 Prof. Dr. Roberto Theron
Prof. Dr. Roberto Theron
Prof. Dr. Roberto Theron
E-Mail
Website
Collection Editor
Computer Science and Automation Department, University of Salamanca, 37008 Salamanca, Spain
Interests: visual analytics; information visualisation; human-computer interaction; digital humanities
 Ms. Eveline Wandl-Vogt
Ms. Eveline Wandl-Vogt
Ms. Eveline Wandl-Vogt
E-Mail
Website
Collection Editor
Austrian Academy of Sciences, Austrian Centre for Digital Humanities (ACDH-ÖAW), Vienna, Austria
Interests: open innovation; experimental humanities; knowledge design; standards and infrastructures; spatial humanities
 Dr. Jennifer Cizik Edmond
Dr. Jennifer Cizik Edmond
Dr. Jennifer Cizik Edmond
E-Mail
Website
Collection Editor
Trinity College Dublin, Dublin, Ireland
Interests: digital humanities; research infrastructure; digital society
 Dr. Cezary Mazurek
Dr. Cezary Mazurek
Dr. Cezary Mazurek
E-Mail
Website1
Website2
Collection Editor
Poznan Supercomputing and Networking Center, 61-888 Poznan, Poland
Interests: research infrastructures; software development; digital humanities; data and information analysis
Dear Colleagues,
In recent years, with the pervasiveness of computers and a great variety of electronic devices connected to the Internet, Digital Humanities (DH), as a research field, has experienced a great transformation that has permitted the completion of very ambitious projects with a large impact on society beyond academia. This has resulted in a major economic impact in the cultural and creative industries. A number of new and powerful ICTs have made possible the exploitation of a wealth of data (either digitized or digitally born) that have enormously changed the practices of DH, and exposed novel challenges that must be faced in order to complete any of the said projects. From the creation to the consumption of digital resources, there are new stakeholders, contexts and tasks to consider. The amount of digital resources produced (or digitized), stored, explored, and analysed in any DH project is immensely vast (especially if we take into account the introduction of linked-data), so the traditional humanities tools have to be either substituted or aided with ancillary tools in the form of interactive visualizations or novel user interfaces.
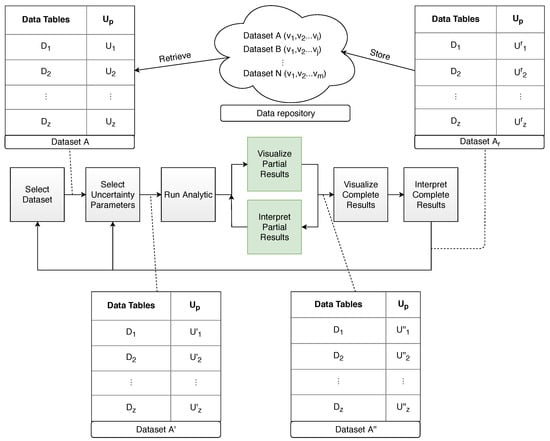
Furthermore, during the whole lifecycle of any DH project—from the data preparation to the actual analysis or exploration phase—many decisions have to be made in order to yield the desired results, which depend on the uncertainty pertaining to both the datasets and the models behind them.
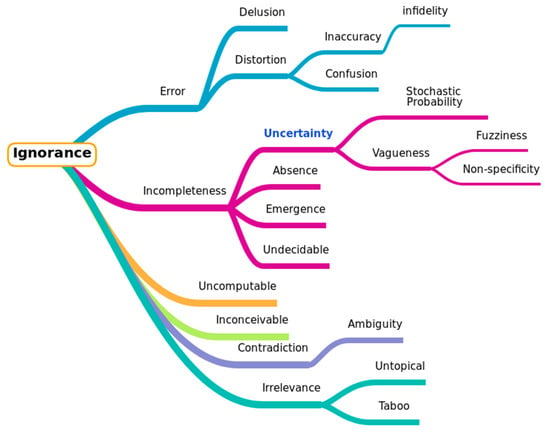
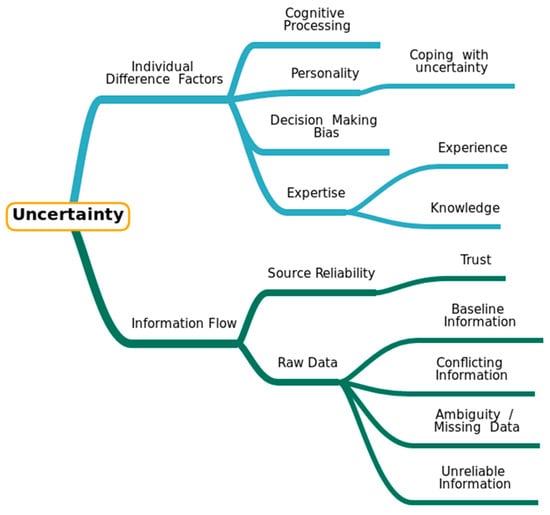
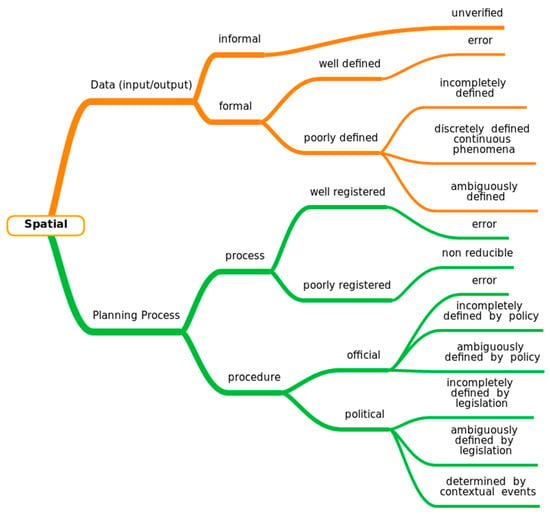
One result of these many adjustments, adaptations and migrations is that the sources, nature and role of uncertainty in humanities research, and the options researchers have to manage them, are changing. Debates, which previously could not be resolved in a satisfactory way, can now be argued statistically, but, at the same time, certain rich modes of information input, from the library shelf to the potsherd, have been deprecated in the shadow of their less contextualised digital surrogates. This Special Issue will feature a range of perspectives on how humanistic researchers’ relationship to uncertainty has changed in the digital age, how the risks might be managed and the opportunities exploited, and what digital research in other disciplines might learn from the lessons of uncertainty in DH.
Topics:
- Concepts of uncertainty in various disciplines
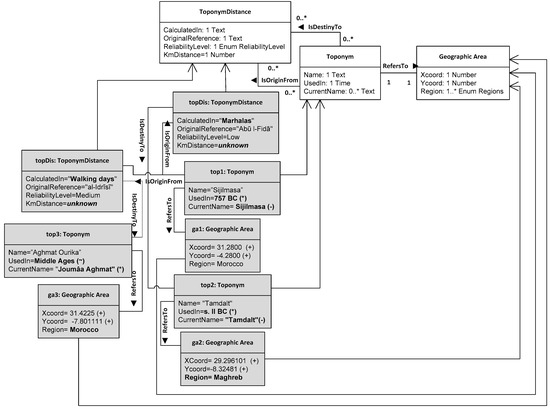
- Understanding all the sources of uncertainty that can affect the DH practice
- Assessing the degree of uncertainty of data sources
- Quantifying and Measurement of uncertainty in various disciplines
- Uncertainty, risks and innovation
- Uncertainty and digital transformation
- Communication of uncertainty to the user/researcher
- Uncertainty and teaching, communication of uncertainty to scholars
- Uncertainty and the media, communication of uncertainty to non-scientists
- Applications
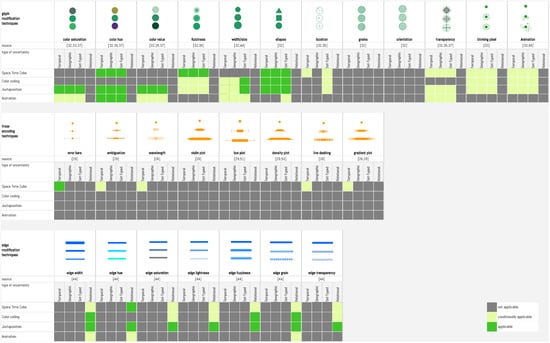
- Software and tools for uncertainty management
- Technologies like semantics, linked data and language processing for data uncertainty
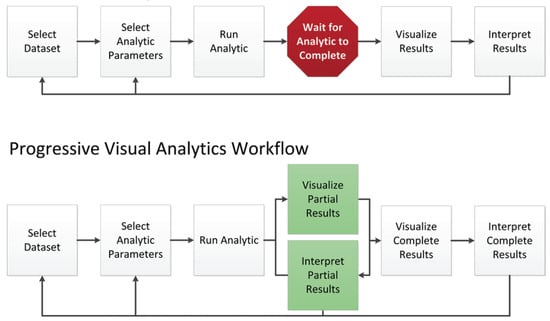
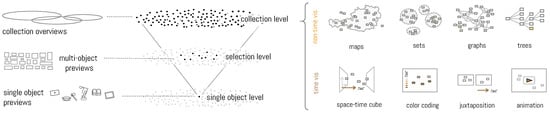
- (Progressive) Visualization of uncertainty
- History of discussion certainty and uncertainty in science
Assoc. Prof. Roberto Sánchez
Ms. Eveline Wandl-Vogt
Dr. Jennifer Cizik Edmond
Dr. Cezary Mazurek
Guest Editors
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. Manuscripts can be submitted until the deadline. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 100 words) can be sent to the Editorial Office for announcement on this website.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Informatics is an international peer-reviewed open access quarterly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 1800 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}