
Multilevel Integration Entropies: The Case of Reconstruction of Structural Quasi-Stability in Building Complex Datasets


{kind=link}
{kind=link}
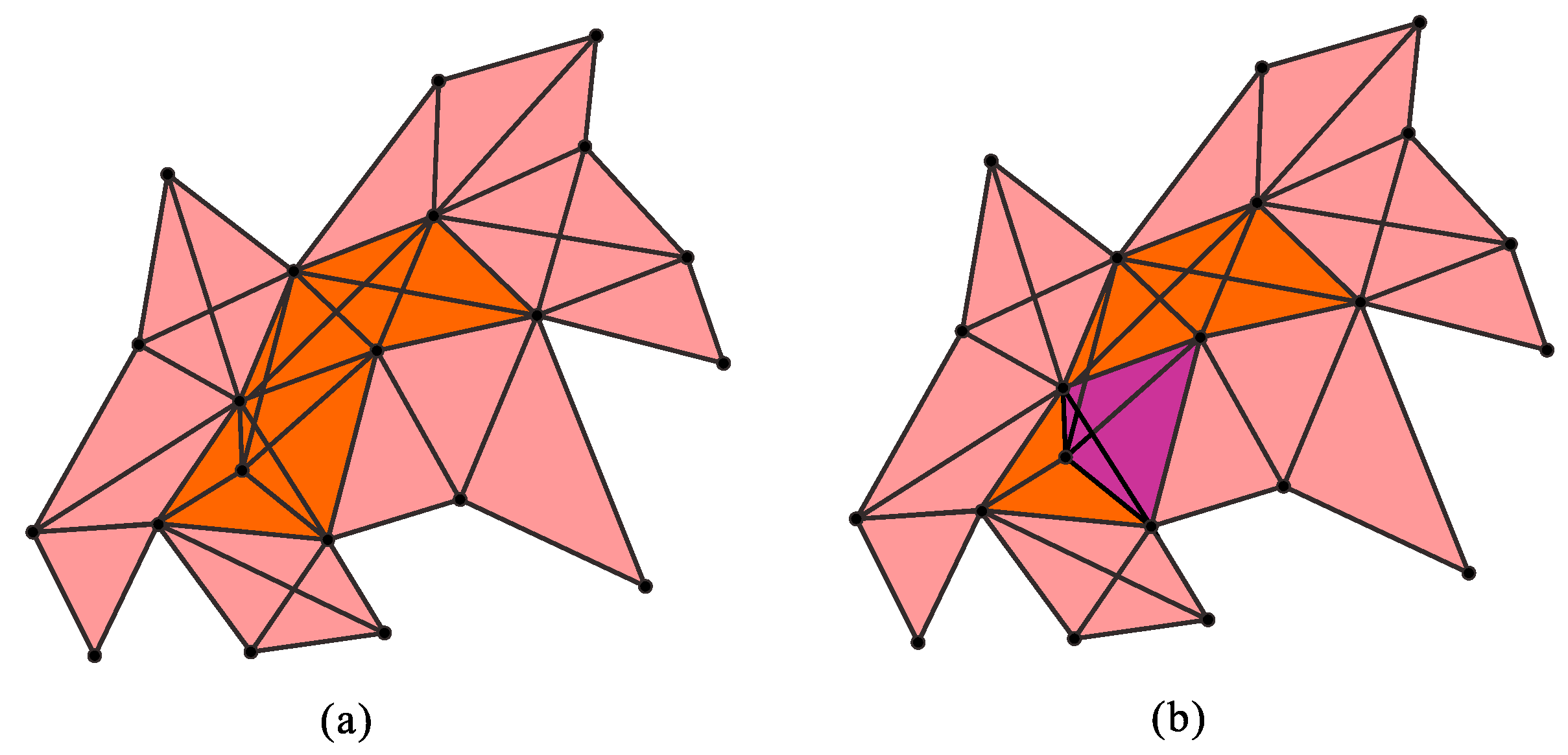{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Results
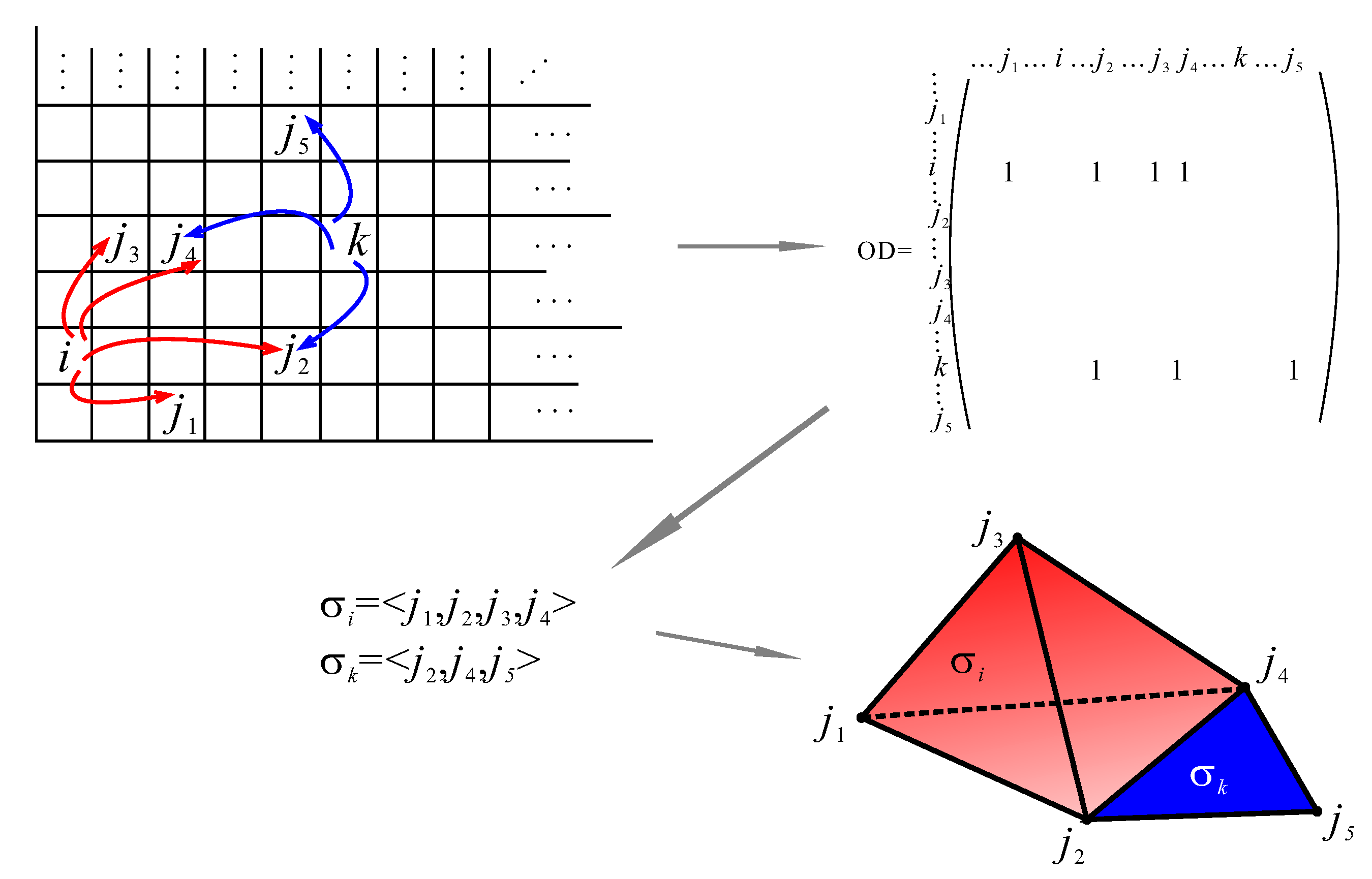
2.1. Simplicial Complex in the Context of Case Study
2.2. Multilevel Integration Entropies
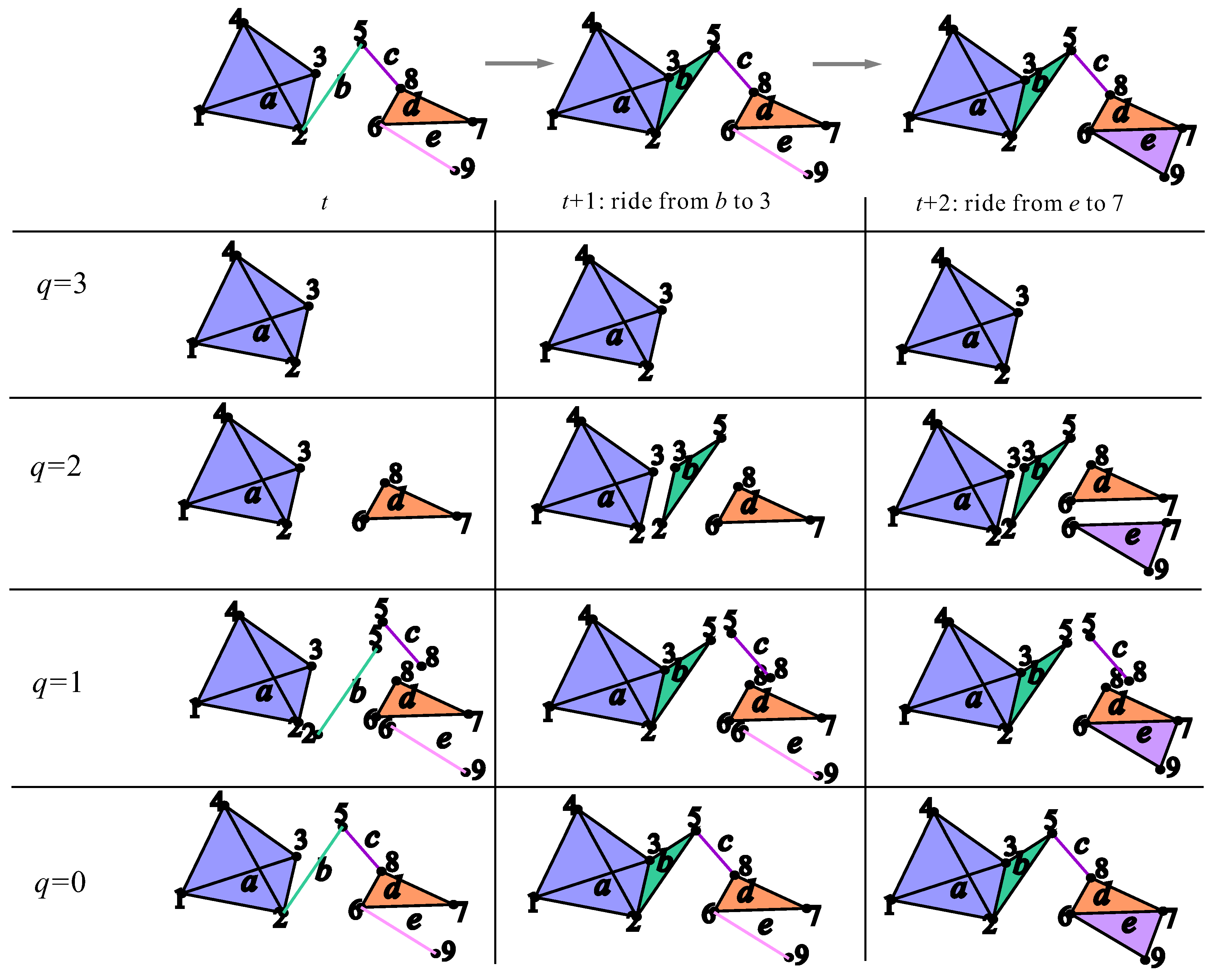
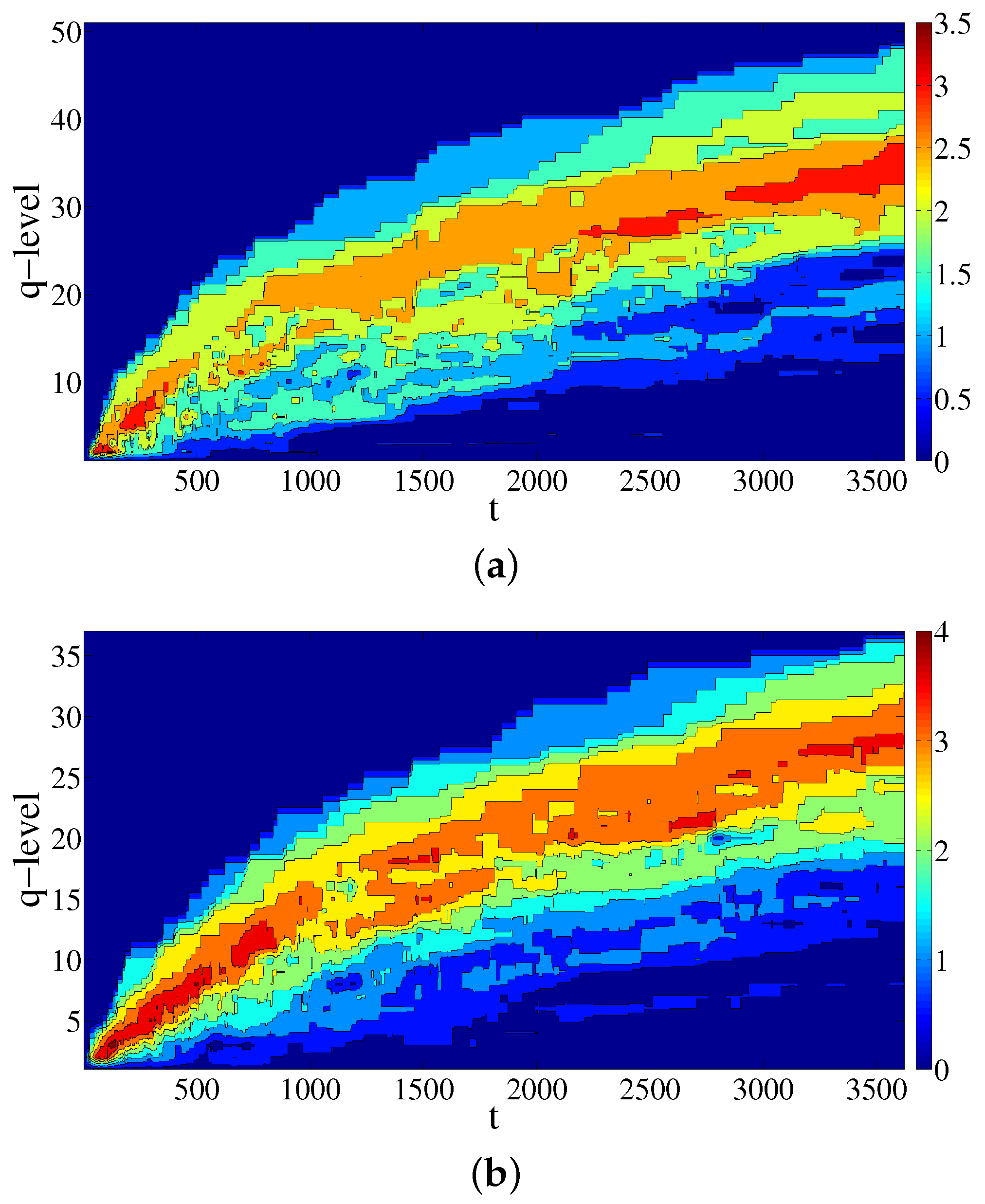
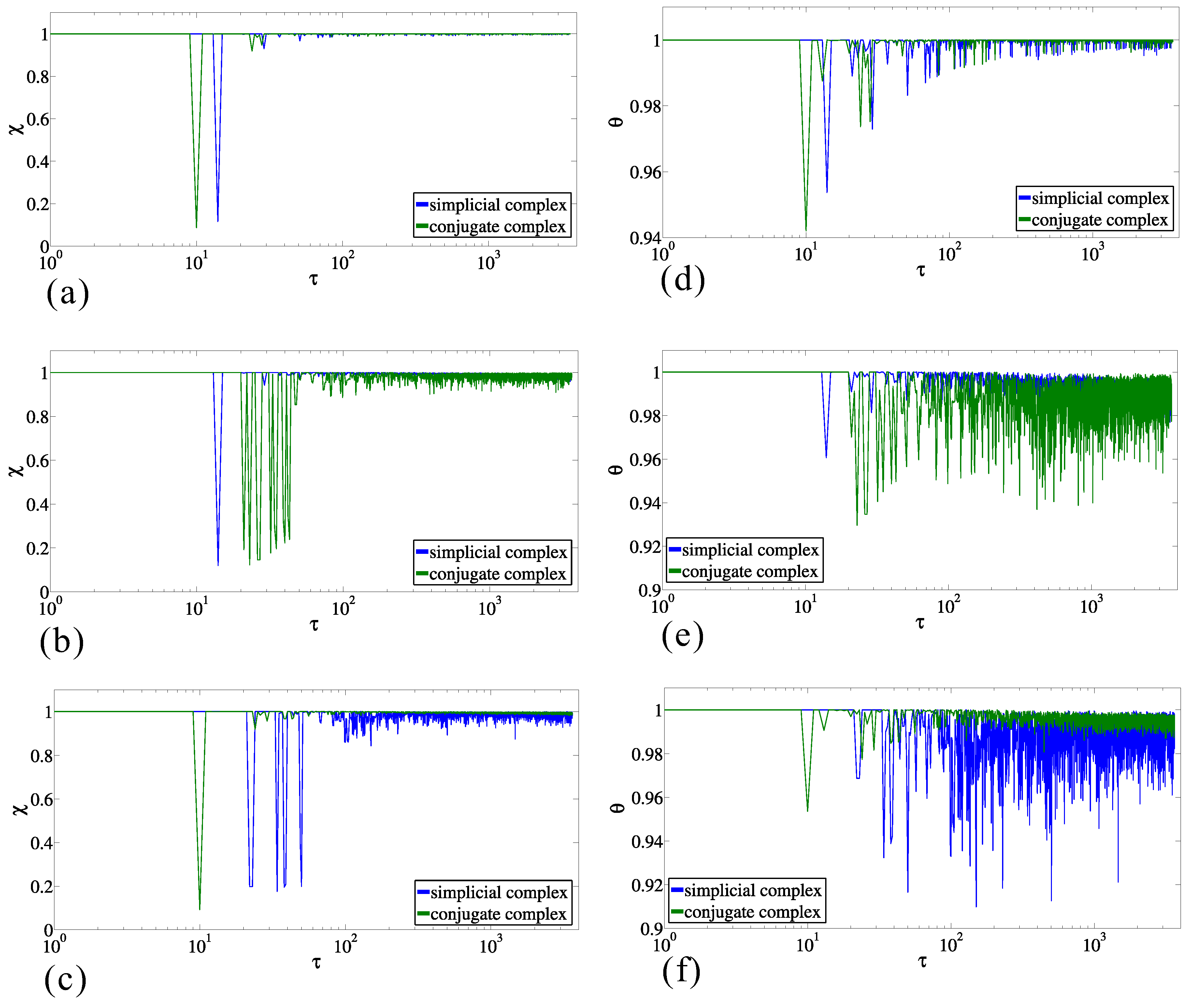
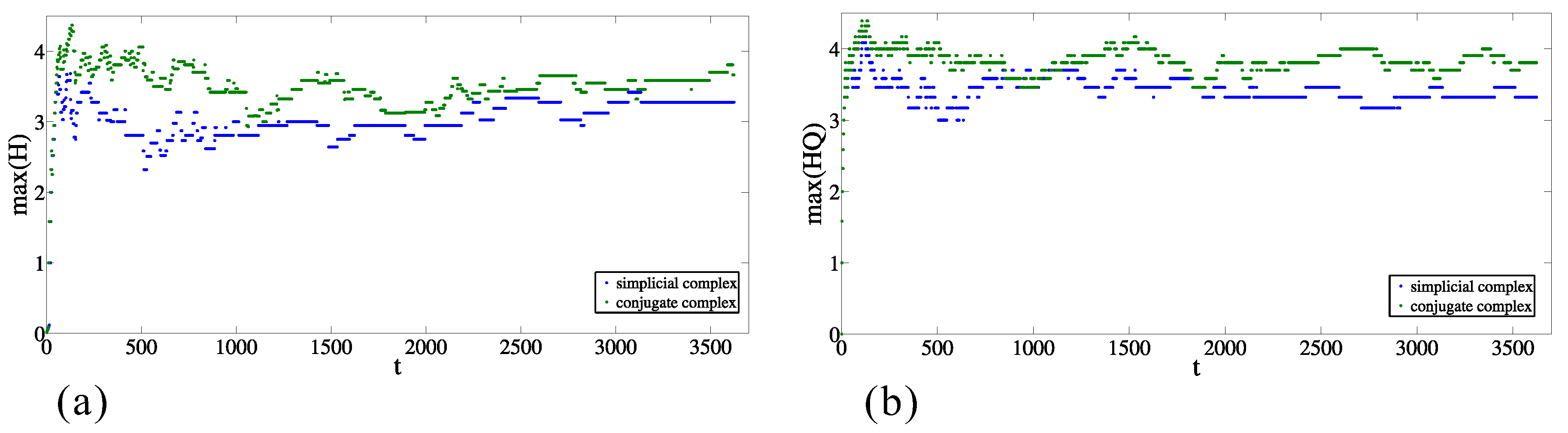
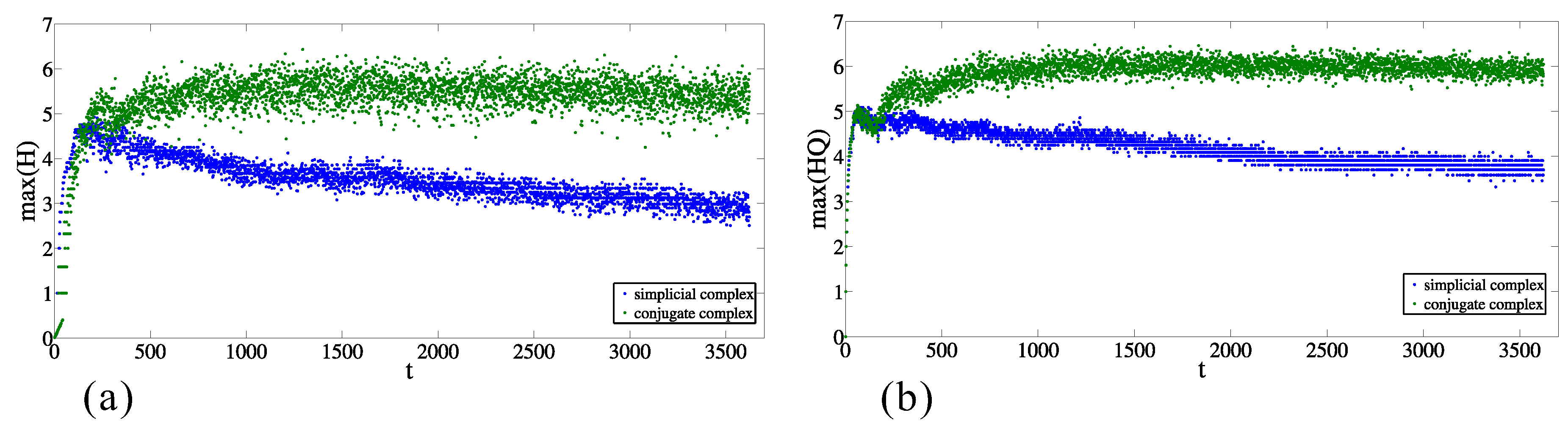
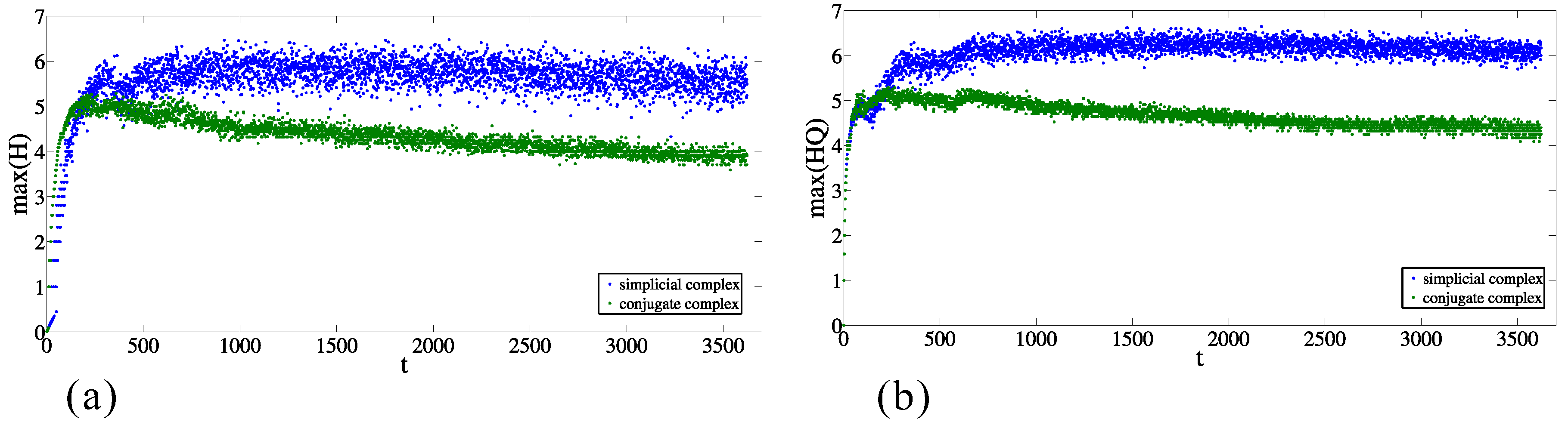
2.3. Results of the Calculations
3. Discussion
4. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A.
Appendix A.1. Simplicial Complex
Appendix A.2. Data Preparation
- (1)
- appearance of zero values at the places of latitude and longitude coordinates;
- (2)
- the recordings of some rides were repeating;
- (3)
- the latitude and longitude coordinates of some rides are (far) out of the city border.
References
- Munkres, J.R. Elements of Algebraic Topology; Addison-Wesley Publishing: Menlo Park, CA, USA, 1984. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Baudot, P.; Bennequin, D. The Homological Nature of Entropy. Entropy 2015, 17, 3253–3318. [Google Scholar] [CrossRef]
- Chintakunta, H.; Gentimis, T.; Gonzalez-Diaz, R.; Jimenez, M.-J.; Krim, H. An entropy-based persistence barcode. Pattern Recognit. 2015, 48, 391–401. [Google Scholar] [CrossRef]
- Merelli, E.; Rucco, M.; Sloot, P.; Tesei, L. Topological Characterization of Complex Systems: Using Persistent Entropy. Entropy 2015, 17, 6872–6892. [Google Scholar] [CrossRef]
- Tadić, B.; Andjelković, M.; Šuvakov, M. The influence of architecture of nanoparticle networks on collective charge transport revealed by the fractal time series and topology of phase space manifolds. J. Coupled Syst. Multiscale Dyn. 2016, 4, 30–42. [Google Scholar] [CrossRef]
- Maletić, S.; Rajković, M. Combinatorial Laplacian and entropy of simplicial complexes associated with complex networks. Eur. Phys. J. ST 2012, 212, 77–97. [Google Scholar] [CrossRef]
- Lum, P.Y.; Singh, G.; Lehman, A.; Ishkanov, T.; Vejdemo-Johansson, M.; Alagappan, M.; Carlsson, J.; Carlsson, G. Extracting insights from the shape of complex data using topology. Sci. Rep. 2013, 3, 1236. [Google Scholar] [CrossRef] [PubMed]
- Carlsson, G. Topology and data. Bull. Am. Math. Soc. 2009, 46, 255–308. [Google Scholar] [CrossRef]
- Epstein, C.; Carlsson, G.; Edelsbrunner, H. Topological data analysis. Inverse Probl. 2011, 27, 120201. [Google Scholar]
- Edelsbrunner, H.; Harer, J. Computational Topology: An Introduction; American Mathematical Society: Providence, RI, USA, 2010. [Google Scholar]
- Edelsbrunner, H.; Harer, J. Persistent homology—A survey. Contemp. Math. 2008, 453, 257–282. [Google Scholar]
- Zomorodian, A.; Carlsson, G. Computing persistent homology. Discret. Comput. Geom. 2005, 33, 249–274. [Google Scholar] [CrossRef]
- Nicolau, M.; Levine, A.J.; Carlsson, G. Topology based data analysis identifies a subgroup of breast cancers with a unique mutational profile and excellent survival. Proc. Natl Acad. Sci. USA 2001, 108, 7265–7270. [Google Scholar] [CrossRef] [PubMed]
- Nielson, J.L.; Paquette, J.; Liu, A.W.; Guandique, C.F.; Tovar, C.A.; Inoue, T.; Irvine, K.-A.; Gensel, J.C.; Kloke, J.; Petrossian, T.C.; et al. Topological data analysis for discovery in preclinical spinal cord injury and traumatic brain injury. Nat. Commun. 2015, 6, 8581. [Google Scholar] [CrossRef] [PubMed]
- Petri, G.; Expert, P.; Turkheimer, F.; Carhart-Harris, R.; Nutt, D.; Hellyer, P.J.; Vaccarino, F. Homological scaffolds of brain functional networks. J. R. Soc. Interface 2014, 11, 20140873. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.; Kang, H.; Chung, M.K.; Kim, B.N.; Lee, D.S. Persistent brain network homology from the perspective of dendrogram. IEEE Trans. Med. Imaging 2012, 31, 2267–2277. [Google Scholar] [PubMed]
- Singh, G.; Memoli, F.; Ishkhanov, T.; Sapiro, G.; Carlsson, G.; Ringach, D.L. Topological analysis of population activity in visual cortex. J. Vis. 2008, 8, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Dabaghian, Y.; Mémoli, F.; Frank, L.; Carlsson, G. A topological paradigm for hippocampal spatial map formation using persistent homology. PLoS Comput. Biol. 2012, 8, e1002581. [Google Scholar] [CrossRef] [PubMed]
- Arai, M.; Brandt, V.; Dabaghian, Y. The Effects of Theta Precession on Spatial Learning and Simplicial Complex Dynamics in a Topological Model of the Hippocampal Spatial Map. PLoS Comput. Biol. 2014, 10, e1003651. [Google Scholar] [CrossRef] [PubMed]
- Bendich, P.; Marron, J.S.; Miller, E.; Pieloch, A.; Skwerer, S. Persistent homology analysis of brain artery trees. Ann. Appl. Stat. 2016, 10, 198–218. [Google Scholar] [CrossRef] [PubMed]
- Yao, Y.; Sun, J.; Huang, X.; Bowman, G.R.; Singh, G.; Lesnick, M.; Guibas, L.J.; Pande, V.S.; Carlsson, G. Topological methods for exploring low-density states in biomolecular folding pathways. J. Chem. Phys. 2009, 130, 144115. [Google Scholar] [CrossRef] [PubMed]
- Krishnamoorthy, B.; Provan, S.; Tropsha, A. A Topological Characterization of Protein Structure. Data Min. Biomed. Part IV 2007, 7, 431–455. [Google Scholar]
- Xia, K.; Wei, G.-W. Persistent homology analysis of protein structure, flexibility, and folding. Int. J. Numer. Methods Biomed. Eng. 2014, 30, 814–844. [Google Scholar] [CrossRef] [PubMed]
- Chan, J.M.; Carlsson, G.; Rabadan, R. Topology of viral evolution. Proc. Natl. Acad. Sci. USA 2013, 110, 18566. [Google Scholar] [CrossRef] [PubMed]
- Ibekwe, A.M.; Ma, J.; Crowley, D.E.; Yang, C.-H.; Johnson, A.M.; Petrossian, T.C.; Lum, P.Y. Topological data analysis of Escherichia coli O157: H7 and non-O157 survival in soils. Front. Cell. Infect. Microbiol. 2014, 4, 122. [Google Scholar] [CrossRef] [PubMed]
- De Silva, V.; Ghrist, R. Coordinate-free Coverage in Sensor Networks with Controlled Boundaries via Homology. Int. J. Robot. Res. 2006, 25, 1205–1222. [Google Scholar] [CrossRef]
- De Silva, V.; Ghrist, R. Coverage in sensor networks via persistent homology. Algebraic Geom. Topol. 2007, 7, 339–358. [Google Scholar] [CrossRef]
- Perea, J.A.; Harer, J. Sliding windows and persistence: An application of topological methods to signal analysis. Found. Comput. Math. 2015, 15, 799–838. [Google Scholar] [CrossRef]
- Carlsson, G.; Ishkhanov, T.; de Silva, V.; Zomorodian, A. On the local behavior of spaces of natural images. Int. J. Comput. Vis. 2008, 76, 1–12. [Google Scholar] [CrossRef]
- Sethares, W.A.; Budney, R. Topology of musical data. J. Math. Music 2014, 8, 73–92. [Google Scholar] [CrossRef]
- Wagner, H.; Dłotko, P.; Mrozek, M. Computational Topology in Text Mining. In Proceedings of the 4th International Workshop Computational Topology in Image Context, CTIC, Bertinoro, Italy, 28–30 May 2012; pp. 68–78. [Google Scholar]
- Maletić, S.; Zhao, Y.; Rajković, M. Persistent topological features of dynamical systems. Chaos 2016, 26, 053105. [Google Scholar] [CrossRef] [PubMed]
- Garland, J.; Bradley, E.; Meiss, J.D. Exploring the Topology of Dynamical Reconstructions. Physica D 2016, 334, 49–59. [Google Scholar] [CrossRef]
- Taylor, D.; Klimm, F.; Harrington, H.A.; Kramar, M.; Mischaikow, K.; Porter, M.A.; Mucha, P.J. Topological data analysis of contagion maps for examining spreading processes on networks. Nat. Commun. 2015, 6, 7723. [Google Scholar] [CrossRef] [PubMed]
- Carstens, C.J.; Horadam, K.J. Persistent Homology of Collaboration Networks. Math. Probl. Eng. 2013, 2013, 815035. [Google Scholar] [CrossRef]
- Horak, D.; Maletić, S.; Rajković, M. Persistent Homology of Complex Networks. J. Stat. Mech. 2009, 3, P03034. [Google Scholar] [CrossRef]
- Atkin, R.H. From cohomology in physics to q-connectivity in social sciences. Int. J. Man Mach. Stud. 1972, 4, 139–167. [Google Scholar] [CrossRef]
- Atkin, R.H. Combinatorial Connectivities in Social Systems; Birkhäuser Verlag: Stuttgart, Germany, 1977. [Google Scholar]
- Atkin, R.H. Mathematical Structure in Human Affairs; Heinemann: London, UK, 1974. [Google Scholar]
- Gould, P.; Johnson, J.; Chapman, G. The Structure of Television; Pion Limited: London, UK, 1984. [Google Scholar]
- Jacobson, T.L.; Yan, W. Q-Analysis Techniques for Studying Communication Content. Qual. Quant. 1998, 32, 93–108. [Google Scholar] [CrossRef]
- Seidman, S.B. Rethinking backcloth and traffic: Prespectives from social network analysis and Q-analysis. Environ. Plan. B 1983, 10, 439–456. [Google Scholar] [CrossRef]
- Freeman, L.C. Q-analysis and the structure of friendship networks. Int. J. Man Mach. Stud. 1980, 12, 367–378. [Google Scholar] [CrossRef]
- Doreian, P. Polyhedral Dynamics and Conflict Mobilization in Social Networks. Soc. Netw. 1981, 3, 107–116. [Google Scholar] [CrossRef]
- Doreian, P. Leveling coalitions as network phenomena. Soc. Netw. 1982, 4, 27–45. [Google Scholar] [CrossRef]
- Atkin, R.H.; Johnson, J.; Mancini, V. An analysis of urban structure using concepts of algebraic topology. Urban Stud. 1971, 8, 221–242. [Google Scholar] [CrossRef]
- Johnson, J. The q-analysis of road intersections. Int. J. Man Mach. Stud. 1976, 8, 531–548. [Google Scholar] [CrossRef]
- Griffiths, J.C. Geological Similarity by Q-Analysis. Math. Geol. 1983, 15, 85–108. [Google Scholar] [CrossRef]
- Duckstein, L. Evaluation of the Performance of a Distribution System by Q-Analysis. Appl. Math. Comput. 1983, 13, 173–185. [Google Scholar] [CrossRef]
- Duckstein, L.; Nobe, S.A. Q-analysis for modeling and decision making. Eur. J. Oper. Res. 1997, 103, 411–425. [Google Scholar] [CrossRef]
- Ishida, Y.; Adachi, N.; Tokumaru, H. Topological approach to failure diagnosis of large-scale systems. IEEE Trans. Syst. Man Cybern. 1985, 5, 327–333. [Google Scholar] [CrossRef]
- Casti, J. Polyhedral Dynamics and the Controllability of Dynamical Systems. J. Math. Anal. Appl. 1979, 68, 334–346. [Google Scholar] [CrossRef]
- Atkin, R.H. Multi-dimensional Structure in the Game of Chess. Int. J. Man Mach. Stud. 1972, 4, 341–362. [Google Scholar] [CrossRef]
- Maletić, S.; Rajković, M.; Vasiljević, D. Simplicial Complexes of Networks and Their Statistical Properties. Lect. Notes Comput. Sci. 2008, 5102, 568–575. [Google Scholar]
- Tolman, E.C. Cognitive maps in rats and men. Psychol. Rev. 1948, 55, 189–208. [Google Scholar] [CrossRef] [PubMed]
- Kitchin, R.M. Cognitive maps: What are they and why study them? J. Environ. Psychol. 1994, 14, 1–19. [Google Scholar] [CrossRef]
- Kaplan, S. Cognitive maps in perception and thought. In Image and Environment; Downs, R.M., Stea, D., Eds.; Aldine: Chicago, IL, USA, 1973; pp. 63–78. [Google Scholar]
- Tversky, B. Distortions in cognitive maps. Geoforum 1992, 23, 131–138. [Google Scholar] [CrossRef]
- Wakabayashia, Y.; Itohb, S.; Nagami, Y. The Use of Geospatial Information and Spatial Cognition of Taxi Drivers in Tokyo. Procedia Soc. Behav. Sci. 2011, 21, 353–361. [Google Scholar] [CrossRef]
- Giraudo, M.-D.; Peruch, P. Spatio-temporal aspects of the mental representation of urban space. J. Environ. Psychol. 1988, 8, 9–17. [Google Scholar] [CrossRef]
- Peng, C.; Jin, X.; Wong, K.-C.; Shi, M.; Liò, P. Collective Human Mobility Pattern from Taxi Trips in Urban Area. PLoS ONE 2012, 7, e34487. [Google Scholar]
- Brockmann, D.; Hufnagel, L.; Geisel, T. The scaling laws of human travel. Nature 2006, 439, 462–465. [Google Scholar] [CrossRef] [PubMed]
- González, M.C.; Hidalgo, C.A.; Barabási, A.-L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.-L. Limits of Predictability in Human Mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef] [PubMed]
- Hull, C.L. The discrimination of stimulus configurations and the hypothesis of afferent neural interaction. Psychol. Rev. 1945, 52, 133–142. [Google Scholar] [CrossRef]
- Asch, S.E. Forming Impressions of Personality. J. Abnorm. Soc. Psychol. 1946, 41, 258–290. [Google Scholar] [CrossRef]
- Johnson, J.H. Some structures and notation of Q-analysis. Envniron. Plan. B 1981, 8, 73–86. [Google Scholar] [CrossRef]
- Dowker, C.H. Homology groups of relations. Ann. Math. 1952, 56, 84–95. [Google Scholar] [CrossRef]
- Woollett, K.; Maquire, E.A. The effect of navigational expertise on wayfinding in new environment. J. Environ. Psychol. 2010, 30, 565–573. [Google Scholar] [CrossRef] [PubMed]
- Tversky, B. Cognitive maps, cognitive collages, and spatial mental models. In Spatial Information Theory: A Theoretical Basis for GIS; Frank, A.U., Campari, I., Eds.; Springer-Verlag: New York, NY, USA, 1993; pp. 14–24. [Google Scholar]









© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maletić, S.; Zhao, Y. Multilevel Integration Entropies: The Case of Reconstruction of Structural Quasi-Stability in Building Complex Datasets. Entropy 2017, 19, 172. https://doi.org/10.3390/e19040172
Maletić S, Zhao Y. Multilevel Integration Entropies: The Case of Reconstruction of Structural Quasi-Stability in Building Complex Datasets. Entropy. 2017; 19(4):172. https://doi.org/10.3390/e19040172
Chicago/Turabian StyleMaletić, Slobodan, and Yi Zhao. 2017. "Multilevel Integration Entropies: The Case of Reconstruction of Structural Quasi-Stability in Building Complex Datasets" Entropy 19, no. 4: 172. https://doi.org/10.3390/e19040172
APA StyleMaletić, S., & Zhao, Y. (2017). Multilevel Integration Entropies: The Case of Reconstruction of Structural Quasi-Stability in Building Complex Datasets. Entropy, 19(4), 172. https://doi.org/10.3390/e19040172