1. Introduction
Exponential growth of Internet usage [
1] is driving the development of new algorithms to efficiently search text for potentially relevant information. As smartphones will overtake personal computers in Internet traffic by 2020 [
2], identifying maximal information in concise text is increasingly important. Objective search may be approached by utility functions based on word statistics in the natural language (e.g., [
3]), viewing text as linguistic networks (e.g., [
4]).
Herein we discuss utility functions based on Shannon information theory [
5,
6] which are applicable to snippets of text obtained by key words search. These concordances ([
7] and references therein) are extracted from documents obtained from the Internet. Real-world searches require robust utility functions that are well-defined in the face of words that fall outside common dictionaries or in mixed language documents. In a computerized extraction of concordances from large numbers of documents, such utility functions enable the ranking of text, facilitating in-depth document search in any given language.
Shannon quantifies information by surprise factors of symbols used in discrete encoding of messages by probability of occurrence. In digital computer communications, message size is typically much greater than the size of the dictionary of symbols
. However, conveying information by snippets generally comprises very few words from a natural language dictionary. Miller [
8] refers to such snippets as “chunks”. Shannon and Miller hereby discuss principally distinct limits of
large and
small message size in data transmission, measured by size relative to the dictionary. Miller posits (without proof) that the Shannon information and variance fulfill similar roles in human communication.
In this Letter, we report on empirical power law behavior in information rate and variance in concordances as a function of size
N measured by total word count. A distinguishing feature of the present study is emphasis on relatively short concordances of
20–200 words, distinct from entire books (e.g., [
9]).
To illustrate and set notation, consider a dictionary
. Messaging by a source
with uniform probability distribution
features an information rate
that is,
bits per word, defined by the average surprise factor
. Messaging over a proper subset
by a source
with probability distribution
(
;
) features a reduced information rate
where the right-hand-side provides an approximation based on the probability distribution of
. By probabilities,
is preferred over
S as a source of messages. In the present study, we aim to rank messages accordingly, in the form of concordances extracted from online text by key word search.
In real-world applications, our symbols of encoding are words with typical frequencies determined by the natural language. Sources may display variations in word probabilities reflecting individual word preferences. For computational analysis of messages across a broad range of sources, we consider a truncated dictionary
D of the most common words, whose probability distribution approximates that of all words in a more comprehensive dictionary, dropping words that are exceedingly rare, not traditionally included in dictionaries, or of foreign origin. Such
D is readily extracted from a large number of documents, randomly selected over a broad range of subjects. Fixing
D,
for each
is established by normalizing inferred word frequencies,
For instance,
have relative probabilities
based on a truncated dictionary
D defined by a top list of 10,000 words (
Table 1).
In text, words contribute to the information rate per word according to
A sum over all
in
D obtains the mean rate
Relative to the maximum
bits word
for a uniform probability distribution (
for all
i), we have
illustrated by (
2) in our example above.
The result (
6) illustrates Miller’s classic result on approximately 8–10 mostly binary features identified in speech analysis [
8,
10]. However, (
7) under-estimates information rates in short expressions due to the non-unform probability distribution of words in the natural language (
Table 1). It becomes meaningful only in the large
N limit, for text approaching the size of a dictionary. While this limit may apply to large bodies of text, it is not representative for messages in direct human-to-human communication or human–machine interactions.
To begin, we consider the above for communications in a data base of 90,094 concordances of size
20–200 comprising a total of 8,842,720 words, extracted from the Internet by various key word searches and evaluated for Shannon information rates and associated variances (
Section 2). Statistical properties are observed to satisfy power law behavior. They are analyzed for their dependence on
, motivated by a heuristic analogy between information flow across messages of various size and inertial energy cascade over turbulent eddies. The latter serves as a model for energy flow over complex nonlinear dynamics involving a large number of degrees of freedom, satisfying Kolmogorov scaling as a function of wave number
k [
11,
12,
13] (
Section 3). Results for our data base of concordances are given in terms of power law indices and compared with Kolmogorov scaling (
Section 4). In
Section 5, we summarize our findings.
2. A Data-Base of Concordances
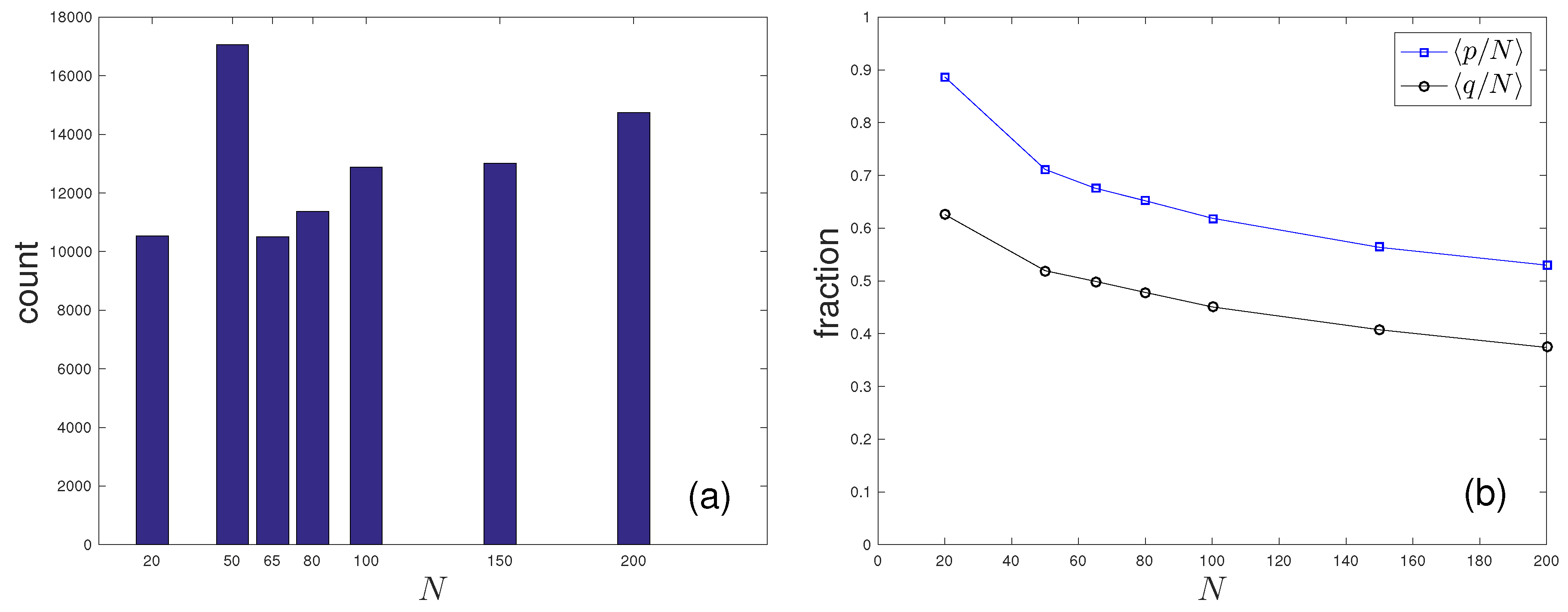
We compiled a data-base of 90,094 concordances
C with size
20–200 from thousands of documents on the Word Wide Web (
Figure 1). They are extracted by key word search covering a broad range of generic topics in sports, culture, science, and politics [
14,
15]. For each search, concordances are extracted from about
online source pages identified with the highest document rank by existing Internet search, and downloaded for analysis as described below by parallel computing on a cluster of personal computers. Experimentally, we determined top lists of concordances ranked by information rate (
8) (below), which remain essentially unchanged when
M reaches 80;
M less than 50 occasionally fails to capture concordances of highest text rank as defined below. On this basis, our results are also expected to be reasonably independent of the choice of Internet document search engine.
As snippets, concordances always comprise a small subset of a dictionary, including
D containing most common words mentioned above. For
N on the order of tens to hundreds of words,
in (
7) is not directly meaningful for estimating information in concordances due to selection effects: snippets contain few words, many of which are relatively common by non-uniformity of word frequencies in
D (
Table 1) with relatively significant contributions to information flow rate
in (
5).
Information rates in concordances are obtained by summing (
5) over all distinct words therein,
Our focus is to quantify statistical properties of
R as a function of
N given
D. Here,
shall denote its list of
q distinct words in
C that are in
D. This reduction avoids over-counting of words, and implicitly assigns probability zero to words that are not in
D. The first is important for accuracy, the second renders (
8) robust in the face of words that are not included in
D, because they are rarely used (
Table 1) or of foreign origin. Assigned
, these exceptional words are not included in (
3). Since (
8) has a well-defined limit as
approaches zero, it applies to real-world text extracted from documents online by generic search engines. Distinct words
in
C that are in
D comprise
words, typically about one-half of
N (
Figure 1).
Table 2 illustrates a top list of concordances, obtained by the key word search “apple pie” and text ranked by
R. A search with relatively few key and generic words readily obtains well over ten concordances per document (i.e., on the order of one thousand in
documents extracted from the Internet by existing document search). Identification of those potentially most relevant to the user necessitates computerized ranking, here by the utility function
R.
In studying statistical properties of
R as a function of concordance size
N, we further consider the unnormalized variance
suggested by Miller’s conjecture on information measured by variance,
. Dependence on
N in the statistical properties of
will be found to satisfy a power law with index
,
The index
in (
10) will be determined by detailed partitioning of information flow in large amounts of text into multiple messages, i.e., in expressions, statements, snippets and the like across different sizes. In the absence of detailed modeling,
in (
10) is expected to be tightly correlated to
R in (
8) in an intuitive analogy of information and energy flow. In fluid dynamics, representing a nonlinear system with a large number of degrees of freedom, energy flow satisfies Kolmogorov scaling in conservative cascade to small scales in fully developed turbulence [
16].
3. Kolmogorov Scaling in Energy Flow
Turbulent motion in high Reynolds number (Re) fluid flow demonstrates power law behavior in energy cascade by nonlinear dynamics that includes period doubling. Its inertial range comprises a large number of degrees of freedom ∝ Re
, over which energy flow cascades over eddies of size
, breaking up
conservatively into increasingly smaller eddies across wave numbers
Here,
,
refers to eddies set by the linear size of the system, and
refers to the wave number at which viscous dissipation sets in. This cascade persists by power input
at
. In the inertial range (
11), the
is conserved across
k, posing a constraint on the spectral energy density
, satisfying Plancherel’s formula
with
Since
s
,
s
, dimensional analysis obtains the Kolmogorov scaling
The Kolmogorov index
has been found to be remarkably universal in fully developed turbulence, from fluid dynamics [
17] to broadband fluctuations in gamma-ray light curves [
18].
4. Power Law and Kolmogorov Scaling in Information Flow
By (
5), information rates of concordances
are increasing as a function of size
N, formally satisfying
where
denotes the number of times a word
appears in
C. The latter is a consequence of the fact that
approaches
D in the limit as
N becomes arbitrarily large.
For our data base,
Figure 1 shows concordance averages of relative counts
of distinct words (avoiding multiplicities of recurring words) and the relative counts
of distinct words in
D. The average value of
is found to be somewhat similar to
in (
7), with a minor dependence on the choice of
N.
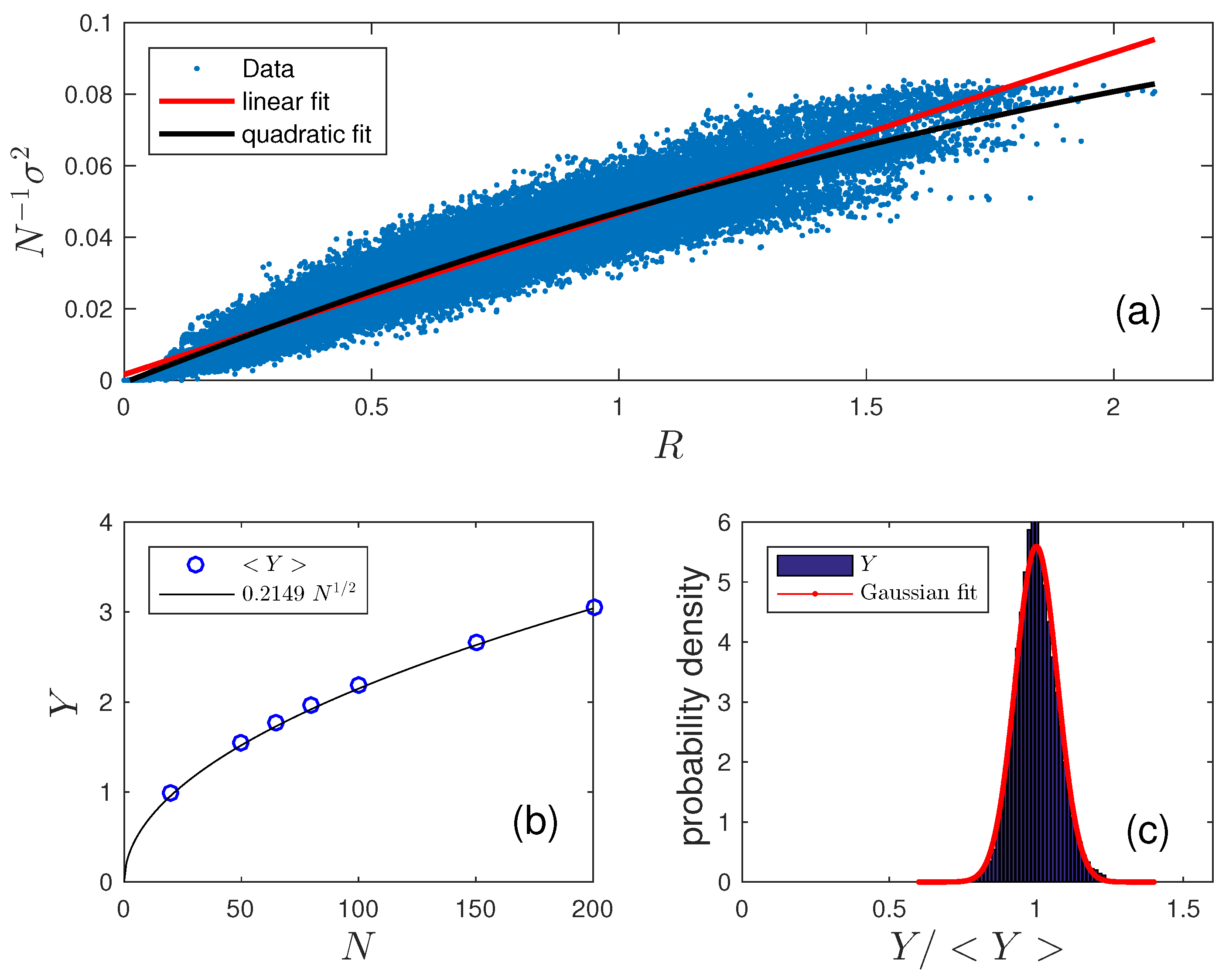
Figure 2 shows
and its correlation to
R. Expressed in terms of the normalized standard deviation
which points to
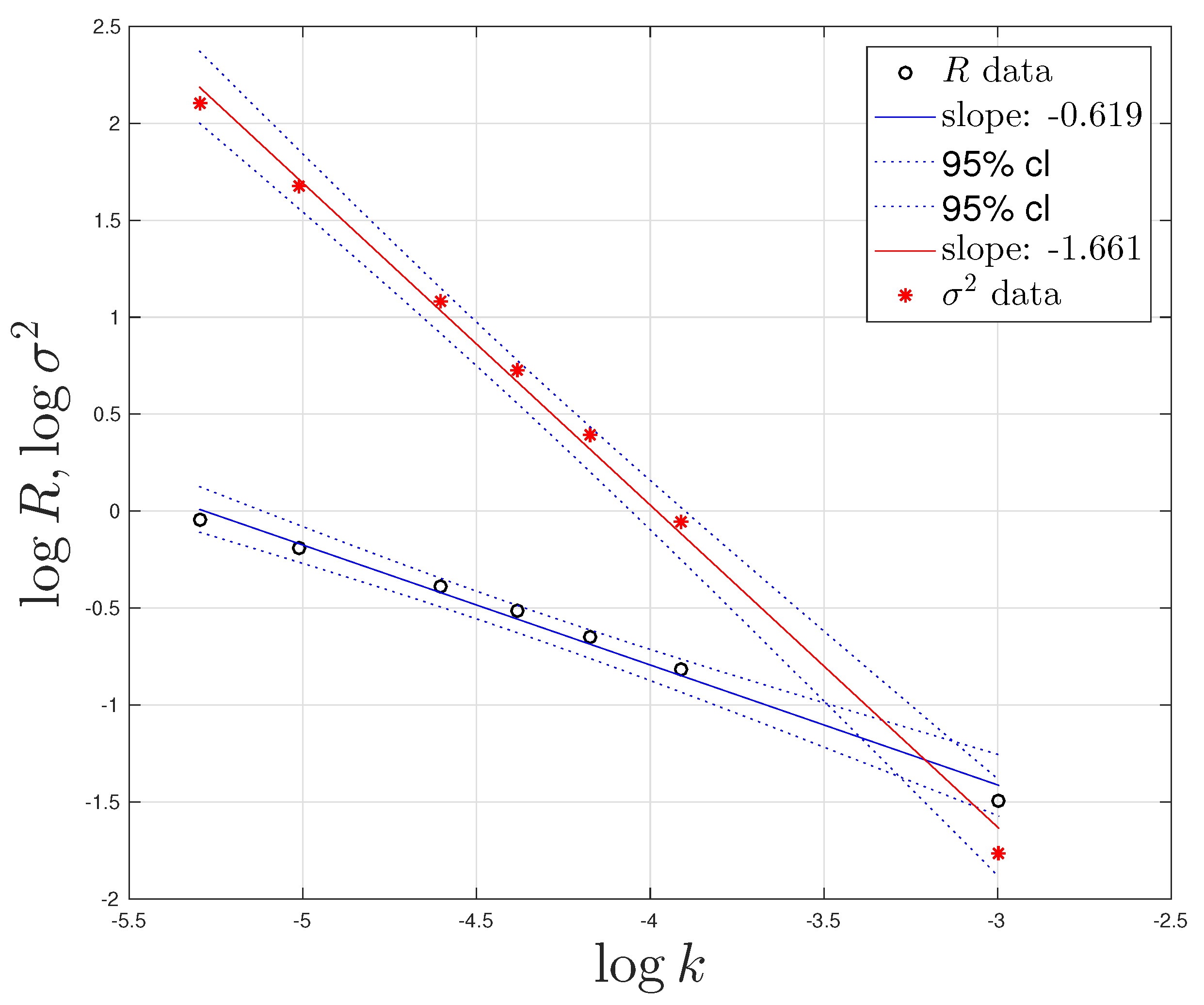
Figure 3 shows the power law behavior as a function of
obtained by weighted nonlinear model regression computed by the MatLab function
fitnlm [
19] with weights according to concordance counts (
Figure 1). The results with 95% confidence levels are
Scaling of
in (
19) is consistent with (
18) combined with scaling of
R in (
19).
Figure 3 shows a slight concave curvature in the residuals to the linear fit to the data. While this is within the 95% confidence level shown, this feature may be a real deviation from power law behavior, perhaps associated with nonlinear scaling at large
R (
Figure 2). A detailed consideration is beyond the present scope, however.
5. Conclusions
We identify Kolmogorov scaling (
19) in the variance of concordance information with power law scaling in association with information rate as a function of size
20–200.
We present Kolmogorov scaling in variance as an empirical result, which suggests that information flow over snippets is analogous to energy cascade over eddies. Since Kolmogorov scaling in the inertial range (
11) critically depends on conservation of energy, (
19) suggests that perhaps there is a similar conservation law at work in information flow by concordances.
Our observed power law scalings (
19) give a succinct statistical summary on communication by concordances in the natural language. At sizes much smaller than the size of a dictionary, the results are fundamentally different from what is obtained in Shannon’s large
N limit of binary strings in computer-to-computer communications, arising from the strongly non-uniform probability distribution in words in the natural language.
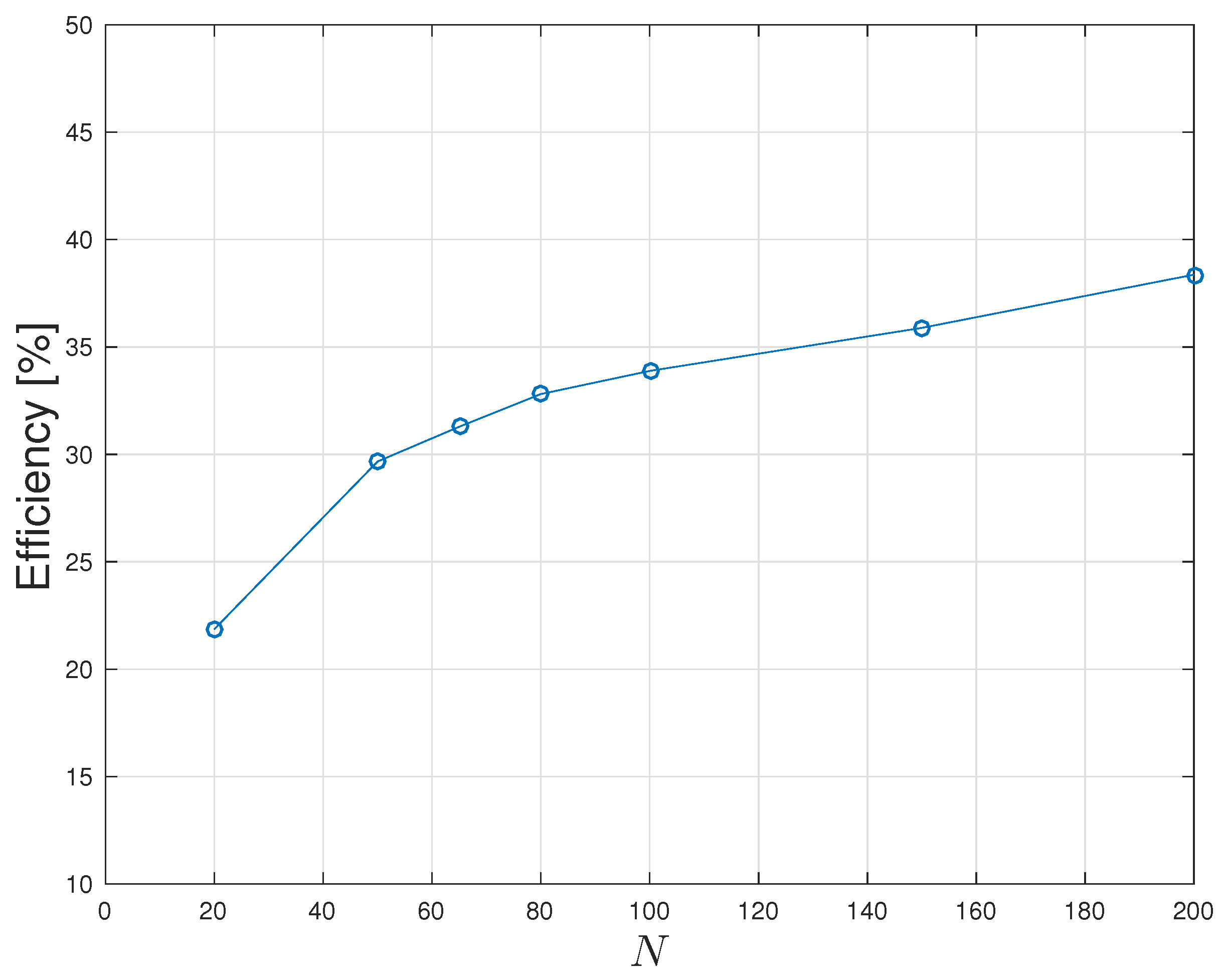
Figure 4 further shows a generally increasing efficiency
, normalized to the upper bound
U defined by word probabilities sorted in descending order (
,
),
Relatively long concordances show an increase to about 40% efficiency, beyond about 25% in short concordances. Twitter’s tweets of 140 characters—corresponding to about 24 words on average at a mean of about five letters and one space per word in English—hereby appears sub-optimal by a factor of about two. Reasonably efficient social networking communication obtains with tweets on the order of 1000 characters.
Based strictly on word frequencies in natural language,
R and/or
provide robust utility functions for objective ranking of snippets by potential relevance. This can be used for efficient search through a large body of documents from a variety of sources by limiting output to a top list of ranked concordances [
14,
15]. A suitable sample of source documents is readily extracted from the Internet by existing search engines.
A generalization to search seamlessly across different languages is obtained by first translating key words to a second language in which to obtain a body of source documents and concordances therein. Ranking by
R and/or
based on word frequencies in this second language produces a top list that can be translated back to the first language. This process is highly efficient, by limiting translations to a moderate number of concordances, circumventing the need for any document translation in full [
20].
Power law behavior (
19) in snippets of text also points to novel directions to machine learning. For instance, ranking by
R and/or
may be a first step to artificial attention—with concordances larger in size than tweets—to select snippets as input to further processing (e.g., generating new queries by artificial intelligence).







{kind=link}
{kind=link}
{kind=link}
{kind=link}