1. Introduction
Innovation processes are ubiquitous. New elements constantly appear in virtually all systems and the occurrence of the new goes well beyond what we now call innovation. The term innovation refers to a complex set of phenomena that includes not only the appearance of new elements in a given system, e.g., technologies, ideas, words, cultural products, etc., but also their adoption by a given population of individuals. From this perspective one can distinguish between a personal, or local, experience of the new—for instance when we discover a new favorite writer or a new song—and a global occurrence of the new, i.e., every time something appears that never appeared before—for instance, if we write a new book or write a new song. In all these cases there is something new entering the history of a given system or a given individual.
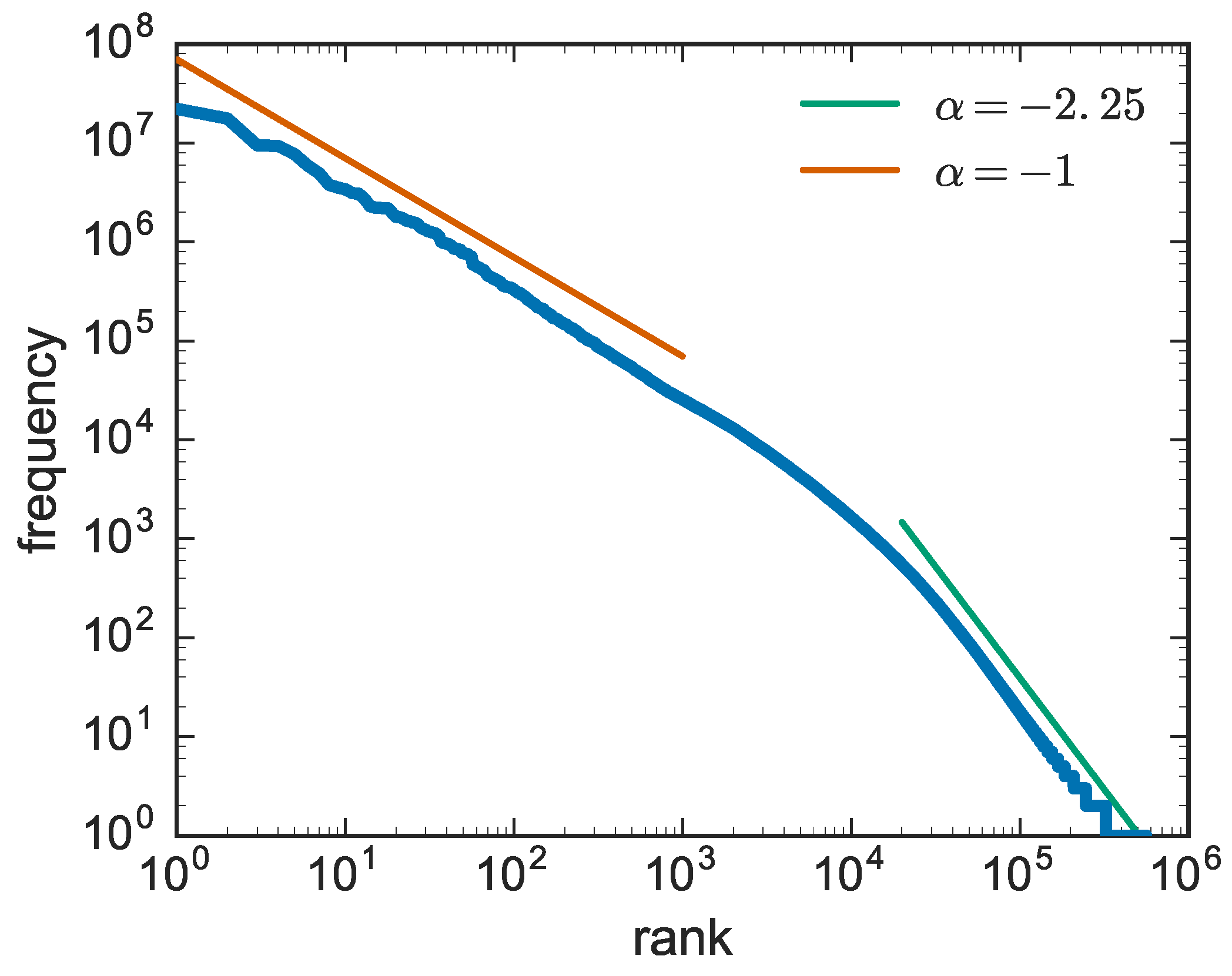
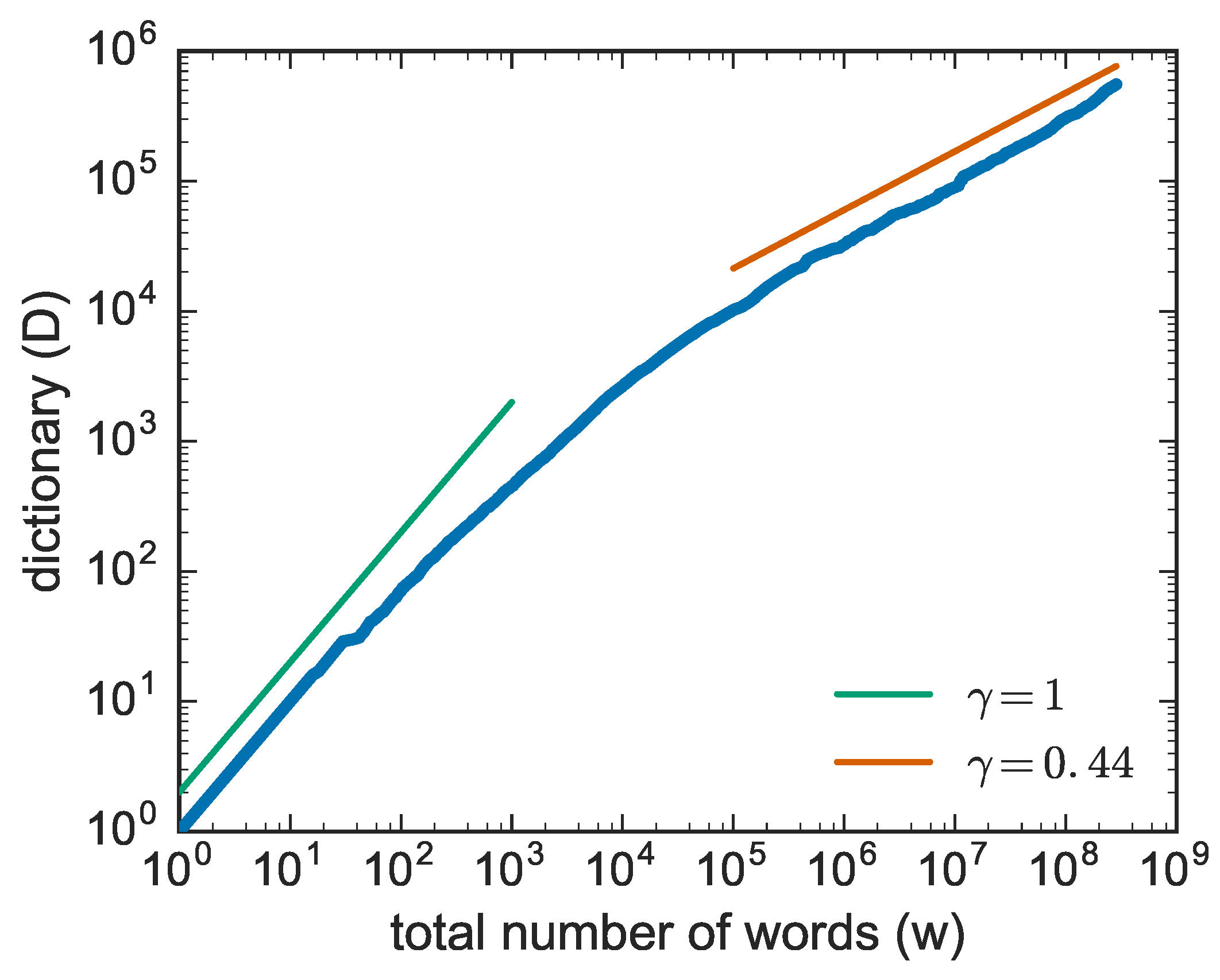
Given the paramount relevance of innovation processes, it is highly important to grasp their nature and understand how the new emerges in all its possible instantiations. To this end, it is essential to fix a certain number of stylized facts characterizing the overall phenomenology of the new and quantifying its occurrence and its dynamical properties. Here we focus in particular on three basic laws whose general validity has been assessed in virtually all systems displaying innovation. The Zipf’s law [
1,
2,
3,
4], quantifying the frequency distribution of elements in a given system, the Heaps’ law [
5,
6], quantifying the rate at which new elements enter a given system and the Taylor’s law [
7], quantifying the intrinsic fluctuations of variables associated to the occurrence of the new. Any basic theory, supposedly close to the actual phenomenology of innovation processes, should be able at least to explain those three laws from first principles. Despite an abundant literature on the subject related to many different disciplines, a clear and self-consistent framework to explain the above-mentioned stylized facts has been missing for a very long time. Many approaches have been proposed so far, often adopting ad-hoc assumptions or attempting to derive the three laws while taking the others for granted. The aim of this paper is that of trying to put order in the often scattered and disordered literature, by proposing a self-consistent framework that, in its simplicity and generality, is able to account for the existence of the three laws from very first principles.
The framework we propose is based on the notion of “Adjacent Possible” and, more generally, on the interplay between what Francois Jacob named the dichotomy between the “actual” and the “possible”, the actual realization of a given phenomenon and the space of possibilities still unexplored. Originally introduced by the famous biologist and complex-systems scientist Stuart Kauffman, the notion of the adjacent possible [
8,
9] refers to the progressive expansion, or restructuring, of the space of possibilities, conditional to the occurrence of novel events. Based on this early intuition, we recently introduced, in collaboration with Steven Strogatz, a mathematical framework [
10,
11] to investigate the dynamics of the new via the adjacent possible. The modeling scheme is based on older schemes, named Polya’s urns and it mathematically predicts the notion that “one thing leads to another”, i.e., the intuitive idea, presumably we all have, that innovation processes are non-linear and the conditions for the occurrence of a given event could realize only after something else happened.
It turns out that the mathematical framework encoding the notion of adjacent possible represents a sufficient first-principle scheme to explain the Zipf’s, Heaps’ and Taylor’s laws on the same ground. In this paper we present this approach and we discuss the links it bears with other approaches. In particular, we discuss the relation of our approach with well known stochastic processes, widely studied in the framework of nonparametric Bayesian inference, namely the Dirichlet and the Poisson-Dirichlet processes [
12,
13,
14]. In addition, based on this comparison, a coherent framework emerges where the importance of the adjacent possible scheme appears as crucial to understand the basic phenomenology of innovation processes. Though we can only conjecture that the expansion of the adjacent possible space is also a necessary condition for the validity of the three laws mentioned above, no counterexamples have been found so far that, without a dynamical space of possibilities, that one can use to satisfactorily explain the empirically observed laws.
3. Urn Model with Triggering
We now introduce a simple modeling scheme able to reproduce both Zipfs’ and Heaps’ laws simultaneously. Crucial for this result is the conditional expansion of the space of possibilities, that we will elucidate in the following. In [
8,
9], S. Kauffman introduces and discusses the notion of the
adjacent possible, which is all those things that are one step away from what actually exists. The idea is that evolution does not proceed by leaps, but moves in a space where each element should be connected with its precursor. The Kauffman’s theoretical concept of
adjacent possible, originally discussed in his investigations of molecular and biological evolution, has also been applied to the study of innovation and technological evolution [
27,
28]. To clarify the concept, let us think about a baby that is learning to talk. We can say almost surely that she will not utter “serendipity” as the first word in her life. More than this, we can safely guess that her first word will be “papa”, or “mama”, or one among a list of few other possibilities. In other words, in the period of lallation, only few words belong to the space of the adjacent possible and can be actualized in the next future. Once the baby has learned how to utter simple words, she can try more sophisticated ones, involving more demanding articulation efforts. In the process of learning, her space of possibilities (her adjacent possible) considerably grows, with the result that guessing a priori the first 100 words learned by a child is much less obvious than guessing which will be the first one.
Here we formalize the idea that by opening up new possibilities, an innovation paves the way for other innovations, explicitly introducing this concept in a Pólya’s urn based model. In particular, we will discuss the simplest version of the model introduced in [
10], which we will name Pólya’s urn model with triggering (PUT). The interest of this model lies, on the one hand, in its generality, the only assumptions it makes refer to the general and not system-specific mechanisms for the expansion into the adjacent possible; on the other hand, its simplicity allows to draw analytical solutions.
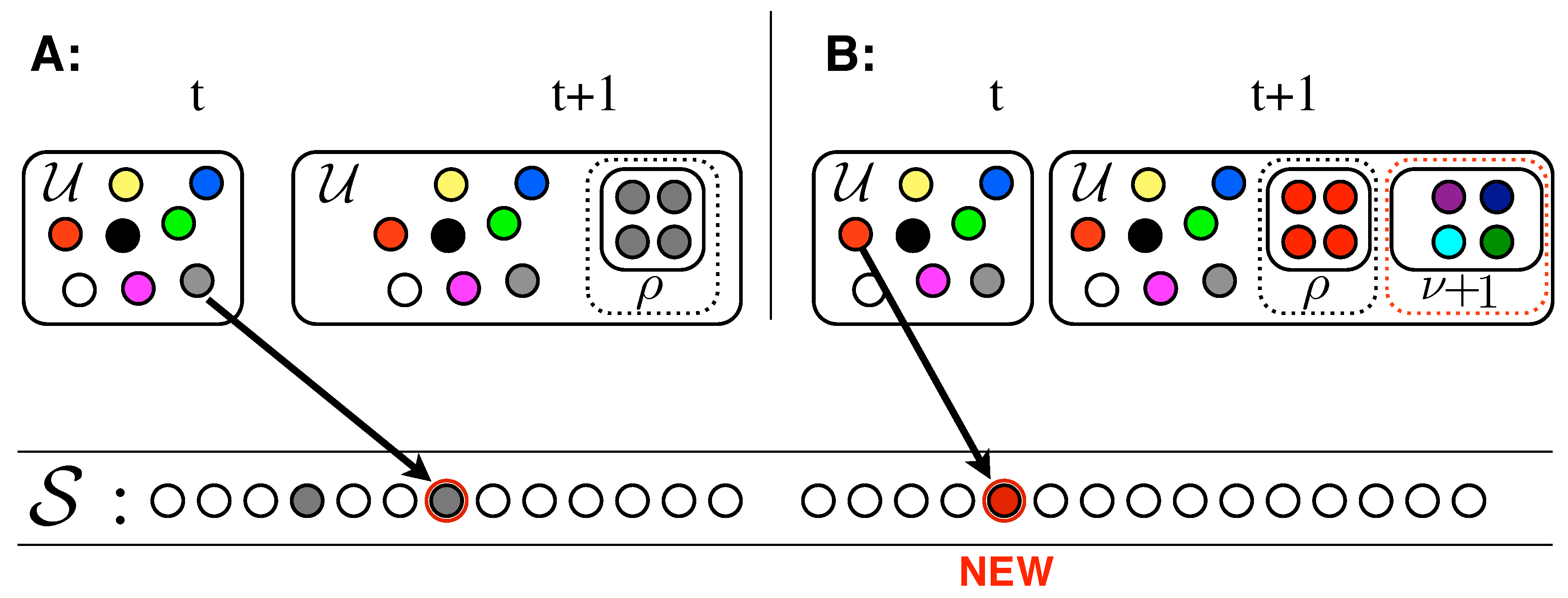
The model works as follows (please refer to
Figure 3). An urn
initially contains
distinct elements, represented by balls of different colors. By randomly extracting elements from the urn, we construct a sequence
mimicking the evolution of our system (e.g., the sequence of words in a given text). Both the urn and the sequence enlarge during the process: (i) at each time step
t, an element
is drawn at random from the urn, added to the sequence, and put back in the urn along with
additional copies of it (
Figure 3A); (ii) iff the chosen element
is new (i.e., it appears for the
first time in the sequence
),
brand new distinct elements are also added to the urn (
Figure 3B). These new elements represent the set of new possibilities opened up by the seed
. Hence
is the size of the
new adjacent possible available once an innovation occurs.
Simple asymptotic formulas for the number
of distinct elements appearing in the sequence as a function of the sequence’s length
n (Heaps’ law), and for the asymptotic power-law behavior of the frequency-rank distribution (Zipf’s law), in terms of the model parameters
and
can be derived. In order to do so, one can write a recursive formula for
as:
where we have defined
as the probability of drawing a new ball (never extracted before) at time
n (note that we consider intrinsic time, that is we identify the time elapsed with the length of the sequence constructed). The probability
is equal to the ratio (at time
n) between the number of elements in the urn never extracted and the total number of elements in the urn. Approximating Equation (
18) with its continuous limit, we can write:
where
is the number of balls, all distinct, initially placed in the urn. This equation can be integrated analytically in the limit of large
n, when
can be neglected, by performing a change of variable
. After some algebra (detailed computations can be found in [
11] and in
Appendix A for an extended model), we find the asymptotic solutions (valid for large
n):
For the derivation of the Zipf’s law we refer the reader to the SI of [
10] and to
Appendix B for an alternative derivation based on the continuous approximation. Results contrasting numerical results and theoretical predictions for the Heaps’ and Zipf’s laws are reported in
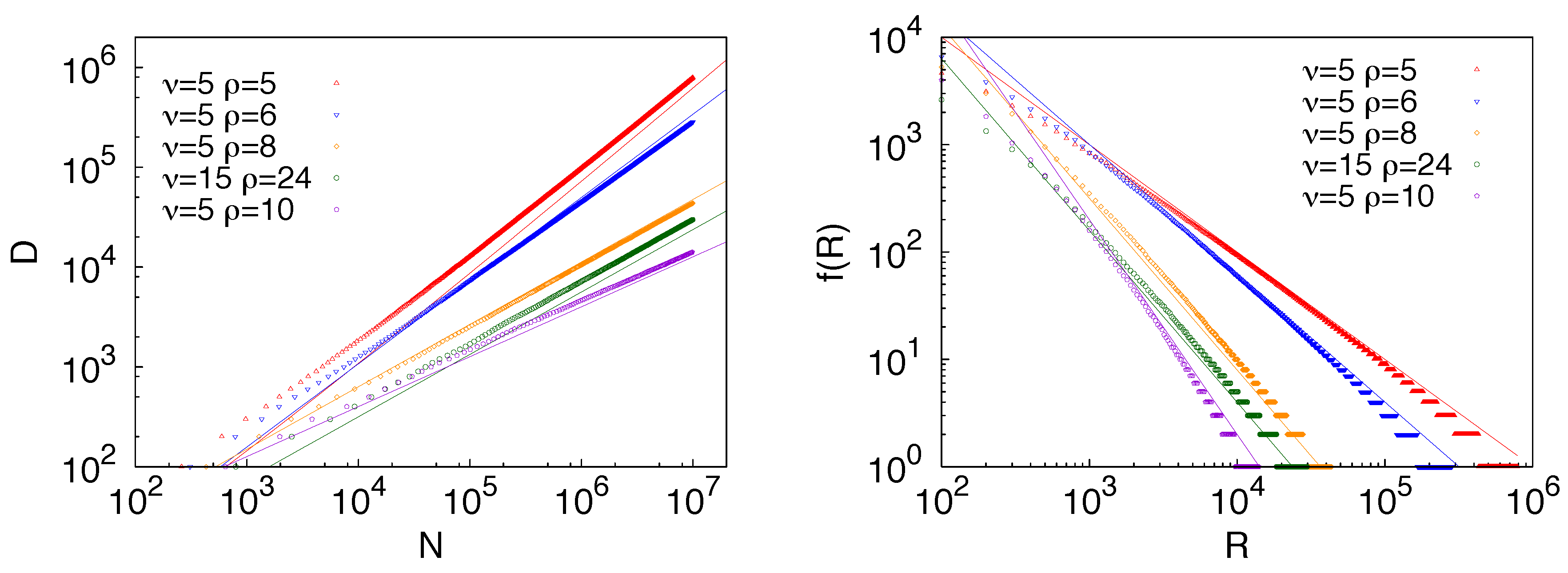
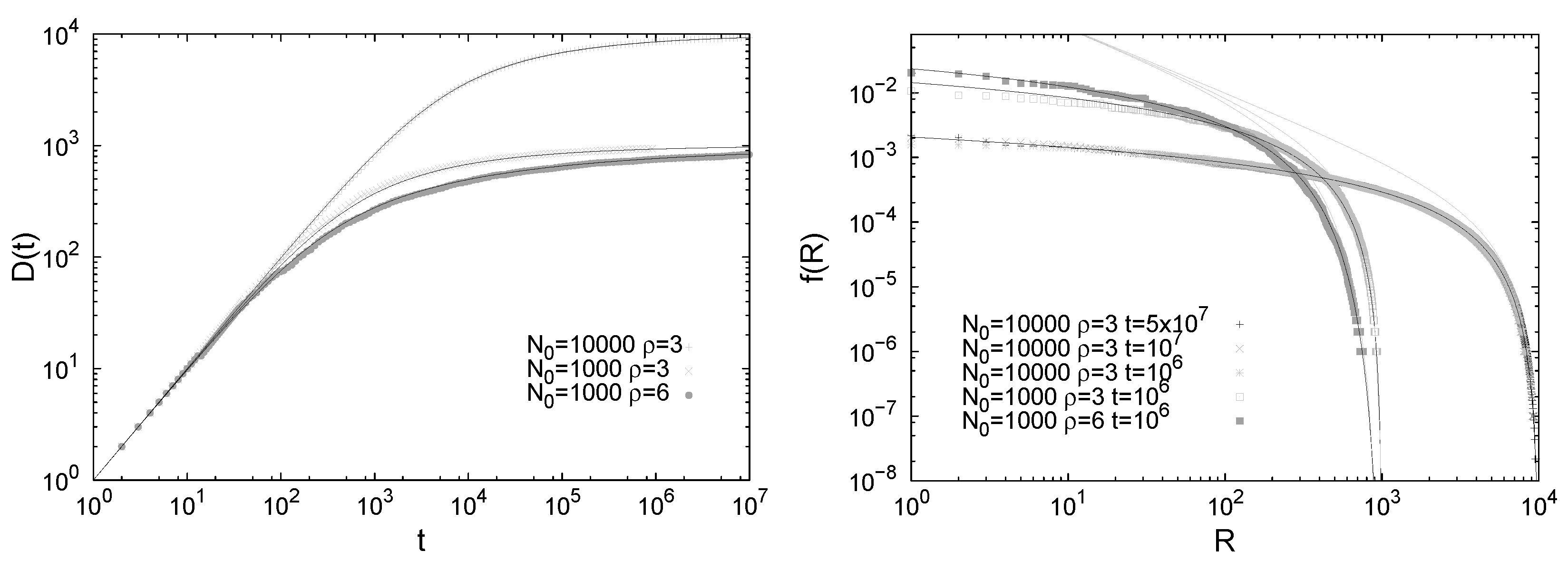
Figure 4.
The Role of the Adjacent Possible: Heaps’ and Zipf’s Laws in the Classic Multicolors Pólya Urn Model
One question that naturally emerges concerns the relevance of the notion of adjacent possible and its conditional growth. One could for instance argue that the same predictions of the PUT model could be replicated having all the possible outcomes of a process immediately available from the outset, instead of appearing progressively through the conditional process related to the very notion of adjacent possible. In order to remove all doubt, we consider an urn initially filled with
distinct colors, with
arbitrarily large, with no other colors entering into the urn during the process of construction of the sequence
. This is the Pólya multicolors urn model [
29] and we here briefly discuss the Heaps’ and Zipf’s laws emerging from it. Let us thus consider an urn initially containing
balls, all of different colors. At each time step, a ball is withdrawn at random, added to a sequence, and placed back in the urn along with
additional copies of it. This process corresponds to the one depicted in
Figure 3A, that is to the rule of the PUT model in the case that the drawn element is not new.
Note that although in this case the urn does not acquire new colors during the process, we can still study the dynamic of innovation by looking at the entrance of new color in the growing sequence. Let us then consider
very large, so that we can consider a long time interval far from saturation (when there are still many colors in the urn that have not already appeared in
). The number of different colors
added to the sequence at time
n follows the equation (when the continuous limit is taken):
We thus obtain that for
,
follows a linear behaviour (
), while for large
n saturates at
, failing to predict the power law (sublinear) growth of new elements. In
Figure 5, we report results for both the Heaps’ and Zipf’s laws predicted by the model along with their theoretical predictions, referring the reader to [
30] for a detailed derivation of the Zipf’s law. It is evident that a simple exploration of a static, though large, space of possibilities cannot account for the empirical observations summarized by the Zipf’s and the Heaps’s laws.
4. Connection of the Urn Model with Triggering and with Stochastic Processes Featuring Innovation
The PUT model is closely related to well known stochastic processes, widely studied in the framework of nonparametric Bayesian inference, namely the Dirichlet and the Poisson-Dirichlet processes. We will discuss here those processes in terms of their predictive probabilities, referring to excellent reviews [
12,
13,
14] for a complete and formal definition of them.
The problem can be framed in the following way. Given a sequence of events , we want to estimate the probability that the next event will be , where can be one of the already seen events , , or a completely new one, unseen until the intrinsic time n.
4.1. Urn Model with Triggering and the Poisson-Dirichlet Process
Let us first discuss the Poisson-Dirichlet process, whose predictive conditional probability reads:
where
and
are parameters of the model,
a given continuous probability distribution defined
a priori on the possible values the variables
can take, named
base probability distribution, and
the
D distinct values appearing in the sequence
, respectively with multiplicity
. Let us briefly discuss Equation (
24). The first term on the right hand side refers to the probability that
takes a value that has never appeared before, i.e., a novel event. This happens with probability
, depending both on the total number
n of events seen until time
n, and on the total number
D of distinct events seen until time
n. In this way, in the Poisson-Dirichlet process, the concept that the more novelties that are actualized, the higher the probability of encountering further novelties is implicit. The second term in Equation (
24) weights the probability that
equals one of the events that has previously occurred, and differs from a bare proportionality rule when
.
The Poisson-Dirichlet process predicts an asymptotic power-law behavior for the number
of distinct elements seen as a function of the sequence length
n. The exact expression for the expected value of
can be found in [
12]. Here we report the results obtained under the same approximations made for the urn model with triggering:
that can be solved by separation of variables, leading to:
Note that the Poisson-Dirichlet process predicts a sublinear power law behavior for but cannot reproduce a linear growth for it, being only defined for .
The ubiquity of the Poisson-Dirichlet process is due, together with its ability of producing sequences featuring Heaps’ and Zipf’s laws, to the fundamental property of
exchangeability [
12,
31]. This refers to the fact that the probability of a sequence generated by the Poisson-Dirichlet process does not depend on the order of the elements in the sequence:
for any permutation
of the sequence elements, so that we can write the joint probability distribution
for the number of occurrences of the variables
. Exchangeability is a powerful property related to the de Finetti theorem [
32,
33]; it is also a strong and sometimes unrealistic assumption on the lack of correlations and causality in the data.
Returning to the PUT model, we observe that the model produces, in general, sequences that are not exchangeable. It recovers exchangeability in a particular case, corresponding to a slightly different definition of rule (i): the drawn element
is put back in the urn along with
additional copies of it iff
is not new; in the other case (i.e., when we apply rule (ii)),
is put back in the urn along with
additional copies of it, with
. In this particular case the PUT model corresponds exactly to the Poisson-Dirichlet process, with
and
. In this case, at odds with the previously discussed version of the model, the urn acquires the same number of balls at each time step, regardless of whether a novelty occurs. This variant makes the generated sequences exchangeable, but imposes the constraint
, and thus in this case we cannot recover the linear growth of
; this is the same for the Poisson-Dirichlet process. We demonstrate in
Appendix A that the dependence of the power law’s exponents of the Heaps’ and Zipf’s laws on the PUT model’s parameters
and
reads the same as in Equations (
20–
22) if we modify rule (i) with any
.
Here we wish to remark that the urn representation of the PUT model allows for straightforward generalizations where correlations can be explicitly taken into account (see for instance [
10] for a first step in this direction). In addition, it can be easily rephrased in terms of walks in a complex space (for instance a graph), allowing to consider more complex underlying structures for the space of possibilities (see for instance the SI of [
10,
34,
35]).
4.2. Urn Model with Triggering, Dirichlet Process and Hoppe Model
By setting
in Equation (
24), we obtain the predictive conditional probability for the Dirichlet process, predicting a logarithmic growth of
[
12]. Correspondingly, if we chose
in the urn model, we obtain:
If we now neglect
in the denominator of (
27), we can solve in the large limit of large
n:
The same asymptotic growth of
is also found in one of the first models introducing innovation in the framework of Pólya’s urn, namely the Hoppe’s model [
36]. The motivation of the Hoppe’s work was to derive the Ewens’ sampling formula [
37], describing the allelic partition at equilibrium of a sample from a population evolved according to a discrete time Wright-Fisher process [
38,
39]. In the Hoppe model, innovations are introduced through a special ball, the “mutator”. In particular, the process starts with only the mutator in the urn, with a mass
. At any time
n, a ball is withdrawn with a probability proportional to its mass, and, if the ball is the mutator, it is placed back in the urn along with a ball of a brand new color, with unitary mass, thus increasing the number of different colors present in the urn. Otherwise, the selected ball is placed back in the urn along with another ball of the same color. Writing the recursive formula for
and taking the continuous limit, we obtain:
that is exactly Equation (
27) with
. It predicts a logarithmic increase of new colors in the urn:
corresponds to Equation (
28), by identifying
with
. Hoppe’s urn scheme is non-cooperative in the sense that one novelty does nothing to facilitate another. In other words, while in the Hoppe’s model a mechanism is already present that allows for the expansion of the space of possibilities, this mechanism is completely independent of the actual realization of a novelty, and fails to reproduce both the Heaps’ and the Zipf’s laws.
5. Fluctuation Scaling (Taylor’s Law)
From Equations (
14)–(
16), it is clear that randomly sampling a Zipf’s law with a given exponent results in a Heaps’ law with linear and sublinear exponents tuned by the exponent of the Zipf’s. On the other hand, Equations (
20)–(
22) show that the PUT model is also producing the same Heaps’ exponents with the same relation to the Zipf’s exponent as in the random sampling. Therefore, one legitimate question is whether the PUT is also actually performing a kind of sophisticated random sampling of an underlying Zipf’s law. One possible way to discriminate PUT from a random sampling is to look at the fluctuation scaling, i.e., the Taylor’s law discussed in
Section 2.3, which connects the standard deviation
s of a random variable to its mean
. Simple analytic calculations [
26] show that the Poissonian sampling of a power-law leads to a Taylor’s law with exponent 1/2, i.e.,
.
Real text analysis shows instead a Taylor exponent of 1 [
26], which points to the obvious conclusion that the process of writing texts is not an uncorrelated choice of words from a fixed distribution. In [
26] this was explained by a “topic-dependent frequencies of individual words”. The empirical observation therein, was that the frequency of a given word changes according to the topic of the writing. For example, the term “electron” has a high frequency in physics books and a low frequency in fairy tales, so that its rank is low in the first case and high in the second. The result is that there exist different Zipf’s laws with the same exponent according to the topic and the enhanced variance of the dictionary size is ascribable to this multitude of Zipf’s laws that add a further variability to the sampling process.
In PUT there is certainly no topicality as in real texts. Nevertheless, we find numerically a linear Taylor’s law in the case of sublinear Heaps’ exponents (). In PUT, there is no Zipf’s law beforehand: it is built during the process instead and this is sufficient to boost the variance of the dictionary, on average, at any given time.
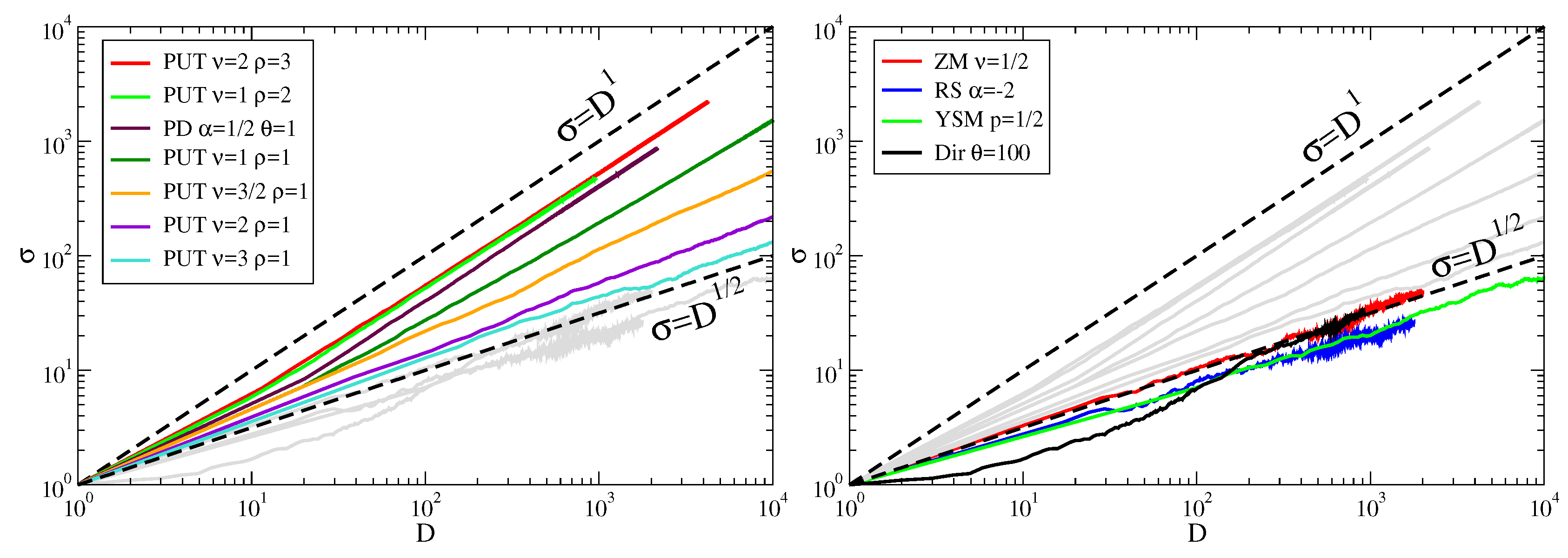
In
Figure 6, we show the numerical results of two simulations of PUT with
, one with
and one with
, in order to cover all the possible cases of Equations (
20)–(
22), plus the random sampling from a zipfian distribution with exponent
. Besides the interesting linearity of the fluctuation scaling in the case of
, its behaviour in case of fast growing spaces
can also be pointed out. In that case, Heaps’ law is linear as shown in Equation (
21), and the traditional model of reference is the Yule-Simon model (YSM) [
40]. The Yule-Simon model generates a sequence of characters with the following iterative rule. Starting from an initial character, at each time with a constant probability
p, a brand new character is chosen while with probability
one selects one of the characters already present in the sequence (which implies drawing them with their multiplicity). In this way, in YSM, the rate of growth of different characters is constant and equal to
p and this constant rate of innovation yields a linear Heaps’ law. The preferential attachment rule leads to a Zipf’s law with exponent
. This is consistent with Equation (
16) of random sampling and even with Equation (
21) of PUT. The difference between YSM and PUT can be appreciated with Taylor’s law. In YSM, new characters appear with probability
p so that the average number of different characters at step
N is
, and the variance
as in the binomial distribution. As a result, in YSM one gets the Poissonian result
. In contrast, PUT features numerically an exponent of
, i.e., larger than
but still less than 1 (see
Figure 6).
Given the intrinsic inability of YSM to accomplish for sub-linear dictionary growths, Zanette and Montemurro [
41] proposed a simple variant of it. In this variant (ZM), the rate of introduction of new characters, i.e.,
p, is not constant any more. It is made instead time-dependent with an
ad hoc chosen functional form able to reproduce the right range for the Heaps’ exponents. For a Heaps’ exponent
, the rate of innovation
p is chosen proportional to
. This expedient allows to reproduce both Zipf’s law and, by construction, Heaps’ law. The two mechanisms for Zipf’s and Heaps’ production are independent of each other as in YSM so that we expect for Taylor’s law the same behavior of YSM, i.e., an exponent
. After all, ZM can be seen as a YSM with a diluting time flow, which might not affect the scaling of the fluctuations of YSM at a given time. In
Figure 6 we show that indeed ZM features a Taylor’s exponent of
(magenta curve).
For the Poisson-Dirichlet and the Dirichlet processes, analytical solutions can be computed for the moments of the probability distribution
[
13,
42], yielding the asymptotic exponents respectively 1 and
in the Taylor’s law. Numerical results are given in
Figure 6. Note that a non trivial exponent in the Taylor’s law is featured by the Poisson-Dirichlet process, where the probability of a novelty to occur does depend on the number of previous novelties, while the Dirichlet process lacks both properties.
6. Discussion
In this paper we have argued that the notion of adjacent possible is key to explain the occurrence of the Zipf’s, Heaps’ and Taylor’s laws in a very general way. We have presented a mathematical framework, based on the notion of adjacent possible, and instantiated through a Polya’s urn modelling scheme, that accounts for the simultaneous validity of the three laws just mentioned in all their possible regimes.
We think this a very important result that will help in assessing the relevance and the scope of the many approaches proposed so far in the literature. In order to be as clear as possible, let us itemize the key points:
The first point we make is about the many claims made in literature about the possibility to deduce the Heaps’ law by simply sampling a Zipf-like distribution of frequencies of events. Though, as seen above, it is possible to deduce a power-law behaviour for the growth of distinct elements by randomly drawing from a Zipf-like distribution, this procedure does not allow to reproduce the empirical results. It has been conjectured in [
26], that texts are subject to a topicality phenomenon, i.e., writers do not sample the same Zipf’s law. This implies that the same word can appear at different ranking positions depending on the specific context. Though this is an interesting point, we think that the deduction of the Heaps’ law from the sampling of a Zipfian distribution is not satisfactory from two different points of view. First of all, the empirical Heaps’ and Zipf’s laws are never pure power-laws. We have seen for instance that for written texts the frequency-rank plot features a double slope. Nevertheless, we have seen that a relation exists between the exponent of the frequency-rank distribution at high ranks (rare words) and the asymptotic exponent of the Heaps’ law. In other words, the behaviour of the rarest words is responsible for the entrance rate of new words (or new items). Even though a pure power-law behaviour was observed, we have shown that the statistics of fluctuations, represented by the Taylor’s law, would not reproduce the empirical results (unless a specific sampling procedure based on the hypothesis of topicality is adopted [
26]). The conclusion to be taken is that in general the Heaps’ and the Zipf’s laws are non-trivially related and their explanation should be made based instead on first-principle.
Models featuring a fixed space of possibilities are not able to reproduce the simultaneous occurrence of the three laws. For instance, a multicolor Polya’s urn model [
29] does not even produce power-law-like behaviours for the Zipf’s and the Heaps’ laws. It rather features a saturation phenomenon, related to the exploration of the predefined boundaries of the space of possibilities. The conclusion here is that one needs a modelling scheme featuring a space of possibilities with dynamical boundaries, for instance expanding ones.
Models that incorporate the possibility to expand the space of possibilities like the Yule-Simon [
40] model or the Hoppe model fail in explaining the empirical results. In the Yule-Simon model, the innovation rate is constant and the the Heaps’ law is reproduced with the trivial unitary exponent. An ad-hoc correction to this has been proposed by Zanette and Montemurro [
41], who postulate a sublinear power-law Heaps’s law form the outset, without providing any first-principle explanation for it. In addition, in this case the result is not satisfactory because the resulting time-series does not obey the Taylor’s law, being instead compatible with a series of i.i.d variables. The question is now why this approach is not reproducing Taylor’s law despite the fact that it fixes the expansion of the space of possibilities. In our opinion what is lacking in the scheme by Zanette and Montemurro is the interplay between the preferential attachment mechanism and the exploration of new possibilities. In other words, the triggering effect which is instead a key features of the PUT model (see next item). The situation for the Hoppe model is different [
36], i.e., a multicolor Polya’s urn with a special replicator color. In this case, though a self-consistent expansion of the space of possibilities is in place, an explicit mechanism of triggering, in which the realization of an innovation facilitates the realization of further innovations, lacks. In this case the innovation rate is too weak and the Heap’s law features only a logarithmic growth, i.e., it is slower than any power-law sublinear behaviour.
The Polya’s urn model with triggering (PUT) [
10], incorporating the notion of adjacent possible, allows to simultaneously account for the three laws, Zipf’s, Heaps’ and Taylor’s, in all their regimes, without ad-hoc or arbitrary assumptions. In this case, the space of possibilities expands conditional to the occurrence of novel events in a way that is compatible with the empirical findings. From the mathematical point of view, the expansion into the adjacent possible solves another issue related to Zipf’s and Heaps’ generative models. In fact, in PUT one can switch with continuity from the sublinear to the linear regime of the dictionary growth and vice-versa and this by tuning one parameter only: the ratio
. This ratio is not limited to a ratio of integers. In fact, in the SI of [
10] it was demonstrated that the same expressions for the Heaps’ and Zipf’s laws are recovered if one uses parameters
and
extracted from a distribution with fixed means. One possible strategy is to fix an integer
while
can assume any value in the real numbers (in simulations this is a floating point value), and the mantissa can be taken into account by resorting to probabilities. Therefore, it is perfectly sound to state that one switches
with continuity from the sublinear regime to the linear one in the interval
, with
, although the rigorous mathematical characterization of the transition is far from being understood.
It should be remarked that the Poisson-Dirichlet process [
12,
13,
14] is also able to explain the three Zipf’s, Heaps’ and Taylor’s laws only in the strict sub-linear regime for the Heaps’ law. It cannot however account for a constant innovation rate as in the PUT modelling scheme. We also point out that the PUT model embraces the Poisson-Dirichlet and the Dirichlet processes as particular cases.
In this paper we highlighted that the simultaneous occurrence of the Zipf’s, Heaps’ and Taylor’s laws can be explained in the framework of the adjacent possible scheme. This implies considering a space of possibilities that expands or gets restructured conditional to the occurrence of a novel event. The Pólya’s urn with triggering features these properties. Poisson-Dirichlet processes can also be said to belong to the adjacent possible scheme. Though no explicit mention is made about the space of possibilities in those schemes, the probability of the occurrence of a novel event closely depends on how many novelties occurred in the past. We recall that the PUT model includes Dirichlet-like processes as particular cases. From this perspective, PUT-like models seem to be good candidates to explain higher order features connected to innovation processes. We conclude by saying that the very notion of adjacent possible, though sufficient to explain the stylized facts of innovation processes, can be only conjecture as a necessary condition for the validity of the three laws mentioned above. No counterexamples have been found so far with which, without a dynamically restructured space of possibilities, one can satisfactorily explain the empirically observed laws.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





