
Prediction and Evaluation of Zero Order Entropy Changes in Grammar-Based Codes



Abstract
:1. Introduction
1.1. Notation and Terminology
- The alphabet of the input message m of the size is denoted by and its size by .
- Greek symbols are used to denote variables representing symbols in the input message. For instance, suppose two digrams , and the alphabet . Then, and .
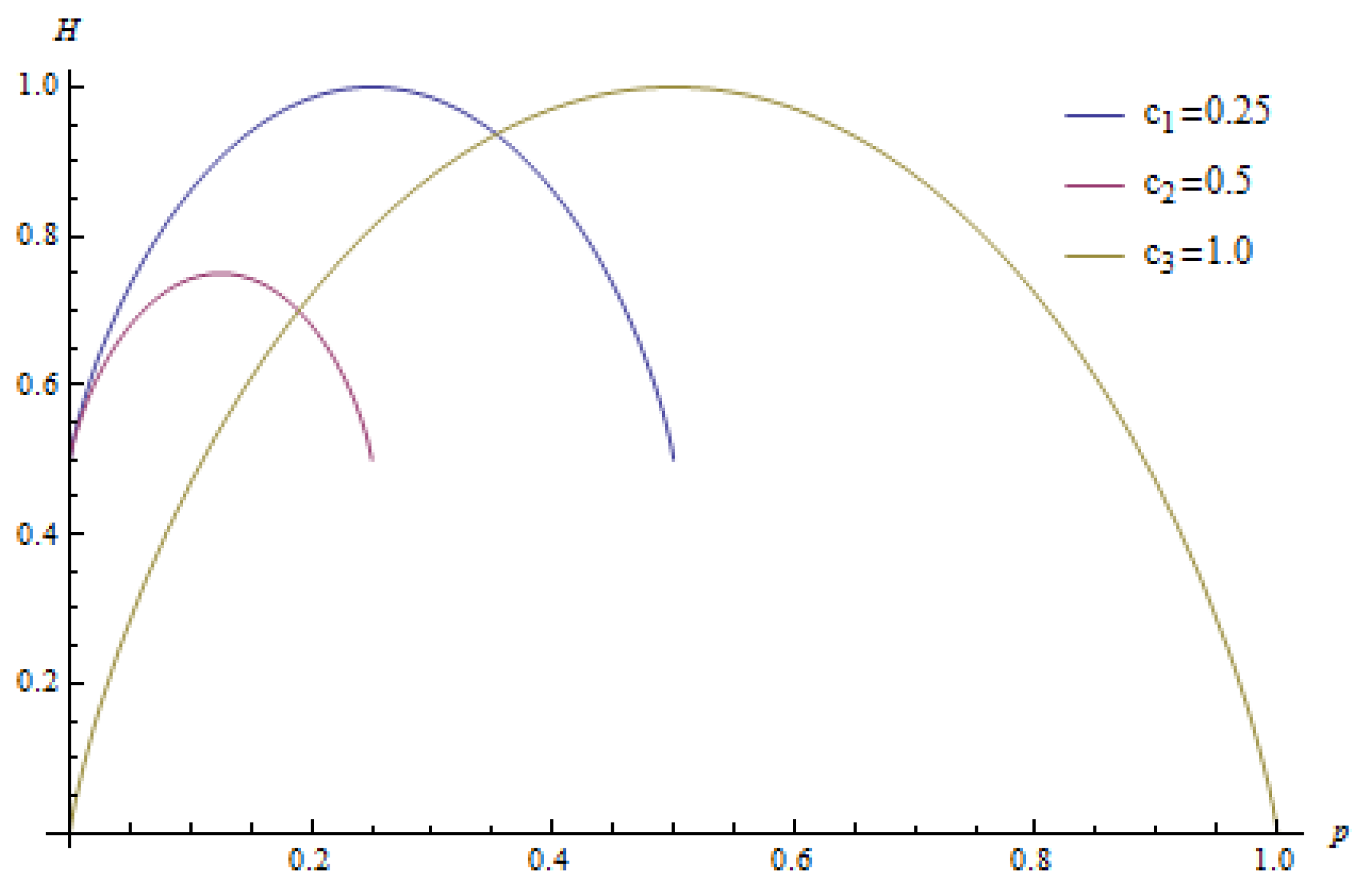
- When we refer to the term entropy, we always mean Shannon’s entropy defined by Equation (1).
- All logarithms are to base two.
- Any quantity with a subscript denotes consecutive states of the quantity between substitutions. For instance, a quantity is a value of the quantity before any substitution is applied, and is a value of the quantity after some substitution is applied.
1.2. Order of Context and Entropy
1.2.1. Zero Order Context
1.2.2. N-th Order Context
2. Previous Work
3. Transformations and Compression Algorithms
3.1. Transformations
3.1.1. Context Transformation
3.1.2. Generalized Context Transformation
- Find and apply transformation T so that the change of the entropic size is maximal.
- Repeat Step 1 until no transformation can decrease the entropic size of the message.
3.1.3. Higher Order Context Transformation
- Find and apply over the set of positions , so that the change of entropic size is maximal and .
- If the frequency of resp. is larger than one, then repeat Step 1 over the set of positions resp. , i.e., positions where from Step 1 was applied; otherwise, repeat Step 1 over positions or return if no more passes the entropic size reduction conditions.
3.2. Compression Functions
3.2.1. Re-Pair
- Select the most frequent digram in message m.
- Replace all occurrences of for new symbol .
- Repeat Steps 1 and 2 until every digram appears only once.
3.2.2. MinEnt
- Select digram in message so that the change of entropic size is maximal.
- Replace all occurrences of for new symbol .
- Repeat Steps 1 and 2 until every digram appears only once.
3.3. Discussion of the Transformation and Compression Function Selection Strategies
- : selection of the generalized context transformation so that the decrease of entropy is maximal.
- : selection of the higher order context transformation so that the decrease of entropy is maximal in the context of prefix w.
- Re-Pair: selection of the most frequent digram and its replacement with an unused symbol.
- MinEnt: selection of the most entropic size reducing digram and its replacement with an unused symbol.
3.3.1. The Upper Boundary on the Dictionary Entry Size
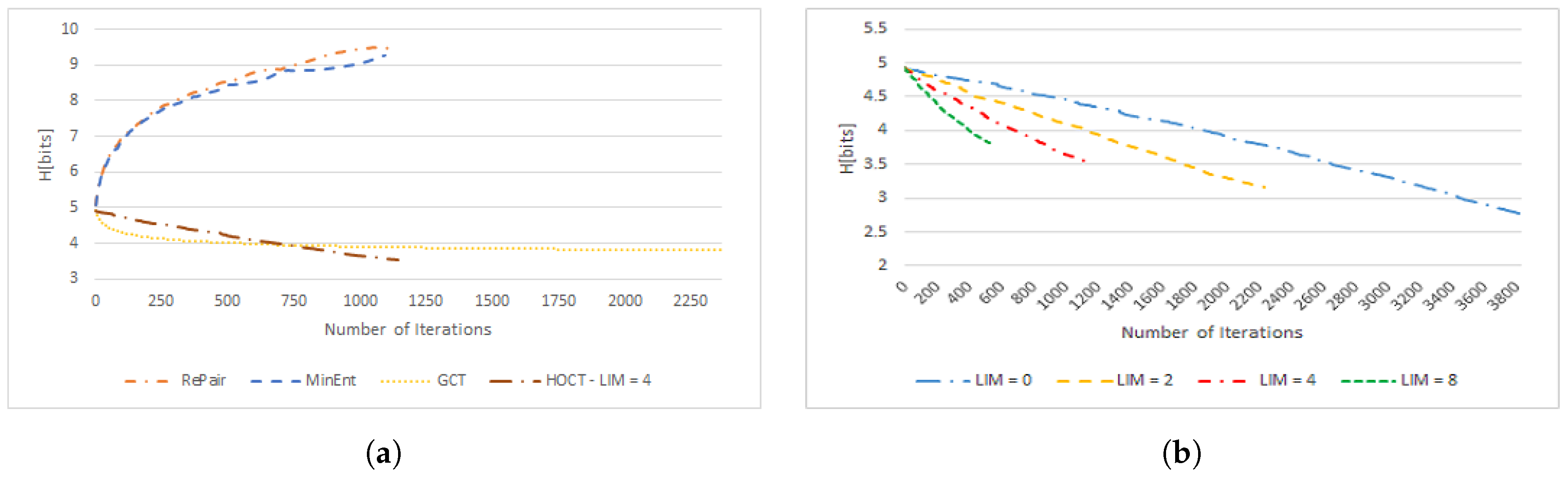
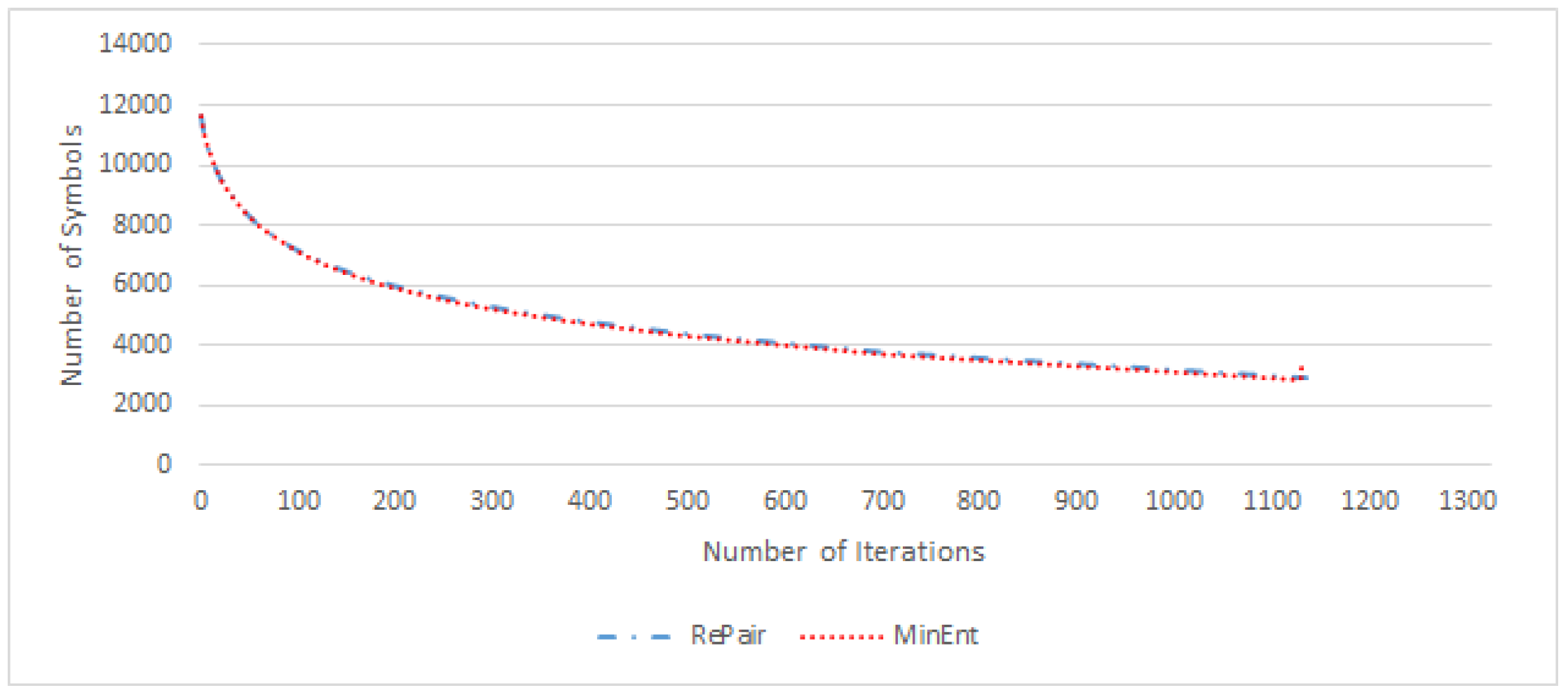
3.3.2. Comparison of the Alphabet’s Entropy Evolution
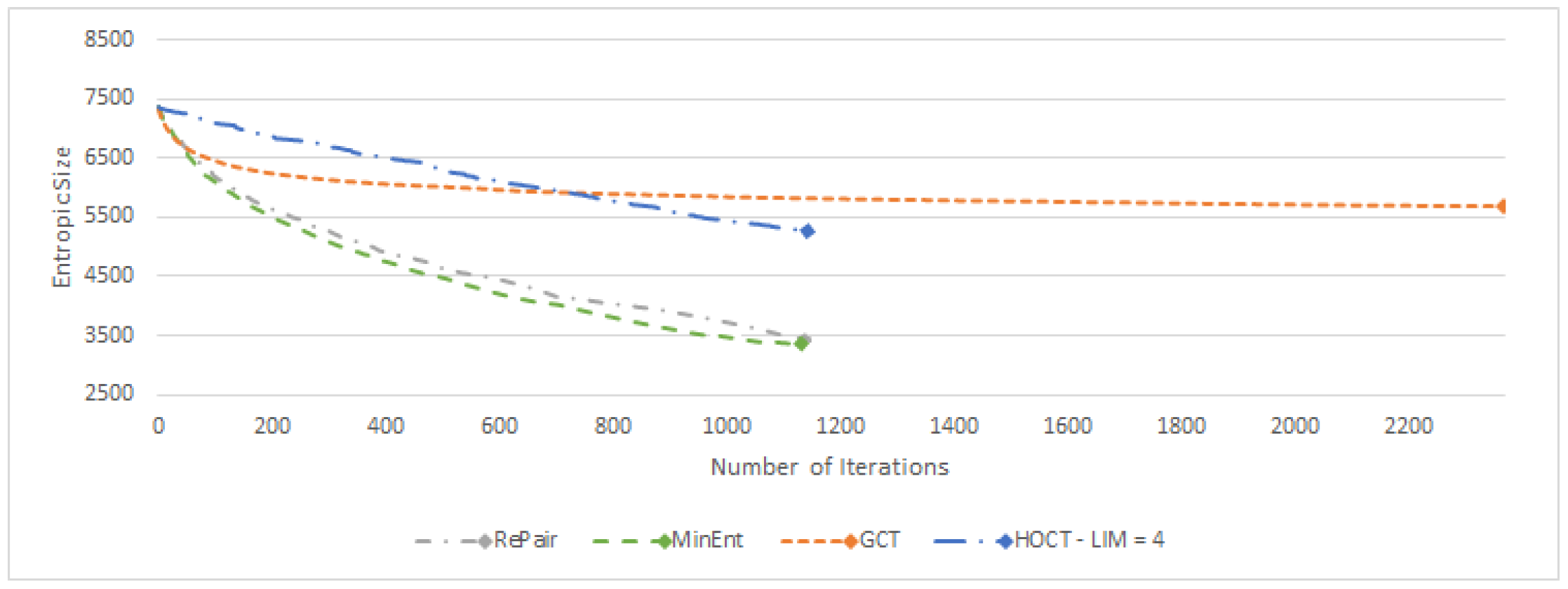
3.3.3. Comparison of Entropic Size Evolution
4. Zero Order Entropy and Entropic Message Size Reduction
4.1. Transformation of Probabilities
4.2. General Entropy Change Relations
4.2.1. The First Part: Symbols Remaining Intact by the Substitution Function
4.2.2. The Second Part: Symbols Participating in the Substitution Function
4.2.3. Third Part: Introduced and Removed Symbols
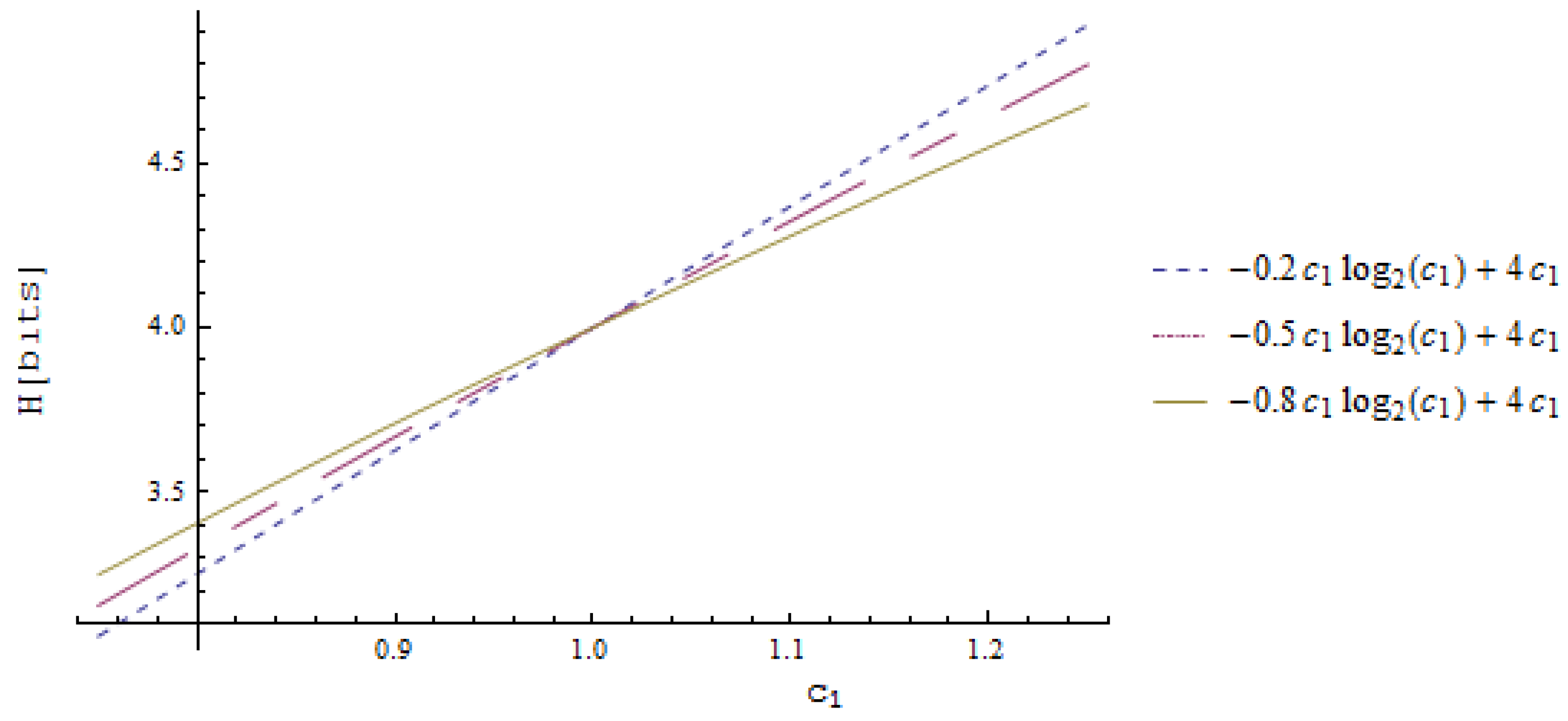
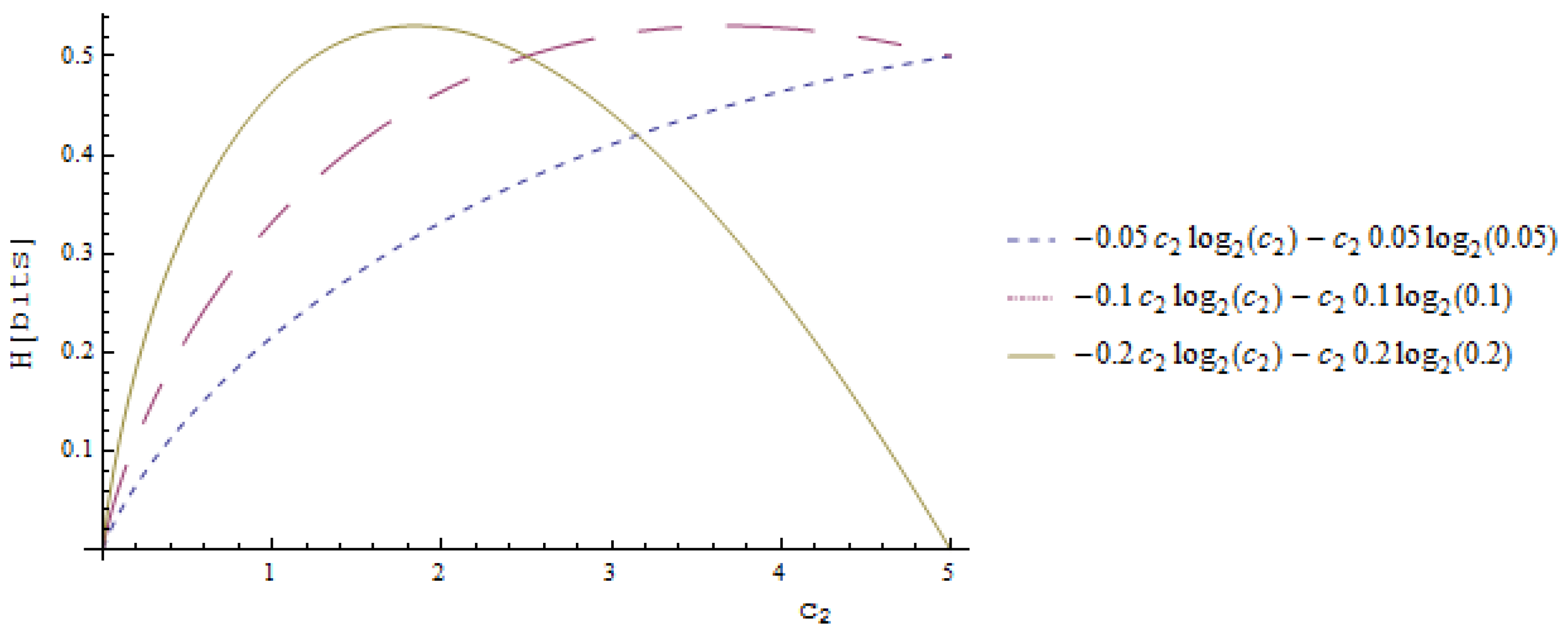
4.3. Calculation of
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
Appendix A.1. CT—Proof of the Correctness
Appendix A.2. Diagonal Context Transformation
Appendix A.3. GCT—Frequencies Alteration
Appendix A.4. Generic Transformation—Proof of Correctness
Appendix A.5. HOCT—Proof of the Correctness
References
- Cover, T.M.; Thomas, J.A. Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing); Wiley-Interscience: New York, NY, USA, 2006. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Huffman, D.A. A Method for the Construction of Minimum-Redundancy Codes. Proc. Inst. Radio Eng. 1952, 40, 1098–1101. [Google Scholar] [CrossRef]
- Witten, I.H.; Neal, R.M.; Cleary, J.G. Arithmetic Coding for Data Compression. Commun. ACM 1987, 30, 520–540. [Google Scholar] [CrossRef]
- Charikar, M.; Lehman, E.; Lehman, A.; Liu, D.; Panigrahy, R.; Prabhakaran, M.; Sahai, A.; Shelat, A. The Smallest Grammar Problem. IEEE Trans. Inf. Theory 2005, 51, 2554–2576. [Google Scholar] [CrossRef]
- Nevill-Manning, C.G. Inferring Sequential Structure. Ph.D. Thesis, University of Waikato, Hamilton, New Zealand, May 1996. [Google Scholar]
- Nevill-Manning, C.G.; Witten, I.H. Identifying Hierarchical Structure in Sequences: A Linear-time Algorithm. J. Artif. Int. Res. 1997, 7, 67–82. [Google Scholar]
- Kieffer, J.C.; Yang, E.-H. Grammar Based Codes: A New Class of Universal Lossless Source Codes. IEEE Trans. Inf. Theory 2000, 46, 737–754. [Google Scholar] [CrossRef]
- Ziv, J.; Lempel, A. Compression of individual sequences via variable-rate coding. IEEE Trans. Inf. Theory 1978, 24, 530–536. [Google Scholar] [CrossRef]
- Yang, E.; He, D. Efficient universal lossless data compression algorithms based on a greedy sequential grammar transform 2. With context models. IEEE Trans. Inf. Theory 2003, 49, 2874–2894. [Google Scholar] [CrossRef]
- Gage, P. A New Algorithm for Data Compression. C Users J. 1994, 12, 23–38. [Google Scholar]
- Nakamura, H.; Marushima, S. Data Compression by Concatenation of Symbol Pairs. In Proceedings of the IEEE International Symposium on Information Theory and Its Applications, Paris, France, 13–17 September 1996; pp. 496–499. [Google Scholar]
- Larsson, N.J.; Moffat, A. Off-line dictionary-based compression. Proc. IEEE 2000, 88, 1722–1732. [Google Scholar] [CrossRef]
- Claude, F.; Farina, A.; Navarro, G. Re-Pair Compression of Inverted Lists. arXiv 2009. [Google Scholar]
- Masaki, T.; Kida, T. Online Grammar Transformation Based on Re-Pair Algorithm. In Proceedings of the Data Compression Conference (DCC), Snowbird, UT, USA, 29 March–1 April 2016; pp. 349–358. [Google Scholar]
- Grassberger, P. Data Compression and Entropy Estimates by Non-sequential Recursive Pair Substitution. Physics 2002. [Google Scholar]
- Calcagnile, L.M.; Galatolo, S.; Menconi, G. Non-sequential recursive pair substitutions and numerical entropy estimates in symbolic dynamical systems. arXiv 2008. [Google Scholar]
- Navarro, G.; Russo, L. Re-pair Achieves High-Order Entropy. In Proceedings of the Data Compression Conference, DCC 2008, Snowbird, UT, USA, 25–27 March 2008; p. 537. [Google Scholar]
- Vasinek, M.; Platos, J. Entropy Reduction Using Context Transformations. In Proceedings of the Data Compression Conference (DCC), Snowbird, UT, USA, 26–28 March 2014; p. 431. [Google Scholar]
- Vasinek, M.; Platos, J. Generalized Context Transformations—Enhanced Entropy Reduction. In Proceedings of the Data Compression Conference (DCC), Snowbird, UT, USA, 7–9 April 2015; p. 474. [Google Scholar]
- Vasinek, M.; Platos, J. Higher Order Context Transformations. arXiv 2017. [Google Scholar]
- Kida, T.; Matsumoto, T.; Shibata, Y.; Takeda, M.; Shinohara, A.; Arikawa, S. Collage System: A Unifying Framework for Compressed Pattern Matching. Theor. Comput. Sci. 2003, 298, 253–272. [Google Scholar] [CrossRef]
- González, R.; Navarro, G. Compressed Text Indexes with Fast Locate. In Proceedings of the 18th Annual Conference on Combinatorial Pattern Matching, CPM’07, London, ON, Canada, 9–11 July 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 216–227. [Google Scholar]
- Claude, F.; Farina, A.; Navarro, G. Re-Pair compression of inverted lists. arXiv 2009. [Google Scholar]
- Vasinek, M. Kontextove Mapy a Jejich Aplikace. Master’s Thesis, Vysoka Skola Banska—Technicka Univerzita Ostrava, Ostrava, Czech Republic, 2013. [Google Scholar]
- Vasinek, M.; Platos, J. Parallel Approach to Context Transformations. Available online: http://ceur-ws.org/Vol-1343/paper4.pdf (accessed on 11 May 2017).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| File Name | ||||
|---|---|---|---|---|
| paper5 | 91 | 11 954 | 4.936 | 7 376 |
| Strategy | i | |||||
|---|---|---|---|---|---|---|
| 0 | 2367 | 3.796 | 5674 | 6.508 | 11,451 | |
| 127 | 4.260 | 6366 | 6.508 | 6676 | ||
| 0 | 3 821 | 2.786 | 4163 | 6.508 | 13,488 | |
| 4 | 1 143 | 3.528 | 5272 | 6.508 | 8061 | |
| 8 | 525 | 3.830 | 5713 | 6.508 | 6994 | |
| 222 | 4.067 | 6078 | 6.508 | 6439 |
| Strategy | i | ||||||
|---|---|---|---|---|---|---|---|
| Re-Pair | 1146 | 965 | 2832 | 9.283 | 3286 | 10.240 | 4753 |
| MinEnt | 1129 | 944 | 2798 | 9.395 | 3286 | 10.281 | 4737 |
| File Name | i | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Calgary corpus | ||||||||||
| bib | 111,261 | 81 | 5.257 | 5469 | 4216 | 15,159 | 11.410 | 21,621 | 11.589 | 29,544 |
| book1 | 768,771 | 82 | 4.528 | 23,587 | 22,649 | 128,059 | 13.422 | 214,859 | 11.904 | 249,957 |
| book2 | 610,856 | 96 | 4.681 | 21,147 | 18,501 | 82,446 | 13.213 | 136,165 | 12.829 | 170,079 |
| news | 377,109 | 98 | 5.226 | 20,079 | 13,602 | 55,500 | 12.809 | 88,863 | 12.761 | 120,892 |
| obj1 | 21,504 | 256 | 5.929 | 1650 | 1475 | 6464 | 9.888 | 7990 | 10.918 | 10,242 |
| obj2 | 246,814 | 256 | 6.280 | 14,635 | 9569 | 35,540 | 12.323 | 54,743 | 13.044 | 78,607 |
| paper1 | 53,161 | 95 | 4.967 | 3559 | 2678 | 8800 | 10.890 | 11,979 | 11.360 | 17,033 |
| paper2 | 82,199 | 91 | 4.506 | 4297 | 3753 | 14,102 | 11.235 | 19,805 | 11.181 | 25,811 |
| paper3 | 46,526 | 84 | 4.588 | 2989 | 2575 | 9061 | 10.767 | 12,195 | 10.791 | 16,227 |
| paper4 | 13,286 | 80 | 4.602 | 1194 | 997 | 3136 | 9.622 | 3772 | 10.130 | 5284 |
| paper6 | 38,105 | 93 | 5.000 | 2834 | 2108 | 6670 | 10.585 | 8826 | 11.220 | 12,801 |
| progc | 39,611 | 92 | 5.282 | 2854 | 2066 | 6526 | 10.641 | 8681 | 11.254 | 12,696 |
| progl | 71,646 | 87 | 4.830 | 4162 | 2577 | 7216 | 10.851 | 9788 | 12.003 | 16,033 |
| progp | 49,379 | 89 | 4.823 | 3147 | 1684 | 4528 | 10.272 | 5814 | 11.952 | 10,516 |
| trans | 93,695 | 99 | 5.545 | 5918 | 2505 | 6513 | 10.968 | 8929 | 12.419 | 18,116 |
| Canterbury corpus | ||||||||||
| alice29.txt | 152,089 | 74 | 4.435 | 6733 | 6068 | 25,077 | 11.985 | 37,568 | 11.482 | 47,232 |
| asyoulik.txt | 125,179 | 68 | 4.889 | 5799 | 5293 | 23,532 | 11.774 | 34,634 | 10.932 | 42,559 |
| bible.txt | 4,047,392 | 63 | 4.260 | 81,229 | 71,256 | 386,094 | 15.017 | 724,728 | 14.525 | 872 215 |
| cp.html | 24,603 | 86 | 5.107 | 1785 | 1271 | 4242 | 9.590 | 5085 | 10.689 | 7470 |
| E.coli | 4,638,690 | 4 | 2.000 | 67,368 | 62,924 | 652,664 | 13.725 | 1,119,687 | 7.462 | 1182 530 |
| fields.c | 11,150 | 90 | 4.924 | 927 | 658 | 1503 | 9.304 | 1748 | 10.822 | 3002 |
| kennedy.xls | 1,029,744 | 256 | 3.584 | 2446 | 2545 | 160,177 | 9.788 | 195,978 | 8.274 | 198 508 |
| lcet10.txt | 426,754 | 84 | 4.627 | 14,515 | 12,395 | 55,691 | 12.759 | 88,823 | 12.426 | 111,369 |
| ptt5 | 513,216 | 159 | 1.049 | 5995 | 5697 | 30,463 | 11.424 | 43,503 | 11.178 | 51,880 |
| random.txt | 100,000 | 64 | 6.000 | 5065 | 5126 | 54,182 | 11.182 | 75,731 | 3.983 | 78,253 |
| sum | 38,240 | 255 | 5.447 | 3116 | 1749 | 6251 | 10.290 | 8041 | 11.912 | 12,681 |
| world192.txt | 2,473,400 | 94 | 5.024 | 55,473 | 47,150 | 212,647 | 14.552 | 386,808 | 13.973 | 483 705 |
| xargs.1 | 4227 | 74 | 4.863 | 468 | 384 | 990 | 8.255 | 1022 | 9.811 | 1596 |
| File Name | i | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Calgary corpus | ||||||||||
| bib | 111,261 | 81 | 5.201 | 5513 | 4150 | 15,103 | 11.307 | 21,346 | 11.717 | 29,421 |
| book1 | 768,771 | 82 | 4.527 | 23,843 | 22,616 | 127,777 | 13.377 | 213,656 | 12.134 | 249,822 |
| book2 | 610,856 | 96 | 4.793 | 20,852 | 17,997 | 80,814 | 13.170 | 133,045 | 12.847 | 166,533 |
| news | 377,109 | 98 | 5.190 | 20,118 | 13,388 | 55,347 | 12.697 | 87,845 | 12.918 | 120,333 |
| obj1 | 21,504 | 256 | 5.948 | 1638 | 1418 | 6459 | 9.727 | 7853 | 11.135 | 10,133 |
| obj2 | 246,814 | 256 | 6.260 | 14,673 | 9337 | 35,510 | 12.173 | 54,031 | 13.218 | 78,275 |
| paper1 | 53 161 | 95 | 4.983 | 3579 | 2633 | 8726 | 10.741 | 11,716 | 11.413 | 16,822 |
| paper2 | 82,199 | 91 | 4.601 | 4247 | 3612 | 13,797 | 11.088 | 19,123 | 11.221 | 25,080 |
| paper3 | 46,526 | 84 | 4.665 | 3004 | 2529 | 8993 | 10.676 | 12,002 | 10.892 | 16,092 |
| paper4 | 13,286 | 80 | 4.700 | 1136 | 930 | 3133 | 9.232 | 3615 | 10.288 | 5076 |
| paper6 | 38,105 | 93 | 5.010 | 2841 | 2080 | 6662 | 10.398 | 8659 | 11.297 | 12,671 |
| progc | 39,611 | 92 | 5.199 | 2871 | 2034 | 6530 | 10.444 | 8525 | 11.307 | 12,583 |
| progl | 71,646 | 87 | 4.770 | 4175 | 2495 | 7134 | 10.742 | 9579 | 12.100 | 15,894 |
| progp | 49,379 | 89 | 4.869 | 3145 | 1631 | 4509 | 10.166 | 5730 | 12.194 | 10,524 |
| trans | 93,695 | 99 | 5.533 | 5916 | 2425 | 6515 | 10.736 | 8743 | 12.713 | 18,145 |
| Canterbury corpus | ||||||||||
| alice29.txt | 152,089 | 74 | 4.568 | 6649 | 5903 | 24,825 | 11.767 | 36,516 | 11.573 | 46,135 |
| asyoulik.txt | 125,179 | 68 | 4.808 | 5804 | 5220 | 23,359 | 11.563 | 33,764 | 11.018 | 41,758 |
| bible.txt | 4,047,392 | 63 | 4.343 | 77,117 | 66,593 | 386,092 | 14.649 | 706,991 | 14.543 | 847,187 |
| cp.html | 24,603 | 86 | 5.229 | 1748 | 1212 | 4313 | 9.462 | 5101 | 10.897 | 7482 |
| E.coli | 4,638,690 | 4 | 2.000 | 66,995 | 62,463 | 652,663 | 13.717 | 1,119,067 | 7.667 | 1,183,281 |
| fields.c | 11,150 | 90 | 5.008 | 868 | 587 | 1606 | 8.724 | 1751 | 11.013 | 2946 |
| kennedy.xls | 1,029,744 | 256 | 3.573 | 2612 | 2511 | 159,999 | 10.012 | 200,240 | 8.575 | 203,040 |
| lcet10.txt | 426,754 | 84 | 4.669 | 14,506 | 12,178 | 54,937 | 12.661 | 86,941 | 12.462 | 109,539 |
| ptt5 | 513,216 | 159 | 1.210 | 23,203 | 6314 | 94,463 | 4.566 | 53,918 | 12.308 | 89,618 |
| random.txt | 100,000 | 64 | 5.999 | 5145 | 5209 | 54,011 | 11.235 | 75,854 | 4.075 | 78,475 |
| sum | 38,240 | 255 | 5.329 | 3130 | 1683 | 6245 | 10.034 | 7833 | 12.184 | 12,600 |
| world192.txt | 2,473,400 | 94 | 4.998 | 54,946 | 45,920 | 212,499 | 14.340 | 380,896 | 14.078 | 477,588 |
| xargs.1 | 4227 | 74 | 4.898 | 342 | 326 | 1235 | 7.755 | 1197 | 9.988 | 1624 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vasinek, M.; Platos, J. Prediction and Evaluation of Zero Order Entropy Changes in Grammar-Based Codes. Entropy 2017, 19, 223. https://doi.org/10.3390/e19050223
Vasinek M, Platos J. Prediction and Evaluation of Zero Order Entropy Changes in Grammar-Based Codes. Entropy. 2017; 19(5):223. https://doi.org/10.3390/e19050223
Chicago/Turabian StyleVasinek, Michal, and Jan Platos. 2017. "Prediction and Evaluation of Zero Order Entropy Changes in Grammar-Based Codes" Entropy 19, no. 5: 223. https://doi.org/10.3390/e19050223
APA StyleVasinek, M., & Platos, J. (2017). Prediction and Evaluation of Zero Order Entropy Changes in Grammar-Based Codes. Entropy, 19(5), 223. https://doi.org/10.3390/e19050223