
Practical Application of Deep Reinforcement Learning to Optimal Trade Execution


Abstract
:1. Introduction
- We set up an order execution simulation environment using level 3 market data to minimize the discrepancy between the environment and the real market during training, which cannot be achieved when using less granular market data.
- We successfully trained a generalized DRL agent that can, on average, outperform the volume-weighted average price (VWAP) of the market for a stock group comprising 50 stocks over an execution time horizon ranging from 165 min to 380 min, which is the longest in the literature; this is accomplished by using the dynamic target volume.
- We formulated a problem setting within the DRL framework in which the agent can choose to pass, submit a market/limit order, modify an outstanding limit order, and choose the volume of the order if the chosen action type is an order.
- We successfully commercialized our algorithm in the South Korea stock market.
Related Work
2. DRL for Optimal Trade Execution
2.1. Optimal Trade Execution
2.2. Deep RL Algorithms
2.2.1. Deep Q-Network (DQN)
2.2.2. Proximal Policy Optimization (PPO)
2.3. Problem Formulation
- States
- Market State:
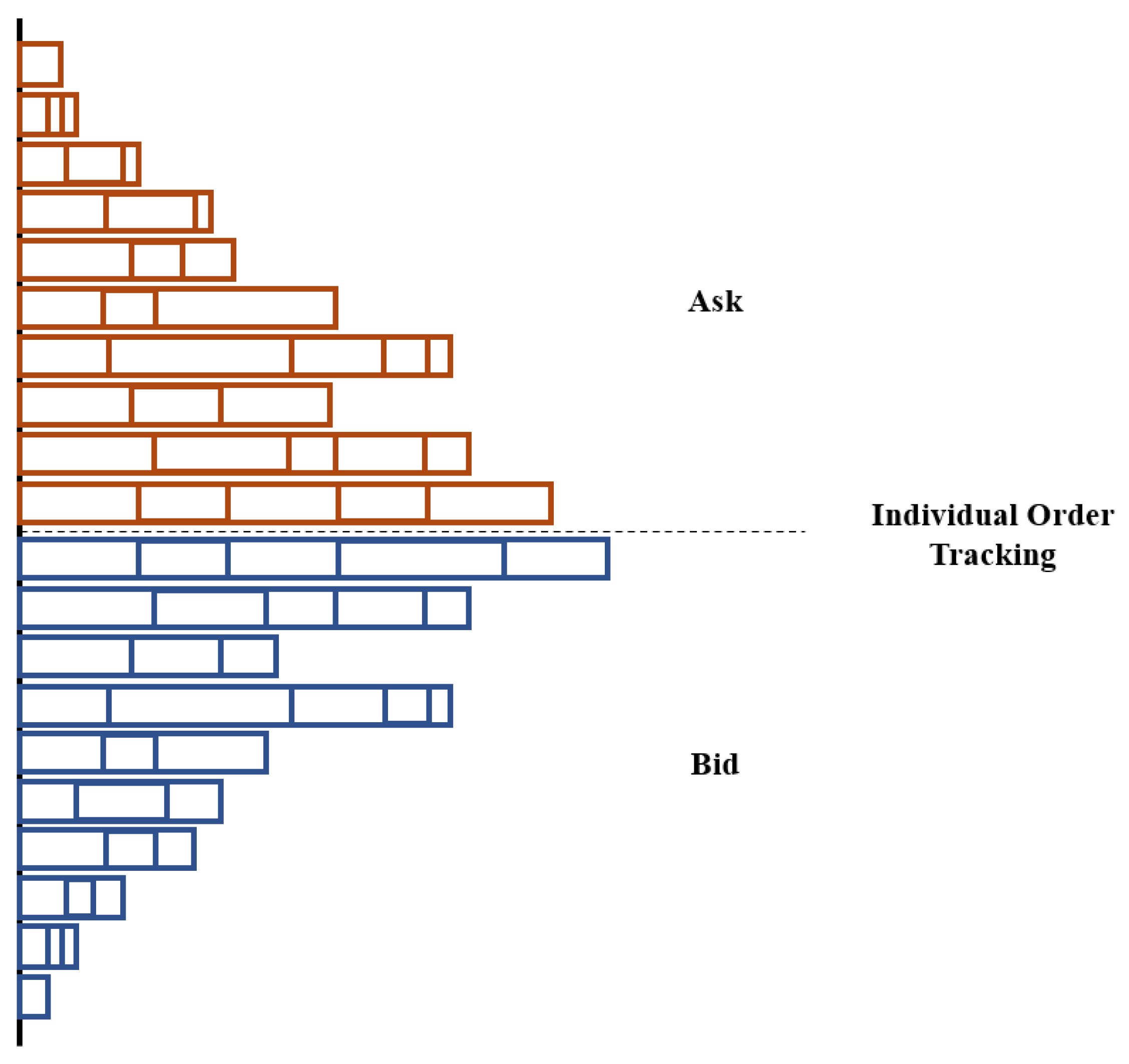
- Order Book
- -
- Bid/ask spread: ;
- -
- Mid-price: ;
- -
- Price level volume: [, ];
- -
- Ask volume: ;
- -
- Bid volume: ;
- -
- Order imbalance: .
- Execution
- -
- Total execution volume: ;
- -
- Signed execution volume: ;
- -
- First execution price: ;
- -
- Highest execution price: ;
- -
- Lowest execution price: ;
- -
- Last execution price: .
- Agent State:
- Job
- -
- Target ratio: ;
- -
- Pending ratio: ;
- -
- Executed ratio: ;
- -
- Time ratio: .
- Pending Orders
- -
- Pending feature: A list of volumes of any pending orders at each of the top five price levels of the order book. For pending orders that do not have a matching price in the order book, we added the pending orders’ quantities at the last index of the list to still represent all outstanding orders.
- Actions
- Action Type
- -
- Market order: submit a market order;
- -
- Limit order (1–5): submit a limit order with the price of the corresponding price level of the opposing side;
- -
- Correction order (1–5): modify the price of a pending order to the price of the corresponding price level of the opposing side. The goal is to modify a pending order that has remained unexecuted for the longest period due to its unfavorable price. Thus, a pending order with the price that is least likely to be executed and the oldest submission time is selected for correction. The original price of the pending order is excluded to ensure that the modified price is different from the original price;
- -
- Pass: skip action at the current time step t.
- Action Quantity
- -
- Discrete
- -
- Continuous
- Rewards
- New orders submitted by the agent between time steps and t, denoted as ;
- Orders corrected by the agent between time steps and t, denoted as ;
- Pending orders of the agent at time step t, denoted as .
2.4. Model Architecture
3. Simulation
3.1. Dataset
3.2. Market Simulation

3.3. Validity of Simulation Environment
4. Experimental Results
4.1. Training Set Up
- Side: ask and bid;
- Date range: 1 January 2018–1 January 2020;
- Universe (the full list of stocks is shown in Table A1): Fifty high-trading volume stocks listed on Korea Stock Exchange (KRX);
- Execution time horizon: 165 min–380 min;
- Target volume: 0.05–1% of daily trading volume.
4.2. Training Results
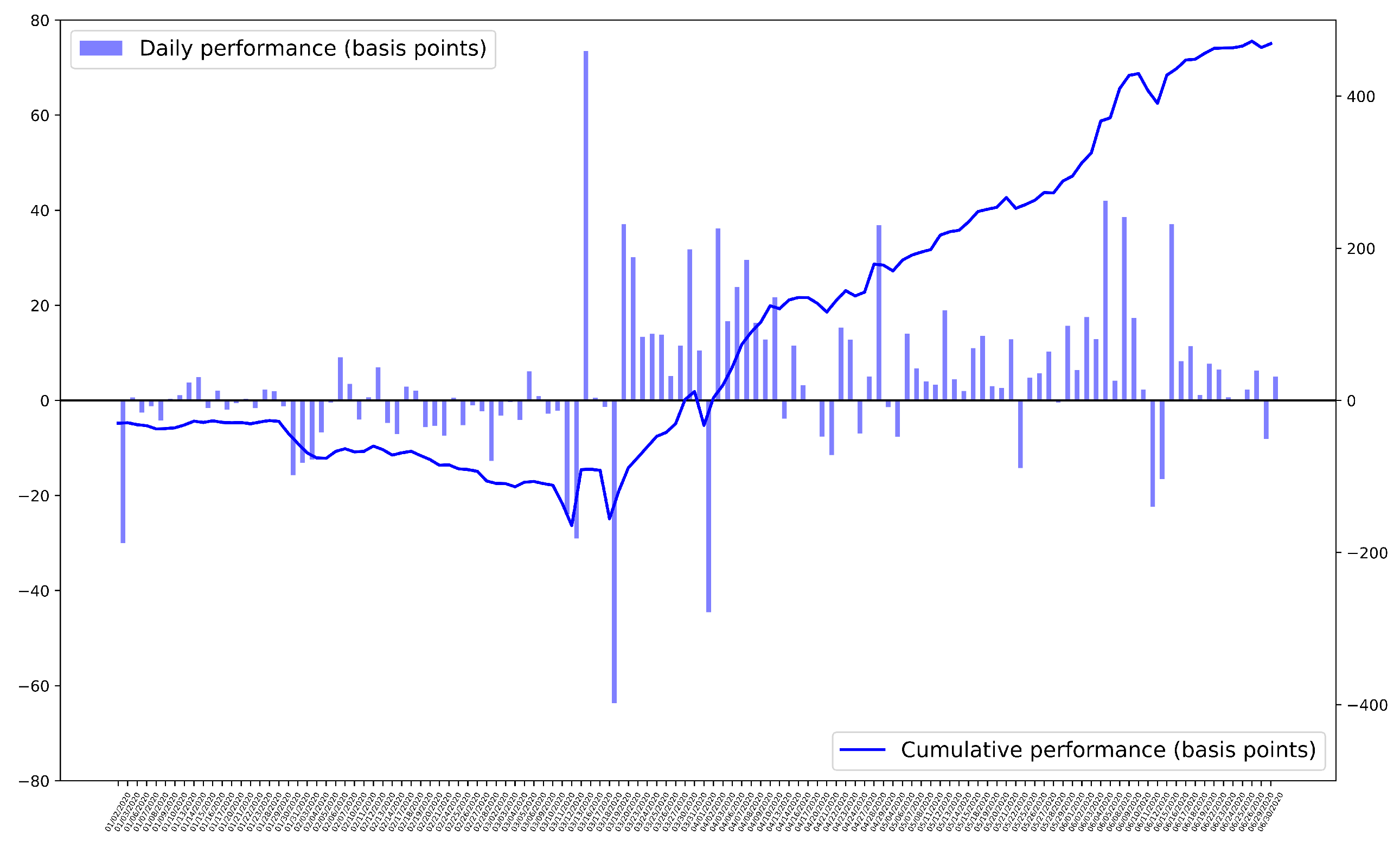
4.3. Validation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stock Issue Code |
|---|
| 000060, 000100, 000270, 000660, 000720, 000810, 002790, 003670, 004020, 004990, |
| 005380, 005490, 005830, 005930, 005940, 006400, 006800, 007070, 008560, 008770, |
| 009150, 009830, 010130, 010140, 010620, 010950, 011070, 011170, 011780, 015760, |
| 016360, 017670, 018260, 024110, 028050, 028260, 028670, 029780, 030200, 032640, |
| 241560, 055550, 068270, 033780, 035250, 035420, 066570, 086790, 035720, 307950 |
| Hyperparameter | PPO-Discrete | PPO-Hybrid |
|---|---|---|
| Minibatch size | 128 | 128 |
| LSTM size | 128 | 128 |
| Network Dimensions | 256 | 256 |
| Learning rate | ||
| Gradient clip | 1.0 | 1.0 |
| Discount | 0.993 | 0.993 |
| GAE parameter | 0.96 | 0.96 |
| Clipping parameter | 0.1 | 0.1 |
| VF coeff. | 1.0 | 1.0 |
| Entropy coeff. |
| Year | Count | Avg. Performance (Basis Points) | Win Rate (%) |
|---|---|---|---|
| 2020 | 503 | 11.035 | 54.32 |
| 2021 | 3829 | 1.966 | 51.25 |
| All | 4332 | 3.019 | 51.61 |
References
- Nevmyvaka, Y.; Feng, Y.; Kearns, M. Reinforcement learning for optimized trade execution. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 673–680. [Google Scholar]
- Hendricks, D.; Wilcox, D. A reinforcement learning extension to the Almgren-Chriss framework for optimal trade execution. In Proceedings of the 2014 IEEE Conference on Computational Intelligence for Financial Engineering & Economics (CIFEr), London, UK, 27–28 March 2014; pp. 457–464. [Google Scholar]
- Almgren, R.; Chriss, N. Optimal execution of portfolio transactions. J. Risk 2001, 3, 5–40. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Dabérius, K.; Granat, E.; Karlsson, P. Deep Execution-Value and Policy Based Reinforcement Learning for Trading and Beating Market Benchmarks. 2019. Available online: https://ssrn.com/abstract=3374766 (accessed on 21 April 2019).
- Ye, Z.; Deng, W.; Zhou, S.; Xu, Y.; Guan, J. Optimal trade execution based on deep deterministic policy gradient. In Proceedings of the Database Systems for Advanced Applications: 25th International Conference, DASFAA 2020, Jeju, Republic of Korea, 24–27 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 638–654. [Google Scholar]
- Ning, B.; Lin, F.H.T.; Jaimungal, S. Double deep q-learning for optimal execution. Appl. Math. Financ. 2021, 28, 361–380. [Google Scholar] [CrossRef]
- Lin, S.; Beling, P.A. An End-to-End Optimal Trade Execution Framework based on Proximal Policy Optimization. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 11–17 July 2020; pp. 4548–4554. [Google Scholar]
- Shen, Y.; Huang, R.; Yan, C.; Obermayer, K. Risk-averse reinforcement learning for algorithmic trading. In Proceedings of the 2014 IEEE Conference on Computational Intelligence for Financial Engineering & Economics (CIFEr), London, UK, 27–28 March 2014; pp. 391–398. [Google Scholar]
- Li, X.; Wu, P.; Zou, C.; Li, Q. Hierarchical Deep Reinforcement Learning for VWAP Strategy Optimization. arXiv 2022, arXiv:2212.14670. [Google Scholar]
- Kyle, A.S.; Obizhaeva, A.A. The Market Impact Puzzle. 2018. Available online: https://ssrn.com/abstract=3124502 (accessed on 4 February 2018).
- Bertsimas, D.; Lo, A.W. Optimal control of execution costs. J. Financ. Mark. 1998, 1, 1–50. [Google Scholar] [CrossRef]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Karpe, M.; Fang, J.; Ma, Z.; Wang, C. Multi-agent reinforcement learning in a realistic limit order book market simulation. In Proceedings of the First ACM International Conference on AI in Finance, New York, NY, USA, 15–16 October 2020; pp. 1–7. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Berkowitz, S.A.; Logue, D.E.; Noser Jr, E.A. The total cost of transactions on the NYSE. J. Financ. 1988, 43, 97–112. [Google Scholar] [CrossRef]
- Kakade, S.M.; Kearns, M.; Mansour, Y.; Ortiz, L.E. Competitive algorithms for VWAP and limit order trading. In Proceedings of the 5th ACM Conference on Electronic Commerce, New York, NY, USA, 17–20 May 2004; pp. 189–198. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, Anaheim, CA, USA, 18–20 December 2016; pp. 1995–2003. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Pardo, F.d.M.; Auth, C.; Dascalu, F. A Modular Framework for Reinforcement Learning Optimal Execution. arXiv 2022, arXiv:2208.06244. [Google Scholar]






| Author | Stock Group Size | Execution Time Horizon | Dynamic Target Volume |
|---|---|---|---|
| Nevmyvaka et al. [1] | 3 | 2–8 min | No |
| Hendricks and Wilcox [2] | 166 | 20–60 min | No |
| Shen et al. [9] | 1 | 10 min | No |
| Ning et al. [7] | 9 | 60 min | No |
| Ye et al. [6] | 3 | 2 min | No |
| Lin and Beling [8] | 14 | 1 min | No |
| Li et al. [10] | 8 | 240 min | No |
| Our study | 50 | 165–380 min | Yes |
| Algorithm | Total (Basis Points) | Ask (Basis Points) | Bid (Basis Points) |
|---|---|---|---|
| PPO-Discrete | 3.282 | 2.719 | 3.845 |
| PPO-Hybrid | 3.114 | 2.604 | 3.623 |
| DQN | −3.752 | −4.351 | −3.153 |
| TWAP Strategy | −10.420 | −9.824 | −11.015 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Byun, W.J.; Choi, B.; Kim, S.; Jo, J. Practical Application of Deep Reinforcement Learning to Optimal Trade Execution. FinTech 2023, 2, 414-429. https://doi.org/10.3390/fintech2030023
Byun WJ, Choi B, Kim S, Jo J. Practical Application of Deep Reinforcement Learning to Optimal Trade Execution. FinTech. 2023; 2(3):414-429. https://doi.org/10.3390/fintech2030023
Chicago/Turabian StyleByun, Woo Jae, Bumkyu Choi, Seongmin Kim, and Joohyun Jo. 2023. "Practical Application of Deep Reinforcement Learning to Optimal Trade Execution" FinTech 2, no. 3: 414-429. https://doi.org/10.3390/fintech2030023
APA StyleByun, W. J., Choi, B., Kim, S., & Jo, J. (2023). Practical Application of Deep Reinforcement Learning to Optimal Trade Execution. FinTech, 2(3), 414-429. https://doi.org/10.3390/fintech2030023