The Reconciliation of Multiple Conflicting Estimates: Entropy-Based and Axiomatic Approaches


Abstract
:1. Introduction
2. Entropy-Based Approach
2.1. Basic Concepts
2.2. Problem Formulation
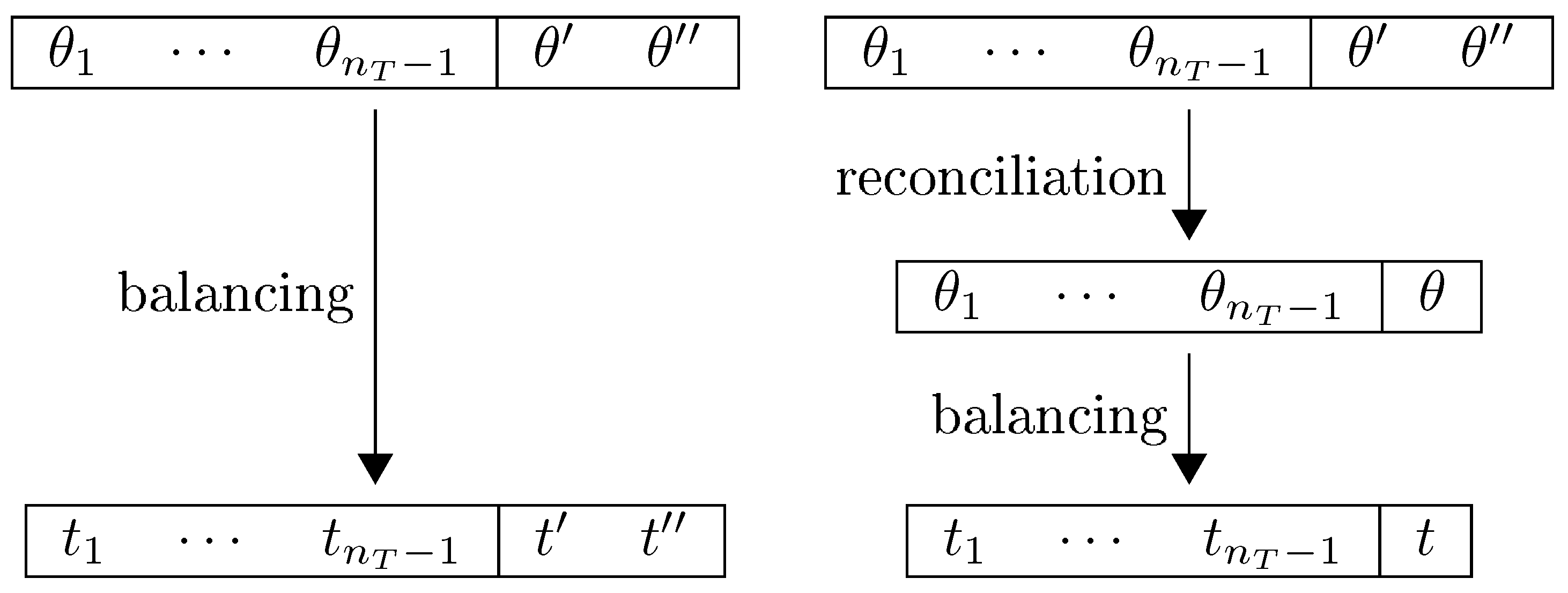
2.3. From Balancing to Reconciliation
2.4. A Tentative Solution
2.4.1. Aggregate Datum
2.4.2. Disaggregate Datum
2.4.3. Mixed Datum
3. Axiomatic Approach
3.1. Axiomatic Formulation
3.2. The Canonical Data Reconciliation Method
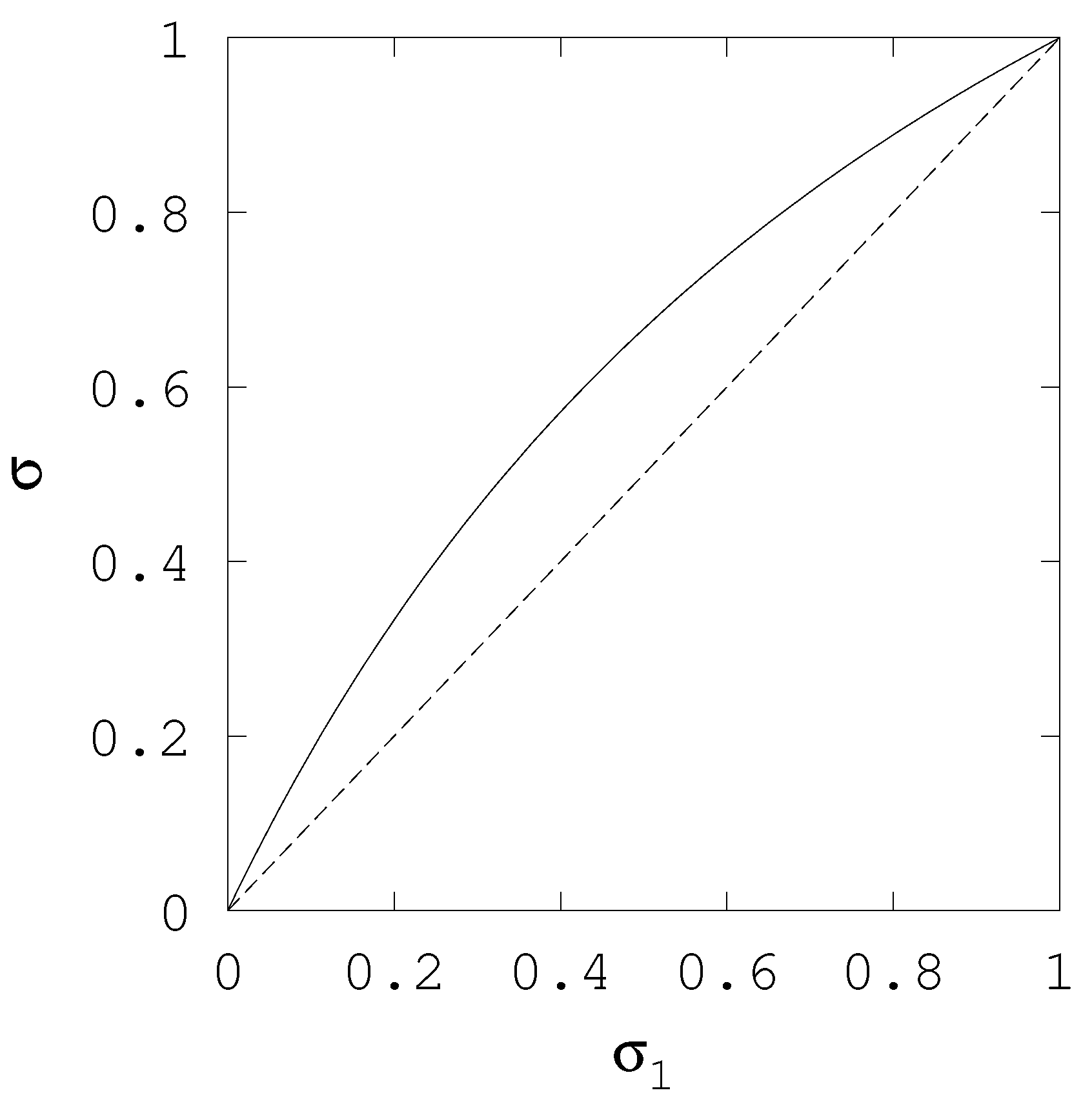
3.3. The Number of Combined Priors
3.4. Ranking of Data Quality
3.5. Summary
4. Conclusions and Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lohr, S. The Origins of ‘Big Data’: An Etymological Detective Story. New York Times. 2013. Available online: https://bits.blogs.nytimes.com/2013/02/01/the-origins-of-big-data-an-etymological-detective-story/ (accessed on 22 October 2018).
- Duncan, G.T.; Elliot, M.; Salazar-Gonzalez, J.J. Statistical Confidentiality: Principles and Practice; Springer: New York, NY, USA, 2011. [Google Scholar]
- Garfinkel, R.; Gopal, R.; Goes, P. Privacy Protection of Binary Confidential Data against Deterministic, Stochastic, and Insider Attack. Manag. Sci. 2002, 48, 749–764. [Google Scholar] [CrossRef]
- Evans, T.; Zayatz, L.; Slanta, J. Using Noise for Disclosure Limitation of Establishment Tabular Data. Off. Stat. 1998, 14, 537–551. [Google Scholar]
- Miller, R.E.; Blair, P.D. Input-Output Analysis: Foundations and Extensions, 2nd ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Kruithof, R. Telefoonverkeersrekening. De Ingenieur 1937, 52, E15–E25. (In Dutch) [Google Scholar]
- Stone, R.; Meade, J.E.; Champernowne, D.G. The Precision of National Income Estimates. Rev. Econ. Stud. 1942, 9, 111–125. [Google Scholar] [CrossRef]
- Byron, R. The Estimation of Large Social Account Matrices. Stat. Soc. Ser. A 1978, 141, 359–367. [Google Scholar] [CrossRef]
- Van Der Ploeg, F. Reliability and the Adjustment of Sequences of Large Economic Accounting Matrices. Stat. Soc. Ser. A 1982, 145, 169–194. [Google Scholar] [CrossRef]
- Lahr, M.L.; Mesnard, L.D. Biproportional Techniques in Input-Output Analysis: Table Updating and Structural Analysis. Econ. Syst. Res. 2004, 16, 115–134. [Google Scholar] [CrossRef] [Green Version]
- Chen, B. A Balanced System of U.S. Industry Accounts and Distribution of the Aggregate Statistical Discrepancy by Industry. Bus. Econ. Stat. 2012, 30, 202–211. [Google Scholar] [CrossRef]
- Isserman, A.; Westervelt, J. 1.5 Million Missing Numbers: Overcoming Employment Suppression in County Business Patterns Data. Int. Reg. Sci. Rev. 2006, 29, 311–335. [Google Scholar] [CrossRef]
- Gerking, S.; Isserman, A.; Hamilton, W.; Pickton, T.; Smirnov, O.; Sorenson, D. Anti-suppressants and the Creation and Use of Non-Survey Regional Input-Output Models. In Regional Science Perspectives in Economic Analysis: A Festschrift in Memory of Benjamin H. Stevens; Lahr, M., Miller, R., Eds.; Elsevier: New York, NY, USA, 2001; pp. 379–406. [Google Scholar]
- Rodrigues, J.; Marques, A.; Wood, R.; Tukker, A. A network approach for assembling and linking input-output models. Econ. Syst. Res. 2016, 28, 518–538. [Google Scholar] [CrossRef]
- Bourque, P.J.; Chambers, E.J.; Chiu, J.S.Y.; Denman, F.L.; Dowdle, B.; Gordon, G.; Thomas, M.; Tiebout, C.; Weeks, E.E. The Washington Economy: An Input-Output Study; University of Washington: Seattle, WA, USA, 1967. [Google Scholar]
- Miernyk, W.H.; Shellhammer, K.L.; Brown, D.M.; Coccari, R.L.; Gallagher, C.J.; Wineman, W.H. Simulating Regional Economic Development: An Interindustry Analysis of the West Virginia Economy; D.C. Heath and Co.: Lexington, KY, USA, 1970. [Google Scholar]
- Jensen, R.C.; McGaurr, D. Reconciliation of purchases and sales estimates in an Input-Output table. Urban Stud. 1976, 13, 59–65. [Google Scholar] [CrossRef]
- Gerking, S. Reconciling ‘rows only’ and ‘columns only’ coefficients in an Input-Output model. Int. Reg. Sci. Rev. 1976, 1, 623–626. [Google Scholar] [CrossRef]
- Gerking, S. Reconciling reconciliation procedures in regional Input-Output Analysis. Int. Reg. Sci. Rev. 1979, 4, 23–36. [Google Scholar] [CrossRef]
- Weale, M. The reconciliation of values, volumes and prices in national accounts. Stat. Soc. Ser. A 1988, 151, 211–221. [Google Scholar] [CrossRef]
- Boomsma, P.; Oosterhaven, J. A double-entry method for the construction of bi-regional Input-Output tables. Reg. Sci. 1992, 32, 269–284. [Google Scholar] [CrossRef]
- Rassier, D.; Howells, T.; Morgan, E.; Empey, N.; Roesch, C. Implementing a Reconciliation and Balancing Model in the U.S. Industry Accounts; Working Paper WP2007-4; Bureau of Economic Analysis: Washington, DC, USA, 2007.
- Jaynes, E.T. Probability Theory: The Logic of Science; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Rodrigues, J.F.D. A Bayesian Approach to the Balancing of Statistical Economic Data. Entropy 2014, 16, 1243–1271. [Google Scholar] [CrossRef] [Green Version]
- Persons, W.M. Fisher’s Formula for Index Numbers. Rev. Econ. Stat. 1921, 3, 103–113. [Google Scholar] [CrossRef]
- Kop Jansen, P.; Raa, T.T. The Choice of Model in the Construction of Input-Output Coefficients Matrices. Int. Econ. Rev. 1990, 31, 213–227. [Google Scholar] [CrossRef]
- Schneider, J.R.T.D.S.G.F. Designing an indicator of environmental responsibility. Ecol. Econ. 2006, 59, 256–266. [Google Scholar]
- Laplace, P.S. Essai Philosophique sur les Probabilités; Courcier Imprimeur: Paris, France, 1814. [Google Scholar]
- Jeffreys, H. Theory of Probability; Clarendon Press: Oxford, UK, 1939. [Google Scholar]
- Jaynes, E.T. Papers on Probability, Statistics and Statistical Physics; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1983. [Google Scholar]
- Weise, K.; Woger, W. A Bayesian theory of measurement uncertainty. Meas. Sci. Technol. 1992, 4, 1–11. [Google Scholar] [CrossRef]
- Rodrigues, J.F.D. Maximum-Entropy Prior Uncertainty and Correlation of Statistical Economic Data. Bus. Econ. Stat. 2016, 34, 357–367. [Google Scholar] [CrossRef] [Green Version]
- Jaynes, E.T. Information Theory and Statistical Mechanics I. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Makarkina, G.V.; Lahr, M.L. Estimating Nationwide Impacts using an Input-Output Model with Fuzzy Parameters. In Proceedings of the 25th International Input-Output Conference, Atlantic, NJ, USA, 19–23 June 2017. [Google Scholar]
- Keane, E.A.L.M.J. Inconsistency reduction in decision making via multi-objective optimisation. Eur. Oper. Res. 2018, 267, 212–226. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| d | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | −1 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | |
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | −1 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | −1 |
| d | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | −1 | 0 | 1 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | −1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | −1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | −1 |
| 1 | 1 | 1 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | |
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | −1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | −1 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | −1 |
| d | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | |
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | −1 | 1 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | −1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | −1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodrigues, J.F.D.; Lahr, M.L. The Reconciliation of Multiple Conflicting Estimates: Entropy-Based and Axiomatic Approaches. Entropy 2018, 20, 815. https://doi.org/10.3390/e20110815
Rodrigues JFD, Lahr ML. The Reconciliation of Multiple Conflicting Estimates: Entropy-Based and Axiomatic Approaches. Entropy. 2018; 20(11):815. https://doi.org/10.3390/e20110815
Chicago/Turabian StyleRodrigues, João F. D., and Michael L. Lahr. 2018. "The Reconciliation of Multiple Conflicting Estimates: Entropy-Based and Axiomatic Approaches" Entropy 20, no. 11: 815. https://doi.org/10.3390/e20110815
APA StyleRodrigues, J. F. D., & Lahr, M. L. (2018). The Reconciliation of Multiple Conflicting Estimates: Entropy-Based and Axiomatic Approaches. Entropy, 20(11), 815. https://doi.org/10.3390/e20110815