fold was used for training and at least one time for testing. This type of validation ensured a good setting for evaluating the classifiers since all available data were used and multiple models were generated (ten for each algorithm).
Once trained, each model generated went through the evaluation stage with a test subset. The evaluation was conducted through the analysis of the accuracy metric and F1 score. These two metrics were chosen for their ability to evaluate classification models on an unbalanced dataset, as was the case in this work. The accuracy metric measured only the proportion of the total number of predictions that were correct, while the F1 score took into account the precision and the number of correct positive predictions made out of all positive predictions that could have been made by the classifier (recall). The evaluation consisted of the mean average of the accuracy and F1 score values of the ten models generated by the RF and XGB.
The results of the evaluation step for the RF and XGB classifiers on fraud detection in the acquired dataset
Section 4.1 were as follows: the RF classifier had an average performance of 81%, while XGB obtained 80% for the accuracy metric; regarding the F1 score, the results were 79% for both RF and XGB, as shown in
Table 3.
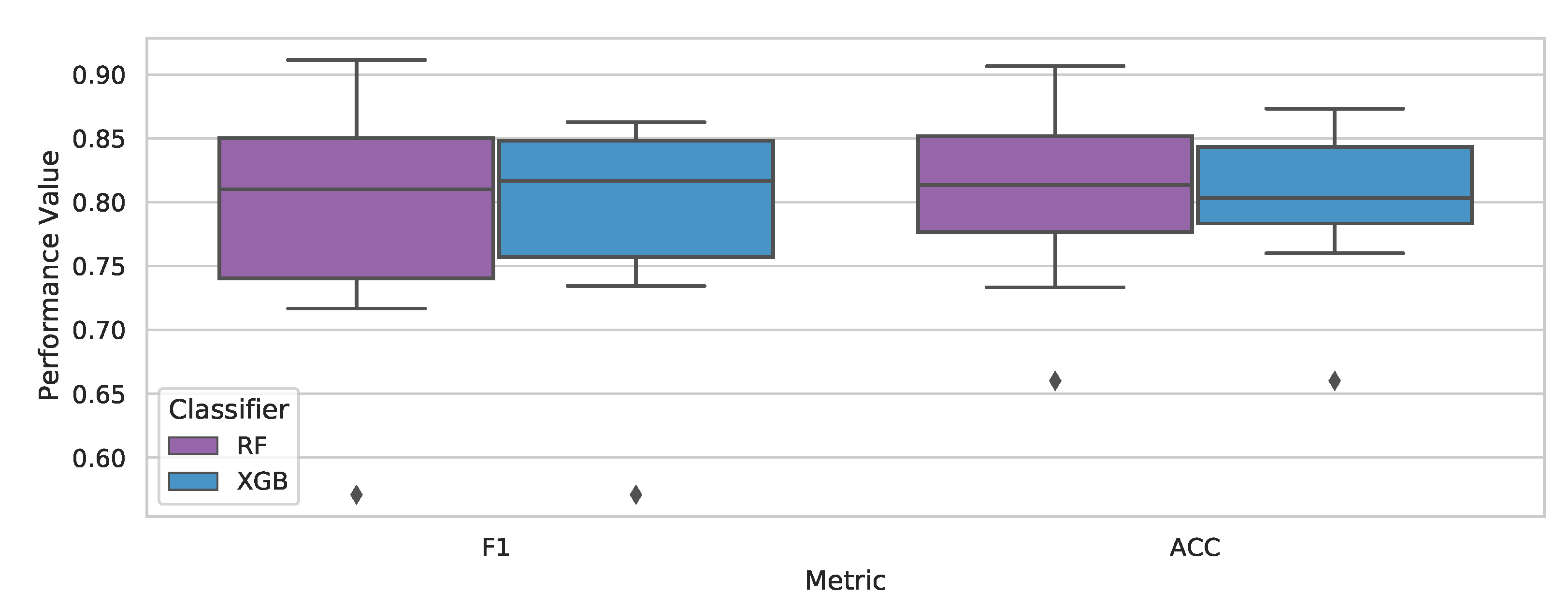
By analysing the boxplot in
Figure 4, it was possible to evaluate the RF’s and XGB’s metrics distribution. Both had a negative skewness in the F1 score, which meant that they had a concentration of scores on the lower end of the distribution, between 74% and 81% for the RF and 76% and 82% for XGB. The RF’s higher amplitude (with a maximum of 92%) allowed it to reach greater scores than XGB, but in an inconsistent way. Even though they obtained similar F1 score averages, XGB presented more consistent values, with a smaller amplitude than the RF both for the positive and negative ends of the distribution.
When analysing the accuracy values in
Figure 4, we see that the RF also had a larger range from 74% to 91% but with a normal distribution. Despite being smaller, XGB’s distribution presented a positive skewness, which meant that its accuracy values were disproportionately present above its median, towards the higher end.
Since, in the context of the fraud detection task, the objective is to prevent the greatest possible number of fraudulent users from creating accounts through digital onboarding, the ability of a model to identify the greatest possible number of users must be taken into account. It is worth mentioning both models presented similar performance results.
Models generated by a single decision tree are highly readable; a stakeholder with knowledge of their own business rules can look at the nodes of a tree and understand how it describes their data. However, for models generated by more complex algorithms such as XGB and RF, the interpretability of how the model obtains its results is equally complex. Thankfully, they are equipped with a score that represents the “importance” of every feature to their model, where a higher value indicates that a certain feature is more useful to the model’s classification of data.
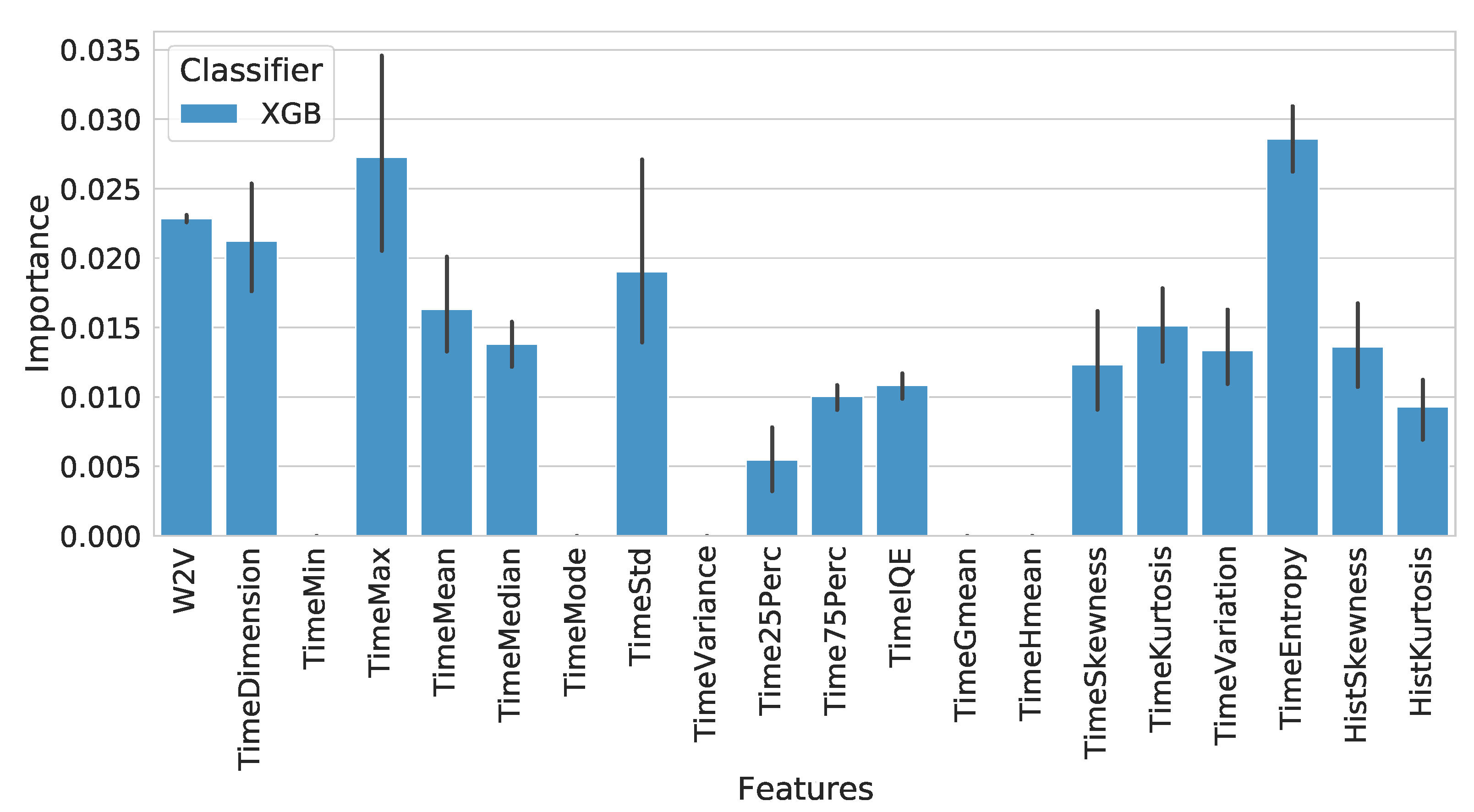
Taking into consideration that the classification step was performed on an embedded dataset concatenated with time features, it was not possible to directly identify the meaning of each feature in relation to their DO process, so we performed a feature importance analysis on the mean importance of the embedded features (w2v) in addition to the time features. The analysis revealed that for the XGB classifier, the features of time,
TimeEntropy and
TimeMax, were the most relevant ones for identifying fraud at an importance rate of 0.28 and 0.26. The third most important feature was the one representing the embedded features as shown in
Figure 5.
In short, the XGB classifier presented the most consistently positive results for creating models capable of detecting identity fraud during the onboarding process, where the most important features for detection were related to the maximum time that the user spent on the entire onboarding, the calculation of the entropy on the distribution of time during the activities of a user in the onboarding process, and finally, the embedded features related to carrying out the activities of the DO process.
7. Conclusions
This work conducted a study regarding the application of PM for fraud detection, specifically DO frauds. The results showed that the combination of PM techniques with ML classification algorithms (XGB and RF) was able to correctly identify whether a trace (sequence of events) was carried out by fraudulent or legitimate users. Furthermore, it was shown that the XGB classifier presented more constant results during this phase compared to the RF, but with similar performances. This study also provided a feature importance analysis on the XGB classifier, which revealed the impact of time features (TimeEntropy and TimeMax) in addition to embedded process features on fraud detection.
An important contribution of using a PM approach was the creation of visual models of the DO process. Even if stakeholders have a general knowledge about the DO stages of their institution, it is not always clear to them the users’ behaviour during these stages. As a result, this work applied process discovery techniques to provide insights into user behaviour for DO. Despite the resulting model presented in
Figure 2 being relatively complex in relation to the number of transitions between various activities, it was possible to observe several patterns that allowed stakeholders to investigate anomalous cases, for example.
In conclusion, the use of PM approaches, despite being little used, has great potential in the task of detecting fraud by obtaining good results in classifying users during the DO process based on event logs. In addition, it provided process visualisation models to stakeholders, even allowing future applications in areas such as AutoML. In future work, we will strive to detect fraud during the DO process, creating honeypots and obtaining more information from the fraudulent user.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}