
Entropy in the Tangled Nature Model of Evolution




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
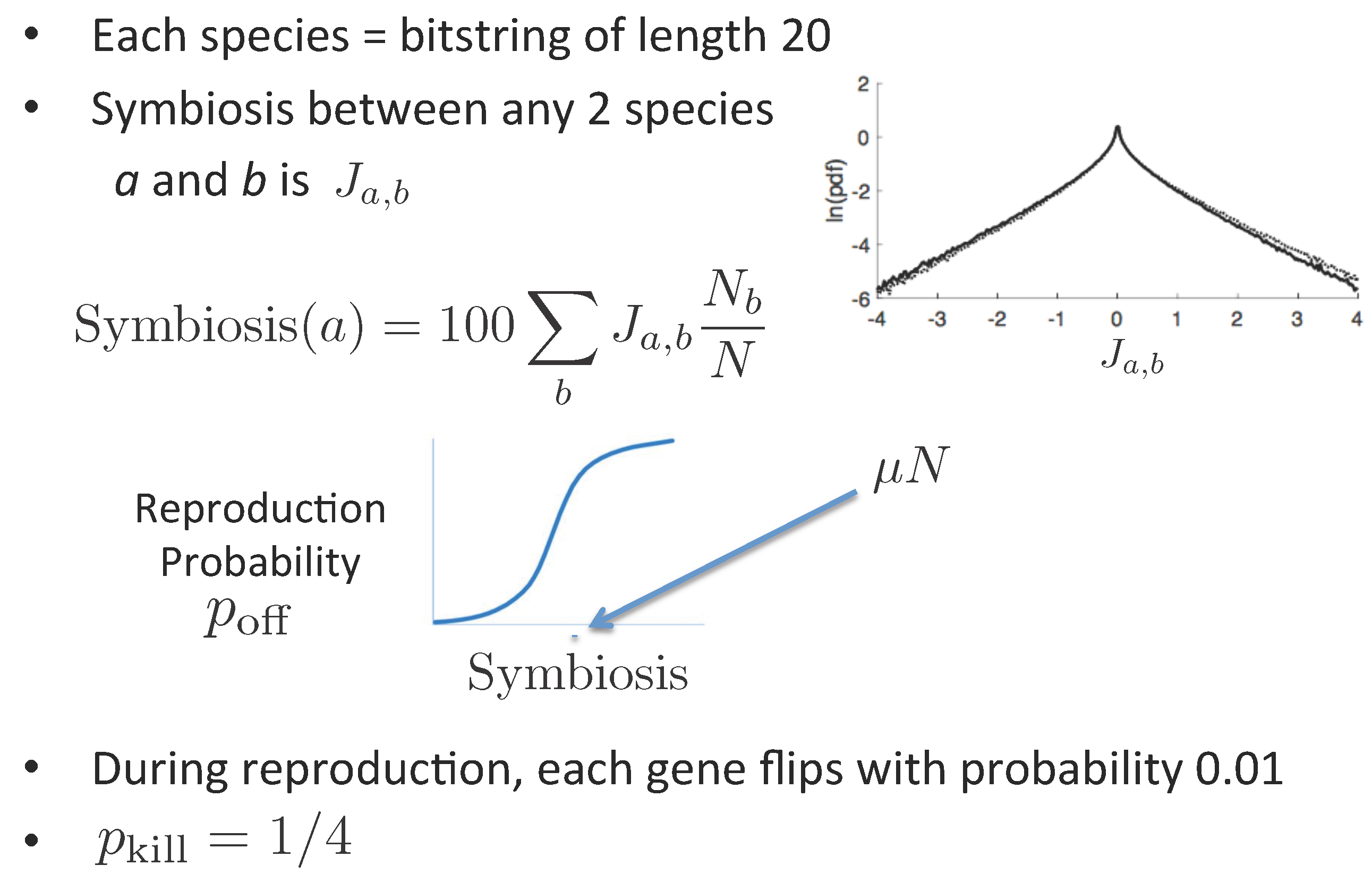
2. The TNM
- The TNM’s elementary variables are binary strings of length K, i.e., points of the K-dimensional hypercube. Each point represents a genome and is populated by a varying number of individuals or agents. This number is the abundance of the corresponding species.
- The probability that a queried agent is removed is the same for all agents.
- Simulation time is given in generations, each comprising the number of updates needed to remove all extant individuals. Specifically, when the initial population is N, the first generation comprises updates. The length of subsequent generations is computed similarly, but with N denoting in each case the population present at the end of the preceding generation.
- The reproduction probability of an agent is the same within each species, and depends for species a on the average symbiosis species a enjoys with other extant species.
3. Structure and Entropy in the TNM
3.1. The Two Entropies
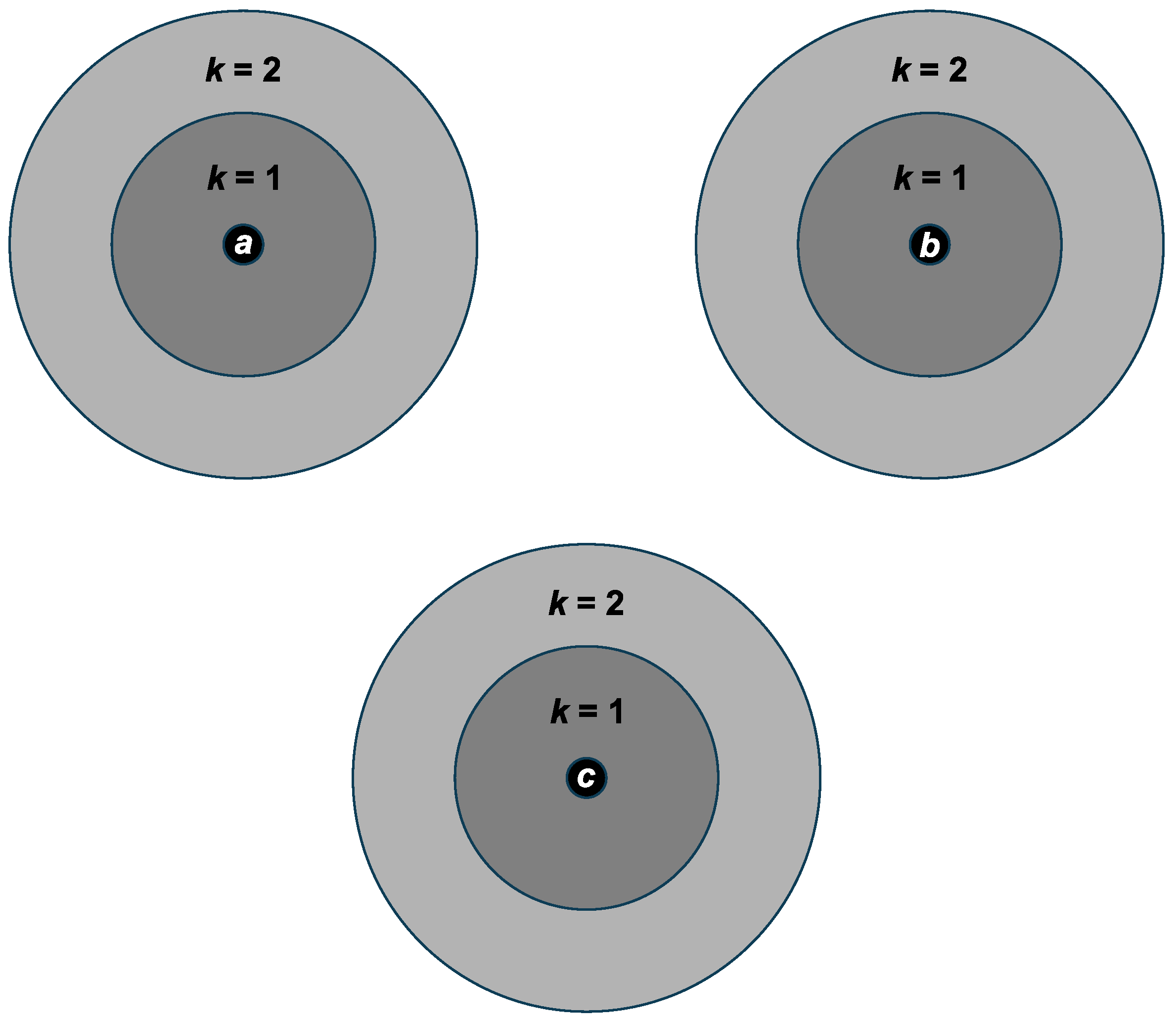
3.2. Simplified QESS Structure
- n core species
- each core species is surrounded by a cloud of its mutants
- only core species reproduce and mutate; cloud species never reproduce
- each cloud-core distribution of individuals is spread out to k point mutations according to a binomial distribution (described below).
- the separate core-clouds do not overlap;
- all core species are equally likely to reproduce.
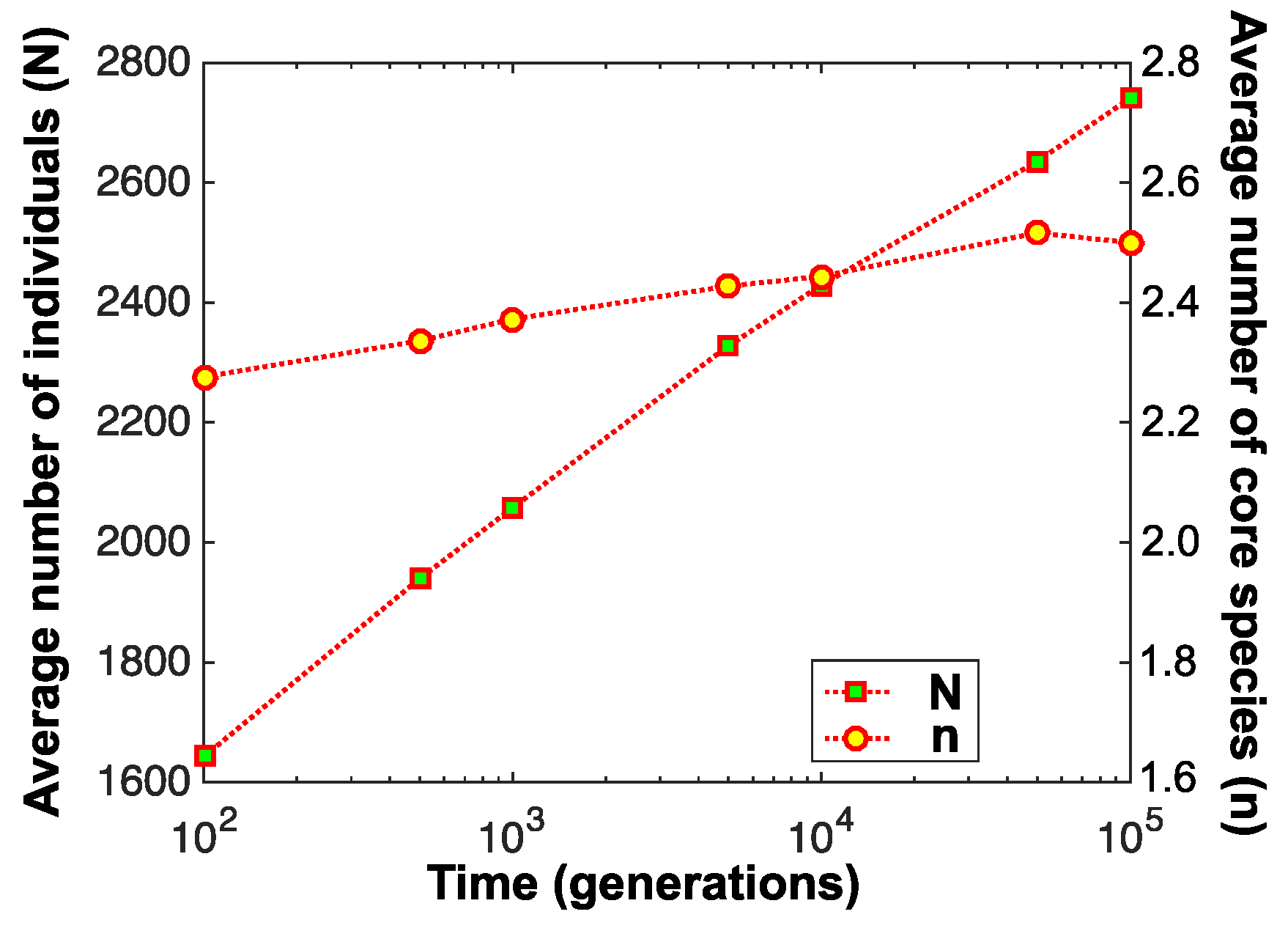
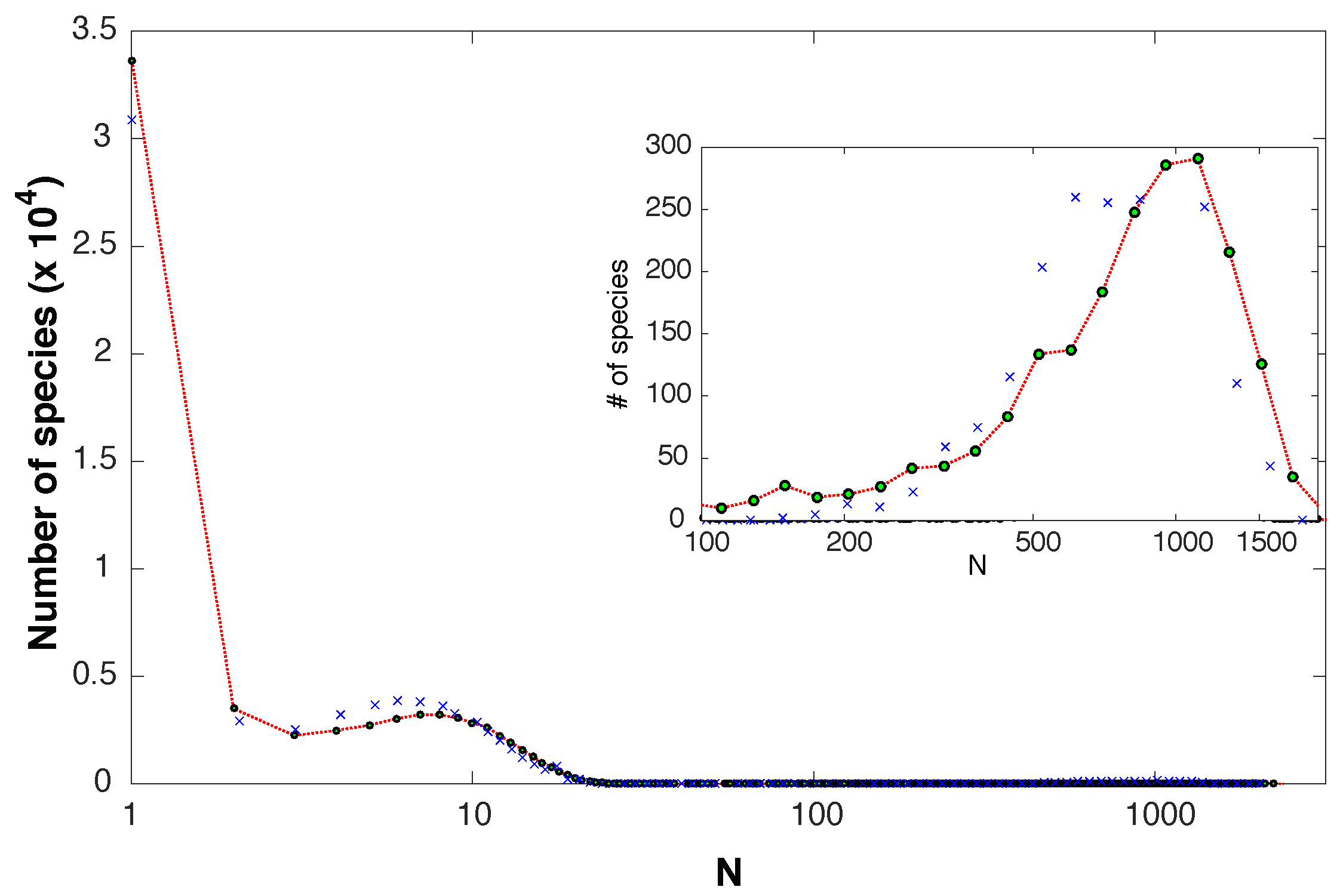
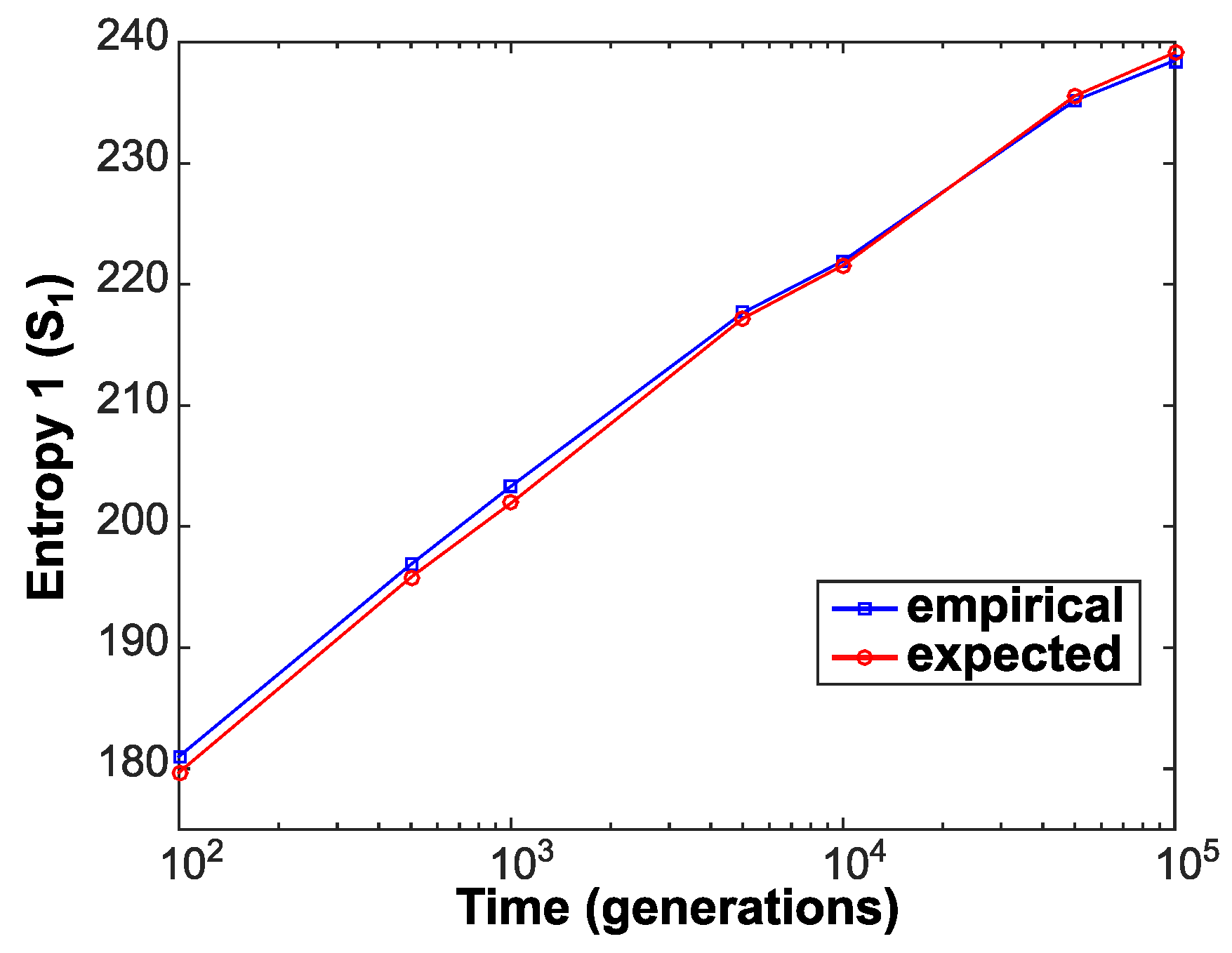
3.3. Predictions from the Simple Model
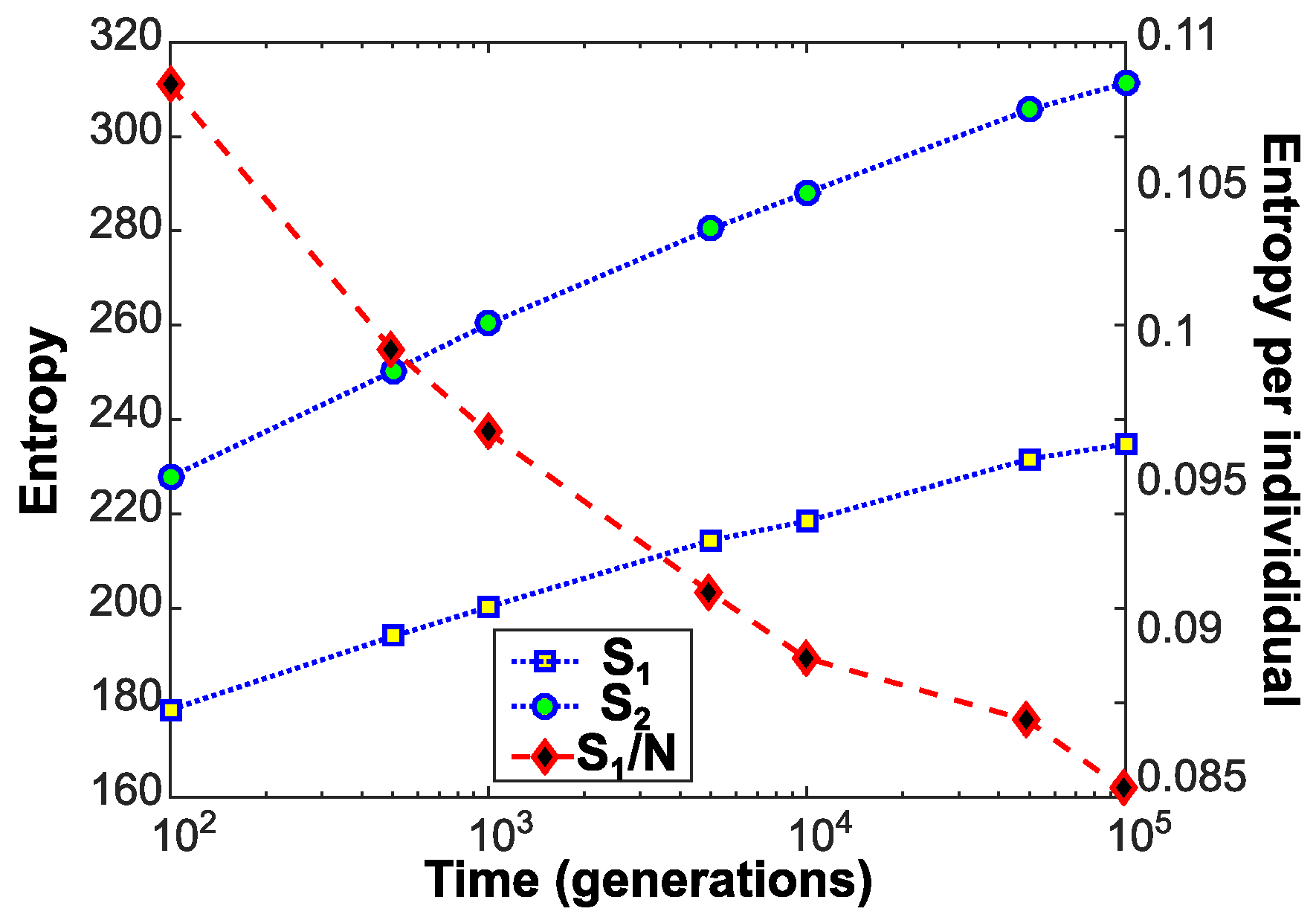
4. Experimental Findings
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. TNM Implementation
Appendix B. Expected Species Abundance

References
- Cushman, S.A. Calculating the configurational entropy of a landscape mosaic. Landsc. Ecol. 2016, 31, 481–489. [Google Scholar] [CrossRef]
- Vranken, I.; Baudry, J.; Aubinet, M.; Visser, M.; Bogaert, J. A review on the use of entropy in landscape ecology: Heterogeneity, unpredictability, scale dependence and their links with thermodynamics. Landsc. Ecol. 2015, 30, 51–65. [Google Scholar] [CrossRef]
- Harte, J. Maximum Entropy and Ecology: A Theory of Abundance, Distribution, and Energetics; Oxford University Press: Oxford, UK, 2011. [Google Scholar]
- Odum, H.T.; Pinkerton, R.C. Time’s speed regulator: The optimum efficiency for maximum power output in physical and biological systems. Am. Sci. 1955, 43, 331–343. [Google Scholar]
- Ulanowicz, R.E. Ecology, the Ascendent Perspective: Robert E. Ulanowicz; Columbia University Press: New York, NY, USA, 1997. [Google Scholar]
- Ulanowicz, R.E. Growth and Development: Ecosystems Phenomenology; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Brooks, D.R.; Wiley, E.O. Evolution as Entropy; University of Chicago Press: Chicago, IL, USA, 1988. [Google Scholar]
- Wicken, J.S. A thermodynamic theory of evolution. J. Theor. Biol. 1980, 87, 9–23. [Google Scholar] [CrossRef]
- Wicken, J.S. Evolution, Thermodynamics, and Information: Extending the Darwinian Program; Oxford University Press: Oxford, UK, 1987. [Google Scholar]
- Depew, D.J.; Weber, B.H. Entropy, Information, and Evolution: New Perspectives on Physical and Biological Evolution; MIT Press: Cambridge, MA, USA, 1988. [Google Scholar]
- Landsberg, P.T. Can entropy and “order” increase together? Phys. Lett. A 1984, 102, 171–173. [Google Scholar] [CrossRef]
- Kauffman, S.A.; Levine, S. Towards a general theory of adaptive walks in rugged landscapes. J. Theor. Biol. 1987, 128, 11–45. [Google Scholar] [CrossRef]
- Kauffman, S.A.; Johnsen, B. Coevolution to the Edge of Chaos: Coupled Fitness Landscapes, Poised States, and Coevolutionary Avalanches. J. Theor. Biol. 1991, 149, 467–505. [Google Scholar] [CrossRef]
- Eldredge, N.; Gould, S.J. Punctuated equilibria: An alternative to phyletic gradualism. In Models in Paleobiology; Freeman, Cooper and Company: San Francisco, CA, USA, 1972; pp. 82–115. [Google Scholar]
- Christensen, K.; de Collobiano, S.A.; Hall, M.; Jensen, H.J. Tangled nature: A model of evolutionary ecology. J. Theor. Biol. 2002, 216, 73–84. [Google Scholar] [CrossRef] [PubMed]
- Hall, M.; Christensen, K.; di Collobiano, S.A.; Jensen, H.J. Time-dependent extinction rate and species abundance in a tangled-nature model of biological evolution. Phys. Rev. E 2002, 66, 011904. [Google Scholar] [CrossRef] [PubMed]
- Anderson, P.E.; Jensen, H.J. Network properties, species abundance and evolution in a model of evolutionary ecology. J. Theor. Biol. 2005, 232, 551–558. [Google Scholar] [CrossRef] [PubMed]
- Volkan, S.; Rikvold, P.A. Effects of correlated interactions in a biological coevolution model with individual-based dynamics. J. Phys. A 2005, 38, 9475–9489. [Google Scholar]
- Lawson, D.; Jensen, H.J. The species-area relationship and evolution. J. Theor. Biol. 2006, 241, 590–600. [Google Scholar] [CrossRef] [PubMed]
- Laird, S.; Jensen, H.J. The Tangled Nature model with inheritance and constraint: Evolutionary ecology restricted by a conserved resource. Ecol. Complex. 2006, 3, 253–262. [Google Scholar] [CrossRef]
- Yoshuke, M.; Shimada, T.; Ito, N.; Rikvold, P.A. Random walk in genome space: A key ingredient of intermittent dynamics of community assembly on evolutionary time scales. J. Theor. Biol. 2010, 264, 663–672. [Google Scholar]
- Becker, N.; Sibani, P. Evolution and non-equilibrium physics: A study of the Tangled Nature Model. EPL 2014, 105, 18005. [Google Scholar] [CrossRef]
- Andersen, C.W.; Sibani, P. Tangled nature model of evolutionary dynamics reconsidered: Structural and dynamical effects of trait inheritance. Phys. Rev. E 2016, 93, 052410. [Google Scholar] [CrossRef] [PubMed]
- Anderson, P.E.; Jensen, H.J.; Oliveira, L.P.; Sibani, P. Evolution in complex systems. Complexity 2004, 10, 49–56. [Google Scholar] [CrossRef]
- Gould, S.J.; Eldredge, N. Punctuated equilibria: The tempo and mode of evolution reconsidered. Paleobiology 1977, 3, 115–151. [Google Scholar] [CrossRef]
- Baldridge, E.; Harris, D.J.; Xiao, X.; White, E.P. An extensive comparison of species-abundance distribution models. PeerJ 2016, 4, e2823. [Google Scholar] [CrossRef] [PubMed]
- Hester, E.R.; Barott, K.L.; Nulton, J.; Vermeij, M.J.; Rohwer, F.L. Stable and sporadic symbiotic communities of coral and algal holobionts. ISME J. 2015, 10, 1157–1169. [Google Scholar] [CrossRef] [PubMed]






© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roach, T.N.F.; Nulton, J.; Sibani, P.; Rohwer, F.; Salamon, P. Entropy in the Tangled Nature Model of Evolution. Entropy 2017, 19, 192. https://doi.org/10.3390/e19050192
Roach TNF, Nulton J, Sibani P, Rohwer F, Salamon P. Entropy in the Tangled Nature Model of Evolution. Entropy. 2017; 19(5):192. https://doi.org/10.3390/e19050192
Chicago/Turabian StyleRoach, Ty N. F., James Nulton, Paolo Sibani, Forest Rohwer, and Peter Salamon. 2017. "Entropy in the Tangled Nature Model of Evolution" Entropy 19, no. 5: 192. https://doi.org/10.3390/e19050192
APA StyleRoach, T. N. F., Nulton, J., Sibani, P., Rohwer, F., & Salamon, P. (2017). Entropy in the Tangled Nature Model of Evolution. Entropy, 19(5), 192. https://doi.org/10.3390/e19050192