
Tea Category Identification Using a Novel Fractional Fourier Entropy and Jaya Algorithm

 ,
,  ,
,  ,
, 

Abstract
:1. Introduction
2. Materials
2.1. Tea Sample Preparation
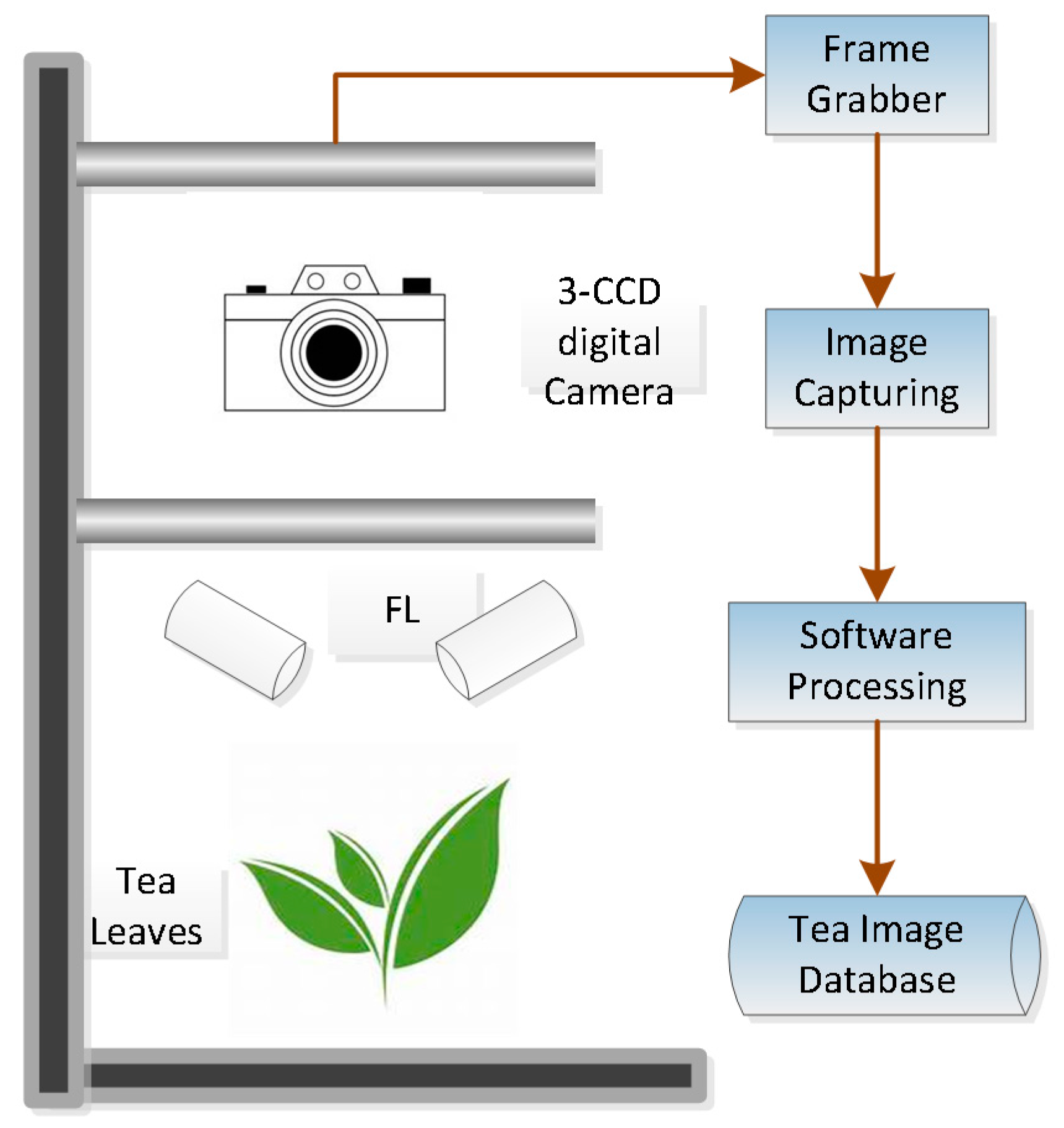
2.2. Image Acquiring
3. Feature Extraction
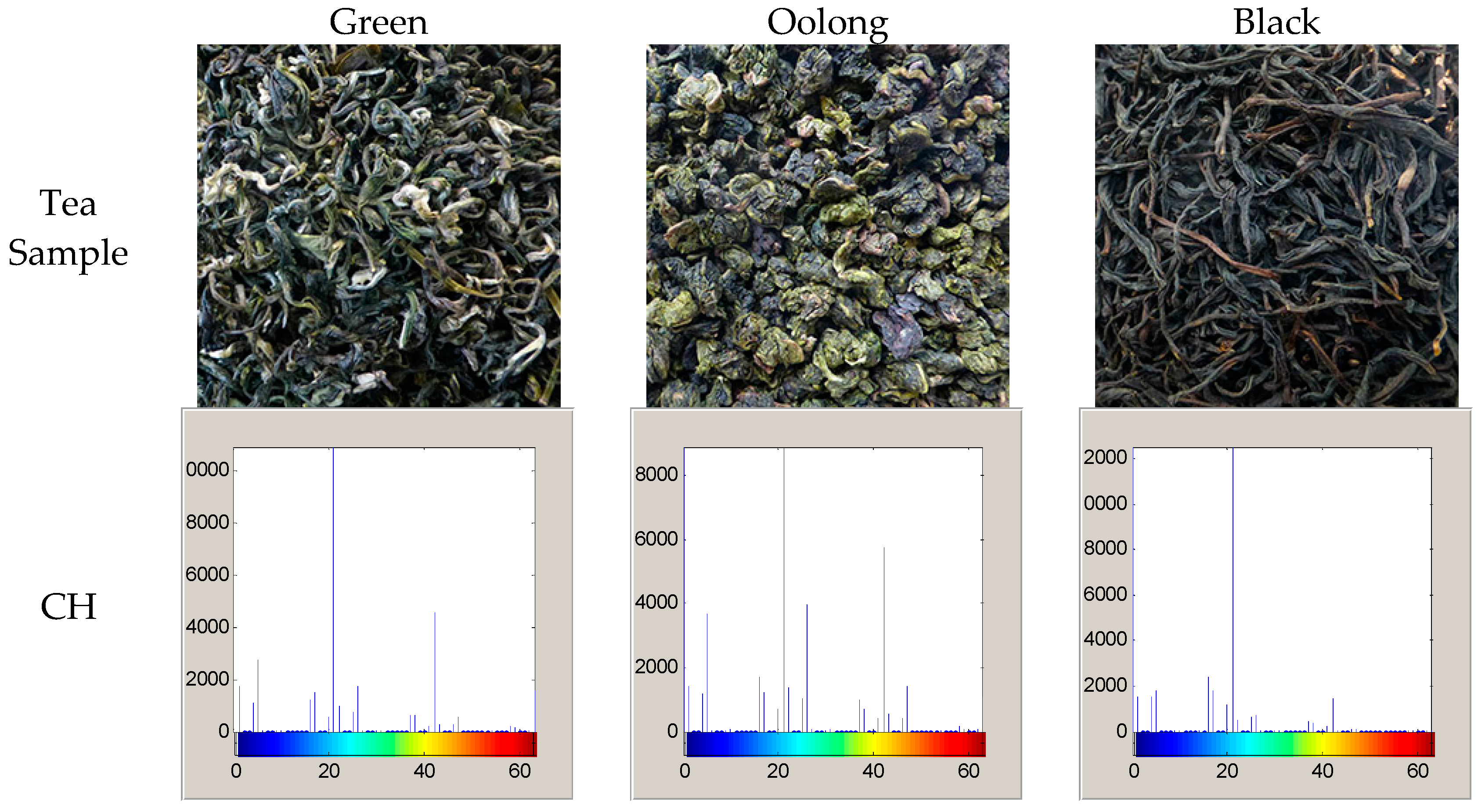
3.1. Color Histogram
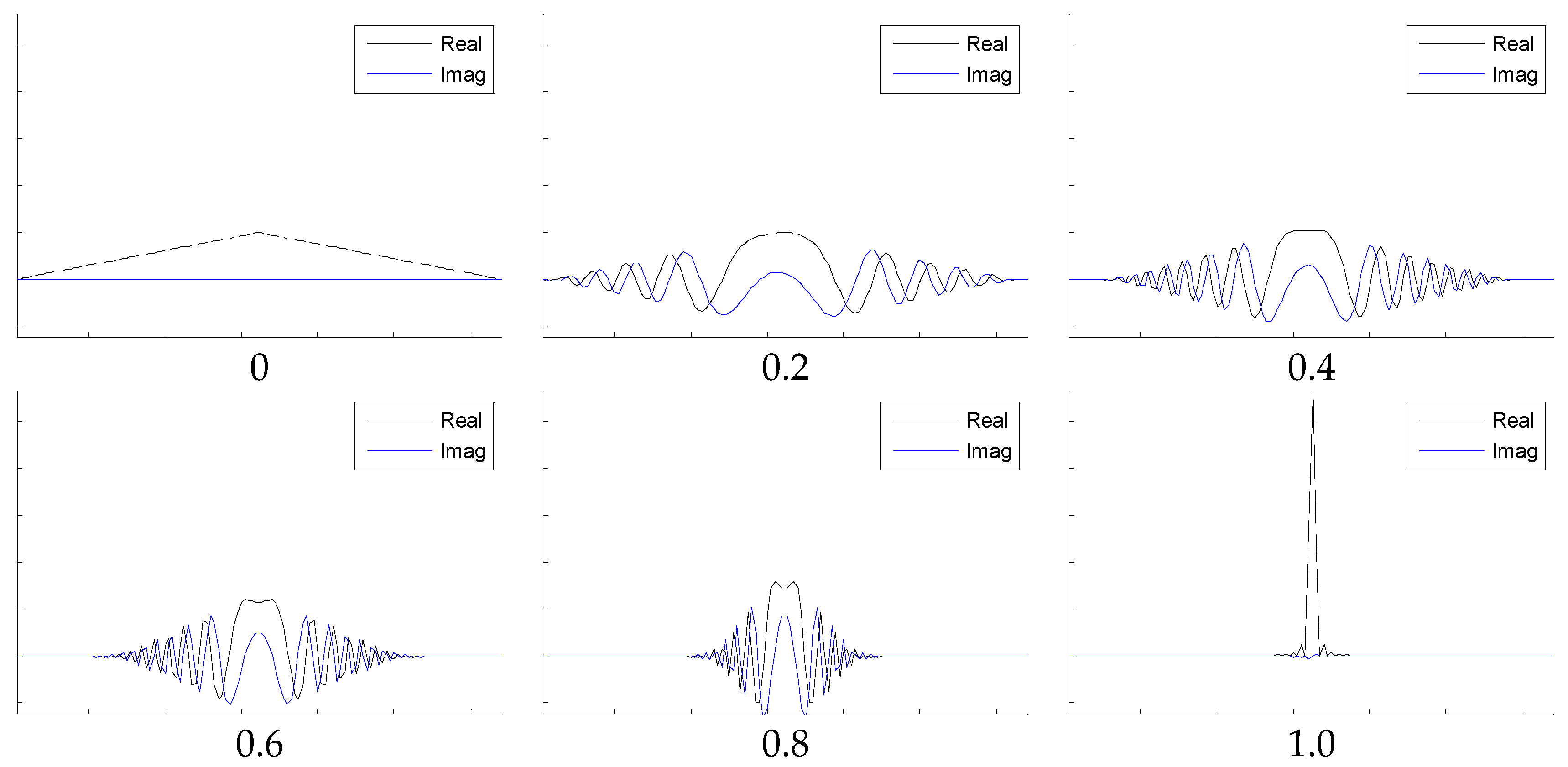
3.2. Fractional Fourier Transform
3.3. Fractional Fourier Entropy
4. Feature Reduction
4.1. Principal Component Analysis
4.2. Kernel Principal Component Analysis
4.3. Implementation
5. Classification
5.1. Feed-Forward Neural Network
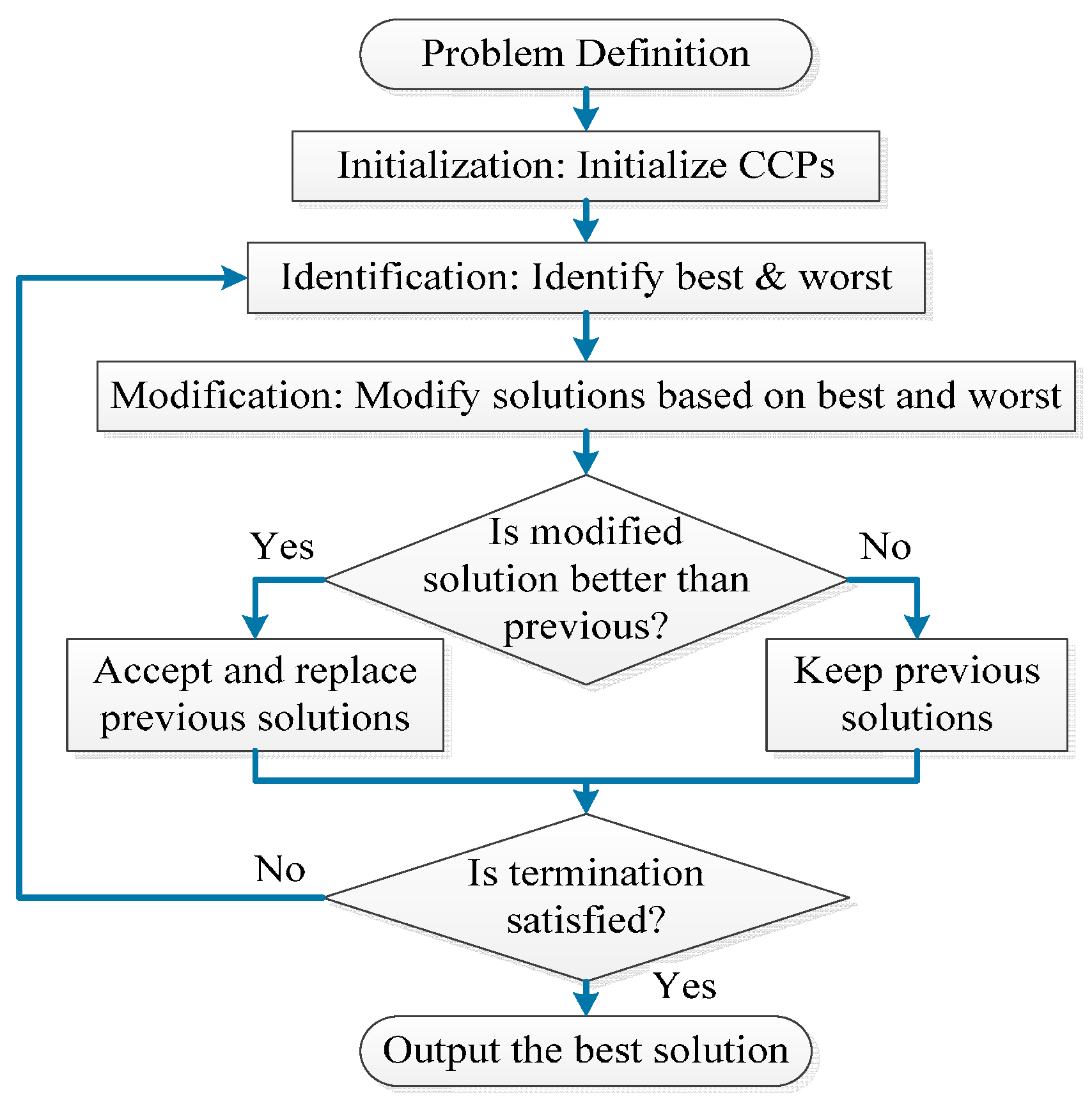
5.2. Optimization Methods
5.3. Statistical Setting
6. Experiments, Results and Discussions
6.1. Color Histogram
6.2. FRFT Results
6.3. FRFE Results
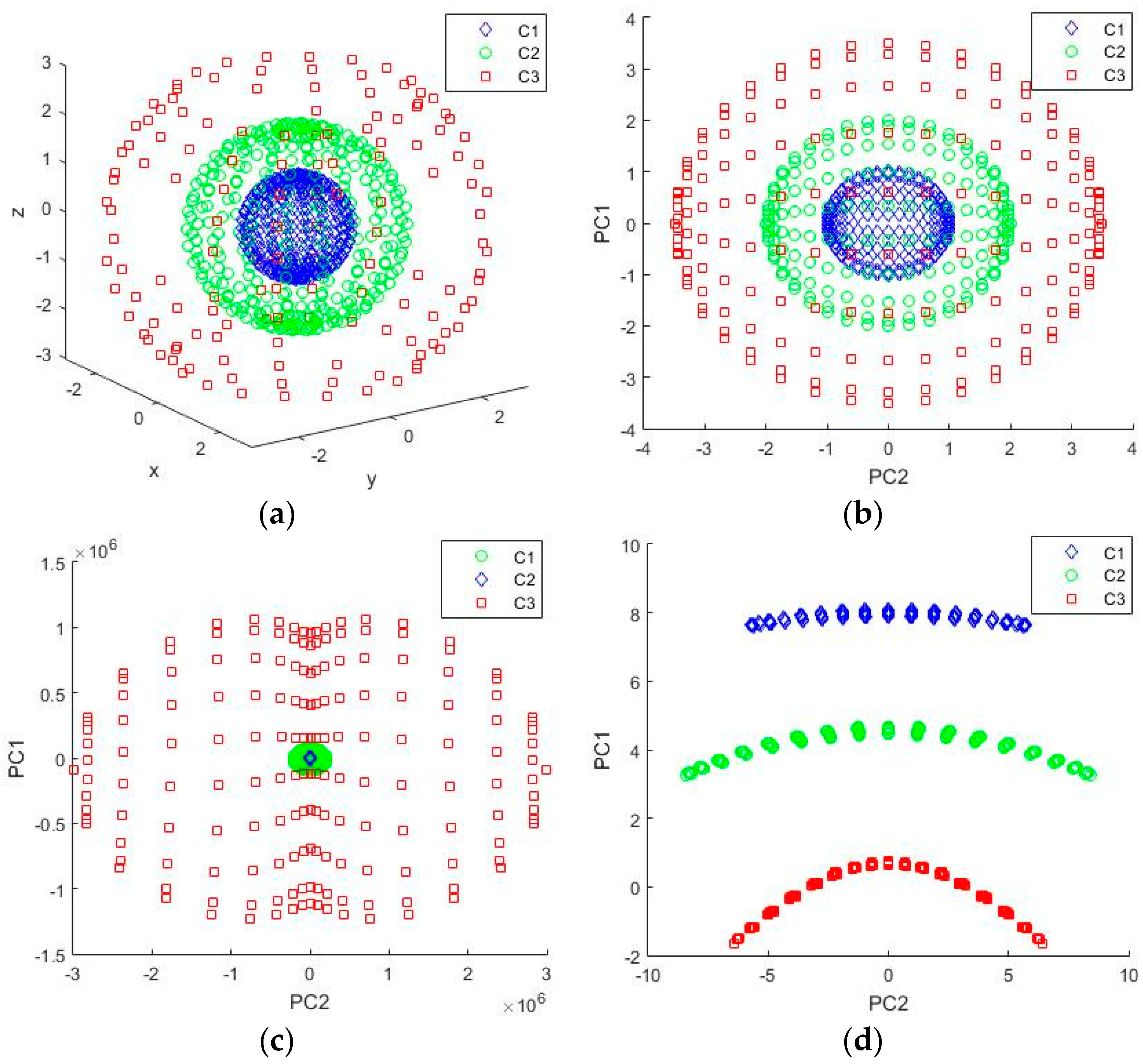
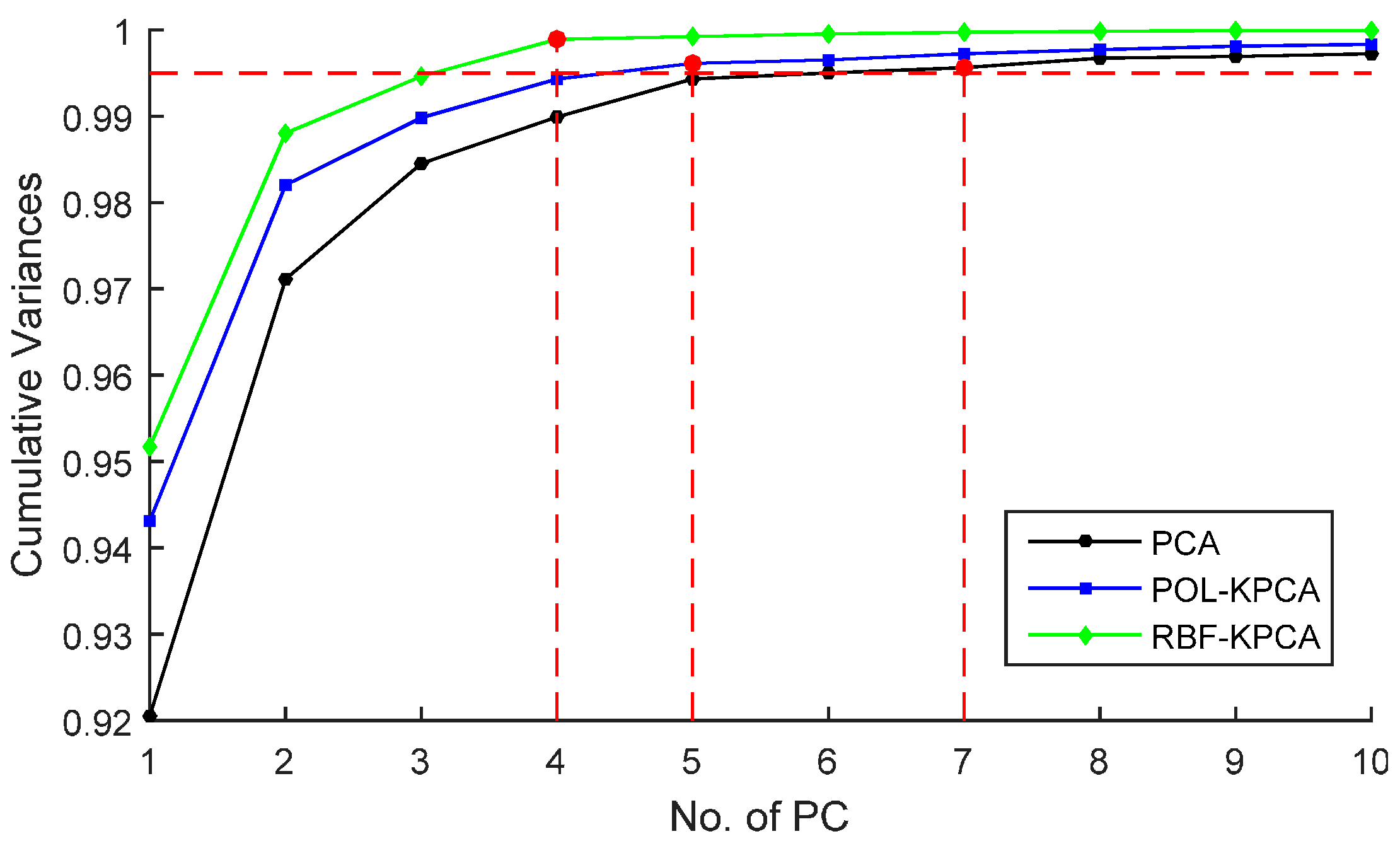
6.4. KPCA over Simulation Data
6.5. KPCA over Tea Features
6.6. Training Comparison
6.7. Feature Comparison
6.8. Comparison to State-of-the-Art Approaches
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| Abbreviation | Definition |
| (BP)(F)NN | (back-propagation) (feed-forward) neural network |
| (F)(B)L | (Front) (Back) Lighting |
| ASP | Algorithm-specific parameter |
| ASR | Average sensitivity rate |
| CCD | Charge-coupled device |
| CCP | Common controlling parameter |
| FNN | Feed-forward neural network |
| FRFD/E/T | FRactional Fourier domain/entropy/transform |
| FSCABC | Fitness-scaled Chaotic Artificial bee colony |
| FSVM | Fuzzy SVM |
| GNN | Genetic neural-network |
| LDA | Linear discriminant analysis |
| NIR | Near-infrared |
| OHL | One-hidden-layer |
| SCV | Stratified cross validation |
| SE | Shannon entropy |
| SVM | Support vector machine |
| TLBO | Teaching-learning-based optimization |
| WPE | Wavelet packet entropy |
| WTA | Winner-Takes-All |
References
- Yang, C.S.; Landau, J.M. Effects of tea consumption on nutrition and health. J. Nutr. 2000, 130, 2409–2412. [Google Scholar] [PubMed]
- Ch Yiannakopoulou, E. Green tea catechins: Proposed mechanisms of action in breast cancer focusing on the interplay between survival and apoptosis. Anti-Cancer Agents Med. Chem. 2014, 14, 290–295. [Google Scholar] [CrossRef]
- Sironi, E.; Colombo, L.; Lompo, A.; Messa, M.; Bonanomi, M.; Regonesi, M.E.; Salmona, M.; Airoldi, C. Natural compounds against neurodegenerative diseases: Molecular characterization of the interaction of catechins from green tea with Aβ1-42, PrP106-126, and ataxin-3 oligomers. Chemistry 2014, 20, 13793–13800. [Google Scholar] [CrossRef] [PubMed]
- Miura, K.; Hughes, M.C.B.; Arovah, N.I.; van der Pols, J.C.; Green, A.C. Black tea consumption and risk of skin cancer: An 11-year prospective study. Nutr. Cancer 2015, 67, 1049–1055. [Google Scholar] [CrossRef] [PubMed]
- Qi, H.; Li, S.X. Dose-response meta-analysis on coffee, tea and caffeine consumption with risk of Parkinson’s disease. Geriatr. Gerontol. Int. 2014, 14, 430–439. [Google Scholar] [CrossRef] [PubMed]
- Gopalakrishna, R.; Fan, T.; Deng, R.; Rayudu, D.; Chen, Z.W.; Tzeng, W.S.; Gundimeda, U. Extracellular matrix components influence prostate tumor cell sensitivity to cancer-preventive agents selenium and green tea polyphenols. Cancer Res. 2014, 74. [Google Scholar] [CrossRef]
- Lim, H.J.; Shim, S.B.; Jee, S.W.; Lee, S.H.; Lim, C.J.; Hong, J.T.; Sheen, Y.Y.; Hwang, D.Y. Green tea catechin leads to global improvement among Alzheimer’s disease-related phenotypes in NSE/hAPP-C105 Tg mice. J. Nutr. Biochem. 2013, 24, 1302–1313. [Google Scholar] [CrossRef] [PubMed]
- Bohn, S.K.; Croft, K.D.; Burrows, S.; Puddey, I.B.; Mulder, T.P. J.; Fuchs, D.; Woodmand, R.J.; Hodgson, J.M. Effects of black tea on body composition and metabolic outcomes related to cardiovascular disease risk: A randomized controlled trial. Food Funct. 2014, 5, 1613–1620. [Google Scholar] [CrossRef] [PubMed]
- Hajiaghaalipour, F.; Kanthimathi, M.S.; Sanusi, J.; Rajarajeswaran, J. White tea (Camellia sinensis) inhibits proliferation of the colon cancer cell line, HT-29, activates caspases and protects DNA of normal cells against oxidative damage. Food Chem. 2015, 169, 401–410. [Google Scholar] [CrossRef] [PubMed]
- Horanni, R.; Engelhardt, U.H. Determination of amino acids in white, green, black, oolong, pu-erh teas and tea products. J. Food Compos. Anal. 2013, 31, 94–100. [Google Scholar] [CrossRef]
- DeCost, B.L.; Holm, E.A. A computer vision approach for automated analysis and classification of microstructural image data. Comput. Mater. Sci. 2015, 110, 126–133. [Google Scholar] [CrossRef]
- Gomez, M.J.; Garcia, F.; Martin, D.; de la Escalera, A.; Armingol, J.M. Intelligent surveillance of indoor environments based on computer vision and 3D point cloud fusion. Expert Syst. Appl. 2015, 42, 8156–8171. [Google Scholar] [CrossRef]
- Wang, S.; Feng, M.M.; Li, Y.; Zhang, Y.; Han, L.; Wu, J.; Du, S.D. Detection of dendritic spines using wavelet-based conditional symmetric analysis and regularized morphological shared-weight neural networks. Comput. Math. Methods Med. 2015. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.W.; Chen, Q.S.; Huang, X.Y.; Fang, C.H. Qualitative identification of tea categories by near infrared spectroscopy and support vector machine. J. Pharm. Biomed. Anal. 2006, 41, 1198–1204. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.S.; Zhao, J.W.; Fang, C.H.; Wang, D.M. Feasibility study on identification of green, black and Oolong teas using near-infrared reflectance spectroscopy based on support vector machine (SVM). Spectrochim. Acta A Mol. Biomol. Spectrosc. 2007, 66, 568–574. [Google Scholar] [CrossRef] [PubMed]
- Herrador, M.A.; Gonzalez, A.G. Pattern recognition procedures for differentiation of green, black and Oolong teas according to their metal content from inductively coupled plasma atomic emission spectrometry. Talanta 2001, 53, 1249–1257. [Google Scholar] [CrossRef]
- Chen, Q.S.; Liu, A.P.; Zhao, J.W.; Ouyang, Q. Classification of tea category using a portable electronic nose based on an odor imaging sensor array. J. Pharm. Biomed. Anal. 2013, 84, 77–89. [Google Scholar] [CrossRef] [PubMed]
- Szymczycha-Madeja, A.; Welna, M.; Pohl, P. Determination of essential and non-essential elements in green and black teas by FAAS and ICP OES simplified—Multivariate classification of different tea products. Microchem. J. 2015, 121, 122–129. [Google Scholar] [CrossRef]
- Liu, N.A.; Liang, Y.Z.; Bin, J.; Zhang, Z.M.; Huang, J.H.; Shu, R.X.; Yang, K. Classification of green and black teas by PCA and SVM analysis of cyclic voltammetric signals from metallic oxide-modified electrode. Food Anal. Meth. 2014, 7, 472–480. [Google Scholar] [CrossRef]
- Dai, Y.W.; Zhi, R.C.; Zhao, L.; Gao, H.Y.; Shi, B.L.; Wang, H.Y. Longjing tea quality classification by fusion of features collected from E-nose. Chemom. Intell. Lab. Syst. 2015, 144, 63–70. [Google Scholar] [CrossRef]
- Chen, Q.; Zhao, J.; Cai, J. Identification of tea varieties using computer vision. Trans. ASABE 2008, 51, 623–628. [Google Scholar] [CrossRef]
- Jian, W.; Xianyin, Z.; ShiPing, D. Identification and grading of tea using computer vision. Appl. Eng. Agric. 2010, 26, 639–645. [Google Scholar] [CrossRef]
- Laddi, A.; Sharma, S.; Kumar, A.; Kapur, P. Classification of tea grains based upon image texture feature analysis under different illumination conditions. J. Food Eng. 2013, 115, 226–231. [Google Scholar] [CrossRef]
- Gill, G.S.; Kumar, A.; Agarwal, R. Monitoring and grading of tea by computer vision—A review. J. Food Eng. 2011, 106, 13–19. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Ji, G.; Phillips, P. Fruit classification using computer vision and feedforward neural network. J. Food Eng. 2014, 143, 167–177. [Google Scholar] [CrossRef]
- Tang, Z.; Su, Y.C.; Er, M.J.; Qi, F.; Zhang, L.; Zhou, J.Y. A local binary pattern based texture descriptors for classification of tea leaves. Neurocomputing 2015, 168, 1011–1023. [Google Scholar] [CrossRef]
- Akar, O.; Gungor, O. Integrating multiple texture methods and NDVI to the Random Forest classification algorithm to detect tea and hazelnut plantation areas in northeast Turkey. Int. J. Remote Sens. 2015, 36, 442–464. [Google Scholar] [CrossRef]
- Wang, S.; Yang, X.; Zhang, Y.; Phillips, P.; Yang, J.; Yuan, T.F. Identification of green, oolong and black teas in China via wavelet packet entropy and fuzzy support vector machine. Entropy 2015, 17, 6663–6682. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, Y.; Yang, X.J.; Sun, P.; Dong, Z.C.; Liu, A.J.; Yuan, T.F. Pathological brain detection by a novel image feature—Fractional Fourier entropy. Entropy 2015, 17, 8278–8296. [Google Scholar] [CrossRef]
- Rao, R.V. Jaya: A simple and new optimization algorithm for solving constrained and unconstrained optimization problems. Int. J. Ind. Eng. Comput. 2016, 7, 19–34. [Google Scholar]
- Tai, Y.H.; Chou, L.S.; Chiu, H.L. Gap-Type a-Si TFTs for Front Light Sensing Application. J. Disp. Technol. 2011, 7, 679–683. [Google Scholar] [CrossRef]
- Diniz, P.; Dantas, H.V.; Melo, K.D.T.; Barbosa, M.F.; Harding, D.P.; Nascimento, E.C.L.; Pistonesi, M.F.; Band, B.S.F.; Araujo, M.C.U. Using a simple digital camera and SPA-LDA modeling to screen teas. Anal. Methods 2012, 4, 2648–2652. [Google Scholar] [CrossRef]
- Yu, X.J.; Liu, K.S.; He, Y.; Wu, D. Color and texture classification of green tea using least squares support vector machine (LSSVM). Key Eng. Mater. 2011, 460–461, 774–779. [Google Scholar] [CrossRef]
- De Almeida, V.E.; da Costa, G.B.; Fernandes, D.D.D.; Diniz, P.; Brandao, D.; de Medeiros, A.C.D.; Veras, G. Using color histograms and SPA-LDA to classify bacteria. Anal. Bioanal. Chem. 2014, 406, 5989–5995. [Google Scholar] [CrossRef] [PubMed]
- Ajmera, P.K.; Holambe, R.S. Fractional Fourier transform based features for speaker recognition using support vector machine. Comput. Electr. Eng. 2013, 39, 550–557. [Google Scholar] [CrossRef]
- Machado, J.A.T. Matrix fractional systems. Commun. Nonlinear Sci. Numer. Simul. 2015, 25, 10–18. [Google Scholar] [CrossRef]
- Cagatay, N.D.; Datcu, M. FrFT-based scene classification of phase-gradient InSAR images and effective baseline dependence. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1131–1135. [Google Scholar] [CrossRef]
- Bailey, D.H.; Swarztrauber, P.N. The fractional Fourier transform and applications. SIAM Rev. 1991, 33, 389–404. [Google Scholar] [CrossRef]
- Chen, S.F.; Wang, S.H.; Yang, J.F.; Phillips, P. Magnetic resonance brain image classification based on weighted-type fractional Fourier transform and nonparallel support vector machine. Int. J. Imaging Syst. Technol. 2015, 24, 317–327. [Google Scholar]
- Azoug, S.E.; Bouguezel, S. A non-linear preprocessing for opto-digital image encryption using multiple-parameter discrete fractional Fourier transform. Opt. Commun. 2016, 359, 85–94. [Google Scholar] [CrossRef]
- Machado, J.A.T. A fractional perspective to financial indices. Optimization 2014, 63, 1167–1179. [Google Scholar] [CrossRef]
- Yang, X.J.; Dong, Z.C.; Liu, G.; Phillips, P. Pathological brain detection in MRI scanning by wavelet packet Tsallis entropy and fuzzy support vector machine. SpringerPlus 2015, 4. [Google Scholar] [CrossRef]
- Llave, Y.A.; Hagiwara, T.; Sakiyama, T. Artificial neural network model for prediction of cold spot temperature in retort sterilization of starch-based foods. J. Food Eng. 2012, 109, 553–560. [Google Scholar] [CrossRef]
- Shojaee, S.A.; Hezave, A.Z.; Lashkarbolooki, M.; Shafipour, Z.S. Prediction of the binary density of the ionic liquids plus water using back-propagated feed forward artificial neural network. Chem. Ind. Chem. Eng. Q. 2014, 20, 325–338. [Google Scholar] [CrossRef]
- Karmakar, S.; Shrivastava, G.; Kowar, M.K. Impact of learning rate and momentum factor in the performance of back-propagation neural network to identify internal dynamics of chaotic motion. Kuwait J. Sci. 2014, 41, 151–174. [Google Scholar]
- Chandwani, V.; Agrawal, V.; Nagar, R. Modeling slump of ready mix concrete using genetic algorithms assisted training of Artificial Neural Networks. Expert Syst. Appl. 2015, 42, 885–893. [Google Scholar] [CrossRef]
- Manoochehri, M.; Kolahan, F. Integration of artificial neural network and simulated annealing algorithm to optimize deep drawing process. Int. J. Adv. Manuf. Technol. 2014, 73, 241–249. [Google Scholar] [CrossRef]
- Awan, S.M.; Aslam, M.; Khan, Z.A.; Saeed, H. An efficient model based on artificial bee colony optimization algorithm with Neural Networks for electric load forecasting. Neural Comput. Appl. 2014, 25, 1967–1978. [Google Scholar] [CrossRef]
- Momeni, E.; Armaghani, D.J.; Hajihassani, M.; Amin, M.F.M. Prediction of uniaxial compressive strength of rock samples using hybrid particle swarm optimization-based artificial neural networks. Measurement 2015, 60, 50–63. [Google Scholar] [CrossRef]
- Wang, S.; Ji, G.L.; Yang, J.Q.; Wu, J.G.; Wei, L. Fruit classification by wavelet-entropy and feedforward neural network trained by fitness-scaled chaotic ABC and biogeography-based optimization. Entropy 2015, 17, 5711–5728. [Google Scholar] [CrossRef]
- Yu, L.; Wang, S.Y.; Kai, K.K. Forecasting foreign exchange rates with an improved back-propagation learning algorithm with adaptive smoothing momentum terms. Front. Comput. Sci. China 2009, 3, 167–176. [Google Scholar] [CrossRef]
- Rao, R.V.; Savsani, V.J.; Vakharia, D.P. Teaching-learning-based optimization: A novel method for constrained mechanical design optimization problems. Comput. Aided Des. 2011, 43, 303–315. [Google Scholar] [CrossRef]
- Rao, R.V.; Savsani, V.J.; Balic, J. Teaching-learning-based optimization algorithm for unconstrained and constrained real-parameter optimization problems. Eng. Optim. 2012, 44, 1447–1462. [Google Scholar] [CrossRef]
- Dokeroglu, T. Hybrid teaching-learning-based optimization algorithms for the Quadratic Assignment Problem. Comput. Ind. Eng. 2015, 85, 86–101. [Google Scholar] [CrossRef]
- Gonzalez-Alvarez, D.L.; Vega-Rodriguez, M.A.; Rubio-Largo, A. Finding patterns in protein sequences by using a hybrid multiobjective teaching learning based optimization algorithm. IEEE ACM Trans. Comput. Biol. Bioinform. 2015, 12, 656–666. [Google Scholar] [CrossRef] [PubMed]
- Dede, T.; Togan, V. A teaching learning based optimization for truss structures with frequency constraints. Struct. Eng. Mech. 2015, 53, 833–845. [Google Scholar] [CrossRef]
- Rao, R.V.; Patel, V. An improved teaching-learning-based optimization algorithm for solving unconstrained optimization problems. Sci. Iran. 2013, 20, 710–720. [Google Scholar] [CrossRef]
- Zhang, Y.D. Detection of Alzheimer’s disease by displacement field and machine learning. PeerJ 2015, 3, e1251. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Zhang, Y.; Liu, G.; Phillips, P.; Yuan, T.F. Detection of Alzheimer’s Disease by Three-Dimensional Displacement Field Estimation in Structural Magnetic Resonance Imaging. J. Alzheimer’s Dis. 2015, 50, 233–248. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Wang, S.; Sun, P.; Phillips, P. Pathological Brain Detection based on wavelet entropy and Hu moment invariants. Bio-Med. Mater. Eng. 2015, 26, S1283–S1290. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tea Category | Wilted | Bruised | Oxidized |
|---|---|---|---|
| Green | No | No | No |
| Oolong | Yes | Yes | Partially |
| Black | Yes | No | Yes |
| Category * | # | Origins |
|---|---|---|
| G | 100 | Guizhou; Henan; Anhui; Jiangxi; Jiangsu; Zhejiang |
| B | 100 | Yunnan; Fujian; Hunan; Hubei |
| O | 100 | Guangdong; Fujian |
| Angles | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 |
|---|---|---|---|---|---|
| 0.6 | 7.35 + 0.10 | 7.15 + 0.06 | 6.82 + 0.04 | 6.56 + 0.03 | 6.32 + 0.09 |
| 7.31 + 0.09 | 7.12 + 0.08 | 6.80 + 0.06 | 6.50 + 0.08 | 6.24 + 0.17 | |
| 6.94 + 0.11 | 6.81 + 0.10 | 6.62 + 0.09 | 6.39 + 0.04 | 5.85 + 0.11 | |
| 0.7 | 7.15 + 0.06 | 6.91 + 0.04 | 6.61 + 0.04 | 6.48 + 0.05 | 6.31 + 0.08 |
| 7.12 + 0.08 | 6.88 + 0.06 | 6.57 + 0.07 | 6.40 + 0.10 | 6.22 + 0.17 | |
| 6.80 + 0.10 | 6.67 + 0.09 | 6.47 + 0.07 | 6.23 + 0.04 | 5.85 + 0.10 | |
| 0.8 | 6.80 + 0.04 | 6.60 + 0.04 | 6.41 + 0.04 | 6.39 + 0.07 | 6.29 + 0.08 |
| 6.75 + 0.06 | 6.54 + 0.07 | 6.31 + 0.09 | 6.28 + 0.11 | 6.18 + 0.16 | |
| 6.60 + 0.08 | 6.45 + 0.07 | 6.22 + 0.04 | 6.05 + 0.05 | 5.82 + 0.09 | |
| 0.9 | 6.55 + 0.03 | 6.47 + 0.05 | 6.38 + 0.07 | 6.40 + 0.08 | 6.29 + 0.08 |
| 6.47 + 0.09 | 6.37 + 0.10 | 6.28 + 0.12 | 6.28 + 0.11 | 6.17 + 0.16 | |
| 6.38 + 0.05 | 6.23 + 0.04 | 6.06 + 0.05 | 6.00 + 0.07 | 5.82 + 0.09 | |
| 1.0 | 6.28 + 0.08 | 6.27 + 0.08 | 6.26 + 0.08 | 6.26 + 0.08 | 6.21 + 0.08 |
| 6.17 + 0.16 | 6.16 + 0.15 | 6.14 + 0.15 | 6.13 + 0.15 | 6.08 + 0.15 | |
| 5.78 + 0.08 | 5.78 + 0.09 | 5.76 + 0.08 | 5.77 + 0.08 | 5.73 + 0.09 |
| Algorithm | CCP |
| All | MIE = 1000, Population = 20, RT = 50 |
| Algorithm | ASP |
| BP | LR = 0.01 |
| MBP | LR = 0.01, MC = 0.9 |
| PSO | MV = 1, IW = 0.5, AC = 1 |
| SA | TDF = “Exp”, IT = 100, FT = 0 |
| GA | CP = 0.8, MP = 0.1 |
| Jaya | No ASPs |
| Proposed Method | Mean | SD |
|---|---|---|
| BP | 0.1242 | 0.0269 |
| MBP | 0.0939 | 0.0228 |
| SA | 0.1043 | 0.0317 |
| GA | 0.0266 | 0.0105 |
| PSO | 0.0197 | 0.0040 |
| Jaya | 0.0072 | 0.0015 |
| Feature | Green | Oolong | Black |
|---|---|---|---|
| 64 CH | 94.7% ± 0.4% | 96.3% ± 0.5% | 95.4% ± 0.5% |
| 25 FRFE | 95.3% ± 0.3% | 98.2% ± 0.4% | 96.6% ± 0.4% |
| (64 CH and 25 FRFE) reduced to 4 PCs | 97.3% ± 0.4% | 98.9% ± 0.3% | 97.6% ± 0.3% |
| Existing Approaches | |||||||
|---|---|---|---|---|---|---|---|
| Original Features | Reduced Feature # | Classification Method | Green | Oolong | Black | Overall | Rank |
| 3735 spectrum | 5 | SVM [15] | 90% | 100% | 95% | 95% | 7 |
| 8 metal | 8 | BPNN [16] | – | – | – | 95% | 7 |
| 12 color, 12 texture | 11 | LDA [21] | 96.7% | 92.3% | 98.5% | 95.8% | 6 |
| 2 color, 6 shape | 8 | GNN [22] | 95.8% | 94.4% | 97.9% | 96.0% | 5 |
| 64 CH, 7 texture, 8 shape | 14 | FSCABC-FNN [25] | 98.1% | 97.7% | 96.4% | 97.4% | 3 |
| 64 CH, 16 WPE | 5 | SVM + WTA [28] | 95.7% | 98.1% | 97.9% | 97.23% | 4 |
| 64 CH, 16 WPE | 5 | FSVM + WTA [28] | 96.2% | 98.8% | 98.3% | 97.77% | 2 |
| Proposed Approaches | |||||||
| 64 CH, 25 FRFE | 4 | Jaya-FNN | 97.3% ± 0.4% | 98.9% ± 0.3% | 97.6% ± 0.3% | 97.9% ± 0.3% | 1 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Yang, X.; Cattani, C.; Rao, R.V.; Wang, S.; Phillips, P. Tea Category Identification Using a Novel Fractional Fourier Entropy and Jaya Algorithm. Entropy 2016, 18, 77. https://doi.org/10.3390/e18030077
Zhang Y, Yang X, Cattani C, Rao RV, Wang S, Phillips P. Tea Category Identification Using a Novel Fractional Fourier Entropy and Jaya Algorithm. Entropy. 2016; 18(3):77. https://doi.org/10.3390/e18030077
Chicago/Turabian StyleZhang, Yudong, Xiaojun Yang, Carlo Cattani, Ravipudi Venkata Rao, Shuihua Wang, and Preetha Phillips. 2016. "Tea Category Identification Using a Novel Fractional Fourier Entropy and Jaya Algorithm" Entropy 18, no. 3: 77. https://doi.org/10.3390/e18030077
APA StyleZhang, Y., Yang, X., Cattani, C., Rao, R. V., Wang, S., & Phillips, P. (2016). Tea Category Identification Using a Novel Fractional Fourier Entropy and Jaya Algorithm. Entropy, 18(3), 77. https://doi.org/10.3390/e18030077