1. Introduction
Entropy maximization as the classical variational principle of the statistical physics is an effective tool for modeling and solving a lot of applied problems. There are many definitions of “entropy” functions [
1]. Part of them is connected with characterization of the macrosystems [
2]. They are the systems which consist of a lot of number elements with stochastic behavior but theirs holistic behavior is quasi-deterministic one.
For the first time this approach has been formulated in physics where the terms “microlevel, macrolevel” and “microstate, macrostate” appeared. Then it came into other scientific disciplines. Gradually, it became a tool for theoretic and experimental research. The macrosystems theory is based on this approach.
One of its branches is connected with the study of equilibria in macrosystems with indistinguishable elements, which are distributed in a random way among Fermi-, or Einstein-, or Boltzmann-states. For Fermi-macrosystems, only one element can be in each state, and for Einstein-macrosystems, any number of elements can be in each state. Boltzmann-macrosystems are considered as asymptotics of the first two classes of macrosystems, namely, when the mean number of elements in the the subsets of close states is small. The above phenomenology of states can be interpreted as a statistic by Fermi, Einstein, and Boltzmann, respectively.
However, the question arises as to how the statistics are arranged in macrosystems, the states in which can take
elements, i.e., the states can have capacities
, where
m is the number of the subsets and
is the number of elements that can occupy the
i-th subset. These statistics occupy the interval between the Fermi- and the Einstein-statistics and they are called
parastatistics of the order [
3,
4]. In the terms of the order, the Fermi-statistics is the
parastatistics of the order , and the Einstein-statistics is the
parastatistics of the order ∞.
We shall identify the macrosystems whose states are characterized by parastatistics of the order
as
paramacrosystems of the order [
5]. The problems of existing, uniqueness (or non-uniqueness) and identification of the equilibrium macrostates remain burning ones for paramacrosystems. In addition, these problems concern possibility to apply the variation principle of entropy maximization. They are not only cognitive but pragmatic, since a lot of applied systems related to urban and regional planning, demo-economic prediction, routing in computer network, and
etc., have “parastatistical” properties.
As microlevel of a paramacrosystem consists of elements with stochastic behavior, the macrostates are also random. Identification of macrostates, selection and study of equilibrium macrostate are based on forming of probabilistic characteristics of paramacrosystems (probability distribution or entropy functions), investigation of their morphological properties, and declaration of the variation principle.
The classical variation principle of statistical physics enunciates the uniqueness of the realized equilibria with entropy maximum. It is true for linear world or not so far from equilibrium state (also in the framework of the linear hypothesis). But the real world is nonlinear. The entropy function can have several maxima. Realization of macrostate depends on a dynamics of the distributed process and domain of attraction of any maximum of the entropy function.
Let us remark that the macrosystem theory is based on the phenomenological scheme in which the elements and the states are indistinguishable. However there are many interesting applied problems when the properties of the elements and the states are more various.
Our contribution to this theory consists of two parts. First, it is the method of forming the probability characteristics of the paramacrosystem with both the equiprobable microstates and the different combination of the distinguishable and indistinguishable elements and states.
The second contribution is connected with accounting of prior information (when the prior probabilities of microstates are not equal) by forming the probability characteristics of the paramacrosystem.
The probability characteristics (probability distribution and entropy functions) give the important information about the realized macrostate, i.e., the information about the number of the function’s maxima, and their morphological properties, namely, their “sharpness”. If the maximum is unique and “sharp”, then we could hope that the macrostate corresponding to such maximum is realized. The Fermi-, Einstein-, Boltzmann-macrosystems have these properties.
However, some types of the paramacrosystems have the entropy function and the probability distribution functions with non-unique maximum. Such situations arise when prior probabilities are not equiprobable. We will demonstrate some examples.
2. Phenomenology and Classification of Paramacrosystems
Description of the paramacrosystem includes descriptions of the elements, the states and the set of states . First of all, let us consider elements and states. Assume that there are two functionals, one of which is a generalized characteristics of the element and the other is a generalized characteristics of the state. If this functional takes on similar values for all elements, then the elements are indistinguishable (). If these values are strictly different, then the elements are distinguishable (). Analogical procedure can be applied for selection of the states. We will have the indistinguishable states () and the distinguishable states ().
Thereby, we obtain four classes of paramacrosystems:
is a paramacrosystem with distinguishable elements and states;
is a paramacrosystem with indistinguishable elements and distinguishable states;
is a paramacrosystem with distinguishable elements and indistinguishable states;
is a paramacrosystem with indistinguishable elements and states.
The classification above may be illustrated by the following examples with a random behavior of elements. Let us consider a distribution of specialists over vacancies in the labor market. In this case, the elements are the specialists and the states are vacancies. The functional for the elements is the level of qualification. The functional for the states is the salary. If the functionals for elements and states are different, then we have a model of -paramacrosystem.
Let us imagine that the specialists have the same level of qualification, and the salaries of the vacancies are different. In this case we have a model of -paramacrosystem.
A reversed situation occurs, when specialists of different level have to be distributed over equal vacancies, which corresponds to a model of -paramacrosystem.
Finally, there may be a situation, when specialists of equal level are distributed over identical vacancies, i.e., according to a model -paramacrosystem.
Now consider the set which is a union of disjoin subsets with states. The states have capacities . If all capacities , we have a macrosystem with Fermi-states. If all capacities , we have a macrosystem with Einstein-states.
The macrostates are described by vectors , where is a number of elements occupying the subset and is the set of feasible macrostates. From this definition, it follows that elements and states are faceless in it. On the other hand, its characteristics are made of some union of microstates, which are defined by a complete microscopic description of elements and states.
The microstate is characterized by the tuple , whose components are indexed elements, occupied a state in the set . The set of microstates contains Z various microstates , each of which is implemented with a probability .
Let, for each subset , there exist a prior probability of the entry into any of the states belonging to it. All are not equal to one another. Because it is assumed that the elements are distributed by states randomly and independently of one another, the probability of the fact that in the subset containing the states the states will be occupied and states will be free, is equal to .
As the subsets
do not intersect, the probability of the microstate
is defined by the following equality:
This function display the following property:
Introduce two functions:
We will present the function
(
1) in the form
In the set
of microsets there exists a subset
of microstates
with prior probabilities
, which generate the macrostate
. Denote the number of this microstates in the subset
by the
.
In view of the independence of microstates,
the probability of the macrostate for unequal-probable microstates takes the form:
where the normalization constant is
Here
.
If the
for all subsets
then
, where
. In this case,
the probability of the macrostate for equal-probable microstates takes the form:
where the normalization constant is
We will use also
the physical entropy defined with accurate multiplicative constant:
This implies that the problems of forming probabilistic characteristics of the paramacrosystems are reduced to defining the number .
3. Probability Characteristics of Paramacrosystems of
Order “” with Equal-Probable Microstates
We shall assume the distribution of elements is performed in two stages: first, the elements are distributed over the subsets ; and then, over the states within the subsets.
Following this distribution scheme, the number of microstates
generating the macrostate
is defined by the product of the numbers of elements’ allocations at the first
and second
stages:
3.1. -Paramacrosystem
We have paramacrosystem with distinguishable elements and states. So, the function
defines the number of allocations for
Y different elements in the subsets
with occupation numbers
:
The states in each subset
with occupation number
are different; their number is
and capacity is
. Denote
as a number of allocations for
different elements in
states with capacity
. As states are independent, then the function
takes them form:
We shall define the functions
using the method of generating functions [
6,
7]. Since the elements and states are different, the exponential generating function for permutations is used:
This equality determines values of the function
numerically. Examples of its computation are shown in the first column of Tables
Table 1 and
Table 2.
Table 1.
Examples of the allocation functions for , .
Table 1.
Examples of the allocation functions for , .
|
|---|
| | | | |
| 1 | 7 | 7 | 1 | 1 |
| 2 | 49 | 28 | 2 | 2 |
| 3 | 336 | 77 | 4 | 2 |
| 4 | 2226 | 161 | 10 | 3 |
| 5 | 14070 | 266 | 26 | 3 |
| 6 | 83790 | 357 | 76 | 4 |
| 7 | 463680 | 393 | 232 | 4 |
| 8 | 2346120 | 357 | 763 | 4 |
| 9 | 10636920 | 266 | 2583 | 3 |
| 10 | 42071400 | 161 | 8820 | 3 |
| 11 | 139708800 | 77 | 27720 | 2 |
| 12 | 366735600 | 28 | 72765 | 2 |
| 13 | 681080400 | 7 | 135135 | 1 |
| 14 | 681080400 | 1 | 135135 | 1 |
Table 2.
Examples of the allocation functions for .
Table 2.
Examples of the allocation functions for .
|
|---|
| | | | |
| 1 | 7 | 7 | 1 | 1 |
| 2 | 49 | 28 | 2 | 2 |
| 3 | 343 | 84 | 5 | 3 |
| 4 | 2394 | 203 | 14 | 4 |
| 5 | 16590 | 413 | 46 | 5 |
| 6 | 113610 | 728 | 166 | 7 |
| 7 | 765030 | 1128 | 652 | 8 |
| 8 | 5039160 | 1554 | 2779 | 9 |
| 9 | 32287080 | 1918 | 12607 | 10 |
| 10 | 200008200 | 2128 | 60340 | 10 |
| 11 | 1189788600 | 2128 | 299915 | 10 |
| 12 | 6744183600 | 1918 | 1512665 | 10 |
| 13 | 36097261200 | 1554 | 7562555 | 9 |
| 14 | 180435855600 | 1128 | 36501465 | 8 |
| 15 | 830791962000 | 728 | 165540375 | 7 |
| 16 | 3460897440000 | 413 | 686686000 | 5 |
| 17 | 12727626912000 | 203 | 2525322800 | 4 |
| 18 | 39863888064000 | 84 | 7909501600 | 3 |
| 19 | 100380151872000 | 28 | 19916696800 | 2 |
| 20 | 182509367040000 | 7 | 36212176000 | 1 |
| 21 | 182509367040000 | 1 | 36212176000 | 1 |
We can obtain analytic expressions for Fermi- and Eistein-states:
the capacity of the states is
the capacity of the states is infinite
The last relation corresponds to the number of permutations
of elements among
boxes with unbounded returns [
2].
Thereby, from (
10) we obtain that
and the distribution of the macrostates probabilities takes the form:
According to definition (
9) the physical entropy of the
-paramacrosystem is
where ≐ implies an equality with accurate additive constant.
We shall write expressions for the distribution of probabilities and entropies of the macrostates for Fermi-, Einstein-, Boltzmann-states. Let us consider a macrosystem with Fermi-states
. According to (
17) and (
14) the distribution of macrostates probabilities will have the following form:
Physical entropy will be
Assuming that the general number of elements in the F-macrosystem is sufficiently great, we can use the Stirling approximation of the factorial function. Then from (
20) we obtain the expression for information entropy (Fermi-entropy) [
8]:
Let us consider the paramacrosystems with Einstein-states (
). The distribution of macrostates probabilities is defined by the following equality:
Physical entropy is
The information entropy is constructed by the Sterling-approximation of the factorial function:
Let us consider macrosystems with Boltzmann-states. To obtain expressions for the distribution of macrostates probabilities, the limiting process in the corresponding expressions for Fermi- and Einstein-macrosystems is used.
For example, at
(F-macrosystem)
Then the function distribution of macrostates probabilities for Boltzmann-states takes on the following form:
Physical entropy is
After application the Sterling-approximation we obtain the generalized information entropy by Boltzmann–Shannon [
8]:
3.2. -Paramacrosystem
In this paramacrosystem, a microstate is specified by the numbers of elements
that occupy the state
j in the subset
. So, a microstate
The vector of macrostate
consists of the components
. Hence,
is a number of microstates,
i.e., the vectors
generating the occupation numbers
.
As the subsets
are independent:
where
is a number of locations of
indistinguishable elements in
distinguishable states with capacities
. The values of the function
are defined by an ordinary generating function [
7] in the following form:
This equality allows obtaining the analytical expression for the function
, which takes the form:
Tables
Table 1 and
Table 2 contain the values of the function
for
and
(second columns of the indicated tables).
As the subsets are independent, the distribution of the macrostates probabilities is equal to;
For
-paramacrosystems, the physical entropy has the form
Let us consider the special cases of the expressions obtained. At
, we obtain the distribution of macrostates probabilities (
19) and the entropy functions (
20) and (
21) for Fermi-states.
If , then we obtain the well-known expressions for macrosystem with Einstein-states:
—the distribution of the macrostates probabilities
—the information entropy
When
, we obtain Boltzmann distribution (
26) from (
35). The macrosystems of the ID-class with
and
are considered in [
8].
3.3. -Paramacrosystem
The -microstates can be viewed as classes of equivalency in the set of the -microstates. Those -microstates are equivalent such that one can be transferred into another by means of permutations of states within the subset .
By analogy with the
-paramacrosystems, the function
defining the number of
-microstates generating the macrostate
is determined by the following expression:
Here the function
defines the number of locations of
different elements in
in indistinguishable states with the capacity
. Using the technique stated in [
7], we obtain a generating function for
from the equality
Examples of the functions
for
and
are shown in the third column of Tables
Table 1 and
Table 2.
For the
-paramacrosystem, the distribution of the macrostates probabilities can be represented in the form
The physical entropy takes the form
Let us consider
-macrosystem with Fermi-states. Assuming in (
39) that
, we obtain:
It should be noted that these expressions do not derive from (
14) that defines the functions
and
for macrosystems with Fermi-states. The distinction is that the function
does not depend on
and
.
Substituting (
42) into (
40), we obtain the expression for the distribution of the macrostate probabilities of the
-macrosystems with Fermi-states:
It is classical polynomial distribution at equally possible outcomes of independent tests. The physical entropy for this class of macrosystems has the form:
Using the Stirling approximation, we obtain the expression for the information entropy:
Let us now consider
-macrosystem with Einstein-states (
). In this case we can represent the function
(
39) at analytical form:
where
are Stirling numbers of the second kind. So, the distribution of the macrostate probabilities for Einstein-macrosystem takes the form:
The physical entropy is
3.4. -Paramacrosystem
Both elements and states are indistinguishable in
-paramacrosystems. Therefore,
-microstates can be viewed as classes of equivalency of
-microstates. We consider the equivalent
-microstates where one can be transformed into another by means of permutations within the subset
.
Then we have
The problem of finding the numbers
is related to finding the number of partitions of the number
. The partition of the number
is its representation in the form of a sum of unordered set of integers
,
i.e.,
The disorder implies in this case that those sets
are considered different and cannot be transferred from one into another be means of permutations of the numbers
.
The function
specifies a number of partitions of the number
such that the number of parts in them does not exceed
and the size of the part is not greater than
. According to [
7], the generating function for
has the form:
Examples of the functions
for
and
are shown in the fourth column of Tables
Table 1 and
Table 2.
The distribution of the macrostate probabilities and the physical entropy have the forms:
Let us consider the case of Fermi-states (
). We obtain:
We can see that all macrostates are equally possible. Therefore, there no equilibrium macrostate in this case.
4. Probability Characteristics of Paramacrosystems of Order “” with Unequal-Probable Microstates
A case when the microstates have unequal probabilities is very wide-spread at the applied problems. For instance, the behaviour of the users in the transportation modeling is described by the unequal prior probabilities. Migratory decisions of the individuals are characterized by the different prior probabilities. At last, the prior images in a problem of the computer tomography are described in the terms of the unequal prior probabilities.
Existence of the unequal-probable microstates significantly influences the morphological properties of the macrostate probability characteristics for the paramacrosystems of the order
with
D and
I elements and states. We will account the unequal-probable microstates following the method from
Section 2 and
Section 3.
4.1. -Paramacrosystem
According to (
5) and (
16), the distribution of the macrostates probabilities is
where the functions
are defined by the equalities (
13), and the normalization constant
These expressions differ from the corresponding expressions (
16) and (
17). The multipliers
(
3) depend on the prior probabilities
and components of the macrostate’s vector
. Moreover, the definition (
57) includes as a normalization not a full number of microstates
Z, but a number of microstates
that corresponds to adopted prior probabilities only.
Let us note that values of the
for various values of the
Y can be found using the generating function:
Consider the special cases of the paramacrosystems of the DD-class, namely, with Fermi- and Einstein-states in the subsets
.
Let us recall that for the Fermi-states, the
and
From (
56) the distribution of the macrostates probabilities for Fermi-macrosystem takes the form:
The physical entropy is
The generalized information entropy
[
8] is defined by the following expression:
Consider the
-paramacrosystems with Einstein-states, for which the capacities of states are unbounded. So,
The distribution of the macrostate probabilities takes the form:
where the normalization constant is
The physical entropy takes the form:
where
Using the Stirling’s approximation we can obtain the information entropy for the
-paramacrosystem with Einstein-states:
From these formulas we can see that the distribution of the macrostate probabilities and the entropy functions do not depend on the capacities of the states. So, the capacity of states can be any value.
4.2. -Paramacrosystem
According to (
14), the distribution of the macrostate probabilities for
-paramacrosystem acquires the form:
where the functions
are defined by the equalities (
32) and
For the macrosystem with the Fermi-states, the expression (
68) is transformed to the distribution (
59). For the macrosystem with the Einstein-states, we will have:
The physical entropy is
The generalized information entropy by Einstein takes the form:
4.3. -Paramacrosystem
According to (
5), the distribution of the macrostate probabilities is defined by the following equality:
where the functions
are defined by the generating function (
39), and
Consider the special cases of the function (
73). If the
-paramacrosystem has Fermi-states (
), then according to (
39)
for
. The distribution of the macrostate probabilities for the
-paramacrosystem with Fermi-states takes the form:
Let us consider the
-paramacrosystem with Einstein-states. According to (
46) and (
47) we will have
4.4. -Paramacrosystem
According to (
5) the distribution of the macrostate probabilities takes the form:
where the functions
are defined by the generating functions (
52).
For the
-paramacrosystem with Fermi-states
, the distribution of the macrostate probabilities is
5. Examples
5.1. DD-Paramacrosystem
We consider a subway train consisting of m cars, each of which can accommodate R passengers. The car has two types of places in which passengers can be disposed: the seats and the car floor. The seats and floor are quantified, i.e., there are Q “sitting” and “standing” places. We will assume that the numbers of “sitting” and “standing” places are identical, i.e., . In addition, the “sitting” and “standing” places differ by their location in the car. The passengers are also different. We assume that the passengers are distributed in the car randomly and independently of one another. This distribution is also random.
Unequal prior probabilities. A survey of the transport behavior of passengers shows that the position of a car in the train plays an important role in the choice by the passenger of one or another car. Therefore, it seems to be natural to assign to each car a definite probability of the fact that it will be chosen by a passenger and, respectively, the probability of the fact that ith car will not be chosen.
Now let us describe this object in paramacrosystem terms. In this case, elements are the passengers distinguishable by their characteristics. As to states, we will consider the states of the first type, when a passenger can sit, and the states of the second type, when a passenger can only stand. The ith car is the subset of close states.
Thus, there are m subsets , each of which contains two different states, i.e., the capacities of the subsets are . The states of the first type and of the second type have identical capacities .
Since the states and elements are distinguishable, and the states have a finite capacity , we have the model of the DD-paramacrosystem of the order Q. Its macrostates is specified by the vector , the components of which are the numbers of passengers in appropriate cars.
By way of illustration, we will give a simple numerical example. We consider a train of two cars (
), each of which contains
seats and
standing places. Consequently,
and
. The total number of passengers that the train can accommodate is equal to 12. The passengers select the first or the second types of places, respectively, in a random way, independently of one another, and with prior probabilities
and
. According to (
3) the functions
.
Using the definition of the generating function (
13), we can represent the function
by the following equality:
Equating the coefficients at identical degrees
t, we can obtain values of the function
, which are given in
Table 3.
Table 3.
Values of the function .
Table 3.
Values of the function .
| n | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|
| 1 | 2 | 4 | 8 | 14 | 20 | 20 |
In this case
. So, the distribution of the macrostates probability takes the form:
where
Values of the function
are listed in
Table 4, and its graphic representation is shown in
Figure 1.
Table 4.
Probability distribution function with .
Table 4.
Probability distribution function with .
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | × |
|---|
| 0 | 4.72 | 6.33 | 4.23 | 1.88 | 0.55 | 0.1 | 0.012 | |
| 1 | 3.78 | 5.02 | 3.38 | 1.51 | 0.44 | 0.08 | 0.0094 | |
| 2 | 1.51 | 2 | 1.34 | 0.6 | 0.18 | 0.033 | 0.004 | |
| 3 | 4 | 5.4 | 3.6 | 1.6 | 0.47 | 0.088 | 0.01 | |
| 4 | 7 | 9.4 | 6.3 | 2.8 | 0.81 | 0.15 | 0.18 | |
| 5 | 8.1 | 10.82 | 7.2 | 3.2 | 9.4 | 0.17 | 0.02 | |
| 6 | 5.4 | 7.2 | 4.8 | 2.2 | 6.3 | 0.12 | 0.013 | |
Figure 1.
Probability distribution function with .
Figure 1.
Probability distribution function with .
We can see that the function has two maxima. One of them has value 0.1082 and argument , and the other has value 0.094 and argument . In this situation, the variation principle does not work.
Equal prior probabilities. If
, then the distribution of the macrostates probabilities takes the form:
where
Its values are given in
Table 5, and its graphic representation is shown in
Figure 2.
Table 5.
Probability distribution function with .
Table 5.
Probability distribution function with .
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | × |
|---|
| 0 | 1.95 | 3.91 | 3.91 | 2.56 | 1.15 | 0.33 | 0.055 | |
| 1 | 3.91 | 7.94 | 7.94 | 5.25 | 2.32 | 0.66 | 0.11 | |
| 2 | 3.91 | 7.94 | 8.01 | 5.25 | 2.32 | 0.66 | 0.11 | |
| 3 | 2.56 | 5.25 | 5.25 | 3.54 | 1.59 | 0.44 | 0.073 | |
| 4 | 1.15 | 2.32 | 2.32 | 1.59 | 0.67 | 0.19 | 0.032 | |
| 5 | 0.33 | 0.66 | 0.66 | 0.44 | 0.19 | 0.055 | 0.0091 | |
| 6 | 0.055 | 0.11 | 0.11 | 0.073 | 0.032 | 0.0091 | 0.0016 | |
Figure 2.
Probability distribution function with .
Figure 2.
Probability distribution function with .
As it would be expected, the distribution of the macrostates probabilities proves to be symmetric at equal prior probabilities. Its maximum equals to 0.0801 and corresponds to the macrostate .
5.2. ID-Paramacrosystem
Let us consider the object of the first example assuming the passengers are indistinguishable, while the states (places) are distinguishable.
Unequal prior probabilities. All parameters remain the same as those in the preceding example. In this case, the function
will be defined by the generating function (
31), which at the given parameters will take the form:
Values of the function
are given in
Table 6.
Table 6.
Values of the function .
Table 6.
Values of the function .
| n | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|
| 1 | 2 | 3 | 4 | 3 | 2 | 1 |
The distribution of the macrostates probabilities has the form:
where
Values of the function
are listed in
Table 7, and its graphic representation is shown in
Figure 3.
Table 7.
Probability distribution function with .
Table 7.
Probability distribution function with .
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | × |
|---|
| 0 | 2.36 | 3.17 | 3.18 | 2.84 | 1.42 | 0.64 | 0.21 | |
| 1 | 1.89 | 2.54 | 2.55 | 2.27 | 1.14 | 0.51 | 0.17 | |
| 2 | 1.14 | 1.52 | 1.53 | 1.36 | 0.68 | 0.31 | 0.1 | |
| 3 | 6.06 | 8.12 | 8.14 | 7.27 | 3.64 | 1.64 | 0.54 | |
| 4 | 1.8 | 2.4 | 2.5 | 2.2 | 1.1 | 0.5 | 0.2 | |
| 5 | 4.8 | 6.5 | 6.6 | 5.8 | 2.9 | 1.3 | 0.4 | |
| 6 | 9.7 | 12.9 | 13.2 | 11.6 | 5.8 | 2.6 | 0.9 | |
Figure 3.
Probability distribution function with .
Figure 3.
Probability distribution function with .
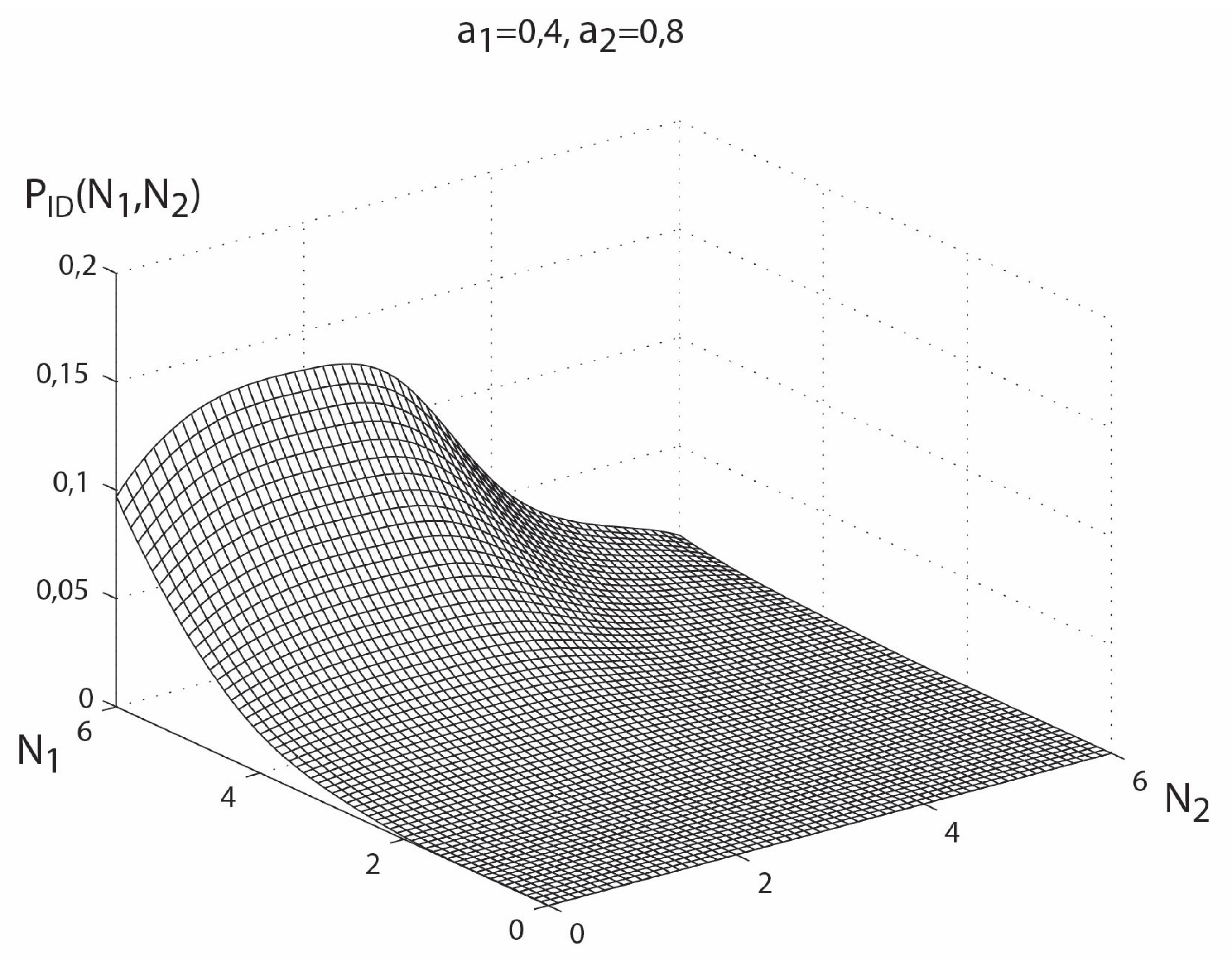
For the paramacrosystem under study, the distribution of the macrostates probabilities has a unique maximum equal to 0.132 and the corresponding argument .
Equal prior probabilities. In this case, the distribution of the macrostates probabilities takes the form:
where
Values of the function
are listed in
Table 8, and its graphic representation is shown in
Figure 4.
Table 8.
Probability distribution function with .
Table 8.
Probability distribution function with .
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | × |
|---|
| 0 | 0.39 | 0.078 | 1.2 | 1.6 | 1.2 | 0.078 | 0.039 | |
| 1 | 0.078 | 1.6 | 2.3 | 3.1 | 2.3 | 1.6 | 0.078 | |
| 2 | 1.2 | 2.3 | 3.5 | 4.7 | 3.5 | 2.3 | 1.2 | |
| 3 | 1.6 | 3.1 | 4.7 | 6.2 | 4.7 | 3.1 | 1.6 | |
| 4 | 1.2 | 2.3 | 3.5 | 4.7 | 3.5 | 2.3 | 1.2 | |
| 5 | 0.078 | 1.6 | 2.3 | 3.1 | 2.3 | 1.6 | 0.078 | |
| 6 | 0.039 | 0.078 | 1.2 | 1.6 | 1.2 | 0.078 | 0.039 | |
Figure 4.
Probability distribution function with .
Figure 4.
Probability distribution function with .
For the paramacrosystem under consideration, the distribution of the macrostates probabilities has the unique maximum equal to 0.062 and the corresponding argument .
6. Conclusions
The equilibrium theory of macrosystems is based on the assumption that their elements can occupy Fermi-states or Einstein-states only and these states are indistinguishable. However, there is quite a vast class of applied object, in which elements are distinguishable and states have finite capacity greater than unity. For designation of this class objects, the notion “paramacrosystem of the order ” is introduced in the paper. In these systems the notion of microstate, a set of which generates a macrostate in such object, differs from the classical one that was formulated in statistical physics. Mechanisms of element distribution in states have specific features. In this paper, we obtained the distribution of the macrostates probabilities and “physical” entropies for paramacrosystems, in which there can be both distinguishable and indistinguishable elements and states with finite capacities.
The method using the generating functions has been developed for determination of the probabilities characteristics of the paramacrosystems (DD, DI, ID, II class). The gained expressions allow to obtain known probabilistic characteristics for macrosystems with marginal capacities of states (Fermi and Einstein).
The method that takes into account prior information on the distribution elements of the paramacrosystems by states is suggested. The distribution of the macrostates probabilities and the entropies are obtained for four classes of the paramacrosystems.
It is shown by examples that accounting of the prior information can change the form of the distribution of the macrostates probabilities. In particular, the entropy functions are transformed from the single-modal functions into the multimodal functions.


{kind=link}
{kind=link}
{kind=link}
{kind=link}



