1. Introduction
As EEG signals can reflect the instant state of the brain, it is an excellent method to evaluate the state and function of the brain, and is often used to assist in the diagnosis of stroke, epilepsy, and seizure. Various computational methods based on EEG signals have been developed for the analysis and detection of driver fatigue.
Correa et al. [
1] developed an automatic method to detect the drowsiness stage in EEG signals using 19 features and a Neural Network classifier, and obtained an accuracy of 83.6% for drowsiness detections. Mu et al. [
2] employed fuzzy entropy for feature extraction and an SVM classifier to achieve an average accuracy of 85%. Other results from their study showed that four feature sets (SE, AE, PE, and FE) and SVM were proposed, with an average accuracy of 98.75% [
3]. Fu et al. [
4] proposed a fatigue detection model based on the Hidden Markov Model (HMM), and achieved a highest accuracy of 92.5% based on EEG signals and other physiological signals. Li et al. [
5] collected 16 channels of EEG data and computed 12 types of energy parameters, and achieved a highest accuracy of 91.5%. Xiong et al. [
6] combined features of AE and SE with an SVM classifier and achieved a highest accuracy of 91.3%. Chai et al. [
7] presented an autoregressive (AR) model for features extraction and a Bayesian neural network for the classification algorithm, and achieved an accuracy of 88.2%. In another study, Chai et al. [
8] employed AR modeling and sparse-deep belief networks to yield an accuracy of 90.6%. Chai et al. [
9] also explored power spectral density (PSD) as a feature extractor and fuzzy swarm based-artificial neural network (ANN) as a classifier, achieving an accuracy of 78.88%. Wu et al. [
10] proposed an online weighted adaptation regularization for a regression algorithm which could significantly improve performance. Huang’s [
11] results validated the efficacy of this online closed-loop EEG-based fatigue detection.
With respect to driver fatigue detection based on EEG signals, the performance of many linear and nonlinear single classifiers has already been assessed, such as the Fisher discriminant analysis, DT, SVM, KNN, Neural Network, and Hidden Markov Model. However, it may be difficult to build an excellent single classifier as EEG signals are unstable and the training set is usually comparatively small. Consequently, single classifiers may have a poor performance or be unstable. Recent studies have shown that ensemble classifiers perform better than single classifiers [
12,
13,
14,
15]; however, few studies have been conducted for using ensemble classifiers based on EEG signals to study driver fatigue detection. Hassan and Bhuiyan [
12] proposed an EEG based method for sleep staging using Complete Ensemble Empirical Mode Decomposition with Adaptive Noise and Bootstrap Aggregating (Bagging), and their results showed that the proposed method was superior when compared to the state-of-the-art methods in terms of accuracy. Furthermore, Hassan and Subasi [
13] implemented linear programming Boosting to perform seizure detection, which performed better than the existing works. Sun et al. [
14] evaluated the performance of the three ensemble methods for EEG signal classification of mental imagery tasks with the base classifiers of KNN, DT, and SVM, where their results suggested the feasibilities of ensemble classification methods. Finally, Yang et al. [
15] proposed a gradient Boosting decision tree (GBDT) to classify aEEG tracings.
It is well known that EEG signals are non-stationary. The non-stationary signals can be observed during the change in eye blinking, event-related potential (ERP), and evoked potential [
16]. Unfortunately, EEG recordings are often contaminated by different forms of noises, such as noises due to electrode displacement, motion, ocular activity, and muscle activity. These offending noises not only misinterpret underlying neural information processing, but may also themselves be difficult to identify [
17]. This is one of the major obstacles in EEG signal classification, thus, a classifier optimized for one set of training EEG data may not work with another set of test EEG data. The variety of artifacts and their overlap with signals of interest in both the spectral and temporal domains, and even sometimes in the spatial domain, makes it difficult for a simple signal preprocessing technique to identify them from the EEG. Therefore, the use of simple filtering or amplitude thresholds to remove artifacts often results in poor performance both in terms of signal distortion and artifact removal. Thus, many methods and algorithms have been developed for artifact detection and removal from EEG signals [
18,
19]; however, some noise removal methods may also weaken features. Our question was to ask if there was a feature extraction method or algorithm that did not need to remove noise, and was insensitive to noise. Thus, this method could improve classification performance, reduce computational complexity and avoid new noise.
Recently, entropy has been broadly applied in the analysis of EEG signals as EEG is a complex, unstable, and non-linear signal [
20,
21]. A diverse collection of these methods has been proposed in the last few decades, including spectral entropy (PE), permutation entropy, distribution entropy, fuzzy entropy (FE), Renyi entropy, approximate entropy (AE), sample entropy (SE) and others. Specifically in the field of EEG processing, four of the most widely used and successful entropy estimators are FE [
22], AE [
23], and SE [
24]. AE has demonstrated its capability to detect complex changes; SE is a similar statistic, but has not yet been used as extensively as AE. AE and SE are very successful data entropy estimators, but they also have their weaknesses. AE is biased since it includes self-matches in the count, and SE requires a relatively large r to find similar subsequences and to avoid the log(0) problem. They are also very sensitive to input parameters m, r, and N [
25]. More recently, FE has been proposed to alleviate these problems. FE is based on a continuous function to compute the dissimilarity between two zero-mean subsequences and, consequently, is more stable in noise and parameter initialization terms. These metrics is still scarcely used in EEG studies, but are expected to replace AE and SE because of their excellent stability, mainly when applied to noisy or short records.
Given the non-stationary characteristics of EEG signals, we have observed that the optimal detection performance varied as a result of the classifiers or feature sets, which is a major obstacle in EEG signal classification. Thus, a classifier optimized for a particular set of training data may not work well for driver fatigue detection with new data.
Investigating the ability of feature sets and classifiers to evaluate the performance of a detection system in the presence of noise is an important area of investigation as the real EEG signal is seldom noise free. However, how the addition of simulated noise can cause changes in the driver fatigue detection performance for various classifiers or various feature sets has yet to be sufficiently studied. Furthermore, research involving noise robustness analysis to evaluate for the driver fatigue detection performance of the EEG signals in the presence of noise by various feature sets and various classifiers has not been addressed. In general, systematic study investigating the effects of simulated noise on driver fatigue detection systems and the ability of such measures to evaluate the detection systems under simulated Gaussian noise is missing. To the best of our knowledge, our study is one of the first to apply the noise robustness analysis method on EEG signals for driver fatigue detection.
In this study, our aim was to evaluate the robustness of various classifiers and feature sets for driver fatigue detection systems under simulated Gaussian noise. Four types of entropy were deployed as feature sets in this work: FE, SE, AE, and PE. The classification procedure was implemented by three base classifiers: KNN, SVM, and DT, which have been known as state-of-the-art classification methods in many studies. The ensemble classifiers were developed by two ensemble methods: Bagging and Boosting. The challenge was to analyze the impacts of noise on detection performance with four feature sets and five classification methods.
First, with simulated Gaussian noise, we compared the detection performance, i.e., the average accuracy of DT, SVM, and KNN methods. Second, we evaluated the noise robustness of these methods. The noisy EEG signals were generated with the addition of random Gaussian noise into the original EEG signal. Then, we assessed the noise robustness of these methods. Third, in addition to the base classifiers, we examined the effects of the Bagging and Boosting ensemble methods. Moreover, we repeated these analyses with simulated spike noise and simulated EMG noise. This paper is organized as follows: in
Section 2, the experiment and EEG signal processing methods such as acquisition, preprocessing, segment, feature extraction and classification are described. In addition, noise generation is explained in this section.
Section 3 shows the experimental results and discussion. Finally, we conclude this paper in
Section 4.
2. Materials and Methods
Figure 1 shows the workflow of this paper, including EEG acquisition, preprocessing, segment, feature extraction, noise generation, classification, and performance analysis.
2.1. Subjects
Twenty-two university students (14 male, 19–24 years) participated in this experiment. All subjects were asked to be abstain from any type of stimulus like alcohol, medicine, or tea before and during the experiment. Before the experiment, subjects practiced the driving task for several min to become acquainted with the experimental procedures and purposes. This work was approved by all subjects, and the experiments was authorized by the Academic Ethics Committee of the Jiangxi University of Technology. The subjects provided their written informed consent as per human research protocol in this study. Furthermore, all subjects provided their written informed consent as per human research protocol in this study.
2.2. Experimental Paradigm
The driving fatigue simulation experiment was performed by each subject on a static driving simulator (The ZY-31D car driving simulator, produced by Peking ZhongYu CO., LTD, Beijing, China), as shown in
Figure 2. On the screen, a customized version of the Peking ZIGUANGJIYE software ZG-601 (Car driving simulation teaching system, V9.2) was shown.
This equipment was an analog form of a real driving car, which contained all the driving capabilities of a vehicle. Using computer software technology, different driving environments could be constructed, such as sunny, foggy or snowy weather and mountain, highway, and countryside areas. The driving environment selected for this experiment was a highway with low traffic density that could more easily induce monotonous driving. Some research has suggested that the brain in this driving environment is more easily turned into a state of fatigue and the EEG signal was more stable, therefore benefiting our next data recording. All subjects in this experiment had an approximate real driving experience.
2.3. Data Acquisition and Preprocessing
In summary, the total duration of the experiment was 40–130 min. The first step was to become familiar with the simulating software, followed by continuous monotonous driving until driver fatigue was determined and the experiment terminated.
When the driving lasted 10 min, the last 5 min of the EEG signals were recorded as the normal state. When the continuous driving lasted 30–120 min (until the self-reported fatigue questionnaire results showed the subject was in driving fatigue), obeying Borg’s fatigue scale and Lee’s subjective fatigue scale, the last 5 min of the EEG signals were labeled as the fatigue state. EOG was also used to analyze eye blink patterns as an objective part of the validation of the fatigue state. It should be noted that the validation of the fatigue condition was also based on a self-reported fatigue questionnaire as per Borg’s fatigue scale and Lee’s subjective fatigue scale [
26,
27]. This method of using a questionnaire to identify the fatigue condition has not only been used in our study, but also in many other studies [
2,
3]. The drivers were required to complete all tasks and ensure safe driving. Prior to the experiment, the drivers familiarized themselves with the driving simulator and the completion of the driving tasks.
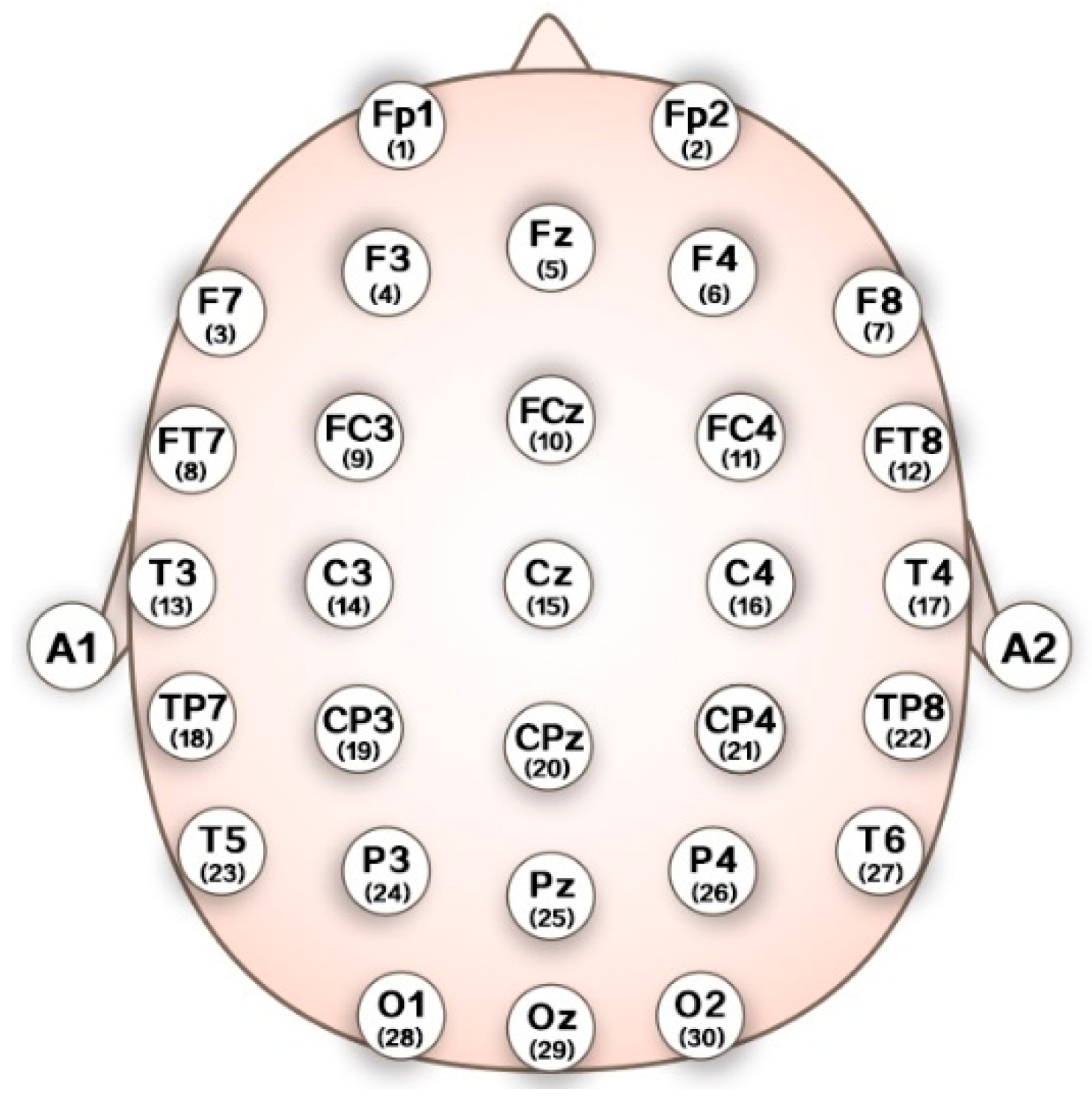
All channel data were referenced to two electrically linked mastoids at A1 and A2, digitized at 1000 Hz from a 32-channel electrode cap (including 30 effective channels and two reference channels) based on the International 10–20 system (
Figure 3) and stored in a computer for offline analysis. Eye movements and blinks were monitored by recording the horizontal and vertical EOG.
After the acquisition of EEG signals, the main steps of data preprocessing were carried out by using the Scan 4.3 software of Neuroscan (Compumedics, Australia). The raw signals were first filtered by a 50 Hz notch filter and a 0.15–45 Hz band-pass filter was used. Next, 5-min EEG signals from 30 channels were sectioned into 1-s epochs, resulting in 300 epochs. With 22 subjects, a total of 6600 epochs (792,000 units for 30 channels and 4 feature sets) of dataset was randomly formed for the normal state and another 6600 epochs (792,000 units for 30 channels and 4 feature sets) for the fatigue state.
2.4. Feature Extraction
As the EEG signal is assumed to be a non-stationary time series and most feature extraction methods are only applicable to stationary signal, in this study, to deal with this problem, the EEG time series was divided into many short windows and its statistics were assumed to be approximately stationary within each window. The following feature extraction methods were applied to each 1 s windowed signal. EEG signals were segmented without overlap, and finally feature sets were extracted from all channels in each 1 s window.
The ability to distinguish between the normal state and fatigue state depended mainly on the quality of input vectors of the classifier. To capture EEG characteristics, four feature sets including FE, SE, AE, and PE were calculated [
21,
22,
23,
24,
25]. In this section, methods for the calculation of these feature sets on EEG recordings are described in detailed.
2.4.1. Spectral Entropy (PE)
PE was evaluated using the normalized Shannon entropy [
28], which quantifies the spectral complexity of the time series. The power level of the frequency component is denoted by
Yi and the normalization of the power
yi is performed as:
The spectral entropy of the time series is computed using the following formula:
2.4.2. Approximate Entropy (AE)
AE, as proposed by Pincus [
23], is a statistically quantified nonlinear dynamic parameter that measures the complexity of a time series. The procedure for the AE-based algorithm is described as follows:
Considering a time series t(i), a set of m-dimensional vectors are obtained as per the sequence order of t(i):
where
is the distance between two vectors
and
, defined as the maximum difference values between the corresponding elements of two vectors:
Define
as the number of vectors
that are similar to
, subject to the criterion of similarity
Define the function
as:
Set
m =
m + 1, and repeat Equations (1) to (3) to obtain
and
, then:
The approximate entropy can be expressed as:
2.4.3. Sample Entropy (SE)
The SE algorithm is like that of AE [
25,
29], and is a new measure of time series complexity proposed by Richman and Moorman [
24]. Equations (1) and (2) can be defined in the same way as the AE-based algorithm; other steps in the SE-based algorithm are described as follows:
Define
as the number of vectors
that are similar to
, subject to the criterion of similarity
Define the function
as:
Set m = m + 1, and repeat the above steps to obtain
and
, then
The sample entropy can be expressed as:
2.4.4. Fuzzy Entropy (FE)
To deal with some of the issues with sample entropy, Xiang et al. [
22] proposed the use of a fuzzy membership function in computing the vector similarity to replace the binary function in sample entropy algorithm, so that the entropy value as continuous and smooth. The procedure for the FE-based algorithm is described in detail as follows:
Set a L-point sample sequence: ;
The phase-space reconstruction is performed on
v(
i) as per the sequence order. The reconstructed vector can be written as:
where
, and
is the average value described as the following equation:
, the distance between two vectors
and
, is defined as the maximum difference in values between the corresponding elements of two vectors:
Based on the fuzzy membership function
, the similarity degree
between two vectors
and
is defined as:
where the fuzzy membership function
is an exponential function, while
n and
s are the gradient and width of the exponential function, respectively.
Define the function
:
Repeat the Equations (1) to (4) in the same manner. Define the function:
The fuzzy entropy can be expressed as:
In the above-mentioned four types of entropies, AE, SE and FE have variable parameters,
m and
r. In the present study,
m = 2 while
r = 0.2*SD, where SD denotes the standard deviation of the time series as per the literature [
3,
22,
25].
For optimizing detection quality, the feature sets were normalized for each subject and each channel by scaling between 0 and 1.
2.5. Classification
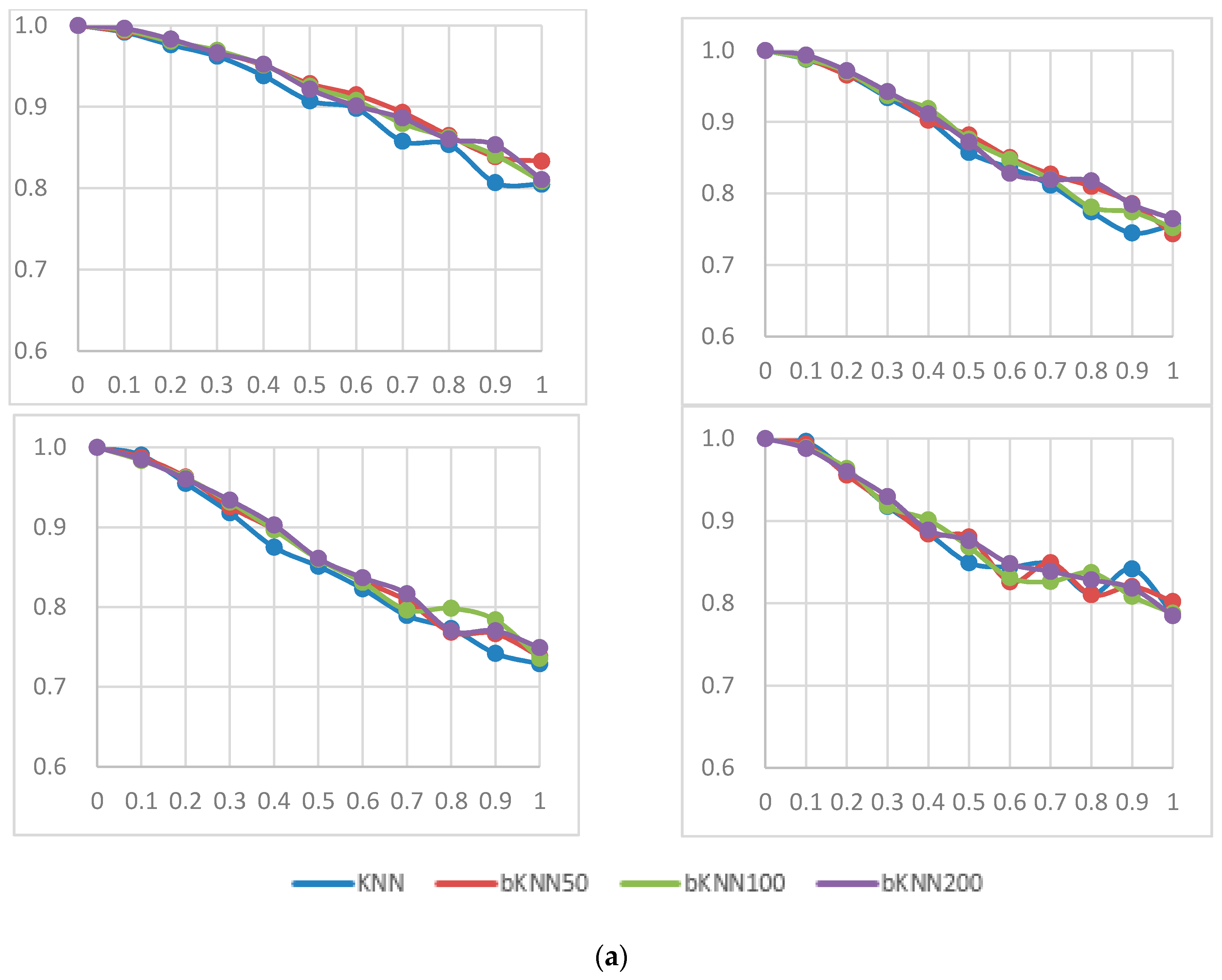
However, due to the lack of a substantial sample size, algorithms based on ensemble learning methods needed to evaluate the detection performance for driver fatigue. Bagging is an acronym of ‘‘bootstrap aggregating’’ [
30,
31], and builds several subsets and aggregates their individual predictions to form a final prediction. In the Bagging method, the number of base classifiers must be set. To investigate the impact of base classifier number on the classification result, we set the number of base classifiers as 50, 100, and 200, respectively. Like Bagging, Boosting also uses subsets to train classifiers, but not randomly [
32,
33,
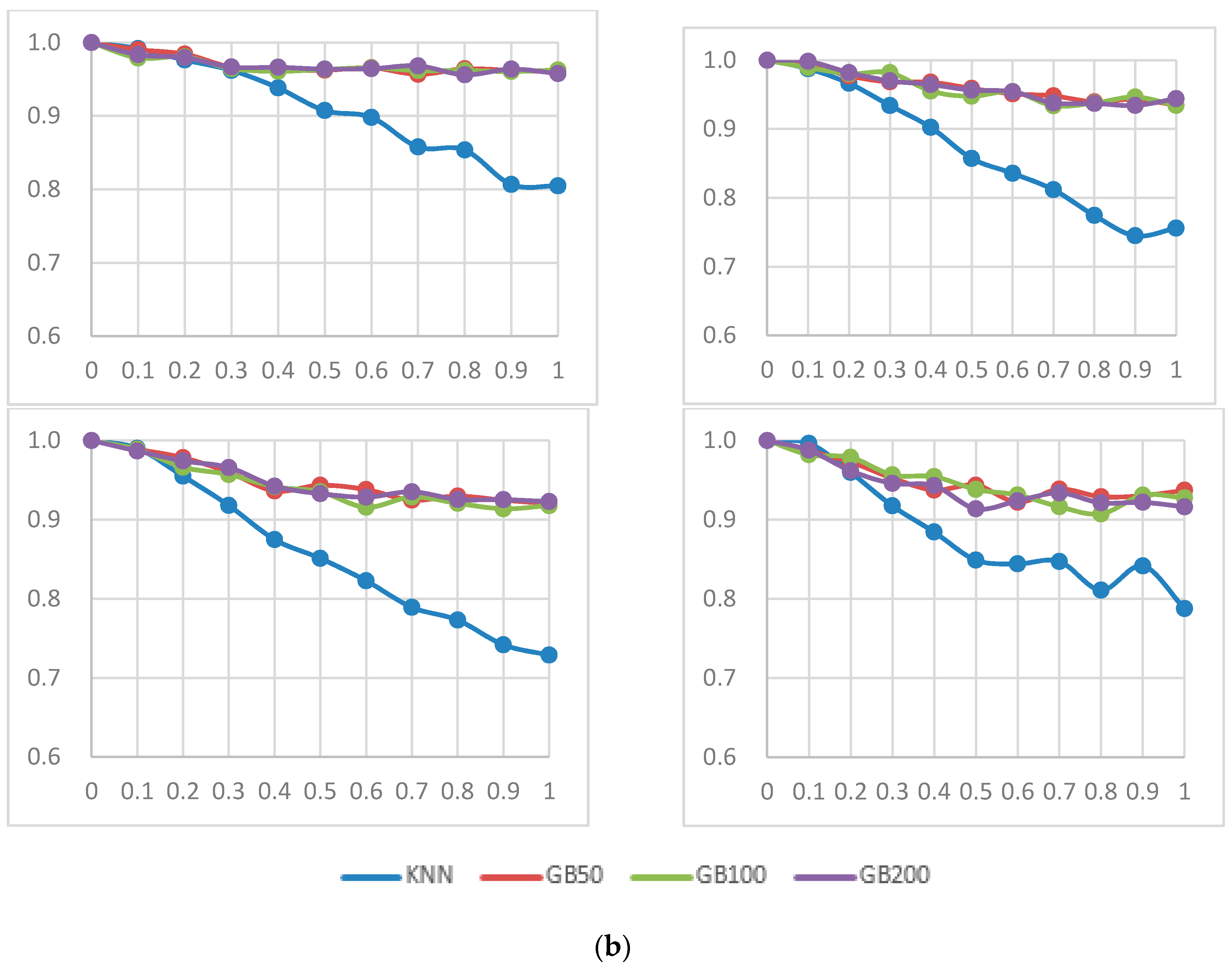
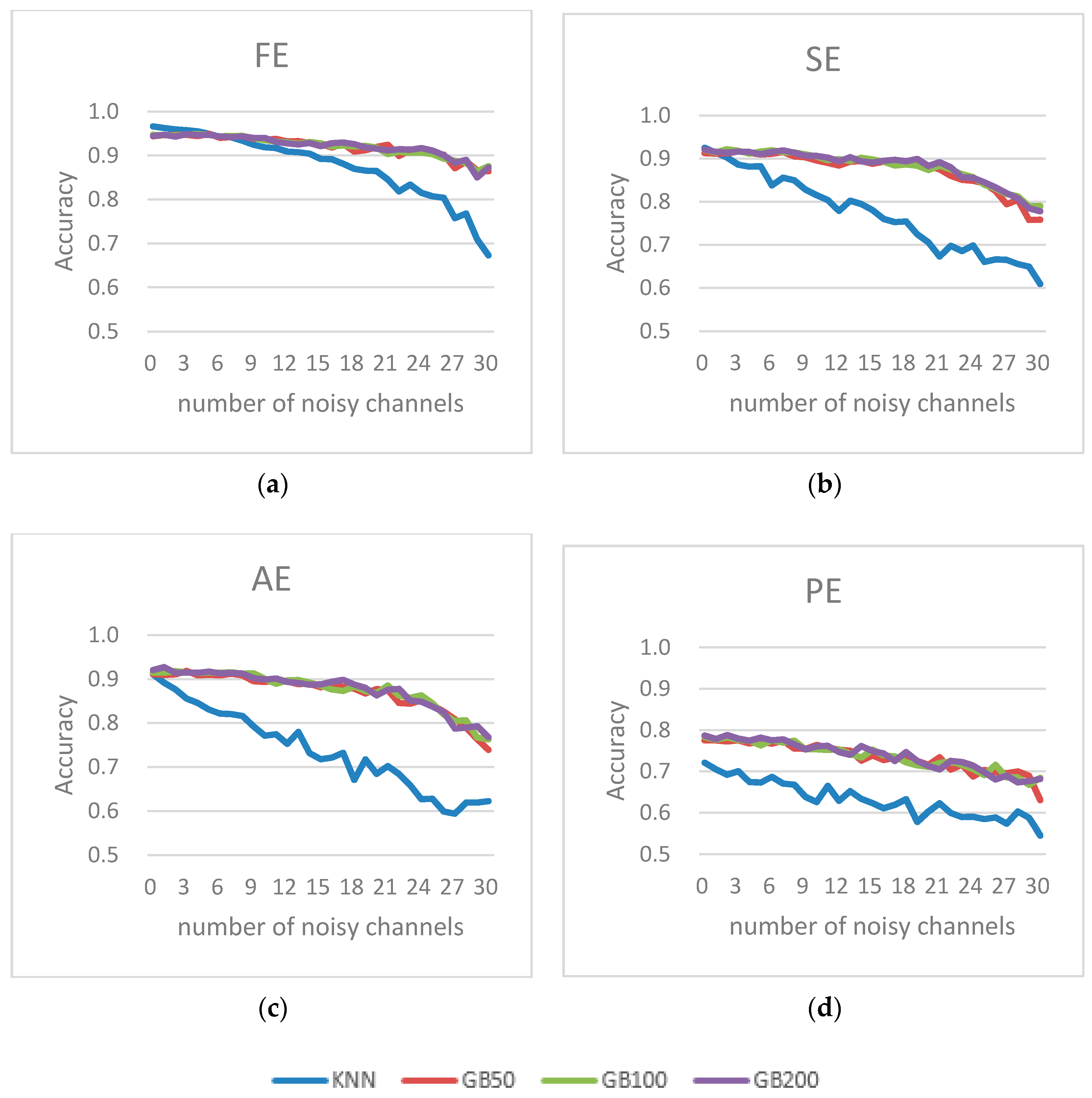
34]. In Boosting, difficult samples have higher probabilities of being selected for training, and easier samples have less chance of being used. In the Boosting method, the number of Boosting stages has to be set. To investigate the impact of the Boosting stage number on the classification result, we set the number of the Boosting stage to 50, 100, and 200, respectively.
The Bagging and Boosting methods both try to construct multiple classifiers by using different subsets. Bagging trains each classifier over a randomly selected subset, while the Boosting method trains each new classifier [
35].
Some classification models can fit data for a range of values of a parameter almost as efficiently as fitting the classifier for specific value of the parameters. This feature can be leveraged to perform a more efficient cross-validation for the selection of parameters. A high variance can lead to over-fitting in model selection, and hence poor performance, even when the number of hyper-parameters is relatively small [
36]. It seems likely that over-fitting during model selection can be overcome using various approaches. To overcome the bias in performance evaluation, parameter selection should be conducted independently in each trial to prevent selection bias and to reflect optimal performance. Performance evaluation based on these principles requires repeated training with different sets of hyper-parameter values on different samples of the available data, which makes it well-suited to parallel implementation. The magnitude of the bias deviations from full nested cross-validation can be introduced, which can easily swamp the difference in performance between the classifier systems.
To avoid the problem of over-fitting and to make general classifiers for other independent datasets, the datasets were separated into training sets and test sets in the following pattern. In the training phase, a 10-fold cross validation was applied on the features so that 10% of the feature vectors were dedicated as a test set and the other 90% of feature vectors were considered as the training set. In the next iteration, another 10% of the feature vectors were considered as a test set and the rest for the training set, until all the feature vectors had participated once in the test phase. The final result was achieved by averaging the outcome produced in the corresponding test repeated 10 times (for different subjects and different feature sets). Using this evaluation scheme, the dependency of the training and test features was removed, thus avoiding the over-fitting problem [
37,
38,
39,
40,
41,
42]. In particular, though GB is a more capable and practical boosting algorithm, like most other classifiers, GB also had the problem of over-fitting when dealing with very noisy data. To overcome such a problem, the validation sets were used to adjust the hypothesis of the Boost algorithm to improve generalization, thereby alleviating overfitting and improving performance, which have long been used in addressing the problem of overfitting with neural networks and decision trees [
43,
44]. Its basic concept is to apply the classifier to a set of instances distinct from the training set. Thus, the sequence of base classifiers produced by GB from the training set, also is applied to the validation set for alleviating overfitting problem.
For optimizing parameters, it is very important to obtain the optimum values for the classifier performance. Three widely used classifiers (KNN, SVM, and DT) were employed as classifiers in this work. To select optimal parameters of the model, this paper adopted the method of cross validation based on grid search, thus avoiding arbitrary and capricious behavior. Grid search is a model hyperparameter optimization technique. In this study, a grid parameter search was used to achieve optimal results. Related parameters in this study are as follows: penalty parameter, kernel and kernel coefficient for SVM, number of neighbors for KNN, the number of features, the maximum depth of the tree and the minimum number of samples for DT, the number of base estimators and the number of features for Bagging method, learning rate, the number of boosting stages and maximum depth for Boosting method.
2.6. Simulated Noise
The noises of the EEG signals included white noise, spike noise, muscular noise, ocular noise, and cardiac noise.
2.6.1. White Noise
White noise accounts for possible sources in real environments, such as thermal noise or electro-magnetic noise, which can be generated by a Gaussian random process. Spikes can be of sensor movement origin and the probability of appearance was kept relatively low in a real case. Muscular artifacts were drawn from electromyogram (EMG) signals. Ocular artifacts came from electrooculogram (EOG) signals. Cardiac artifacts were generated by heartbeat. In this paper, only white noise was considered for simplicity.
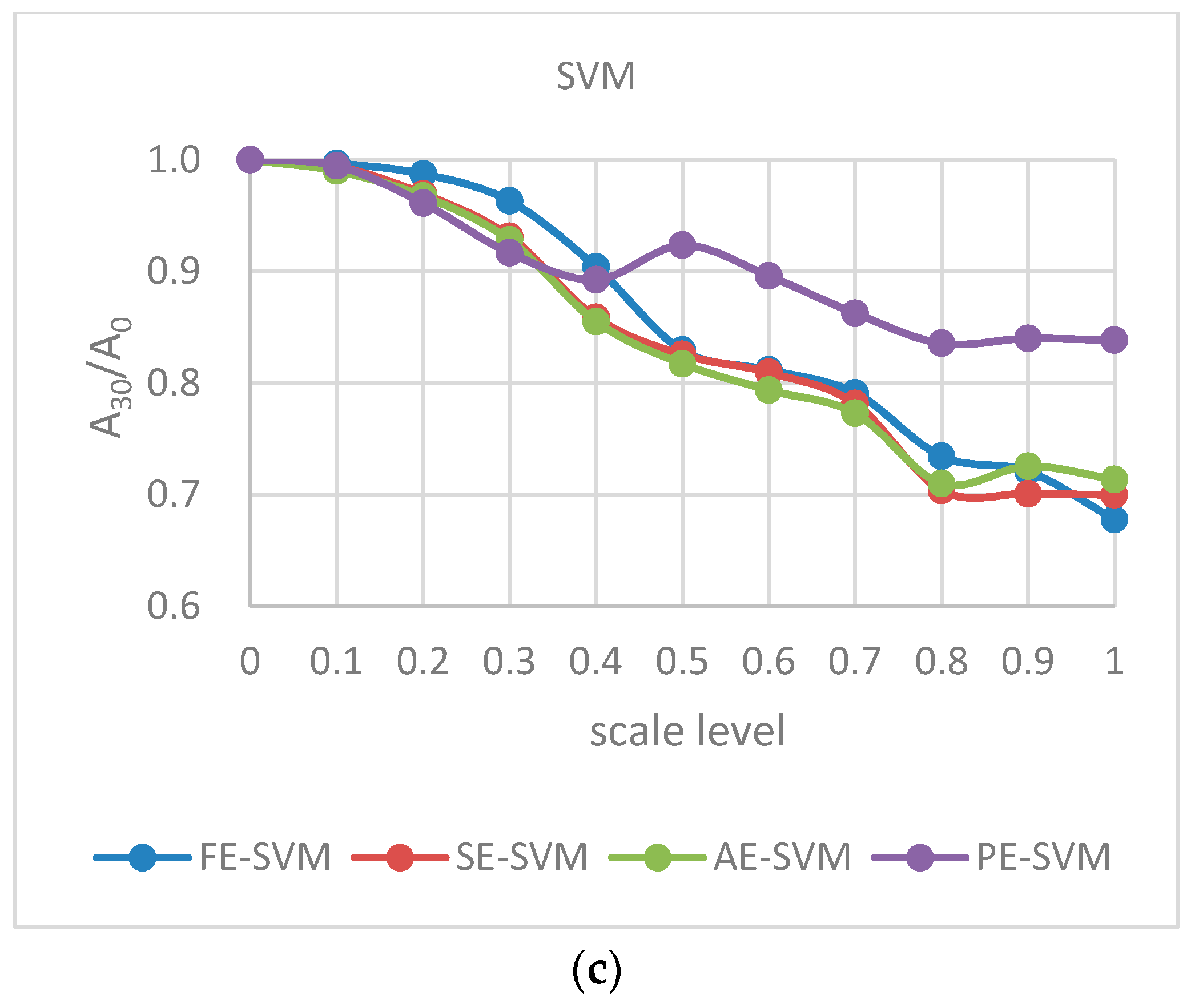
To analyze the influence of noise on detection performance, we built a simulated Gaussian noise
:
where
is the original EEG signal of channel I;
is the simulated Gaussian white noise; and
is the noisy EEG signal with simulated Gaussian white noise. We assumed that
and
were uncorrelated, and
∼D*N(0, 1). Here, D is defined as the level of noise given as a percentage of the average level of the noise-free data
.
Therefore, to evaluate the noise robustness of the classifiers systematically, we used scale factor D to control the noise power. To make polluted EEG data by Gaussian noise, we generated the same dimension of Gaussian noise to the segmented EEG signal, i.e., noise dimension was 1024 per second per channel.
2.6.2. Spike Noise
Spikes were synthetically generated as described in Reference [
45] and these interferences can be of a technological (sensor movement, electrical interferences) or physiological (mainly eye blinks) origin. The probability of appearance was kept relatively low (0.01), as to be expected in a real case. Duration was set at 1 sample and amplitude was set at 1.
2.6.3. Muscular Noise
Muscular noises were drawn from an actual long electromyogram (EMG) signal downloaded from PhysioNet [
46], which corresponded to a patient with myopathy. Data were acquired at 50 KHz and then down sampled to 1 KHz. For each run, an EMG epoch of length N was extracted from the entire record by commencing at a random sample. These noises accounted for muscular activity during EEG recording.
2.7. Performance Metrics
To estimate the potential application performance of a detector, it is very important to properly examine the detection quality. The total average accuracy based on a feature set and some classifiers was the average of the accuracy of all single channels based on the same feature and the same classifiers. The classification capabilities of different classifiers were comprehensively investigated with several indexes including Accuracy, Precision, Recall, F1-score, and the Matthews Correlation Coefficient (MCC) [
47]. These indexes are given as follows: Accuracy is the percentage of normal predictions corresponding to all samples; Precision is the percentage of normal predictions corresponding to the normal samples; and Recall is the percentage of fatigue predictions corresponding to the fatigue samples. Furthermore, the F1-score was used to appraise both Precision and Recall. The MCC was used as a measure of the quality of binary classifications as it considers true and false positives and negatives, and is generally regarded as a balanced measure which can be used even if the classes are of extremely different sizes. Therefore, a high Precision, Recall, F1-score, and MCC value relates to higher performance. The following equation set is used in the literature for examining performance quality:
The recall is intuitively the ability of the classifier to find all the positive samples.
The precision is intuitively the ability of the classifier not to label as positive a sample that is negative.
The F1 score can be interpreted as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0.
The Matthews correlation coefficient (MCC) is used in machine learning as a measure of the quality of two-class classifications. The MCC is a correlation coefficient value between −1 and +1.
where
TP (true positive) represents the number of normal signals identified as such;
TN (true negative), the number of fatigue signals classified as such;
FP (false positive), the number of fatigue signals recognized as such;
FN (false negative), the number of normal signals distinguished as fatigue signals.
To investigate differences in average accuracy among various classifiers and feature sets, the paired sample t-test was used to evaluate the effectiveness of each comparison. The results were averaged over ten independently drawn combinations in each experiment.
4. Conclusions
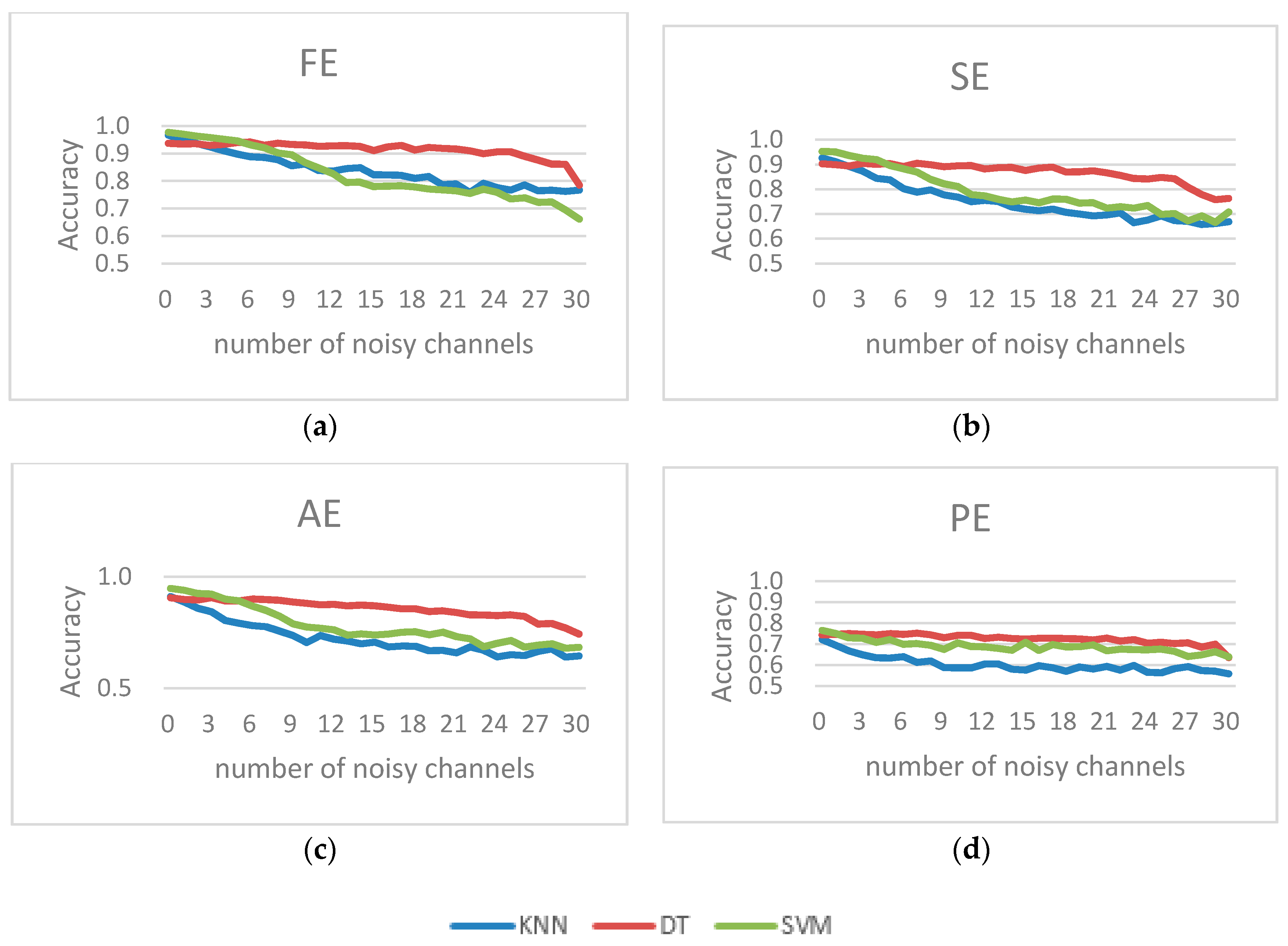
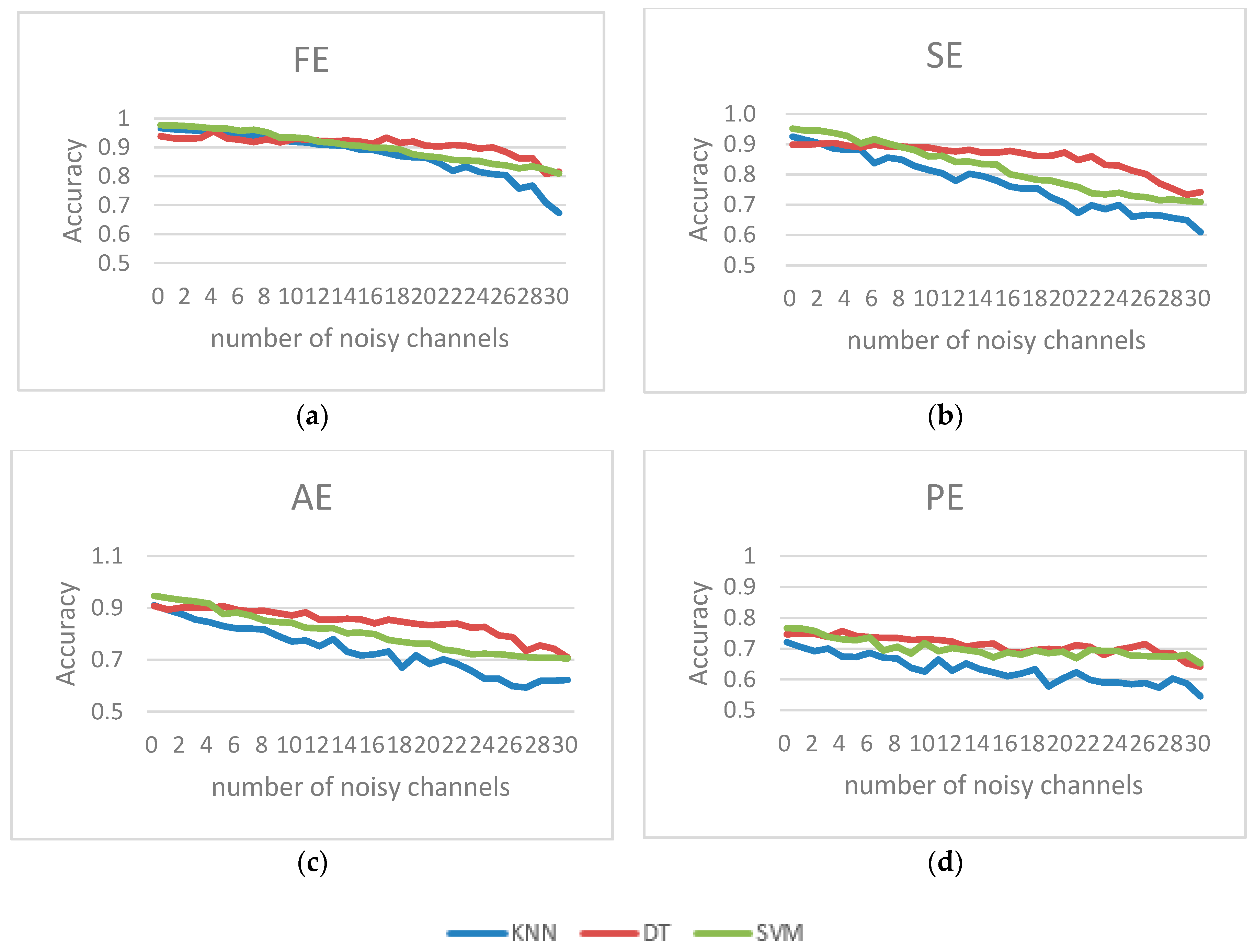
In this study, an approach based on simulated Gaussian noise was proposed to investigate the effect of different classifiers and four feature sets in detecting driver fatigue in an EEG-based system. For this purpose, we generated noise corrupted EEG signals using simulated Gaussian noise, Spike noise and simulated EMG noise. Next, we assessed the detection performance of various classifier methods with a varied number of noisy channels. Using the experimental driver fatigue based EEG and generated noisy signals, we compared the classification results of the DT, SVM, and KNN methods. From our results, it was evident that DT showed superior noise robustness than the SVM and KNN methods. Furthermore, the results showed that the classification accuracy of FE and the combined feature set were better than those of the other feature sets. It was also found that the Bagging method could not effectively improve performance with noise, while the Boosting method may have effectively improved performance with noise.
Practically, the proposed method may face more problems outside the EEG acquisition from the lab. One of the most important is the noise issue as there are many artifacts that may affect driving fatigue recognition. Currently, there has been some research focused on artifact removal methods prior to the feature extraction process, but these methods may also cause problems in the elimination of the artifacts, and also weaken the feature, such as the average method. In addition, it may lead to computational complexity and temporal extension, which is unfavorable in practical applications. This study revealed that the extraction method with an appropriate combination of entropy features (such as FE or combined feature sets) and classifier (such as DT or Boosting) could not only improve the recognition rate; but could weaken the noise impact on the recognition rate.
However, some limitations of this study are: (1) the number of subjects was relatively small. Although the existing literature suggests that 22 subjects is not too small a sample size, the number still needs to be increased; (2) Only three commonly used classifiers and the four feature sets were compared in this study; (3) For simplicity, the noise and the original signal were subject to linear superposition. However, the models of external noise were diverse, and the interaction model with the original EEG signal were also diverse. Finally, the different impacts of different channels were not considered.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}