1. Introduction
Customers are one of the most important assets of an enterprise, and they play a very important role in improving the market competitiveness and performance of the enterprise [
1]. Amid fierce market competition, customers can easily choose among numerous products or service providers [
2]. Studies show that the cost of developing a new customer is often higher than the cost of retaining an old customer [
3]. If an enterprise maintains a good relationship with customers for a long time, it will gain more profits from existing customers. If the customer retention rate increases by 5%, the net present value of the enterprise will increase by 25–95% [
4]. When the customer churn rate is reduced by 5%, the average profit margin of an enterprise will increase by 25–85% [
5,
6]. In order to maintain market advantages, it has become important for enterprises to determine how to make use of existing customer resources and avoid the loss of existing customers [
7].
Customer churn prediction techniques can be used to identify customers that may be lost. Then, marketing strategies can be improved according to the forecast results. Retention of existing customers can effectively prevent performance loss [
8]. Datta et al. proposed a framework for customer churn management that comprised data acquisition, business understanding, feature selection, a construction model, and a validation model [
9], this literature described CHAMP (CHurn Analysis, Modeling, and Prediction), an automated system, and offered specific guiding methods for researching customer churn management, which is significant. Jain et al. showed that in the highly competitive telecom market, companies must analyze corporate behaviors to determine customer loss and take effective measures to retain existing customers [
10]. Research on churn prediction was carried out in the telecom, banking, retail, and other industries. For example, in the prediction of telecom customer churn, Coussement et al. examined the customers’ calling behavior, customer and operator’s interaction behavior, package subscription, account information, calling information, and demographic characteristics [
11]. Loss prediction was performed through algorithms, such as the logit model, simple linear regression, k-nearest neighbors, decision tree, and artificial neural network [
11,
12,
13]. For the customer churn prediction, credit card information, transaction information, and abnormal usage information have been used to predict customer churn through the logit model and decision tree algorithm [
14,
15]. Online shopping is a common consumer shopping mode. E-commerce enterprises constantly launch new products; market conditions are constantly changing, and many e-commerce enterprises face the serious problem of customer loss [
11].
However, most of the studies on customer churn prediction are concentrated in the telecom, banking, retail, and other industries, and there are few studies on customer churn prediction in B2C e-commerce. Customers in the telecommunications and banking industries need to sign contracts with enterprises, which means the customers are contractually bound. These enterprises can accurately identify customer churn. Online shopping customers do not need to sign contracts with enterprises. The shopping behavior of non-contractual customers is complicated, and the loss state is vague. E-commerce enterprises often find it difficult to judge when and why their customers are lost and whether it is worth retaining them. In addition, the shopping behavior dataset of B2C e-commerce customers contains two types of data. The first type of data is the demographic data of customer groups, such as age, gender, address, contact information, nationality, and social class. E-commerce enterprises can easily obtain the data directly from their database. The other kind of data is customer shopping behavior data, including shopping time, purchase preparation, shopping intention, and attitude toward products [
16], this literature (Kotler and Keller) points out the research methods and direction for researchers studying customer relationship management and plays an important role in classifying data attributes. The behavioral data of B2C e-commerce customers are characterized by longitudinal timeliness and multidimensional variables, and such data are usually stored independently in the business database managed by enterprises [
17,
18]. B2C shopping websites have an extensive variety and quantity of customer data, including customer behavior information, such as shopping time, clicking on product pages, collecting goods, adding to a shopping cart, and shopping frequency. These information variables may have a better ability to predict customer churn. In the previous works on forecasting customer churn in e-commerce, longitudinal behavior data and longitudinal timeliness of customers are often ignored [
19,
20,
21].
E-commerce enterprise managers can use big data and cloud computing to analyze and model consumer behavior data by extracting all kinds of information as well as carrying out customer churn prediction research. This paper builds on existing research and uses B2C e-enterprise, non-contractual customers, as the research object to analyze data and information on shopping behavior. The k-means algorithm was used for customer segmentation, and the random forest was used to select variable characteristics. Finally, a machine learning algorithm was used to construct an erosion prediction model, and the empirical results are discussed. This paper aims to provide B2C e-commerce enterprises with a complete solution for customer segmentation and churn prediction and help enterprise managers realize customer relationship management that utilizes artificial intelligence technologies. The ultimate goal is to formulate reasonable and effective customer retention strategies and reduce operating costs for enterprises.
The rest of this paper is organized into five parts. The next section is the literature review.
Section 3 describes the research methods, including the introduction of the basic principles of support vector machine (SVM) and logistic regression (LR).
Section 4 presents the empirical methodology, including data pretreatment, customer segmentation based on k-means, feature selection based on random forest, and prediction evaluation indicators.
Section 5 presents the experimental results and discussion.
Section 6 is the conclusion.
2. Literature Review
The forecasting methods of customer churn can be summarized into three types: forecasting methods based on traditional statistical analysis, prediction methods based on machine learning, and prediction methods based on combinatorial classifiers. The prediction methods based on traditional statistical analysis mainly include linear discriminant analysis, the naive Bayesian model, cluster analysis, and logistic regression. For example, Pınar et al. used a naive Bayes classifier to predict customer churn of a telecom company in 2011. Their results showed that the average call duration of customers was strongly correlated with customer churn [
22]. Renjith et al. predicted e-commerce customer churn by logistic regression and proposed a personalized customer retention strategy using machine learning [
23]. Caignya et al. combined logistic regression and a decision tree to predict customer churn in the telecom industry [
24]. In these studies, traditional statistical analysis methods were used for prediction, and the prediction model had strong interpretability. However, these methods have a limitation while dealing with big data and multidimensional variable data; the prediction performance was not obvious in these cases.
Prediction methods based on machine learning mainly include decision trees, the support vector machine, and artificial neural networks, among others. For example, Neslin et al. stated that decision trees are widely used in practical customer churn prediction. The decision tree algorithm can be applied as the basic model of loss prediction [
25]. Zhang et al. used the C5.0 decision tree to predict the loss of postal short message service of telecom enterprises. The results showed that the C5.0 decision tree prediction model had high accuracy [
26]. Farquad et al. predicted the churn of bank credit card customers and proposed a hybrid method to extract rules from the support vector machine [
27]. Gordini et al. predicted the loss of B2B e-commerce customers, and the results showed that the support vector machine had a good prediction performance in processing noisy, unbalanced, and non-linear B2B e-commerce data [
7]. Tian et al. predicted the churn of telecom customers, extracted appropriate variables from the original data with a two-layer neural network and proposed a churn prediction model based on an artificial neural network. The results showed that the prediction effect of this method was better than that of the decision tree and naive Bayes classifier [
28]. Yu et al. studied the prediction of telecom customer churn, used iterative particle classification optimization and particle fitness calculation to train the prediction model, and proposed a BP neural network based on particle classification optimization. The results showed that their method improved the accuracy of churn prediction [
29].
The prediction methods based on combinatorial classifiers integrate several weak classifiers and form a strong classifier. Commonly used combinative classifier methods include AdaBoost, XGBoost, and random forest. For example, Wu et al. studied the e-commerce customer churn prediction problem by balancing positive and negative class data by adjusting the sampling ratio, reducing the size of the dataset, and improving the classification accuracy of the classifier by combining the AdaBoost algorithm. The results showed that Adaboost had a good prediction effect [
30]. For datasets with time characteristics, such as that of telecom industry customers, Ji et al. proposed a hybrid feature selection algorithm based on XGBoost. The algorithm chose features from two angles to select the most important characteristic to predict customer churn while removing redundant features. The experimental results showed that this method had a good prediction performance [
31]. Ahmed et al. studied the prediction of customer churn in the telecom industry and proposed a prediction model based on a combinatorial heuristic algorithm [
32]. Ying et al. performed an in-depth study on the duality of bank customers and adopted integrated LDA and boosting methods to predict customer churn and achieved good prediction results [
33]. Zhang et al. used CART and the adaptive boosting integrated model to predict telecom customer churn. The results showed that their method had high prediction accuracy [
34].
In summary, researchers have used various forecasting methods to conduct in-depth research on the churn of contractual customers in the telecom industry, banking industry, and B2B e-commerce enterprises. Previous works have also discussed the advantages of various methods, thus making valuable contributions to the research on churn prediction of contractual customers. Customer loss of B2C e-commerce enterprises is concerning. Such customers’ shopping behavior is multidimensional, and their shopping intentions and tendencies are personalized. Therefore, using the characteristics of customer data, this work studies the loss of non-contractual customers of B2C e-commerce enterprises.
3. Research Methods
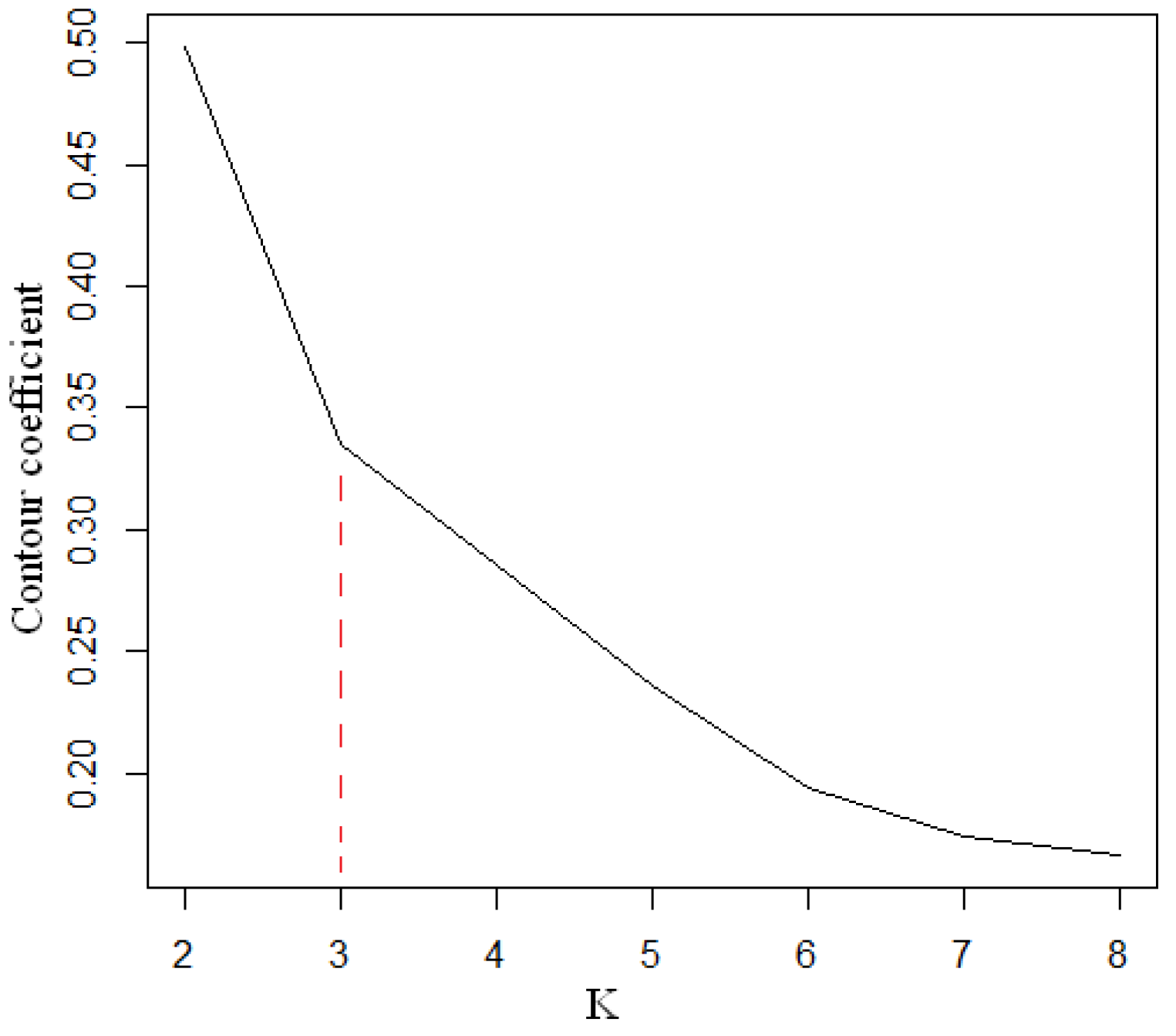
E-commerce customers have two possible behaviors: customer churn and customer non-churn. Therefore, customer churn prediction is a binary classification problem. Online shopping has its own characteristics in terms of shopping time and behavior. Taking shopping time and behavioral tendency into full consideration may play an important role in judging customer loss. In this research, there are two important steps- customer segmentation and churn prediction. The clustering algorithm and prediction model that are expected to be adopted are important tasks that must be determined. The chosen clustering algorithm is dependent on the type of data and the purpose of clustering. In the literature on customer segmentation from the last five years, the customer segmentation method via k-means has been adopted in the e-commerce [
35,
36], retail [
37,
38], finance [
39,
40], and telecommunications industries [
41,
42]. This algorithm can help process large-scale data and exhibits simple calculation and high operation efficiency, and thus has been widely adopted in other industries [
43]. In terms of prediction models, comparisons among prediction effects of different models for most literature are made by using a unified data set to determine the optimal one. In the literature on churn prediction [
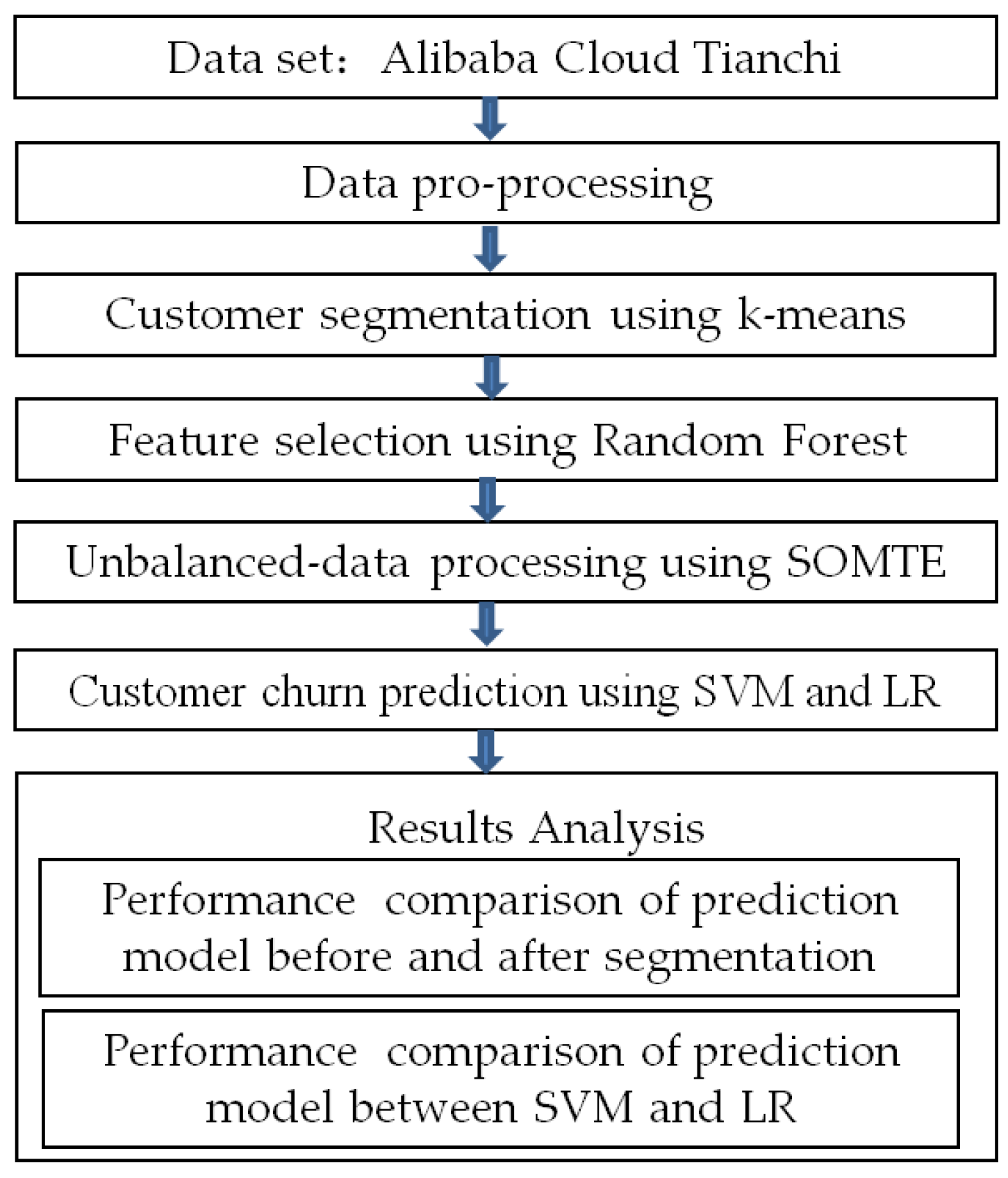
7], by comparing prediction models, such as LR, SVM, Neural Network, Decision Trees, and Random Forest, the research results show that the SVM model exhibited a positive prediction performance with a quick training speed. Therefore, considering the obvious advantages of the k-means and SVM algorithms, we chose the k-means and SVM as the main algorithms in this paper and made a comparative analysis through LR. On the basis of pre-processed data, this study first uses the k-means algorithm for the clustering subdivision of customers and then uses the LR algorithm and SVM algorithm to establish prediction models. The prediction accuracy and effectiveness of these two prediction models are investigated, and a comparative analysis is conducted. The research process is shown in
Figure 1.
The following is a brief introduction to the algorithms of SVM and LR.
3.1. Support Vector Machines
Support vector machines are linear classifiers [
44,
45,
46] that classify data by solving quadratic optimization problems to establish the optimal separation plane between datasets. SVM can also be applied to nonlinear classification problems by kernel function transformation. SVM transforms the original problem into a more solvable dual problem through the Lagrange multiplier method, which is mathematically expressed as:
Take partial derivatives of
w and
b, and set them to 0, yielding:
Substitute Equations (2) and (3) into Equation (1), and finally convert the original problem into the following objective function (4) for the solution:
SVM can simulate the nonlinear decision boundary well with the kernel function and also control overfitting.
The advantage of SVM is that it can improve the generalization ability and deal with high-dimensional data problems.
3.2. Logistic Regression
Logistic regression is a classical classification method [
47,
48]. It predicts the probability of the categories of the dataset of unknown categories through the dataset of the existing category labels. It can be expressed as
P(
Y|
X) in the form of a conditional probability distribution. Take dichotomies as an example, where
X is an n-dimensional vector and
Y is 0 or 1. The mathematical expression of the prediction result is:
where the real values of the linear regression model
z =
WTx +
b are transformed into values between [0, 1] by the sigmoid function. In other words, the result of a certain sample
X calculated by Equation (5) or (6) is the probability that the sample point
X belongs to a certain class. We can categorize them by setting thresholds. Generally, values calculated by the sigmoid function are classified as category 1 if they are greater than or equal to 0.5 and category 0 if they are not. The advantage of LR is that the results are easy to interpret and applicable to both continuous and categorical variables.
6. Discussion
As mentioned in the first part of this paper, the behavioral data of B2C e-commerce customers is characterized by vertical timeliness and a variety of behavioral information (PV, Buy, Cart, and Fav). We take those shopping behaviors recorded with time periods (segments) as an important variable characteristic and segment the shopping time into four periods (Daybreak, AM, PM, and Night), which is a new opinion of this paper. Among the customer segmentation models, the classical RFM model is popular. The recency in the model takes the time information as the variable, i.e., the time variable. To study the impact time variables have on customer segmentation and churn prediction, Chang et al. [
66] extended the time variable and offered an LRFM model based on RFM. L is defined as the number of time periods (such as days). The research results show that the number of time periods (L) is an important variable for customer churn prediction and can be used to evaluate customer loyalty. Rachid et al. [
67] studied the LRFM model using a data set from online retailers (electronics, fashion, household appliances, and children’s products) and took the number of time periods as an important variable for churn prediction. The results show that customer shopping behaviors in different time periods (days) are quite different. In the literature of Wu et al. [
30], the shopping periods of e-commerce customers were divided into three periods, i.e., day, night, and late night (not segmented into “hours”). The results show that the customer churn rates in different periods are different. Alboukaey et al. [
41] proposed an RF-Daily model, in which the time variable was defined as daily dynamic behavior (not monthly dynamic behavior). The daily dynamic behavior and other variables form the multivariate time series. The results show that the churn prediction effect of the model is good, and the daily model is significantly better than the monthly one. Chen et al. [
68] also extended the RFM model and proposed an LRFMP model, in which the Time Variable L represents the time between transactions. The results show that the time between transactions has a great impact on customer churn.
The time (period) variable described in this paper is divided into “hours”. In the prediction data set, excluding the variable of Categories, the data variables in this paper are composed of time variables (Daybreak, AM, PM and Night) and four behavior variables (PV, Buy, Cart, and Fav). Our model can be called RF-PBCF, and the empirical research shows that the Night and PM variables have a great impact on churn predictions. It can be seen from
Table 3 that the importance of Night Buy and PM Buy variables ranks as the top two. Our results are fundamentally consistent with the results of the aforementioned literature, namely, the shopping time variable is key to churn prediction, which embodies a new value for this paper. Marketing managers are particularly interested in when customers shop because this time variable segmented into hours can provide operable information for them. They can then provide real-time and customized product promotions for customers during these time periods according to this operable information for the sake of continuous customer retention.
The literature on B2C e-commerce customer relationship management primarily focuses on researching customer churn prediction modeling [
69,
70,
71]. One of the purposes of customer churn prediction for enterprises is to evaluate the effectiveness of customer retention measures and conduct targeted commodity promotion activities for retained customers. These marketing strategies should be operable, or enterprises should not only determine target customers according to the customer churn tendency but evaluate the practical effects of customer retention measures according to the practical situation [
72]. This paper adopts the research method Classification before Prediction. The customers are first segmented into three types according to the k-means algorithm. After the type of customers is made clear, customer churn can then be predicted. The recent literature [
73] emphasizes the importance of customer segmentation, which places customer segmentation as the first step, and is thus fundamentally consistent with our research method (Classification before Prediction). For e-commerce enterprises, our research method holds practical significance. For example, when an enterprise determines that Cluster I is the key customer group to be focused on, it can make a churn prediction for Cluster I customers through an appropriate algorithm, judge the churn tendency of Cluster I customers according to the prediction and evaluation indicators and then formulate appropriate marketing strategies. If the enterprise cannot judge such customers in time, no effective customer retention strategies will be carried out, and, accordingly, part of the Cluster I customers may be subject to churn. Therefore, the research method utilized in this paper fully takes into account customer retention. Our research results reflect practicality, which embodies another important value of this paper.
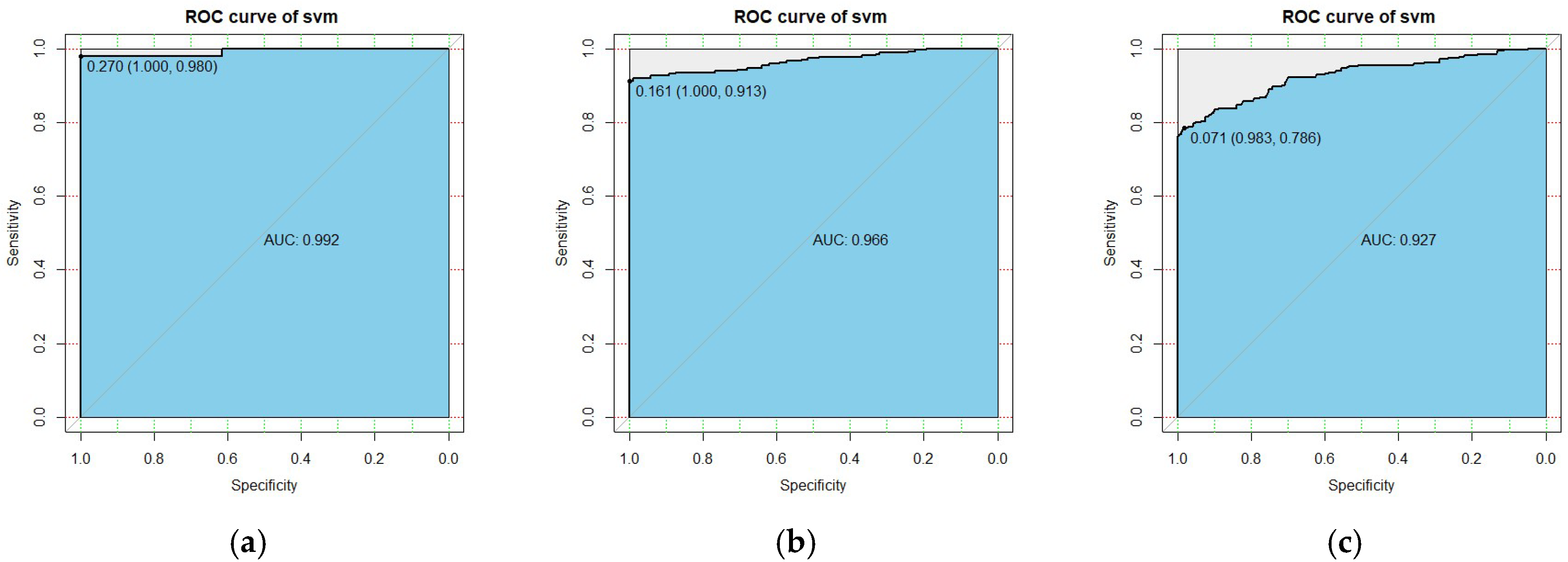
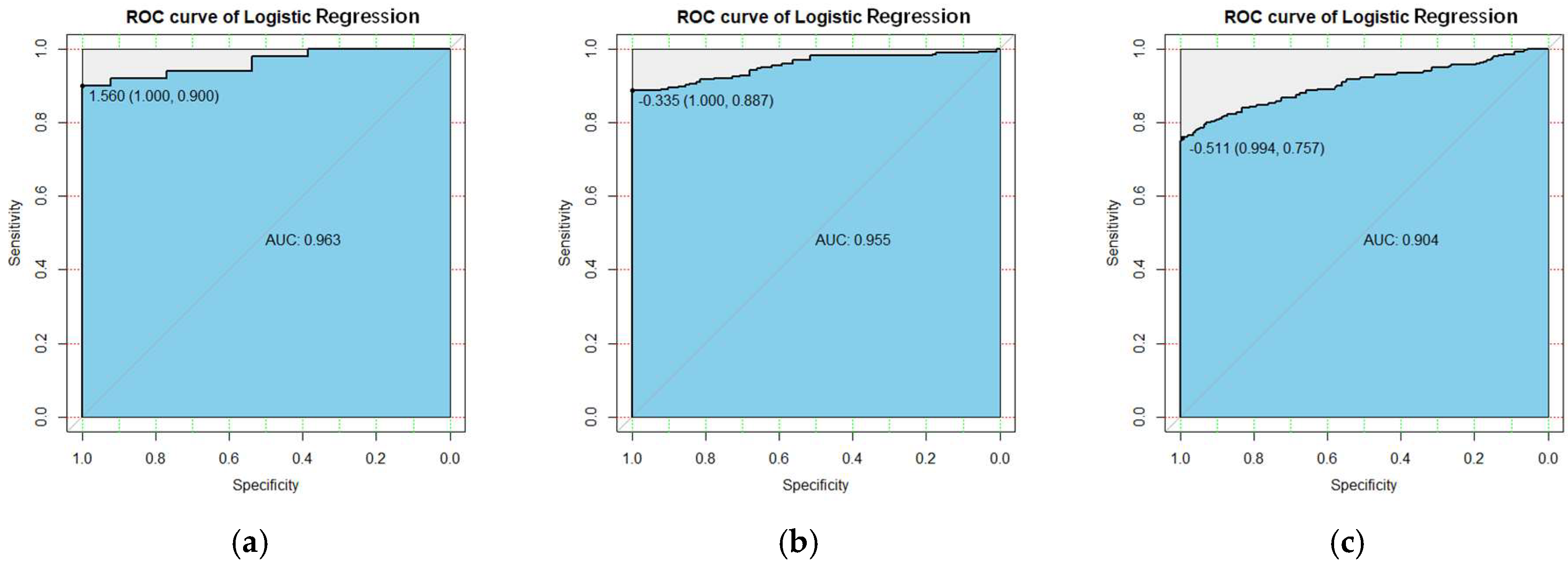
LR and SVM are compared to judge the prediction performance of the two models, which is consistent with the research methods and results of other literature. The prediction performance of SVM is better than that of LR [
74,
75,
76]. When evaluating the prediction performance of a model, undoubtedly several performance indicators are always used. Our research adopts three indicators, namely Accuracy, Recall, and Precision, which are basically the same as those evaluation indicators mentioned in other literature [
7,
77,
78]. However, we believe that the customer data of e-commerce enterprises is unique. Enterprises often change product information or upload a variety of evaluation information about consumption for the sake of customer retention, which is quite different from financial and telecommunication customer information. The training and testing times of various prediction models are quite disparate when dealing with customer data. As a matter of fact, when we use the SVM model to train customer data, the data training time for SVM is significantly reduced than that for LR. To retain customers, e-commerce enterprises need to predict customers in real time. Therefore, the operational efficiency of the models should be considered, which is mentioned in only a few pieces of literature [
57].
6.1. Theoretical Implications
Our research results, to some extent, are enlightening for model development in B2C e-commerce customer churn predictions and customer relationship management in enterprises. We first made some contributions to the existing literature on customer segmentation and churn prediction models in the B2C e-commerce industry. In this paper, four variables that directly affect consumer shopping behaviors were selected based on various information from current online shopping websites as our data variables, and a new customer churn prediction model is thus developed. The variables of this model comprehensively reflect consumer shopping behavior and specific shopping times. New opinions have been proposed based on the methods for selecting variables, segmenting customers, and realizing variable quantity dimension reduction under the B2C e-commerce environment. Although a large number of shopping websites exist, not all variables have the same impact on customer churn. The previous researches [
68] are a basis for this paper, helps us continue to expand the research scope and shows that shopping time (time period) is a key variable for prediction. Traditional R and F variables are not key for predictions. For customers who are most likely to choose other companies for consumption, the “Buy” and “PV” within the Night and PM periods are the most relevant variables for customer churn. Previous research on customer churn [
69,
70,
71] has focused on the prediction performance of models. Although we have a limited understanding of the reasons for customer churn in the B2C e-commerce industry and enterprises, studying the impact of time variables (P, B, C and F) in this context helps prove the generalizability of the traditional RFM model. In addition, this paper, based on the research method segmentation before prediction, clarifies how to predict customer churn more accurately in the e-commerce industry, which is another achievement of this paper.
6.2. Implications for Practice
From a practical point of view, our research results are also significant. Developing a customer churn prediction model that meets the practical requirements of enterprises is obviously helpful for enterprise customer relationship management. Enterprises can have an insight into the causes of customer churn in accordance with the importance of consumption characteristics. Our research is helpful for B2C e-commerce marketing managers in optimizing enterprise marketing strategies and retaining customers through commodity promotion activities based on the results of the churn model (rather than the traditional churn prediction model) proposed in this paper. Traditional churn prediction models cannot fully achieve the business goal of maximizing customer retention, namely, how to minimize customer churn through the commodity recommendation system. Traditional churn prediction models focus more on the overall results, namely, whether customers will churn, but ignore the factors of customer retention in practical situations. For an enterprise, these may cause some problems in that online shopping customers usually have their own individual consumption habits and intentions. If the enterprise cannot adapt to customer consumption habits, a transfer of customers with consumption intention to other competitive companies will be caused. Traditional models often ignore the correlation between the number of churned customers and the retained ones to exclude some of them with shopping intention from retention activities. For example, some customers habitually, such as shopping at night, however, commodity promotion activities are not held at night. This problem can be solved by accurately identifying customer types and improving the customer churn model, i.e., the customer segmentation method and prediction model mentioned in this paper. Gattermann-Itschert et al. [
78] studied the correlation between the number of churned customers and retention activities through a field experiment and proved the effectiveness of customer retention activities based on the churn prediction with practical evidence. The model proposed in this paper can help enterprises lock target customers easily. Enterprises can reduce not only customer churn but also marketing expenditures. The research results show that the combination of our customer segmentation and the prediction model is a feasible scheme for B2C e-commerce enterprises to deal with customer churn.
On the other hand, we support the analysis teams of enterprises adopting a prediction method that combines customer segmentation and churn prediction. Our research shows that the performances of these customer segmentation methods and prediction algorithms are similar to that of other methods, including the SVMauc prediction model [
7], segmentation-based modeling approach [
73], and multi-slicing technique [
78]. The existing marketing literature detail that k-means customer segmentation is a valuable tool in all cases because there will always be some customer groups with different shopping behaviors. For example, the literature [
79] shows that the customer churn rate of the time-based customer segmentation method is quite different from that of enterprise profitability (e.g., Money). Our research supports “segmentation first” as the first step in predictions, which is of practical guiding significance for enterprise customer retention. B2C e-commerce companies should understand that it is not impossible to fully utilize machine learning tools (technologies) in the customer recommendation system. Marketing managers need to constantly learn the application methods for various machine learning tools (technologies). The method mentioned in this paper is reliable and operable and allows an enterprise to judge which customers are liable to leave in time. Our research shows that marketing managers can easily optimize their customer retention strategies and product promotion activities by seeking target customer groups. Considering the operation efficiency of the model and the ability inherent in enterprise technical teams, the fruits of our method are consistent with previous literature [
80,
81]. The technical teams and managers at companies should not only consider prediction technologies, but also the ability and knowledge of the personnel or managers using machine learning technologies. In short, for enterprises, cooperation between people and technologies is always necessary for data processing and customer segmentation or model optimization and performance evaluation.
7. Conclusions
Customer churn predictions are very important in e-commerce. To maintain market competitiveness, B2C enterprises should make full use of machine learning in customer relationship management to predict the potential loss of customers and devise new marketing strategies and customer retention measures according to the prediction results. This will help establish efficient and accurate loss prediction for e-commerce enterprises.
This paper used customer behavior data of a B2C e-commerce enterprise to test the predictive ability of the SVM and LR models. To evaluate the prediction performance of the two models, the k-means algorithm was first used for clustering subdivision to classify into three types of customers, and then predictions were made for these three types of customers. Accuracy, recall, precision, and AUC were calculated. There were two motivations for our research. The first purpose was to study the effectiveness of customer segmentation and the prediction effect of the model before and after customer segmentation according to the longitudinal timeliness and multivariate variables of customer shopping behavior. The experimental results prove that the customer segmentation of each prediction index has a significant improvement. Therefore, k-means clustering segmentation is necessary. The second purpose was to compare the effects of the LR model’s prediction based on traditional statistics and the SVM’s prediction based on machine learning. The results prove that the accuracy of the SVM model prediction was higher than that of the LR model prediction. These research results have significance for customer relationship management of B2C e-commerce enterprises.
The results of this study also have some limitations. We used a real data set containing 987,994 customers under the B2C environment, namely, the selection of data is limited to a certain extent. Ideally, the research results should be verified by several data sets. The results of customer segmentation greatly impact the prediction performance of the model. In terms of the method, this paper only uses the k-means algorithm to segment and divide customer types, which may have limitations, because if two or more segmentation methods are compared, more convincing results may be obtained. In addition, we only use a small number of predictive variables, which makes the promotion of our results limited, because a lot of shopping information is presented on B2C websites, and some of it may be ignored.
Future research can be conducted from several aspects. First, we can collect and compare the customer behavioral data from several companies to further enhance the generalizability of our model. Second, considering customer retention is a durative task of the enterprises, it is necessary to continuously predict and evaluate the churn. It is crucial to carry out a segmentation considering the customer value and build a prediction model with value variables, in that all prediction modeling works and customer retention activities of enterprises aim at profit first.







{kind=link}
{kind=link}
{kind=link}
{kind=link}