Channel Coding and Source Coding With Increased Partial Side Information

{kind=link}
{kind=link}
{kind=link}
{kind=link}
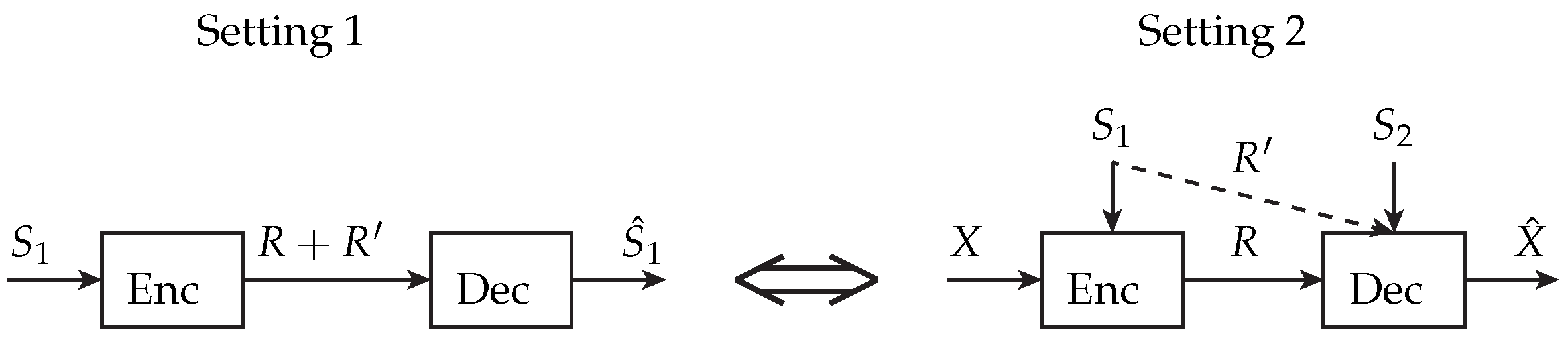{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Channel Capacity in the Presence of State Information
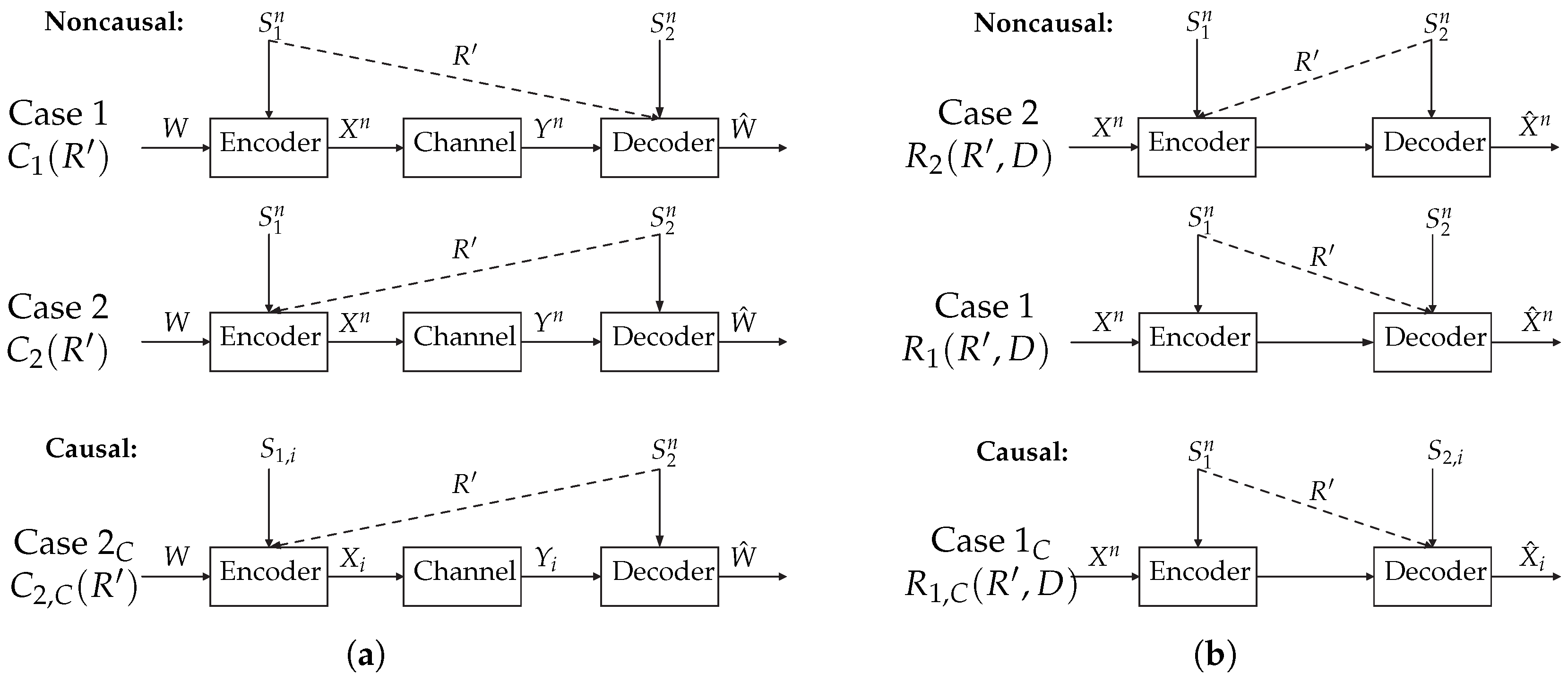
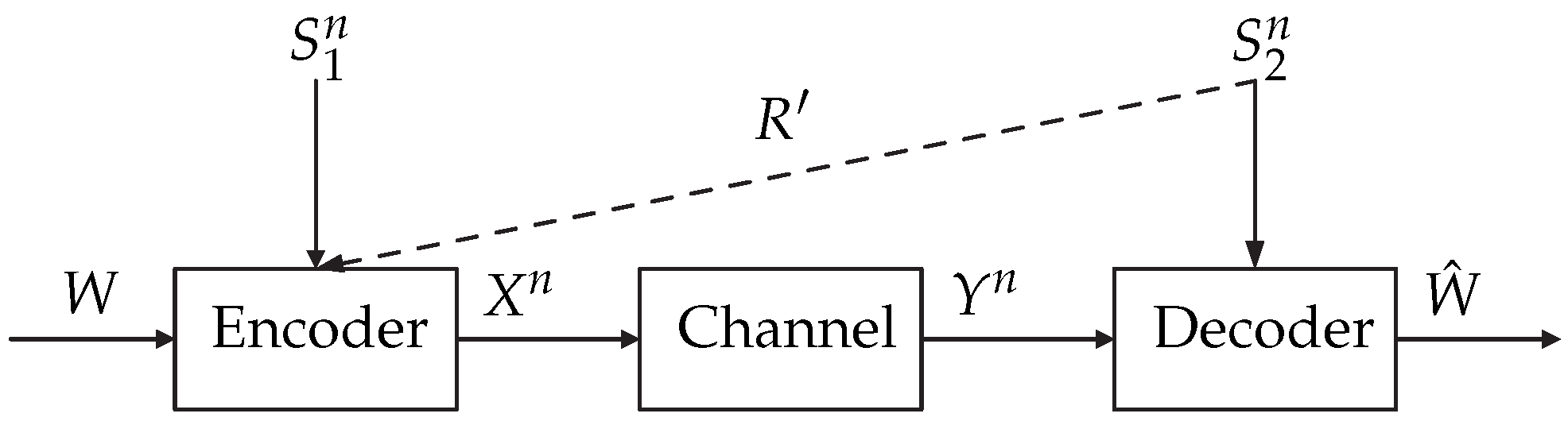
- Case 1: The decoder is provided with increased DSI; i.e., in addition to the DSI, the decoder is also informed with a rate-limited description of the ESI.
- Case 2: The encoder is informed with increased ESI.
- Case 2: Similar to Case 2, with the exception that the ESI is known to the encoder in a causal manner. Notice that the rate-limited description of the DSI is still known to the encoder noncausally.
1.2. Rate-Distortion with Side Information
- Case 1: The decoder is provided with increased DSI.
- Case 1: Similar to Case 1, with the exception that the ESI is known to the encoder in a causal manner. The rate-limited description of the ESI is still known to the decoder noncausally.
- Case 2: The encoder is informed with increased ESI.
1.3. Duality
1.4. Computational Algorithms
1.5. Organization of the Paper and Main Contributions
- We characterize the capacity and the rate-distortion functions of new channel and source coding problems with increased partial side information. We quantify the gain in the rate that can be achieved by having the parties involved share their partial side information with each other over a rate-limited secondary channel.
- We show a duality relationship between the channel capacity cases and the rate-distortion cases that we discuss.
- We provide a B-A based algorithm to solve the channel capacity problems we describe.
- We show a duality between the Gelfand–Pinsker capacity converse and the Wyner-Ziv rate-distortion converse.
2. Problem Setting and Definitions
2.1. Definitions and Problem Formulation—Channel Coding with State Information
- Case 1: The encoder is informed with ESI and the decoder is informed with increased DSI.
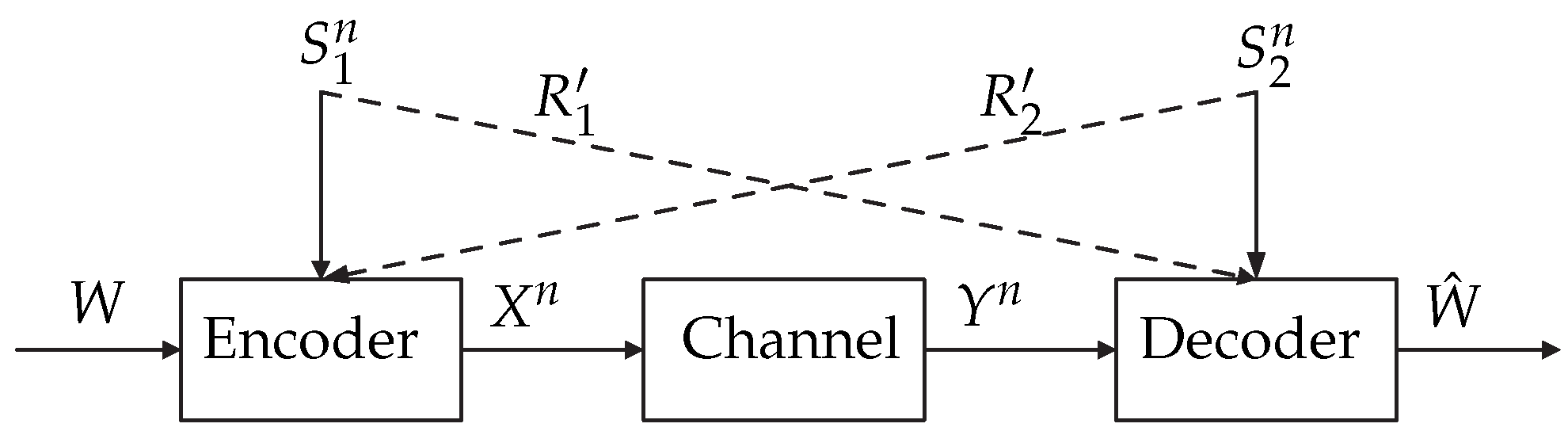
- Case 2: The encoder is informed with increased ESI and the decoder is informed with DSI.
- Case 2: The encoder is informed with increased causal ESI ( at time i) and the decoder is informed with DSI. This case is the same as Case 2, except for the causal ESI.
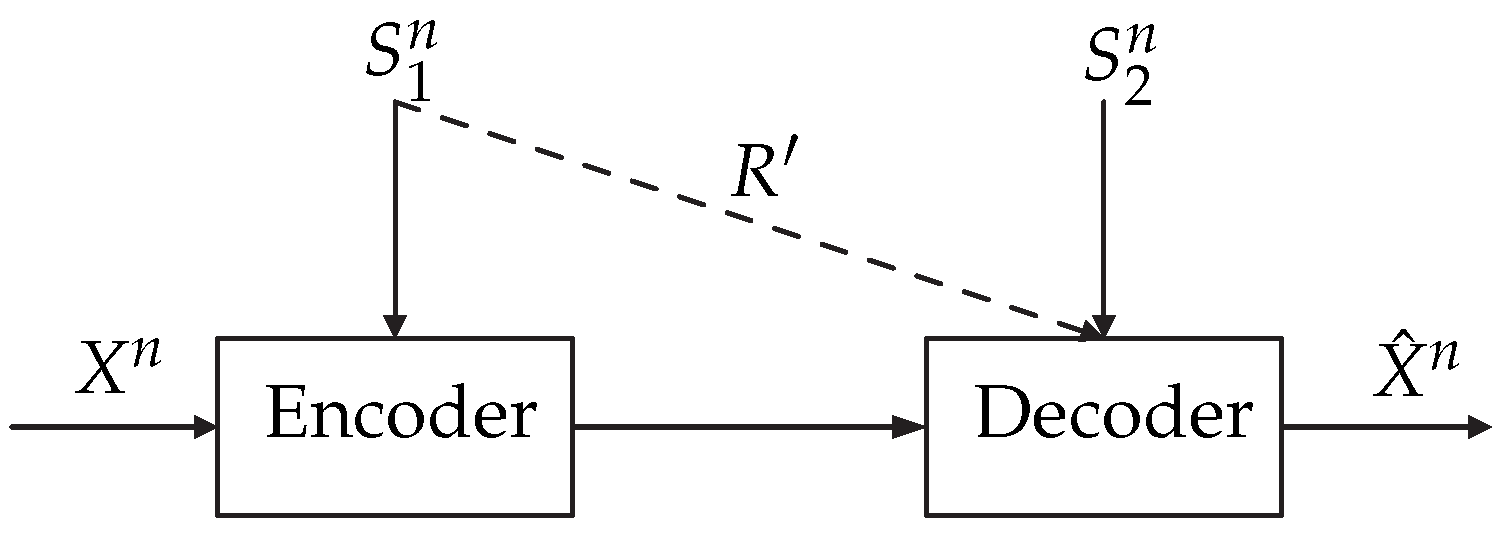
2.2. Definitions and Problem Formulation—Source Coding with Side Information
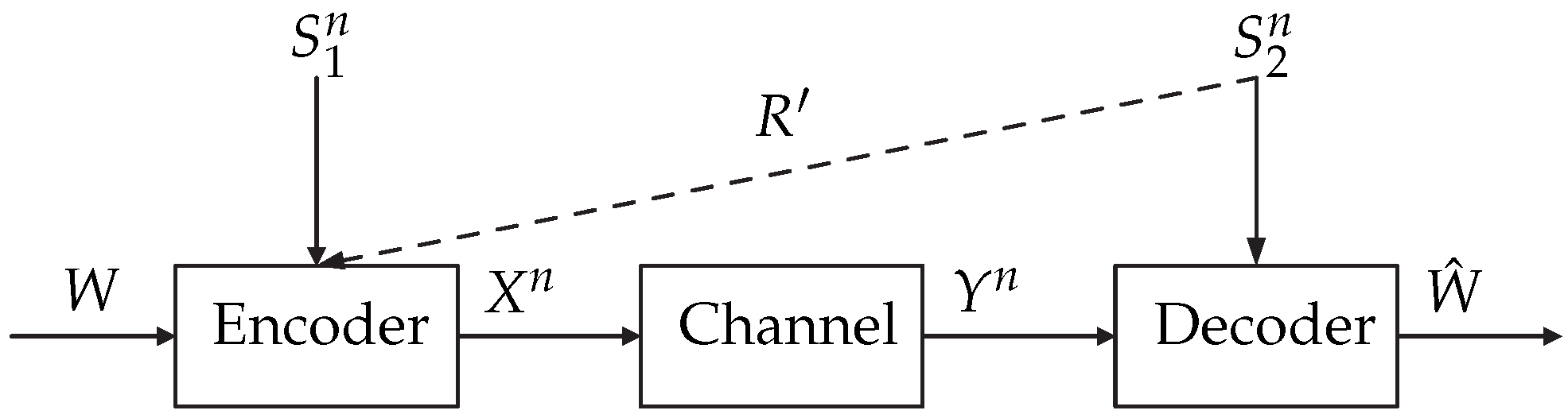
- Case 1: The encoder is informed with ESI and the decoder is informed with increased DSI.
- Case 2: The encoder is informed with increased ESI and the decoder is informed with DSI.
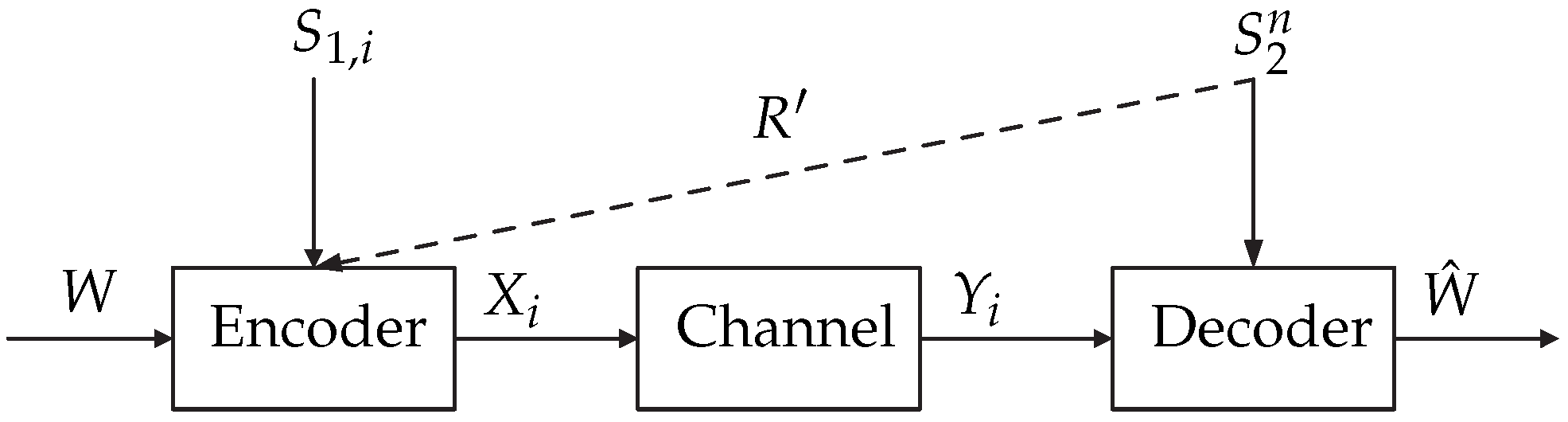
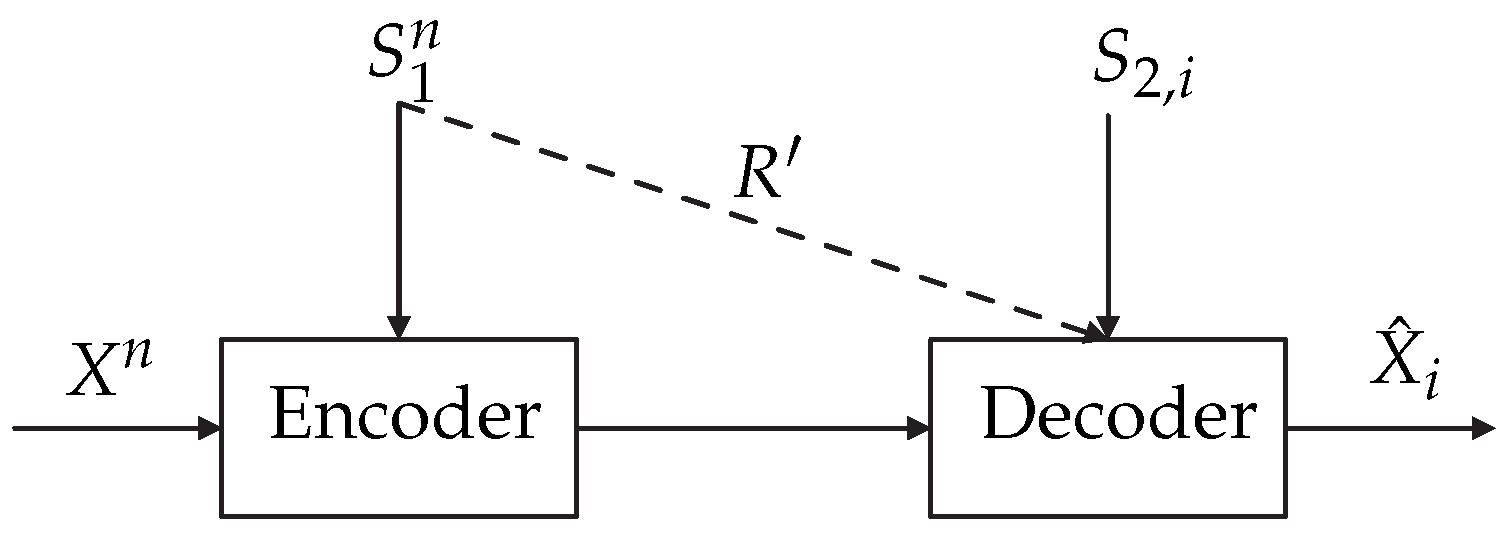
- Case 1: The encoder is informed with ESI and the decoder is informed with increased causal DSI ( at time i). This case is the same as Case 1, except for the causal DSI.
3. Results
3.1. Channel Coding with Side Information
- The function is a concave function of .
- It is enough to take X to be a deterministic function of to evaluate .
- The auxiliary alphabets and satisfy
3.2. Source Coding with Side Information
- The function is a convex function of and D.
- It is enough to take to be a deterministic function of to evaluate .
- The auxiliary alphabets and satisfy
3.3. Duality
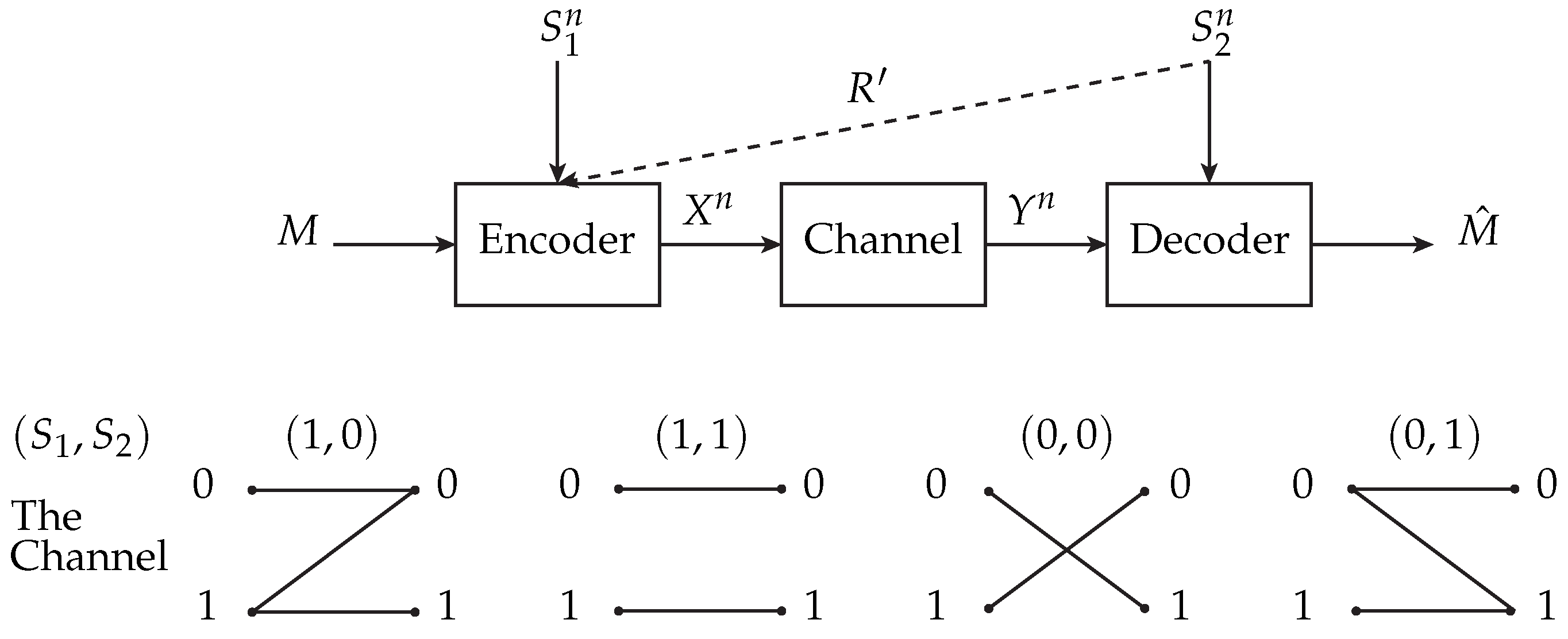
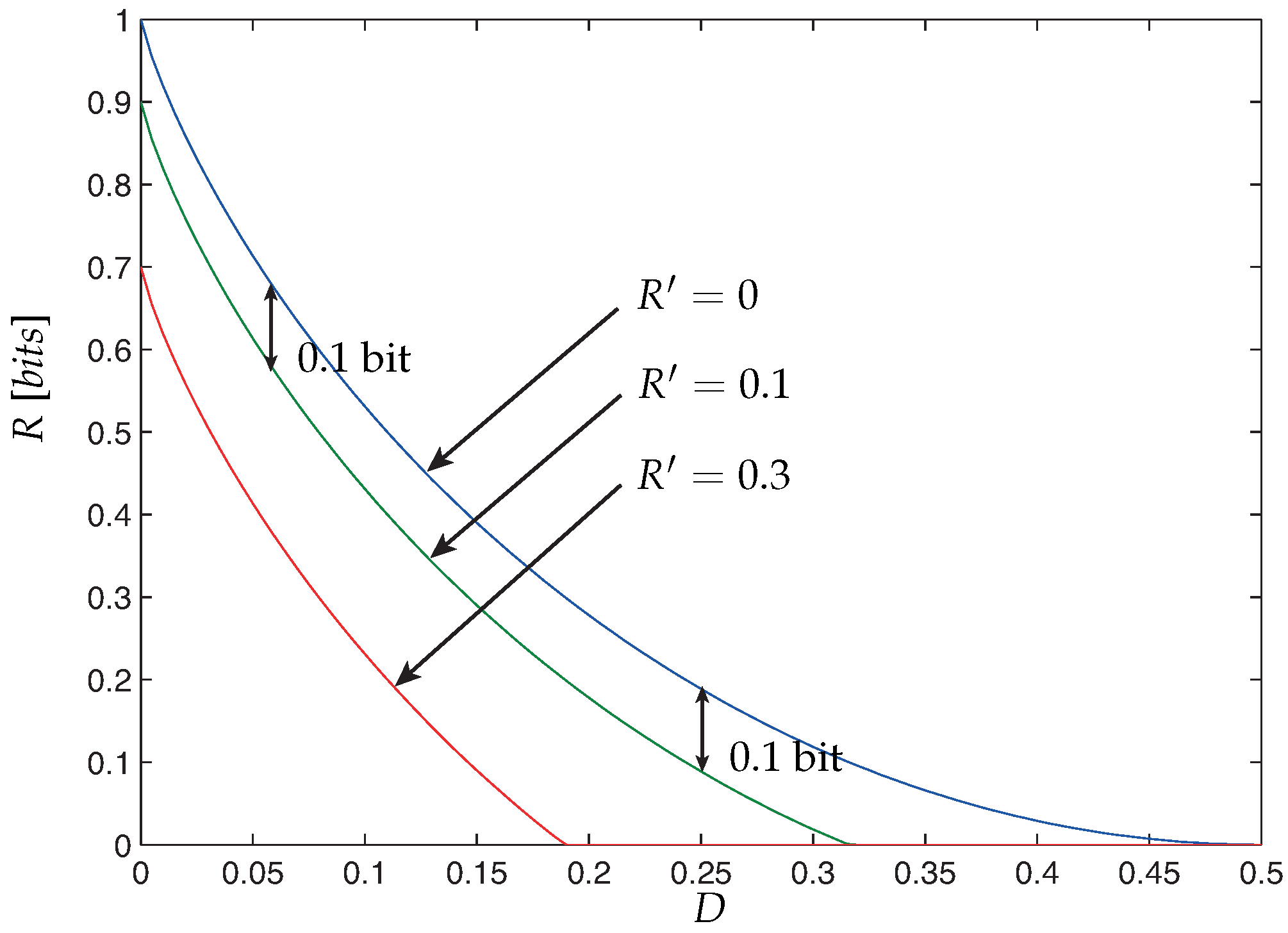
4. Examples
- The algorithm that we used to calculate and combines a grid-search and a Blahut-Arimoto-like algorithms. We first construct a grid of probabilities of the random variable given , namely, . Then, for every probability such that is close enough to we calculate the maximum of using the iterative algorithm described in the next section. We then choose the maximum over those maximums and declare it to be . By taking a fine grid of the probabilities the operation’s result can be arbitrarily close to .
- For a given joint PMF matrix , we can see that is non-decreasing in . Furthermore, since the expression is bounded by , allowing to be greater than cannot improve any more. i.e., . Therefore, it is enough to allow to achieve , as if the encoder is fully informed with .
- Although is a lower bound on the capacity, it can be significantly greater than the Cover-Chiang and the Gelfand–Pinsker rates for some channel models, as can be seen in this example. Moreover, we can actually state that is always greater than or equal to the Gelfand–Pinsker and the Cover-Chiang rates. This is due to the fact that when , coincides with the Cover-Chiang rate, which, in its turn, is always greater than or equal to the Gelfand–Pinsker rate; since is also non-decreasing in , it is obvious that our assertion holds.
5. Semi-Iterative Algorithm
5.1. An Algorithm for Computing the Lower Bound on the Capacity of Case 2
- Establish a fine and uniformly spaced grid of legal PMFs, , and denote the set of all of those PMFs as .
- Establish the set and . This set is the set of all PMFs such that is -close to from below. If is empty, go back to step 1 and make the grid finer. Otherwise, continue.
- For every , perform a Blahut-Arimoto-like optimization to find with accuracy of .
- Declare .
- 1.
- We considered only those s such that since is the maximal value that takes. The interpretation of this is that if the encoder is informed with , we cannot increase its side information about in more than . Therefore, for any , we can limit to be equal to in order to compute the capacity;
- 2.
- Since is continuous in and bounded (for example, by from above and by from below), can be arbitrarily close to for and .
5.1.1. Mathematical background and justification
5.2. Semi-Iterative Algorithm
| Algorithm 1 Numerically calculating |
|
6. Open Problems
6.1. A Lower Bound on the Capacity of a Channel with Two-Sided Increased Partial Side Information
6.2. An Upper Bound on the Rate-Distortion with Two-Sided Increased Partial Side Information
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Duality of the Converse of the Gelfand–Pinsker Theorem and the Wyner-Ziv Theorem

Appendix B. Proof of Theorem 1
Appendix B.1. Proof of Theorem 1, Case 2

- Generate a codebook of sequences independently using . Label them , where , and randomly assign each sequence a bin number in the set .
- Generate a codebook of sequences independently using . Label them , , and randomly assign each sequence a bin number in the set .
- State Encoder: Given the sequence , search the codebook and identify an index k such that . If such a k is found, stop searching and send the bin number . If no such k is found, declare an error.
- Encoder: Given the message W, the sequence and the index j, search the codebook and identify an index k such that . If no such k is found or there is more than one such index, declare an error. If a unique k, as defined, is found, search the codebook and identify an index l such that and . If a unique l, as defined, is found, transmit , . Otherwise, if there is no such l or there is more than one, declare an error.
- The probability that there is no in such that is strongly jointly typical is exponentially small provided that . This follows from the standard rate-distortion argument that ’s “cover” , therefore .
- By the Markov lemma [31], since are strongly jointly typical, are strongly jointly typical and the Markov chain holds, then are strongly jointly typical with high probability. Therefore, .
- The probability that there is another index , , such that is in bin number 1 and that is strongly jointly typical with is bounded by the number of ’s in the bin times the probability of joint typicality. Therefore, if the number of bins then .
- We use here the same argument we used for ; by the covering lemma, we can state that the probability that there is no in bin number 1 that is strongly jointly typical with tends to zero for large enough n if the average number of ’s in each bin is greater than ; i.e., . This also implies that in order to avoid an error the number of words one should use is , where the last expression also equals .
- As we argued for , since is strongly jointly typical, is strongly jointly typical and the Markov chain holds, then, by the Markov lemma, is strongly jointly typical with high probability, i.e., .
- The probability that there is another index , , such that is strongly jointly typical with is bounded by the total number of ’s times the probability of joint typicality. Therefore, taking assures us that . This follows the standard channel capacity argument that one can distinguish at most different ’s given any typical member of .
Appendix B.2. Proof of Theorem 1, Case 2C

- Generate a codebook of sequences independently using . Label them where .
- For each generate a codebook of sequences distributed independently according to . Label them , where , and associate the sequences with the message .
- State Encoder: Given the sequence , search the codebook and identify an index k such that . If such a k is found, stop searching and send it. Otherwise, if no such k is found, declare an error.
- Encoder: Given the message , the index k and at time i, identify in the codebook and transmit at any time . The element is the result of a multiplexer with an input signal and a control signal .
- For each sequence , the probability that is not jointly typical with is at most . Therefore, having sequences in , the probability that none of those sequences is jointly typical with is bounded bywhere, for every , the last line goes to zero as n goes to infinity.
- The random variable is distributed according to , therefore, having implies that . Recall that and that is generated according to ; therefore, is jointly typical. Thus, by the Markov lemma [31], we can state that with high probability for a large enough n.
- Now, the probability for a random , such that , to be also jointly typical with is upper bounded by , hencewhich goes to zero exponentially fast with n for every .Therefore, goes to zero as .
Appendix C. Proof of Theorem 2

Appendix C.1. Proof of Theorem 2, Case 1

- Generate a codebook, , of sequences, , independently using . Label them , where and randomly assign each sequence a bin number in the set .
- Generate a codebook of sequences independently using . Label them , where , and randomly and assign each a bin number in the set .
- State Encoder: Given the sequence , search the codebook and identify an index k such that . If such a k is found, stop searching and send the bin number . If no such k is found, declare an error.
- Encoder: Given the sequences , and , search the codebook and identify an index l such that . If such an l is found, stop searching and send the bin number . If no such l is found, declare an error.
- The probability that there is no in such that is strongly jointly typical is exponentially small provided that . This follows from the standard rate-distortion argument that s “cover” , therefore .
- By the Markov lemma, since are strongly jointly typical and are strongly jointly typical and the Markov chain holds, then are also strongly jointly typical. Thus, .
- The probability that there is another index , such that is in bin number 1 and that it is strongly jointly typical with is bounded by the number of ’s in the bin times the probability of joint typicality. Therefore, if then . Furthermore, using the Markov chain , we can see that the inequality can be presented as .
- We use here the same argument we used for . By the covering lemma we can state that the probability that there is no in that is strongly jointly typical with tends to 0 as if . Hence, .
- Using the same argument we used for , we conclude that .
- We use here the same argument we used for . Since are strongly jointly typical, are strongly jointly typical and the Markov chain holds, then are also strongly jointly typical.
- The probability that there is another index such that is in bin number 1 and that it is strongly jointly typical with is exponentially small provided that . Notice that stands for the average number of sequences ’s in each bin indexed w for .
Appendix C.2. Proof of Theorem 2, Case 1C

- Generate a codebook of sequences independently using . Label them where .
- For each generate a codebook of sequences distributed independently according to . Label them , where .
- State Encoder: Given the sequence , search the codebook and identify an index k such that . If such a k is found, stop searching and send it. Otherwise, if no such k is found, declare an error.
- Encoder: Given and the index k, search the codebook and identify an index w such that . If such an index w is found, stop searching and send it. Otherwise, declare an error.
Appendix C.3. Proof of Theorem 2, Case 2

Appendix D. Proof of Lemma 1
Appendix E. Proofs for Section 5
Appendix E.1. Proof of Lemma 4
Appendix E.2. Proof of Lemma 6
Appendix E.3. Proof of Lemma 7
References
- Steinberg, Y. Coding for Channels With Rate-Limited Side Information at the Decoder, with Applications. IEEE Trans. Inf. Theory 2008, 54, 4283–4295. [Google Scholar] [CrossRef]
- Gel’fand, S.I.; Pinsker, M.S. Coding for Channel with Random Parameters. Probl. Control Theory 1980, 9, 19–31. [Google Scholar]
- Wyner, A.; Ziv, J. The rate-distortion function for source coding with side information at the decoder. IEEE Trans. Inf. Theory 1976, 22, 1–10. [Google Scholar] [CrossRef]
- Shannon, C.E. Channels with side information at the transmitter. IBM J. Res. Dev. 1958, 2, 289–293. [Google Scholar] [CrossRef]
- Heegard, C.; Gamal, A.A.E. On the capacity of computer memory with defects. IEEE Trans. Inf. Theory 1983, 29, 731–739. [Google Scholar] [CrossRef]
- Cover, T.M.; Chiang, M. Duality between channel capacity and rate distortion with two-sided state information. IEEE Trans. Inf. Theory 2006, 48, 1629–1638. [Google Scholar] [CrossRef]
- Rosenzweig, A.; Steinberg, Y.; Shamai, S. On channels with partial channel state information at the transmitter. IEEE Trans. Inf. Theory 2005, 51, 1817–1830. [Google Scholar] [CrossRef]
- Cemal, Y.; Steinberg, Y. Coding Problems for Channels With Partial State Information at the Transmitter. IEEE Trans. Inf. Theory 2007, 53, 4521–4536. [Google Scholar] [CrossRef]
- Keshet, G.; Steinberg, Y.; Merhav, N. Channel Coding in the Presence of Side Information. Found. Trends Commun. Inf. Theory 2007, 4, 445–586. [Google Scholar] [CrossRef]
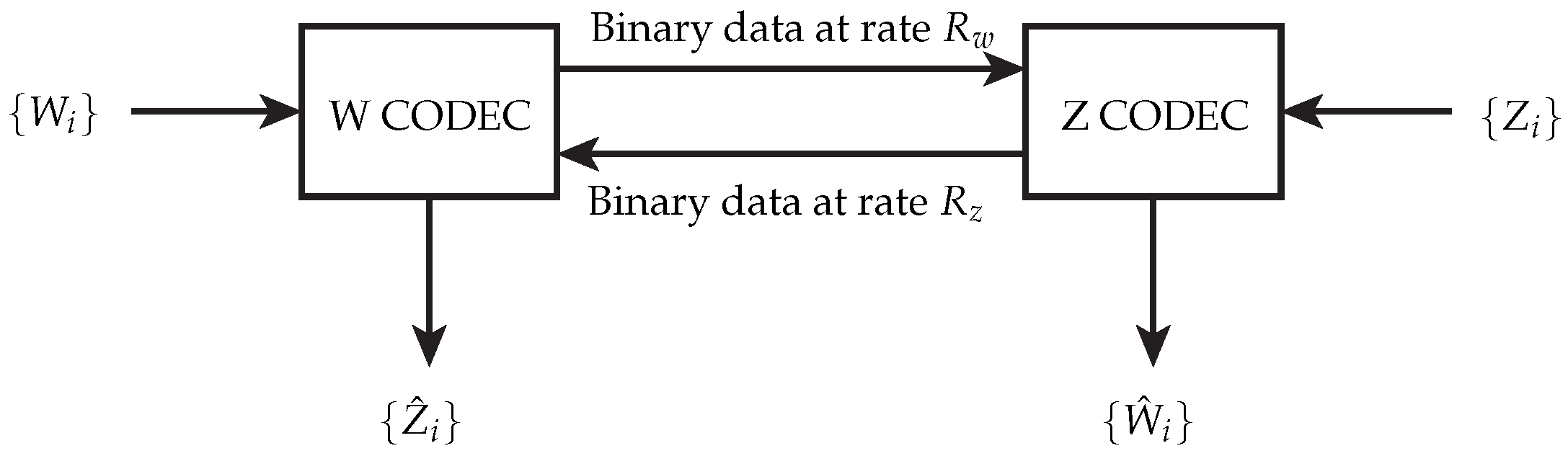
- Kaspi, A.H. Two-way source coding with a fidelity criterion. IEEE Trans. Inf. Theory 1985, 31, 735–740. [Google Scholar] [CrossRef]
- Permuter, H.; Steinberg, Y.; Weissman, T. Two-Way Source Coding With a Helper. IEEE Trans. Inf. Theory 2010, 56, 2905–2919. [Google Scholar] [CrossRef]
- Weissman, T.; Gamal, A.E. Source Coding With Limited-Look-Ahead Side Information at the Decoder. IEEE Trans. Inf. Theory 2006, 52, 5218–5239. [Google Scholar] [CrossRef]
- Weissman, T.; Merhav, N. On causal source codes with side information. IEEE Trans. Inf. Theory 2005, 51, 4003–4013. [Google Scholar] [CrossRef]
- Shannon, C.E. Coding Theorems for a Discrete Source with a Fidelity Criterion. IRE Nat. Conv. Rec. 1959, 4, 142–163. [Google Scholar]
- Pradhan, S.S.; Chou, J.; Ramchandran, K. Duality between source coding and channel coding and its extension to the side information case. IEEE Trans. Inf. Theory 2003, 49, 1181–1203. [Google Scholar] [CrossRef]
- Pradhan, S.S.; Ramchandran, K. On functional duality in multiuser source and channel coding problems with one-sided collaboration. IEEE Trans. Inf. Theory 2006, 52, 2986–3002. [Google Scholar] [CrossRef]
- Zamir, R.; Shamai, S.; Erez, U. Nested linear/lattice codes for structured multiterminal binning. IEEE Trans. Inf. Theory 2006, 48, 1250–1276. [Google Scholar] [CrossRef]
- Su, J.; Eggers, J.; Girod, B. Illustration of the duality between channel coding and rate distortion with side information. In Proceedings of the 2000 Conference Record of the Thirty-Fourth Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 29 October–1 November 2000; Volume 2, pp. 1841–1845. [Google Scholar]
- Goldfeld, Z.; Permuter, H.H.; Kramer, G. Duality of a Source Coding Problem and the Semi-Deterministic Broadcast Channel With Rate-Limited Cooperation. IEEE Trans. Inf. Theory 2016, 62, 2285–2307. [Google Scholar] [CrossRef]
- Asnani, H.; Permuter, H.H.; Weissman, T. Successive Refinement With Decoder Cooperation and Its Channel Coding Duals. IEEE Trans. Inf. Theory 2013, 59, 5511–5533. [Google Scholar] [CrossRef]
- Gupta, A.; Verdu, S. Operational Duality Between Lossy Compression and Channel Coding. IEEE Trans. Inf. Theor. 2011, 57, 3171–3179. [Google Scholar] [CrossRef]
- Blahut, R.E. Computation of channel capacity and rate-distortion functions. IEEE Trans. Inform. Theory 1972, 18, 460–473. [Google Scholar] [CrossRef]
- Arimoto, S. An Algorithm for Computing the Capacity of Arbitrary Discrete MemorylessChannels. IEEE Trans. Inf. Theory 1972, 18, 14–20. [Google Scholar] [CrossRef]
- Willems, F.M.J. Computation of the Wyner-Ziv Rate-Distortion Function; Research Report; University of Technology: Hong Kong, China, 1983. [Google Scholar]
- Dupuis, F.; Yu, W.; Willems, F. Blahut-Arimoto algorithms for computing channel capacity and rate-distortion with side information. In Proceedings of the 2004 International Symposium on Information Theory, Chicago, IL, USA, 27 June–2 July 2004; p. 179. [Google Scholar]
- Cheng, S.; Stankovic, V.; Xiong, Z. Computing the channel capacity and rate-distortion function with two-sided state information. IEEE Trans. Inf. Theory 2005, 51, 4418–4425. [Google Scholar] [CrossRef]
- Sumszyk, O.; Steinberg, Y. Information embedding with reversible stegotext. In Proceedings of the 2009 IEEE International Symposium on Information Theory, Seoul, Korea, 28 June–3 July 2009; pp. 2728–2732. [Google Scholar]
- Naiss, I.; Permuter, H.H. Extension of the Blahut-Arimoto Algorithm for Maximizing Directed Information. IEEE Trans. Inf. Theory 2013, 59, 204–222. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1991. [Google Scholar]
- Yeung, R.W. Information Theory and Network Coding, 1 ed.; Springer: Berlin, Germany, 2008. [Google Scholar]
- Berger, T. Multiterminal source coding. In Information Theory Approach to Communications; Longo, G., Ed.; CSIM Course and Lectures; Springer: Berlin, Germany, 1978; pp. 171–231. [Google Scholar]
- Csiszar, I.; Korner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems/Imre Csiszar and Janos Korner; Academic Press: Cambridge, MA, USA, 1981. [Google Scholar]









© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sadeh-Shirazi, A.; Basher, U.; Permuter, H. Channel Coding and Source Coding With Increased Partial Side Information. Entropy 2017, 19, 467. https://doi.org/10.3390/e19090467
Sadeh-Shirazi A, Basher U, Permuter H. Channel Coding and Source Coding With Increased Partial Side Information. Entropy. 2017; 19(9):467. https://doi.org/10.3390/e19090467
Chicago/Turabian StyleSadeh-Shirazi, Avihay, Uria Basher, and Haim Permuter. 2017. "Channel Coding and Source Coding With Increased Partial Side Information" Entropy 19, no. 9: 467. https://doi.org/10.3390/e19090467
APA StyleSadeh-Shirazi, A., Basher, U., & Permuter, H. (2017). Channel Coding and Source Coding With Increased Partial Side Information. Entropy, 19(9), 467. https://doi.org/10.3390/e19090467