
Decision Tree-Based Federated Learning: A Survey



Abstract
:1. Introduction
- This survey categorizes and summarizes federated decision tree models, explains the innovative points of each scheme, and compares the differences and connections between different schemes in multiple aspects.
- We elaborate on the main issues currently facing privacy in federated learning and summarize the performance differences brought about by using different cryptographic techniques and privacy protection schemes in training federated decision tree models.
- We consider using decision trees as the underlying model for federated learning, which involves a large amount of computation and communication between multiple parties during the training process. Therefore, we discuss iterative and aggregation strategies in federated learning to improve the convergence and communication efficiency of the model.
- Finally, we provide prospects for future research directions in this field.
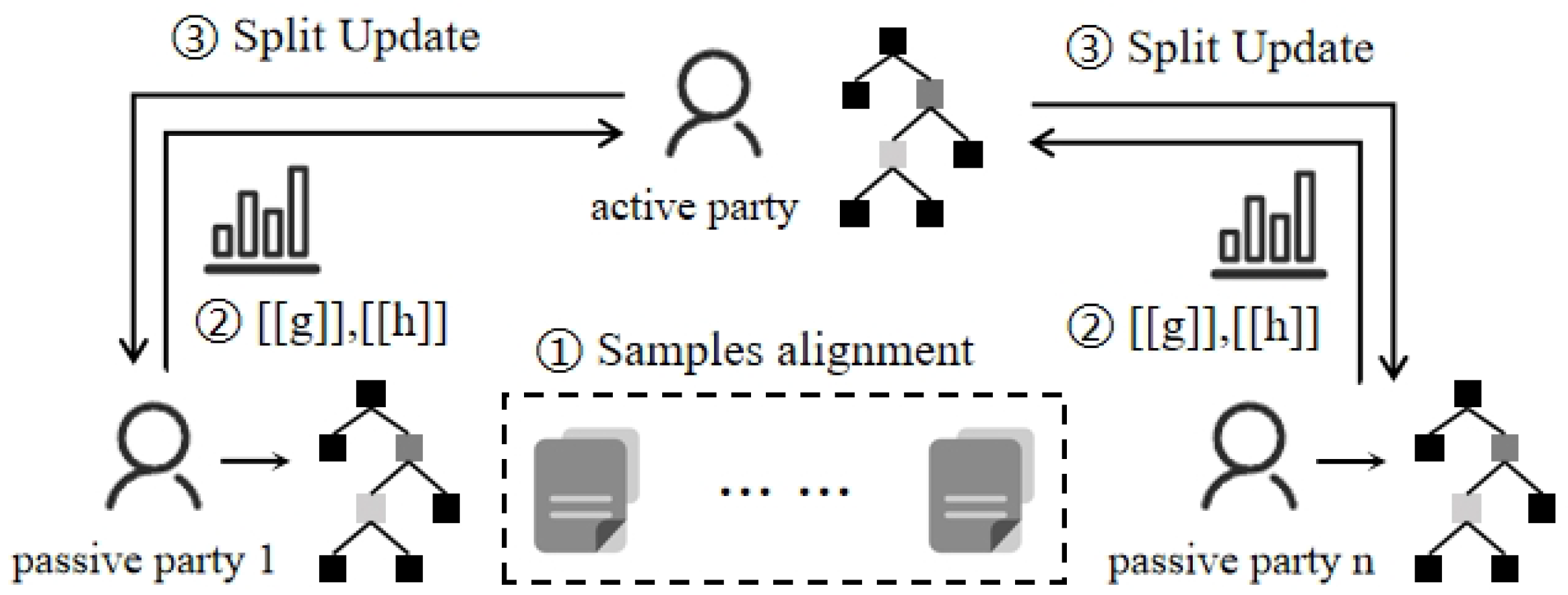
2. Federated Decision Tree
3. Security Scheme
- Model Inference Attack: Attackers can infer sensitive information about training data by observing the output of the federated decision tree model [70,71,72]. Attackers can establish training data or infer specific eigenvalues by utilizing the probability distribution or decision path of the output, thereby infringing on the privacy of participants.
- Model/Data Poisoning Attack: Attackers may attempt to manipulate model updates or gradients of participants during federated learning, or use malicious data for model training, causing malicious interference to the aggregated decision tree model. This may lead to a decrease in the performance of the final model or produce misleading results during the inference stage [73,74,75].
- Aggregation Information Leakage Attack: Attackers can infer the data information of participants by observing the aggregation process of the model parameters or gradients [76,77]. By analyzing the changes in aggregation results, attackers may obtain sensitive information about data distribution or features.
- Malicious Behavior: Participants in federated learning may engage in malicious behavior, such as providing false model updates [78,79], tampering with data labels [80], or manipulating the aggregation process [81,82,83]. This malicious behavior may undermine the accuracy and reliability of the federated decision tree model and may also threaten data privacy.
3.1. Cryptographic Technology
3.2. Different Privacy
3.3. Data Security Aggregation
- Current research on decision trees in federated learning is mostly focused on VFL. In a horizontal setting, it is difficult to aggregate directly through model parameters like neural networks, as different participants use different features to split the intermediate nodes. In VFL, it is more feasible to establish synchronization layer-by-layer among the parties.
- We summarized the existing security schemes applied in the federal decision tree model, including, but not limited to, HE, MPC, DP and secure aggregation. We explained the application of various technologies in federated decision trees, as well as the privacy protection capabilities and performance advantages and disadvantages they provide.
- The introduction of security technology has had an impact on the cost of computation and communication, as well as on the accuracy of models. Following review, we believe that balancing privacy protection and model accuracy in designing security technology solutions is a direction for further research.
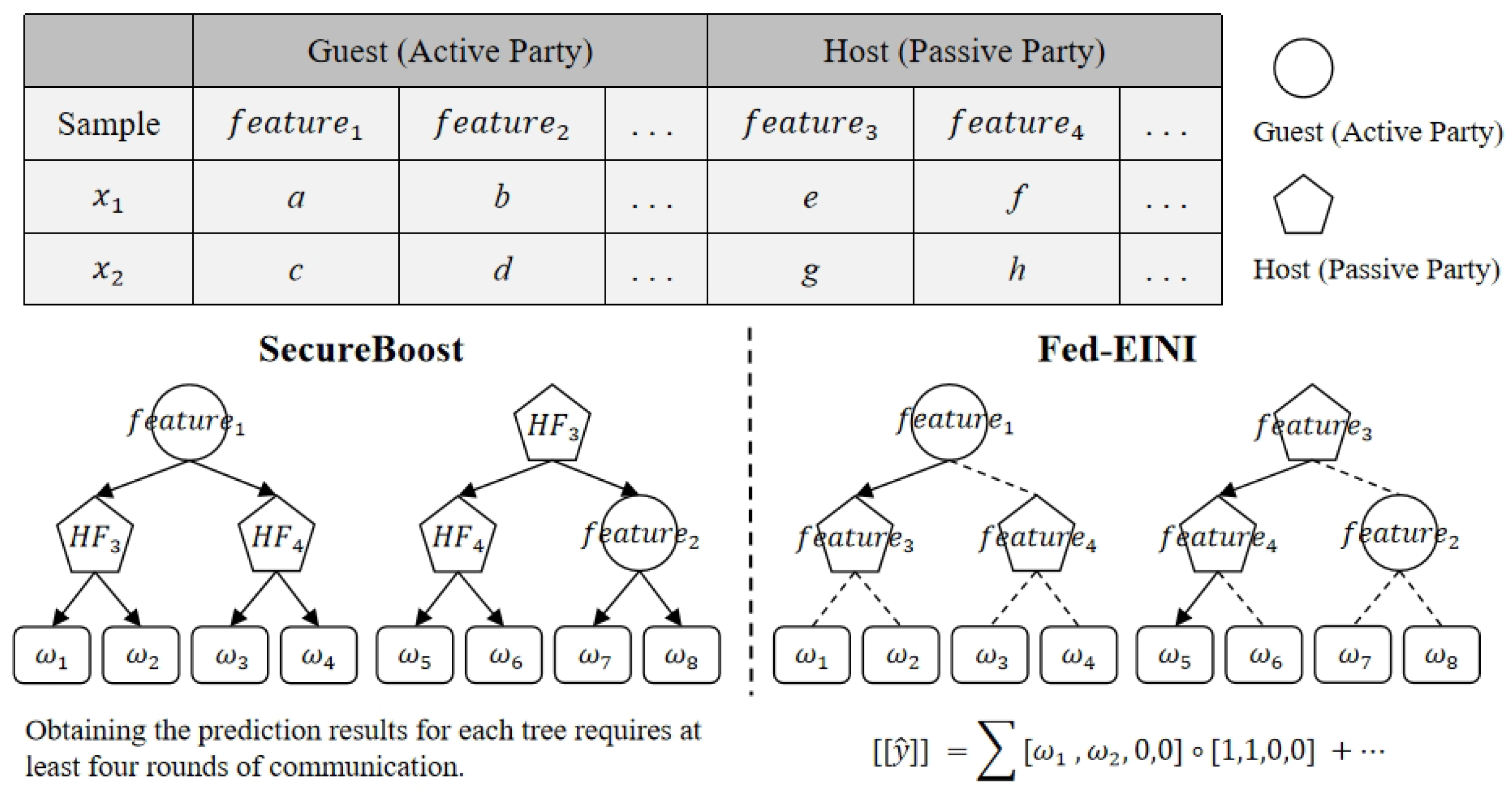
4. Efficiency Scheme
- Our efficiency evaluation of the federated decision tree is divided into the training stage and the prediction stage. We summarized the existing improvement plans and provided an overview of the experimental results.
- When training a decision tree model in a federated environment, many factors, such as safety, accuracy, and efficiency need to be considered. Currently, most solutions focus on one or two of them, and there is room for improvement.
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhuang, J.; Yu, J.; Ding, Y.; Qu, X.; Hu, Y. Towards Fast and Accurate Image-Text Retrieval with Self-Supervised Fine-Grained Alignment. IEEE Trans. Multimed. 2023, 26, 1361–1372. [Google Scholar] [CrossRef]
- Peng, W.; Hu, Y.; Yu, J.; Xing, L.; Xie, Y. APER: Adaptive evidence-driven reasoning network for machine reading comprehension with unanswerable questions. Knowl.-Based Syst. 2021, 229, 107364. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, X.; Qin, Z.; Zhang, W.; Hu, Y.; Wu, Q. Learning dual encoding model for adaptive visual understanding in visual dialogue. IEEE Trans. Image Process. 2020, 30, 220–233. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Zhang, W.; Lu, Y.; Qin, Z.; Hu, Y.; Tan, J.; Wu, Q. Reasoning on the relation: Enhancing visual representation for visual question answering and cross-modal retrieval. IEEE Trans. Multimed. 2020, 22, 3196–3209. [Google Scholar] [CrossRef]
- Gai, K.; Guo, J.; Zhu, L.; Yu, S. Blockchain meets cloud computing: A survey. IEEE Commun. Surv. Tut. 2020, 22, 2009–2030. [Google Scholar] [CrossRef]
- Yu, J.; Zhu, Z.; Wang, Y.; Zhang, W.; Hu, Y.; Tan, J. Cross-modal knowledge reasoning for knowledge-based visual question answering. Pattern Recognit. 2020, 108, 107563. [Google Scholar] [CrossRef]
- Zaeem, R.N.; Barber, K.S. The effect of the GDPR on privacy policies: Recent progress and future promise. Acm Trans. Manag. Inf. Syst. 2020, 12, 1–20. [Google Scholar] [CrossRef]
- Gai, K.; Xiao, Q.; Qiu, M.; Zhang, G.; Chen, J.; Wei, Y.; Zhang, Y. Digital twin-enabled AI enhancement in smart critical infrastructures for 5G. Acm Trans. Sens. Netw. 2022, 18, 1–20. [Google Scholar] [CrossRef]
- Zhang, Y.; Gai, K.; Xiao, J.; Zhu, L.; Choo, K.-K.R. Blockchain-empowered efficient data sharing in Internet of Things settings. IEEE J. Sel. Areas Commun. 2022, 40, 3422–3436. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. Acm Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; Arcas, B.A.Y. Federated learning of deep networks using model averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Li, Q.; Wen, Z.; He, B. Federated learning systems: Vision, hype and reality for data privacy and protection. arXiv 2019, arXiv:1907.09693. [Google Scholar] [CrossRef]
- Li, Z.; Huang, C.; Gai, K.; Lu, Z.; Wu, J.; Chen, L.; Choo, K.K.R. AsyFed: Accelerated Federated Learning With Asynchronous Communication Mechanism. IEEE IoT J. 2022, 10, 8670–8683. [Google Scholar] [CrossRef]
- Gascón, A.; Schoppmann, P.; Balle, B.; Raykova, M.; Doerner, J.; Zahur, S.; Evans, D. Secure linear regression on vertically partitioned datasets. IACR Cryptol. ePrint Arch. 2016, 2016, 892. [Google Scholar]
- Cellamare, M.; van Gestel, A.J.; Alradhi, H.; Martin, F.; Moncada-Torres, A. A federated generalized linear model for privacy-preserving analysis. Algorithms 2022, 15, 243. [Google Scholar] [CrossRef]
- Zhu, H.; Jin, Y. Multi-objective evolutionary federated learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1310–1322. [Google Scholar] [CrossRef] [PubMed]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Zhao, S. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Yurochkin, M.; Agarwal, M.; Ghosh, S.; Greenewald, K.; Hoang, T.N.; Khazaeni, Y. Bayesian nonparametric federated learning of neural networks. In Proceedings of the ICML. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 7252–7261. [Google Scholar]
- Liu, Y.; James, J.; Kang, J.; Niyato, D.; Zhang, S. Privacy-preserving traffic flow prediction: A federated learning approach. IEEE Internet Things J. 2020, 7, 7751–7763. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, Z.; Yang, Y.; Liu, X.; Ma, J.; Ren, K. Revfrf: Enabling cross-domain random forest training with revocable federated learning. IEEE Trans. Dependable Secur. Comput. 2021, 19, 3671–3685. [Google Scholar] [CrossRef]
- Hou, J.; Su, M.; Fu, A.; Yu, Y. Verifiable privacy-preserving scheme based on vertical federated random forest. IEEE Internet Things J. 2021, 9, 22158–22172. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the SIGKDD, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Cheng, K.; Fan, T.; Jin, Y.; Liu, Y.; Chen, T.; Papadopoulos, D.; Yang, Q. Secureboost: A lossless federated learning framework. IEEE Intell. Syst. 2021, 36, 87–98. [Google Scholar] [CrossRef]
- Tian, Z.; Zhang, R.; Hou, X.; Liu, J.; Ren, K. Federboost: Private federated learning for gbdt. arXiv 2020, arXiv:2011.02796. [Google Scholar] [CrossRef]
- Benhamou, E.; Ohana, J.; Saltiel, D.; Guez, B. Planning in Financial Markets in Presence of Spikes: Using Machine Learning GBDT; Université Paris-Dauphine: Paris, France, 2021. [Google Scholar]
- Zhang, X.; Yan, C.; Gao, C.; Malin, B.A.; Chen, Y. Predicting missing values in medical data via XGBoost regression. Healthc. Inform. Res. 2020, 4, 383–394. [Google Scholar] [CrossRef] [PubMed]
- Memon, N.; Patel, S.B.; Patel, D.P. Comparative analysis of artificial neural network and XGBoost algorithm for PolSAR image classification. In Proceedings of the TPAMI, Tepzur, India, 17–20 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 452–460. [Google Scholar]
- Grinsztajn, L.; Oyallon, E.; Varoquaux, G. Why do tree-based models still outperform deep learning on tabular data? arXiv 2022, arXiv:2207.08815. [Google Scholar]
- Popov, S.; Morozov, S.; Babenko, A. Neural oblivious decision ensembles for deep learning on tabular data. arXiv 2019, arXiv:1909.06312. [Google Scholar]
- Chen, Y. Attention augmented differentiable forest for tabular data. arXiv 2020, arXiv:2010.02921. [Google Scholar]
- Luo, H.; Cheng, F.; Yu, H.; Yi, Y. SDTR: Soft decision tree regressor for tabular data. IEEE Access 2021, 9, 55999–56011. [Google Scholar] [CrossRef]
- Chen, X.; Zhou, S.; Yang, K.; Fao, H.; Wang, H.; Wang, Y. Fed-EINI: An efficient and interpretable inference framework for decision tree ensembles in federated learning. arXiv 2021, arXiv:2105.09540. [Google Scholar]
- Liu, Y.; Ma, Z.; Liu, X.; Ma, S.; Nepal, S.; Deng, R. Boosting privately: Privacy-preserving federated extreme boosting for mobile crowdsensing. arXiv 2019, arXiv:1907.10218. [Google Scholar]
- Wu, Y.; Cai, S.; Xiao, X.; Chen, G.; Ooi, B.C. Privacy preserving vertical federated learning for tree-based models. arXiv 2020, arXiv:2008.06170. [Google Scholar] [CrossRef]
- Zhao, L.; Ni, L.; Hu, S.; Chen, Y.; Zhou, P.; Xiao, F.; Wu, L. Inprivate digging: Enabling tree-based distributed data mining with differential privacy. In Proceedings of the INFOCOM, Honolulu, HI, USA, 15–19 April 2018; pp. 2087–2095. [Google Scholar]
- Yamamoto, F.; Ozawa, S.; Wang, L. eFL-Boost: Efficient Federated Learning for Gradient Boosting Decision Trees. IEEE Access 2022, 10, 43954–43963. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.; Liu, Z.; Liang, Y.; Meng, C.; Zhang, J.; Zheng, Y. Federated forest. IEEE Trans. Big Data 2020, 8, 843–854. [Google Scholar] [CrossRef]
- Maddock, S.; Cormode, G.; Wang, T.; Maple, C.; Jha, S. Federated Boosted Decision Trees with Differential Privacy. In Proceedings of the CCS, Nagasaki, Japan, 30 May–2 June 2022; pp. 2249–2263. [Google Scholar]
- Fu, F.; Shao, Y.; Yu, L.; Jiang, J.; Xue, H.; Tao, Y.; Cui, B. Vf2boost: Very fast vertical federated gradient boosting for cross-enterprise learning. In Proceedings of the SIGMOD, Xi’an, China, 20–25 June 2021; pp. 563–576. [Google Scholar]
- Xu, Y.; Hu, X.; Wei, J.; Yang, H.; Li, K. VF-CART: A communication-efficient vertical federated framework for the CART algorithm. Eur. J. Inform. Syst. 2023, 35, 237–249. [Google Scholar] [CrossRef]
- Gai, K.; Zhang, Y.; Qiu, M.; Thuraisingham, B. Blockchain-enabled service optimizations in supply chain digital twin. IEEE Trans. Serv. Comput. 2022, 16, 1673–1685. [Google Scholar] [CrossRef]
- Xie, T.; Gai, K.; Zhu, L.; Guo, Y.; Choo, K. Cross-Chain-Based Trustworthy Node Identity Governance in Internet of Things. IEEE Internet Things J. 2023, 10, 21580–21594. [Google Scholar] [CrossRef]
- Xie, T.; Gai, K.; Zhu, L.; Wang, S.; Zhang, Z. RAC-Chain: An Asynchronous Consensus-based Cross-chain Approach to Scalable Blockchain for Metaverse. Acm Trans. Multimed. Comput. Commun. Appl. 2023. [Google Scholar] [CrossRef]
- Pelttari, H. Federated learning for mortality prediction in intensive care units. arXiv 2022, arXiv:2205.15104. [Google Scholar]
- Yang, M.W.; Song, L.Q.; Xu, J.; Li, C.; Tan, G. The tradeoff between privacy and accuracy in anomaly detection using federated xgboost. arXiv 2019, arXiv:1907.07157. [Google Scholar]
- De Souza, L.A.C.; Rebello, G.A.F.; Camilo, G.F.; Guimarães, L.C.; Duarte, O.C.M. DFedForest: Decentralized federated forest. In Proceedings of the Blockchain, Rhodes, Greece, 2–6 November 2020; pp. 90–97. [Google Scholar]
- Yamamoto, F.; Wang, L.; Ozawa, S. New approaches to federated XGBoost learning for privacy-preserving data analysis. In Proceedings of the NeurIPS, Bangkok, Thailand, 23–27 November 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 558–569. [Google Scholar]
- Wang, Z.; Yang, Y.; Liu, Y.; Liu, X.; Gupta, B.B.; Ma, J. Cloud-based federated boosting for mobile crowdsensing. arXiv 2020, arXiv:2005.05304. [Google Scholar]
- Li, Q.; Wu, Z.; Wen, Z.; He, B. Privacy-preserving gradient boosting decision trees. In Proceedings of the AAAI, Austin, TX, USA, 7–12 February 2020; pp. 784–791. [Google Scholar]
- Li, Q.; Wen, Z.; He, B. Practical federated gradient boosting decision trees. In Proceedings of the AAAI, Austin, TX, USA, 7–12 February 2020; pp. 4642–4649. [Google Scholar]
- Chen, W.; Ma, G.; Fan, T.; Kang, Y.; Xu, Q.; Yang, Q. Secureboost+: A high performance gradient boosting tree framework for large scale vertical federated learning. arXiv 2021, arXiv:2110.10927. [Google Scholar]
- Law, A.; Leung, C.; Poddar, R.; Popa, R.A.; Shi, C.; Sima, O.; Yu, C.; Zhang, X.; Zheng, W. Secure collaborative training and inference for xgboost. In Proceedings of the PPMLP, New York, NY, USA, 9 November 2020; pp. 21–26. [Google Scholar]
- Zhang, J.; Zhao, X.; Yuan, P. Federated security tree algorithm for user privacy protection. J. Comput. Appl. 2020, 40, 2980. [Google Scholar]
- Le, N.K.; Liu, Y.; Nguyen, Q.M.; Liu, Q.; Liu, F.; Cai, Q.; Hirche, S. Fedxgboost: Privacy-preserving xgboost for federated learning. arXiv 2021, arXiv:2106.10662. [Google Scholar]
- Wang, R.; Ersoy, O.; Zhu, H.; Jin, Y.; Liang, K. Feverless: Fast and secure vertical federated learning based on xgboost for decentralized labels. IEEE Trans. Big Data 2022, 1–19. [Google Scholar] [CrossRef]
- Han, Y.; Du, P.; Yang, K. Fedgbf: An efficient vertical federated learning framework via gradient boosting and bagging. arXiv 2022, arXiv:2204.00976. [Google Scholar]
- Yao, H.; Wang, J.; Dai, P.; Bo, L.; Chen, Y. An efficient and robust system for vertically federated random forest. arXiv 2022, arXiv:2201.10761. [Google Scholar]
- Li, X.; Hu, Y.; Liu, W.; Feng, H.; Peng, L.; Hong, Y.; Ren, K.; Qin, Z. OpBoost: A vertical federated tree boosting framework based on order-preserving desensitization. arXiv 2022, arXiv:2210.01318. [Google Scholar] [CrossRef]
- Zhao, J.; Zhu, H.; Xu, W.; Wang, F.; Lu, R.; Li, H. SGBoost: An Efficient and Privacy-Preserving Vertical Federated Tree Boosting Framework. TIFS 2022, 18, 1022–1036. [Google Scholar] [CrossRef]
- Chen, H.; Li, H.; Wang, Y.; Hao, M.; Xu, G.; Zhang, T. PriVDT: An Efficient Two-Party Cryptographic Framework for Vertical Decision Trees. TIFS 2022, 18, 1006–1021. [Google Scholar] [CrossRef]
- Zhang, X.; Mavromatics, A.; Vafeas, A.; Nejabati, R.; Simeonidou, D. Federated Feature Selection for Horizontal Federated Learning in IoT Networks. IEEE Internet Things J. 2023, 10, 10095–10112. [Google Scholar] [CrossRef]
- Kwatra, S.; Torra, V. A k-anonymised federated learning framework with decision trees. In Proceedings of the DPM and CBT, Darmstadt, Germany, 4–8 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 106–120. [Google Scholar]
- Kalloori, S.; Klingler, S. Cross-silo federated learning based decision trees. In Proceedings of the SAC, Brno, Czech Republic, 24–26 August 2022; pp. 1117–1124. [Google Scholar]
- Xu, Y.; Lu, Z.; Gai, K.; Duan, Q.; Lin, J.; Wu, J.; Choo, K.R. Besifl: Blockchain empowered secure and incentive federated learning paradigm in iot. IEEE Internet Things J. 2021, 10, 6561–6573. [Google Scholar] [CrossRef]
- Gai, K.; Tang, H.; Li, G.; Xie, T.; Wang, S.; Zhu, L.; Choo, K.R. Blockchain-based privacy-preserving positioning data sharing for IoT-enabled maritime transportation systems. IEEE Trans. Intell. Transp. Syst. 2022, 24, 2344–2358. [Google Scholar] [CrossRef]
- Gai, K.; She, Y.; Zhu, L.; Choo, K.R.; Wan, Z. A blockchain-based access control scheme for zero trust cross-organizational data sharing. Acm Trans. Internet Technol. 2023, 23, 1–25. [Google Scholar] [CrossRef]
- Gai, K.; Wu, Y.; Zhu, L.; Choo, K.R.; Xiao, B. Blockchain-enabled trustworthy group communications in UAV networks. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4118–4130. [Google Scholar] [CrossRef]
- Peng, Z.; Xu, J.; Chu, X.; Gao, S.; Yao, Y.; Gu, R.; Tang, Y. Vfchain: Enabling verifiable and auditable federated learning via blockchain systems. IEEE Trans. Netw. Sci. Eng. 2021, 9, 173–186. [Google Scholar] [CrossRef]
- Zhu, L.; Liu, Z.; Han, S. Deep leakage from gradients. In Proceedings of the NeurIPS, Vancouver, Canada, 8–14 December 2019; pp. 14774–14784. [Google Scholar]
- Yin, H.; Mallya, A.; Vahdat, A.; Alvarez, J.M.; Kautz, J.; Molchanov, P. See through gradients: Image batch recovery via gradinversion. In Proceedings of the CVPR, Nashville, TN, USA, 19–25 June 2021; pp. 16337–16346. [Google Scholar]
- Fu, C.; Zhang, X.; Ji, S.; Chen, J.; Wu, J.; Guo, S.; Zhou, J.; Liu, A.; Wang, T. Label inference attacks against vertical federated learning. In Proceedings of the USENIX Security, Boston, MA, USA, 10–12 August 2022; pp. 1397–1414. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. In Proceedings of the AISTATS, PMLR, Palermo, Italy, 26–28 August 2020; pp. 2938–2948. [Google Scholar]
- Xie, C.; Huang, K.; Chen, P.; Li, B. Dba: Distributed backdoor attacks against federated learning. In Proceedings of the ICLR, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Andreina, S.; Marson, G.A.; Möllering, H.; Karame, G. Baffle: Backdoor detection via feedback-based federated learning. In Proceedings of the ICDCS, Washington DC, USA, 7–10 July 2021; pp. 852–863. [Google Scholar]
- Zhou, X.; Peng, B.; Li, Y.F.; Chen, Y.; Tang, H.; Wang, X. To Release or Not to Release: Evaluating Information Leaks in Aggregate Human-Genome Data. In Proceedings of the ESORICS, Athens, Greece, 20–22 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; Volume 11, pp. 607–627. [Google Scholar]
- Weng, H.; Zhang, J.; Xue, F.; Wei, T.; Ji, S.; Zong, Z. Privacy leakage of real-world vertical federated learning. arXiv 2020, arXiv:2011.09290. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should i trust you? Explaining the predictions of any classifier. In Proceedings of the SIGKDD, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Blanchard, P.; Mahdi, E.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. NeurIPS 2017, 30, 118–128. [Google Scholar]
- Taheri, R.; Javidan, R.; Shojafar, M.; Pooranian, Z.; Miri, A.; Conti, M. On defending against label flipping attacks on malware detection systems. Neural Comput. Appl. 2020, 32, 14781–14800. [Google Scholar] [CrossRef]
- Xia, Q.; Tao, Z.; Hao, Z.; Li, Q. FABA: An algorithm for fast aggregation against byzantine attacks in distributed neural networks. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019. [Google Scholar]
- Xie, C.; Koyejo, S.; Gupta, I. Zeno: Distributed stochastic gradient descent with suspicion-based fault-tolerance. In Proceedings of the ICML, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6893–6901. [Google Scholar]
- Li, L.; Xu, W.; Chen, T.; Giannakis, G.B.; Ling, Q. RSA: Byzantine-robust stochastic aggregation methods for distributed learning from heterogeneous datasets. In Proceedings of the AAAI, Honolulu, HI, USA, 29–31 January 2019; Volume 33, pp. 1544–1551. [Google Scholar]
- Yang, S.; Ren, B.; Zhou, X.; Liu, L. Parallel distributed logistic regression for vertical federated learning without third-party coordinator. arXiv 2019, arXiv:1911.09824. [Google Scholar]
- Zhang, Y.; Zhu, H. Additively homomorphical encryption based deep neural network for asymmetrically collaborative machine learning. arXiv 2020, arXiv:2007.06849. [Google Scholar]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the EUROCRYPT, Prague, Czech Republic, 2–6 May 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 223–238. [Google Scholar]
- Goldreich, O. Secure multi-party computation. In Manuscript Preliminary Version; Citeseer: University Park, PA, USA, 1998; Volume 78. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for federated learning on user-held data. arXiv 2016, arXiv:1611.04482. [Google Scholar]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the CCS, Denver Colorado, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the SP, San Jose, CA, USA, 22–24 May 2017; pp. 3–18. [Google Scholar]
- Mohassel, P.; Zhang, Y. Secureml: A system for scalable privacy-preserving machine learning. In Proceedings of the SP, San Jose, CA, USA, 22–24 May 2017; pp. 19–38. [Google Scholar]
- Papernot, N.; Abadi, M.; Erlingsson, U.; Goodfellow, I.; Talwar, K. Semi-supervised knowledge transfer for deep learning from private training data. arXiv 2016, arXiv:1610.05755. [Google Scholar]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the TCC, New York, NY, USA, 4–7 March 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the CCS, Vienna, Austria, 25–27 October 2016; pp. 308–318. [Google Scholar]
- Dey, A.K.; Martin, C.F.; Ruymgaart, F.H. Input recovery from noisy output data, using regularized inversion of the Laplace transform. IEEE Trans. Inf. Theory 1998, 44, 1125–1130. [Google Scholar] [CrossRef]
- McHutchon, A.; Rasmussen, C. Gaussian process training with input noise. NeurIPS 2011, 24, 1341–1349. [Google Scholar]
- Awan, J.; Kenney, A.; Reimherr, M.; Slavković, A. Benefits and pitfalls of the exponential mechanism with applications to hilbert spaces and functional pca. In Proceedings of the ICML, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 374–384. [Google Scholar]
- Liu, X.; Li, Q.; Li, T.; Chen, D. Differentially private classification with decision tree ensemble. Appl. Soft Comput. 2018, 62, 807–816. [Google Scholar] [CrossRef]
- Xiang, T.; Li, Y.; Li, X.; Zhong, S.; Yu, S. Collaborative ensemble learning under differential privacy. In Proceedings of the WI, Santiago, Chile, 7 November 2018; pp. 73–87. [Google Scholar]
- Fletcher, S.; Islam, M.Z. A Differentially Private Decision Forest. AusDM 2015, 15, 99–108. [Google Scholar]
- Yang, S.; Li, N.; Sun, D.; Du, Q.; Liu, W. A differential privacy preserving algorithm for greedy decision tree. In Proceedings of the ICBASE, IEEE, Zhuhai, China, 24–26 September 2021; pp. 229–237. [Google Scholar]
- Mironov, I. Rényi differential privacy. In Proceedings of the CSF, IEEE, Santa Barbara, CA, USA, 21–25 August 2017; pp. 263–275. [Google Scholar]
- Shi, L.; Shu, J.; Zhang, W.; Liu, Y. HFL-DP: Hierarchical federated learning with differential privacy. In Proceedings of the GLOBECOM, IEEE, Madrid, Spain, 7–11 December 2021; pp. 1–7. [Google Scholar]
- Wu, Z.; Li, Q.; He, B. Practical vertical federated learning with unsupervised representation learning. TBD arXiv 2022, arXiv:2208.10278. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the CCS, Dallas, TX, USA, 31 October 2017; pp. 1175–1191. [Google Scholar]
- Bittau, A.; Erlingsson, U.; Maniatis, P.; Mironov, I.; Raghunathan, A.; Lie, D.; Rudominer, M.; Kode, U.; Tinnes, J.; Seefeld, B. Prochlo: Strong privacy for analytics in the crowd. In Proceedings of the SOSP, Shanghai, China, 29–31 October 2017; pp. 441–459. [Google Scholar]
- Erlingsson, U.; Feldman, V.; Mironov, I.; Raghunathan, A.; Song, S.; Talwar, K.; Thakurta, A. Encode, shuffle, analyze privacy revisited: Formalizations and empirical evaluation. arXiv 2020, arXiv:2001.03618. [Google Scholar]
- Sun, L.; Qian, J.; Chen, X.; Yu, P.S. Ldp-fl: Practical private aggregation in federated learning with local differential privacy. arXiv 2020, arXiv:2007.15789. [Google Scholar]
- Erlingsson, U.; Feldman, V.; Mironov, I.; Raghunathan, A.; Talwar, K.; Thakurta, A. Amplification by shuffling: From local to central differential privacy via anonymity. In Proceedings of the SODA, SIAM, San Diego, CA, USA, 6–9 January 2019; pp. 2468–2479. [Google Scholar]
- Liu, R.; Cao, Y.; Chen, H.; Guo, R.; Yoshikawa, M. Flame: Differentially private federated learning in the shuffle model. In Proceedings of the AAAI, Virtual, 2–9 February 2021; Volume 35, pp. 8688–8696. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the AISTATS, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Weinberg, A.I.; Last, M. Selecting a representative decision tree from an ensemble of decision-tree models for fast big data classification. J. Big Data 2019, 6, 1–17. [Google Scholar] [CrossRef]
- Kwatra, S.; Torra, V. A Survey on Tree Aggregation. In Proceedings of the FUZZ-IEEE, IEEE, Luxembourg, Luxembourg, 11–14 July 2021; pp. 1–6. [Google Scholar]
- Kargupta, H.; Park, B. A fourier spectrum-based approach to represent decision trees for mining data streams in mobile environments. TKDE 2004, 16, 216–229. [Google Scholar] [CrossRef]
- Miglio, R.; Soffritti, G. The comparison between classification trees through proximity measures. Comput. Stat. Data. An. 2004, 45, 577–593. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A.; Crew, G.; Ksikes, A. Ensemble selection from libraries of models. In Proceedings of the ICML, Banff, AL, Canada, 4–8 July 2004; p. 18. [Google Scholar]
- Tian, Y.; Feng, Y. Rase: Random subspace ensemble classification. J. Mach. Learn. Res. 2021, 22, 2019–2111. [Google Scholar]
- Chen, M.; Shlezinger, N.; Poor, H.V.; Eldar, Y.C.; Cui, S. Communication-efficient federated learning. Proc. Natl. Acad. Sci. USA 2021, 118, e2024789118. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.Y.; Chao, W.L. Fedbe: Making bayesian model ensemble applicable to federated learning. arXiv 2020, arXiv:2009.01974. [Google Scholar]
- Antunes, R.S.; da Costa, C.A.; Küderle, A. Federated learning for healthcare: Systematic review and architecture proposal. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–23. [Google Scholar] [CrossRef]
- Kasturi, A.; Ellore, A.R.; Hota, C. Fusion learning: A one shot federated learning. In Proceedings of the ICCS, Amsterdam, The Netherlands, 3–5 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 424–436. [Google Scholar]
- Li, M.; Chen, Y.; Wang, Y.; Pan, Y. Efficient asynchronous vertical federated learning via gradient prediction and double-end sparse compression. In Proceedings of the ICARCV, Shenzhen, China, 13–15 December 2020; pp. 291–296. [Google Scholar]
- Chiti, F.; Fantacci, R.; Picano, B. A matching theory framework for tasks offloading in fog computing for IoT systems. IEEE Internet Things J. 2018, 5, 5089–5096. [Google Scholar] [CrossRef]
- Arisdakessian, S.; Wahab, O.A.; Mourad, A.; Otrok, H.; Guizani, M. A survey on iot intrusion detection: Federated learning, game theory, social psychology and explainable ai as future directions. IEEE Internet Things J. 2022, 10, 4059–4092. [Google Scholar] [CrossRef]
- Wehbi, O.; Arisdakessian, S.; Wahab, O.A.; Otrok, H.; Otoum, S.; Mourad, A.; Guizani, M. FedMint: Intelligent Bilateral Client Selection in Federated Learning with Newcomer IoT Devices. IEEE Internet Things J. 2023, 10, 20884–20898. [Google Scholar] [CrossRef]
- Li, Y.; Feng, Y.; Qian, Q. FDPBoost: Federated differential privacy gradient boosting decision trees. J. Inf. Secur. Appl. 2023, 74, 103468. [Google Scholar] [CrossRef]
- Hu, Y.; Zhang, Y.; Gong, D.; Sun, X. Multi-participant federated feature selection algorithm with particle swarm optimizaiton for imbalanced data under privacy protection. IEEE Trans. Artif. Intell. 2022, 4, 1002–1016. [Google Scholar] [CrossRef]
- Courbariaux, M.; Bengio, Y.; David, J. Binaryconnect: Training deep neural networks with binary weights during propagations. NeurIPS 2015, 28, 3123–3131. [Google Scholar]
- Devos, L.; Meert, W.; Davis, J. Fast gradient boosting decision trees with bit-level data structures. In Proceedings of the ECML-PKDD, 19–23 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 590–606. [Google Scholar]
- Shi, Y.; Ke, G.; Chen, Z.; Zheng, S.; Liu, T. Quantized Training of Gradient Boosting Decision Trees. arXiv 2022, arXiv:2207.09682. [Google Scholar]
- Fu, M.; Zhang, C.; Hu, C.; Wu, T.; Dong, J.; Zhu, L. Achieving Verifiable Decision Tree Prediction on Hybrid Blockchains. Entropy 2023, 25, 1058. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Fang, Z.; Zhang, Y.; Song, D. Zero knowledge proofs for decision tree predictions and accuracy. In Proceedings of the CCS, Virtual Event, USA, 9–13 November 2020; pp. 2039–2053. [Google Scholar]
- Wang, H.; Deng, Y.; Xie, X. Public Verifiable Private Decision Tree Prediction. In Proceedings of the Inscrypt, Guangzhou, China, 11–14 December 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 247–256. [Google Scholar]
- Wen, H.; Fang, J.; Wu, J.; Zheng, Z. Transaction-based hidden strategies against general phishing detection framework on ethereum. In Proceedings of the ISCAS, Daegu, Republic of Korea, 22–28 May 2021; pp. 1–5. [Google Scholar]
- Joshi, K.; Bhatt, C.; Shah, K.; Parmar, D.; Corchado, J.M.; Bruno, A.; Mazzeo, P.L. Machine-learning techniques for predicting phishing attacks in blockchain networks: A comparative study. Algorithms 2023, 16, 366. [Google Scholar] [CrossRef]
- Ali, M.N.; Imran, M.; din, M.S.U.; Kim, B.S. Low rate DDoS detection using weighted federated learning in SDN control plane in IoT network. Appl. Sci. 2023, 13, 1431. [Google Scholar] [CrossRef]
- Kazmi, S.H.A.; Qamar, F.; Hassan, B.; Nisar, K.; Chowdhry, B.S. Survey on joint paradigm of 5G and SDN emerging mobile technologies: Architecture, security, challenges and research directions. Wirel. Pers Commun 2023, 130, 2753–2800. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Proposed Model | HFL/VFL | Tree Algorithm | Security Measure | Performance Improvement | ||
|---|---|---|---|---|---|---|
| Security | Accuracy | Efficiency | ||||
| Tree-based FL [35] | HFL | GBDT | DP + SecAgg | ✓ | ✓ | |
| FEDXGB [33] | HFL | XGBoost | HE + SS | ✓ | ✓ | |
| F-XGBoost [45] | HFL | XGBoost | K-Anon | ✓ | ✓ | |
| Federated Forest [37] | HFL | Extra trees | LDP | ✓ | ✓ | |
| DFedForest [46] | HFL | RF | Blockchain | ✓ | ✓ | |
| FL-XGBoost [47] | HFL | XGBoost | Encryption | ✓ | ||
| FedXGB [48] | HFL | XGBoost | SS | ✓ | ✓ | |
| DPBoost [49] | HFL | GBDT | DP | ✓ | ||
| SimFL [50] | HFL | XGBoost | LSH | ✓ | ||
| eFL-Boost [36] | HFL | GBDT | SecAgg | ✓ | ||
| Pri Fed GBDT [38] | HFL | GBDT | RDP | ✓ | ✓ | ✓ |
| SecureBoost [23] | VFL | XGBoost | HE | ✓ | ||
| SecureBoost+ [51] | VFL | XGBoost | HE | ✓ | ✓ | |
| Pivot [34] | VFL | RF & GBDT | HE + MPC | ✓ | ✓ | |
| Secure XGBoost [52] | VFL | XGBoost | SecEnclave | ✓ | ||
| FLSectree [53] | VFL | XGBoost | Encryption | ✓ | ✓ | |
| FedXGBoost [54] | VFL | XGBoost | DP | ✓ | ||
| VF2Boost [39] | VFL | GBDT | SecAgg | ✓ | ||
| FEVERLESS [55] | VFL | XGBoost | SecAgg + CDP | ✓ | ✓ | |
| Fed-EINI [32] | VFL | RF & GBDT | HE | ✓ | ✓ | |
| FedGBF [56] | VFL | RF & GBDT | Encryption | ✓ | ||
| FedRF [57] | VFL | RF | Encryption | ✓ | ||
| OpBoost [58] | VFL | XGBoost | LDP | ✓ | ✓ | |
| VPRF [21] | VFL | RF | HE | ✓ | ✓ | |
| SGBoost [59] | VFL | XGBoost | SS + FE + SHE | ✓ | ✓ | ✓ |
| VF-CART [40] | VFL | CART | HE | ✓ | ||
| PriVDT [60] | VFL | GBDT | FSS | ✓ | ||
| FederBoost [24] | HFL/VFL | GBDT | SecAgg + DP | ✓ | ✓ | |
| Mechanisms | Technology | Principle | Advantages | Disadvantages |
|---|---|---|---|---|
| Data ambiguity | DP | Central/local noise provided to perturb data or gradient values. | High computational efficiency; Low communication overhead; Post-processing, protecting published data. | Decreased accuracy and availability of training models. |
| Process encryption | HE | Gradient encryption, operating on ciphertext. | Strict privacy protection. | Unable to handle complex operations; Low computational efficiency; High storage overhead. |
| SMC | Intermediate data are private and cannot be learned by other parties. | Prevent man-in-the-middle attack and data leakage. | Low computational efficiency; High communication overhead. |
| Aggregating decision trees | Structure-based: according to the hierarchical structure of the tree, then aggregating different layers. Classifying the samples in the sub-nodes in the hierarchy. |
| Weight-based: considering the division of the tree as a set, and aggregating the weight values of the samples in the set. | |
| Logic-based: considering the setting up of the decision tree as a set of logical rules, and then aggregating the logical expressions. | |
| Dataset-based: fitting the results of multiple decision trees onto a complete dataset. | |
| Selecting decision trees | In one iteration, selecting the single tree that best represents the information of all datasets as the global model. |
| Training Stage | Incremental learning. |
| Model compression and pruning. | |
| Parallel and asynchronous computing. | |
| Sampling and subsampling. | |
| Prediction Stage | Client inference. |
| Compression model and quantization. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Gai, K. Decision Tree-Based Federated Learning: A Survey. Blockchains 2024, 2, 40-60. https://doi.org/10.3390/blockchains2010003
Wang Z, Gai K. Decision Tree-Based Federated Learning: A Survey. Blockchains. 2024; 2(1):40-60. https://doi.org/10.3390/blockchains2010003
Chicago/Turabian StyleWang, Zijun, and Keke Gai. 2024. "Decision Tree-Based Federated Learning: A Survey" Blockchains 2, no. 1: 40-60. https://doi.org/10.3390/blockchains2010003
APA StyleWang, Z., & Gai, K. (2024). Decision Tree-Based Federated Learning: A Survey. Blockchains, 2(1), 40-60. https://doi.org/10.3390/blockchains2010003