1. Introduction
One of the central problems in coding theory deals with determining upper and lower bounds on the probability of error when communication over a given channel is attempted at some rate
R. The capacity of the channel
C is defined as the highest rate at which communication is possible with probability of error that vanishes as the blocklength of the code grows to infinity (see [
1,
2,
3]). At rates
, it is known that the probability of error vanishes exponentially fast in the blocklength, and a classic problem in information theory is the determination of that exponential speed or, as is it customary to say, of the error exponent. This problem was dealt with in the classical setting back in the 1960s, when most of the still strongest results were obtained [
4,
5,
6,
7,
8]. Instead, for classical-quantum channels, the topic is relatively more recent; first results were obtained around 1998 ([
9,
10]) and new ones are still in progress.
An important bound on error exponents is the so-called sphere packing bound, a fundamental lower bound on the probability of error of optimal codes and hence an upper bound on achievable error exponents. This particular result was first derived in different forms in the 1960s for classical channels (of different types) and more recently in [
11,
12,
13] for classical-quantum channels. The aim of this paper is to present a detailed and self-contained discussion of the differences between the classical and classical-quantum settings, pointing out connections with an important open problem first suggested by Holevo in [
10] and possibly with recent results derived by Mosonyi and Ogawa in [
14].
2. The Problem
We consider a classical-quantum channel with finite input alphabet
and associated density operators
,
, in a finite dimensional Hilbert space
. The
n-fold product channel acts in the tensor product space
of
n copies of
. To a sequence
, we associate the signal state
. A block code with
M codewords is a mapping from a set of
M messages
into a set of
M codewords
, and the rate of the code is
. A quantum decision scheme for such a code, or Positive-Operator Valued Measure (POVM), is a collection of
M positive operators
such that
, where
I is the identity operator. The probability that message
is decoded when message
m is transmitted is
and the probability of error after sending message
m is
The maximum error probability of the code is defined as the largest
; that is,
When all the operators commute, the channel is classical and we will use the classical notation to indicate the eigenvalues of the operators, which are the transition probabilities from inputs x to outputs . Similarly, will represent the transition probabilities from input sequences to output sequences . In the classical case, it can be proved that optimal decision schemes can always be assumed to have separable measurements which commute with the states. Hence, we will use the classical notation in place of , where is the decoding region for message m.
Let
be the smallest maximum error probability among all codes of length
n and rate at least
R. We define the reliability function of the channel as
In this paper, we focus on the so-called sphere packing upper bound on
, which states that
where
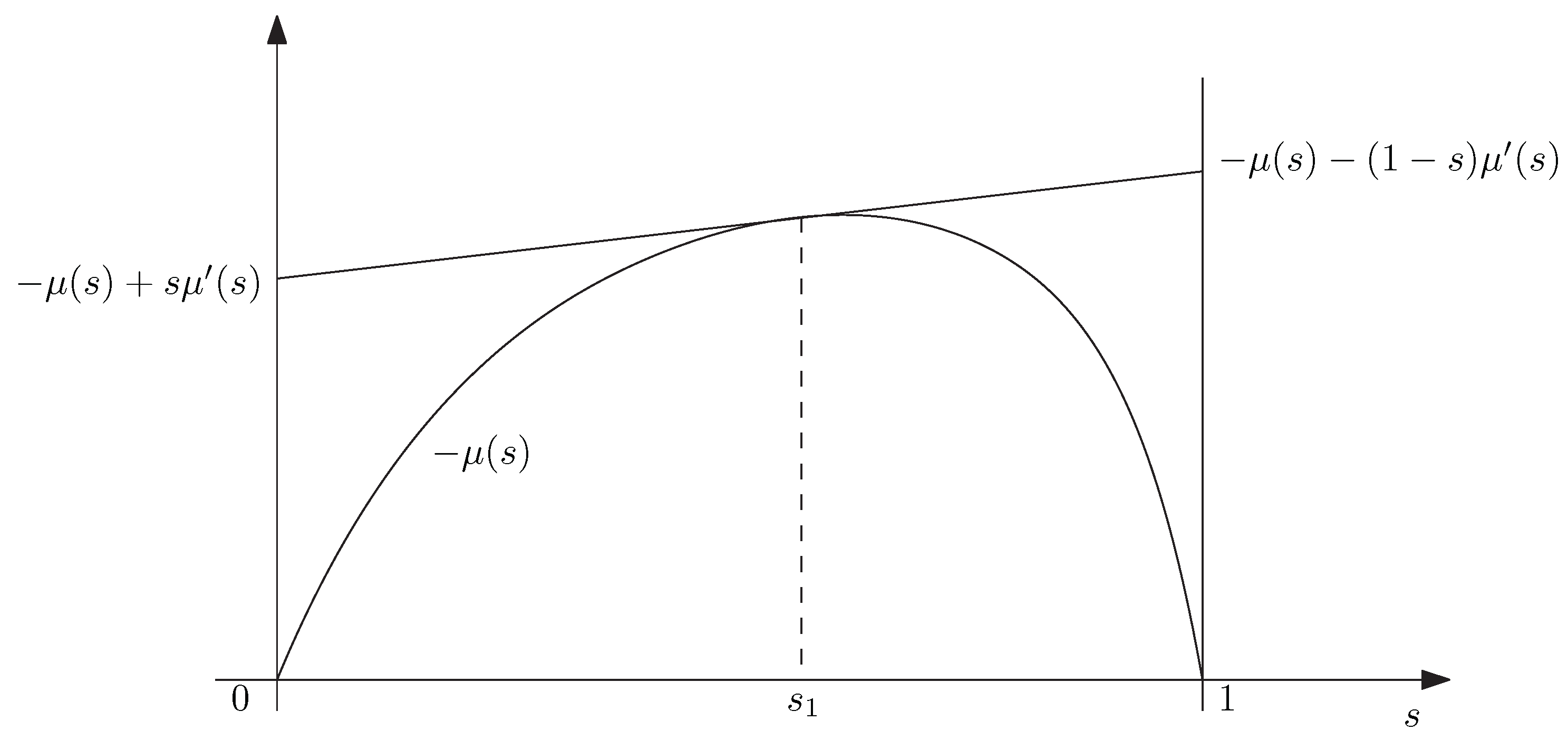
and
the minimum being over density operators
Q. Here
is an upper bound on the error exponent achievable by so-called constant composition codes; that is, such that in each codeword symbols appear with empirical frequency
P. For classical channels,
is written in the standard notation as
4. Classical Sphere-Packing Bound
Two proofs are known for the classical version of the bound, which naturally lead to two equivalent yet different analytical expressions for the function
. The first was developed at the Massachusetts Institute of Technology (MIT) ([
5,
7]) while the other is due to Haroutunian [
16,
17]. A preliminary technical feature common to both procedures is that they both focus on some constant-composition sub-code which has virtually the same rate as the original code, but where all codewords have the same empirical composition
P. In both cases, then, the key ingredient is binary hypothesis testing (BHT).
4.1. The MIT Proof
The first proof (see [
5,
7]) is based on a binary hypothesis test between the output distributions
induced by the codewords
and an auxiliary output product distribution
on
. Let
be the decision region for message
m. Since
is a distribution, for at least one
m, we have
Considering a binary hypothesis test between
and
, with
as decision region for
, Equation (
26) gives an exponential upper bound on the probability of error under hypothesis
, which implies a lower bound on the probability of error under hypothesis
, which is
, the probability of error for message
m. Here the BHT is considered in the regime where both probabilities decrease exponentially. The standard procedure uses the first form of the bound mentioned in the previous section based on the Rényi divergence. The bound can be extended to the case of testing products of non-identical distributions; for the pair of distributions
and
, it gives the performance of an optimal test in the form
where now
At this point, the arguments in [
5,
7] diverge a bit; while the former is not rigorous, it has the advantage of giving the tight bound for the arbitrary codeword composition
P. The latter is instead rigorous, but only gives the tight bound for the optimal composition
P. In [
13], we proposed a variation which we believe to be rigorous and that at the same time gives the tight bound for an arbitrary composition
P. The need for this variation will be clear in the discussion of classical-quantum channels in the next section.
For the test based on the decoding region
, the left hand side of (29) is lower-bounded by
R due to (
26). So, if we choose
s and
Q in such a way that the right hand side of (29) is roughly
, then
must be smaller than the right hand side of (
28) computed for those same
s and
Q (for otherwise the decision region
would give a test strictly better than the optimal one). This is obtained by choosing
Q, as a function of
s, as the minimizer of
and then selecting
s which makes the right hand side of (29) equal to
(whenever possible). Extracting
from (29) in terms of
and
R and using it in (
28), the probability of error for message
m is bounded in terms of
R. After some tedious technicalities, cf. [
13] (Appendix A), we get
where
the minimum being over distributions
Q and
being the
-mutual information as defined by Csiszár [
18]. We thus find the bound, valid for codes with constant composition
PIt is worth pointing out that the chosen
Q, which achieves the minimum in the definition of
, satisfies the constraint (cf. [
5] (Equations (9.23), (9.24), and (9.50)), [
19] (Corollary 3))
where we define
as
note the analogy with the definition of
in (
11). So, the chosen
Q is such that its tilted mixtures with the distributions
induce
Q itself on the output set
. Using the second representation of the error exponents in binary hypothesis testing mentioned in
Section 3.1 (extended for independent extractions from non-identical distributions), we observe thus that the chosen
Q induces the construction of an auxiliary channel
V such that the induced mutual information with input distribution
P, say
, equals
. The second proof of the sphere packing bound, which is summarized in the next section, takes this line of reasoning as a starting point.
4.2. Haroutunian’s Proof
In the second proof (see [
16,
17]), one considers the performance of the given coding scheme for channel
W when used for an auxiliary channel
V with same input and output sets such that
. The converse to the coding theorem implies that the probability of error for channel
V is bounded away from zero at rate
R, which means that there exists a fixed
such that for any blocklength
n,
for at least one
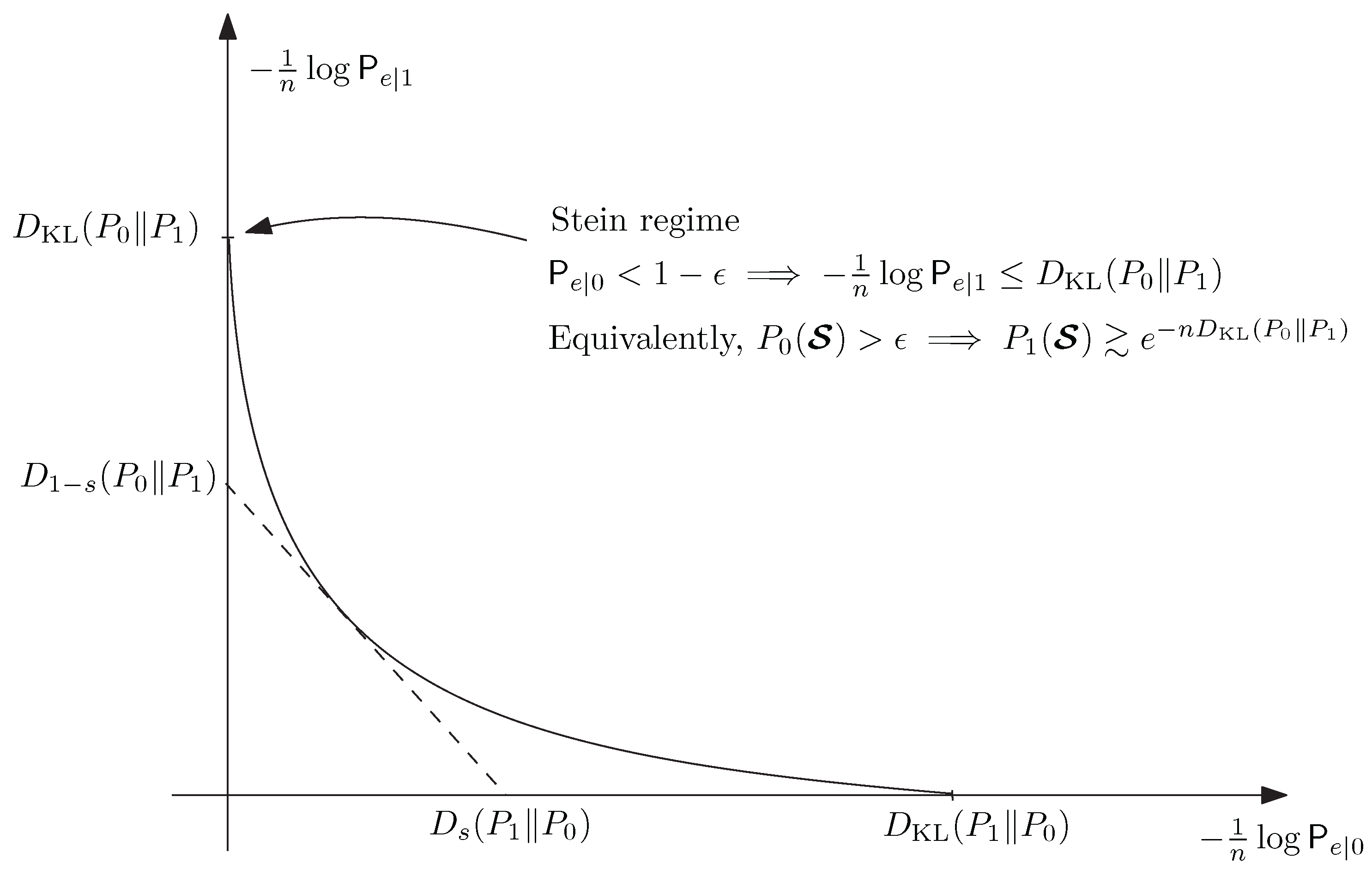
m. Using the Stein lemma mentioned before, we deduce that
where now
After optimization over
V, we deduce that the error exponent for channel
W is bounded as
We observe that a slightly different presentation (e.g., [
17]) avoids the use of the Stein lemma by resorting to the strong converse rather than a weak converse. Indeed, for channel
V, the coding scheme will actually incur an error probability
, which means that for at least one codeword
m we must have
. Applying the data processing inequality for the Kullback–Leibler divergence, one thus finds that
from which
So, strong converse can be traded for Stein’s lemma, and this fact (which appears as a detail here) will be seen to be related to a less trivial question.
The bound derived is precisely the same as in the previous section, and for the optimal choice of the channel
V, if we define the output distribution
as in (
36), then (
37) is satisfied for some
s (see Equation (
19) in [
16]). So, we notice that the two proofs actually rely on a comparison between the original channel and equivalent auxiliary channels/distributions. In the first procedure, we start with an auxiliary distribution
Q, but we find that the optimal choice of
Q is such that the tilted mixtures with the
distributions are the
which give
. In the second procedure, we start with the auxiliary channel
V, but we find that the optimal
V induces an output distribution
Q whose tilted mixtures with the
are the
themselves. It is worth noting that in this second procedure we use a converse for channel
V; hidden in this step we are using the output distribution
Q induced by
V, which we directly use for
W in the MIT approach.
These observations point out that while the MIT proof follows the first formulation of the binary hypothesis testing bound in terms of Rényi divergences, Haroutunian’s proof exploits the second formulation based on Kullback–Leiblrer divergences, but the compared quantities are equivalent. There seems to be no reason to prefer the first procedure given the simplicity of the second one.
5. Classical-Quantum Sphere-Packing Bound
The different behavior of binary hypothesis testing in the quantum case with respect to the classical has a direct impact on the sphere packing bound for classical-quantum channels. Both the MIT and Haroutunian’s approaches can be extended to this setting, but the resulting bounds are different. In particular, since the binary hypothesis testing is correctly handled with the Rényi divergence formulation, the MIT form of the bound extends to what one expects as the right generalization (in particular, it matches known achievability bounds for pure-state channels), while Haroutunian’s form extends to a weaker bound. It was already observed in [
20] that the latter gives a trivial bound for all pure state channels, which is a direct consequence of what has already been shown for the simple binary hypothesis testing in the previous section.
It is useful to investigate this weakness at a deeper level in order to clearly see where the problem truly is. Let now
,
be general non-commuting density operators, the states of the channel to be studied. Consider then an auxiliary classical-quantum channel with states
and with capacity
. Again, the converse to the channel coding theorem holds for channel
V, which implies that for any decoding rule, for at least one message the probability of error is larger than some fixed positive constant
. In particular for the given POVM, for at least one
m,
Using the quantum Stein lemma, we deduce
and hence, again as in the classical case,
In this case as well, one can use a strong converse to replace the Stein lemma with a simpler data processing inequality.
The problem we encounter in this case is that if
W is a pure state channel, at rates
, any auxiliary channel
gives
, so that the bound is trivial for all pure state channels. It is important to observe that this is not due to a weakness in the use of the Stein lemma or of the data processing inequality. In a binary hypothesis test between the pure state
and a state
built from a different channel
V, one can notice that the POVM
with
satisfies
So, it is actually impossible to deduce a positive lower bound for using only the fact that is bounded away from zero, or even approaches one.
It is also worth checking what happens with the MIT procedure. All the steps can be extended to the classical-quantum case (see [
13] for details) leading to a bound which has the same form as (
31) where
is defined in analogy with (
32) as
the minimum being over all density operators
Q, and
being the quantum Rényi divergence. However, as far as we know there is no analog of Equations (
36) and (
37), and the optimizing
Q does not induce an auxiliary
V such that
.
6. Auxiliary Channels and Strong Converses
We have presented the two main approaches to sphere packing as different procedures which are equivalent in the classical case but not in the classical-quantum case. However, it is actually possible to consider the two approaches as particular instances of one general approach where the channel
W is compared to an auxiliary channel
V, since the auxiliary distribution/state
Q can be considered as a channel with constant
. This principle is very well described in [
21], where it is shown that essentially all known converse bounds in channel coding can be cast in this framework.
According to this interpretation, the starting point in Haroutunian’s proof is general enough to include the MIT approach as a special case. So, the weakness of the method in the classical-quantum case must be hidden in one of the intermediate steps. It is not difficult to notice that the key point is how the (possibly strong) converse is used in Haroutunian’s proof. The general auxiliary channel V is only assumed to have capacity , and the strongest possible converse for V which can used is of the simple form , which is good enough in the classical case. In the MIT proof, instead, the auxiliary channel is such that , so that the strong converse takes another simple form, . The critical point is that in the classical-quantum setting a converse of the form for V does not lead to a lower bound on for W in general. What is needed is a sufficiently fast exponential convergence to 1 of for channel V, which essentially suggests that V should be chosen with capacity not too close to R, and that the exact strong converse exponent for V should be used.
The natural question to ask at this point is what the optimal (here we mean optimal memoryless channel for bounding the error exponent in the asymptotic regime) auxiliary channel is when the exact exponent of the strong converse is used. At high rates, the question is not really meaningful for all those cases where the known versions of the sphere packing bound coincide with achievability results; that is, for classical channels and for pure state channels [
9]. However, in the remaining cases (i.e., in the low rate region for the mentioned channels or in the whole range of rates
for general non-commuting mixed-state channels), the question is legitimate. In the classical case, since the choice of an (optimal) auxiliary channel with
or
leads to the same result, one might expect that any other intermediate choice would give the same result. This can be indeed be proved by noticing that any version of the sphere packing derived with the considered scheme, independently of the used auxiliary channel, will always hold also when list decoding is considered for any fixed list-size
L (see [
7] for details or notice that the converse to the coding theorem for
V would also hold in this setting). Since the bound obtained with the mentioned choices of auxiliary
Q and
V is achievable at any rate
R when list-size decoding is used with sufficiently large list-size
L (see [
3] (Prob. 5.20)), no other auxiliary channel can give a better bound.
For classical-quantum channels, instead, the question is perhaps not trivial; it is worth pointing out that even the exact strong converse exponent has been determined only very recently [
14]. What is very interesting is that while in the classical case the strong converse exponent for
is expressed in terms of Rényi divergence [
22,
23] ( similarly as error exponents for
), for classical-quantum channels, the strong converse exponents are expressed in terms of the so-called “sandwiched” Rényi divergence defined by
The problem to study would thus be more or less as follows: Consider an auxiliary channel V with capacity and evaluate its strong converse exponent in terms of sandwiched Rényi divergences. Fix this exponent as the probability of error under hypothesis in a test between and , where is the operator in favor of and is the one in favor of . Then, deduce a lower bound for the probability of error under hypothesis using the standard binary hypothesis testing bound in terms of Rényi divergences. It is not entirely clear to this author that the optimal auxiliary channel should necessarily always be one such that , as used up to now. Since for non-commuting mixed-state channels the current known form of sphere packing bound is not yet matched by any achievability result, one cannot exclude the possibility that it is not the tightest possible form.


{kind=link}
{kind=link}

